اليوم على المواقع الأجنبية المواضيعية حول البيانات الكبيرة ، يمكنك أن تجد إشارة إلى هذه الأداة الجديدة نسبيا لنظام Hadoop البيئي مثل Apache NiFi. هذا هو أداة ETL مفتوحة المصدر الحديثة. تعتبر البنية الموزعة للتحميل المتوازي السريع ومعالجة البيانات ، وعدد كبير من المكونات الإضافية للمصادر والتحويلات ، وإصدار التكوينات جزءًا فقط من مزاياها. مع كل قوتها ، تظل NiFi سهلة الاستخدام إلى حد ما.
نسعى في Rostelecom لتطوير العمل مع Hadoop ، لذلك قمنا بالفعل بتقييم وتقييم مزايا Apache NiFi مقارنة بالحلول الأخرى. سأخبرك في هذه المقالة كيف جذبتنا هذه الأداة وكيف نستخدمها.
الخلفية
منذ وقت ليس ببعيد ، واجهنا اختيار حل لتحميل البيانات من مصادر خارجية إلى مجموعة Hadoop. لفترة طويلة ، استخدمنا
Apache Flume لحل هذه المشكلات. لم تكن هناك شكاوى حول Flume ككل ، باستثناء بضع نقاط لا تناسبنا.
أول شيء لم نكن نحن كمسؤولين فيه ، هو أن كتابة تهيئة Flume لتنفيذ التنزيل التافه التالي لا يمكن أن يعهد بها إلى مطور أو محلل لم يكن منغمسًا في تعقيدات هذه الأداة. ربط كل مصدر جديد مطلوب تدخل إلزامي من فريق الإدارة.
النقطة الثانية هي التسامح مع الخطأ والتوسع. للتنزيلات الثقيلة ، على سبيل المثال ، عبر syslog ، كان من الضروري تكوين عدة عوامل Flume وتعيين موازن أمامها. كل هذا كان لابد من مراقبته واستعادته بطريقة ما في حالة حدوث عطل.
ثالثًا ، لم يسمح Flume بتنزيل البيانات من قواعد بيانات متعددة (DBMS) والعمل مع بعض البروتوكولات الأخرى خارج الصندوق. بالطبع ، في المساحات الشاسعة من الشبكة ، يمكنك إيجاد طرق لجعل Flume تعمل مع Oracle أو SFTP ، ولكن دعم هذه الدراجات ليس ممتعًا على الإطلاق. لتحميل البيانات من نفس Oracle ، كان علينا استخدام أداة أخرى -
Apache Sqoop .
بصراحة ، بطبيعتي أنا شخص كسول ، ولم أكن أرغب في دعم حديقة الحيوانات على الإطلاق. ولم يعجبني أن كل هذا العمل يجب أن أقوم به بنفسي.
هناك ، بالطبع ، حلول قوية للغاية في سوق أدوات ETL يمكنها العمل مع Hadoop. وتشمل هذه المعلومات Informatica و IBM Datastage و SAS و Pentaho Data Integration. هذه هي الأشياء التي يمكن سماعها في أغلب الأحيان من الزملاء في ورشة العمل وتلك التي تتبادر إلى الذهن أولاً. بالمناسبة ، نستخدم IBM DataStage لـ ETL في حلول فئة Data Warehouse. ولكن حدث ذلك تاريخيًا حتى لم يتمكن فريقنا من استخدام DataStage للتنزيلات في Hadoop. مرة أخرى ، لم نكن بحاجة إلى القوة الكاملة للحلول من هذا المستوى لإجراء تحويلات بسيطة وتنزيلات للبيانات. ما احتجنا إليه هو إيجاد حل بديناميكيات تطوير جيدة وقادرة على العمل مع العديد من البروتوكولات ولديه واجهة مريحة وبديهية لم يكن فقط المسؤول الذي يفهم كل التفاصيل الدقيقة قادراً على التعامل معها ، ولكن أيضًا مطور مع محلل ، والذي غالبًا ما يكون لنا عملاء البيانات نفسها.
كما ترون من العنوان ، قمنا بحل المشكلات المذكورة أعلاه مع Apache NiFi.
ما هو اباتشي نيفي
اسم NiFi يأتي من "ملفات نياجرا". تم تطوير المشروع من قبل وكالة الأمن القومي الأمريكية لمدة ثماني سنوات ، وفي نوفمبر 2014 تم فتح الكود المصدري الخاص به ونقله إلى مؤسسة Apache Software Foundation كجزء من
برنامج نقل التكنولوجيا التابع لوكالة الأمن القومي .
NiFi عبارة عن أداة ETL / ELT مفتوحة المصدر يمكنها العمل مع العديد من الأنظمة ، وليس فقط فئات البيانات الكبيرة ومستودع البيانات. فيما يلي بعض منها: HDFS و Hive و HBase و Solr و Cassandra و MongoDB و ElastcSearch و Kafka و RabbitMQ و Syslog و HTTPS و SFTP. يمكنك رؤية القائمة الكاملة في
الوثائق الرسمية.
يتم تطبيق العمل مع DBMS معين عن طريق إضافة برنامج تشغيل JDBC المناسب. هناك واجهة برمجة تطبيقات لكتابة وحدتك كمستقبل إضافي أو محول بيانات. أمثلة يمكن العثور عليها
هنا وهنا .
الميزات الرئيسية
يستخدم NiFi واجهة ويب لإنشاء DataFlow. سوف يتعامل معها محلل بدأ مؤخرًا العمل مع Hadoop ، وهو مطور ، ومسؤول ملتح. يمكن أن يتفاعل الأخيران ليس فقط مع "المستطيلات والسهام" ، ولكن أيضًا مع
REST API لجمع الإحصاءات ومراقبة وإدارة مكونات DataFlow.
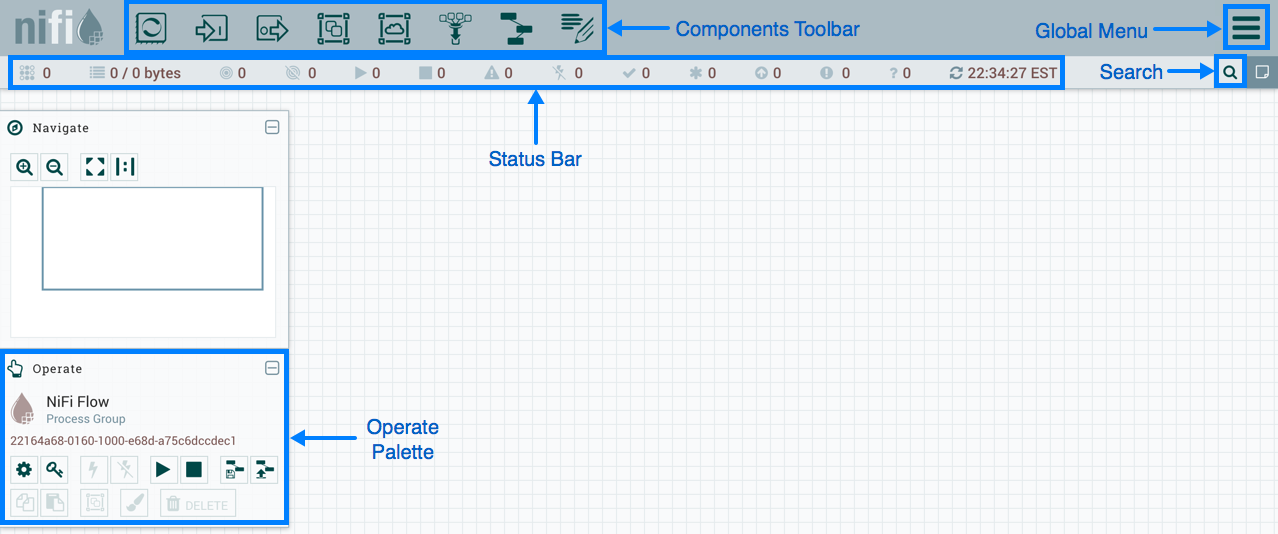 نيفي على شبكة الإنترنت الإدارة
نيفي على شبكة الإنترنت الإدارةأدناه سأعرض بعض أمثلة DataFlow لأداء بعض العمليات المشتركة.
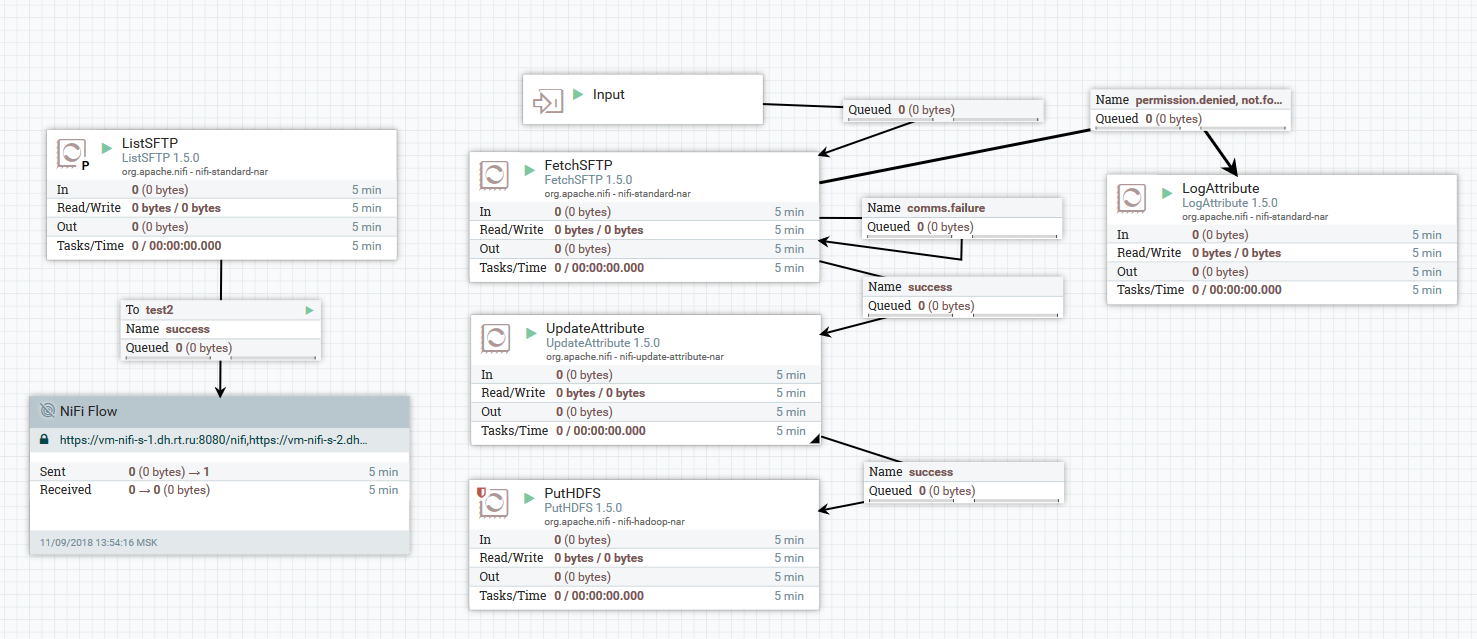 مثال على تنزيل الملفات من خادم SFTP إلى HDFS
مثال على تنزيل الملفات من خادم SFTP إلى HDFSفي هذا المثال ، يقوم معالج ListSFTP بإدراج ملف على الخادم البعيد. يتم استخدام نتيجة هذه القائمة لتحميل ملف متوازي بواسطة كافة عقد الكتلة بواسطة معالج FetchSFTP. بعد ذلك ، تتم إضافة السمات إلى كل ملف ، يتم الحصول عليها عن طريق تحليل اسمه ، والتي يتم استخدامها بعد ذلك بواسطة معالج PutHDFS عند كتابة الملف إلى الدليل النهائي.
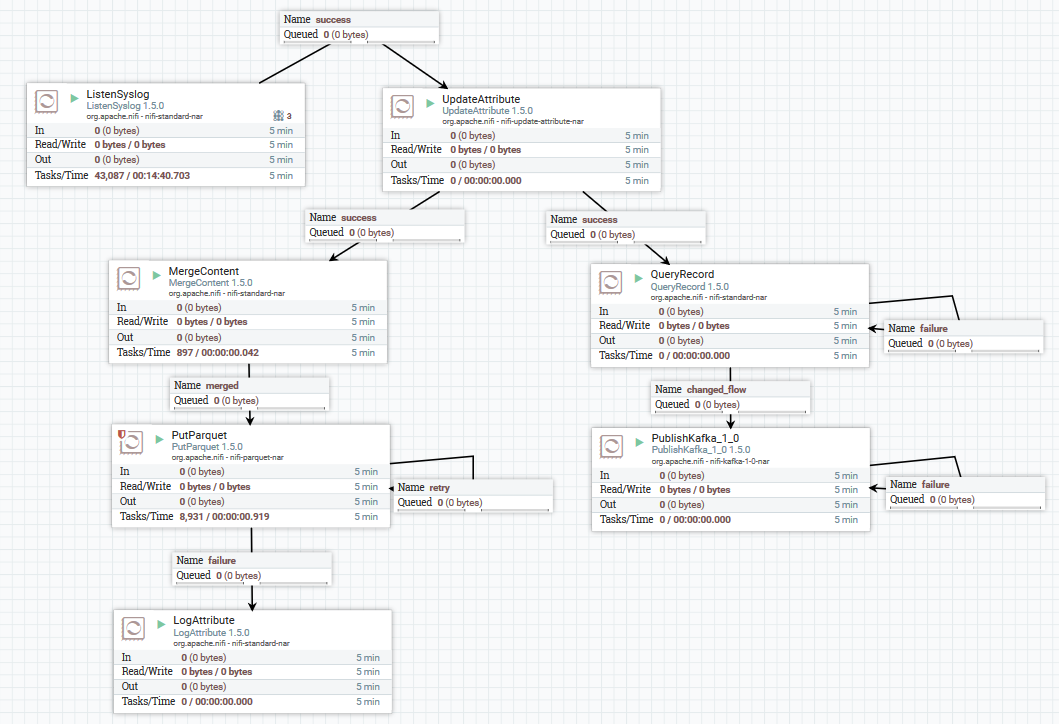 مثال على تنزيل بيانات syslog في Kafka و HDFS
مثال على تنزيل بيانات syslog في Kafka و HDFSهنا ، باستخدام معالج ListenSyslog ، نحصل على دفق رسالة الإدخال. بعد ذلك ، تتم إضافة سمات حول وقت وصولهم إلى NiFi واسم المخطط في Avro Schema Registry إلى كل مجموعة رسائل. بعد ذلك ، يتم توجيه الفرع الأول إلى مدخلات معالج QueryRecord ، والذي ، بناءً على المخطط المحدد ، يقرأ البيانات ويوزعها باستخدام SQL ، ثم يرسلها إلى كافكا. يتم إرسال الفرع الثاني إلى معالج MergeContent ، الذي يقوم بتجميع البيانات لمدة 10 دقائق ، ثم يعطيه للمعالج التالي للتحويل إلى تنسيق Parquet والتسجيل إلى HDFS.
فيما يلي مثال على كيفية قيامك بتصميم DataFlow:
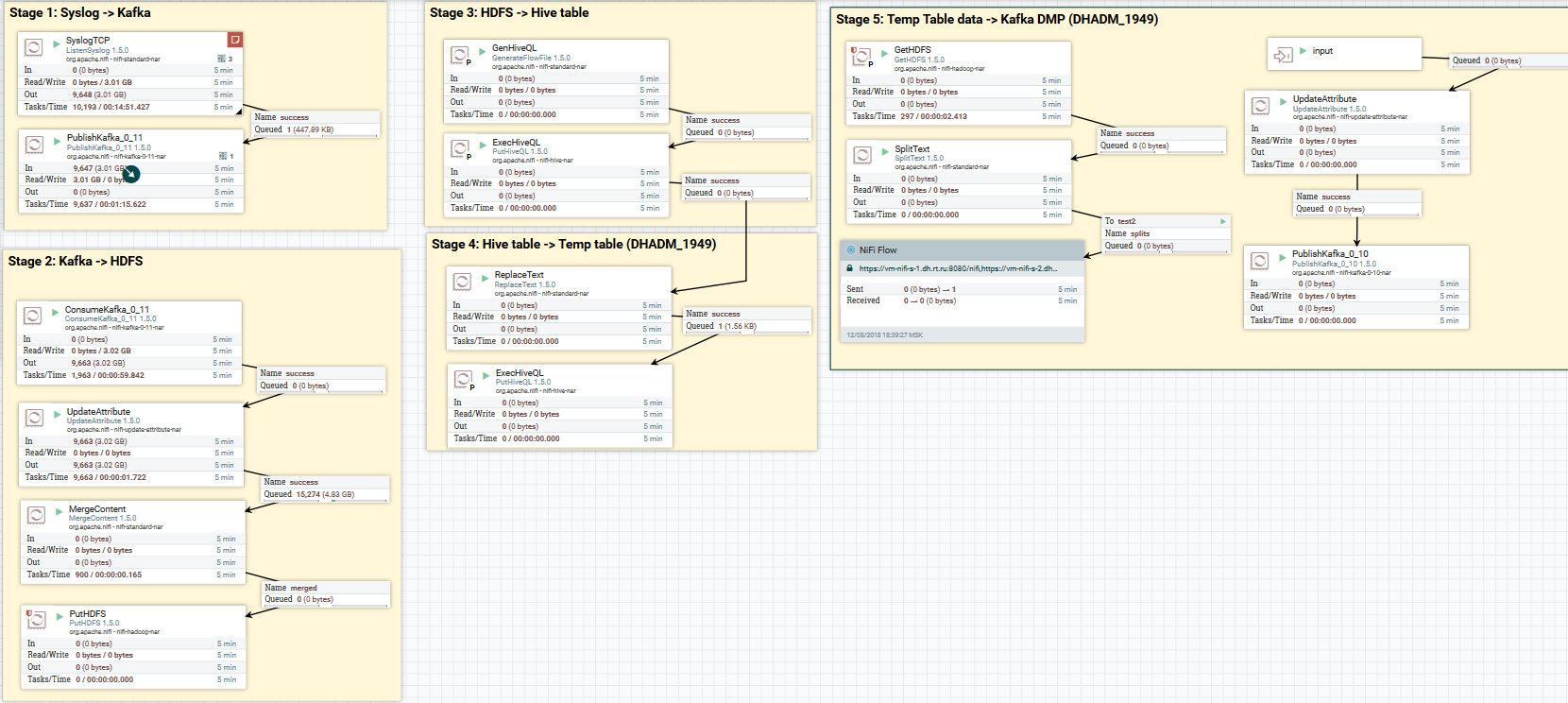 قم بتنزيل بيانات syslog على Kafka و HDFS. مسح البيانات في الخلية
قم بتنزيل بيانات syslog على Kafka و HDFS. مسح البيانات في الخليةالآن حول تحويل البيانات. يتيح لك NiFi تحليل البيانات مع البيانات العادية وتنفيذ SQL عليها وتصفية الحقول وإضافتها وتحويل تنسيق بيانات واحد إلى آخر. كما أن لديها لغة تعبير خاصة بها ، غنية بالعديد من العوامل والوظائف المدمجة. مع ذلك ، يمكنك إضافة متغيرات وسمات إلى البيانات ، ومقارنة وحساب القيم ، واستخدامها لاحقًا في تكوين العديد من المعلمات ، مثل مسار الكتابة إلى HDFS أو استعلام SQL في Hive. اقرأ المزيد
هنا .
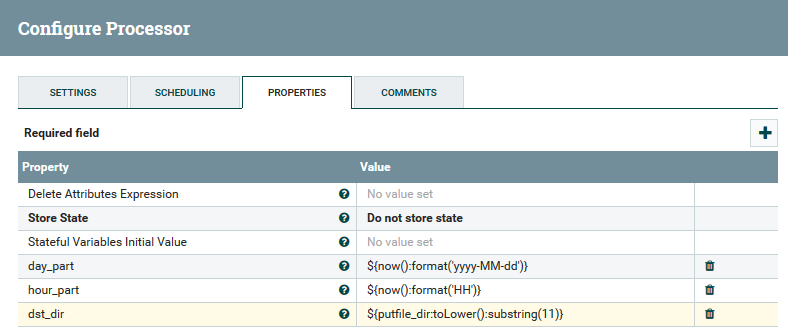 مثال على استخدام المتغيرات والوظائف في معالج UpdateAttribute
مثال على استخدام المتغيرات والوظائف في معالج UpdateAttributeيمكن للمستخدم تتبع المسار الكامل للبيانات ، ومراقبة التغيير في محتوياتها وسماتها.
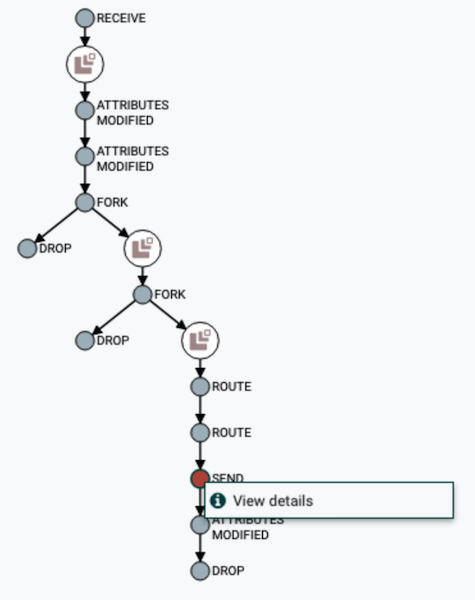 التصور سلسلة DataFlow
التصور سلسلة DataFlow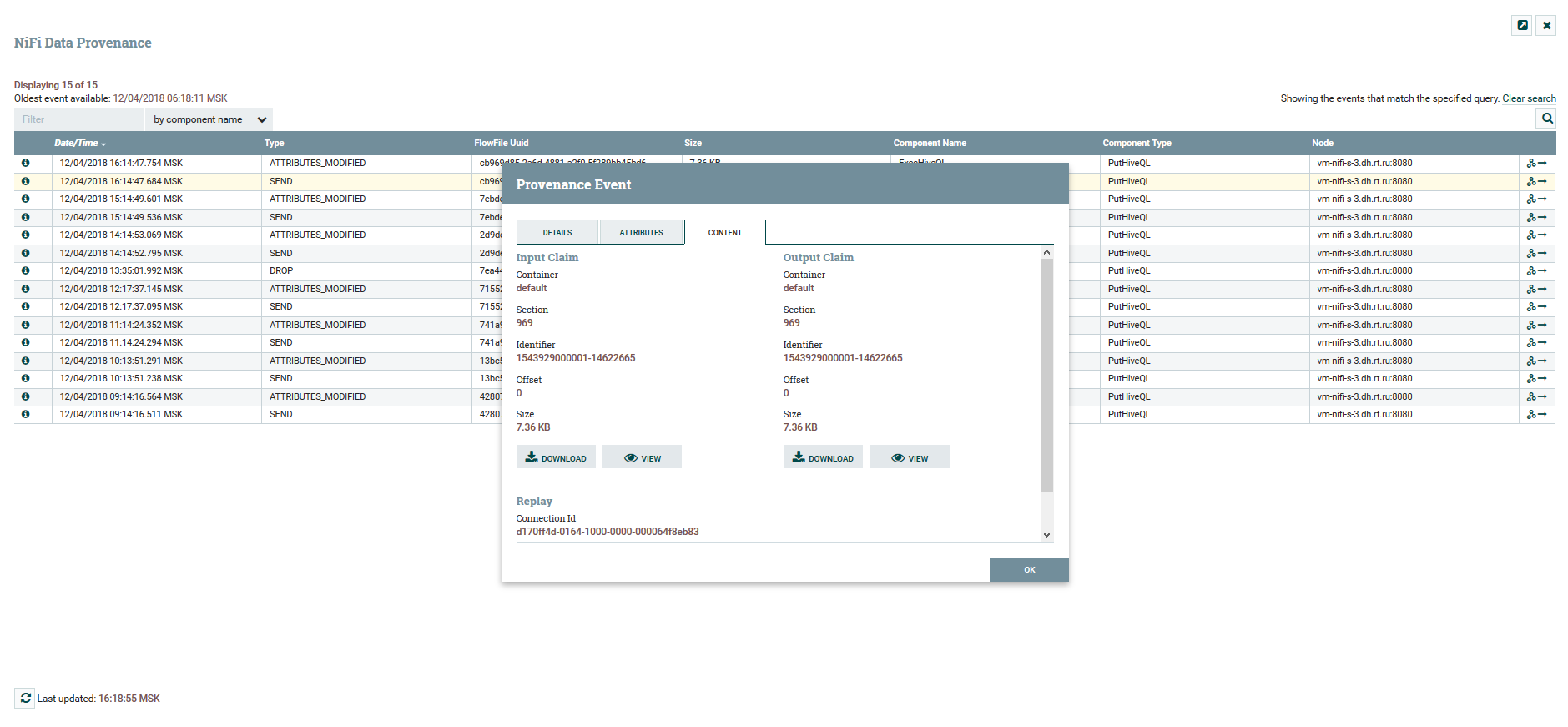 عرض سمات المحتوى والبيانات
عرض سمات المحتوى والبياناتلإصدار
DataFlow ، هناك خدمة منفصلة
لتسجيل NiFi . من خلال إعداده ، يمكنك الحصول على القدرة على إدارة التغييرات. يمكنك تشغيل التغييرات المحلية أو التراجع أو تنزيل أي إصدار سابق.
 قائمة التحكم الإصدار
قائمة التحكم الإصدارفي NiFi ، يمكنك التحكم في الوصول إلى واجهة الويب وفصل حقوق المستخدم. آليات المصادقة التالية مدعومة حاليًا:
الاستخدام المتزامن لعدة آليات في وقت واحد غير معتمد. لتخويل المستخدمين في النظام ، يتم استخدام FileUserGroupProvider و LdapUserGroupProvider. اقرأ المزيد عن هذا
هنا .
كما قلت ، NiFi يمكن أن تعمل في وضع الكتلة. هذا يوفر التسامح مع الخطأ ويمكّن من قياس الحمل الأفقي. لا توجد عقدة رئيسية ثابتة ثابتًا. بدلاً من ذلك ، يقوم
Apache Zookeeper بتحديد عقدة واحدة كمنسق وواحدة أساسية. يتلقى المنسق معلومات حول حالته من العقد الأخرى ويكون مسؤولاً عن اتصاله وانقطاع الاتصال به.
يتم استخدام العقدة الأولية لبدء المعالجات المعزولة ، والتي يجب ألا تعمل على جميع العقد في وقت واحد.
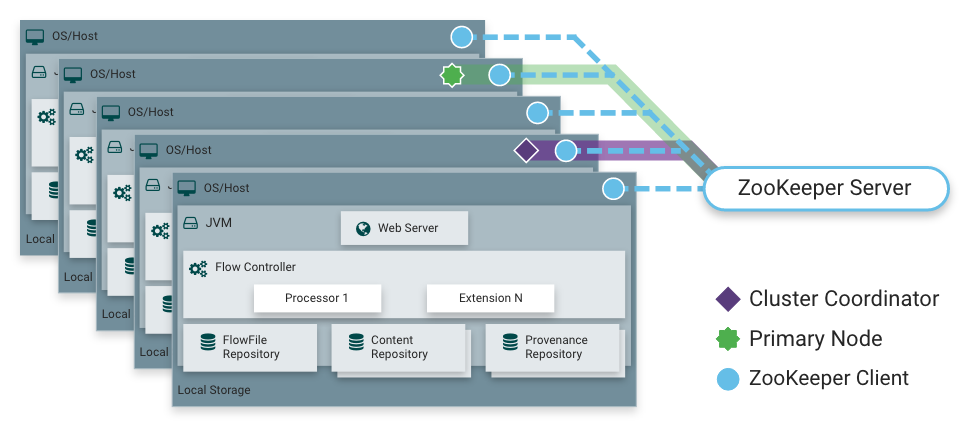 عملية NiFi في كتلة
عملية NiFi في كتلة تحميل التوزيع بواسطة عقد الكتلة باستخدام معالج PutHDFS كمثال
تحميل التوزيع بواسطة عقد الكتلة باستخدام معالج PutHDFS كمثالوصف موجز للهندسة المعمارية ومكونات NiFi
 نيفي مثيل العمارة
نيفي مثيل العمارةتعتمد NiFi على مفهوم "البرمجة المستندة إلى التدفق" (
FBP ). فيما يلي المفاهيم والمكونات الأساسية التي يواجهها كل مستخدم:
FlowFile - كيان يمثل كائنًا ذو محتوى من صفر أو أكثر من البايت وسماته المقابلة. يمكن أن يكون هذا إما البيانات نفسها (على سبيل المثال ، تدفق رسالة Kafka) ، أو نتيجة المعالج (PutSQL ، على سبيل المثال) ، والذي لا يحتوي على بيانات على هذا النحو ، ولكن فقط السمات التي تم إنشاؤها كنتيجة للاستعلام. السمات هي بيانات تعريفية FlowFile.
FlowFile Processor هو بالضبط جوهر العمل الأساسي في NiFi. كقاعدة عامة ، يحتوي المعالج على وظيفة واحدة أو عدة وظائف للعمل مع FlowFile: إنشاء ، قراءة / كتابة وتغيير المحتويات ، قراءة / الكتابة / تغيير السمات ، التوجيه. على سبيل المثال ، يتلقى معالج ListenSyslog البيانات باستخدام بروتوكول syslog ، ويقوم بإنشاء FlowFiles باستخدام السمات syslog.version و syslog.hostname و syslog.sender وغيرهم. يقرأ معالج RouteOnAttribute سمات الإدخال FlowFile ويقرر إعادة توجيهها إلى الاتصال المناسب مع معالج آخر ، اعتمادًا على قيم السمات.
اتصال - يوفر اتصال flowFile والنقل بين المعالجات المختلفة وبعض كيانات NiFi الأخرى. يضع الاتصال FlowFile في قائمة انتظار ، ثم يمررها إلى أسفل السلسلة. يمكنك تكوين كيفية اختيار FlowFiles من قائمة الانتظار ، وعمرها ، والحد الأقصى لعدد وحجم جميع الكائنات في قائمة الانتظار.
مجموعة العمليات - مجموعة من المعالجات ، اتصالاتهم وعناصر DataFlow الأخرى. إنها آلية لتنظيم العديد من المكونات في بنية منطقية واحدة. يساعد في تبسيط فهم DataFlow. تستخدم منافذ الإدخال / الإخراج لتلقي وإرسال البيانات من مجموعات العمليات. اقرأ المزيد عن استخدامها
هنا .
مستودع FlowFile هو المكان الذي يخزن فيه NiFi جميع المعلومات التي يعرفها عن كل FlowFile الموجود في النظام.
مستودع المحتوى - مستودع التخزين الذي توجد به محتويات كل FlowFiles ، أي البيانات المنقولة نفسها.
Provenance Repository - يحتوي على قصة عن كل FlowFile. في كل مرة يحدث فيها حدث مع FlowFile (الإنشاء ، التغيير ، إلخ) ، يتم إدخال المعلومات المقابلة في هذا المستودع.
خادم الويب - يوفر واجهة ويب وواجهة برمجة تطبيقات REST.
الخاتمة
مع NiFi ، تمكنت Rostelecom من تحسين آلية تسليم البيانات إلى Data Lake على Hadoop. بشكل عام ، أصبحت العملية برمتها أكثر ملاءمة وموثوقية. اليوم ، يمكنني أن أقول بثقة أن NiFi شيء رائع للتنزيل على Hadoop. ليس لدينا أي مشاكل في عملها.
بالمناسبة ، تعد NiFi جزءًا من توزيع Hortonworks Data Flow ويتم تطويرها بنشاط بواسطة Hortonworks نفسها. لديه أيضًا مشروع فرعي Apache MiNiFi ، والذي يسمح لك بجمع البيانات من الأجهزة المختلفة ودمجها في DataFlow داخل NiFi.
معلومات إضافية حول NiFi
ربما هذا كل شيء. شكرا لكم جميعا على اهتمامكم. اكتب التعليقات إذا كانت لديك أسئلة. سأجيب عليها بكل سرور.