
ينشئ DeepMind خوارزميات مدهشة حقًا قادرة على تحقيق ما لم تستطع أنظمة الماكينات تحقيقه من قبل. على وجه الخصوص ،
تمكنت الشبكة العصبية
AlphaGo من التغلب على أفضل اللاعبين في العالم. وفقًا للخبراء ، فإن قدرات النظام قد نمت كثيرًا حتى لا يكون من المنطقي حتى محاولة إلحاق الهزيمة به - فالنتيجة محددة مسبقًا.
ومع ذلك ، فإن الشركة لا تتوقف عند هذا الحد ، ولكنها تواصل العمل. بفضل بحث موظفيها ، ولدت نسخة محسنة من AlphaGo ، تسمى AlphaZero. كما هو موضح في العنوان ، كان النظام نفسه قادرًا على تعلم كيفية لعب ثلاث ألعاب منطقية في آن واحد - لعبة الشطرنج والشوغي والذهاب.
كان الفرق بين الإصدار الجديد وجميع الإصدارات السابقة
هو أن النظام نفسه تعلم كل شيء تقريبًا. بدأت من الصفر وتعلمت بسرعة أن تلعب جميع الألعاب الثلاث بشكل مثالي. لا أحد ساعد AlphaZero - النظام "حصل على كل شيء بنفسه".
تم تضمين الشطرنج في المجموعة ، بدلاً من ذلك ، وفقًا للتقاليد - ليس من الصعب تعليم الكمبيوتر كيفية لعب الشطرنج ، لا. لأول مرة ، تم تقديم نظام كمبيوتر للعبة في الخمسينيات. ثم ، في الستينيات من القرن الماضي ، تم إنشاء برنامج
Mac Hack IV ، والذي بدأ في التغلب على منافسيه من البشر. مع مرور الوقت ، تحسنت برامج الشطرنج تدريجياً ، وفي عام 1997 ، طورت شركة IBM "الشطرنج للكمبيوتر" Deep Blue ، والذي تمكن من الفوز على Grandmaster و World Champion Garry Kasparov.
كما يشير هو نفسه ، في الوقت الحاضر ، تلعب العديد من التطبيقات على الهاتف الذكي لعبة الشطرنج أفضل من ديب بلو. بعد تحقيق الكمال في إنشاء أنظمة يمكنها لعب الشطرنج ، بدأ المطورون في إنشاء إصدارات جديدة من منافسي الكمبيوتر البشري - على وجه الخصوص ، تمكنوا من تعليم الكمبيوتر للعب. في السابق ، كانت هذه اللعبة ذات التاريخ الألفي تعتبر واحدة من أكثر الألعاب التي يتعذر الوصول إليها على "فهم" الكمبيوتر. لكن الأوقات تغيرت. كما ذكرنا أعلاه ، حقق AlphaGo مستوى عاليًا من إتقان لعبة الانتقال إلى درجة أن الشخص لم يقف في مكان قريب.
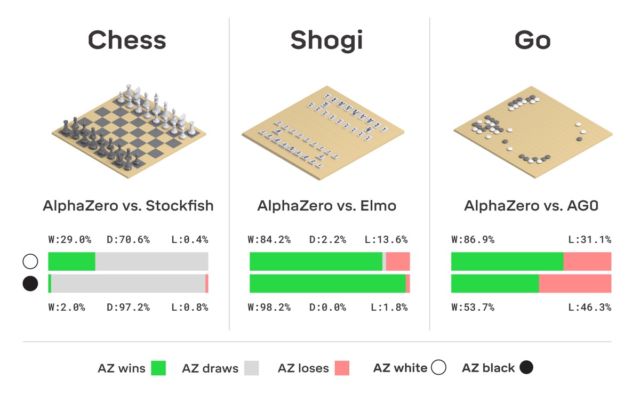
بالمناسبة ، تلقى AlphaGo هذا العام تحديثًا ، بفضل الشبكة العصبية التي يمكنها الآن تعلم الاستراتيجيات المختلفة للعب دون تدخل بشري. اللعب مع نفسه مرارًا وتكرارًا ، يتحسن AlphaGo. هذا النوع من نظام التدريب الذي يستخدمه "السليل" من AlphaGo - الشبكة العصبية AlphaZero. في ثلاثة أيام فقط ، حصلت على مستوى من التمكن في Go ، حيث فازت على الإصدار الأصلي من AlphaGo بنتيجة 100 إلى 0. الشيء الوحيد الذي يحصل عليه النظام في البداية هو قواعد اللعبة.
لا يوجد أي خيال هنا ، يستخدم DeepMind نظام تعلم آلة التعزيز المعروفة. يسعى الكمبيوتر للفوز ، لأن كل فوز يحصل على مكافأة (نقاط). علاوة على ذلك ، تفقد AlphaZero ملايين المجموعات في عملية التعلم. لا تنفق AlphaZero سوى 0.4 ثانية لإساءة تقدير الخطوة التالية وتقييم احتمال الفوز. بالنسبة إلى AlphaGo من الإصدار الأصلي ، فإن الشبكة العصبية تتألف من عنصرين ، شبكتين عصبيتين - أحدهما يحدد الخطوة المحتملة التالية ، والثاني يحسب الاحتمالات.
لتحقيق المستوى الرئيسي في Go AlphaZero ، تحتاج إلى "التمرير" حوالي 4.5 مليون لعبة عند اللعب مع نفسك. لكن AlphaGo تطلب 30 مليون لعبة.
تجدر الإشارة إلى أنه تم إنشاء AlphaZero خصيصًا للعب go. الشركة لم تنس هذا. لكن إلى جانب ذلك ، فإن النظام قادر على التعلم ومباراتان أخريان ، تم ذكرهما أعلاه. النظام المستخدم هو نفسه - تعلم الآلة مع التعزيز. تجدر الإشارة إلى أن AlphaZero يعمل فقط مع المهام التي لها عدد معين من الحلول. يحتاج النظام أيضًا إلى نموذج بيئة (افتراضي).
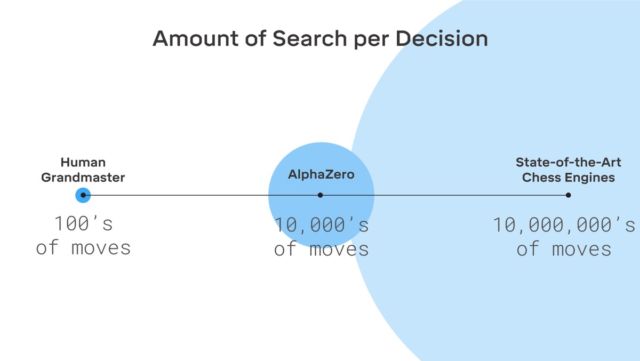
ومن المثير للاهتمام ، أن Kasparov نفسه يعتقد أنه يمكن للشخص الحصول على الكثير من أنظمة مثل AlphaGo - يمكنك أن تتعلم الكثير منها.
يواجه المطورون حاليًا مهمة تعليم الكمبيوتر للعب البوكر بشكل أفضل من أي شخص آخر ، وأيضًا إنشاء نظام يمكنه التغلب على أي لاعب رياضي في معركة عادلة. في أي حال ، من الواضح أن الشبكات العصبية ومنظمة العفو الدولية قادرة على الكثير.