
في ديسمبر الماضي ، كانت هناك
موجة من الأخبار حول القوة المذهلة لمحرك جديد للشطرنج باستخدام شركة AlphaMero للذكاء الاصطناعي DeepMind. اليوم أصدروا نتائج مذهلة لإصدار محدث من هذا المحرك.
لا تترك النتائج مرة أخرى أي شك في أن AlphaZero هو أحد أقوى محركات الشطرنج في العالم.
هزم AlphaZero المحدث Stockfish 8 في مباراة جديدة مع 1000 لعبة والنتيجة: 155 فوزًا و 6 خسائر و 839 تعادلات.
تفوقت AlphaZero أيضًا على Stockfish في سلسلة من الألعاب مع تحكم غير متكافئ في الوقت ، متغلبًا على المحرك التقليدي حتى مع وجود عائق قدره 10 مرات.
وفقًا لـ DeepMind ، في مباريات إضافية ، تجاوز AlphaZero الجديد "أحدث نسخة تطويرية" لـ Stockfish في 13 يناير 2018 ، مما أظهر نتائج مماثلة تقريبًا ، كما في المباراة ضد Stockfish 8.
وفقًا لـ DeepMind ، فاز محرك التعلم الآلي أيضًا بجميع المباريات ضد "Stockfish variant" ، والذي يستخدم كتابًا قويًا لاول مرة. " يبدو أن إضافة كتاب لاول مرة يساعد Stockfish ، الذي فاز أخيرًا بعدد كبير من الألعاب عندما لعب AlphaZero باللون الأسود ، لكن ليس بما يكفي للفوز بالمباراة.
تم نشر النتائج
في مقال في مجلة Science وتم توفيرها من قبل
وسائط شطرنج مختارة.
عقدت مباراة 1000 مباراة في أوائل عام 2018. في المباراة ، حصل كل من AlphaZero و Stockfish على ثلاث ساعات من كل لعبة بالإضافة إلى 15 ثانية لكل دورة. من المحتمل أن يجعل التحكم في الوقت القديم إحدى أكبر الحجج ضد نتائج مباراة العام الماضي ، أي أنه في عام 2017 ، كان التحكم في الوقت لمدة دقيقة واحدة ميزة قوية لـ AlphaZero.
مع زيادة ثلاث ساعات بالإضافة إلى 15 ثانية ، فإن مثل هذه الحجة غير منطقية ، حيث إنها فترة لعب كبيرة لأي محرك شطرنج. في الألعاب ذات الأوقات غير المتكافئة ، سيطر AlphaZero حتى مع نسبة وقت 10 إلى 1. بدأت شركة Stockfish في الفوز بنسبة 30 إلى 1 فقط.
تُظهر نتائج AlphaZero في الألعاب ذات الوقت غير المتكافئ أنها ليست أقوى بكثير من أي محرك شطرنج تقليدي فحسب ، بل تستخدم أيضًا بحثًا أكثر فاعلية في التنقل. وفقًا لـ DeepMind ، يستخدم AlphaZero البحث عن شجرة Monte Carlo ويستكشف حوالي 60،000 موقع في الثانية ، مقارنة بـ 60 مليونًا لـ Stockfish.
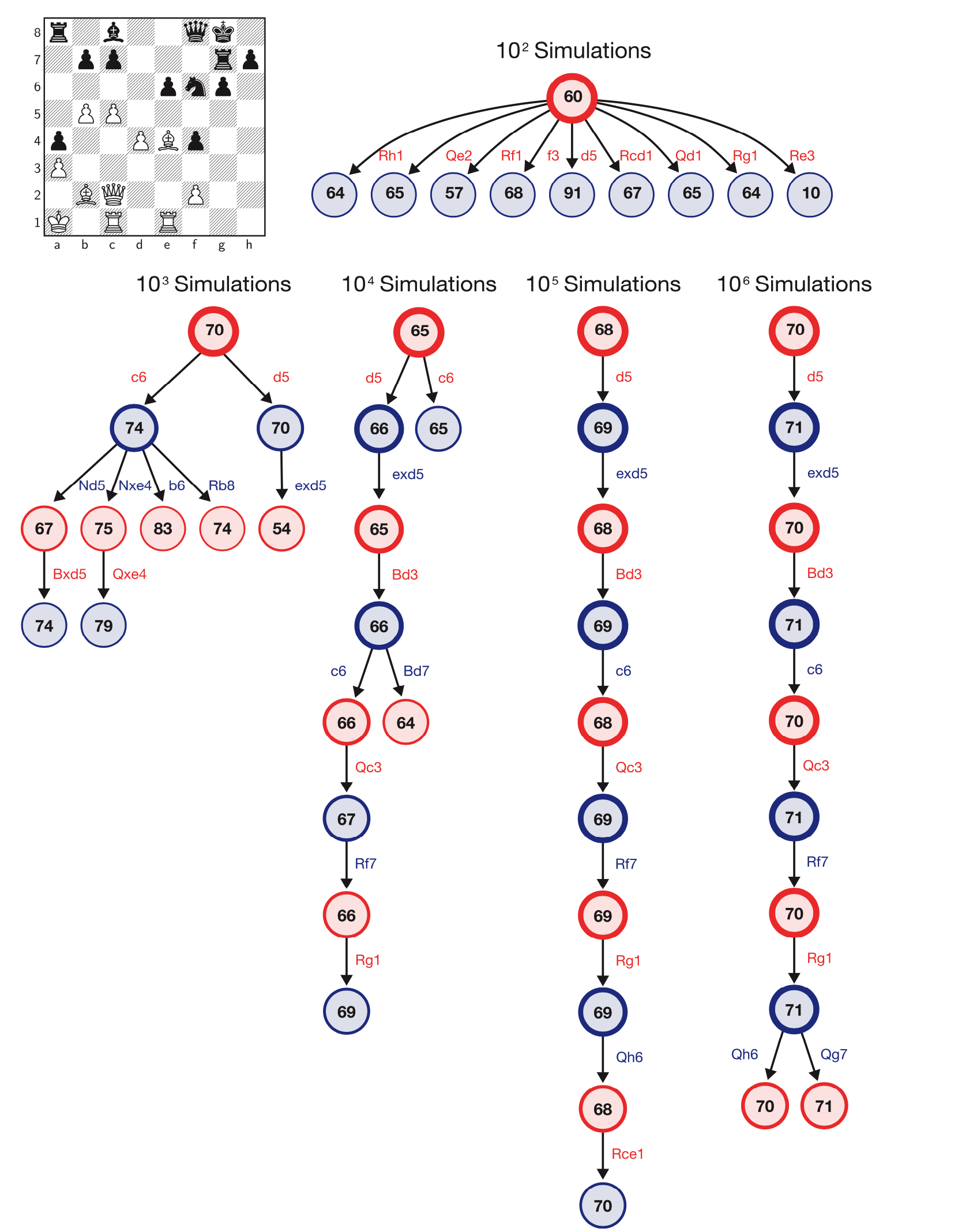 AlphaZero يتحرك خوارزمية البحث التوضيح. صورة DeepMind من مقال في العلوم.
AlphaZero يتحرك خوارزمية البحث التوضيح. صورة DeepMind من مقال في العلوم.وفقًا لهذه المقالة ، فإن خوارزمية AlphaZero المحدّثة متطابقة في ثلاث ألعاب معقدة: لعبة الشطرنج ، shogi ، اذهب. تمكن هذا الإصدار من AlphaZero من التغلب على أفضل محركات الكمبيوتر في جميع الألعاب الثلاث بعد ساعات من التدريب الذاتي ، بدءًا من قواعد اللعبة البسيطة.
أصدر DeepMind 210 لعبة من المباراة ، والتي يمكنك تنزيلها
هنا .
قام الإصدار الجديد من AlphaZero بتدريب نفسه على لعب الشطرنج ، بدءًا من قواعد اللعبة ، باستخدام أساليب التعلم الآلي لتحديث شبكاتها العصبية باستمرار. وفقًا لـ DeepMind ، تم استخدام 5000 TPUs (معالج غوغل tensor ، دائرة متكاملة متخصصة لـ AI) لإنشاء أول مجموعة من الألعاب للعب المستقل ، ثم تم استخدام 16 TPUs لتدريب الشبكات العصبية.
استغرق وقت التدريب الكلي في لعبة الشطرنج تسع ساعات من الصفر. وفقًا لـ DeepMind ، تطلب AlphaZero الجديد أربع ساعات فقط من التدريب لتجاوز Stockfish ؛ في تسع ساعات ، كان يتقدم بفارق كبير عن بطل العالم في الشطرنج.
للألعاب نفسها ، استخدم Stockfish 44 معالجات ، بينما استخدم AlphaZero جهازًا واحدًا مزودًا بأربعة TPU و 44 وحدة معالجة.
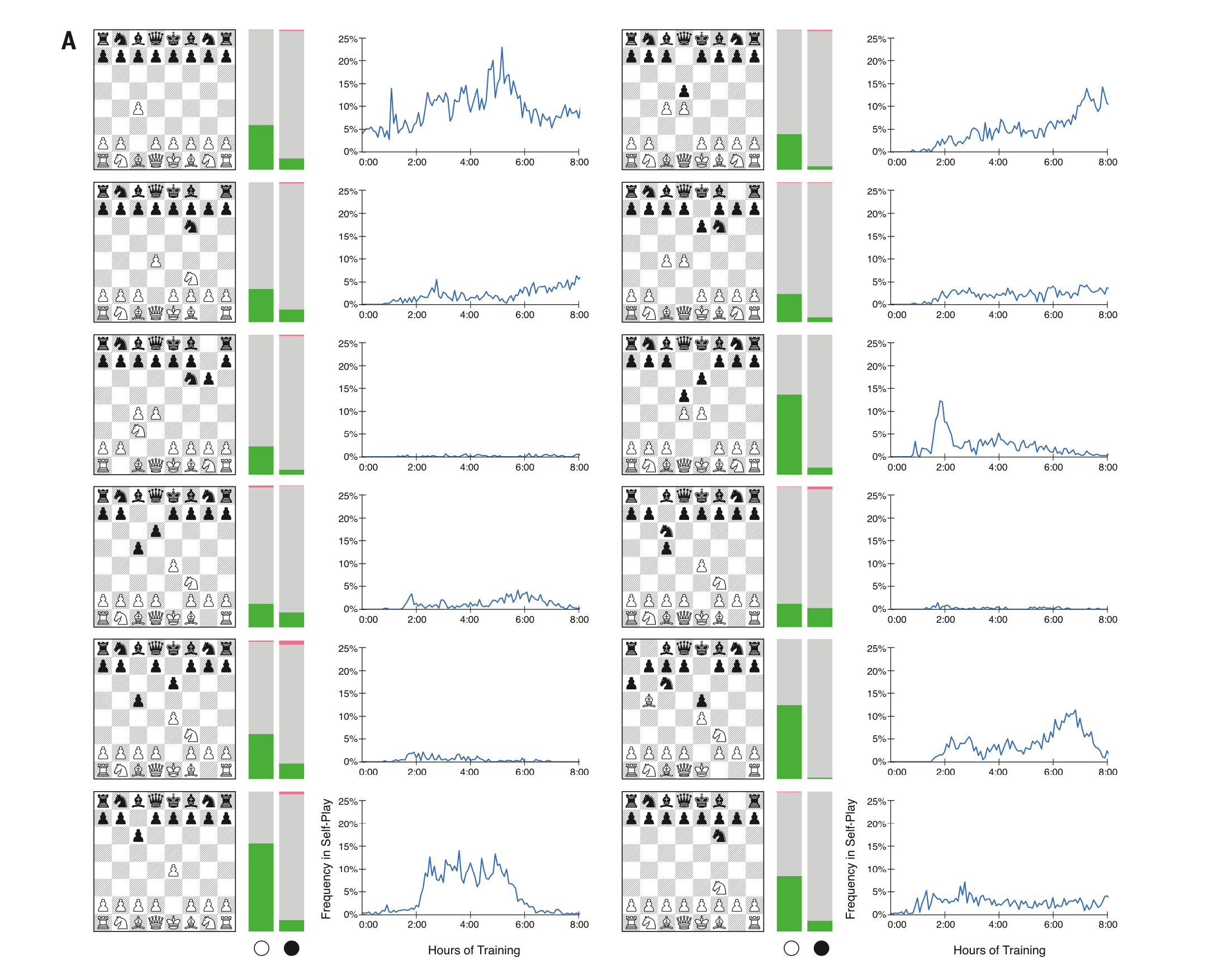 AlphaZero مقابل Stockfish ينتج عنه ظهوره الأكثر شعبية. على اليسار ، يلعب AlphaZero الأبيض ؛ على اليمين - أسود.
AlphaZero مقابل Stockfish ينتج عنه ظهوره الأكثر شعبية. على اليسار ، يلعب AlphaZero الأبيض ؛ على اليمين - أسود.لاحظ DeepMind أنفسهم أسلوب اللعب الفريد لبرنامجهم في المقالة:
وقال باحثو DeepMind: "في العديد من الألعاب ، ضحى AlphaZero بالقطع من أجل ميزة استراتيجية طويلة الأجل ، مما يشير إلى أن لديه تصنيفًا موضعيًا للسياق أكثر من التصنيفات القائمة على القواعد المستخدمة في برامج الشطرنج السابقة".
أكدت منظمة العفو الدولية أيضًا على أهمية استخدام الإصدار نفسه من AlphaZero في ثلاث ألعاب مختلفة ، ووصفها بأنها تقدم كبير في الذكاء الإجمالي للعبة:
وقال الباحثون في DeepMind: "هذه النتائج تقربنا من تحقيق طموحات الذكاء الاصطناعي الطويلة الأمد: نظام ألعاب مشترك يمكن أن يتعلم إتقان أي لعبة".