هل طُلب منك يومًا حساب مقدار شيء ما استنادًا إلى البيانات الموجودة في قاعدة البيانات الخاصة بالشهر الماضي ، وتجميع النتيجة حسب بعض القيم وتقسيمها كل يوم / ساعة؟
إذا كانت الإجابة بنعم - فأنت تتخيل بالفعل أنه يتعين عليك كتابة شيء مثل هذا ، بل الأسوأ من ذلك
SELECT hour(datetime), somename, count(*), sum(somemetric) from table where datetime > :monthAgo group by 1, 2 order by 1 desc, 2
من وقت لآخر ، تبدأ مجموعة كبيرة ومتنوعة من هذه الطلبات في الظهور ، وإذا كنت تحملت المساعدة مرة واحدة ، للأسف ، ستأتي الطعون في المستقبل.
ولكن مثل هذه الطلبات سيئة من حيث أنها تستهلك موارد النظام بشكل جيد في وقت التشغيل ، ويمكن أن يكون هناك الكثير من البيانات حتى أن نسخة متماثلة لهذه الطلبات ستكون مؤلمة (ووقتها).
ولكن ماذا لو قلت أنه مباشرة في PostgreSQL ، يمكنك إنشاء طريقة عرض مفادها أنه في الحال ستنظر فقط في البيانات الواردة الجديدة في استعلام مماثل مباشرةً ، كما هو مذكور أعلاه؟
لذلك - يمكن أن تفعل تمديد PipelineDB
كان PipelineDB في السابق مشروعًا منفصلاً ، ولكنه متوفر الآن كملحق لـ PG 10.1 والإصدارات الأحدث.
على الرغم من أن الفرص المتاحة كانت موجودة منذ زمن طويل في منتجات أخرى مصممة خصيصًا لجمع مقاييس الوقت الفعلي ، إلا أن PipelineDB لها ميزة مهمة: حد دخول أدنى للمطورين الذين يعرفون SQL بالفعل.
ربما بالنسبة للبعض ليس من الضروري. أنا شخصياً لست كسولًا جدًا لأن أجرب كل ما يبدو مناسبًا لحل مشكلة معينة ، لكنني لن أتحرك فورًا لاستخدام حل جديد لجميع الحالات. لذلك ، في هذه المقالة لا أحث على إسقاط كل شيء وتثبيت PipelineDB على الفور ، هذه مجرد نظرة عامة على الوظيفة الرئيسية ، كما بدا الشيء فضولي بالنسبة لي.
وهكذا ، بشكل عام ، لديهم وثائق جيدة ، لكنني أرغب في مشاركة تجربتي حول كيفية تجربة هذا العمل في الممارسة وتقديم النتائج إلى Grafana.
حتى لا تتناثر في الجهاز المحلي ، أقوم بنشر كل شيء في الجهاز.
الصور المستخدمة:
postgres:latest ،
grafana/grafanaتثبيت PipelineDB على بوستجرس
على جهاز مع postgres ، نفذ بالتتابع:
apt updateapt install curlcurl -s http://download.pipelinedb.com/apt.sh | bashapt install pipelinedb-postgresql-11cd /var/lib/postgresql/data- افتح ملف
postgresql.conf في أي محرر - ابحث عن مفتاح
shared_preload_libraries ، وقم بإلغاء الضبط وقم بتعيين قيمة pipelinedb - تعيين
max_worker_processes المفتاح إلى 128 (أرصفة التوصية) - إعادة تشغيل الخادم
إنشاء دفق وعرض في PipelineDB
بعد إعادة تشغيل pg - مشاهدة السجلات بحيث يكون هناك شيء من هذا القبيل - قاعدة البيانات التي سنعمل فيها:
CREATE DATABASE testpipe; - إنشاء ملحق:
CREATE EXTENSION pipelinedb; - الآن الشيء الأكثر إثارة للاهتمام هو إنشاء تيار. تحتاج فيه إلى إضافة بيانات للمعالجة الإضافية:
CREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
في الواقع ، إنه يشبه إلى حد بعيد إنشاء جدول عادي ، لا يمكنك فقط الحصول على البيانات من هذا الدفق مع select بسيط - تحتاج إلى عرض - في الواقع كيفية إنشائه:
CREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
يطلق عليها " المشاهدات المستمرة" وتعثرت في الواقع ، أي مع الحفاظ على الدولة.
WITH بتمرير معلمات إضافية.
في حالتي ، يعني ttl = '3 month' أنك تحتاج إلى تخزين البيانات فقط لمدة 3 أشهر الماضية ، وأن تأخذ التاريخ / الوقت من العمود M reaper عملية reaper الخلفية عن البيانات القديمة وتحذفها.
بالنسبة لأولئك الذين ليسوا في معرفة ، ترجع الدالة minute تاريخ / وقت دون ثوانٍ. وبالتالي ، فإن جميع الأحداث التي وقعت في دقيقة واحدة سيكون لها نفس الوقت كنتيجة للتجميع. - مثل هذا العرض هو جدول تقريبًا ، لأن الفهرس حسب تاريخ أخذ العينات سيكون مفيدًا في حالة تخزين الكثير من البيانات
create index on viewflow (m desc, action);
باستخدام PipelineDB
تذكر: إدراج البيانات في الدفق ، وقراءة من العرض الاشتراك فيه
insert into flow_stream VALUES (now(), 'act1', 21); insert into flow_stream VALUES (now(), 'act2', 33); select * from viewflow order by m desc, action limit 4; select now()
أولاً ، أشاهد كيف تتغير البيانات في الدقيقة 46
بمجرد أن يأتي 47 ، توقف السابقة السابقة التحديث وتبدأ الدقيقة الحالية تدق.
إذا كنت تهتم بخطة الاستعلام ، يمكنك رؤية الجدول الأصلي مع البيانات
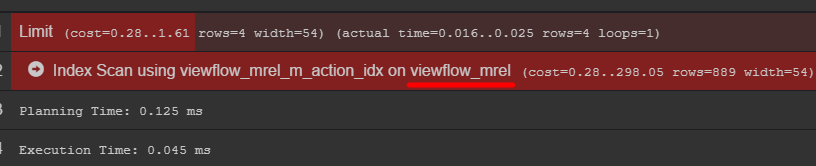
أوصي بالذهاب إليه ومعرفة كيفية تخزين بياناتك بالفعل
مولد الحدث C # using Npgsql; using System; using System.Threading; namespace PipelineDbLogGenerator { class Program { private static Random _rnd = new Random(); private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" }; static void Main(string[] args) { var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe"; using (var conn = new NpgsqlConnection(connString)) { conn.Open(); while (true) { var dt = DateTime.UtcNow; using (var cmd = new NpgsqlCommand()) { var act = GetAction(); cmd.Connection = conn; cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)"; cmd.Parameters.AddWithValue("dtmsk", dt); cmd.Parameters.AddWithValue("action", act); cmd.Parameters.AddWithValue("duration", GetDuration(act)); var res = cmd.ExecuteNonQuery(); Console.WriteLine($"{res} {dt}"); } Thread.Sleep(_rnd.Next(50, 230)); } } } private static int GetDuration(string act) { var c = 0; for (int i = 0; i < act.Length; i++) { c += act[i]; } return _rnd.Next(c); } private static string GetAction() { return _actions[_rnd.Next(_actions.Length)]; } } }
الاستنتاج في غرافانا
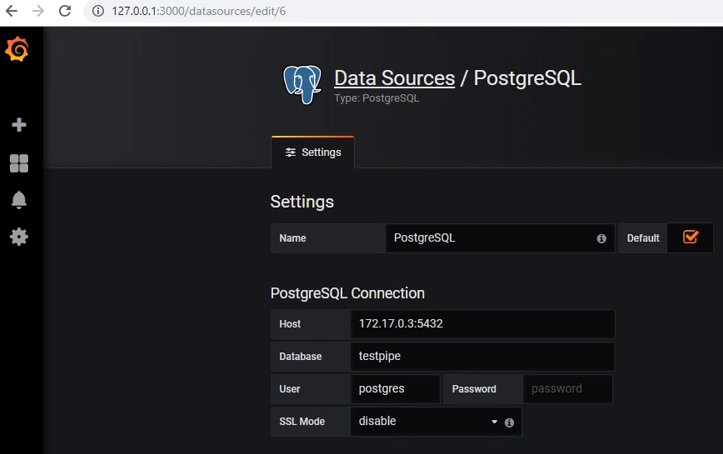
للحصول على البيانات من postgres ، تحتاج إلى إضافة مصدر البيانات المناسب:
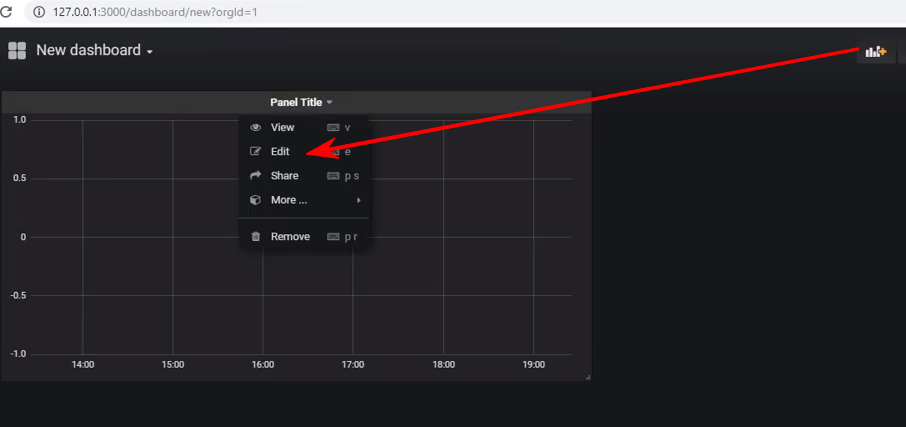
قم بإنشاء لوحة معلومات جديدة وإضافة لوحة من النوع Graph إليها ، وبعد ذلك تحتاج إلى الدخول في تحرير اللوحة:
التالي - حدد مصدر بيانات ، وانتقل إلى وضع كتابة sql- الاستعلام وأدخل هذا:
select m as time,
ثم تحصل على جدول زمني طبيعي ، بطبيعة الحال ، إذا كنت قد بدأت مولد الحدث
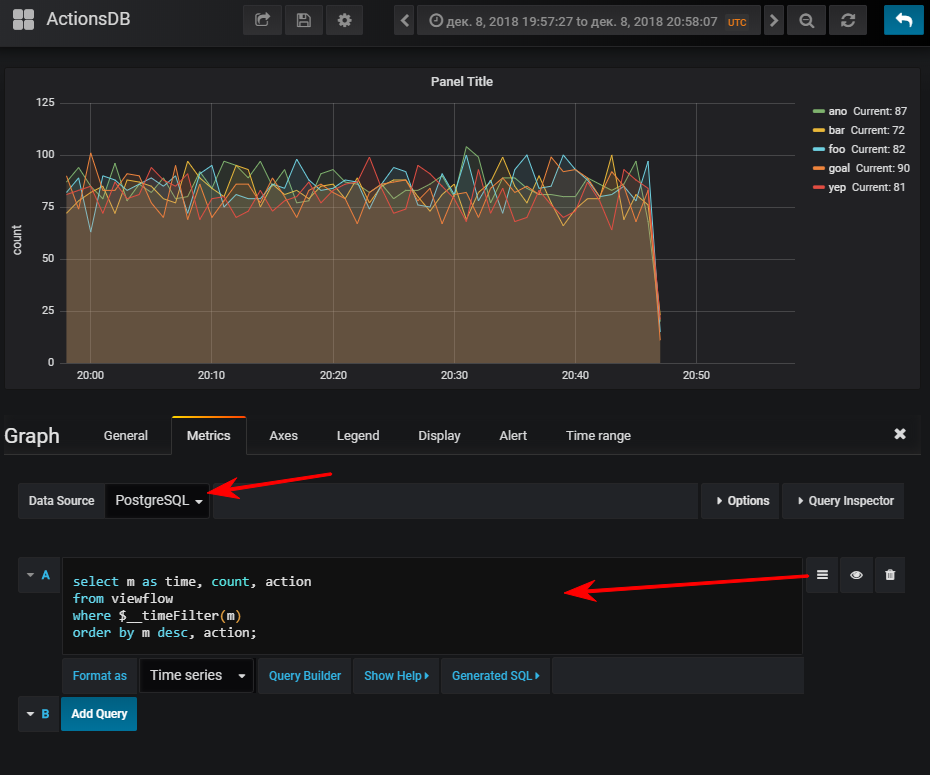
لمعلوماتك: وجود مؤشر يمكن أن يكون مهمًا جدًا. على الرغم من أن استخدامه يعتمد على حجم الجدول الناتج. إذا كنت تخطط لتخزين عدد صغير من الصفوف في فترة صغيرة من الوقت ، فيمكن أن يتحول بسهولة إلى أن فحص seq سيكون أرخص ، وسيضيف الفهرس إضافيًا فقط. تحميل عند تحديث القيم
يمكن الاشتراك وجهات نظر متعددة في تيار واحد.
افترض أنني أريد أن أرى عدد طرق api التي يتم تنفيذها بواسطة النسب المئوية
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS select minute(dtmsk) m, action, percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50, percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95, percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99 from flow_stream group by 1, 2; create index on viewflow_per (m desc);
أفعل نفس الخدعة مع grafana وأحصل على: المجموع
بشكل عام ، الشيء يعمل ، لقد تصرف بشكل جيد ، دون شكاوى. على الرغم من أنه تحت عامل النقل ، فقد تبين أن تنزيل قاعدة بيانات العرض التوضيحي في الأرشيف (2.3 جيجابايت) طويل جدًا.
أريد أن أشير - لم أقم بإجراء اختبارات الإجهاد.
الوثائق الرسميةقد يكون مثيرا للاهتمام