
استمرارًا لمقالاتنا العملية حول كيفية جعل الحياة أسهل في العمل اليومي مع Kubernetes ، نتحدث عن قصتين من عالم التشغيل: تخصيص العقد الفردية لمهام محددة وتكوين php-fpm (أو خادم تطبيقات آخر) للأحمال الثقيلة. كما في السابق ، لا تدعي الحلول الموضحة هنا أنها مثالية ، ولكنها تقدم كنقطة انطلاق لحالاتك المحددة وأساس للتفكير. الأسئلة والتحسينات في التعليقات هي موضع ترحيب!
1. تخصيص العقد الفردية لمهام محددة
نحن نرفع مجموعة Kubernetes على خوادم افتراضية أو سحب أو خوادم معدنية عارية. إذا قمت بتثبيت جميع برامج النظام وتطبيقات العميل على نفس العقد ، فمن المحتمل أن تواجه مشكلات:
- سيبدأ تطبيق العميل "بالتسرب" فجأة من الذاكرة ، على الرغم من أن حدوده مرتفعة للغاية ؛
- الطلبات المعقدة لمرة واحدة إلى loghouse أو Prometheus أو Ingress * تؤدي إلى OOM ، نتيجة لذلك يعاني تطبيق العميل ؛
- تسرب للذاكرة بسبب وجود خلل في برنامج النظام يقتل تطبيق العميل ، على الرغم من أن المكونات قد لا تكون متصلة منطقيا مع بعضها البعض.
* من بين أشياء أخرى ، كانت ذات صلة بالإصدارات الأقدم من Ingress ، عندما ظهرت عدد "عمليات تعليق nginx" نظرًا للعدد الكبير من اتصالات websocket وعمليات إعادة التحميل المستمرة لـ nginx ، والتي بلغت الآلاف واستهلكت كم هائل من الموارد.الحالة الحقيقية هي مع تثبيت Prometheus مع عدد كبير من المقاييس ، حيث عند عرض لوحة القيادة "الثقيلة" ، حيث يتم تقديم عدد كبير من حاويات التطبيقات ، من كل منها يتم رسم الرسوم البيانية ، ارتفع استهلاك الذاكرة بسرعة إلى ~ 15 غيغابايت. نتيجةً لذلك ، يمكن لـ "قاتل OOM" أن "يأتي" على النظام المضيف ويبدأ في قتل الخدمات الأخرى ، مما أدى بدوره إلى "سلوك غير مفهوم للتطبيقات في المجموعة". وبسبب تحميل وحدة المعالجة المركزية عالية على تطبيق العميل ، فمن السهل الحصول على وقت معالجة استعلام Ingress غير مستقر ...
الحل سرعان ما دفع نفسه: كان من الضروري تخصيص أجهزة فردية للمهام المختلفة. لقد حددنا 3 أنواع رئيسية من مجموعات المهام:
- الجبهات ، حيث نضع Ingresss فقط ، للتأكد من عدم وجود خدمات أخرى يمكن أن تؤثر على وقت معالجة الطلبات ؛
- عقد النظام التي ننشر عليها شبكات VPN ، loghouse ، Prometheus ، Dashboard ، CoreDNS ، إلخ ؛
- عقد للتطبيقات - في الواقع ، حيث يتم طرح تطبيقات العميل. يمكن أيضًا تخصيصها للبيئات أو الوظائف: dev، prod، perf، ...
الحل
كيف ننفذ هذا؟ في غاية البساطة: اثنين من آليات Kubernetes الأصلي. الأول هو
nodeSelector لتحديد العقدة المطلوبة حيث يجب أن يذهب التطبيق ، والذي يعتمد على التسميات
المثبتة على كل عقدة.
قل لدينا عقدة
kube-system-1 . نضيف ملصقًا إضافيًا إليها:
$ kubectl label node kube-system-1 node-role/monitoring=
... وفي
Deployment ، الذي يجب طرحه على هذه العقدة ، نكتب:
nodeSelector: node-role/monitoring: ""
الآلية الثانية هي
الدهانات والتسامح . من خلال مساعدتها ، نشير صراحة إلى أنه لا يمكن إطلاق سوى الحاويات التي لها تأثير على هذه الصورة على هذه الأجهزة.
على سبيل المثال ، هناك آلة
kube-frontend-1 لن نقوم فقط بتدوير Ingress. إضافة ملوث إلى هذه العقدة:
$ kubectl taint node kube-frontend-1 node-role/frontend="":NoExecute
... وفي
Deployment نقوم بإنشاء التسامح:
tolerations: - effect: NoExecute key: node-role/frontend
في حالة kops ، يمكن إنشاء مجموعات مثيل فردية لنفس الاحتياجات:
$ kops create ig --name cluster_name IG_NAME
... وتحصل على شيء مثل تهيئة مجموعة المثيلات هذه في kops:
apiVersion: kops/v1alpha2 kind: InstanceGroup metadata: creationTimestamp: 2017-12-07T09:24:49Z labels: dedicated: monitoring kops.k8s.io/cluster: k-dev.k8s name: monitoring spec: image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14 machineType: m4.4xlarge maxSize: 2 minSize: 2 nodeLabels: dedicated: monitoring role: Node subnets: - eu-central-1c taints: - dedicated=monitoring:NoSchedule
وبالتالي ، ستضيف العقد من مجموعة المثيلات هذه تلقائيًا تصنيفًا وتلوينًا إضافيين.
2. تكوين php-fpm للأحمال الثقيلة
هناك مجموعة واسعة من الخوادم المستخدمة لتشغيل تطبيقات الويب: php-fpm ، gunicorn وما شابه ذلك. يعني استخدامها في Kubernetes أن هناك العديد من الأشياء التي يجب أن تفكر بها دائمًا:
- من الضروري أن نفهم تقريبًا عدد العمال الذين نرغب في تخصيصهم في php-fpm في كل حاوية. على سبيل المثال ، يمكننا تخصيص 10 عمال لمعالجة الطلبات الواردة ، وتخصيص موارد أقل للقرص وحجم باستخدام عدد من القرون - وهذه ممارسة جيدة. مثال آخر هو تخصيص 500 عامل لكل جراب ولديهم 2-3 قرون في الإنتاج ... ولكن هذه فكرة سيئة للغاية.
- يلزم إجراء اختبارات للقدرة / الاستعداد للتحقق من التشغيل الصحيح لكل جراب وفي حالة "توقف" البود بسبب مشاكل في الشبكة أو بسبب الوصول إلى قاعدة البيانات (قد يكون هناك أي من خياراتك وسببك). في مثل هذه الحالات ، تحتاج إلى إعادة إنشاء جراب مشكلة.
- من المهم تسجيل الطلب بشكل صريح والحد من الموارد لكل حاوية حتى لا "يتدفق" التطبيق ولا يبدأ في إلحاق الضرر بجميع الخدمات على هذا الخادم.
حلول
لسوء الحظ ،
لا توجد رصاصة فضية تساعدك على فهم عدد الموارد (CPU ، RAM) التي قد يحتاجها التطبيق على الفور. يتمثل الخيار المحتمل في مراقبة استهلاك الموارد وتحديد القيم المثلى في كل مرة. لتجنب قتل OOM غير المبرر وخنق وحدة المعالجة المركزية ، مما يؤثر بشكل كبير على الخدمة ، يمكنك تقديم:
- أضف اختبارات الصلابة / الاستعداد الصحيحة حتى يمكننا أن نقول على وجه اليقين أن هذه الحاوية تعمل بشكل صحيح. على الأرجح ، ستكون صفحة خدمة تتحقق من توفر جميع عناصر البنية التحتية (اللازمة لتشغيل التطبيق في الحافظة) وتُرجع رمز استجابة 200 موافق ؛
- حدد عدد العمال الذين سيقومون بمعالجة الطلبات بشكل صحيح ، ثم قم بتوزيعها بشكل صحيح.
على سبيل المثال ، لدينا 10 قرون تتكون من حاويتين: nginx (لإرسال الإحصائيات وطلبات الوكيل إلى الواجهة الخلفية) و php-fpm (في الواقع الواجهة الخلفية ، التي تعالج الصفحات الديناميكية). تم تكوين تجمع php-fpm لعدد ثابت من العمال (10). وبالتالي ، في وحدة زمنية ، يمكننا معالجة 100 طلب نشط للواجهات الخلفية. دع كل طلب تتم معالجته بواسطة PHP خلال ثانية واحدة.
ماذا يحدث إذا وصل طلب آخر إلى جراب واحد محدد ، حيث تتم الآن معالجة 10 طلبات بشكل نشط الآن؟ لن يتمكن PHP من معالجته وسيقوم Ingress بإرساله لإعادة المحاولة إلى pod التالي إذا كان طلب GET. إذا كان هناك طلب POST ، فسيتم إرجاع خطأ.
وإذا أخذنا في الاعتبار أنه أثناء معالجة جميع الطلبات العشرة ، سوف نتلقى شيكًا من kubelet (مسبار الثبات) ، سينتهي هذا الخطأ وسيبدأ Kubernetes في الاعتقاد بأن هناك خطأ ما في هذه الحاوية ونقتلها. في هذه الحالة ، ستنتهي جميع الطلبات التي تمت معالجتها في الوقت الحالي بخطأ (!) وفي وقت إعادة تشغيل الحاوية ، سينتهي رصيدها ، مما يستلزم زيادة في طلبات جميع الإصدارات الخلفية الأخرى.
بوضوح
لنفترض أن لدينا 2 حاضنات تحتوي كل منها على 10 من عمال php-fpm. فيما يلي رسم بياني يعرض المعلومات أثناء "وقت التوقف" ، أي عندما يكون الشخص الوحيد الذي يطلب php-fpm هو مصدر php-fpm (لدينا عامل نشط لكل واحد):
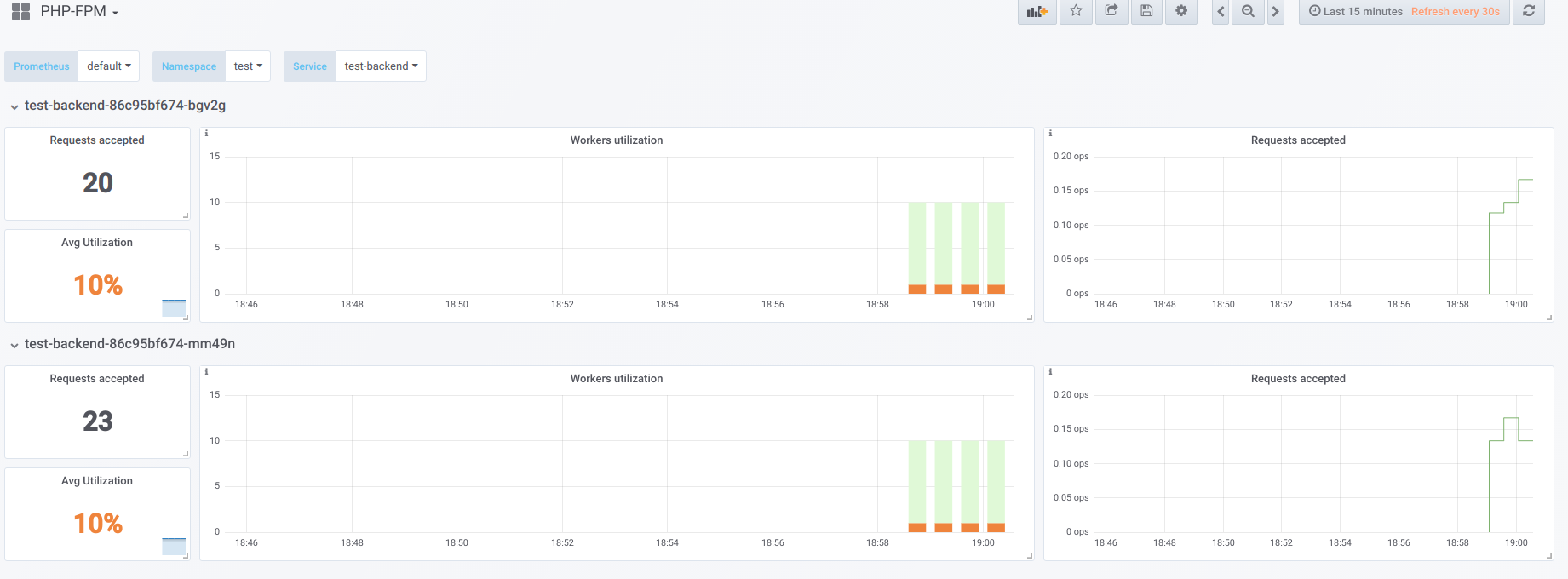
الآن بدء التمهيد مع التزامن 19:
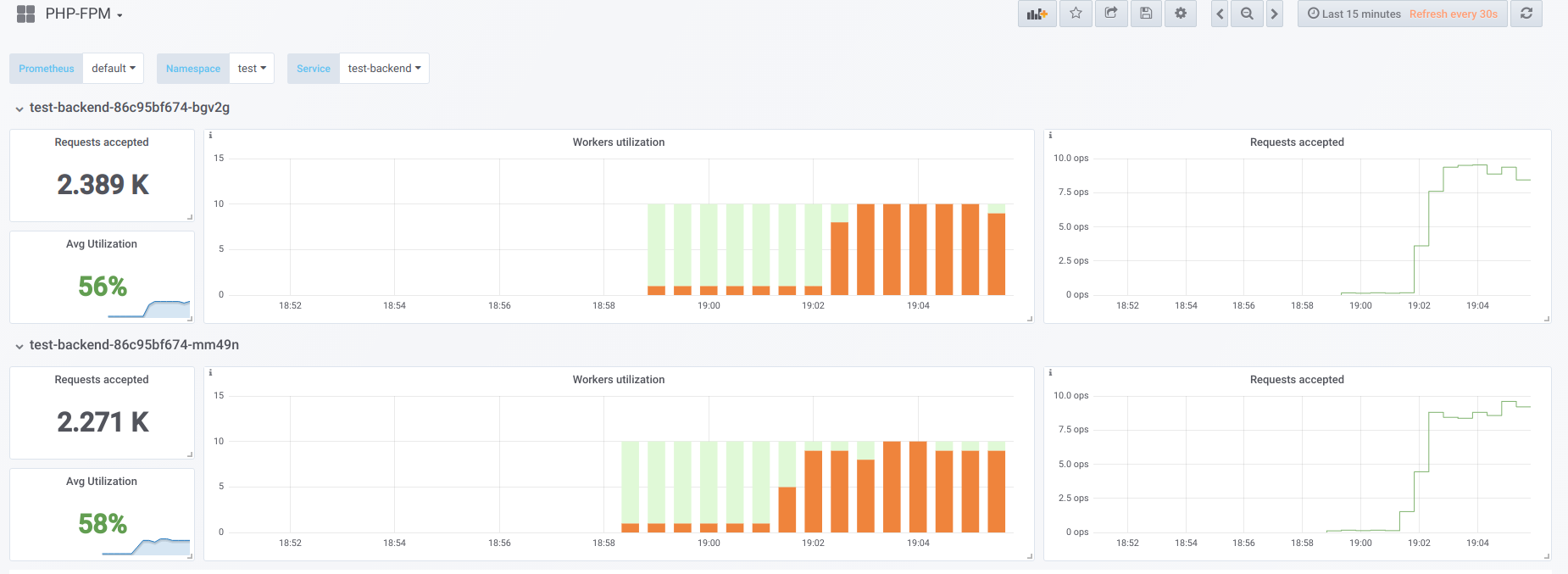
الآن دعونا نحاول جعل التزامن أعلى مما يمكننا التعامل معه (20) ... دعنا نقول 23. ثم جميع مشغلي php-fpm مشغولون بمعالجة طلبات العميل:

لم يعد Vorkers كافيًا لمعالجة عينة حيوية ، لذلك نرى هذه الصورة في لوحة معلومات Kubernetes (أو
describe pod ):

الآن ، عند إعادة تشغيل أحد البرامج ،
يحدث تأثير الانهيار : تبدأ الطلبات في السقوط على الجراب الثاني ، وهو أيضًا غير قادر على معالجتها ، نظرًا لأننا نتلقى عددًا كبيرًا من الأخطاء من العملاء. بعد امتلاء أحواض جميع الحاويات ، يصبح رفع الخدمة مشكلة - وهذا ممكن فقط من خلال الزيادة الحادة في عدد القرون أو العمال.
الخيار الأول
في حاوية بها PHP ، يمكنك تكوين بركتي fpm: واحدة لمعالجة طلبات العميل ، والآخر للتحقق من "قابلية بقاء" الحاوية. ثم في حاوية nginx ، ستحتاج إلى تكوين مماثل:
upstream backend { server 127.0.0.1:9000 max_fails=0; } upstream backend-status { server 127.0.0.1:9001 max_fails=0; }
كل ما تبقى هو إرسال عينة حيوية للمعالجة إلى المنبع تسمى
backend-status .
الآن وبعد إجراء اختبار liveness بشكل منفصل ، ستظل الأخطاء تحدث في بعض العملاء ، ولكن على الأقل لا توجد مشكلات مرتبطة بإعادة تشغيل pod وفصل بقية العملاء. وبالتالي ، سنقوم بتقليل عدد الأخطاء إلى حد كبير ، حتى لو لم تستطع عملياتنا الخلفية مواجهة الحمل الحالي.
من المؤكد أن هذا الخيار أفضل من لا شيء ، لكنه سيئ أيضًا لأنه يمكن أن يحدث شيء في المجموعة الرئيسية ، والتي لم نتعرف على استخدام اختبار الثبات.
الخيار الثاني
يمكنك أيضًا استخدام وحدة nginx غير الشائعة جدًا والتي تسمى
nginx-limit-upstream . ثم في PHP سنحدد 11 عاملاً ، وفي الحاوية مع nginx سنقوم بعمل تهيئة مماثلة:
limit_upstream_zone limit 32m; upstream backend { server 127.0.0.1:9000 max_fails=0; limit_upstream_conn limit=10 zone=limit backlog=10 timeout=5s; } upstream backend-status { server 127.0.0.1:9000 max_fails=0; }
على مستوى الواجهة الأمامية ، سيحدد nginx عدد الطلبات التي سيتم إرسالها إلى الواجهة الخلفية (10). هناك نقطة مهمة تتمثل في إنشاء تراكم خاص: إذا كان الطلب الحادي عشر لـ nginx يأتي من العميل ، ورأى nginx أن تجمع php-fpm مشغول ، فسيتم وضع هذا الطلب في backlog لمدة 5 ثوانٍ. إذا لم يتم تحرير php-fpm ، خلال هذا الوقت ، عندها فقط سيتم تشغيل Ingress ، مما سيؤدي إلى إعادة محاولة الطلب إلى جراب آخر. هذا ينعم الصورة ، حيث سيكون لدينا دائمًا عامل PHP واحد مجاني لمعالجة نموذج الفاعلية - يمكننا تجنب تأثير الانهيار.
أفكار أخرى
للحصول على خيارات أكثر تنوعًا وجمالًا لحل هذه المشكلة ، يجدر البحث في اتجاه
Envoy ونظائرها.
بشكل عام ، من أجل أن يكون لدى Prometheus توظيف واضح للعمال ، مما سيساعد بدوره في إيجاد المشكلة بسرعة (والإبلاغ عنها) ، أوصي بشدة بتزويد
المصدرين الجاهزين لتحويل البيانات من البرنامج إلى تنسيق Prometheus.
PS
بخلاف دورة نصائح وحيل K8s:
اقرأ أيضًا في مدونتنا: