
كل يوم ، يبحث مليون ونصف المليون شخص عن الأوزون بحثًا عن مجموعة متنوعة من المنتجات ، ولكل منهم يجب أن تختار الخدمة منتجات مماثلة (إذا كانت المكنسة الكهربائية لا تزال بحاجة إلى واحدة أكثر قوة) أو تلك ذات الصلة (إذا كانت البطاريات ضرورية لديناصور الغناء). عندما يكون هناك العديد من أنواع المنتجات ، يساعد نموذج Word2Vec على حل المشكلة. نحن نفهم كيف يعمل وكيفية إنشاء تمثيلات متجهة للأشياء التعسفية.
الدافع
لإنشاء النموذج وتدريبه ، نستخدم تقنية التضمين ، المعيار للتعلم الآلي ، عندما يتحول كل كائن إلى متجه ذي طول ثابت ، وتتوافق المتجهات القريبة مع الكائنات القريبة. تتطلب جميع النماذج المعروفة تقريبًا أن تكون بيانات المدخلات ذات طول ثابت ، ومجموعة من المتجهات طريقة سهلة لإحضارها إلى هذا النموذج.
إحدى طرق التضمين الأولى هي word2vec. قمنا بتكييف هذه الطريقة لمهمتنا ، ونحن نستخدم المنتجات ككلمات ، وجلسات المستخدم كجمل. إذا كان كل شيء واضحًا لك ، فلا تتردد في استعراض النتائج.
بعد ذلك سوف أتحدث عن بنية النموذج وكيف يعمل. نظرًا لأننا نتعامل مع البضائع ، نحتاج إلى معرفة كيفية إنشاء مثل هذه الأوصاف منها ، من ناحية ، تحتوي على معلومات كافية ، ومن ناحية أخرى ، يمكن فهمها لخوارزمية التعلم الآلي.
على الموقع ، كل منتج لديه بطاقة. وهو يتألف من العنوان والوصف النصي والمواصفات والصور الفوتوغرافية. يوجد أيضًا تحت تصرفنا بيانات عن تفاعل المستخدمين مع المنتج: يتم تخزين المشاهدات ، إضافة إلى السلة أو المفضلة في السجلات.
هناك طريقتان مختلفتان بشكل أساسي لإنشاء وصف متجه للمنتج:
- استخدام شبكات عصبية تلافيفية للمحتوى لاستخراج ميزات من الصور أو الشبكات المتكررة أو كيس من الكلمات لتحليل وصف نصي ؛
- استخدام البيانات على تفاعلات المستخدم مع المنتج: ما هي المنتجات وعدد مرات ظهورهم / إضافتهم إلى السلة مع البيانات.
سوف نركز على الطريقة الثانية.
بيانات طراز Prod2Vec
أولاً ، دعونا نتعرف على البيانات التي نستخدمها. لدينا تحت تصرفنا جميع نقرات المستخدمين على الموقع ، ويمكن تقسيمهم إلى جلسات مستخدمين - تسلسل نقرات بفواصل زمنية لا تزيد عن 30 دقيقة بين النقرات المجاورة. لتدريب النموذج ، نستخدم البيانات من حوالي 100 مليون جلسة مستخدم ، والتي نرغب فقط في كل منها في عرض المنتجات وإضافتها إلى السلة.
مثال لجلسة مستخدم حقيقية:

يتوافق كل منتج في الجلسة مع السياق الخاص به - جميع المنتجات التي أضافها المستخدم إلى السلة في هذه الجلسة ، وكذلك المنتجات التي يتم عرضها مع هذا. يعتمد نموذج prod2vec على افتراض أن المنتجات المماثلة لها غالبًا سياقات متشابهة.
على سبيل المثال:

وبالتالي ، إذا كان الافتراض صحيحًا ، فعلى سبيل المثال ، سيكون لحالات طراز الهاتف نفسه سياقات مماثلة (نفس الهاتف). سنختبر هذه الفرضية من خلال بناء ناقلات المنتجات.
موديل Prod2Vec
عندما قدمنا مفاهيم المنتج وسياقه ، نصف النموذج نفسه. هذه شبكة عصبية ذات طبقتين متصلتين تمامًا. عدد مدخلات الطبقة الأولى يساوي عدد المنتجات التي نريد بناء متجهات لها. سيتم تشفير كل منتج عند المدخل بواسطة متجه من الأصفار مع وحدة واحدة - مكان هذا المنتج في القاموس.
عدد الخلايا العصبية عند إخراج الطبقة الأولى مساوٍ لبعد المتجهات التي نريد الحصول عليها ، على سبيل المثال 64. عند إخراج الطبقة الأخيرة ، مرة أخرى ، هناك عدد من الخلايا العصبية يساوي عدد البضائع.

سنقوم بتدريب النموذج على التنبؤ بالسياق ، ومعرفة المنتج. تسمى هذه البنية Skip-gram (بديلها هو CBOW ، حيث نتوقع المنتج وفقًا لسياقه). أثناء التدريب ، يتم تسليم البضائع إلى المدخل ، ومن المتوقع أن يتم إخراج البضائع من سياقها (ناقل من الأصفار مع وحدة في المكان المقابل).
في جوهره ، هذا تصنيف متعدد الطبقات ، ويمكن استخدام فقد إنتروبيا لتدريب النموذج. لزوج كلمة واحدة من السياق ، هو مكتوب على النحو التالي:
L=−pc+ log sumVi=1exp(pi)
اين pc - التنبؤ بالشبكة للمنتج من السياق ، V - إجمالي عدد البضائع pi - التنبؤ بالشبكة للمنتج i .
بعد تدريب النموذج ، يمكننا تجاهل الطبقة الثانية - لن تكون هناك حاجة للحصول على ناقلات. مصفوفة أوزان الطبقة الأولى (حجم عدد السلع × 64) هي قاموس لمتجهات البضائع. يتوافق كل منتج مع صف واحد من مصفوفة بطول 64 - هذا هو المتجه المقابل للمنتج ، والذي يمكن استخدامه في خوارزميات أخرى.
لكن هذا الإجراء لا يعمل مع عدد كبير من المنتجات. ولدينا ، أذكر ، مليون ونصف المليون.
لماذا Prod2Vec لا يعمل
- تحتوي وظيفة الخسارة على العديد من عمليات أخذ الأس - وهذه عملية حسابية طويلة وغير مستقرة.
- نتيجة لذلك ، يتم اعتبار التدرجات لجميع أوزان الشبكات - وقد يكون هناك عشرات الملايين.
لحل هذه المشكلات ، تعد طريقة أخذ العينات السالبة مناسبة ، حيث نستخدمها لتعليم الشبكة ليس فقط للتنبؤ بسياق المنتج ، ولكن أيضًا لتعليم عدم التنبؤ بالمنتجات التي ليست في السياق تمامًا. للقيام بذلك ، نحتاج إلى إنشاء أمثلة سلبية - لكل منتج ، حدد تلك التي لا تحتاج إلى التنبؤ به. وهنا توفر كمية هائلة من البضائع يساعدنا. عند اختيار زوج عشوائي لمنتج ما ، لدينا احتمال ضئيل للغاية أن يتحول إلى منتج من السياق.
نتيجة لذلك ، لكل منتج في السياق ، نقوم بإنشاء عشوائي 5-10 المنتجات التي لم يتم تضمينها في السياق. علاوة على ذلك ، لا يتم أخذ عينات من توزيع موحد ، ولكن بما يتناسب مع تكرار حدوثها.
تشبه وظيفة الخسارة الآن تلك المستخدمة في التصنيف الثنائي. بالنسبة لزوج كلمة واحد ، من السياق ، يبدو كما يلي:
L=− log sigma(uTwOvwI)− sumwn log sigma(−uTwnvwI)
في هذه التدوين uwO يشير إلى عمود بمصفوفة الوزن للطبقة الثانية المقابلة للمنتج من السياق ، uwn - نفس الشيء بالنسبة لمنتج تم اختياره عشوائيًا ، vwI - صف مصفوفة الوزن للطبقة الأولى المقابلة للمنتج الرئيسي (هذا هو بالضبط المتجه الذي نصنعه من أجله). وظيفة sigma(x)= frac11+exp(−x) .
الفرق من الإصدار السابق هو أننا لسنا بحاجة إلى تحديث جميع أوزان الشبكات في كل تكرار ، نحن بحاجة فقط إلى تحديث تلك التي تتوافق مع عدد صغير من المنتجات (المنتج الأول هو المنتج الذي نتوقع من أجله ، والباقي إما منتج من سياقه أو تم اختياره عشوائيًا ) في الوقت نفسه ، تخلصنا من عدد كبير من الأسرات الأسية في كل تكرار.
هناك طريقة أخرى ، والتي بدورها تعمل على تحسين جودة النموذج الناتج ، وهي أخذ العينات. في هذه الحالة ، نأخذ عن عمد سلعًا متكررة الاستخدام للتدريب من أجل الحصول على أفضل نتيجة للسلع النادرة.
النتائج
المنتجات ذات الصلة
لذلك ، تعلمنا كيفية الحصول على ناقلات للبضائع ، والآن نحن بحاجة إلى التحقق من كفاية وتطبيق نموذجنا.
توضح الصورة التالية المنتج وأقرب جيرانه في مقياس جيب التمام.
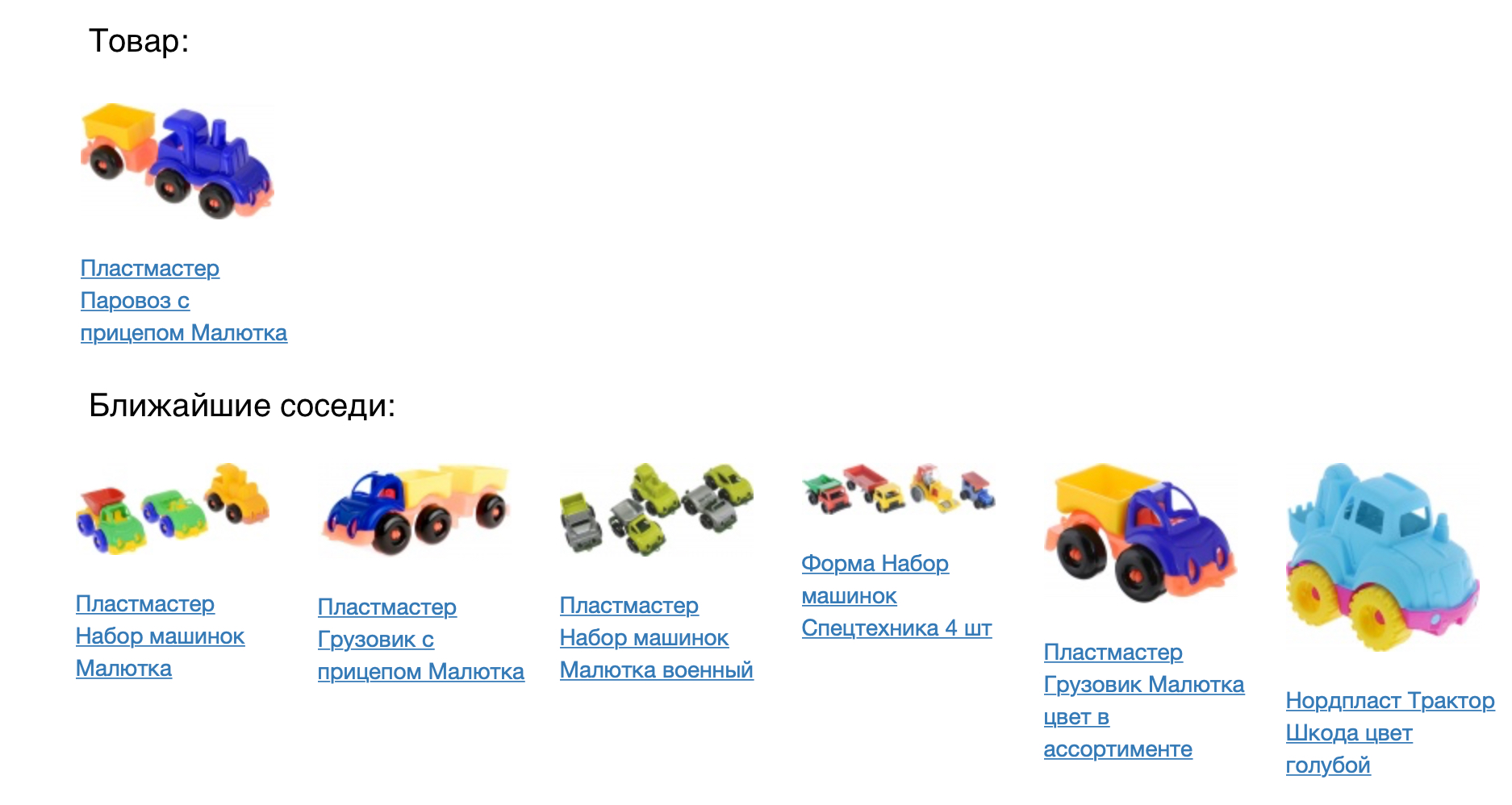
تبدو النتيجة جيدة ، لكنك بحاجة إلى التحقق عدديًا من مدى جودة نموذجنا. للقيام بذلك ، قمنا بتطبيقه على مهمة توصيات المنتج. لكل منتج ، نوصيك بالحصول على مساحة ناقل متجهة. قارنا طراز prod2vec بنموذج أبسط كثيرًا ، استنادًا إلى إحصائيات وجهات النظر المشتركة وإضافة عناصر إلى السلة. لكل منتج في الجلسة ، تم اتخاذ قائمة من 7 توصيات. تمت مقارنة مزيج جميع المنتجات الموصى بها في الجلسة مع ما أضافه الشخص فعليًا إلى السلة. باستخدام prod2vec ، في أكثر من 40٪ من الجلسات ، أوصينا بمنتج واحد على الأقل ، تم إضافته بعد ذلك إلى السلة. للمقارنة ، تظهر خوارزمية أبسط جودة 34 ٪.
لا يسمح لنا وصف المتجه الناتج بالبحث فقط عن أقربها (والتي يمكن القيام بها من خلال نموذج أبسط ، وإن كان بجودة أسوأ). يمكننا النظر في الآثار الجانبية المثيرة للاهتمام التي يمكن عرضها باستخدام نموذجنا.
المتجهات الحسابية
لتوضيح أن المتجهات تحمل المعنى الحقيقي للبضائع ، يمكننا محاولة استخدام الحساب المتجه لهم. كما هو الحال في مثال الكتاب المدرسي على word2vec (king - man + woman = queen) ، يمكننا على سبيل المثال أن نسأل أنفسنا عن المنتج الذي يقع على مسافة تقريبًا من الطابعة مثل حقيبة الغبار من المكنسة الكهربائية. يملي الفطرة السليمة أنه يجب أن يكون نوعًا من المواد الاستهلاكية ، أي الخرطوشة. نموذجنا قادر على التقاط مثل هذه الأنماط:

التصور مساحة المنتج
لفهم النتائج بشكل أفضل ، يمكننا تصور مساحة ناقل البضائع على متن الطائرة ، مع تقليل البعد إلى اثنين (في هذا المثال ، استخدمنا t-SNE).

من الواضح أن المنتجات ذات الصلة تشكل مجموعات. على سبيل المثال ، مجموعات مع المنسوجات لغرفة النوم والملابس الذكور والإناث ، والأحذية واضحة للعيان. مرة أخرى ، نلاحظ أن هذا النموذج مبني فقط على أساس تاريخ تفاعلات المستخدم مع البضائع ؛ ولم نستخدم تشابه الصور أو الأوصاف النصية عند التدريب.
من خلال الرسم التوضيحي للمساحة ، يمكنك أيضًا معرفة كيفية استخدام الملحقات للسلع باستخدام النموذج. للقيام بذلك ، تحتاج إلى أن تأخذ البضائع من أقرب مجموعة ، على سبيل المثال ، توصي بالسلع الرياضية للقمصان وقبعات السترات الصوفية الدافئة.
خطط
نعرض الآن نموذج prod2vec في الإنتاج لحساب توصيات المنتج. أيضًا ، يمكن استخدام المتجهات التي تم الحصول عليها كميزات لخوارزميات التعلم الآلي الأخرى التي يشارك فريقنا فيها (التنبؤ بالطلب على السلع ، الترتيب في البحث والكتالوجات ، التوصيات الشخصية).
في المستقبل ، نخطط لتنفيذ حفلات الزفاف المستلمة على الموقع في الوقت الفعلي. بالنسبة إلى جميع السلع التي يتم عرضها ، ستكون السلع التالية في الجلسة ، والتي ستنعكس على الفور في عملية التسليم الشخصية. نخطط أيضًا لدمج تحليل الصور وتحليل التشابه وفقًا لوصف المتجه في نموذجنا ، مما سيحسن بشكل كبير من جودة المتجهات الناتجة.
إذا كنت تعرف أفضل طريقة للقيام بذلك (أو إعادة صنع) - تعال إلى الزيارة (وحتى العمل الأفضل).
المراجع
- ميكولوف وتوماس وآخرون. "توزع تمثيل الكلمات والعبارات وتكوينها." التقدم في نظم معالجة المعلومات العصبية. 2013.
- Grbovic ، Mihajlo ، وآخرون. "التجارة الإلكترونية في صندوق الوارد الخاص بك: توصيات المنتج على نطاق واسع." وقائع المؤتمر الدولي الـ 21 ACM SIGKDD لاكتشاف المعرفة واستخراج البيانات. ACM ، 2015.
- Grbovic ، Mihajlo ، و Haibin Cheng. "التخصيص في الوقت الحقيقي باستخدام حفلات الزفاف لترتيب البحث في Airbnb." وقائع المؤتمر الدولي ACM SIGKDD الرابع والعشرين حول اكتشاف المعرفة واستخراج البيانات. ACM ، 2018.