في Rostelecom ، نستخدم Hadoop لتخزين ومعالجة البيانات التي تم تنزيلها من مصادر متعددة باستخدام تطبيقات جافا. لقد انتقلنا الآن إلى إصدار جديد من hadoop مع Kerberos Authentication. عند التنقل ، واجهت عددًا من المشكلات ، بما في ذلك استخدام YARN API. يستحق عمل Hadoop مع Kerberos Authentication مقالة منفصلة ، ولكن في هذه المقالة سنتحدث عن تصحيح Hadoop MapReduce.

عند تنفيذ المهام في الكتلة ، يكون بدء تشغيل مصحح الأخطاء معقدًا بسبب حقيقة أننا لا نعرف العقدة التي ستقوم بمعالجة هذا أو ذاك الجزء من بيانات الإدخال ، ولا يمكننا تكوين مصحح الأخطاء مسبقًا.
يمكنك استخدام
System.out.println("message") الذي تم اختباره عبر الزمن. ولكن كيف يمكن تحليل مخرجات
System.out.println("message") المنتشرة عبر هذه العقد؟
يمكننا إخراج الرسائل إلى دفق الأخطاء القياسي. كل شيء مكتوب في stdout أو stderr ،
إرسالها إلى ملف السجل المناسب ، والذي يمكن العثور عليه على صفحة معلومات المهمة الموسعة أو في ملفات السجل.
يمكننا أيضًا تضمين أدوات تصحيح الأخطاء في التعليمات البرمجية الخاصة بنا وتحديث رسائل حالة المهمة واستخدام عدادات مخصصة لمساعدتنا في فهم حجم الكارثة.
يمكن تصحيح تطبيق Hadoop MapReduce في جميع الأوضاع الثلاثة التي يمكن أن يعمل Hadoop فيها:
- مستقل
- وضع الموزعة الزائفة
- موزعة بالكامل
بمزيد من التفصيل سنركز على الأولين.
وضع الموزعة الزائفة
يتم استخدام وضع الموزعة الزائفة لمحاكاة كتلة حقيقية. ويمكن استخدامه للاختبار في بيئة أقرب إلى الإنتاجية قدر الإمكان. في هذا الوضع ، ستعمل جميع شياطين Hadoop على عقدة واحدة!
إذا كان لديك خادم dev أو صندوق رمل آخر (على سبيل المثال ، Virtual Machine مع بيئة تطوير مخصصة ، مثل Hortonworks Sanbox with HDP) ، يمكنك تصحيح برنامج التحكم باستخدام أدوات تصحيح الأخطاء عن بُعد.
لبدء تصحيح الأخطاء ، تحتاج إلى تعيين قيمة متغير البيئة:
YARN_OPTS . ما يلي مثال. للراحة ، يمكنك إنشاء ملف startWordCount.sh وإضافة المعلمات اللازمة إليه لبدء تشغيل التطبيق.
الآن ، بتشغيل البرنامج النصي
`./startWordCount.sh` ، سنرى رسالة
Listening for transport dt_socket at address: 6000
يبقى تكوين IDE لتصحيح الأخطاء عن بُعد. أنا أستخدم intellij IDEA. انتقل إلى القائمة تشغيل -> تحرير التكوينات ... إضافة تكوين
Remote جديد.
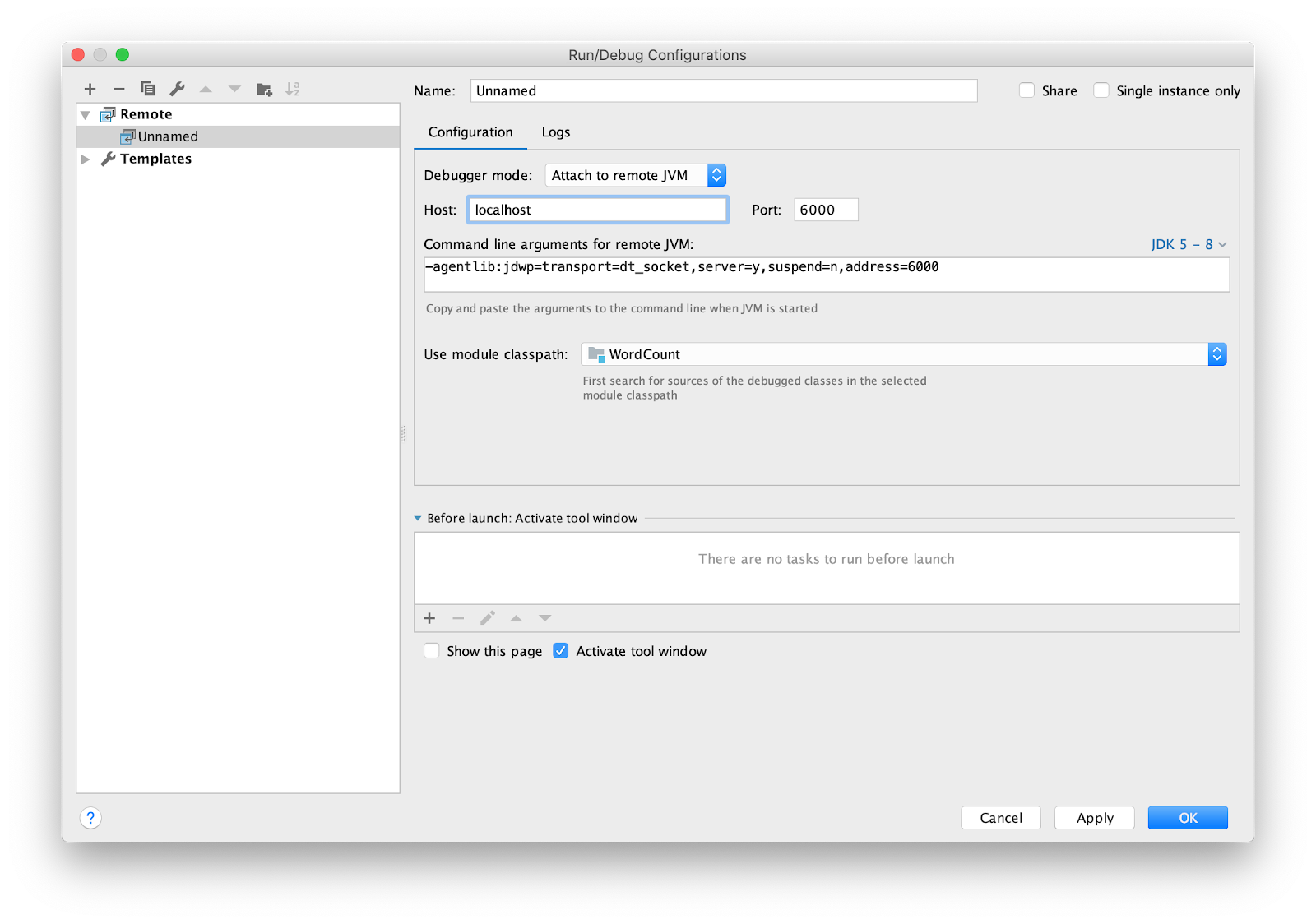
تعيين نقطة توقف الرئيسية وتشغيل.
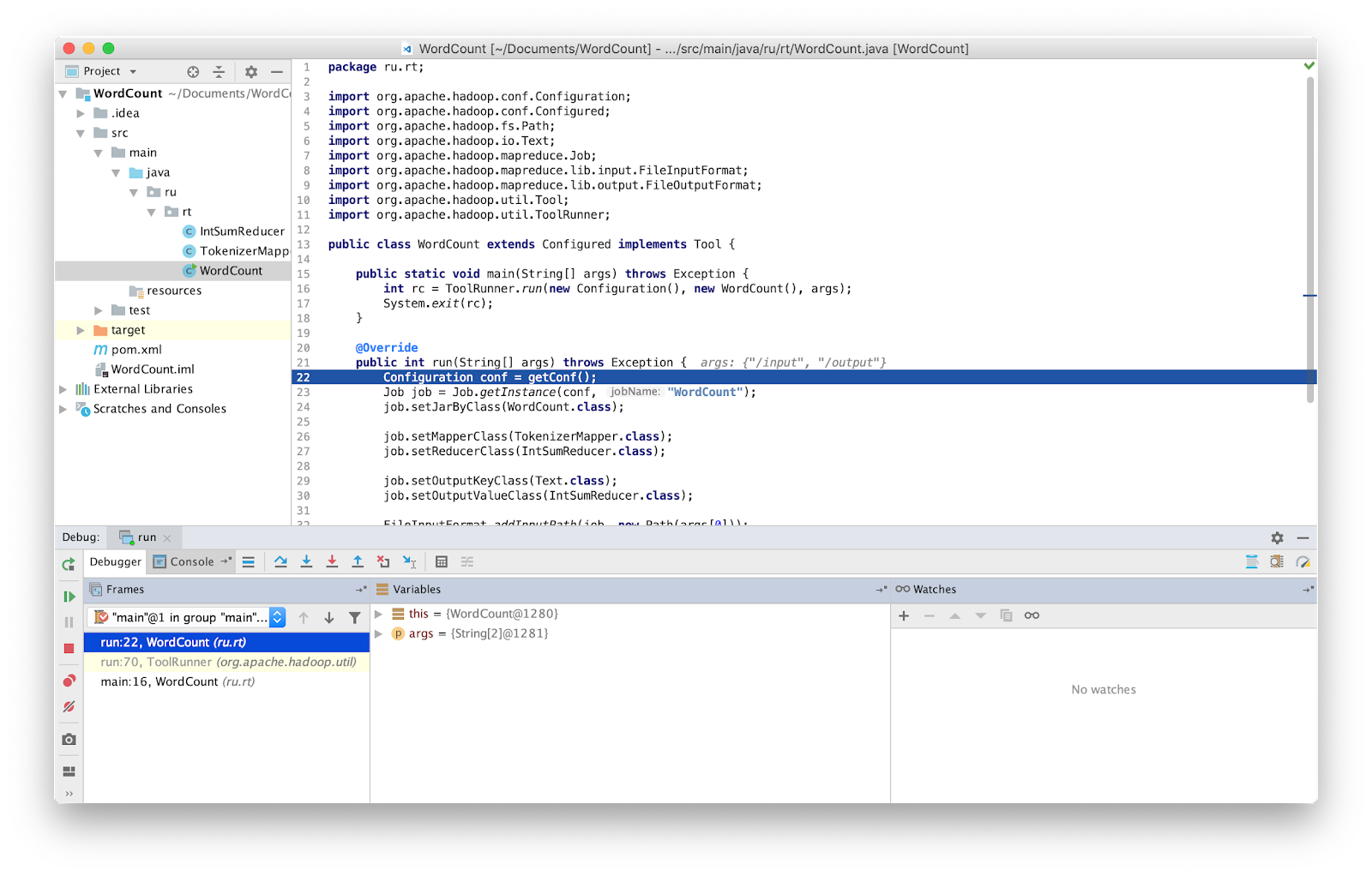
هذا كل شيء ، الآن يمكننا تصحيح البرنامج كالمعتاد.
الاهتمام يجب عليك التأكد من أنك تعمل مع أحدث إصدار من التعليمات البرمجية المصدر. إذا لم يكن الأمر كذلك ، فقد تكون هناك اختلافات في الأسطر التي يتوقف فيها المصحح.
في الإصدارات السابقة من Hadoop ، تم توفير فئة خاصة تسمح لك بإعادة تشغيل مهمة فاشلة - isolationRunner. تم حفظ البيانات التي تسببت في الفشل على القرص على العنوان المحدد في متغير البيئة Hadoop mapred.local.dir. لسوء الحظ ، في الإصدارات الأخيرة من Hadoop ، لم تعد هذه الفئة متوفرة.
مستقل (بداية محلية)
مستقل هو الوضع القياسي الذي يعمل Hadoop. وهي مناسبة للتصحيح حيث لا يتم استخدام HDFS. مع مثل هذا التصحيح ، يمكنك استخدام المدخلات والمخرجات من خلال نظام الملفات المحلي. يعد الوضع المستقل عادةً أسرع وضع Hadoop لأنه يستخدم نظام الملفات المحلي لجميع بيانات المدخلات والمخرجات.
كما ذكر سابقًا ، يمكنك حقن أدوات تصحيح الأخطاء في التعليمات البرمجية الخاصة بك ، مثل العدادات. يتم تعريف عدادات بواسطة
تعداد Java. يعرّف اسم التعداد اسم المجموعة ، وتحدد حقول التعداد أسماء العدادات. يمكن أن يكون العداد مفيدًا لتقييم المشكلة ،
ويمكن استخدامها كإضافة إلى إخراج التصحيح.
إعلان واستخدام العداد:
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private Text word = new Text(); enum Word { TOTAL_WORD_COUNT, } @Override public void map(LongWritable key, Text value, Context context) { String[] stringArr = value.toString().split("\\s+"); for (String str : stringArr) { word.set(str); context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); } } } }
لزيادة العداد ، استخدم طريقة
increment(1) .
... context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); ...
بعد اكتمال MapReduce بنجاح ، تعرض المهمة العدادات في النهاية.
Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 ru.rt.example.Map$Word TOTAL_WORD_COUNT=655
يمكن إخراج البيانات الخاطئة إلى stderr أو stdout ، أو لكتابة الإخراج إلى hdfs باستخدام فئة
MultipleOutputs لمزيد من التحليل. يمكن إرسال البيانات المستلمة إلى إدخال التطبيق في الوضع المستقل أو عند كتابة اختبارات الوحدة.
لدى Hadoop مكتبة MRUnit ، والتي يتم استخدامها مع أطر اختبار (على سبيل المثال JUnit). عند كتابة اختبارات الوحدة ، نتحقق من أن الوظيفة تنتج النتيجة المتوقعة في المخرجات. نحن نستخدم فئة MapDriver من حزمة MRUnit ، التي نعيّن خصائصها في الصف الذي تم اختباره. للقيام بذلك ، استخدم الأسلوب
withMapper() وقيم الإدخال
withInputValue() والنتيجة المتوقعة
withOutput() أو
withMultiOutput() إذا تم استخدام إخراج متعدد.
هنا هو اختبارنا.
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mrunit.mapreduce.MapDriver; import org.apache.hadoop.mrunit.types.Pair; import org.junit.Before; import org.junit.Test; import java.io.IOException; public class TestWordCount { private MapDriver<Object, Text, Text, IntWritable> mapDriver; @Before public void setUp() { Map mapper = new Map(); mapDriver.setMapper(mapper) } @Test public void mapperTest() throws IOException { mapDriver.withInput(new LongWritable(0), new Text("msg1")); mapDriver.withOutput(new Pair<Text, IntWritable>(new Text("msg1"), new IntWritable(1))); mapDriver.runTest(); } }
وضع الموزعة بالكامل
كما يوحي الاسم ، هذا هو الوضع الذي يتم فيه استخدام كل قوة Hadoop. يمكن تشغيل برنامج MapReduce الذي تم إطلاقه على 1000 خادم. من الصعب دائمًا تصحيح برنامج MapReduce ، نظرًا لأن لديك معينين يعملون على أجهزة مختلفة ببيانات إدخال مختلفة.
الخاتمة
كما اتضح فيما بعد ، فإن اختبار MapReduce ليس سهلاً كما يبدو للوهلة الأولى.
لتوفير الوقت في البحث عن الأخطاء في MapReduce ، استخدمت جميع الطرق المذكورة أعلاه ، وأنصح الجميع بتطبيقها أيضًا. هذا مفيد بشكل خاص في حالة المنشآت الكبيرة ، مثل تلك التي تعمل في Rostelecom.