
يتم إجراء 17 مليار حدث و 60 مليون جلسة مستخدم وعدد كبير من التواريخ الافتراضية في Badoo يوميًا. يتم تخزين كل حدث بدقة في قواعد البيانات العلائقية لتحليلها لاحقا في SQL وخارجها.
قواعد بيانات المعاملات الموزعة الحديثة مع عشرات تيرابايت من البيانات - معجزة حقيقية للهندسة. لكن SQL ، باعتبارها تجسيدًا للجبر العلائقي في معظم التطبيقات القياسية ، لا تسمح لنا بعد بصياغة استعلامات من حيث tuples المطلوبة.
في المقال الأخير في سلسلة حول الأجهزة الافتراضية ، سأتحدث عن طريقة بديلة لإيجاد جلسات مثيرة للاهتمام - محرك التعبير العادي ( Pig Match ) ، والذي تم تحديده لتسلسل الأحداث.
يتم تضمين الجهاز الظاهري ، bytecode ومترجم مجانا!
الجزء الأول ، تمهيدية
الجزء الثاني ، الأمثل
الجزء الثالث ، المطبق (الحالي)
حول الأحداث والدورات
افترض أن لدينا بالفعل مستودع بيانات يسمح لك بمشاهدة أحداث كل جلسة من جلسات المستخدم بسرعة وبشكل متتابع.
نريد العثور على جلسات عن طريق طلبات مثل "حساب جميع الجلسات التي يوجد فيها تتابع محدد للأحداث" ، أو "العثور على أجزاء من جلسة موصوفة بنموذج معين" ، أو "إرجاع جزء الجلسة الذي حدث بعد نمط معين" أو "حساب عدد الجلسات التي وصلت إلى أجزاء معينة القالب. " قد يكون ذلك مفيدًا لأنواع مختلفة من التحليل: البحث عن جلسات مشبوهة ، وتحليل قمع ، إلخ.
يجب أن يتم وصف الخطوات التالية المطلوبة. تشبه هذه المهمة في أبسط أشكالها العثور على سلسلة فرعية في نص ؛ نريد أن يكون لدينا أداة أكثر قوة - التعبيرات العادية. غالباً ما تستخدم التطبيقات الحديثة لمحركات التعبير العادية (تفكر في ذلك!) الأجهزة الافتراضية.
ستتم مناقشة إنشاء أجهزة افتراضية صغيرة لمطابقة الجلسات مع التعبيرات العادية أدناه. لكن أولاً ، سنوضح التعاريف.
يتكون الحدث من نوع الحدث والوقت والسياق ومجموعة من السمات الخاصة بكل نوع.
نوع وسياق كل حدث عبارة عن أعداد صحيحة من قوائم محددة مسبقًا. إذا كان كل شيء واضحًا مع أنواع الأحداث ، فسيكون السياق ، على سبيل المثال ، هو رقم الشاشة التي وقع عليها الحدث المحدد.
سمة الحدث هي عدد صحيح تعسفي يتم تحديد معناه حسب نوع الحدث. قد لا يكون للحدث سمات ، أو قد يكون هناك عدة.
الجلسة عبارة عن سلسلة من الأحداث مرتبة حسب الوقت.
ولكن دعونا أخيرًا نبدأ العمل. تراجعت المشاركات ، كما يقولون ، وخرجت إلى المسرح.
قارن على قطعة من الورق
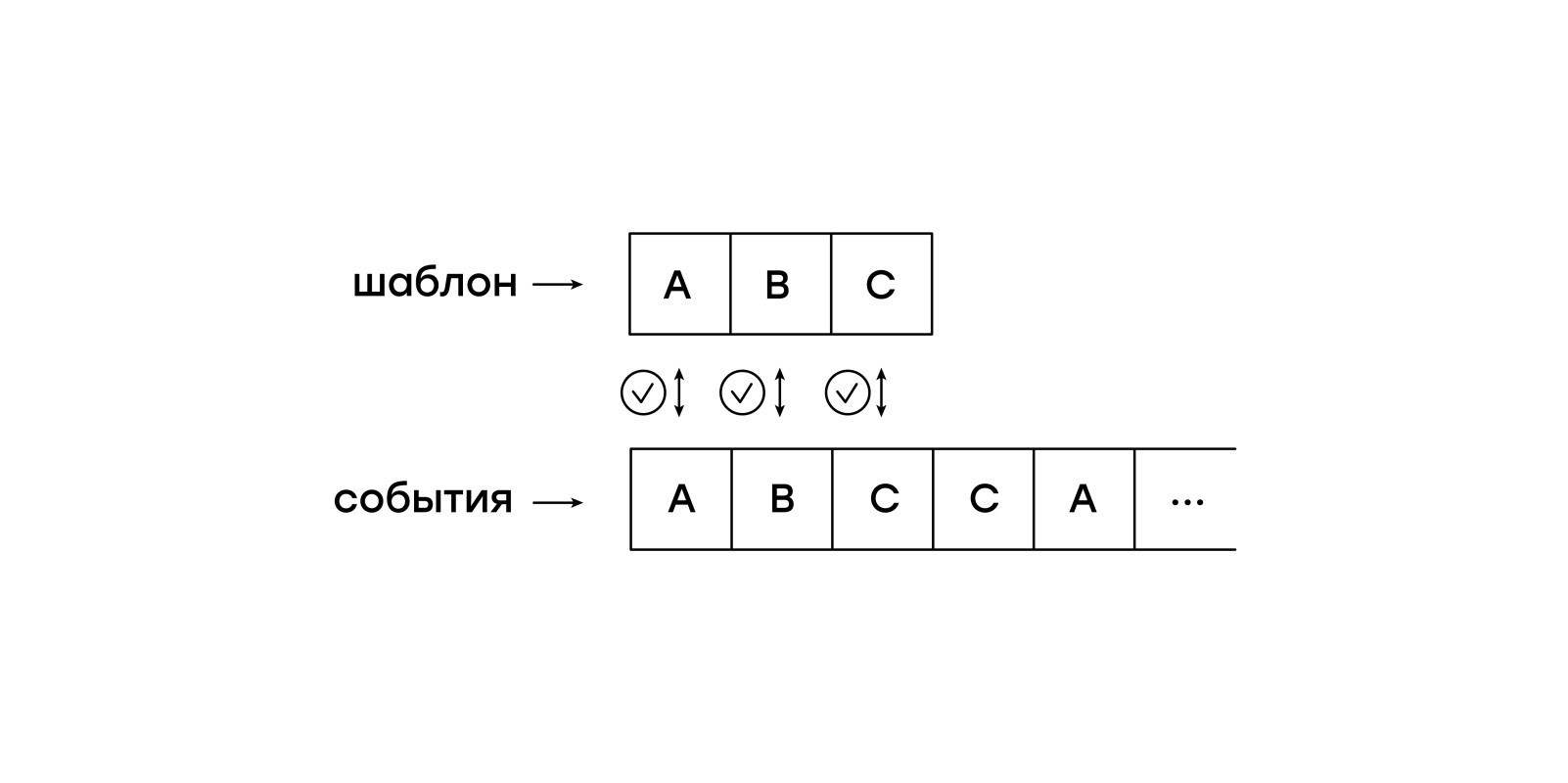
ميزة هذا الجهاز الظاهري هي السلبية فيما يتعلق بأحداث الإدخال. لا نريد الاحتفاظ بالجلسة بأكملها في الذاكرة والسماح للجهاز الظاهري بالتبديل من حدث إلى آخر بشكل مستقل. بدلاً من ذلك ، سنقوم بإدخال الأحداث من الجلسة إلى الجهاز الظاهري واحداً تلو الآخر.
دعونا نحدد وظائف الواجهة:
matcher *matcher_create(uint8_t *bytecode); match_result matcher_accept(matcher *m, uint32_t event); void matcher_destroy(matcher *matcher);
إذا كان كل شيء واضحًا باستخدام الدالات matcher_create و matcher_destroy ، فيجب أن تكون matcher_accept تستحق التعليق. تتلقى وظيفة matcher_accept مثيل الجهاز الظاهري والحدث التالي (32 بت ، حيث 16 بت لنوع الحدث و 16 بت للسياق) ، وتُرجع رمزًا يوضح ما يجب أن يفعله رمز المستخدم بعد ذلك:
typedef enum match_result {
شفرة الآلة الافتراضية:
typedef enum matcher_opcode {
الحلقة الرئيسية للجهاز الظاهري:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP() \ (*m->ip++) #define NEXT_ARG() \ ((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1]) for (;;) { uint8_t instruction = NEXT_OP(); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(); if (event_name(next_event) != name) return MATCH_FAIL; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(); if (event_screen(next_event) != screen) return MATCH_FAIL; break; } case OP_NEXT:{ return MATCH_NEXT; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } #undef NEXT_OP #undef NEXT_ARG }
في هذا الإصدار البسيط ، يتطابق الجهاز الظاهري لدينا بشكل متتابع مع النمط الذي تم وصفه بواسطة bytecode مع الأحداث الواردة. على هذا النحو ، هذه ليست ببساطة مقارنة موجزة للغاية لبادئات سطرين: القالب المطلوب وخط الإدخال.
البادئات هي بادئات ، لكننا نريد العثور على الأنماط المطلوبة ليس فقط في البداية ، ولكن أيضًا في مكان تعسفي في الجلسة. الحل الساذج هو إعادة المطابقة من كل حدث جلسة. ولكن هذا ينطوي على مشاهدة متعددة لكل حدث من الأحداث وتناول الأطفال الخوارزميين.
المثال من المقالة الأولى في السلسلة ، في الواقع ، يحاكي إعادة تشغيل التطابق باستخدام التراجع (التراجع باللغة الإنجليزية). بالطبع ، يبدو الكود في المثال أنحف من الكود الموضح هنا ، لكن المشكلة لم تختف: سيتعين فحص كل حدث عدة مرات.
لا يمكنك العيش هكذا.
لي ، أنا مرة أخرى وأنا مرة أخرى

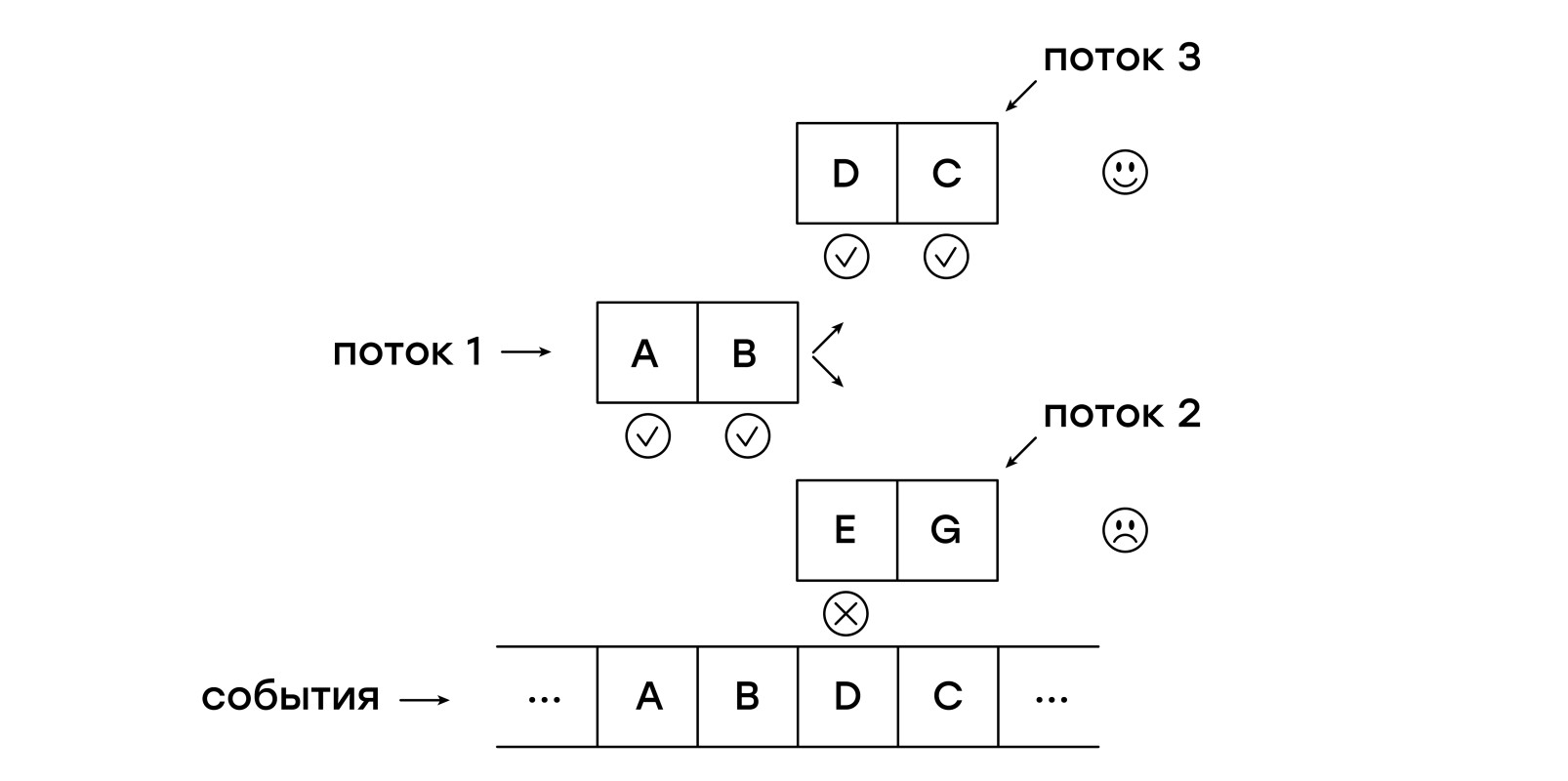
دعنا نوضح المشكلة مرةً أخرى: نحتاج إلى مطابقة القالب بالأحداث القادمة ، بدءًا من كل حدث يبدأ بمقارنة جديدة. فلماذا لا نفعل ذلك؟ دع الجهاز الظاهري يمشي على الأحداث الواردة في العديد من مؤشرات الترابط!
للقيام بذلك ، نحن بحاجة إلى الحصول على كيان جديد - دفق. يخزن كل مؤشر مؤشر واحد - حسب التعليمات الحالية:
typedef struct matcher_thread { uint8_t *ip; } matcher_thread;
بطبيعة الحال ، الآن في الجهاز الظاهري نفسه ، لن نقوم بتخزين المؤشر الصريح. سيتم استبداله بقائمتين من المواضيع (المزيد عنها أدناه):
typedef struct matcher { uint8_t *bytecode; matcher_thread current_threads[MAX_THREAD_NUM]; uint8_t current_thread_num; matcher_thread next_threads[MAX_THREAD_NUM]; uint8_t next_thread_num; } matcher;
وهنا هو حلقة رئيسية محدثة:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP(thread) \ (*(thread).ip++) #define NEXT_ARG(thread) \ ((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1]) /* - */ add_current_thread(m, initial_thread(m)); // for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) { matcher_thread current_thread = m->current_threads[thread_i]; bool thread_done = false; while (!thread_done) { uint8_t instruction = NEXT_OP(current_thread); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(current_thread); // , , // next_threads, if (event_name(next_event) != name) thread_done = true; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(current_thread); if (event_screen(next_event) != screen) thread_done = true; break; } case OP_NEXT:{ // , .. // next_threads add_next_thread(m, current_thread); thread_done = true; break; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } } /* , */ swap_current_and_next(m); return MATCH_NEXT; #undef NEXT_OP #undef NEXT_ARG }
في كل حدث تم استلامه ، قمنا أولاً بإضافة سلسلة رسائل جديدة إلى قائمة Current_threads ، والتحقق من القالب من البداية ، وبعد ذلك نبدأ في اجتياز قائمة Current_threads ، باتباع كل مؤشر باتباع الإرشادات.
إذا تمت مصادفة تعليمات NEXT ، فسيتم وضع الخيط في القائمة next_threads ، أي أنه ينتظر الحدث التالي.
إذا كان نمط سلاسل الرسائل لا يتطابق مع الحدث المستلم ، فلن تتم إضافة سلسلة الرسائل هذه ببساطة إلى قائمة next_threads.
يخرج تعليمة MATCH من الوظيفة فورًا ، حيث يبلغ عن رمز إرجاع يطابق النموذج الجلسة.
عند الانتهاء من الزحف إلى قائمة سلاسل الرسائل ، يتم تبادل القوائم الحالية والقادمة.
في الواقع ، هذا كل شيء. يمكننا أن نقول إننا نقوم حرفيًا بما أردنا: في الوقت نفسه ، نتحقق من عدة قوالب ، ونطلق عملية مطابقة جديدة لكل حدث من أحداث الجلسة.
هويات وفروع متعددة في قوالب
إن البحث عن قالب يصف التسلسل الخطي للأحداث مفيد ، بالطبع ، لكننا نريد الحصول على تعبيرات منتظمة كاملة. والتدفقات التي أنشأناها في المرحلة السابقة مفيدة هنا أيضًا.
لنفترض أننا نريد العثور على سلسلة من حدثين أو ثلاثة تهمنا ، شيء يشبه التعبير المنتظم على الخطوط: "a؟ Bc". في هذا التسلسل ، يكون الرمز "a" اختياريًا. كيفية التعبير عنها في bytecode؟ سهل
يمكننا أن نبدأ خيطين ، واحد لكل حالة: مع الرمز "a" وبدونه. للقيام بذلك ، نقدم تعليمة إضافية (من نوع SPLIT addr1 ، addr2) ، والذي يبدأ بموضوعين من العناوين المحددة. بالإضافة إلى SPLIT ، فإن JUMP مفيد لنا أيضًا ، والذي يواصل التنفيذ ببساطة بالتعليمات المحددة في الوسيطة المباشرة:
typedef enum matcher_opcode { OP_ABORT, OP_NAME, OP_SCREEN, OP_NEXT,
لا تتغير الحلقة نفسها وبقية التعليمات - نقدم فقط معالجين جديدين:
لاحظ أن الإرشادات تضيف مؤشرات ترابط إلى القائمة الحالية ، أي أنها تستمر في العمل في سياق الحدث الحالي. لا يدخل مؤشر الترابط الذي حدث داخل الفرع في قائمة مؤشرات الترابط التالية.
إن الشيء الأكثر إثارة للدهشة في هذا الجهاز الظاهري للتعبير العادي هو أن مؤشرات الترابط الخاصة بنا وهذه الإرشادات تكفي للتعبير عن جميع الإنشاءات المقبولة عمومًا عند مطابقة السلاسل.
تعبيرات منتظمة عن الأحداث
الآن وقد أصبح لدينا آلة وأدوات افتراضية مناسبة لذلك ، يمكننا في الواقع التعامل مع بناء جملة تعبيراتنا العادية.
التسجيل اليدوي لأكواد الشفرة لبرامج أكثر خطورة بسرعة. في المرة الأخيرة ، لم أقم بعمل محلل متكامل ، لكن المستخدم الحقيقي أثبت أن قدرات مكتبة raddsl الخاصة به تستخدم لغة PigletC المصغرة كمثال . لقد تأثرت كثيراً بإيجاز الكود ، وبمساعدة raddsl ، كتبت مترجمًا صغيرًا من التعبيرات العادية للسلاسل في مائة أو مائتي في بيثون. المترجم والتعليمات الخاصة باستخدامه موجودة على GitHub. يتم فهم نتيجة المحول البرمجي في لغة التجميع بواسطة أداة مساعدة تقوم بقراءة الملفين (برنامج لجهاز ظاهري وقائمة بأحداث الجلسة للتحقق منها).
بادئ ذي بدء ، نحن نقتصر على نوع الحدث وسياقه. يُشار إلى نوع الحدث برقم واحد ؛ إذا كنت بحاجة إلى تحديد سياق ، فحدده من خلال نقطتين. أبسط مثال:
> python regexp/regexp.py "13" # , 13 NEXT NAME 13 MATCH
الآن مثال مع السياق:
python regexp/regexp.py "13:12" # 13, 12 NEXT NAME 13 SCREEN 12 MATCH
يجب أن تكون الأحداث المتعاقبة مفصولة بطريقة ما (على سبيل المثال ، بمسافات):
> python regexp/regexp.py "13 11 10:9" 08:40:52 NEXT NAME 13 NEXT NAME 11 NEXT NAME 10 SCREEN 9 MATCH
قالب أكثر إثارة للاهتمام:
> python regexp/regexp.py "12|13" SPLIT L0 L1 L0: NEXT NAME 12 JUMP L2 L1: NEXT NAME 13 L2: MATCH
إيلاء الاهتمام للخطوط التي تنتهي مع القولون. هذه هي العلامات. ينشئ تعليمة SPLIT اثنين من مؤشرات الترابط التي تستمر في التنفيذ من التسميات L0 و L1 ، ويتابع JUMP في نهاية الفرع الأول للتنفيذ ببساطة إلى نهاية الفرع.
يمكنك الاختيار بين سلاسل التعبيرات بشكل أكثر صدقًا عن طريق تجميع الإجابات التالية بين قوسين:
> python regexp/regexp.py "(1 2 3)|4" SPLIT L0 L1 L0: NEXT NAME 1 NEXT NAME 2 NEXT NAME 3 JUMP L2 L1: NEXT NAME 4 L2: MATCH
يشار إلى حدث تعسفي بواسطة نقطة:
> python regexp/regexp.py ". 1" NEXT NEXT NAME 1 MATCH
إذا كنا نريد أن نظهر أن الخطوة التالية اختيارية ، فسنضع علامة استفهام بعدها:
> python regexp/regexp.py "1 2 3? 4" NEXT NAME 1 NEXT NAME 2 SPLIT L0 L1 L0: NEXT NAME 3 L1: NEXT NAME 4 MATCH
بالطبع ، التكرارات المنتظمة المتعددة (علامة الجمع أو النجمة) شائعة أيضًا في التعبيرات العادية:
> python regexp/regexp.py "1+ 2" L0: NEXT NAME 1 SPLIT L0 L1 L1: NEXT NAME 2 MATCH
نحن هنا ننفذ ببساطة تعليمات SPLIT عدة مرات ، ونبدأ المواضيع الجديدة في كل دورة.
بالمثل مع علامة النجمة:
> python regexp/regexp.py "1* 2" L0: SPLIT L1 L2 L1: NEXT NAME 1 JUMP L0 L2: NEXT NAME 2 MATCH

المنظور
قد تكون الإضافات الأخرى للجهاز الظاهري الموصوفة في متناول يدي.
على سبيل المثال ، يمكن توسيعه بسهولة عن طريق التحقق من سمات الحدث. بالنسبة لنظام حقيقي ، أفترض استخدام بناء جملة مثل "1: 2 {3: 4 ، 5:> 3}" ، مما يعني: الحدث 1 في السياق 2 مع السمة 3 التي لها قيمة 4 والقيمة المميزة 5 أكبر من 3. السمات هنا يمكنك ببساطة تمريرها في صفيف إلى الدالة matcher_accept.
إذا قمت أيضًا بتمرير الفاصل الزمني بين الأحداث إلى matcher_accept ، فيمكنك إضافة بناء جملة إلى لغة القالب التي تتيح لك تخطي الوقت بين الأحداث: "1 mindelta (120) 2" ، مما يعني: الحدث 1 ، ثم فترة لا تقل عن 120 ثانية ، الحدث 2 بالاقتران مع الحفاظ على سلسلة لاحقة ، يتيح لك هذا جمع معلومات حول سلوك المستخدم بين اثنتين من أحداث الأحداث.
الأشياء المفيدة الأخرى التي يسهل إضافتها نسبياً هي: الحفاظ على تعبيرات التعبيرات العادية ، وفصل مشغلي النجمة الجشعة والعادية بالإضافة إلى عوامل التشغيل وما إلى ذلك. بالنسبة إلى نظرية الأتمتة ، فإن أجهزتنا الافتراضية هي آلية محدودة غير محددة ، وليس من الصعب تنفيذها مثل هذه الأشياء.
الخاتمة
تم تطوير نظامنا لواجهات المستخدم السريعة ، وبالتالي فإن محرك تخزين الجلسة مكتوب ذاتيًا ومحسّنًا على وجه التحديد للمرور عبر جميع الجلسات. يتم فحص جميع بلايين الأحداث التي تفرقت في الجلسات مقابل الأنماط في ثوانٍ على خادم واحد.
إذا كانت السرعة ليست حاسمة بالنسبة لك ، فيمكن عندئذ تصميم نظام مشابه امتدادًا لبعض أنظمة تخزين البيانات القياسية مثل قاعدة بيانات علائقية تقليدية أو نظام ملفات موزع.
بالمناسبة ، في أحدث إصدارات معيار SQL ، ظهرت بالفعل ميزة مشابهة لتلك الموضحة في المقالة ، وقامت بالفعل قواعد بيانات فردية ( Oracle و Vertica ) بتنفيذها. ياندكس ClickHouse ، بدوره ، ينفذ لغة تشبه SQL الخاصة به ، ولكن لديه أيضا وظائف مماثلة .
بصرف النظر عن الأحداث والتعبيرات العادية ، أريد أن أكرر أن قابلية تطبيق الأجهزة الافتراضية أوسع بكثير مما قد يبدو للوهلة الأولى. هذه التقنية مناسبة وتستخدم على نطاق واسع في جميع الحالات عندما تكون هناك حاجة للتمييز بوضوح بين البدائل التي يفهمها محرك النظام والنظام الفرعي "الأمامي" ، على سبيل المثال ، بعض لغة DSL أو لغة البرمجة.
هذا يختتم سلسلة من المقالات حول الاستخدامات المختلفة لمترجمي bytecode والأجهزة الظاهرية. آمل أن يكون قراء هابر قد أعجبوا بالمسلسل ، وبالطبع سأكون سعيدًا بالإجابة على أي أسئلة حول هذا الموضوع.
تعتبر مترجمو Bytecode للغات البرمجة موضوعًا محددًا ، وهناك القليل جدًا من الأدبيات المتعلقة بهم. أنا شخصياً أحببت كتاب إيان كريج Virtual Machine ، على الرغم من أنه لا يصف تطبيق المترجمين الشفويين بقدر ما يصفه بالأجهزة المجردة - النماذج الرياضية التي تقوم عليها لغات البرمجة المختلفة.
بمعنى أوسع ، يتم تخصيص كتاب آخر للأجهزة الافتراضية - "الأجهزة الافتراضية: أنظمة مرنة للأنظمة والعمليات" ("الأجهزة الافتراضية: أنظمة متعددة الأنظمة للأنظمة والعمليات"). هذه مقدمة عن التطبيقات المختلفة للمحاكاة الافتراضية ، والتي تغطي المحاكاة الافتراضية للغات ، والعمليات ، وهندسة الكمبيوتر بشكل عام.
نادراً ما تناقش الجوانب العملية لتطوير محركات التعبير العادية في أدبيات المترجم الشعبي. تستند لعبة Pig Match والمثال الوارد في المقالة الأولى إلى أفكار من سلسلة مذهلة من المقالات لـ Russ Cox ، أحد مطوري محرك Google RE2.
يتم تقديم نظرية التعبيرات العادية في جميع الكتب الدراسية الأكاديمية عن المترجمين. من المعتاد الإشارة إلى "كتاب التنين" الشهير ، لكنني أوصي بالبدء بالرابط أعلاه.
أثناء العمل على هذه المقالة ، استخدمت نظامًا مثيرًا للاهتمام في البداية للتطوير السريع لمجموعات برنامج Python raddsl ، الذي ينتمي إلى القلم الحقيقي للمستخدم (بفضل Peter!). إذا كنت تواجه مهمة إعداد نماذج أولية للغة أو تطوير نوع من الـ DSL بسرعة ، فيجب عليك الانتباه إليها.