التحدي
تتمثل إحدى المهام الكبيرة لتطبيق تخزين وتخزين المشتريات في البحث عن منتجات متطابقة أو قريبة جدًا في قاعدة البيانات ، والتي تحتوي على أسماء منتجات متنوعة وغير مفهومة تم الحصول عليها من الإيصالات. هناك نوعان من طلب الإدخال:
- اسم محدد مع اختصارات ، والتي لا يمكن فهمها إلا من قبل الصرافين في سوبر ماركت محلي ، أو مشترين متعطشين.
- استعلام باللغة الطبيعية الذي أدخله المستخدم في سلسلة البحث.
تأتي طلبات النوع الأول ، كقاعدة عامة ، من المنتجات الموجودة في الفحص نفسه ، عندما يحتاج المستخدم إلى العثور على منتجات أرخص. مهمتنا هي اختيار المنتج التماثلي الأكثر تشابهًا من الاختيار في المتاجر الأخرى القريبة. من المهم اختيار العلامة التجارية الأكثر ملاءمة للمنتج ، وإذا كان ذلك ممكنًا ، الحجم.
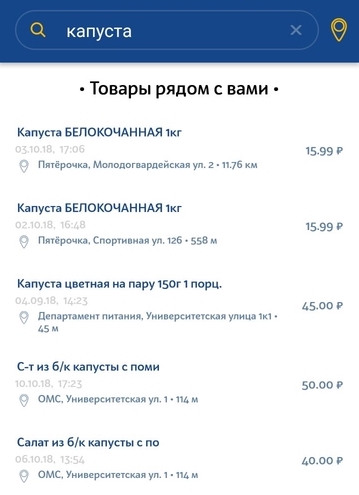
النوع الثاني من الطلبات هو طلب مستخدم بسيط للبحث عن منتج معين في أقرب متجر. يمكن أن يكون الطلب وصفًا عامًا وغير فريد للمنتج. قد يكون هناك انحرافات طفيفة عن الطلب. على سبيل المثال ، إذا بحث المستخدم عن حليب 3.2٪ ، وفي قاعدة بياناتنا حليب 2.5٪ فقط ، فإننا لا نزال نريد عرض هذه النتيجة على الأقل.
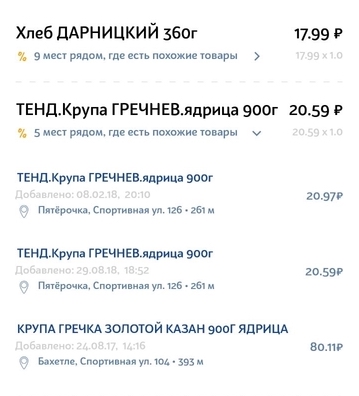
ميزات مجموعة البيانات - مشاكل لحلها
المعلومات الواردة في إيصال المنتج أبعد ما تكون عن المثالية. يحتوي على الكثير من الاختصارات غير الواضحة دائمًا والأخطاء النحوية والأخطاء المطبعية والترجمات المتنوعة والحروف اللاتينية في منتصف الأبجدية السيريلية ومجموعات الأحرف التي لا معنى لها إلا للتنظيم الداخلي في متجر معين.
على سبيل المثال ، يمكن بسهولة كتابة هريس التفاح الموز مع جبنة الكوخ على الشيك مثل هذا:

حول التكنولوجيا
Elasticsearch هي تقنية شعبية إلى حد ما وبأسعار معقولة لتنفيذ البحث. هذا هو محرك بحث API JSON REST باستخدام Lucene ومكتوب بلغة Java. المزايا الرئيسية للمطاط هي السرعة ، القابلية للتطوير والتسامح مع الخطأ. تستخدم محركات مماثلة لعمليات البحث المعقدة في قاعدة بيانات الوثائق. على سبيل المثال ، بحث يأخذ في الاعتبار مورفولوجيا اللغة أو البحث عن طريق الإحداثيات الجغرافية.
اتجاهات التجريب والتحسين
لفهم كيف يمكنك تحسين بحثك ، تحتاج إلى تحليل نظام البحث إلى مكوناته المكونة المخصصة. بالنسبة لحالتنا ، فإن بنية النظام تبدو هكذا.
- تمر سلسلة الإدخال للبحث عبر المحلل ، الذي يقسم السلسلة بطريقة ما إلى الرموز المميزة - وحدات البحث التي تبحث بين البيانات المخزنة أيضًا كرموز.
- ثم هناك بحث مباشر عن هذه الرموز المميزة لكل وثيقة في قاعدة البيانات الموجودة. بعد العثور على الرمز المميز في مستند معين (والذي يتم تقديمه أيضًا في قاعدة البيانات كمجموعة رمزية) ، يتم احتساب أهميته وفقًا لطراز التشابه المحدد (سوف نسميه نموذج الملاءمة). يمكن أن يكون هذا عبارة عن TF / IDF (تردد المدة - تردد المستند العكسي) ، أو قد يكون نماذج أخرى أكثر تعقيدًا أو تحديدًا.
- في المرحلة التالية ، يتم تجميع عدد النقاط التي سجلها كل رمز مميز بطريقة معينة. يتم تعيين معلمات التجميع بواسطة دلالات الاستعلام. مثال على هذه المجموعات يمكن أن يكون أوزان إضافية لبعض الرموز المميزة (القيمة المضافة) ، وشروط التواجد الإلزامي للرمز ، إلخ. نتيجة هذه المرحلة هي النتيجة - التقييم النهائي لأهمية وثيقة معينة من قاعدة البيانات المتعلقة بالطلب الأولي.

يمكن تمييز ثلاثة مكونات قابلة للتكوين بشكل منفصل عن جهاز البحث ، في كل منها يمكنك تسليط الضوء على طرقك وطرق تحسينك الخاصة.
- محللون
- نموذج التشابه
- تحسينات وقت الاستعلام
بعد ذلك ، سننظر في كل مكون على حدة ونحلل إعدادات محددة للمعلمات التي ساعدت في تحسين البحث في حالة أسماء المنتجات.
تحسينات وقت الاستعلام
لفهم ما يمكننا تحسينه في الطلب ، نقدم مثالاً على الطلب الأولي.
{ "query": { "multi_match": { "query": " 105", "type": "most_fields", "fields": ["name"], "minimum_should_match": "70%" } }, “size”: 100, “min_score”: 15 }
نحن نستخدم نوع الاستعلام most_fields ، حيث أننا نتوقع الحاجة إلى مزيج من عدة أجهزة تحليل لحقل "اسم المنتج". يسمح لك هذا النوع من الاستعلامات بدمج نتائج البحث لسمات مختلفة للكائن الذي يحتوي على النص نفسه ، ويتم تحليله بطرق مختلفة. البديل عن هذا النهج هو استخدام أفضل الحقول أو استعلامات الحقول المتقاطعة ، لكنها ليست مناسبة لحالتنا ، حيث يتم حساب البحث بين السمات المختلفة للكائن (على سبيل المثال: الاسم والوصف). نحن نواجه مهمة الأخذ في الاعتبار الجوانب المختلفة لسمة واحدة - اسم المنتج.
ما يمكن تكوينه:
- مزيج مرجح من مختلف المحللين.
في البداية ، جميع عناصر البحث لها نفس الوزن - وبالتالي ، لها نفس الأهمية. يمكن تغيير ذلك عن طريق إضافة المعلمة 'دفعة' ، والتي تأخذ القيم العددية. إذا كانت المعلمة أكبر من 1 ، فسيكون لعنصر البحث تأثير أكبر على النتائج ، على التوالي ، أقل من 1 - أقل. - فصل المحللون إلى "يجب" و "يجب".
وهي أن بعض المحللات يجب أن تتزامن ، وبعضها اختياري ، وهذا غير كافٍ. في حالتنا ، يمكن أن يكون محلل الأرقام مثالًا على فوائد هذا الفصل. إذا كان الرقم يطابق فقط اسم المنتج في الطلب واسم المنتج في قاعدة البيانات ، فهذا ليس شرطا كافيا لمعادلته. نحن لا نريد أن نرى مثل هذه المنتجات نتيجة لذلك. في الوقت نفسه ، إذا كان الطلب "كريم 10٪" ، فنحن نريد أن تتمتع جميع الكريمات التي تحتوي على 10٪ من الدهون بميزة كبيرة على الكريمة بنسبة 20٪ من الدهون. - المعلمة الأدنى_should_match. ما عدد الرموز التي يجب أن تتطابق بالضرورة في الطلب والمستند من قاعدة البيانات؟ تعمل هذه المعلمة مع نوع طلبنا (most_fields) وتتحقق من الحد الأدنى لعدد الرموز المميزة المطابقة لكل حقل (في حالتنا ، لكل محلل).
- المعلمة Min_score. وثائق فحص العتبة مع نقاط غير كافية. المهم هو أنه لا يوجد أقصى سرعة معروفة. تعتمد النتيجة الناتجة على طلب معين وعلى قاعدة بيانات محددة من الوثائق. في بعض الأحيان ، يمكن أن يكون 150 ، وأحيانًا 2 ، ولكن كلتا هاتين القيمتين تعني أن الكائن من قاعدة البيانات مناسب للطلب. لا يمكننا مقارنة نتائج نتائج الاستعلامات المختلفة.
- ثابت
بعد مراقبة كافية للقيم النهائية للسرعة لاستعلامات مختلفة ، يمكنك تحديد حد تقريبي ، وبعد ذلك بالنسبة لمعظم الاستعلامات تصبح النتائج غير مناسبة. هذا هو أسهل قرار ، ولكنه أيضًا القرار الأكثر غباءًا ، والذي يؤدي إلى البحث بجودة رديئة. - حاول تحليل النتائج التي تم الحصول عليها لطلب معين بعد إجراء بحث بأقل أو أقل من دقيقة.
الفكرة هي أنه بعد لحظة معينة ، يمكنك ملاحظة قفزة حادة في اتجاه انخفاض السرعة. يبقى فقط لتحديد هذه القفزة من أجل التوقف في الوقت المناسب. مثل هذا النهج سوف تعمل بشكل جيد على استفسارات مماثلة:
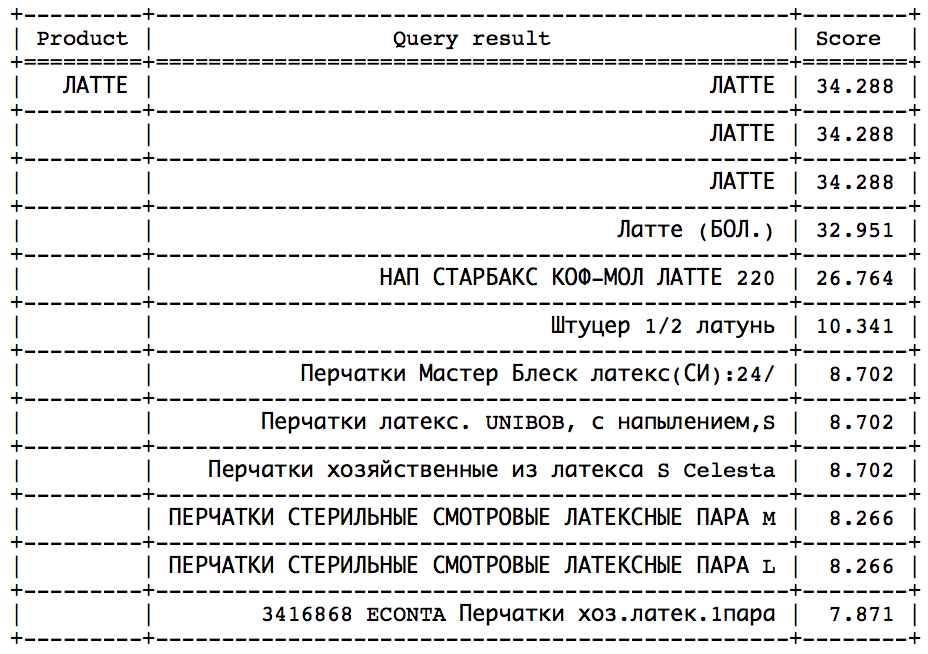
يمكن العثور على القفزة عن طريق الأساليب الإحصائية. ولكن لسوء الحظ ، ليست هذه القفزة موجودة في جميع الطلبات ويمكن التعرف عليها بسهولة. - حساب السرعة المثالية وتعيين min_score ككسر معين من المثالي ، والذي يمكن القيام به بطريقتين:
- من الوصف التفصيلي للحسابات التي قدمها مرن نفسه عند تحديد الشرح: المعلمة الحقيقية. هذه مهمة صعبة ، تتطلب فهماً شاملاً لهندسة الاستعلام والخوارزميات الحسابية المستخدمة من قبل Flex.
- عن طريق خدعة صغيرة. نتلقى طلبًا ، ونضيف منتجًا جديدًا إلى قاعدة البيانات الخاصة بنا بنفس الاسم ، ونقوم بالبحث والحصول على أقصى سرعة. نظرًا لأنه سيكون هناك تطابق بنسبة 100٪ في الاسم ، ستكون القيمة الناتجة مثالية. هذا هو النهج الذي نستخدمه في نظامنا ، حيث لم يتم تأكيد المخاوف بشأن التكلفة العالية لهذه العملية فيما يتعلق بالوقت.
- تغيير خوارزمية التسجيل ، المسؤولة عن قيمة الصلة النهائية. قد يأخذ ذلك في الاعتبار المسافة إلى المتجر (إعطاء المزيد من النقاط للمنتجات الأقرب) ، وأسعار المنتج (إعطاء المزيد من النقاط للمنتجات ذات السعر الأكثر احتمالًا) ، إلخ.
محللون
يحلل المحلل سلسلة الإدخال في ثلاث مراحل وينتج عن الرموز المميزة في وحدات الإخراج - البحث:

أولاً ، تحدث التغييرات على مستوى حرف السلسلة. يمكن أن يكون هذا استبدال أو حذف أو إضافة أحرف إلى سلسلة. ثم يأتي الرمز المميز إلى اللعب ، وهو مصمم لتقسيم السلسلة إلى الرموز. يقسم الرمز المميز القياسي السلسلة إلى رموز وفقًا لعلامات الترقيم. في الخطوة الأخيرة ، يتم تصفية الرموز المميزة المستلمة ومعالجتها.
النظر في الاختلافات في الخطوات التي أصبحت مفيدة في حالتنا.
مرشحات شار
- وفقًا للخصائص الخاصة باللغة الروسية ، سيكون من المفيد معالجة حروف مثل th و e واستبدالها بـ و و ، على التوالي.
- أداء حرفي - نقل أحرف من الكتابة من قبل شخصيات من كتابة أخرى. في حالتنا ، هذا هو معالجة الأسماء المكتوبة باللغة اللاتينية أو مختلطة مع كل الحروف الهجائية. يمكن تنفيذ حرفي باستخدام المكون الإضافي ( ICU Analysis Plugin ) كعامل تصفية مميز (بمعنى أنه لا يعالج السلسلة الأصلية ، ولكن الرموز النهائية). قررنا كتابة حرفنا ، حيث لم نكن سعداء بالخوارزمية في البرنامج المساعد. تتمثل الفكرة في الاستعاضة أولاً عن تكرارات مجموعة الأحرف الأربعة (على سبيل المثال ، "SHCH => u") ، ثم تواجد الأحرف الثلاثة ، إلخ. الترتيب الذي تستخدم به عوامل تصفية الرموز أمر مهم ، لأن النتيجة ستعتمد على الترتيب.
- استبدال اللاتينية ج ، محاطة السيريلية ، مع الروسية ص. تم تحديد الحاجة إلى هذا بعد تحليل الأسماء في قاعدة البيانات - العديد من الأسماء في السيريلية شملت اللاتينية ج ، مما يعني السيريلية ج. عندما يكون الاسم باللغة اللاتينية تمامًا ، فإن اللاتينية C تعني السيريلية k أو c. لذلك ، قبل الحروف ، من الضروري استبدال الحرف c.
- إزالة أعداد كبيرة جدًا من الأسماء. أحيانًا في أسماء المنتجات ، يوجد رقم تعريف داخلي (مثل 3387522 K.Ts. Maslo podsoln.raf. 0.9l) ، والذي لا يحمل أي معنى في الحالة العامة.
- استبدال الفواصل بالنقاط. لماذا هذا مطلوب؟ بحيث تكون الأرقام ، على سبيل المثال ، محتوى الدهون في الحليب 3.2 و 3.2 ، مكافئًا
الرمز المميز
- الرمز المميز القياسي - يفصل الخطوط وفقًا لعلامات المسافات وعلامات الترقيم (على سبيل المثال ، "twix extra 2" -> "twix" ، "extra" ، "2")
- الرمز المميز لـ EdgeNGram - يقسم كل كلمة إلى رموز ذات طول معين (عادةً ما يكون مجموعة من الأرقام) ، بدءًا من الحرف الأول (على سبيل المثال ، N = [3 ، 6]: "twix extra 2" -> "twee" ، و "tweak" ، "Twix" ، "ex" ، "ext" ، "ext" ، "extra")
- الرمز المميز للأرقام - يختار الأرقام فقط من سلسلة من خلال البحث عن تعبير منتظم (على سبيل المثال ، "twix extra 2 4.5" -> "2" ، "4.5")
مرشح الرمز
- مرشح صغير
- مرشح Stamming - ينفذ خوارزمية stamming لكل رمز. التحفيز هو تحديد الشكل الأولي للكلمة (على سبيل المثال ، "الأرز" -> "الأرز")
- التحليل الصوتي. من الضروري تقليل تأثير الأخطاء المطبعية والطرق المختلفة لكتابة الكلمة نفسها على نتائج البحث. يوضح الجدول مختلف الخوارزميات المتاحة للتحليل الصوتي ونتائج عملها في الحالات الصعبة. في الحالة الأولى (شامبو / شامبانيا / شامبينون / شامبيون) يتم تحديد النجاح من خلال توليد ترميزات مختلفة ، في البقية - هي نفسها.

نموذج التشابه
مطلوب نموذج الصلة من أجل تحديد إلى أي مدى يؤثر تزامن رمز مميز على مدى ملاءمة الكائن من قاعدة البيانات فيما يتعلق بالطلب. لنفترض ما إذا كان الرمز المميز في الطلب والمنتج من قاعدة البيانات يطابقان - هذا بالتأكيد ليس سيئًا ، لكنه لا يذكر سوى القليل عن مدى توافق المنتج مع الطلب. وبالتالي ، فإن تزامن الرموز المختلفة يحمل قيمًا مختلفة. من أجل أخذ هذا في الاعتبار ، هناك حاجة إلى نموذج الملاءمة. يوفر مرونة العديد من النماذج المختلفة. إذا كنت تفهمها حقًا ، فيمكنك اختيار نموذج محدد ومناسب جدًا لحالة معينة. يمكن أن يعتمد الاختيار على عدد الكلمات المستخدمة بشكل متكرر (مثل الرمز المميز لنفسه) ، وتقييم أهمية الرموز الطويلة (يعد يعني أفضل؟ أسوأ؟ لا يهم؟) ، ما هي النتائج التي نريد أن نراها في النهاية ، إلخ. يمكن أن تكون أمثلة النماذج المقترحة في Flex (TF-IDF) (النموذج الأبسط والأكثر قابلية للفهم) ، Okapi BM25 (TF-IDF المحسن ، النموذج الافتراضي) ، الانحراف عن العشوائية ، التباعد عن الاستقلال ، إلخ. كل نموذج لديه أيضا خيارات قابلة للتخصيص. بعد عدة تجارب على النموذج ، أظهر النموذج الافتراضي Okapi BM25 أفضل نتيجة ، ولكن مع معلمات مختلفة عن تلك المحددة مسبقًا.
باستخدام الفئات
أثناء العمل مع البحث ، أصبحت المعلومات الإضافية المهمة جدًا حول المنتج - الفئة الخاصة به - متاحة. يمكنك قراءة المزيد حول كيفية تطبيق التصنيف في المقالة ، كما أفهمها ، أنا آكل الكثير من الحلويات ، أو تصنيف البضائع عن طريق التحقق في التطبيق . حتى ذلك الحين ، اعتمدنا في بحثنا فقط على مقارنة بين أسماء المنتجات ، والآن أصبح من الممكن مقارنة فئة الطلب والمنتجات في قاعدة البيانات.
الخيارات الممكنة لاستخدام هذه المعلومات هي تطابق إلزامي في حقل الفئة (منسق كمرشح للنتائج) ، وهي ميزة إضافية في شكل نقاط للمنتجات التي لها نفس الفئة (كما في حالة الأرقام) وترتيب النتائج حسب الفئة (المطابقة الأولى ، ثم جميعها الأخرى). بالنسبة لحالتنا ، فإن الخيار الأخير يعمل بشكل أفضل. هذا لأن خوارزمية التصنيف الخاصة بنا جيدة جدًا لاستخدام الطريقة الثانية ، وليست جيدة بما يكفي لاستخدام الأولى. نحن واثقون بدرجة كافية في الخوارزمية ونريد أن تكون مطابقة الفئات ميزة كبيرة. في حالة إضافة نقاط إضافية إلى السرعة (الطريقة الثانية) ، ستصعد البضائع التي تحمل نفس الفئة إلى القائمة ، ولكنها ستخسر بعض السلع الأكثر مطابقةً مع الاسم. ومع ذلك ، فإن الطريقة الأولى لا تناسبنا أيضًا ، لأن الأخطاء في التصنيف ما زالت ممكنة. في بعض الأحيان قد يحتوي الطلب على معلومات غير كافية لتحديد الفئة بشكل صحيح ، أو أن هناك عددًا قليلًا جدًا من المنتجات في هذه الفئة في نصف قطر المستخدم المباشر. في هذه الحالة ، ما زلنا نريد عرض النتائج بفئة مختلفة ، ولكن لا تزال ذات صلة حسب اسم المنتج.
الطريقة الثانية جيدة أيضًا لأنها لا "تفسد" سرعة المنتجات نتيجة للبحث ، وتسمح لك بمواصلة استخدام الحد الأدنى للسرعة المحسوبة دون عقبات.
يمكن رؤية التنفيذ المحدد لهذا النوع في الاستعلام النهائي.
النموذج النهائي
تضمن اختيار نموذج البحث النهائي إنشاء محركات بحث مختلفة وتقييمها ومقارنتها. في معظم الأحيان ، كانت المقارنة تستند إلى أحد المعلمات. لنفترض في حالة واحدة محددة أننا نحتاج إلى حساب أفضل حجم لرمز مميز لـ edgeNgram (أي ، اختيار النطاق الأكثر فعالية من N). للقيام بذلك ، أنشأنا محركات البحث نفسها مع اختلاف واحد فقط في حجم هذا النطاق. بعد ذلك ، كان من الممكن تحديد أفضل قيمة لهذه المعلمة.
تم تقييم النماذج باستخدام مقياس nDCG (الكسب التراكمي المخصوم المعدل) ، وهو مقياس لتقييم جودة التصنيف. تم إرسال طلبات البحث المحددة مسبقًا إلى كل نموذج بحث ، وبعد ذلك تم حساب مقياس nDCG استنادًا إلى نتائج البحث المستلمة.
المحللون الذين دخلوا النموذج النهائي:



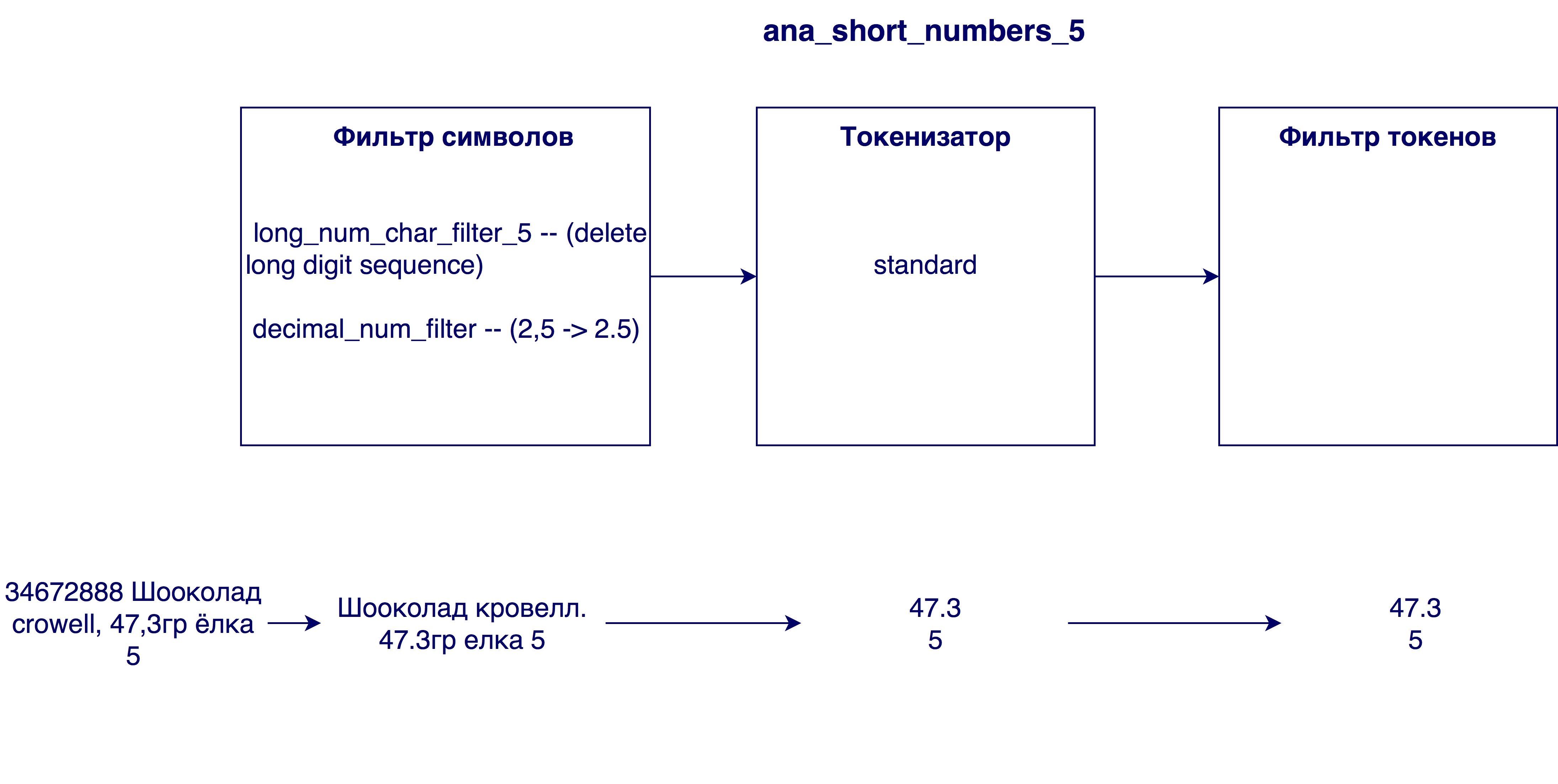
تم اختيار النموذج الافتراضي (Okapi - BM25) مع المعلمة b = 0.5 كنموذج الصلة. القيمة الافتراضية هي 0.75. تُظهر هذه المعلمة إلى أي مدى يقوم طول اسم المنتج بتطبيع متغير tf (تردد المدى). يعمل عدد أصغر في حالتنا بشكل أفضل ، لأن الاسم الطويل لا يؤثر في كثير من الأحيان على أهمية كلمة واحدة. بمعنى أن كلمة "شوكولاتة" في اسم "شوكولاتة بالبندق المسحوق في مجموعة من 25 قطعة" لا تفقد قيمتها من حقيقة أن الاسم طويل بما فيه الكفاية.
يبدو الاستعلام النهائي كالتالي:
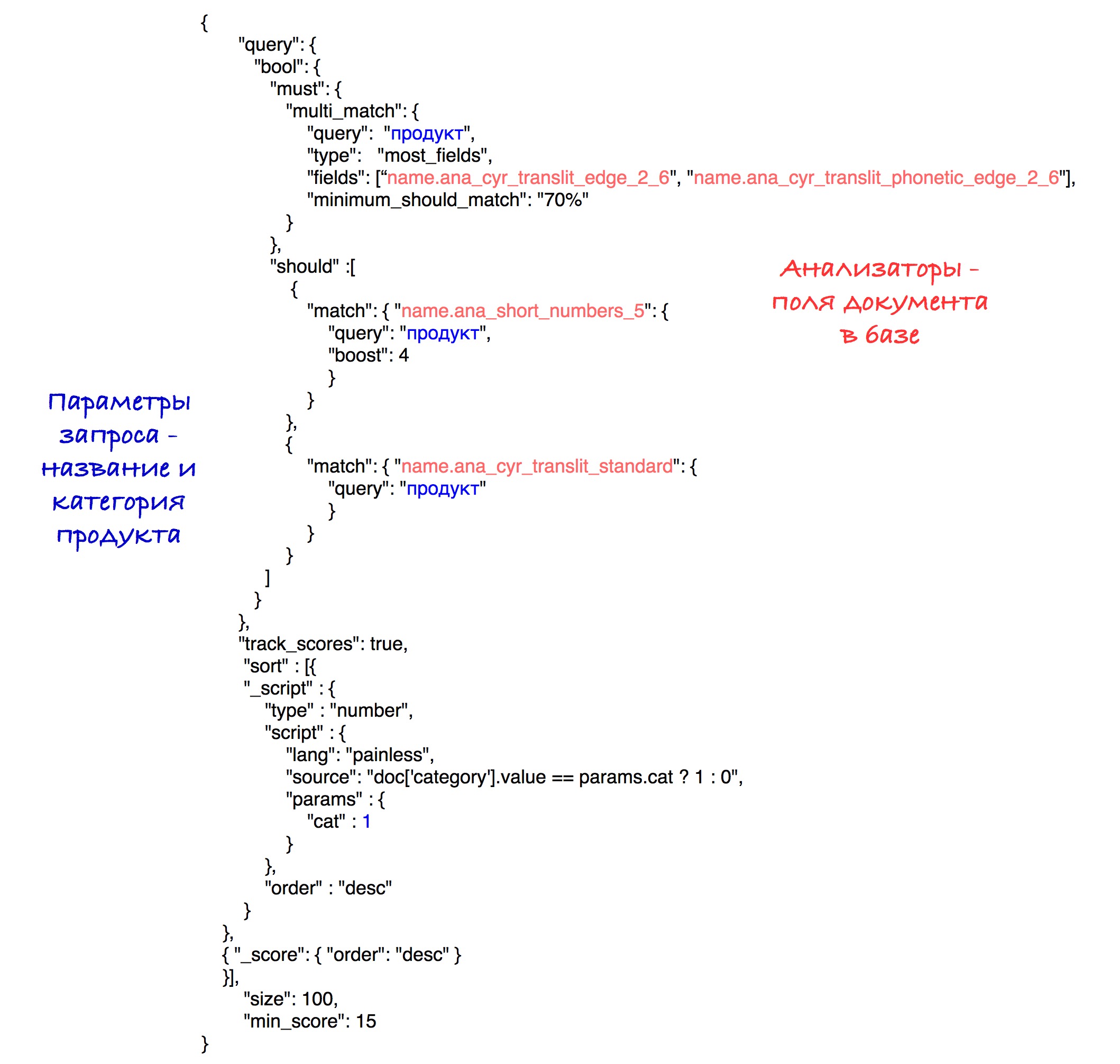
من الناحية التجريبية ، تم الكشف عن أفضل مزيج من أجهزة التحليل والأوزان.
نتيجة الفرز ، تنتقل المنتجات التي تحمل نفس الفئة إلى بداية النتائج ، ثم جميع المنتجات الأخرى. يتم تخزين الفرز حسب عدد النقاط (السرعة) داخل كل مجموعة فرعية.
للبساطة ، يتم تعيين الحد الأقصى للسرعة على 15 في هذا الطلب ، على الرغم من أننا في نظامنا نستخدم المعلمة المحسوبة التي تم وصفها مسبقًا.
في المستقبل
هناك أفكار حول تحسين البحث عن طريق حل واحدة من أكثر المشاكل المحرجة في خوارزمية لدينا ، والتي هي وجود مليون وطريقة مختلفة واحدة لتقصير كلمة من 5 أحرف. يمكن حلها عن طريق المعالجة الأولية للأسماء من أجل الكشف عن الاختصارات. إحدى طرق حل هذه المشكلة هي محاولة مقارنة الاسم المختصر من قاعدة البيانات الخاصة بنا بأحد الأسماء من قاعدة البيانات بالأسماء الكاملة "الصحيحة". هذا القرار يواجه عقبات محددة ، لكنه يبدو تغييرا واعدا.