مرحبا مرة أخرى!
في شهر ديسمبر ، سنبدأ التدريب لمجموعة
البيانات التالية ، بحيث يكون هناك المزيد والمزيد من الدروس المفتوحة وغيرها من الأنشطة. على سبيل المثال ، في اليوم الآخر ، تم عقد ندوة عبر الإنترنت تحت اسم طويل "هندسة الميزات على مثال مجموعة بيانات Titanic الكلاسيكية". قام
بإدارته ألكساندر سيزوف ، وهو مطور خبير ، دكتوراه ، وخبير في التعليم الآلي / العميق ، ومشارك في العديد من المشاريع التجارية الدولية المتعلقة بالذكاء الاصطناعي وتحليل البيانات.
استغرق درس مفتوح حوالي ساعة ونصف. أثناء الندوة عبر الإنترنت ، تحدث المعلم عن اختيار الميزات ، وتحويل بيانات المصدر (الترميز ، والقياس) ، وتحديد المعلمات ، وتدريب النموذج ، وأكثر من ذلك بكثير. خلال الدرس ، عرض على المشاركين دفتر ملاحظات Jupyter. من أجل العمل ، استخدمنا البيانات المفتوحة من منصة
Kaggle (مجموعة البيانات الكلاسيكية حول تيتانيك ، والتي بدأ الكثيرون بالتعرف على علوم البيانات). نقدم أدناه مقطع فيديو وملف للحدث السابق ، ويمكنك
هنا التقاط العرض التقديمي والرموز في كمبيوتر محمول لكوكب المشتري.
اختيار الميزة
تم اختيار المظهر ، رغم أنه كلاسيكي ، لكن لا يزال قاتمًا بعض الشيء. على وجه الخصوص ، كان من الضروري حل مشكلة التصنيف الثنائي والتنبؤ من البيانات المتاحة ما إذا كان الراكب سينجو أم لا. تم تقسيم البيانات نفسها إلى عينتين التدريب والاختبار. المتغير الرئيسي هو البقاء على قيد الحياة (نجا / لم ينجو ؛ 0 = لا ، 1 = نعم).
إدخال بيانات التدريب:
- فئة التذاكر
- عمر وجنس الراكب ؛
- الحالة الاجتماعية (سواء كان هناك أقارب على متن الطائرة) ؛
- سعر التذكرة
- رقم المقصورة
- ميناء الانطلاق.
كما ترى ، تختلف أنواع المتغيرات: عددية ، نصية. من هذا المشكال ، كان من الضروري تشكيل مجموعة بيانات للتدريب النموذجي القادم.
نحن نلخص:
- train.csv - مجموعة التدريب - مجموعة بيانات التدريب. الجواب معروف فيها - البقاء على قيد الحياة - علامة ثنائية 0 (لم تنجو) / 1 (نجت) ؛
- test.csv - مجموعة الاختبار - مجموعة بيانات الاختبار. الجواب غير معروف. هذه عينة لإرسالها إلى النظام الأساسي kaggle لحساب قياس جودة النموذج ؛
- الجندرة_السابق- csv مثال على تنسيق البيانات المراد إرسالها إلى kaggle.
خوارزمية العمل
- تم العمل على مراحل:
- تحليل البيانات من train.csv.
- معالجة القيم المفقودة.
- التحجيم.
- ترميز الميزات الفئوية.
- بناء نموذج واختيار المعلمات ، واختيار أفضل نموذج على البيانات المحولة من train.csv.
- تحول طريقة التثبيت والنموذج.
- تطبيق نفس التحويلات على test.csv باستخدام خط أنابيب.
- تطبيق النموذج على test.csv.
- حفظ ملف نتائج التطبيق بالتنسيق نفسه كما في الجندرة_السابق. csv.
- إرسال النتائج إلى منصة kaggle.
الجزء العملي للندوةأول ما يجب القيام به هو قراءة مجموعة البيانات وعرض بياناتنا على الشاشة:
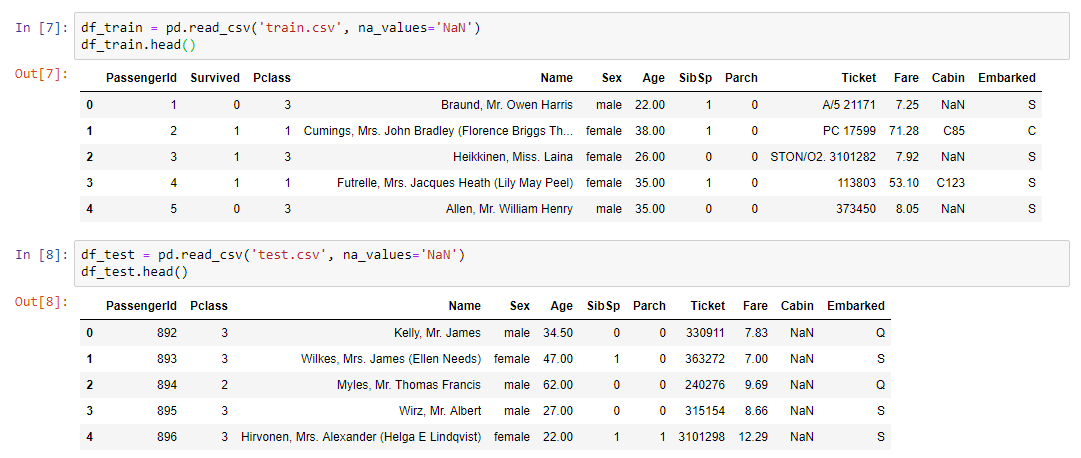
لتحليل البيانات ، تم استخدام مكتبة ملفات تعريف معروفة ولكنها مفيدة إلى حد ما:
pandas_profiling.ProfileReport(df_train)أكثر على التنميطتقوم هذه المكتبة بكل ما يمكن القيام به بشكل مسبق دون معرفة تفاصيل البيانات. على سبيل المثال ، اعرض إحصائيات عن البيانات (عدد المتغيرات ونوعها ، وعدد الصفوف ، والقيم المفقودة ، وما إلى ذلك). علاوة على ذلك ، يتم تقديم إحصائيات منفصلة لكل متغير بحد أدنى وحد أقصى ، ورسم بياني للتوزيع ومعاملات أخرى.
كما تعلمون ، لصنع نموذج جيد ، تحتاج إلى الخوض في العملية التي نحاول محاكاةها ، وفهم ما هي السمات الرئيسية. علاوة على ذلك ، ليس هناك ما هو مطلوب في بياناتنا دائمًا ، وبصورة أكثر دقة ، لا يوجد أبدًا أي شيء ضروري تقريبًا ، حيث يتم تحديد عمليتنا وتحديدها تمامًا. كقاعدة عامة ، نحتاج دائمًا إلى الجمع بين شيء ما ، وربما إضافة ميزات إضافية غير ممثلة في مجموعة البيانات (على سبيل المثال ، توقعات الطقس). من أجل فهم العملية التي نحتاج إلى تحليل البيانات ، والتي يمكن القيام بها باستخدام مكتبة ملفات التعريف.
القيم المفقودةالخطوة التالية هي حل مشكلة القيم المفقودة ، لأنه في معظم الحالات لا يتم ملء البيانات بالكامل.
الحلول التالية متوفرة لهذه المشكلة:
- حذف الصفوف ذات القيم المفقودة (ضع في اعتبارك أنه يمكنك فقد بعض القيم المهمة) ؛
- حذف علامة (ذات صلة إذا كانت هناك بيانات قليلة جدًا عليها) ؛
- استبدال القيم المفقودة بشيء آخر (متوسط ، متوسط ...).
مثال للتحويل البسيط باستخدام طريقة fillna ، التي تعيّن قيم متغير الوسيط فقط للخلايا التي لم يتم ملؤها:

بالإضافة إلى ذلك ، أظهر المعلم أمثلة على استخدام Imputer وخطوط الأنابيب.
تحجيم الميزةيعتمد تشغيل النموذج والقرار النهائي على حجم الميزات. الحقيقة هي أنها ليست حقيقة أن أي ميزة ذات مقياس أكبر أكثر أهمية من ميزة ذات مقياس أصغر. لهذا السبب يحتاج النموذج إلى إرسال ميزات يتم تغيير حجمها بشكل متماثل ، أي أن يكون له نفس وزن النموذج.
هناك طرق مختلفة للتحجيم ، ومع ذلك ، فإن شكل الدرس المفتوح يسمح بالنظر في اثنين منهم فقط بمزيد من التفصيل:
 مجموعات الميزة
مجموعات الميزةتتيح لك مجموعة من الميزات الموجودة التي تستخدم العمليات الحسابية (المجموع ، الضرب ، القسمة) الحصول على أي ميزة تجعل النموذج أكثر كفاءة. هذا ليس ناجحًا دائمًا ، ولا نعلم أي مجموعة ستوفر التأثير المطلوب ، ولكن الممارسة تدل على أنه من المنطقي المحاولة. من الملائم تطبيق تحويلات الميزات باستخدام خط الأنابيب.
الترميزلذلك ، لدينا بيانات من أنواع مختلفة: رقمية ونصية. حاليًا ، لا يمكن لمعظم النماذج الموجودة في السوق التعامل مع البيانات النصية. ونتيجة لذلك ، يجب تحويل جميع العلامات الفئوية (النصية) إلى تمثيل رقمي ، حيث يتم استخدام الترميز.
ترميز التسمية . هذه آلية يتم تنفيذها في إطار العديد من المكتبات التي يمكن استدعاؤها وتطبيقها:

يقوم ترميز التسمية بتعيين معرف فريد لكل قيمة فريدة. ناقص - نقدم الطلب في متغير معين لم يتم طلبه ، وهو أمر غير جيد.
OneHotEncoder. يتم توسيع القيم الفريدة لمتغير النص في شكل أعمدة يتم إضافتها إلى البيانات المصدر ، حيث يكون كل عمود متغيرًا ثنائيًا في شكل 0 و 1. هذا النهج خالٍ من العيوب في ترميز التسمية ، ولكن له ناقص خاص به: إذا كان هناك العديد من القيم الفريدة ، فنحن نضيف العديد من الأعمدة الفريدة وفي بعض الحالات ، تكون الطريقة غير قابلة للتطبيق (تنمو مجموعة البيانات أكثر من اللازم).
التدريب النموذجيبعد تنفيذ الخطوات المذكورة أعلاه ، يتم تجميع خط أنابيب نهائي مع مجموعة من جميع العمليات اللازمة. يكفي الآن أخذ مجموعة البيانات المصدر وتطبيق خط الأنابيب الناتج على هذه البيانات باستخدام عملية fit_transform:
x_train = vec.fit_transform(df_train)نتيجة لذلك ، نحصل على مجموعة بيانات x_train ، وهي جاهزة للاستخدام في النموذج. الشيء الوحيد الذي يجب فعله هو فصل قيمة المتغير المستهدف الخاص بنا حتى نتمكن من إجراء التدريب.
بعد ذلك ، حدد النموذج. كجزء من الويبينار ، اقترح المعلم انحدار لوجستي بسيط. تم تدريب النموذج باستخدام العملية المناسبة ، مما أدى إلى نموذج في شكل انحدار لوجستي مع بعض المعلمات:
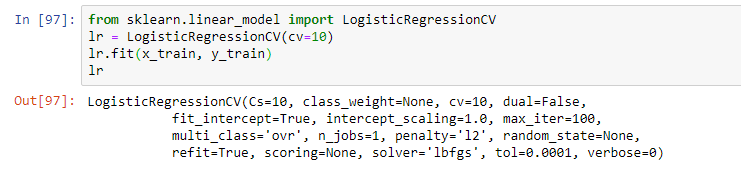
ومع ذلك ، في الممارسة العملية ، عادة ما تستخدم عدة نماذج يبدو أنها الأكثر فعالية. وغالبًا ما يكون الحل النهائي عبارة عن مزيج من هذه النماذج باستخدام أساليب التراص والنُهج الأخرى لتجميع النماذج (باستخدام نماذج متعددة داخل نفس النموذج المختلط).
بعد التدريب ، يمكن تطبيق النموذج على بيانات الاختبار ، وتقييم جودته في إطار بعض المقاييس. في حالتنا ، كانت الجودة داخل الدقة_ 0.8:

هذا يعني أنه في البيانات التي تم الحصول عليها ، يتم توقع المتغير بشكل صحيح في 80٪ من الحالات. بعد تلقي نتائج التدريب ، يمكننا إما تحسين النموذج (إذا كانت الدقة غير مرضية) ، أو المتابعة مباشرةً إلى التنبؤ.
كان هذا هو الموضوع الرئيسي للدرس ، لكن المعلم تحدث بمزيد من التفصيل عن ميزات النموذج في مهام مختلفة وأجاب على أسئلة من الجمهور. لذلك إذا كنت لا تريد أن تفوت أي شيء ، يمكنك مشاهدة الندوة الإلكترونية الكاملة إذا كنت مهتمًا بهذا الموضوع.
كما هو الحال دائمًا ، ننتظر تعليقاتك وأسئلتك التي يمكنك تركها هنا أو طرحها على
ألكساندر بالذهاب إليه في
يوم مفتوح.