عند إنشاء تذكرة في نظام إدارة المشاريع وتتبع المهام ، يسعد كل واحد منا أن يرى الشروط التقريبية للقرار الخاص بجاذبيتنا.
عند تلقي مجموعة من التذاكر الواردة ، يحتاج الشخص / الفريق إلى ترتيبها حسب الأولوية والوقت ، مما يتطلب حل كل استئناف.
كل هذا يسمح لك بتخطيط وقتك بشكل أكثر فعالية لكلا الطرفين.
تحت الخفض ، سأتحدث عن كيفية تحليل نماذج ML وتدريبها التي تتنبأ بالوقت المستغرق لحل التذاكر الصادرة لفريقنا.
أنا نفسي أعمل في منصب SRE في فريق يسمى LAB. نحن نتلقى مكالمات من كل من المطورين و QA فيما يتعلق بنشر بيئات اختبار جديدة ، وتحديثاتهم إلى أحدث إصدارات الإصدار ، والحلول لمختلف المشاكل التي تنشأ ، وأكثر من ذلك بكثير. هذه المهام غير متجانسة تمامًا ، ومن المنطقي ، تستغرق وقتًا مختلفًا لإكمالها. يوجد فريقنا لعدة سنوات وخلال هذه الفترة ، تمكنت قاعدة من الطلبات المتراكمة من التجميع. قررت تحليل هذه القاعدة ، وبناءً على ذلك ، بمساعدة التعلم الآلي ، صنع نموذجًا يتعامل مع التنبؤ بوقت الإغلاق المحتمل للنداء (التذكرة).
في عملنا ، نستخدم JIRA ، ومع ذلك ، فإن النموذج الذي أقدمه في هذه المقالة لا يوجد لديه رابط لمنتج معين - ليست مشكلة في الحصول على المعلومات اللازمة من أي قاعدة بيانات.
لذلك ، دعنا ننتقل من الأقوال إلى الأفعال.
تحليل البيانات الأولية
نقوم بتحميل كل ما نحتاجه ونعرض إصدارات الحزم المستخدمة.
شفرة المصدرimport warnings warnings.simplefilter('ignore') %matplotlib inline import matplotlib.pyplot as plt import pandas as pd import numpy as np import datetime from nltk.corpus import stopwords from sklearn.model_selection import train_test_split from sklearn.metrics import mean_absolute_error, mean_squared_error from sklearn.neighbors import KNeighborsRegressor from sklearn.linear_model import LinearRegression from datetime import time, date for package in [pd, np, matplotlib, sklearn, nltk]: print(package.__name__, 'version:', package.__version__)
pandas version: 0.23.4 numpy version: 1.15.0 matplotlib version: 2.2.2 sklearn version: 0.19.2 nltk version: 3.3
قم بتنزيل البيانات من ملف CSV. أنه يحتوي على معلومات حول التذاكر مغلقة خلال السنوات 1.5 الماضية. قبل كتابة البيانات إلى ملف ، تم معالجتها مسبقًا بقليل. على سبيل المثال ، تمت إزالة الفواصل والنقاط من حقول النص مع الوصف. ومع ذلك ، هذا هو المعالجة الأولية فقط وفي المستقبل سيتم مسح النص.
دعونا نرى ما هو في مجموعة البيانات الخاصة بنا. في المجموع ، حصلت 10783 تذاكر في ذلك.
شرح المجال| تم إنشاؤه | تاريخ إنشاء تذكرة ووقتها |
| حل | تاريخ ووقت إغلاق التذاكر |
| القرار_الوقت | عدد الدقائق المنقضية بين إنشاء وإغلاق تذكرة. ويعتبر الوقت التقويم ، ل لدى الشركة مكاتب في دول مختلفة ، تعمل في مناطق زمنية مختلفة ولا يوجد وقت محدد للإدارة بأكملها. |
| Engineer_N | أسماء المهندسين "المشفرة" (من أجل عدم إعطاء معلومات شخصية أو سرية عن غير قصد في المستقبل ، سيكون هناك القليل من البيانات "المشفرة" في المقالة ، والتي تمت إعادة تسميتها ببساطة). تحتوي هذه الحقول على عدد التذاكر في وضع "قيد التقدم" في وقت استلام كل تذكرة في الموعد المحدد. سوف أتطرق إلى هذه الحقول بشكل منفصل في نهاية المقال ، لأنه انهم يستحقون المزيد من الاهتمام. |
| المحال | الموظف الذي شارك في حل المشكلة. |
| Issue_type | نوع التذكرة. |
| البيئة | اسم بيئة عمل الاختبار التي تم صنع التذكرة من أجلها (قد تعني بيئة محددة أو الموقع ككل ، على سبيل المثال ، مركز بيانات). |
| الأولوية | أولوية التذكرة. |
| نوع العمل | نوع العمل المتوقع لهذه البطاقة (إضافة أو إزالة الخوادم ، وتحديث البيئة ، والعمل مع المراقبة ، وما إلى ذلك) |
| الوصف | الوصف |
| ملخص | عنوان التذكرة. |
| المراقبون | عدد الأشخاص الذين "يشاهدون" التذكرة ، أي يتلقون إشعارات البريد الإلكتروني لكل نشاط في التذكرة. |
| أصوات | عدد الأشخاص الذين "صوتوا" للتذكرة ، مما يدل على أهميتها واهتمامهم بها. |
| مراسل | الشخص الذي أصدر التذكرة. |
| Engineer_N_acation | ما إذا كان المهندس في إجازة وقت إصدار التذكرة. |
df.info()
<class 'pandas.core.frame.DataFrame'> Index: 10783 entries, ENV-36273 to ENV-49164 Data columns (total 37 columns): Created 10783 non-null object Resolved 10783 non-null object Resolution_time 10783 non-null int64 engineer_1 10783 non-null int64 engineer_2 10783 non-null int64 engineer_3 10783 non-null int64 engineer_4 10783 non-null int64 engineer_5 10783 non-null int64 engineer_6 10783 non-null int64 engineer_7 10783 non-null int64 engineer_8 10783 non-null int64 engineer_9 10783 non-null int64 engineer_10 10783 non-null int64 engineer_11 10783 non-null int64 engineer_12 10783 non-null int64 Assignee 10783 non-null object Issue_type 10783 non-null object Environment 10771 non-null object Priority 10783 non-null object Worktype 7273 non-null object Description 10263 non-null object Summary 10783 non-null object Watchers 10783 non-null int64 Votes 10783 non-null int64 Reporter 10783 non-null object engineer_1_vacation 10783 non-null int64 engineer_2_vacation 10783 non-null int64 engineer_3_vacation 10783 non-null int64 engineer_4_vacation 10783 non-null int64 engineer_5_vacation 10783 non-null int64 engineer_6_vacation 10783 non-null int64 engineer_7_vacation 10783 non-null int64 engineer_8_vacation 10783 non-null int64 engineer_9_vacation 10783 non-null int64 engineer_10_vacation 10783 non-null int64 engineer_11_vacation 10783 non-null int64 engineer_12_vacation 10783 non-null int64 dtypes: float64(12), int64(15), object(10) memory usage: 3.1+ MB
في المجموع ، لدينا 10 حقول "كائن" (أي ، تحتوي على قيمة نصية) و 27 حقلًا رقميًا.
بادئ ذي بدء ، ابحث فورًا عن الانبعاثات في بياناتنا. كما ترون ، هناك مثل هذه التذاكر التي يتم فيها تقدير وقت اتخاذ القرار بملايين الدقائق. من الواضح أن هذه ليست معلومات ذات صلة ، فإن هذه البيانات سوف تتداخل فقط مع بناء النموذج. لقد وصلوا إلى هنا ، نظرًا لأن عملية جمع البيانات من JIRA تم إجراؤها بواسطة استعلام في الحقل "حل" وليس "تم الإنشاء". بناءً على ذلك ، فإن التذاكر التي كانت مغلقة في السنوات الخمس ونصف الماضية وصلت إلى هنا ، لكن كان من الممكن فتحها قبل ذلك بكثير. لقد حان الوقت للتخلص منها. سنتجاهل تلك التذاكر التي تم إنشاؤها قبل 1 يونيو 2017. سيكون لدينا 9493 تذاكر متبقية.
بالنسبة للأسباب - أعتقد في كل مشروع أنه يمكنك بسهولة العثور على الطلبات التي تم تعليقها لبعض الوقت بسبب ظروف مختلفة وغالبًا ما يتم إغلاقها ليس عن طريق حل المشكلة نفسها ، ولكن عن طريق "انتهاء صلاحية نظام التقادم".
شفرة المصدر df[['Created', 'Resolved', 'Resolution_time']].sort_values('Resolution_time', ascending=False).head()

شفرة المصدر df = df[df['Created'] >= '2017-06-01 00:00:00'] print(df.shape)
(9493, 33)
لذلك ، دعونا نبدأ في النظر في ما يمكن أن نجدها مثيرة للاهتمام في بياناتنا. للبدء ، دعنا نكتشف أبسطها - أكثر البيئات شيوعًا بين تذاكرنا ، و "المراسلين" الأكثر نشاطًا وما شابه.
شفرة المصدر df.describe(include=['object'])

شفرة المصدر df['Environment'].value_counts().head(10)
Environment_104 442 ALL 368 Location02 367 Environment_99 342 Location03 342 Environment_31 322 Environment_14 254 Environment_1 232 Environment_87 227 Location01 202 Name: Environment, dtype: int64
شفرة المصدر df['Reporter'].value_counts().head()
Reporter_16 388 Reporter_97 199 Reporter_04 147 Reporter_110 145 Reporter_133 138 Name: Reporter, dtype: int64
شفرة المصدر df['Worktype'].value_counts()
Support 2482 Infrastructure 1655 Update environment 1138 Monitoring 388 QA 300 Numbers 110 Create environment 95 Tools 62 Delete environment 24 Name: Worktype, dtype: int64
شفرة المصدر df['Priority'].value_counts().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14, title=' ');
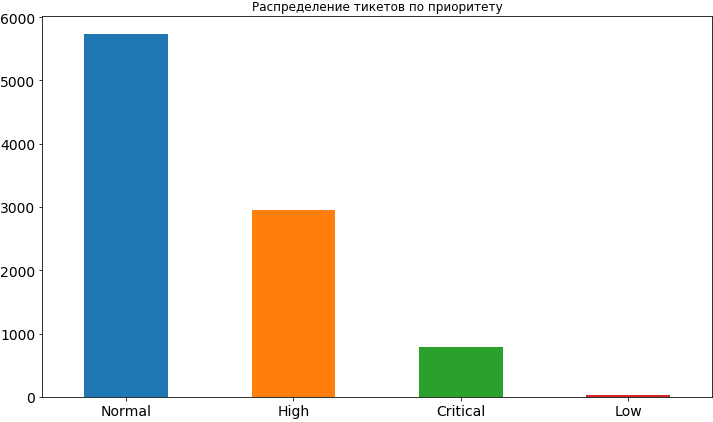
حسنًا ، شيء تعلمناه بالفعل. في معظم الأحيان ، تكون أولوية التذاكر أمرًا طبيعيًا ، وحوالي مرتين تقريبًا أقل ارتفاعًا وأقل أهمية. نادرًا ما تكون هناك أولوية منخفضة ، على ما يبدو أن الناس يخشون كشفها ، معتقدين أنه في هذه الحالة سوف يتم تعليقها لفترة طويلة إلى حد ما في قائمة الانتظار وقد يتأخر وقت اتخاذ قرارها. في وقت لاحق ، عندما سنقوم بالفعل ببناء النموذج وتحليل نتائجه ، سنرى أن هذه المخاوف قد لا أساس لها من الصحة ، لأن الأولوية المنخفضة تؤثر فعليًا على الإطار الزمني للمهمة ، وبالطبع لا في اتجاه التسارع.
من الأعمدة الخاصة بالبيئات الأكثر شيوعًا والمراسلين الأكثر نشاطًا ، نرى أن Reporter_16 يتقدم بهامش واسع ، ويأتي Environment_104 في المرتبة الأولى في البيئات. حتى لو لم تكن قد خمنت بعد ، فسوف أخبركم بسرٍ قليل - هذا المراسل من الفريق العامل في هذه البيئة بالذات.
دعنا نرى نوع البيئة التي تأتي منها التذاكر الأكثر أهمية.
شفرة المصدر df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]
'Environment_91'
سنقوم الآن بطباعة معلومات حول عدد التذاكر ذات الأولويات المختلفة التي تأتي من نفس البيئة "الحرجة".
شفرة المصدر df[df['Environment'] == df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]]['Priority'].value_counts()
High 62 Critical 57 Normal 46 Name: Priority, dtype: int64
دعونا نلقي نظرة على وقت تنفيذ التذكرة في سياق الأولويات. على سبيل المثال ، من الجيد ملاحظة أن متوسط وقت تشغيل التذكرة ذات الأولوية المنخفضة يزيد عن 70 ألف دقيقة (حوالي 1.5 شهر). كما يمكن بسهولة تتبع اعتماد وقت تنفيذ التذاكر على أولويته.
شفرة المصدر df.groupby(['Priority'])['Resolution_time'].describe()
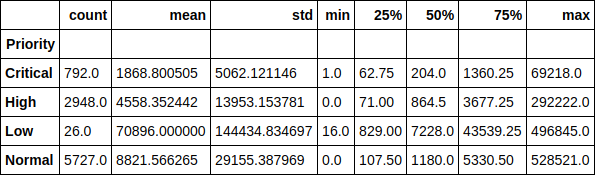
أو هنا كرسم بياني ، القيمة المتوسطة. كما ترى ، لم تتغير الصورة كثيرًا ، وبالتالي ، فإن الانبعاثات لا تؤثر بشكل كبير على التوزيع.
شفرة المصدر df.groupby(['Priority'])['Resolution_time'].median().sort_values().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14);

الآن دعونا نلقي نظرة على متوسط وقت حل التذاكر لكل من المهندسين ، وهذا يتوقف على عدد التذاكر التي كان المهندس في ذلك الوقت. في الواقع ، هذه الرسوم البيانية ، لدهشتي ، لا تظهر أي صورة واحدة. بالنسبة للبعض ، يزيد وقت التنفيذ مع زيادة التذاكر الحالية في العمل ، بينما بالنسبة لبعض هذه العلاقة تكون عكسية. بالنسبة للبعض ، الإدمان لا يمكن تتبعه على الإطلاق.
ومع ذلك ، وبالنظر إلى الأمام مرة أخرى ، أقول إن وجود هذه الميزة في مجموعة البيانات زاد من دقة النموذج بأكثر من مرتين وهناك بالتأكيد تأثير على وقت التنفيذ. نحن فقط لا نراه. ويرى النموذج.
شفرة المصدر engineers = [i.replace('_vacation', '') for i in df.columns if 'vacation' in i] cols = 2 rows = int(len(engineers) / cols) fig, axes = plt.subplots(nrows=rows, ncols=cols, figsize=(16,24)) for i in range(rows): for j in range(cols): df.groupby(engineers[i * cols + j])['Resolution_time'].mean().plot(kind='bar', rot=0, ax=axes[i, j]).set_xlabel('Engineer_' + str(i * cols + j + 1)) del cols, rows, fig, axes
دعنا نجعل مصفوفة صغيرة من التفاعل الثنائي للميزات التالية: وقت حل التذاكر ، وعدد الأصوات وعدد المراقبين. مع مكافأة قطرية ، لدينا توزيع كل سمة.
من المثير للاهتمام ، يمكن للمرء أن يرى الاعتماد على تقليل وقت حل التذاكر على العدد المتزايد من المراقبين. كما يُرى أن الأشخاص ليسوا نشطين للغاية في استخدام الأصوات.
شفرة المصدر pd.scatter_matrix(df[['Resolution_time', 'Watchers', 'Votes']], figsize=(15, 15), diagonal='hist');
لذلك ، أجرينا تحليلًا أوليًا صغيرًا للبيانات ، ورأينا التبعيات الحالية بين السمة الهدف ، وهو الوقت الذي يستغرقه حل التذكرة ، وعلامات مثل عدد الأصوات للتذكرة ، وعدد "المراقبين" وراءها وأولويتها. نحن نمضي قدما.
بناء نموذج. بناء علامات
لقد حان الوقت للانتقال إلى بناء النموذج نفسه. لكن أولاً ، نحتاج إلى تحويل ميزاتنا إلى نموذج يمكن فهمه من خلال النموذج. أي تتحلل علامات قاطعة في ناقلات متفرقة والتخلص من الزائدة. على سبيل المثال ، لا نحتاج إلى الحقول مع الوقت الذي تم فيه إنشاء التذكرة وإغلاقها في النموذج ، بالإضافة إلى حقل Assignee ، لأن سنستخدم هذا النموذج في النهاية للتنبؤ بوقت تنفيذ البطاقة التي لم يتم تخصيصها لأي شخص ("تم اغتياله").
علامة الهدف ، كما ذكرت للتو ، هي الوقت المناسب لحل المشكلة بالنسبة لنا ، لذلك نعتبرها متجهًا منفصلًا ونحذفها أيضًا من مجموعة البيانات العامة. بالإضافة إلى ذلك ، كانت بعض الحقول فارغة بسبب حقيقة أن المراسلين لا يقومون دائمًا بملء حقل الوصف عند إصدار التذكرة. في هذه الحالة ، تقوم مجموعات الباندا بتعيين قيمها على NaN ، نحن فقط نستبدلها بسلسلة فارغة.
شفرة المصدر y = df['Resolution_time'] df.drop(['Created', 'Resolved', 'Resolution_time', 'Assignee'], axis=1, inplace=True) df['Description'].fillna('', inplace=True) df['Summary'].fillna('', inplace=True)
نحن نتحلل العلامات الفئوية في ناقلات متفرق ( ترميز واحد ساخن ). حتى نلمس الحقول مع وصف وجدول محتويات التذكرة. سوف نستخدمها بشكل مختلف قليلا. تحتوي بعض أسماء المراسلين على [X]. لذلك فإن JIRA تميز الموظفين غير النشطين الذين لم يعودوا يعملون في الشركة. قررت تركها بين العلامات ، على الرغم من أنه من الممكن مسح البيانات منها ، لأنه في المستقبل ، عند استخدام النموذج ، لن نرى تذاكر من هؤلاء الموظفين.
شفرة المصدر def create_df(dic, feature_list): out = pd.DataFrame(dic) out = pd.concat([out, pd.get_dummies(out[feature_list])], axis = 1) out.drop(feature_list, axis = 1, inplace = True) return out X = create_df(df, df.columns[df.dtypes == 'object'].drop(['Description', 'Summary'])) X.columns = X.columns.str.replace(' \[X\]', '')
والآن سنتعامل مع حقل الوصف في التذكرة. سنعمل على ذلك باستخدام واحدة من أبسط الطرق - سنجمع كل الكلمات المستخدمة في تذاكرنا ، ونحسب أكثرها شيوعًا ، ونتجاهل الكلمات "الإضافية" - تلك الكلمات التي من الواضح أنها لا يمكن أن تؤثر على النتيجة ، على سبيل المثال ، الكلمة "من فضلك" (من فضلك - تتم جميع الاتصالات في JIRA بشكل صارم باللغة الإنجليزية) ، وهو الأكثر شعبية. نعم ، هؤلاء هم شعبنا المهذب.
نقوم أيضًا بإزالة " كلمات التوقف " ، وفقًا لمكتبة nltk ، ونحذف نص الأحرف غير الضرورية بشكل أكثر دقة. اسمحوا لي أن أذكرك بأن هذا هو أبسط شيء يمكن القيام به مع النص. نحن لا " نختم " الكلمات ، بل يمكنك أيضًا حساب أكثر عدد N من الكلمات شيوعًا ، لكننا سنقتصر على ذلك.
شفرة المصدر all_words = np.concatenate(df['Description'].apply(lambda s: s.split()).values) stop_words = stopwords.words('english') stop_words.extend(['please', 'hi', '-', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '(', ')', '=', '{', '}']) stop_words.extend(['h3', '+', '-', '@', '!', '#', '$', '%', '^', '&', '*', '(for', 'output)']) stop_symbols = ['=>', '|', '[', ']', '#', '*', '\\', '/', '->', '>', '<', '&'] words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)]
بعد كل هذا ، حصلنا على كائن pandas.Series الذي يحتوي على جميع الكلمات المستخدمة. دعونا نلقي نظرة على أكثرهم شعبية ونأخذ الخمسين الأولى من القائمة لاستخدامها كعلامات. لكل تذكرة ، سنرى ما إذا كانت هذه الكلمة مستخدمة في الوصف ، وإذا كان الأمر كذلك ، فضع 1 في العمود المقابل ، وإلا 0.
شفرة المصدر usefull_words = list(words_series.value_counts().head(50).index) print(usefull_words[0:10])
['error', 'account', 'info', 'call', '{code}', 'behavior', 'array', 'update', 'env', 'actual']
الآن في مجموعة البيانات العامة الخاصة بنا ، سننشئ أعمدة منفصلة للكلمات التي اخترناها. على هذا يمكنك التخلص من حقل الوصف نفسه.
شفرة المصدر for word in usefull_words: X['Description_' + word] = X['Description'].str.contains(word).astype('int64') X.drop('Description', axis=1, inplace=True)
سنفعل الشيء نفسه بالنسبة لحقل عنوان التذاكر.
شفرة المصدر all_words = np.concatenate(df['Summary'].apply(lambda s: s.split()).values) words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)] usefull_words = list(words_series.value_counts().head(50).index) for word in usefull_words: X['Summary_' + word] = X['Summary'].str.contains(word).astype('int64') X.drop('Summary', axis=1, inplace=True)
دعونا نرى ما انتهى بنا في مصفوفة الميزة X وموجه الاستجابة y.
((9493, 1114), (9493,))
سنقوم الآن بتقسيم هذه البيانات إلى عينة تدريب (تدريب) وعينة اختبار بنسبة النسبة المئوية 75/25. إجمالي لدينا 7119 أمثلة سنعتمد عليها ، و 2374 سنعمل على تقييم نماذجنا. وزاد البعد من مصفوفة لدينا من سمات إلى 1114 بسبب وضع العلامات الفئوية.
شفرة المصدر X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.25, random_state=17) print(X_train.shape, X_holdout.shape)
((7119, 1114), (2374, 1114))
نحن ندرب النموذج.
الانحدار الخطي
لنبدأ مع الانحدار الخطي الأخف و (المتوقع) الأقل دقة. سنقوم بتقييم كل من الدقة في بيانات التدريب ، والعينة المتأخرة (تعليق) - البيانات التي لم يراها النموذج.
في حالة الانحدار الخطي ، يُظهر النموذج المقبول أكثر أو أقل نفسه على بيانات التدريب ، لكن دقة العينة المتأخرة منخفضة بشكل كبير. أسوأ بكثير من توقع المتوسط المعتاد لجميع التذاكر.
تحتاج هنا إلى أخذ استراحة قصيرة ومعرفة كيفية تقييم النموذج للجودة باستخدام طريقة التسجيل.
يتم التقييم بواسطة معامل التحديد :
أين هي النتيجة التي تنبأ بها النموذج - متوسط قيمة العينة بأكملها.
لن نتطرق إلى المعامل كثيرًا الآن. نلاحظ فقط أنه لا يعكس تمامًا دقة النموذج الذي يهمنا. لذلك ، في الوقت نفسه ، سوف نستخدم Mean Error Absolute Error (MAE) لتقييمه والاعتماد عليه.
شفرة المصدر lr = LinearRegression() lr.fit(X_train, y_train) print('R^2 train:', lr.score(X_train, y_train)) print('R^2 test:', lr.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(lr.predict(X_train), y_train)) print('MAE test', mean_absolute_error(lr.predict(X_holdout), y_holdout))
R^2 train: 0.3884389470220214 R^2 test: -6.652435243123196e+17 MAE train: 8503.67256637168 MAE test: 1710257520060.8154
زيادة التدرج
حسنا ، أين بدونها ، دون زيادة التدرج؟ دعونا نحاول تدريب النموذج ونرى ما سيحدث. سوف نستخدم XGBoost سيئة السمعة لهذا الغرض. لنبدأ بالإعدادات القياسية لبرمجة المعلومات.
شفرة المصدر import xgboost xgb = xgboost.XGBRegressor() xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.5138516547636054 R^2 test: 0.12965507684512545 MAE train: 7108.165167471887 MAE test: 8343.433260957032
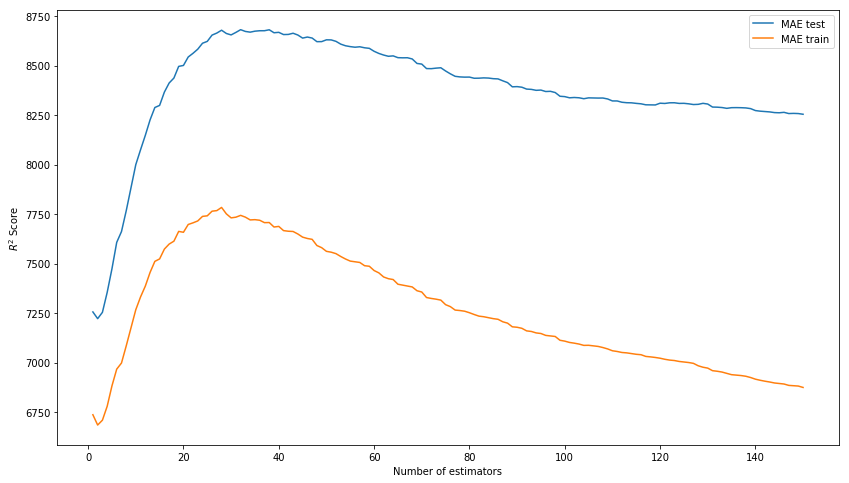
النتيجة من خارج منطقة الجزاء لم تعد سيئة. دعنا نحاول تصميم النموذج من خلال تحديد المعلمات الفائقة: n_estimators و learning_rate و max_depth. ونتيجة لذلك ، فإننا نركز على قيم 150 و 0.1 و 3 على التوالي ، حيث نوضح أفضل نتيجة لعينة الاختبار في غياب التدريب الزائد للنموذج على بيانات التدريب.
نختار n_estimators* بدلاً من R ^ 2 يجب أن تكون النتيجة في الصورة هي MAE.
xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1,151) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Number of estimators') plt.ylabel('$R^2 Score$') plt.legend(loc='best') plt.show();
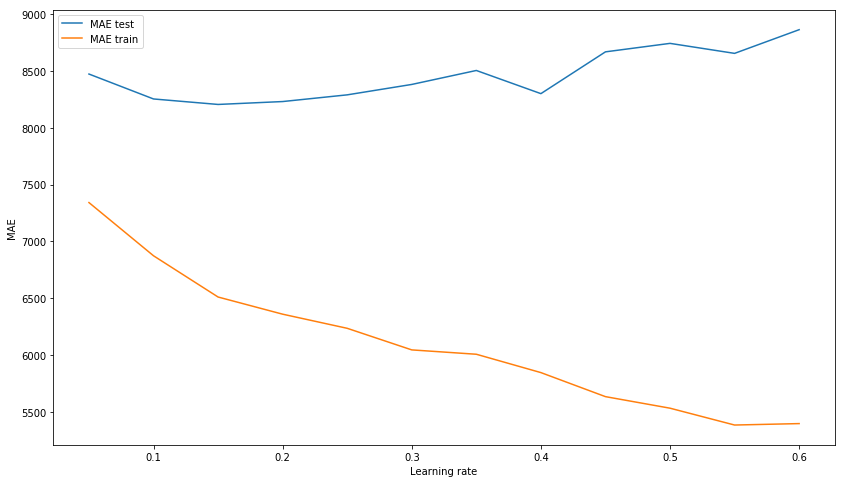
نختار التعلم xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(0.05, 0.65, 0.05) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Learning rate') plt.ylabel('MAE') plt.legend(loc='best') plt.show();
نختار max_depth xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1, 11) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Maximum depth') plt.ylabel('MAE') plt.legend(loc='best') plt.show();

الآن سوف نقوم بتدريب النموذج مع المعلمات المختارة المختارة.
شفرة المصدر xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=3) xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.6745967150462303 R^2 test: 0.15415143189670344 MAE train: 6328.384400466232 MAE test: 8217.07897417256
النتيجة النهائية مع المعلمات المحددة وأهمية ميزة التصور - أهمية علامات وفقا للنموذج. في المقام الأول هو عدد مراقبي التذاكر ، ولكن بعد ذلك يذهب 4 مهندسين على الفور. تبعا لذلك ، يمكن أن تتأثر بشدة وقت العمل للتذكرة بقوة عن طريق توظيف مهندس. ومن المنطقي أن يكون وقت الفراغ لبعضهم أكثر أهمية. على الأقل لأن الفريق يضم مهندسين كبارًا ومتوسطًا (ليس لدينا صغار في الفريق). بالمناسبة ، مرة أخرى في السر ، فإن المهندس في المقام الأول (شريط البرتقال) هو حقًا أحد أكثر المهندسين خبرة في الفريق بأكمله. علاوة على ذلك ، فإن جميع هؤلاء المهندسين الأربعة لديهم بادئة عليا في مواقعهم. اتضح أن النموذج أكد هذا مرة أخرى.
شفرة المصدر features_df = pd.DataFrame(data=xgb.feature_importances_.reshape(1, -1), columns=X.columns).sort_values(axis=1, by=[0], ascending=False) features_df.loc[0][0:10].plot(kind='bar', figsize=(16, 8), rot=75, fontsize=14);
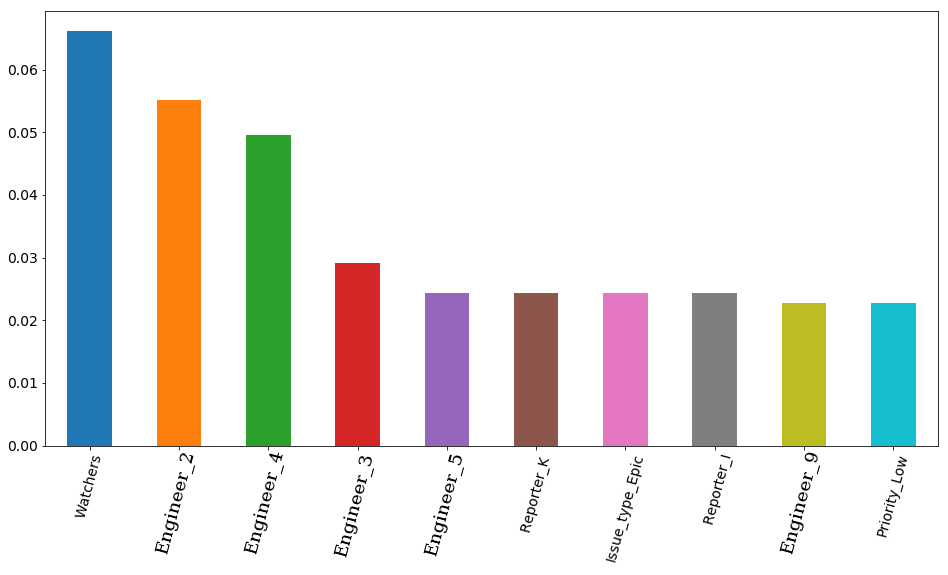
الشبكة العصبية
لكننا لن نتوقف عند تعزيز التدرج ونحاول تدريب الشبكة العصبية ، أو بالأحرى المدركة متعددة الطبقات ، وهي شبكة عصبية للتوزيع المباشر متصلة بالكامل. هذه المرة لن نبدأ بالإعدادات القياسية للمعلمات الفوقية ، كما في مكتبة sklearn ، التي سنستخدمها ، هناك طبقة واحدة فقط خفية تحتوي على 100 خلية عصبية ، وخلال التدريب ، يحذر النموذج من الاختلاف حول التكرار القياسي 200. نستخدم على الفور 3 طبقات مخفية مع 300 و 200 و 100 خلية عصبية ، على التوالي.
نتيجة لذلك ، نرى أن النموذج لا يتدرب بشكل زائد على عينة التدريب ، إلا أنه لا يمنعه من إظهار نتيجة لائقة في عينة الاختبار. هذه النتيجة هي أدنى إلى حد ما نتيجة لزيادة التدرج.
شفرة المصدر from sklearn.neural_network import MLPRegressor nn = MLPRegressor(random_state=17, hidden_layer_sizes=(300, 200 ,100), alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.9771443840549647 R^2 test: -0.15166596239118246 MAE train: 1627.3212161350423 MAE test: 8816.204561947616
دعونا نرى ما يمكننا تحقيقه من خلال محاولة اختيار أفضل بنية لشبكتنا. , , 200 , , . .
plt.figure(figsize=(14, 8)) for i in [(500,), (750,), (1000,), (500,500)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()

. 3 10 .
plt.figure(figsize=(14, 8)) for i in [(500,300,100), (80, 60, 60, 60, 40, 40, 40, 40, 20, 10), (80, 60, 60, 40, 40, 40, 20, 10), (150, 100, 80, 60, 40, 40, 20, 10), (200, 100, 100, 100, 80, 80, 80, 40, 20), (80, 40, 20, 20, 10, 5), (300, 250, 200, 100, 80, 80, 80, 40, 20)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()
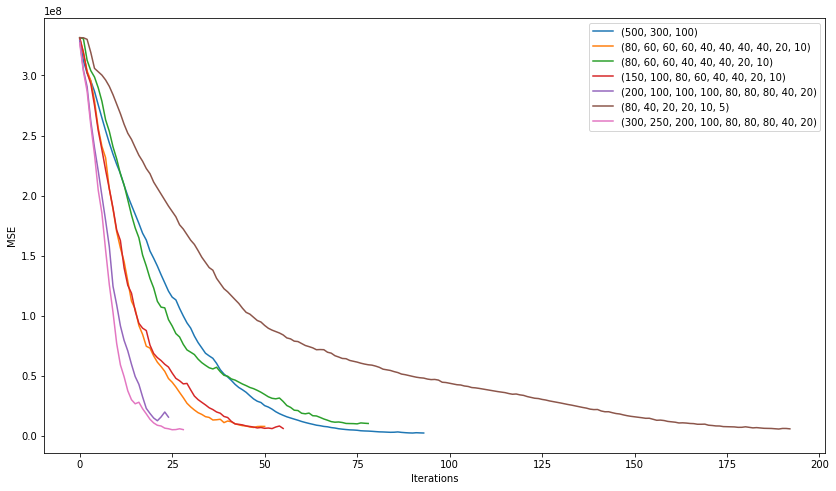
"" (200, 100, 100, 100, 80, 80, 80, 40, 20) :
2506
7351
, , . learning rate .
nn = MLPRegressor(random_state=17, hidden_layer_sizes=(200, 100, 100, 100, 80, 80, 80, 40, 20), alpha=0.1, learning_rate='adaptive', learning_rate_init=0.007, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.836204705204337 R^2 test: 0.15858607391959356 MAE train: 4075.8553476632796 MAE test: 7530.502826043687
, . , . , , .
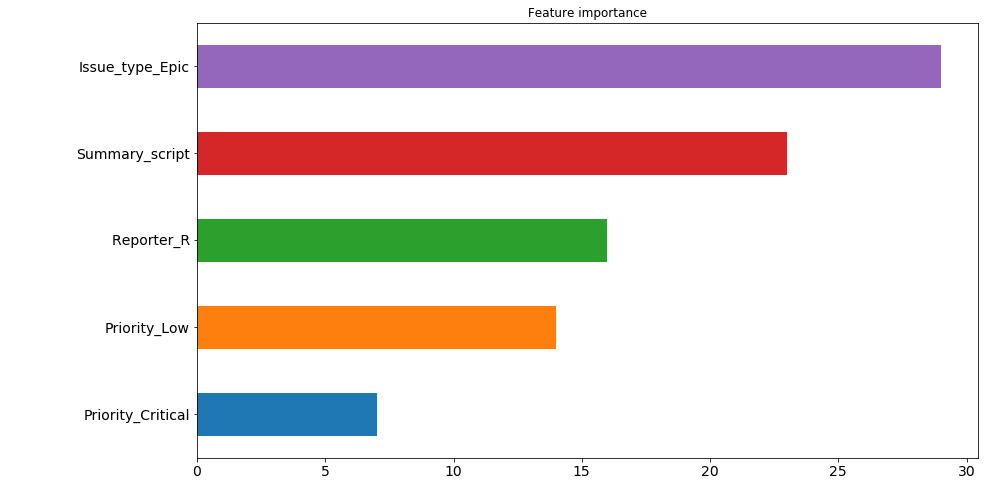
. : ( , 200 ). , "" . , 30 200 , issue type: Epic . , .. , , , , . 4 5 . , . , .
— 9 , . , , , .
pd.Series([X_train.columns[abs(nn.coefs_[0][:,i]).argmax()] for i in range(nn.hidden_layer_sizes[0])]).value_counts().head(5).sort_values().plot(kind='barh', title='Feature importance', fontsize=14, figsize=(14,8));
. لماذا؟ 7530 8217. (7530 + 8217) / 2 = 7873, , , ? , . , . , 7526.
, kaggle . , , .
nn_predict = nn.predict(X_holdout) xgb_predict = xgb.predict(X_holdout) print('NN MSE:', mean_squared_error(nn_predict, y_holdout)) print('XGB MSE:', mean_squared_error(xgb_predict, y_holdout)) print('Ensemble:', mean_squared_error((nn_predict + xgb_predict) / 2, y_holdout)) print('NN MAE:', mean_absolute_error(nn_predict, y_holdout)) print('XGB MSE:', mean_absolute_error(xgb_predict, y_holdout)) print('Ensemble:', mean_absolute_error((nn_predict + xgb_predict) / 2, y_holdout))
NN MSE: 628107316.262393 XGB MSE: 631417733.4224195 Ensemble: 593516226.8298339 NN MAE: 7530.502826043687 XGB MSE: 8217.07897417256 Ensemble: 7526.763569558157
? 7500 . أي 5 . . . , .
( ):
((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).values
[469132.30504392, 454064.03521379, 252946.87342439, 251786.22682697, 224012.59016987, 15671.21520735, 13201.12440327, 203548.46460229, 172427.32150665, 171088.75543224]
. , .
df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
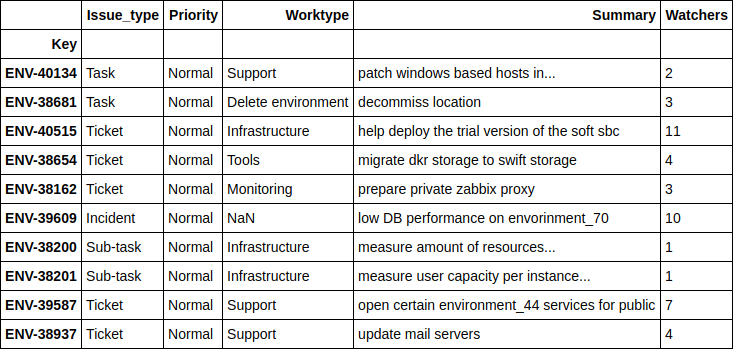
, - , . 4 .
, .
print(((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).values) df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
[ 1.24606014, 2.6723969, 4.51969139, 10.04159236, 11.14335444, 14.4951508, 16.51012874, 17.78445744, 21.56106258, 24.78219295]
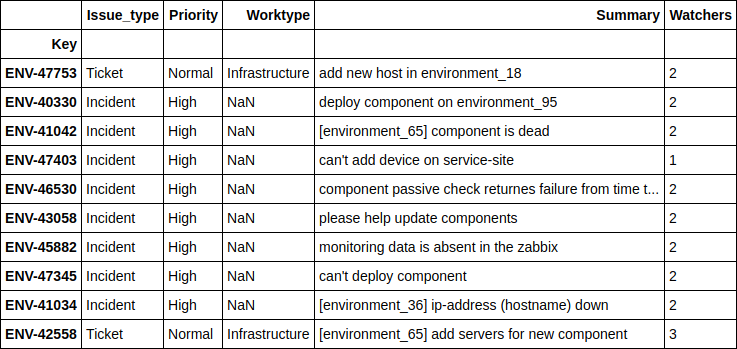
, , - , - . , , , .
Engineer
, 'Engineer', , , ? .
, 2 . , , , , . , , , "" , ( ) , , , . , " ", .
, . , , 12 , ( JQL JIRA):
assignee was engineer_N during (ticket_creation_date) and status was "In Progress"
10783 * 12 = 129396 , … . , , , .. 5 .
, , , , 2 . .
. SLO , .
, , ( : - , - , - ) , .