دعنا ننشئ وكيل تعلم عن النموذج الأولي (RL) يتقن مهارة التداول.
نظرًا لأن تطبيق النموذج الأولي يعمل باللغة R ، أشجع مستخدمي R والمبرمجين على الاقتراب من الأفكار الواردة في هذه المقالة.
هذه ترجمة لمقالتي الإنجليزية:
هل يمكن أن يعزز التعلم تجارة الأسهم؟ التنفيذ في ر.أريد أن أحذر من الباحثين عن الكود أنه في هذه الملاحظة لا يوجد سوى رمز لشبكة عصبية تم تكييفها من أجل R.إذا لم أميز نفسي باللغة الروسية جيدًا ، فأشر إلى الأخطاء (تم إعداد النص بمساعدة مترجم تلقائي).
مقدمة للمشكلة
أنصحك ببدء الغوص في الموضوع باستخدام هذه المقالة:
DeepMindإنه يعرّفك بفكرة استخدام Deep Q-Network (DQN) لتقريب دالة القيمة المهمة في عمليات اتخاذ القرارات في Markov.
أوصي أيضًا بالتعمق في الرياضيات باستخدام مقدمة هذا الكتاب بقلم ريتشارد سوتون وأندرو ج. بارتو:
تعزيز التعلمأدناه سوف أقدم نسخة موسعة من DQN الأصلي ، والذي يتضمن المزيد من الأفكار التي تساعد الخوارزمية على التقارب بسرعة وكفاءة ، وهي:
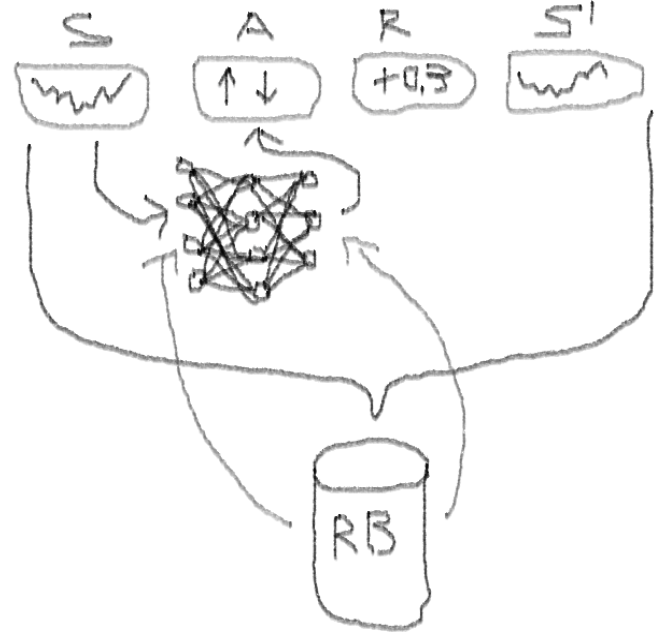
Deep Double Dueling Noisy NN مع اختيار الأولويات من تجربة تشغيل المخزن المؤقت.
ما الذي يجعل هذا النهج أفضل من DQN الكلاسيكية؟
- مزدوج: هناك شبكتان ، واحدة تم تدريبها ، والآخر يقيم القيم التالية لـ Q
- المبارزة: هناك خلايا عصبية ذات قيمة وفائدة بشكل واضح
- صاخبة: توجد مصفوفات ضوضاء مطبقة على أوزان الطبقات الوسيطة ، حيث الانحرافات المعيارية والمعيارية هي أوزان مدربة
- أولوية أخذ العينات: تحتوي مجموعات المراقبة من مخزن التشغيل المؤقت على أمثلة ، وبسبب التدريب السابق للوظائف أدى إلى بقايا كبيرة يمكن تخزينها في الصفيف الإضافي.
حسنًا ، ماذا عن التجارة التي قام بها وكيل DQN؟ هذا هو موضوع مثير للاهتمام على هذا النحو.
هناك أسباب تجعل هذا الأمر مثيرًا للاهتمام:
- حرية مطلقة في اختيار تمثيل الحالة ، والإجراءات ، والجوائز ، وهندسة NN. يمكنك إثراء مساحة الدخول بكل ما تراه جديراً بتجربته ، من الأخبار إلى الأسهم والمؤشرات الأخرى.
- المراسلات من منطق التداول إلى منطق التعلم التعزيز هي: أن الوكيل ينفذ إجراءات منفصلة (أو مستمرة) ، ونادراً ما يكافأ (بعد إغلاق الصفقة أو انتهاء الفترة) ، البيئة يمكن ملاحظتها جزئيًا وقد تحتوي على معلومات حول الخطوات التالية ، التجارة هي لعبة عرضية.
- يمكنك مقارنة نتائج DQN بعدة معايير ، مثل الفهارس وأنظمة التداول الفنية.
- يمكن للعامل تعلم المعلومات الجديدة بشكل مستمر ، وبالتالي ، التكيف مع قواعد اللعبة المتغيرة.
حتى لا تمتد المادة ، انظر إلى رمز NN هذا ، الذي أريد مشاركته ، لأن هذا هو أحد الأجزاء الغامضة للمشروع بأكمله.
كود R لشبكة عصبية ذات قيمة باستخدام Keras لبناء وكيل RL لدينا
لقد استخدمت هذا المصدر لتكييف كود Python لجزء الضوضاء في الشبكة:
github repoتبدو هذه الشبكة العصبية كما يلي:
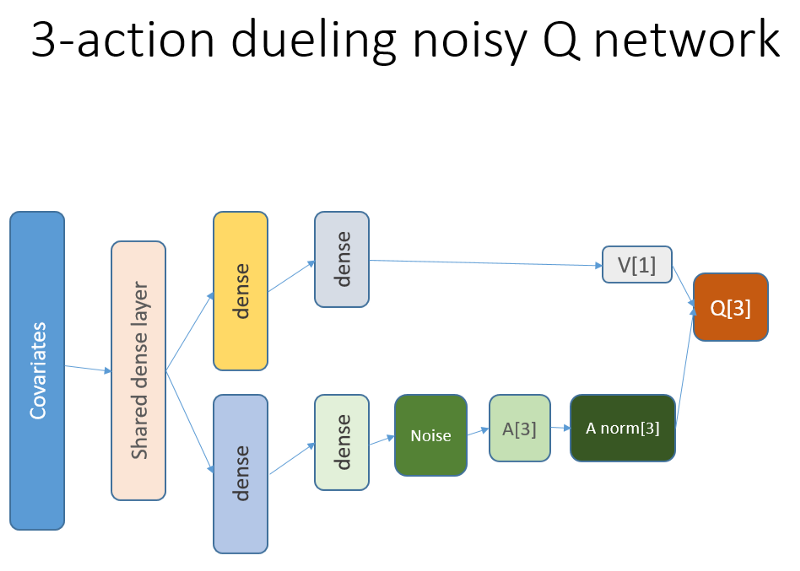
أذكر أننا في هندسة المبارزة نستخدم المساواة (المعادلة 1):
س = A '+ V ، أين
A '= A - avg (A) ؛
س = قيمة حالة العمل ؛
V = قيمة الدولة ؛
أ = ميزة.
المتغيرات الأخرى في الكود تتحدث عن نفسها. بالإضافة إلى ذلك ، هذه البنية جيدة فقط لمهمة محددة ، لذلك لا تأخذها كأمر مسلم به.
من المرجح أن تكون بقية الشفرة عامة بدرجة كافية للنشر ، وسيكون من الممتع للمبرمج أن يكتبها بنفسك.
والآن - التجارب. تم إجراء اختبار لعمل الوكيل في صندوق رمل ، بعيدًا عن حقائق التداول في سوق مباشر ، باستخدام وسيط حقيقي.
المرحلة الأولى
نحن ندير وكيلنا ضد مجموعة البيانات الاصطناعية. تكلفة معاملاتنا هي 0.5:
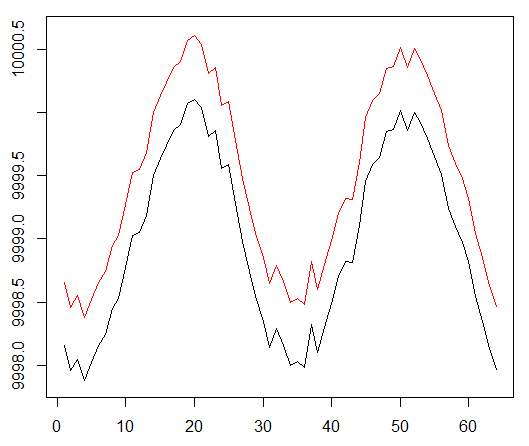
النتيجة ممتازة. الحد الأقصى لمتوسط المكافأة العرضية في هذه التجربة
يجب أن يكون 1.5.
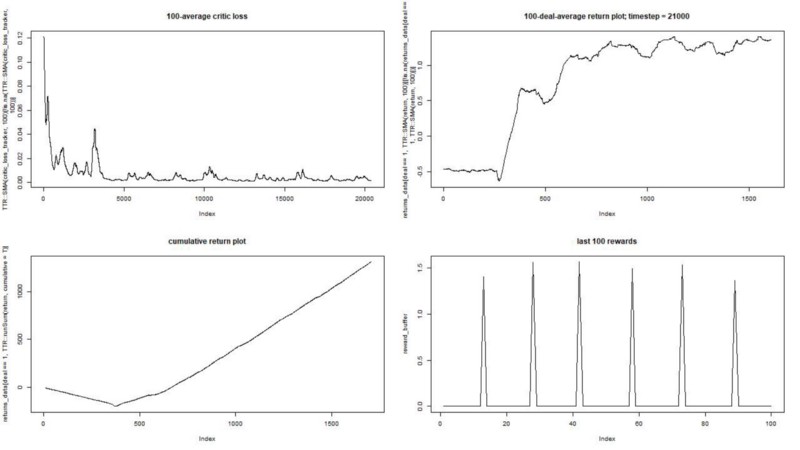
نرى: فقدان النقد (ما يسمى شبكة القيمة في نهج الممثل الناقد) ، ومكافأة متوسط عن حلقة ، ومكافأة متراكمة ، وعينة من المكافآت الأخيرة.
المرحلة الثانية
نعلم وكيلنا رمز أسهم تم اختياره بشكل تعسفي يوضح سلوكًا مثيرًا للاهتمام: بداية ثابتة ونمو سريع في المنتصف ونهاية كئيبة. في مجموعة التدريب لدينا حوالي 4300 يوما. تم تحديد تكلفة المعاملة عند 0.1 دولار أمريكي (منخفضة بشكل مقصود) ؛ المكافأة هي ربح / خسارة الدولار بعد إغلاق صفقة لشراء / بيع 1.0 سهم.
المصدر:
finance.yahoo.com/quote/algn؟ltr=1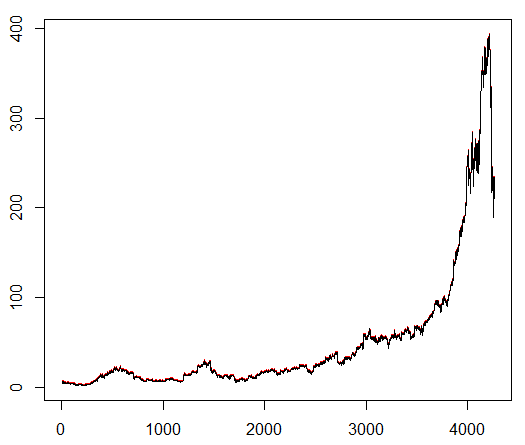 ناسداك: ALGN
ناسداك: ALGNبعد تعيين بعض المعلمات (ترك بنية NN كما هي) ، توصلنا إلى النتيجة التالية:

اتضح أنه ليس سيئًا ، لأنه في النهاية تعلم العميل تحقيق ربح عن طريق الضغط على ثلاثة أزرار على وحدة التحكم الخاصة به.
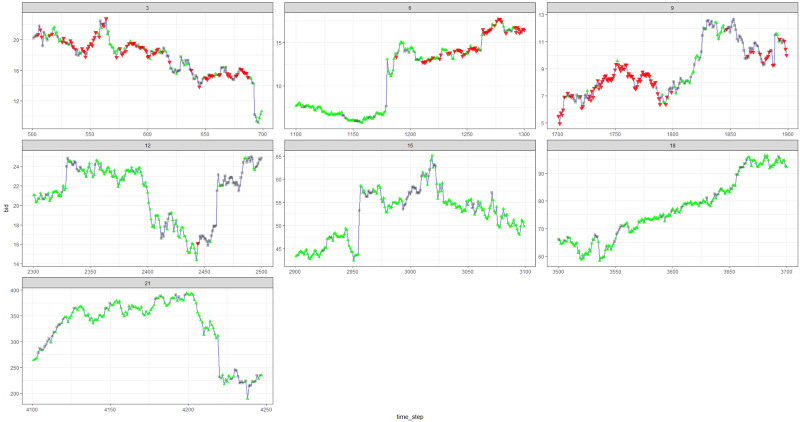 علامة حمراء = بيع ، علامة خضراء = شراء ، علامة رمادية = لا تفعل شيئًا.
علامة حمراء = بيع ، علامة خضراء = شراء ، علامة رمادية = لا تفعل شيئًا.يرجى ملاحظة أنه في ذروتها ، تجاوز متوسط المكافأة لكل حلقة قيمة الصفقة الواقعية التي يمكن مواجهتها في التداول الحقيقي.
إنه لأمر مؤسف أن الأسهم تتراجع مثل الجنون بسبب الأخبار السيئة ...
الملاحظات الختامية
التداول مع RL ليس فقط صعبًا ، ولكنه مفيد أيضًا. عندما يقوم الروبوت الخاص بك بعمل أفضل منك ، فقد حان الوقت لقضاء وقتك الشخصي للحصول على التعليم والصحة.
آمل أن تكون هذه رحلة مثيرة لك. إذا كنت تحب هذه القصة ، فقم بتلوين يدك. إذا كان هناك الكثير من الاهتمام ، فيمكنني المتابعة وإظهار كيف تعمل طرق تدرج السياسة باستخدام لغة R وواجهة برمجة تطبيقات Keras.
أود أيضًا أن أشكر أصدقائي المهتمين بالشبكات العصبية لنصيحتهم.
إذا كنت لا تزال لديك أسئلة ، فأنا دائمًا هنا.