يبدو أننا منغمسون بعمق في غابة التنمية المرتفعة لدرجة أننا لا نفكر ببساطة في المشكلات الأساسية. خذ على سبيل المثال التقسيم. ما يجب فهمه إذا كان من الممكن كتابة شرارات مشروطة = n في إعدادات قاعدة البيانات وسيتم تنفيذ كل شيء بمفرده. هذا صحيح ، لكنه ، لكن إذا حدث خطأ ما ، بدأت الموارد تصبح نادرة حقًا ، وأود أن أفهم ما هو السبب وكيفية إصلاحه.
باختصار ، إذا كنت تساهم في تطبيق تجزئة بديل في كاساندرا ، فليس هناك ما يكشف لك. ولكن إذا كان الحمل على خدماتك يصل بالفعل ، ولم تكن معرفة النظام متوافقة معه ، فأنت مرحب بك.
سيقول Andrei Aksyonov (
shodan )
العظيم والرهيب بالطريقة المعتادة أن
التقسيم سيئ ، وليس التقسيم سيئًا أيضًا ، وكيف يتم ترتيبه بالداخل. وبالصدفة ، لا يتعلق أحد أجزاء القصة عن التدوين بالمشاركة على الإطلاق ، ولكن الشيطان يعرف ماذا - كيفية تعيين الكائنات إلى القطع.

يبدو أن صورة الأختام (على الرغم من أنها بطريق الخطأ تحولت إلى جراء) تجيب بالفعل على السؤال عن سبب كل هذا ، ولكن لنبدأ بالتسلسل.
ما هو التقسيم؟
إذا كنت google بإصرار ، فقد تبين أن هناك حدًا غير واضح إلى حد ما بين التقسيم المزعوم والمزاحمة المزعومة. الجميع يدعو كل ما يريد أكثر مما يريد. بعض الناس يميزون بين التقسيم الأفقي والتقسيم. يقول آخرون أن التقسيم هو نوع معين من التقسيم الأفقي.
لم أجد معيارًا واحدًا للمصطلحات يتم اعتماده من قِبل الآباء المؤسسين ومعتمدة في ISO. الاعتقاد الداخلي الشخصي هو شيء من هذا القبيل:
التقسيم في المتوسط هو "تقطيع القاعدة إلى أجزاء" بطريقة تعسفية.
- التقسيم العمودي على سبيل المثال ، هناك جدول عملاق يحتوي على ملياري إدخال في 60 عمود. بدلاً من الاحتفاظ بجدول عملاق من هذا القبيل ، نحتفظ بـ 60 من الجداول العملاقة لا تقل عن ملياري سجل لكل منها - وهذه ليست قاعدة بيانات بدوام جزئي ، بل هي تقسيم رأسي (كمثال على المصطلحات).
- التقسيم الأفقي - قمنا بقطع سطراً سطراً ، ربما داخل الخادم.
لحظة حرج هنا هو الفرق الدقيق بين التقسيم الأفقي والشرط. يمكنك تقطيعي إلى أجزاء ، لكنني لن أخبرك على وجه اليقين بما تتكون منه. هناك شعور بأن التقسيم والتقسيم الأفقي هما نفس الشيء.
تكون المشاركة عامة عندما يتم قطع جدول كبير من حيث قواعد البيانات أو مجموعة من المستندات ، الكائنات ، إذا لم يكن لديك قاعدة بيانات ، ولكن مخزن المستندات ، مخصصًا للكائنات. وهذا هو ، يتم تحديد القطع من 2 مليار كائن ، بغض النظر عن حجمها. لا يتم تقسيم الكائنات بحد ذاتها داخل كل كائن إلى أجزاء ، ولا نتحلل إلى أعمدة منفصلة ، أي أننا نضع حزمًا في أماكن مختلفة.
رابط إلى العرض التقديمي للتأكد من اكتماله.اختلافات المصطلحات الدقيقة قد استمرت بالفعل. على سبيل المثال ، يمكن أن يقول مطورو Postgres ، على سبيل المثال ، أن التقسيم الأفقي يكون عندما تكمن جميع الجداول التي ينقسم إليها الجدول الرئيسي في نفس المخطط ، وعند التقسيم على أجهزة مختلفة.
بشكل عام ، وبدون الارتباط بمصطلحات قاعدة بيانات معينة ونظام إدارة بيانات محدد ، هناك شعور بأن التقاسم هو مجرد تقطيع سطحي سطراً سطراً وما إلى ذلك - وهذا كله:
المشاركة (~ = ، \ في ...) التقسيم الأفقي == نموذجي.
أؤكد ، عادة. بمعنى أننا نفعل كل هذا ليس فقط لتقليص 2 مليار مستند في 20 جدولًا ، كل منها سيكون أكثر قابلية للإدارة ، ولكن لتوزيعه على العديد من النوى أو العديد من الأقراص أو العديد من الخوادم المادية أو الافتراضية المختلفة .
من المفهوم أننا نقوم بذلك بحيث يتم نسخ كل شارد - كل شاتكا البيانات - عدة مرات. ولكن في الواقع ، لا.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
في الواقع ، إذا قمت بإجراء مثل هذا التقسيم للبيانات ، ومن جدول SQL عملاق على MySQL ، ستقوم بإنشاء 16 جدولًا صغيرًا على الكمبيوتر المحمول الشجاع ، دون تجاوز كمبيوتر محمول واحد ، وليس مخطط واحد ، وليس قاعدة بيانات واحدة ، إلخ. الخ - كل شيء ، لديك بالفعل تقاسم.
تذكر التوضيح مع الجراء ، وهذا يؤدي إلى ما يلي:
- عرض النطاق الترددي يتزايد.
- الكمون لا يتغير ، وهذا هو ، كل ، إذا جاز التعبير ، عامل أو مستهلك في هذه الحالة ، يحصل على بلده. ليس معروفًا ما الذي يحصل عليه الجراء في الصورة ، ولكن يتم تقديم الطلبات في نفس الوقت تقريبًا ، كما لو كان الجرو وحده.
- أو كليهما ، وآخر ، وما زال توافر عالية (النسخ المتماثل).
لماذا عرض النطاق الترددي؟ في بعض الأحيان قد يكون لدينا مثل هذه الكميات من البيانات التي لا تتناسب - ليس من الواضح أين ، ولكن لا تتناسب - بمقدار 1 {core | حملة | الخادم | ...}. ببساطة لا توجد موارد كافية وهذا كل شيء. من أجل العمل مع مجموعة البيانات الكبيرة هذه ، يجب عليك قصها.
لماذا الكمون؟ على أحد النواة ، يكون مسح جدول به ملياري صف أبطأ 20 مرة من مسح 20 جدولًا على 20 نواة ، ويتم ذلك بالتوازي. تتم معالجة البيانات ببطء شديد على مورد واحد.
لماذا توافر عالية؟ أو نقوم بقص البيانات من أجل القيام بواحد والآخر في نفس الوقت ، وفي الوقت نفسه توفر عدة نسخ من كل قشرة - توفر النسخ المتماثل توفرًا كبيرًا.
مثال بسيط على "كيفية القيام بذلك بيديك"
يمكن قطع المشاركة الشرطية باستخدام test.documents لجدول الاختبار لـ 32 مستندًا ، ومن خلال إنشاء هذا الجدول 16 من جداول الاختبار لحوالي وثيقتين test.docs00 ، 01 ، 02 ، ... ، 15 لكل منهما.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
لماذا؟ نظرًا لأننا لا نعلم مسبقًا كيف يتم توزيع المعرّف ، فإذا كان من 1 إلى 32 شاملاً ، فسيكون هناك وثيقتان لكل منهما ، وإلا لن يتم ذلك.
نحن نفعل هذا من أجل ماذا. بعد قيامنا بـ 16 جدولًا ، يمكننا "اللحاق" 16 بما نحتاج إليه. بغض النظر عما استند إليه ، يمكننا موازاة هذه الموارد. على سبيل المثال ، إذا لم تكن هناك مساحة كافية على القرص ، فسيكون من المنطقي تقسيم هذه الجداول إلى أقراص منفصلة.
كل هذا ، لسوء الحظ ، ليست حرة. أظن أنه في حالة معيار SQL الكنسي (لم أقم بإعادة قراءة معيار SQL لفترة طويلة ، ربما لم يتم تحديثه لفترة طويلة) ، لا يوجد بناء جملة موحد رسمي للقول لأي خادم SQL: "عزيزي خادم SQL ، اجعلني 32 مشاركة ووضعها على 4 أقراص. " ولكن في عمليات التنفيذ الفردية ، غالبًا ما يكون هناك بناء جملة محدد من أجل القيام بنفس الشيء من حيث المبدأ. لدى PostgreSQL آليات للتقسيم ، يمتلك MySQL MariaDB ذلك ، وربما فعلت أوراكل كل هذا منذ وقت طويل.
ومع ذلك ، إذا قمنا بذلك يدويًا ، وبدون دعم قاعدة البيانات وضمن إطار المعيار ، فإننا
ندفع بشكل مشروط مدى تعقيد الوصول إلى البيانات . حيث كان هناك SELECT * FROM من المستندات البسيطة حيث يوجد = 123 ، الآن 16 x SELECT * FROM docsXX. حسناً ، إذا حاولنا الحصول على السجل بالمفتاح. أكثر إثارة للاهتمام بشكل كبير إذا حاولنا الحصول على مجموعة مبكرة من السجلات. الآن (إذا كنت أؤكد ، كما لو كنت أغبياء ، وأبقى ضمن المعيار) ، يجب دمج نتائج الـ 16 SELECT * FROM في التطبيق.
ما تغير الأداء لتتوقع؟- خطي حدسي.
- نظريا - خطي ، لأن أضحل القانون .
- في الممارسة العملية - ربما خطيًا تقريبًا ، ربما لا.
في الواقع ، الإجابة الصحيحة غير معروفة. من خلال التطبيق الذكي لتقنية المشاركة ، يمكنك تحقيق تدهور خطي كبير في تشغيل التطبيق الخاص بك ، وحتى DBA سيأتي مع لعبة البوكر الساخنة.
دعونا نرى كيف يمكن تحقيق ذلك. من الواضح أن مجرد إعداد الإعداد لشرائح PostgreSQL = 16 ، ثم أقلعت بنفسها - وهذا غير مثير للاهتمام. دعونا نفكر في الكيفية التي يمكن أن نحقق بها
أننا سنتباطأ إلى 32 مرة من التقسيم ، وهذا أمر مثير للاهتمام من وجهة نظر كيفية عدم القيام بذلك.
إن محاولاتنا للإسراع أو الإبطاء ستظل دائماً ضد الكلاسيكيات - قانون أمدال القديم الطيب ، الذي ينص على أنه لا يوجد تماثل تام لأي طلب ، فهناك دائمًا جزء ثابت.
قانون ادل
هناك دائما جزء متسلسل.
يوجد دائمًا جزء من تنفيذ الطلب المتوازي ، وهناك دائمًا جزء غير متوازٍ. حتى إذا بدا لك أن هناك استعلامًا متوازيًا تمامًا ، فعلى الأقل يجمع صفًا من النتيجة التي سترسلها إلى العميل ، من الصفوف التي يتم تلقيها من كل قشرة ، هناك دائمًا ، وهو ثابت دائمًا.
هناك دائما نوع من الجزء المتسلسل. يمكن أن تكون صغيرة وغير مرئية تمامًا في الخلفية العامة ، ويمكن أن تكون عملاقة ، وبالتالي ، تؤثر بشدة على التوازي ، لكنها دائمًا ما تكون موجودة.
بالإضافة إلى ذلك ، فإن تأثيره
يتغير ويمكن أن ينمو بشكل كبير ، على سبيل المثال ، إذا قمنا بتخفيض جدولنا - دعنا نرفع المعدلات - من 64 سجلًا إلى 16 جدولًا من 4 سجلات ، سيتغير هذا الجزء. بالطبع ، بناءً على مثل هذه الكميات الضخمة من البيانات ، فإننا نعمل على هاتف محمول ومعالج بسرعة 86 ميجاهرتز ، ليس لدينا ملفات كافية يمكن إبقاؤها مفتوحة في نفس الوقت. على ما يبدو ، مع مثل هذه المدخلات ، نفتح ملفًا واحدًا في كل مرة.
- كان المجموع = المسلسل + الموازي . حيث ، على سبيل المثال ، يكون المتوازي هو كل العمل داخل قاعدة البيانات ، ويقوم المسلسل بإرسال النتيجة إلى العميل.
- أصبح Total2 = التسلسلي + الموازي / N + Xserial. على سبيل المثال ، عندما يكون ORDER BY ، Xserial> 0.
مع هذا المثال البسيط ، أحاول إظهار أن بعض Xserial يظهر. بالإضافة إلى حقيقة أن هناك دائمًا جزء متسلسل ، وحقيقة أننا نحاول التعامل مع البيانات بشكل متوازٍ ، يبدو أن هناك جزءًا إضافيًا لضمان تقطيع هذه البيانات. تحدث تقريبًا ، قد نحتاج إلى:
- العثور على هذه الجداول 16 في قاموس قاعدة البيانات الداخلية ؛
- فتح الملفات
- تخصيص الذاكرة ؛
- نقل الذاكرة
- وصمة عار النتائج.
- تزامن بين النوى.
تظهر دائمًا أي تأثيرات خارج المزامنة. يمكن أن تكون ضئيلة وتحتل المليار من إجمالي الوقت ، لكنها دائماً غير صفرية ودائماً موجودة. بمساعدتهم ، يمكننا أن نفقد الإنتاجية بشكل كبير بعد التقسيم.
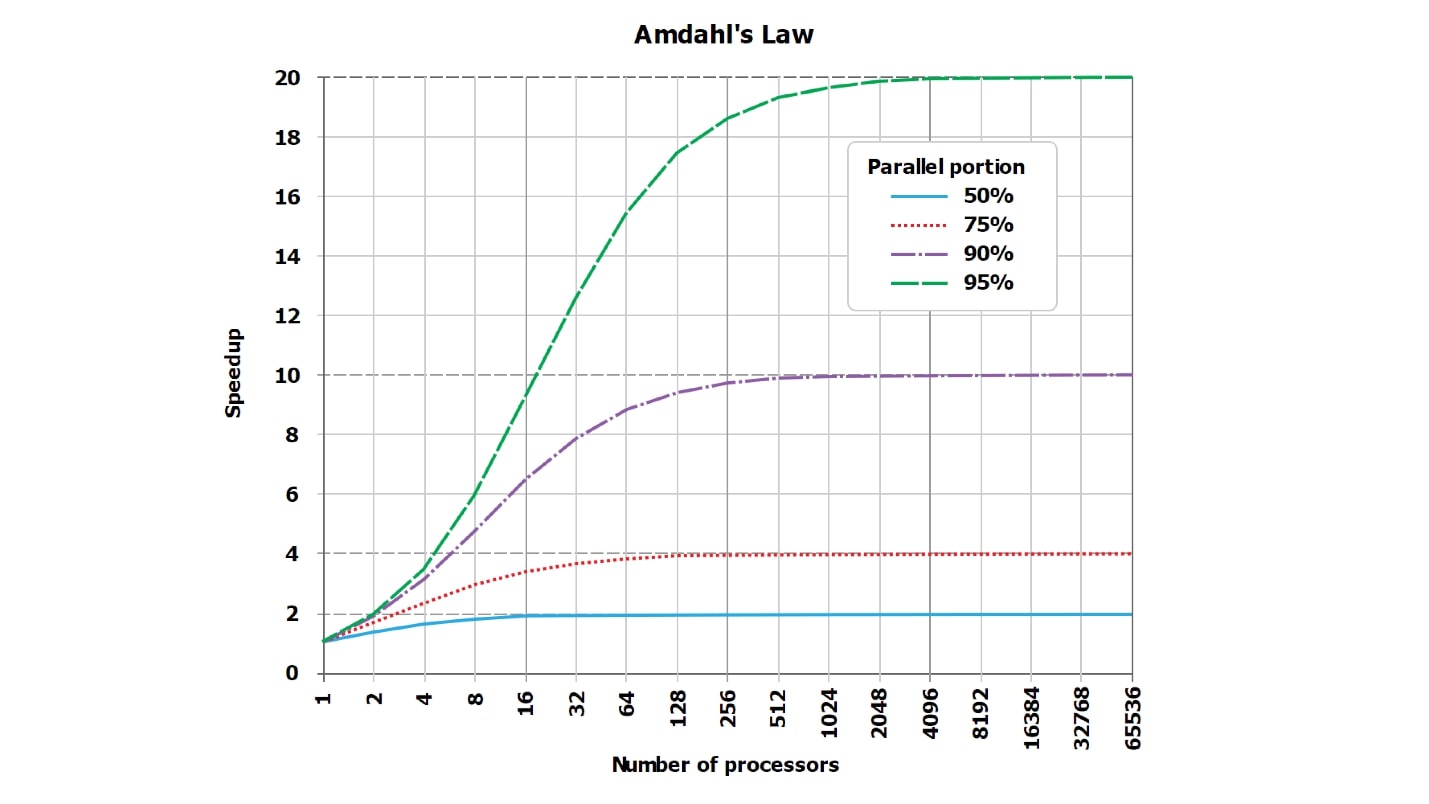
هذه صورة قياسية عن قانون أمدال. إنه ليس قابلاً للقراءة ، ولكن من المهم أن الخطوط ، التي يجب أن تكون مستقيمة وتنمو بشكل خطي ، تتاخم الخط المقارب. ولكن نظرًا لأن الرسم البياني من الإنترنت غير قابل للقراءة ، فقد صنعت ، في رأيي ، المزيد من الجداول المرئية بأرقام.
افترض أن لدينا جزءًا متسلسلاً من معالجة الطلب ، والذي يستغرق 5٪ فقط:
serial = 0.05 = 1/20.بشكل حدسي ، يبدو أنه مع الجزء المتسلسل ، الذي لا يستغرق سوى 1/20 من معالجة الطلب ، إذا قمنا بموازاة معالجة الطلب بمقدار 20 مركزًا ، فسيصبح حوالي 20 ، في أسوأ الحالات ، أسرع 18 مرة.
في الواقع ،
الرياضيات هي شيء بلا قلب :
wall = 0.05 + 0.95/num_cores, speedup = 1 / (0.05 + 0.95/num_cores)اتضح أنه إذا قمت بحساب دقيق ، مع جزء متسلسل من 5 ٪ ، فإن التسارع سيكون 10 مرات (10.3) ، وهذا هو 51 ٪ مقارنة بالمثل النظري.
| 8 النوى | = 5.9 | = 74 ٪ |
| 10 النوى | = 6.9 | = 69 ٪ |
| 20 النوى | = 10.3 | = 51 ٪ |
| 40 النوى | = 13.6 | = 34 ٪ |
| 128 النوى | = 17.4 | = 14 ٪ |
باستخدام 20 مركزًا (20 قرصًا ، إذا أردت) للمهمة التي عملت عليها من قبل ، لن نحصل على تسريع من الناحية النظرية أكثر من 20 مرة ، ولكن عمليًا أقل من ذلك بكثير. علاوة على ذلك ، مع زيادة عدد أوجه التشابه ، يتزايد عدم الكفاءة بسرعة.
عند بقاء 1٪ فقط من العمل المتسلسل ، وموازنة 99٪ ، يتم تحسين قيم التسريع إلى حد ما:
| 8 النوى | = 7.5 | = 93 ٪ |
| 16 النوى | = 13.9 | = 87 ٪ |
| 32 النوى | = 24.4 | = 76 ٪ |
| 64 النوى | = 39.3 | = 61 ٪ |
للحصول على استعلام نووي حراري تمامًا ، والذي يعمل بشكل طبيعي لعدة ساعات ، والعمل التحضيري وتجميع النتيجة يستغرق وقتًا طويلاً للغاية (التسلسلي = 0.001) ، سنرى بالفعل كفاءة جيدة:
| 8 النوى | = 7.94 | = 99 ٪ |
| 16 النوى | = 15.76 | = 99 ٪ |
| 32 النوى | = 31.04 | = 97 ٪ |
| 64 النوى | = 60.20 | = 94 ٪ |
يرجى ملاحظة
أننا لن نرى 100 ٪ . في الحالات الجيدة بشكل خاص ، يمكنك أن ترى ، على سبيل المثال ، 99.999 ٪ ، ولكن ليس بالضبط 100 ٪.
كيفية خلط ورق اللعب في أوقات N؟
يمكنك خلط ورق اللعب في أوقات N بالضبط:
- أرسل docs00 ... docs15 يطلب بالتتابع ، وليس بالتوازي.
- في الاستعلامات البسيطة ، لا تحدد حسب المفتاح ، حيث يوجد شيء = 234.
في هذه الحالة ، لا يشغل الجزء المتسلسل (التسلسلي) 1٪ وليس 5٪ ، ولكن حوالي 20٪ في قواعد البيانات الحديثة. يمكنك الحصول على 50٪ من الجزء المتسلسل إذا قمت بالوصول إلى قاعدة البيانات باستخدام بروتوكول ثنائي فعال أو ربطه كمكتبة ديناميكية ببرنامج نصي Python.
سيشغل باقي وقت المعالجة لطلب بسيط عمليات غير متوازنة لتحليل الطلب وإعداد الخطة ، إلخ. وهذا هو ، فإنه يبطئ عدم قراءة السجل.
إذا قمنا بتقسيم البيانات إلى 16 جدولًا وقمنا بتشغيلها بالتتابع ، كما هو معتاد في لغة برمجة PHP ، على سبيل المثال ، (لا تعرف كيفية تشغيل العمليات غير المتزامنة بشكل جيد للغاية) ، فسنحصل فقط على تباطؤ قدره 16 مرة. وربما أكثر من ذلك ، لأنه سيتم أيضًا إضافة رحلات ذهاب وإياب للشبكة.
فجأة عند المشاركة ، يكون اختيار لغة البرمجة أمرًا مهمًا.
نتذكر اختيار لغة البرمجة ، لأنه إذا أرسلت استعلامات إلى قاعدة البيانات (أو خادم البحث) بالتتابع ، فمن أين تأتي التسارع؟ بدلا من ذلك ، سوف تظهر تباطؤ.
الدراجة من الحياة
إذا اخترت C ++ ،
فاكتب إلى سلاسل POSIX ، وليس Boost I / O. رأيت مكتبة ممتازة من مطورين ذوي خبرة من Oracle و MySQL نفسها ، الذين كتبوا التواصل مع خادم MySQL على Boost. على ما يبدو ، لقد أُجبروا على الكتابة في لغة C تمامًا في العمل ، لكنهم تمكنوا بعد ذلك من الالتفاف والتقاط Boost باستخدام I / O غير المتزامن ، إلخ مشكلة واحدة - هذا I / O غير متزامن ، والتي ينبغي أن يكون من الناحية النظرية مدفوعة 10 طلبات في وقت واحد ، لسبب ما كان نقطة تزامن غير مرئية داخل. عند بدء 10 طلبات بالتوازي ، تم تنفيذها أبطأ 20 مرة بالضبط من واحد ، لأنه 10 مرات للطلبات نفسها ومرة واحدة إلى نقطة التزامن.
الخلاصة: اكتب باللغات التي تنفذ التشغيل المتوازي وانتظار الطلبات المختلفة جيدًا. لا أعرف ، لأكون صادقًا ، ما هو بالضبط النصح إلى جانب Go. ليس فقط لأنني أحب حقًا Go ، ولكن لأنني لا أعرف أي شيء أكثر ملاءمة.
لا تكتب بلغات غير مناسبة لا تستطيع فيها تشغيل 20 استعلامًا متوازيًا إلى قاعدة البيانات. أو في كل فرصة ، لا تفعل كل شيء بيديك - فهم كيف يعمل ، ولكن لا تفعل ذلك يدويًا.
A / B اختبار الدراجة
في بعض الأحيان ، يمكنك التباطؤ لأنك معتاد على حقيقة أن كل شيء يعمل ، ولم تلاحظ أن الجزء المتسلسل ، أولاً ، جزء كبير.
- على الفور ~ 60 فهرس فهرس البحث ، الفئات
- هذه هي القطع الصحيحة والصحيحة ، تحت مجال الموضوع.
- كان هناك ما يصل إلى 1000 وثيقة ، وكان هناك 50000 وثيقة.
هذه دراجة إنتاج ، عندما تم تغيير استعلامات البحث بشكل طفيف وبدأت في اختيار المزيد من المستندات من 60 رأسًا من فهرس البحث. كل شيء سار بسرعة وعلى مبدأ: "إنه يعمل - لا تلمسها" ، لقد نسيها جميعًا ، وهو في الواقع داخل 60 قطعة. قمنا بزيادة حد أخذ العينات لكل قشرة من ألف إلى 50 ألف مستند. فجأة ، بدأت في التباطؤ وتوقف التوازي. كانت الطلبات نفسها ، التي تم تنفيذها وفقًا للشرطات ، جيدة جدًا ، وتم إبطاء المرحلة ، حيث تم جمع 50 ألف مستند من 60 قطعة. تم دمج هذه المستندات النهائية البالغ عددها 3 ملايين على جوهر واحد معًا وفرزها ، وتم اختيار أعلى 3 ملايين وتم تسليمها للعميل. تباطأ نفس الجزء التسلسلي ، وعمل نفس القانون القاسي لأمدال.
لذلك ربما لا ينبغي عليك القيام بالقسط بيديك ، ولكن فقط إنسانيًا
أخبر قاعدة البيانات: "افعلها!"
إخلاء المسؤولية: لا أعرف حقًا كيف أفعل شيئًا صحيحًا. أنا مثل من الطابق الخطأ!
لقد تم الترويج لدين يسمى "الأصولية الخوارزمية" طوال حياتي الواعية بأكملها. وضعت لفترة وجيزة جدا بكل بساطة:
لا ترغب حقًا في فعل أي شيء بيديك ، ولكن من المفيد للغاية معرفة كيفية ترتيبها بالداخل. بحيث في الوقت الذي يحدث فيه خطأ ما في قاعدة البيانات ، فأنت على الأقل تفهم ما حدث هناك ، وكيف يتم ترتيبه بالداخل وما يقرب من كيفية إصلاحه.
دعونا نلقي نظرة على الخيارات:
- "الأيدي" . في وقت سابق ، قمنا يدويًا بتقسيم البيانات إلى 16 جدولًا افتراضيًا ، وأعدنا كتابة جميع الاستعلامات بأيدينا - وهذا أمر غير مريح للغاية. إذا كانت هناك فرصة لعدم خلط الأيدي - فلا تقم بخلط الأيدي! لكن في بعض الأحيان لا يكون ذلك ممكنًا ، على سبيل المثال ، لديك MySQL 3.23 ، ثم يجب عليك.
- "تلقائي". يحدث أنه يمكنك التبديل تلقائيًا أو تلقائيًا تقريبًا ، عندما تتمكن قاعدة البيانات من توزيع البيانات نفسها ، ما عليك سوى كتابة إعداد معين في مكان ما تقريبًا. هناك الكثير من القواعد ، ولديها الكثير من الإعدادات المختلفة. أنا متأكد من أنه في كل قاعدة بيانات يمكن من خلالها كتابة شظايا = 16 (أيًا كان التركيب) ، يتم لصق الكثير من الإعدادات الأخرى على هذه الحالة بواسطة المحرك.
- "شبه التلقائي" - وهو الكونية تماما ، في رأيي ، والوضع الوحشي. بمعنى ، لا يبدو أن القاعدة نفسها قادرة على ذلك ، ولكن هناك تصحيحات إضافية خارجية.
من الصعب معرفة شيء ما عن الجهاز ، باستثناء إرساله إلى الوثائق الموجودة في قاعدة البيانات المناسبة (MongoDB ، Elastic ، Cassandra ، ... بشكل عام ، ما يسمى NoSQL). إذا كنت محظوظًا ، فأنت تقوم فقط بسحب المفتاح "اجعلني 16 قطعًا" وسيعمل كل شيء. في تلك اللحظة ، عندما لا تعمل ، قد تكون بقية المقالة ضرورية.
حول الجهاز شبه التلقائي
في بعض الأماكن ، تلهم تقنيات المعلومات المتطورة الرعب الكاثوني. على سبيل المثال ، لم يكن لدى MySQL خارج الصندوق أي تطبيق للظهور على إصدارات معينة بالتأكيد ، ومع ذلك ، فإن حجم القواعد التي تعمل في المعركة ينمو إلى قيم غير لائقة.
لقد عانت المعاناة الإنسانية في مواجهة DBAs الفردية لسنوات ، وكتبت العديد من حلول المشاركة السيئة المبنية من دون سبب. بعد ذلك ، تتم كتابة حل مشاركة لائق أو أكثر يسمى ProxySQL (MariaDB / Spider ، PG / pg_shard / Citus ، ...). هذا مثال معروف على هذا الوشاح نفسه.
ProxySQL ككل ، بالطبع ، هو حل كامل على مستوى المؤسسات للمصدر المفتوح ، للتوجيه وأكثر من ذلك. ولكن إحدى المهام التي يتعين حلها هي المشاركة في قاعدة بيانات ، والتي في حد ذاتها لا تعرف كيف تتقاسم البشر. كما ترى ، لا يوجد مفتاح "shards = 16" ، إما يتعين عليك إعادة كتابة كل طلب في التطبيق ، وهناك الكثير منهم ، أو وضع طبقة وسيطة بين التطبيق وقاعدة البيانات التي تبدو: "Hmm ... SELECT * FROM documents"؟ نعم ، يجب تمزيقه إلى 16 صغيرًا SELECT * FROM server1.document1 و SELECT * FROM server2.document2 - إلى هذا الخادم الذي يحمل اسم المستخدم / كلمة المرور هذا إلى آخر. إذا لم يجيب أحد ، فعندئذ ... "إلخ.
بالضبط يمكن القيام بذلك عن طريق تصحيحات وسيطة. هم أقل قليلا من لجميع قواعد البيانات. بالنسبة لـ PostgreSQL ، كما أفهمها ، هناك بعض الحلول المضمنة في نفس الوقت (في اعتقادي PostgresForeign Data Wrappers ، في رأيي ، مدمجة في PostgreSQL نفسها) ، هناك تصحيحات خارجية.
يعد تكوين كل تصحيح معين موضوعًا عملاقًا منفصلاً ولن يتلاءم مع تقرير واحد ، لذلك سنناقش المفاهيم الأساسية فقط.
دعنا نتحدث قليلا عن نظرية الطنانة.
الأتمتة المطلقة الكمال؟
النظرية الكاملة للطنانة في حالة التقسيم في هذا الحرف F () ، المبدأ الأساسي هو
دائمًا نفس الخام:
shard_id = F(object).مشاركة عامة حول ماذا؟ لدينا 2 مليار السجلات (أو 64). نريد تقسيمها إلى عدة قطع. يطرح سؤال غير متوقع - كيف؟ بأي مبدأ ينبغي عليّ توزيع ملياري سجل (أو 64) في 16 خادمًا متاحًا لي؟
ينبغي أن يخبرك عالم الرياضيات الكامن فينا أنه في النهاية هناك دائمًا وظيفة سحرية معينة ، لكل مستند (كائن ، خط ، إلخ) ، ستحدد أي قطعة لوضعها.
إذا تعمقنا في الرياضيات ، فإن هذه الوظيفة تعتمد دائمًا ليس فقط على الكائن نفسه (الخط نفسه) ، ولكن أيضًا على الإعدادات الخارجية مثل إجمالي عدد القطع. لا يمكن للوظيفة ، التي يجب على كل كائن تحديد مكان وضعها ، إرجاع قيمة أكثر من الخوادم الموجودة على النظام. وظائف مختلفة قليلا:
- shard_func = F1 (كائن) ؛
- shard_id = F2 (shard_func، ...)؛
- shard_id = F2 ( F1 (كائن) ، current_num_shards ، ...).
لكن علاوة على ذلك ، لن نحفر في أدغال الوظائف الفردية هذه ، بل نتحدث فقط عن الوظائف السحرية F ().
ما هي F ()؟
يمكنهم الخروج بالعديد من آليات التنفيذ المختلفة والمختلفة. ملخص العينة:
- F = rand ()٪ nums_shards
- F = somehash (object.id)٪ num_shards
- F = object.date٪ num_shards
- F = object.user_id٪ num_shards
- ...
- F = shard_table [somehash () | ... object.date | ...]
حقيقة مثيرة للاهتمام - يمكنك بشكل طبيعي توزيع جميع البيانات بشكل عشوائي - نرمي السجل التالي على خادم تعسفي ، على نواة تعسفية ، في جدول تعسفي. لن يكون هناك الكثير من السعادة في هذا ، لكنها ستنجح.
هناك طرق أكثر ذكاءً في عملية الاحتيال لوظائف تجزئة قابلة للاستنساخ أو متناسقة ، أو لخداع لبعض السمات. دعنا نذهب من خلال كل طريقة.
F = راند ()
تناثر حول ليست طريقة صحيحة للغاية. مشكلة واحدة: قمنا بتوزيع ملياري سجل لكل ألف خادم بشكل عشوائي ، ولا نعرف أين يقع السجل. نحتاج إلى سحب user_1 ، لكننا لا نعرف مكانه. نذهب إلى ألف خادم ونفحص كل شيء - بطريقة ما ، إنه غير فعال.
F = somehash ()
دعنا نثرثر على المستخدمين بطريقة بالغة: اقرأ وظيفة التجزئة المستنسخة من user_id ، خذ الباقي من القسمة على عدد الخوادم واتصل على الفور بالخادم المطلوب.
لماذا نفعل هذا؟ وبعد ذلك ، لدينا حمولة كبيرة وليس لدينا أي شيء في خادم واحد. إذا intermeddle ، ستكون الحياة بسيطة جدا.حسنًا ، لقد تحسن الوضع بالفعل ، للحصول على سجل واحد ، نذهب إلى خادم واحد معروف. ولكن إذا كان لدينا مجموعة من المفاتيح ، فعندئذٍ في كل هذا النطاق ، نحتاج إلى فرز جميع قيم المفاتيح وفي الحد الأقصى ، انتقل إما إلى أكبر عدد ممكن من القطع الموجودة في المفاتيح ، أو إلى كل خادم بشكل عام. الوضع ، بالطبع ، قد تحسن ، ولكن ليس لجميع الطلبات. تأثرت بعض الطلبات.
المشاركة الطبيعية (F = object.date٪ num_shards)
في بعض الأحيان ، وهذا هو ، في كثير من الأحيان ، 95 ٪ من حركة المرور و 95 ٪ من الحمل هي الطلبات التي لديها نوع من التقاسم الطبيعي. , 95% - 1 , 3 , 7 , 5% . 95% , , , .
, , , - .
— , . , , , , . 5 % .
, :
- , 95% .
- 95% , , . , . , .
, — , - .
, , , , . « - ».
«». , .
1. :
, , .
, / , , , PM ( , PM ), . .
, . , , 100 . .
, , , , - .
2. «» : , join
, ?
- «» … WHERE randcol BETWEEN aaa AND bbb?
- «» … users_32shards JOIN posts_1024 shards?
: , !
, , , . . (, , document store ), , .
—
- . . , . , , , . - , , , , — .
, .
3. / :
: , .
, .
, , , . , , , 10 , - 30, 100 . . — , - — , - .
, : 16 -, 32. , 17, 23 — . , , - ?
: , , .
, «», « ».
#1.
- NewF(object), .
- NewF()=OldF() .
- .
- أوتش
, 2 , , . : 17 , 6 , 2 , 17 23 . 10 , , . .
#2.
— — 17 23, 16 32 ! , .
- NewF(object), .
- 2^N, 2^(N+1) .
- NewF()=OldF() 0,5.
- 50% .
- , .
, , . , , .
, . , 16 16, — .
, — .
#3. Consistent hashing
, consistent hashing
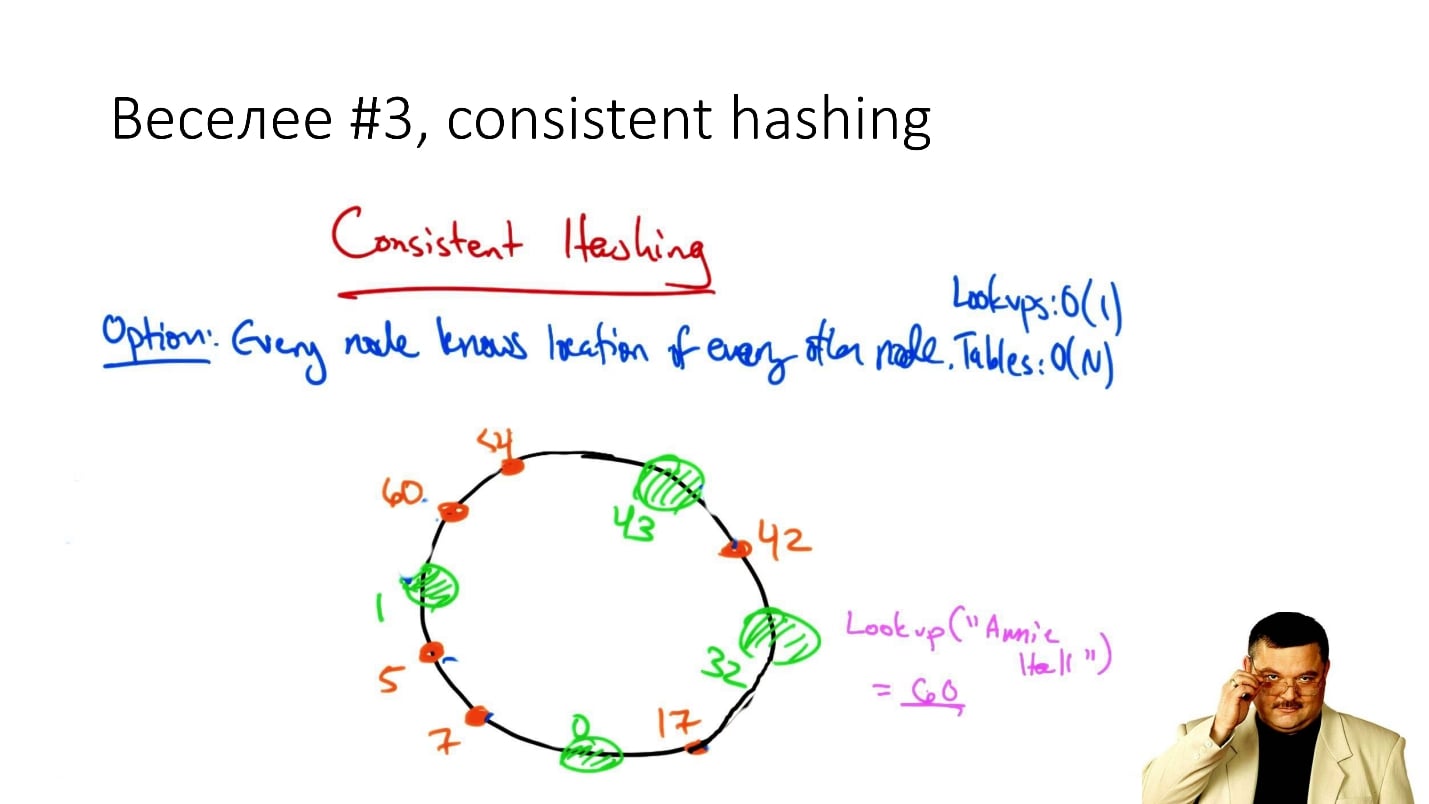
«consistent hashing», , .
: () , . , , , ( , ), .
, . , , , : , .
. , . , .., . , - , , .
, , , Cassandra . , , , , , .
, — / , , .
, : ? ? — , !
#4. Rendezvous/HRW
( , ):
shard_id = arg max hash(object_id, shard_id).Rendezvous hashing, , , Highest Random Weight. :
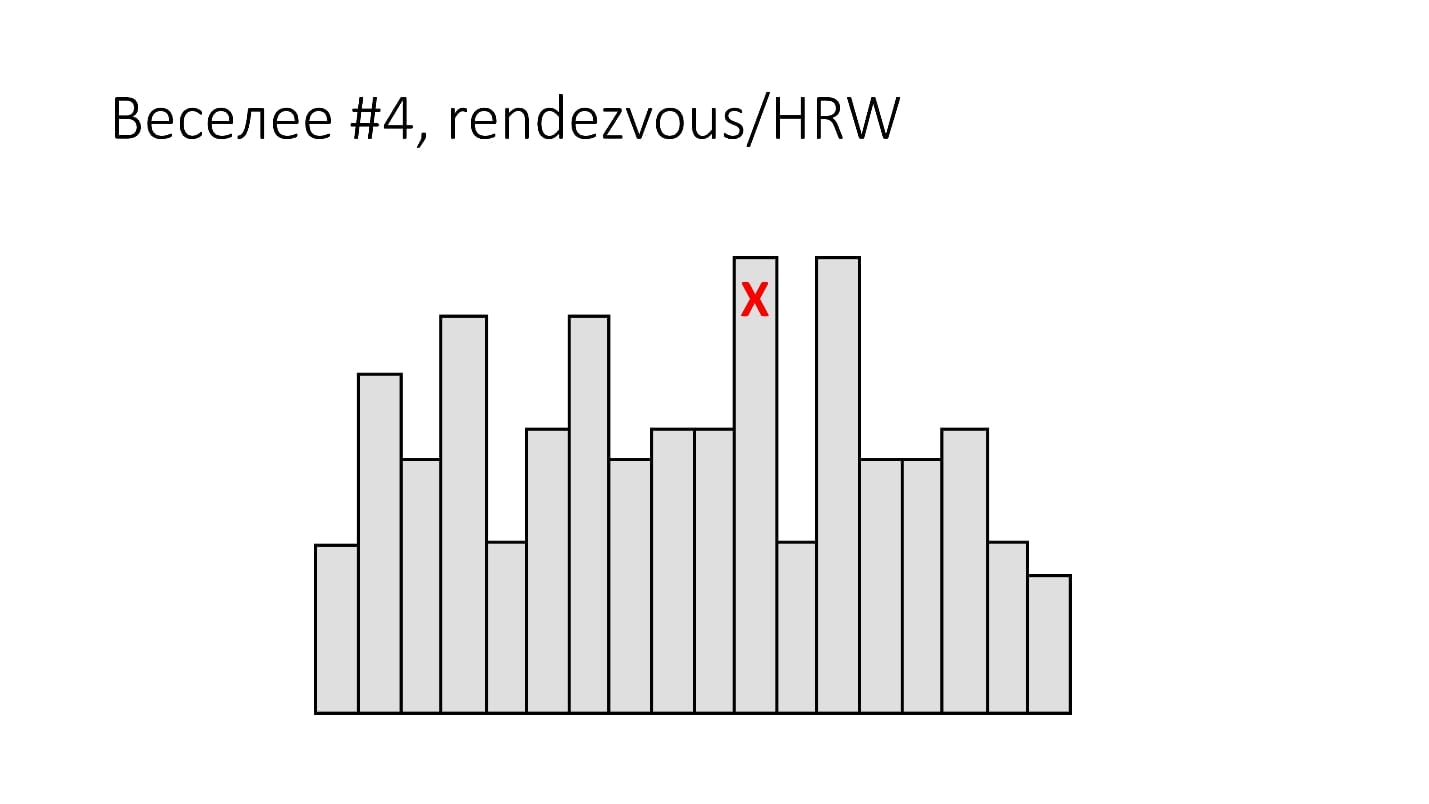
, , 16 . (), - , 16 , . -, .
HRW-hashing, Rendezvous hashing. , -, , .
, . , - - . .
, .
#5.
, Google - :
- Jump Hash — Google '2014.
- Multi Probe —Google '2015.
- Maglev — Google '2016.
, . , , , -, . .
#6.
— . ? , 2 , object_id 2 , .
, ? ?
. , - , , . , , , , .
:
- 1 .
- / / / : min/max_id => shard_id.
- 8 4 (4 !) — 20 .
- - , 20 — .
- 20 — .
2 - 16 — 100 - . : , , — 1 . , , .
, , , - , .
الاستنتاجات
: « , !». , 20 .
, , . ,
— . 100$ , . -, . — .
, , «» (, DFS, ...) . , , highload - . , , - . —
, .
F() , , , .. , , 2
.
, , .
HighLoad++ , , —Sphinx—highload , .
Highload User Group. , .
, ,
HighLoad++ . , , . , , .
highload-, .
, , , . , , , .
24 - «», « ». , . ,
.
, , 8 9 - HighLoad++ early bird .