أنت هنا إذا كنت تريد معرفة كيفية ترويض إطار عمل معروف على نطاق واسع في دوائر مطوري بيثون يطلق عليهم "الكيلي". وحتى إذا نفذت Celery بثقة الأوامر الأساسية في مشروعك ، فإن تجربة fintech قد تفتح جوانب غير معروفة لك. لأن fintech هي دائمًا البيانات الكبيرة ، ومعها الحاجة إلى مهام الخلفية ، ومعالجة الدُفعات ، وواجهة برمجة التطبيقات غير المتزامنة ، إلخ.

إن جمال قصة Oleg Churkin حول الكرفس في
Moscow Python Conf ++ ، بالإضافة إلى الإرشادات التفصيلية حول كيفية تكوين الكرفس تحت الحمل وكيفية مراقبته ، هو أنه يمكنك استعارة أفكار مفيدة.
نبذة عن المتحدث والمشروع: تقوم أوليغ تشوركين (
باهوس ) بتطوير مشاريع بيثون بمختلف تعقيداتها لمدة 8 سنوات ، وقد عملت في العديد من الشركات المعروفة: ياندكس ، رامبلر ، آر بي سي ، كاسبرسكي لاب. الآن techlide في بدء التشغيل fintech-StatusPoney.
يعمل المشروع مع كمية كبيرة من البيانات المالية للمستخدمين (1.5 تيرابايت): الحسابات والمعاملات والتجار ، إلخ. إنها تدير ما يصل إلى مليون مهمة كل يوم. ربما لا يبدو هذا الرقم كبيرًا جدًا بالنسبة لشخص ما ، ولكن بالنسبة لبدء تشغيل صغير بقدرات متواضعة ، فهذه كمية كبيرة من البيانات ، وكان على المطورين مواجهة مشكلات متعددة في طريقهم إلى عملية مستقرة.
تحدث أوليغ عن نقاط العمل الرئيسية:
- ما المهام التي تريد حلها باستخدام الإطار ، لماذا اخترت الكرفس.
- كيف ساعد الكرفس.
- كيفية تكوين الكرفس تحت الحمل.
- كيفية مراقبة حالة الكرفس.
وقد شارك عدة أدوات مساعدة للتصميم تقوم بتنفيذ الوظيفة المفقودة في Celery. كما اتضح ، في عام 2018 ، وهذا قد يكون. ما يلي هو نسخة نصية من التقرير في الشخص الأول.
العدد
كان مطلوبًا لحل المهام التالية:
- تشغيل مهام خلفية منفصلة .
- قم بمعالجة مجموعة من المهام ، أي ، قم بتشغيل العديد من المهام في وقت واحد.
- تضمين عملية استخراج وتحويل وتحميل .
- تطبيق API غير متزامن . اتضح أن واجهة برمجة التطبيقات غير المتزامنة يمكن تنفيذها ليس فقط باستخدام أطر عمل غير متزامنة ، ولكن أيضًا متزامنة تمامًا ؛
- أداء المهام الدورية . لا يمكن لأي مشروع واحد الاستغناء عن المهام الدورية ؛ بالنسبة للبعض ، يمكن الاستغناء عن Cron ، ولكن هناك أيضًا أدوات أكثر ملاءمة.
- بناء بنية المشغل : لتشغيل المشغل ، قم بتشغيل مهمة تقوم بتحديث البيانات. يتم ذلك من أجل التعويض عن نقص وقت التشغيل من خلال الحوسبة المسبقة للبيانات في الخلفية.
تتضمن
مهام الخلفية أي نوع من الإشعارات: البريد الإلكتروني ، والدفع ، وسطح المكتب - كل هذا يتم إرساله في مهام الخلفية بواسطة أحد المشغلات. بنفس الطريقة ، يتم بدء تحديث دوري للبيانات المالية.
في الخلفية ، يتم إجراء عمليات فحص محددة مختلفة ، على سبيل المثال ، التحقق من مستخدم للاحتيال. في الشركات الناشئة ،
يتم إيلاء الكثير من الجهد والاهتمام بشكل خاص لأمان البيانات ، حيث نسمح للمستخدمين بإضافة حساباتهم المصرفية إلى نظامنا ، ويمكننا أن نرى كل معاملاتهم. يمكن للمحتالين محاولة استخدام خدمتنا لشيء سيء ، على سبيل المثال ، للتحقق من رصيد الحساب المسروق.
الفئة الأخيرة من مهام الخلفية هي مهام
الصيانة : قرص شيء ، راجع ، إصلاح ، مراقب ، إلخ.
بالنسبة للإعلامات السائبة ،
يتم استخدام معالجة الدُفعات . يجب حساب كمية كبيرة من البيانات التي نتلقاها من مستخدمينا ومعالجتها بطريقة معينة ، بما في ذلك في وضع الدفعي.
نفس المفهوم يشمل
استخراج الكلاسيكية
، تحويل ، تحميل :
- تحميل البيانات من مصادر خارجية (API الخارجية) ؛
- الحفاظ على غير المجهزة.
- تشغيل المهام التي تقوم بقراءة ومعالجة البيانات ؛
- نحفظ البيانات التي تمت معالجتها في المكان الصحيح بالتنسيق الصحيح ، بحيث يكون استخدامها لاحقًا مناسبًا في واجهة المستخدم ، على سبيل المثال.
ليس سراً أن واجهة برمجة التطبيقات غير المتزامنة يمكن إجراؤها باستخدام طلبات الاقتراع البسيطة: تبدأ الواجهة الأمامية العملية في النهاية الخلفية ، وتقوم الواجهة الخلفية بتشغيل مهمة تطلق نفسها بشكل دوري ، "تصب" النتائج وتحديث الحالة في قاعدة البيانات. تظهر الواجهة الأمامية للمستخدم أن هذه الحالة التفاعلية تتغير. هذا يتيح لك:
- تشغيل مهام الاقتراع من مهام أخرى ؛
- تشغيل مهام مختلفة حسب الظروف.
في خدمتنا ، هذا يكفي الآن ، لكن في المستقبل سيكون علينا إعادة كتابة شيء آخر.
متطلبات الأداة
لتنفيذ هذه المهام ، كان لدينا المتطلبات التالية للأدوات:
- وظائف ضرورية لتحقيق طموحاتنا.
- قابلية التوسع دون عكازات.
- مراقبة النظام من أجل فهم كيفية عمله. نحن نستخدم الإبلاغ عن الأخطاء ، وبالتالي فإن التكامل مع Sentry لن يكون في غير محله ، مع Django أيضًا.
- الأداء ، لأن لدينا الكثير من المهام.
- النضج والموثوقية والتنمية النشطة هي أشياء واضحة. كنا نبحث عن أداة سيتم دعمها وتطويرها.
- كفاية الوثائق - لا توجد وثائق في أي مكان .
أي أداة للاختيار؟
ما هي الخيارات المتاحة في السوق في عام 2018 لحل هذه المشاكل؟
ذات مرة للقيام بمهام أقل طموحًا ، كتبت
مكتبة مفيدة ما زالت تستخدم في بعض المشاريع. إنه سهل التشغيل ويقوم بالمهام في الخلفية. ولكن في الوقت نفسه ، لا توجد حاجة إلى أي وسطاء (لا Celery ، ولا غيرهم) ، فقط خادم تطبيقات
uwsgi ، الذي يحتوي على
ذاكرة التخزين المؤقت ، هو الشيء الذي يبدأ كعامل منفصل. هذا حل بسيط للغاية - يتم تخزين جميع المهام بشكل مشروط في الملفات. بالنسبة للمشروعات البسيطة ، هذا يكفي ، لكن بالنسبة لنا لم يكن هذا كافياً.
بطريقة ما نظرنا:
- الكرفس (10K نجوم على جيثب) ؛
- RQ (5K stars على GitHub) ؛
- هيوي (نجوم 2K على جيثب) ؛
- Dramatiq (1K نجوم على جيثب) ؛
- Tasktiger (0.5K نجوم على جيثب) ؛
- تدفق الهواء؟ لويجي
مرشح واعد 2018
الآن أود أن أوجه انتباهكم إلى
دراماتيك . هذه مكتبة من الكرفس البارع ، الذي كان يعرف كل مساوئ الكرفس وقرر إعادة كتابة كل شيء ، فقط بشكل جميل للغاية. فوائد دراماتك:
- مجموعة من جميع الميزات الضرورية.
- شحذ على الإنتاجية.
- ترقب ودعم المقاييس ل Prometheus من خارج منطقة الجزاء
- قاعدة رمز صغيرة ومكتوبة بوضوح ، رمز التحميل التلقائي.
منذ بعض الوقت ، واجهت Dramatiq مشاكل في التراخيص: أولاً كان هناك AGPL ، ثم تم استبدالها بـ LGPL. ولكن الآن يمكنك أن تجرب.
ولكن في عام 2016 ، بالإضافة إلى الكرفس ، لم يكن هناك شيء خاص يجب أخذه. لقد أحببنا وظيفتها الغنية ، ومن ثم فقد تناسب مهامنا بشكل مثالي ، لأنه حتى ذلك الحين كانت ناضجة وعملية:
- كان لديه مهام دورية خارج الصندوق ؛
- دعم العديد من الوسطاء ؛
- متكامل مع جانغو و ترقب.
ميزات المشروع
سوف أخبركم بسياقنا ، بحيث تكون القصة الإضافية مفهومة أكثر.
نستخدم
Redis كوسيط للرسائل . لقد سمعت الكثير من القصص والشائعات بأن Redis يفقد الرسائل ، وأنه لم يتم تكييفه ليكون وسيط رسائل. فيما يتعلق بتجربة الإنتاج ، لم يتم تأكيد ذلك ، ولكن ، كما اتضح ، يعمل Redis الآن بكفاءة أكبر من RabbitMQ (كما هو الحال مع Celery ، على الأقل ، على ما يبدو ، المشكلة في رمز التكامل مع الوسطاء). في الإصدار 4 ، تم إصلاح وسيط Redis ، فقد توقف عن فقد المهام أثناء إعادة التشغيل ويعمل بثبات تام. في عام 2016 ، كان Celery سيتخلى عن Redis ويركز على التكامل مع RabbitMQ ، لكن لحسن الحظ ، لم يحدث هذا.
في حالة وجود مشاكل مع Redis ، إذا كنا بحاجة إلى توفر كبير وخطير ، فإننا ، نظرًا لاستخدامنا لقوة Amazon ، سنتحول إلى Amazon SQS أو Amazon MQ.
لا نستخدم خلفية النتيجة لتخزين النتائج ، لأننا نفضل تخزين النتائج بأنفسنا حيثما نريد ، والتحقق منها بالطريقة التي نريدها. لا نريد أن يقوم كيليري بهذا من أجلنا.
نحن نستخدم
تجمع pefork ، أي عمال المعالجة الذين يقومون بإنشاء شوكات منفصلة للعمليات من أجل التزامن الإضافي.
وحدة العمل
سوف نناقش العناصر الأساسية من أجل تحديث أولئك الذين لم يجربوا الكرفس ، لكنهم سيذهبون فقط.
وحدة العمل لكيلري هو التحدي . سأقدم مثالاً لمهمة بسيطة ترسل رسالة بريد إلكتروني.
وظيفة بسيطة والديكور:
@current_app.task def send_email(email: str): print(f'Sending email to email={email}')
بدء المهمة بسيط: إما ندعو الوظيفة وسيتم تنفيذ المهمة في وقت التشغيل (send_email (email = "python@example.com")) ، أو في العامل ، أي تأثير المهمة في الخلفية:
send_email.delay(email="python@example.com") send_email.apply_async( kwargs={email: "python@example.com"} )
لمدة عامين من العمل مع الكرفس تحت حمولات عالية ، توصلنا إلى قواعد جيدة الشكل. كان هناك الكثير من المشاحنات ، لقد تعلمنا كيفية الالتفاف عليها ، وسوف أشارك كيف.
تصميم الكود
قد تحتوي المهمة على منطق مختلف. بشكل عام ، يساعدك Celery على الاحتفاظ بالمهام في ملفات أو مهام حزم ، أو استيرادها من مكان ما. في بعض الأحيان تحصل على كومة من منطق العمل في وحدة واحدة. في رأينا ، النهج الصحيح من وجهة نظر نموذجية التطبيق هو الحفاظ على
الحد الأدنى من المنطق في المهمة . نحن نستخدم الألغاز فقط باعتبارها "مشغلات" الكود. أي أن المهمة لا تحمل منطقًا في حد ذاته ، ولكنها تؤدي إلى إطلاق الكود في الخلفية.
@celery_app.task(queue='...') def run_regular_update(provider_account_id, *args, **kwargs): """...""" flow = flows.RegularSyncProviderAccountFlow(provider_account_id) return flow.run(*args, **kwargs)
نضع كل الكود في فصول خارجية تستخدم بعض الفصول الأخرى. جميع المهام تتكون أساسا من سطرين.
كائنات بسيطة في المعلمات
في المثال أعلاه ، يتم تمرير معرف معين إلى المهمة. في جميع المهام التي نستخدمها ، نقوم
بنقل البيانات العددية الصغيرة فقط ، المعرف. نحن لا نقوم بتسلسل نماذج Django لنقلها. حتى في ETL ، عندما تأتي نقطة بيانات كبيرة من خدمة خارجية ، فإننا نقوم أولاً بحفظها ثم تشغيل مهمة تقرأ كل هذه النقطة بواسطة id ومعالجتها.
إذا لم تقم بذلك ، فقد رأينا مزيجًا كبيرًا جدًا من الذاكرة المستهلكة في Redis. تبدأ الرسالة في تناول المزيد من الذاكرة ، يتم تحميل الشبكة بشكل كبير ، كما ينخفض عدد المهام المعالجة (الأداء). طالما أن الكائن يصل إلى الاكتمال ، تصبح المهام غير ذات صلة ، تم حذف الكائن بالفعل. البيانات اللازمة للتسلسل - ليس كل شيء جيد التسلسل في JSON في بيثون. كنا في حاجة إلى الفرصة ، عند إعادة محاولة المهام ، لتحديد ما يجب فعله بهذه البيانات بسرعة ، والحصول عليها مرة أخرى ، وإجراء بعض الاختبارات عليها.
إذا قمت بنقل البيانات الكبيرة في المعلمات ، فكر مرة أخرى! من الأفضل نقل عدد صغير يحتوي على كمية صغيرة من المعلومات في المشكلة ، ومن هذه المعلومات في المهمة للحصول على كل ما تحتاجه.
مشاكل عاطفية
المطورين الكرفس أنفسهم يوصي هذا النهج. عند تكرار قسم الكود ، يجب ألا تحدث أي آثار جانبية ، يجب أن تكون النتيجة هي نفسها. ليس من السهل تحقيق ذلك دائمًا ، خاصةً إذا كان هناك تفاعل مع العديد من الخدمات ، أو على مرحلتين.
ولكن عندما تفعل كل شيء محليًا ، يمكنك دائمًا التحقق من أن البيانات الواردة موجودة وذات صلة ، يمكنك العمل عليها واستخدام المعاملات. إذا كان هناك العديد من الاستعلامات إلى قاعدة البيانات لمهمة واحدة وقد يحدث خطأ ما في وقت التشغيل ، فاستخدم المعاملات لاستعادة التغييرات غير الضرورية.
التوافق الخلفي
كان لدينا بعض الآثار الجانبية المثيرة للاهتمام عندما نشرنا التطبيق. بغض النظر عن نوع النشر الذي تستخدمه (تحديث أزرق + أخضر أو متداول) ، سيكون هناك دائمًا موقف حيث تنشئ رمز الخدمة القديم رسائل لرمز العامل الجديد ، والعكس بالعكس ، يتلقى العامل القديم رسائل من رمز الخدمة الجديد ، لأنه تم نشره "أولاً" وذهب المرور.
اكتشفنا الأخطاء والمهام المفقودة حتى تعلمنا كيفية الحفاظ على
التوافق مع الإصدارات السابقة بين الإصدارات . التوافق الخلفي هو أنه بين الإصدارات يجب أن تعمل المهام بأمان ، بغض النظر عن المعلمات التي تدخل هذه المهمة. لذلك ، في جميع المهام ، نقوم الآن بتوقيع "المطاط" (** kwargs). عندما تحتاج إلى إضافة معلمة جديدة في الإصدار التالي ، فستأخذها من ** kwargs في الإصدار الجديد ، لكنك لن تأخذها في الإصدار القديم - لن ينكسر أي شيء. بمجرد أن يتغير التوقيع ، ولا يعرف Celery عن ذلك ، فإنه يتعطل ويعطي خطأً بعدم وجود مثل هذه المعلمة في المهمة.
هناك طريقة أكثر صرامة لتجنب مثل هذه المشكلات وهي إصدار قوائم انتظار المهام بين الإصدارات ، ولكن من الصعب جدًا تنفيذها وتركناها في قائمة التراكم في الوقت الحالي.
مهلات
قد تنشأ مشاكل بسبب عدم كفاية الأعداد أو المهلات غير الصحيحة.
عدم تعيين مهلة لمهمة الشر. هذا يعني أنك لا تفهم ما يجري في المهمة ، وكيف يجب أن يعمل منطق العمل.
لذلك ، يتم تعليق جميع مهامنا مع المهلات ، بما في ذلك المهام العامة لجميع المهام ، ويتم أيضًا تعيين مهلات لكل مهمة محددة.
يجب أن تكون ملحقة: soft_limit_timeout وتنتهي صلاحيتها.انتهاء الصلاحية هو مقدار مهمة يمكن أن يعيش في خط. من الضروري ألا تتراكم المهام في قوائم الانتظار في حالة حدوث مشاكل. على سبيل المثال ، إذا أردنا الآن إبلاغ المستخدم بشيء ما ، ولكن حدث شيء ما ، ويمكن إكمال المهمة غدًا فقط - وهذا لا معنى له ، وغداً لن تكون الرسالة ذات صلة. لذلك ، بالنسبة للإشعارات لدينا تنتهي صلاحية صغيرة إلى حد ما.
لاحظ استخدام
eta (العد التنازلي) + وضوح _timeout . تصف الأسئلة الشائعة مثل هذه المشكلة في Redis - ما يسمى بمهلة الرؤية الخاصة بسمسار Redis. بشكل افتراضي ، تكون قيمتها ساعة واحدة: إذا رأى العامل بعد ساعة أن أحدا لم يأخذ المهمة إلى التنفيذ ، فإنه يعيد إضافتها إلى قائمة الانتظار. وبالتالي ، إذا كان العد التنازلي ساعتين ، فسوف يكتشف الوسيط بعد ساعة أن هذه المهمة لم تكتمل بعد وسيخلق واحدة أخرى. وفي ساعتين ، سيتم الانتهاء من مهمتين متطابقتين.
إذا تجاوز الوقت المقدر أو العد التنازلي ساعة واحدة ، فسيؤدي استخدام Redis ، على الأرجح ، إلى ازدواجية في المهام ، إلا إذا قمت ، بطبيعة الحال ، بتغيير قيمة visibility_timeout في إعدادات اتصال الوسيط.
إعادة محاولة السياسة
بالنسبة لتلك المهام التي يمكن تكرارها ، أو التي قد تفشل ، نستخدم سياسة إعادة المحاولة. لكننا نستخدمها بعناية حتى لا تطغى على الخدمات الخارجية. إذا قمت بتكرار المهام بسرعة دون تحديد التراجع الأسي ، فقد لا تقف الخدمة الخارجية ، أو ربما الخدمة الداخلية ، في وضع مستقيم.
سيكون من الجيد تحديد المعلمات
retry_backoff و
retry_jitter و
max_retries بشكل صريح ، وخاصة max_retries. retry_jitter - معلمة تسمح لك بإحضار فوضى صغيرة حتى لا تبدأ المهام في التكرار في نفس الوقت.
تسرب الذاكرة
لسوء الحظ ، تتسرب الذاكرة بسهولة بالغة ، ويصعب العثور عليها وإصلاحها.
بشكل عام ، العمل مع الذاكرة في بيثون مثير للجدل للغاية. ستقضي الكثير من الوقت والأعصاب لفهم سبب حدوث التسرب ، ثم اتضح أنه ليس حتى في الكود. لذلك ، دائمًا ، عند بدء مشروع ، ضع
حدًا للذاكرة على العامل : worker_max_memory_per_child.
هذا يضمن أن OOM Killer لا تأتي في يوم من الأيام ، ولا تقتل جميع العمال ، ولن تفقد كل المهام. سوف الكرفس إعادة تشغيل العمال عند الحاجة.
المهام ذات الأولوية
هناك دائمًا مهام يجب إكمالها قبل أي شخص آخر ، أسرع من أي شخص آخر - يجب إكمالها الآن! هناك مهام ليست مهمة للغاية - فليتم إكمالها خلال اليوم. لهذا ، المهمة لها معلمة
أولوية. في Redis ، يعمل بشكل مثير للاهتمام - يتم إنشاء قائمة انتظار جديدة باسم يتم إضافة الأولوية فيه.
نحن نستخدم نهجا مختلفا -
العمال المنفصلين عن الأولويات ، أي بالطريقة القديمة ، نبتكر عمال الكرفس مع "أهمية" مختلفة:
celery multi start high_priority low_priority -c:high_priority 2 -c:low_priority 6 -Q:high_priority urgent_notifications -Q:low_priority emails,urgent_notifications
بدء التشغيل المتعدد من Celery هو المساعد الذي يساعدك على تشغيل تكوين Celery بأكمله على جهاز واحد ومن نفس سطر الأوامر. في هذا المثال ، نقوم بإنشاء العقد (أو العمال): high_priority و low_priority ، 2 و 6 هما التزامن.
يقوم اثنان من العاملين في high_priority بمعالجة قائمة انتظار urgent_notifications باستمرار. لن يقوم أي شخص آخر بأخذ هؤلاء العمال ، وسوف يقرأ المهام الهامة فقط من قائمة انتظار الإلحاح.
بالنسبة للمهام غير المهمة ، توجد قائمة انتظار low_priority. يوجد 6 عمال يتلقون رسائل من جميع قوائم الانتظار الأخرى. نشترك أيضًا مع عمال low_priority في الإخطارات العاجلة حتى يتمكنوا من المساعدة إذا لم يتمكن العاملون في high_priority من التعامل.
نحن نستخدم هذا المخطط الكلاسيكي لتحديد أولويات المهام.
استخراج ، تحويل ، تحميل
في أغلب الأحيان ، تبدو ETL كسلسلة من المهام ، يتلقى كل منها مدخلات من المهمة السابقة.
@task def download_account_data(account_id) … return account_id @task def process_account_data(account_id, processing_type) … return account_data @task def store_account_data(account_data) …
المثال له ثلاث مهام. لدى Celery أسلوب معالجة موزعة والعديد من الأدوات المساعدة المفيدة ، بما في ذلك وظيفة
السلسلة ، مما يجعل خط أنابيب واحدًا من بين ثلاث مهام من هذا القبيل:
chain( download_account_data.s(account_id), process_account_data.s(processing_type='fast'), store_account_data.s() ).delay()
سوف يقوم كيليري بتفكيك خط الأنابيب ، وتنفيذ المهمة الأولى بالترتيب ، ثم نقل البيانات المستلمة إلى الثانية ، ونقل البيانات التي ترجعها المهمة الثانية إلى الثالثة. هذه هي الطريقة التي ننفذ بها خطوط أنابيب ETL البسيطة.
للحصول على سلاسل أكثر تعقيدًا ، عليك توصيل منطق إضافي. لكن من المهم أن تضع في اعتبارك أنه إذا نشأت مشكلة في هذه السلسلة في مهمة واحدة ،
فسوف تنهار السلسلة بأكملها . إذا كنت لا تريد هذا السلوك ، فعليك التعامل مع الاستثناء ومتابعة التنفيذ أو إيقاف السلسلة بأكملها بشكل استثنائي.
في الواقع ، تبدو هذه السلسلة الداخلية وكأنها مهمة واحدة كبيرة ، والتي تحتوي على جميع المهام مع جميع المعلمات. لذلك ، إذا قمت بإساءة استخدام عدد المهام في السلسلة ، فستحصل على استهلاك عالي للذاكرة وتباطؤ في مجمل العملية.
إنشاء سلاسل الآلاف من المهام فكرة سيئة.دفعة مهمة تجهيز
الآن الشيء الأكثر إثارة للاهتمام: ماذا يحدث عندما تحتاج إلى إرسال بريد إلكتروني إلى مليوني مستخدم.
تكتب هذه الوظيفة لتجاوز كل المستخدمين:
@task def send_report_emails_to_users(): for user_id in User.get_active_ids(): send_report_email.delay(user_id=user_id)
ومع ذلك ، في معظم الأحيان ستتلقى الوظيفة ليس فقط معرف المستخدم ، ولكن أيضًا تغسل جدول المستخدمين بالكامل بشكل عام. سيكون لكل مستخدم مهمته الخاصة.
هناك العديد من المشاكل في هذه المهمة:
- يتم إطلاق المهام بالتسلسل ، أي أن المهمة الأخيرة (مليون مستخدم) ستبدأ خلال 20 دقيقة وربما بحلول هذا المهلة ستعمل بالفعل.
- يتم تحميل كل معرف المستخدم أولاً في ذاكرة التطبيق ، ثم في قائمة الانتظار - يؤدي التأخير () مليوني مهمة.
دعوتها مهمة الفيضان ، الرسم البياني يبدو مثل هذا.
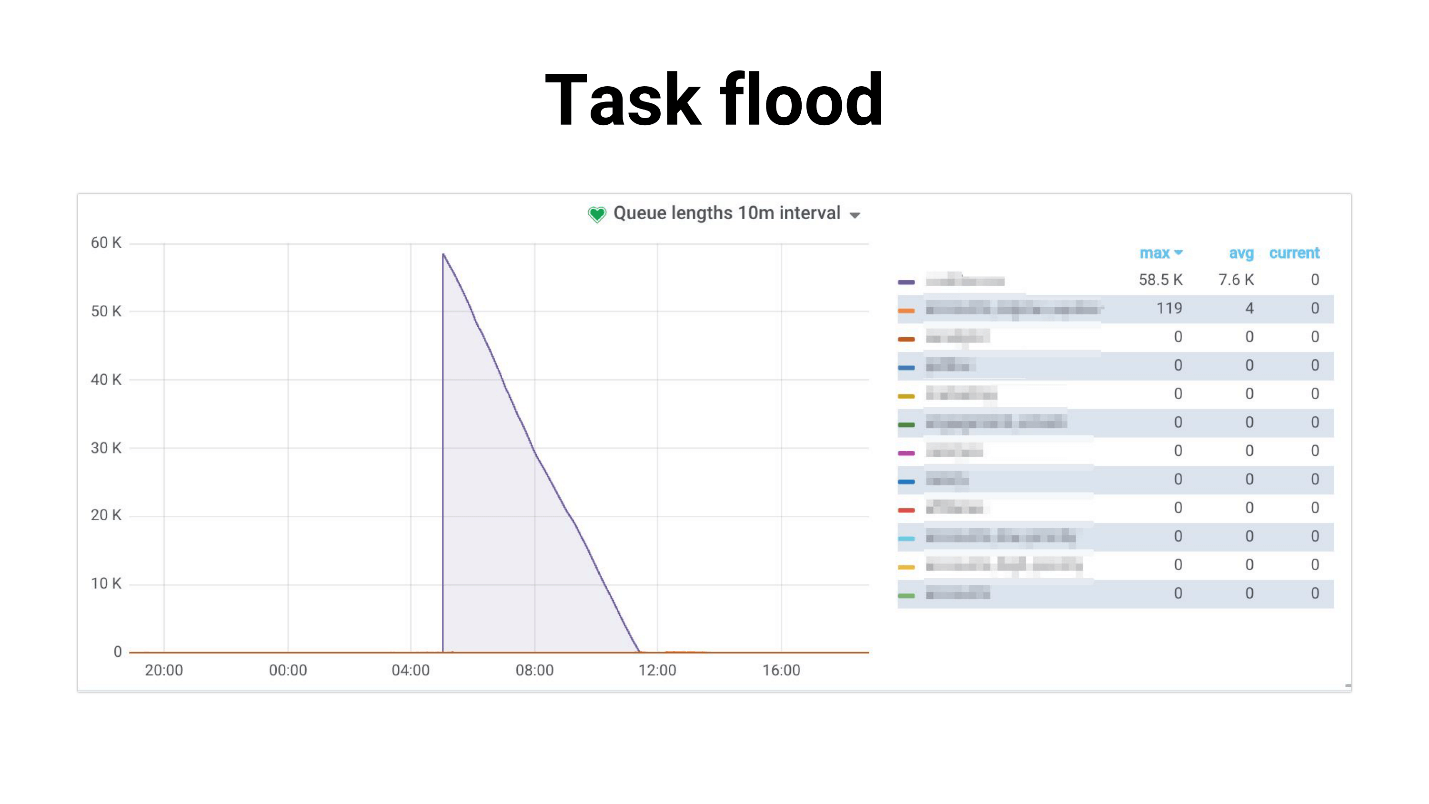
هناك تدفق للمهام التي يبدأ العمال في معالجتها ببطء. يحدث ما يلي إذا كانت المهام تستخدم نسخة متماثلة رئيسية ، يبدأ المشروع بأكمله في التصدع ، لا شيء يعمل. فيما يلي مثال من ممارستنا ، حيث كان DB CPU Usage 100٪ لعدة ساعات ، بصراحة ، تمكنا من الخوف.

المشكلة هي أن النظام يتدهور بدرجة كبيرة مع زيادة عدد المستخدمين. المهمة التي تتعامل مع الجدولة:
- يتطلب المزيد والمزيد من الذاكرة.
- يعمل لفترة أطول ويمكن أن يكون "قتل" من قبل المهلة.
يحدث فيضان المهام: تتراكم المهام في قوائم الانتظار وإنشاء عبء كبير ليس فقط على الخدمات الداخلية ، ولكن أيضًا على الخدمات الخارجية.
لقد حاولنا
تقليل القدرة التنافسية للعمال ، وهذا يساعد بشكل ما - يتم تقليل العبء على الخدمة. أو يمكنك
توسيع نطاق الخدمات الداخلية . ولكن هذا لن يحل مشكلة مشكلة المولد ، والتي لا تزال تأخذ الكثير. وليس بأي حال من الأحوال يؤثر على الاعتماد على أداء الخدمات الخارجية.
توليد المهمة
قررنا اتخاذ مسار مختلف. في أغلب الأحيان ، لا نحتاج إلى تشغيل جميع المهام البالغ عددها مليوني مهمة في الوقت الحالي. من الطبيعي أن يستغرق إرسال الإشعارات إلى جميع المستخدمين ، على سبيل المثال ، 4 ساعات إذا كانت هذه الرسائل ليست مهمة للغاية.
أولاً حاولنا استخدام
Celery.chunks :
send_report_email.chunks( ({'user_id': user.id} for user in User.objects.active()), n=100 ).apply_async()
لم يغير هذا الموقف ، لأنه على الرغم من التكرار ، سيتم تحميل كل user_id في الذاكرة. يحصل جميع العمال على سلسلة من المهام ، وعلى الرغم من أن العمال سوف يرتاحون قليلاً ، إلا أننا لم نكن راضين عن هذا القرار في النهاية.
لقد حاولنا تعيين
rate_limit على العمال بحيث يقومون بمعالجة عدد معين من المهام في الثانية فقط ، واكتشفنا أن rate_limit المحددة فعليًا للمهمة هي rate_limit للعامل. أي إذا حددت rate_limit للمهمة ، فهذا لا يعني أنه سيتم تنفيذ المهمة 70 مرة في الثانية. هذا يعني أن العامل سوف ينفذها 70 مرة في الثانية الواحدة ، واعتمادًا على ما لديك مع العمال ، يمكن أن يتغير هذا الحد بشكل حيوي ، أي الحد الحقيقي rate_limit * لين (العمال).
إذا بدأ العامل أو توقف ، يتغير الإجمالي rate_limit. علاوة على ذلك ، إذا كانت مهامك بطيئة ، فسيتم انسداد كل الجلب المسبق في قائمة الانتظار التي تملأ العامل بهذه المهام البطيئة. يبدو العامل: "أوه ، لدي هذه المهمة في rate_limit ، لم يعد بإمكاني القيام بها. وجميع المهام التالية في قائمة الانتظار هي نفسها تمامًا - دعهم يتعطلون! " - والانتظار.
Chunkificator
في النهاية ، قررنا أن نكتب مكتبنا الخاص ، وقمنا بإنشاء مكتبة صغيرة تسمى Chunkificator.
@task @chunkify_task(sleep_timeout=...l initial_chunk=...) def send_report_emails_to_users(chunk: Chunk): for user_id in User.get_active_ids(chunk=chunk): send_report_email.delay(user_id=user_id)
يستغرق sleep_timeout و initial_chunk ، ويدعو نفسه مع قطعة جديدة. Chunk عبارة عن تجريد إما عبر قوائم أعداد صحيحة أو قوائم تاريخ أو تاريخ. نقوم بتمرير القطعة إلى وظيفة تستقبل المستخدمين فقط باستخدام هذه القطعة ، ونقوم بتشغيل مهام تلك القطعة فقط.
وبالتالي ، فإن منشئ المهام يعمل فقط على عدد المهام المطلوبة ، ولا يستهلك الكثير من الذاكرة. أصبحت الصورة مثل هذا.

الأبرز هو أننا نستخدم قطعة متفرقة ، أي أننا نستخدم المثيلات في قاعدة البيانات كمعرف مقطوع (قد يتم تخطي بعضها ، وبالتالي قد يكون هناك عدد أقل من المهام). ونتيجة لذلك ، أصبح الحمل أكثر اتساقًا ، وأصبحت العملية أطول ، لكن الجميع على قيد الحياة وبصحة جيدة ، والقاعدة لا تجهد.
تم تنفيذ
المكتبة لبيثون 3.6+ وهي متوفرة على جيثب. هناك فارق بسيط أخطط لإصلاحه ، لكن في الوقت الحالي ، تحتاج القطعة إلى مُسلسل مخلل - لن يتمكن الكثيرون من القيام بذلك.
سؤالان بلاغيان - من أين جاءت كل هذه المعلومات؟ كيف اكتشفنا أن لدينا مشاكل؟ كيف تعرف أن المشكلة ستصبح حرجة قريبًا وتحتاج إلى البدء في حلها بالفعل؟
الجواب هو ، بطبيعة الحال ، الرصد.
الرصد
أحب المراقبة حقًا ، أحب مراقبة كل شيء وأبقي إصبعي على النبض. إذا لم تبقي إصبعك على النبض ، فستخطو بشكل مستمر أشعل النار.
أسئلة الرصد القياسية:
- هل يتعامل تكوين العامل / التزامن الحالي مع الحمل؟
- ما هو تدهور وقت تنفيذ المهمة؟
- كم من الوقت تتوقف المهام عن العمل؟ فجأة الخط مزدحم بالفعل؟
حاولنا عدة خيارات. يحتوي Celery على واجهة
CLI ، وهو غني جدًا ويعطي:
- فحص - معلومات حول النظام ؛
- السيطرة - إدارة إعدادات النظام ؛
- تطهير - طوابير واضحة (قوة قاهرة) ؛
- الأحداث - وحدة التحكم UI لعرض معلومات حول المهام التي يتم تنفيذها.
لكن من الصعب مراقبة شيء ما حقًا. يناسب بشكل أفضل الرتوش المحلية ، أو إذا كنت ترغب في تغيير معدل معين في وقت التشغيل.
ملحوظة: أنت بحاجة إلى الوصول إلى وسيط الإنتاج لاستخدام واجهة CLI.
يتيح لك
زهرة الكرفس أن تفعل نفس الشيء مثل CLI ، فقط من خلال واجهة الويب ، وهذا ليس كل شيء. لكنه يبني بعض الرسوم البيانية البسيطة ويسمح لك بتغيير الإعدادات أثناء الطيران.
بشكل عام ، تعد زهرة الكرفس مناسبة لرؤية كيفية عمل كل شيء في أجهزة صغيرة. بالإضافة إلى ذلك ، فإنه يدعم HTTP API ، وهو مناسب إذا كنت تكتب الأتمتة.
لكننا
استقرنا على بروميثيوس. أخذوا
المصدر الحالي: تسرب الذاكرة الثابتة فيه ؛ مقاييس مضافة لأنواع الاستثناءات ؛ إضافة مقاييس لعدد الرسائل في قوائم الانتظار ؛ متكاملة مع التنبيهات في غرافانا ونفرح. كما تم نشره على جيثب ، يمكنك أن ترى ذلك
هنا .
أمثلة في غرافانا

إحصائيات أعلاه لجميع الاستثناءات: ما هي الاستثناءات التي المهام. أدناه هو الوقت المناسب لإكمال المهام.

ما هو مفقود في الكرفس؟
هذا هو إطار الورقية ، لديه الكثير من الأشياء ، لكننا في عداد المفقودين! لا توجد ميزات صغيرة كافية ، مثل:
- إعادة تحميل التعليمات البرمجية تلقائيًا أثناء التطوير - لا يدعم إعادة تشغيل هذا الكرفس.
- مقاييس بروميثيوس خارج الصندوق ، لكن دراماتيك تستطيع ذلك.
- دعم قفل المهام - بحيث تعمل مهمة واحدة فقط في كل مرة. يمكنك القيام بذلك بنفسك ، ولكن Dramatiq و Tasktiger لديهما ديكور مناسب يضمن أن جميع المهام المماثلة الأخرى سيتم حظرها.
- Rate_limit لمهمة واحدة - وليس للعامل.
الاستنتاجات
على الرغم من أن Celery هو إطار يستخدمه الكثيرون في الإنتاج ، إلا أنه يتكون من 3 مكتبات - Celery و Kombu و Billiard. تم تطوير جميع هذه المكتبات من قِبل المطورين المشتركين ، ويمكنهم إصدار تبعية واحدة وكسر التجميع الخاص بك.
لذلك ، آمل أن تكون قد صنفتها بالفعل بطريقة ما وجعلت جمعياتك حتمية.
في الواقع ، فإن الاستنتاجات ليست حزينة جدا.
تتكيف كيليري
مع مهامها في مشروع fintech الخاص بنا. لقد اكتسبنا خبرة قمت بمشاركتها معك ، ويمكنك تطبيق حلولنا أو تحسينها والتغلب على جميع الصعوبات التي تواجهك.
لا تنس أن
المراقبة يجب أن تكون جزءًا أساسيًا من مشروعك . فقط من خلال المراقبة يمكنك معرفة أين لديك شيء خاطئ ، ما الذي يجب إصلاحه ، إضافته ، إصلاحه.
الاتصال المتكلم أوليغ Churkin :
Bahusss ،
الفيسبوك وجيثب .
ستعقد بطولة موسكو بايثون كونف ++ الكبيرة القادمة في موسكو في 5 أبريل . سنحاول هذا العام احتواء جميع المزايا في يوم واحد بطريقة تجريبية. لن يكون هناك تقارير أقل ، فسنخصص مجموعة كاملة للمطورين الأجانب للمكتبات والمنتجات المعروفة. بالإضافة إلى ذلك ، يعتبر يوم الجمعة يومًا مثاليًا للحفلات التي تعد ، كما تعلمون ، جزءًا لا يتجزأ من المؤتمر حول التواصل.
انضم إلى مؤتمر Python الاحترافي - أرسل تقريرك هنا ، وحجز تذكرتك هنا . في هذه الأثناء ، تجري الاستعدادات ، ستظهر هنا مقالات حول Moscow Python Conf ++ 2018.