تجدر الإشارة إلى أن هذه المقالة هي مجرد انعكاس شخصي فقط على كيف يمكن لسلوك عناصر الواجهة التي تعرف ما يفعله المستخدم في لحظة معينة أن يظهر وينفذ. الأفكار ، ومع ذلك ، تدعمها القليل من البحث والتنفيذ. دعنا نذهب.
في فجر الإنترنت ، لم تبحث المواقع عن الفردية في تصميم عناصر الواجهة الأساسية. كان التباين صغيرًا ، لذا كانت الصفحات موحدة إلى حد ما في مكوناتها.
بدا كل رابط وكأنه رابط ، وزر مثل زر ، ومربع اختيار مثل مربع الاختيار. عرف المستخدم ما الذي سيؤدي إليه الإجراء ، لأنه كان لديه فكرة واضحة عن مبدأ تشغيل كل عنصر.
يجب أن يرسل الرابط إلى صفحة أخرى ، بغض النظر عن مصدر الرابط أو من قائمة التنقل أو من النص في الوصف. سيغير الزر محتويات الصفحة الحالية ، ربما عن طريق إرسال طلب إلى الخادم. على الأرجح ، لن تؤثر حالة مربع الاختيار على المحتوى بأي شكل من الأشكال ، حتى نضغط على الزر للقيام ببعض الإجراءات التي تستخدم هذه الحالة. وبالتالي ، كان كافياً للمستخدم أن ينظر إلى عنصر الواجهة لفهم درجة عالية من الاحتمالية في كيفية التفاعل معه وما الذي سيؤدي إليه.
توفر المواقع الحديثة للمستخدم عددًا أكبر بكثير من الألغاز. تبدو جميع الارتباطات مختلفة تمامًا ، والأزرار لا تشبه الأزرار وما إلى ذلك. لفهم ما إذا كان الخط عبارة عن رابط ، يجب على المستخدم التمرير فوقه لرؤية تغيير اللون إلى لون أكثر تباينًا. لفهم ما إذا كان عنصر ما زرًا ، نمرر الماوس أيضًا لرؤية التغيير في نغمة التعبئة. مع عناصر القوائم المختلفة ، يكون كل شيء معقدًا أيضًا ، من المحتمل أن يقوم بعضها بتوسيع قائمة فرعية إضافية ، والبعض الآخر لا يقوم بذلك ، على الرغم من أنها متماثلة ظاهريًا.
ومع ذلك ، فقد اعتدنا بسرعة على الواجهات التي نستخدمها بانتظام ولم نعد مرتبكين في وظائف العناصر. لعبت دورا رئيسيا من خلال الاستمرارية الشاملة للواجهات. عند النظر إلى الصفحة أعلاه ، من المرجح أن ندرك على الفور أن السهم الأصفر بكلمات "Find" ليس مجرد عنصر زخرفي ، بل زر ، على الرغم من أنه لا يبدو على الإطلاق زر HTML قياسي. لذلك ، من حيث القدرة على التنبؤ والشخصية ، توصلت معظم الموارد إلى إجماع مستقر مقبول لدى المستخدمين.
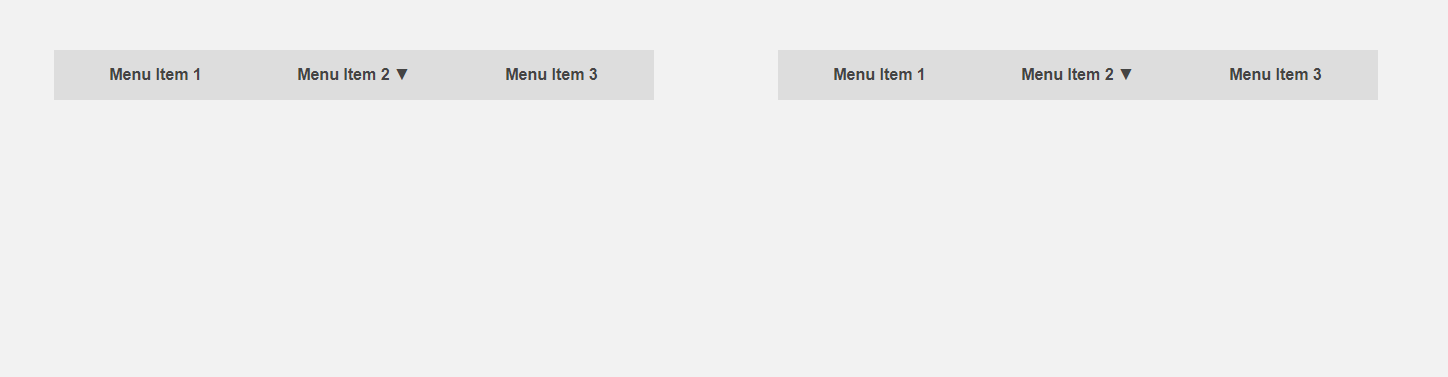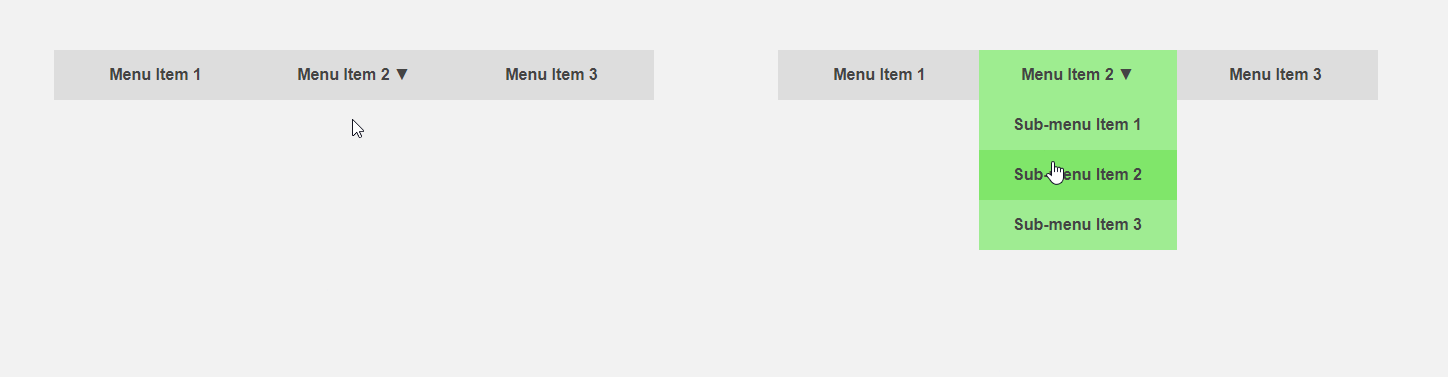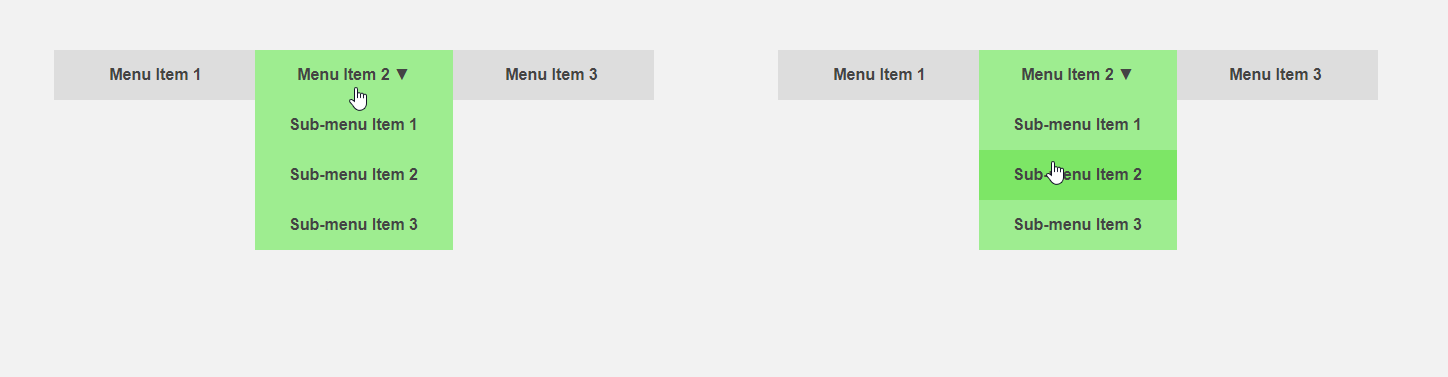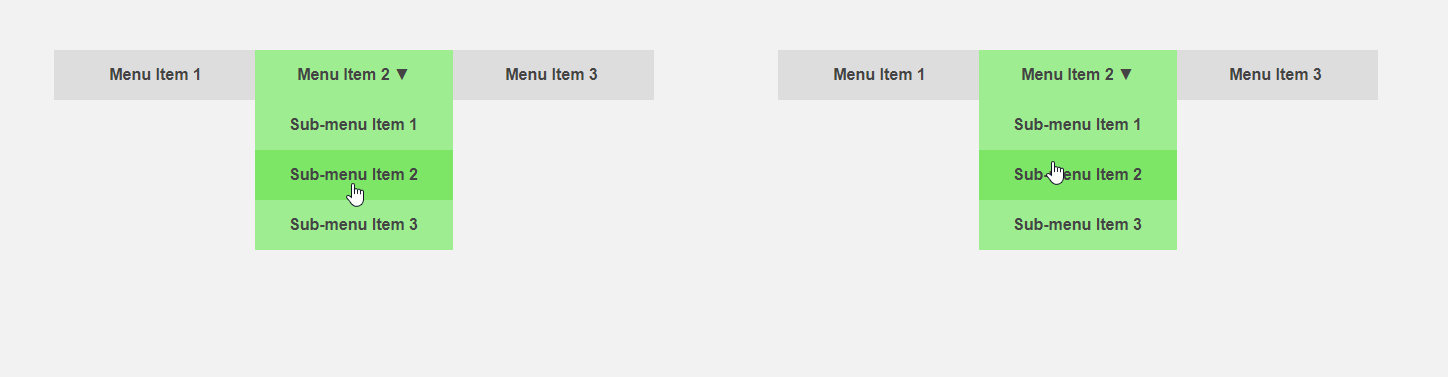
من ناحية أخرى ، سيكون من المثير للاهتمام الحصول على واجهة تخبر المستخدم مسبقًا عن تفاصيل عنصر ما أو تقوم بجزء من العمل الروتيني من أجله. يتحرك المؤشر باتجاه عنصر القائمة - يمكنك توسيع القائمة الفرعية مقدمًا ، وبالتالي تسريع التفاعل مع الواجهة ، يقوم المستخدم بنقل المؤشر إلى الزر - يمكنك تحميل محتوى إضافي مطلوب فقط بعد النقر. يقارن عنوان المقالة الواجهة القياسية (يسار) والتنبؤ.
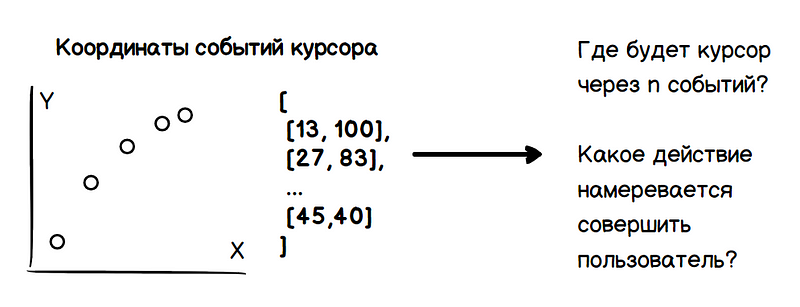
يُظهر اختبار مرئي بسيط أنه من خلال تحليل سرعة المؤشر ومشتقاته ، من الممكن توقع اتجاه الحركة وإحداثيات التوقف في عدد معين من الخطوات. بالنظر إلى أن أحداث الحركة يتم تشغيلها بتردد ثابت بالنسبة لحجم التسارع ، فإن السرعة تقل عند الاقتراب من الهدف. وبالتالي ، يمكنك معرفة الإجراء المخطط له من قبل المستخدم مقدمًا ، مما يؤدي إلى الفوائد المعلنة بالفعل.

وبالتالي ، تتضمن المشكلة مهمتين: تحديد الإحداثيات المستقبلية للمؤشر وتحديد نوايا المستخدم (التمرير بالماوس والنقر والتمييز وما إلى ذلك). يجب الحصول على كل هذه البيانات فقط على أساس تحليل القيم السابقة لإحداثيات المؤشر.
تتمثل المهمة الأساسية في تقييم اتجاه حركة المؤشر بدلاً من التنبؤ بلحظة التوقف ، وهي مشكلة أكثر تعقيدًا. كتقدير لمعلمات كمية صاخبة ، يمكن حل مشكلة حساب اتجاه الحركة من خلال مجموعة من الطرق المعروفة.
الخيار الأول الذي يتبادر إلى الذهن هو مرشح
متوسط متحرك . زيادة السرعة في اللحظات السابقة ، يمكنك الحصول على قيمتها في ما يلي. يمكن تقييم القيم السابقة وفقًا لقانون معين (خطي ، أسي ، أسي) لتعزيز تأثير أقرب الدول ، مما يقلل من مساهمة القيم البعيدة.
خيار آخر هو استخدام خوارزمية متكررة ، مثل
مرشح الجسيمات . لتقييم سرعة المؤشر ، ينشئ المرشح العديد من الفرضيات حول القيمة الحالية للسرعة ، وتسمى أيضًا الجزيئات. في اللحظة الأولى ، تكون هذه الفرضيات عشوائية تمامًا ، لكن على مدار الطريق ، يزيل المرشح فرضيات غير صالحة ويولد دوريًا في مرحلة إعادة التوزيع افتراضات جديدة تستند إلى افتراضات موثوقة. وبالتالي ، من مجموعة الفرضيات كنتيجة لذلك ، تبقى فقط تلك الأقرب إلى القيمة الحقيقية للسرعة.
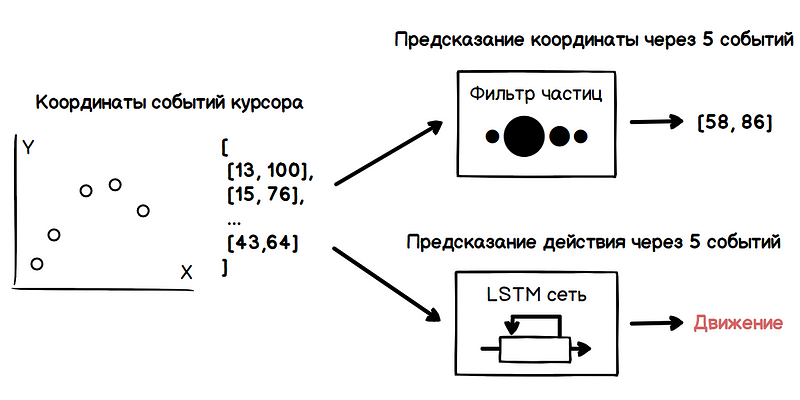
في المثال أدناه ، عند تحريك مؤشر كل جسيم للتصور ، تكون قيمة نصف القطر متناسبة بشكل مباشر مع وزنها. وبالتالي ، فإن المنطقة التي بها أعلى تركيز للجزيئات الثقيلة تميز الاتجاه الأكثر احتمالًا لحركة المؤشر.
ومع ذلك ، فإن اتجاه الحركة الذي تم الحصول عليه لا يكفي لتحديد نوايا المستخدم. مع كثافة عالية من عناصر الواجهة ، يمكن لمسار المؤشر أن يكمن فوق العديد منها ، مما سيؤدي إلى كتلة من الإيجابيات الخاطئة لخوارزمية التنبؤ. هنا تأتي أساليب التعلم الآلي في عملية الإنقاذ ، أي الشبكات العصبية المتكررة.
إحداثيات المؤشر هي سلسلة من القيم المرتبطة بقوة. عندما يتم إبطاء الحركة ، فإن الفرق بين إحداثيات المواقع المجاورة في الجدول الزمني يتناقص من حدث إلى آخر. الاتجاه العكسي ملحوظ في بداية الحركة - فواصل الإحداثيات تزداد. ربما ، مع دقة مقبولة ، يمكن أيضًا حل هذه المشكلة من خلال تحليل قيم المشتقات في أجزاء مختلفة من المسار وترميز عتبة الاستجابة استنادًا إلى سلوك هذه القيم. لكن بطبيعتها ، يبدو تسلسل الإحداثيات لمواقع المؤشر بمثابة مجموعة بيانات تتناسب تمامًا مع مبادئ تشغيل شبكات الذاكرة طويلة المدى على المدى الطويل.
شبكات
LSTM هي نوع معين من بنية الشبكات العصبية المتكررة ، وتكييفها لتدريب التبعيات طويلة الأجل. يتم تسهيل ذلك من خلال القدرة على تخزين المعلومات بواسطة وحدات الشبكة عبر عدد من الحالات. وبالتالي ، يمكن أن تحدد الشبكة العلامات المستندة إلى ، على سبيل المثال ، إلى متى تباطأ المؤشر ، وما سبقه ، وكيف تغيرت سرعة المؤشر في بداية التباطؤ ، وما إلى ذلك. تميز هذه العلامات أنماط معينة من سلوك المستخدم أثناء إجراءات معينة ، على سبيل المثال ، النقر فوق زر.
وبالتالي ، عند إجراء تحليل مستمر للبيانات التي تم الحصول عليها عند إخراج مرشح الجسيمات والشبكة العصبية ، نصل إلى اللحظة التي ، على سبيل المثال ، يمكنك إظهار القائمة المنسدلة ، حيث يقوم المستخدم بنقل المؤشر إليها لفتحه في الثانية التالية. عند إجراء هذا التحليل لكل حدث ماوس ، يصعب تفويت اللحظة المناسبة.
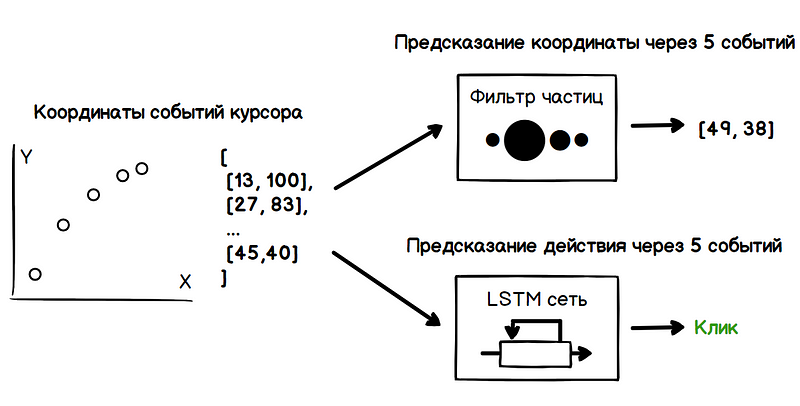
يمكن إجراء تدريب على شبكة LSTM على مجموعة من البيانات التي تم الحصول عليها في عملية تحليل سلوك المستخدم ، وتنفيذ سلسلة من المهام المصممة لتحديد معالمه عند التفاعل مع الواجهة: انقر فوق زر ، وحرك المؤشر فوق رابط ، وافتح القائمة ، وما إلى ذلك. فيما يلي مثال على إطلاق مصفوفة من العناصر التنبؤية التي تستند فقط إلى مرشح الجسيمات ، دون تحليل الشبكة العصبية.

توضح الرسوم المتحركة أدناه مساهمة الشبكة العصبية في عملية التنبؤ بسلوك المستخدم. ايجابيات كاذبة يصبح أقل من ذلك بكثير.

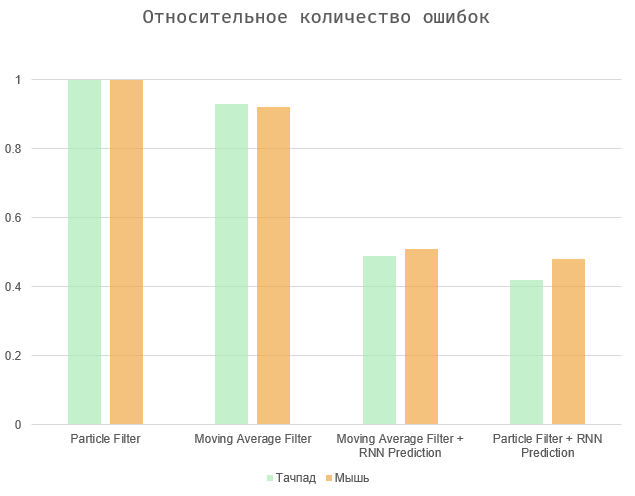
بشكل عام ، تتلخص المهمة في تحقيق التوازن بين كميتين - الفترة الزمنية بين الإجراء وتوقعه وعدد الأخطاء (الإيجابيات الزائفة والإغفالات). حالتان متطرفتان هما تحديد كل العناصر في الصفحة (الحد الأقصى لفترة التنبؤ ، وعدد كبير من الأخطاء) ، أو لجعل الخوارزمية تعمل فورًا عندما يتصرف المستخدم (فترة التنبؤ الصفرية والأخطاء المفقودة).
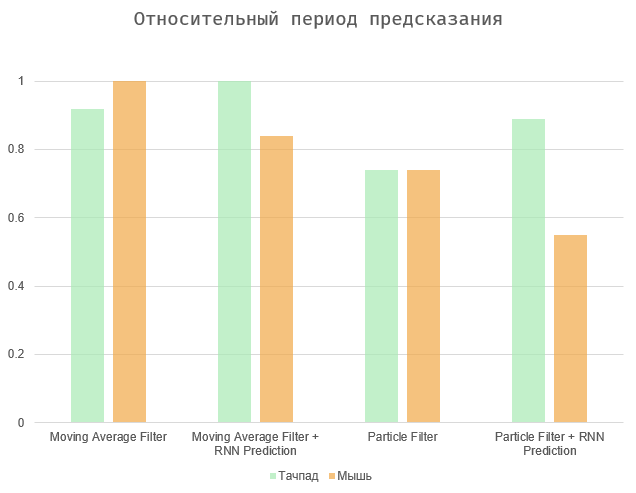
توضح الرسوم البيانية النتائج التي تم تطبيعها إلى الحد الأقصى للقيم ، نظرًا لأن سرعة المستخدم فردية بحتة ، ويعتمد عدد الأخطاء على الواجهة المعنية. خوارزميات مرشح المتوسط والجسيمات المتحركة تظهر نتائج مماثلة تقريبًا. والثاني هو أكثر دقة قليلاً ، خاصةً في حالة استخدام لوحة اللمس. في النهاية ، يمكن أن تعتمد كل هذه الخيارات اعتمادًا كبيرًا على المستخدم والجهاز المحدد.
في الختام ، عرض صغير للسلوك التنبئي لعناصر HTML ، بعيدًا عن المثالية ، ولكنه يكشف قليلاً.
بالطبع ، في مثل هذه المهام ، من الضروري تحقيق توازن بين الوظيفة والقدرة على التنبؤ. إذا كان السلوك الناتج غير واضح للمستخدم ، فسوف يؤدي الإزعاج الناتج إلى إلغاء كل الجهود. من الصعب التحدث عما إذا كان من الممكن جعل عملية تعلم الخوارزمية غير مرئية للمستخدم ، على سبيل المثال ، في الجلسات الأولى من اتصاله بواجهة الصفحة ، بحيث باستخدام الخوارزميات المدربة ، ثم جعل عناصر الواجهة تتصرف بشكل تنبؤي. في أي حال ، سيكون التدريب الإضافي ضروريًا بسبب الخصائص الفردية لكل شخص وهذا موضوع بحث إضافي.