عادة ما يتم هيكلة برنامج التحويل البرمجي AOT الأمثل كما يلي:
- الواجهة الأمامية لتحويل شفرة المصدر إلى التمثيل الوسيط
- خط أنابيب التحسين المستقل عن الآلة (IR): سلسلة من التمريرات التي تعيد كتابة IR لإزالة الأجزاء غير الفعالة والكيانات التي لا يمكن تحويلها مباشرة إلى رمز الجهاز. في بعض الأحيان يسمى هذا الجزء منتصف النهاية.
- الواجهة الخلفية للجهاز لإنشاء رمز التجميع أو رمز الجهاز.

في بعض برامج التحويل البرمجي ، يظل تنسيق IR بدون تغيير خلال عملية التحسين ، في حالات أخرى ، يتغير تنسيقه أو دلالاته. في LLVM ، يتم إصلاح التنسيق والدلالات ، وبالتالي فمن الممكن تشغيل التمريرات في أي ترتيب دون التعرض لخطر التجميع أو المحول البرمجي غير الصحيح.
تم تطوير تسلسل تمريرات التحسين بواسطة مطوري برنامج التحويل البرمجي ، والهدف هو إكمال العمل في وقت مقبول. يتغير من وقت لآخر ، وبالطبع ، هناك مجموعة مختلفة من التصاريح لتشغيلها بمستويات تحسين مختلفة. يتمثل أحد الموضوعات طويلة الأجل في أبحاث الكمبيوتر في استخدام التعلم الآلي أو طرق أخرى للعثور على أفضل خط أنابيب للاستخدام العام والتطبيقات المحددة التي لا يكون خط الأنابيب الافتراضي مناسبًا لها.
مبادئ تصميم المقاطع هي بساطتها وتعامدها: كل ممر يجب أن يفعل شيئًا واحدًا جيدًا ، ويجب ألا تتداخل وظائفه. في الممارسة العملية ، حلول وسط ممكنة في بعض الأحيان. في الممارسة العملية ، عندما يولد شخصان العمل لبعضهما البعض ، يمكن دمجهما في مسار أكبر واحد. أيضًا ، فإن بعض وظائف مستوى IR ، مثل المشغلات الثابتة القابلة للطي ، مفيدة جدًا بحيث لا معنى لوضعها في مسار منفصل ، حيث يقلل LLVM افتراضيًا من العمليات المستمرة عند إنشاء تعليمة.
في هذا المنشور ، سنرى كيف تنجح بعض عمليات تحسين LLVM. أعني أنك قرأت
هذا الجزء حول كيفية تجميع Clang للوظيفة أو أنك تفهم بشكل أو بآخر كيفية عمل LLVM IR. يعد فهم نموذج SSA (التعيين الفردي الثابت) مفيدًا بشكل خاص: ستقدم لك
Wikipedia مقدمة ، وسيمنحك
هذا الكتاب معلومات أكثر مما تريد أن تعرفه. اقرأ أيضًا
مرجع لغة LLVM وتمرير قائمة التحسين .
دعونا نرى كيف يقوم Clang / LLVM 6.0.1 بتحسين كود C ++ هذا:
bool is_sorted(int *a, int n) { for (int i = 0; i < n - 1; i++) if (a[i] > a[i + 1]) return false; return true; }
في الوقت نفسه ، نتذكر أن خط أنابيب التحسين هو مكان مزدحم للغاية ، وسنفقد الكثير من اللحظات الممتعة ، مثل:
التجسيد هو تحسين بسيط ولكنه مهم للغاية لا يحدث في هذا المثال ، لأن نحن نعتبر وظيفة واحدة فقط. تقريبًا كل التحسينات الخاصة بـ C ++ ، ولكن ليس إلى C. الاتجه التلقائي ، مما يمنع الخروج المبكر من الحلقة
في النص أدناه ، سوف أتخطى جميع التصاريح التي لا تجري تغييرات على الكود. أيضًا ، لن ننظر إلى الواجهة الخلفية ، التي تؤدي أيضًا الكثير من العمل. ولكن حتى المقاطع المتبقية هي الكثير! (آسف للصور ، ولكن يبدو أن هذا هو أفضل طريقة لتجنب صعوبات التنسيق).
فيما يلي ملف الأشعة تحت الحمراء الذي أنشأه Clang (قمت بحذف سمة "optnone" التي أدخلها Clang يدويًا) وسطر الأوامر المستخدم لرؤية تأثير كل عملية مرور تحسين:
opt -O2 -print-before-all -print-after-all is_sorted2.ll
أول تمرير هو
تبسيط CFG (الرسم البياني لتدفق التحكم). نظرًا لأن Clang لا يقوم بالتحسين ، فإن IR التي يولدها تحتوي على خيارات تحسين بسيطة:

هنا ، الوحدة الأساسية 26 تنتقل ببساطة إلى الكتلة 27. يمكن حذف هذه الكتل عن طريق إعادة توجيه المراجع إليها بواسطة كتلة الوجهة. سوف LLVM ترقيم الكتل تلقائيا. يتم سرد القائمة الكاملة للتحويلات التي تنتجها SimplifyCFG في الجزء العلوي من الممر.
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
تظهر معظم فرص تحسين CFG كنتيجة لتمريرات LLVM الأخرى. على سبيل المثال ، يمكن أن يؤدي حذف إزالة الكود الميت ونقل المتغيرات الثابتة للحلقة إلى كتل قاعدة فارغة.
المقطع التالي ،
SROA (استبدال عددي للركام) ، هو أحد أكثر الطرق استخدامًا. يؤدي اسمها إلى بعض الالتباس لأن SROA ليست سوى واحدة من وظائفها. يتحقق التمرير من كل إرشادات تخصيص (تخصيص الذاكرة في مكدس الوظائف) ، ويحاول تحويله إلى سجلات SSA. تتحول تعليمة تخصيص واحد (
أي ، في الواقع ، متغير في حزمة التقريب. ترجمة ..) إلى العديد من السجلات إذا تم تعيينها بشكل ثابت عدة مرات ، وأيضًا ، إذا كانت التخصيصات فئة أو بنية ، يتم تقسيمها إلى مكونات (تسمى هذه "العددية" استبدال "المشار إليها في اسم المقطع). قد تستسلم نسخة بسيطة من SROA لتكدس المتغيرات التي تستخدم فيها عملية أخذ عنوان ، لكن إصدار LLVM يتفاعل مع خوارزمية تحليل الاسم المستعار ويعمل بطريقة ذكية (على الرغم من أن هذا غير مطلوب في المثال التالي).

بعد SROA ، تختفي تعليمات تخصيص (وتعليمات التحميل والتخزين المقابلة) ، ويصبح الرمز أكثر نظافة وأكثر ملاءمة للتحسينات اللاحقة (بالطبع ، لا يمكن لـ SROA حذف جميع التخصيصات في الحالة العامة ، وهذا يحدث فقط إذا كان تحليل المؤشر يمكن تخلص تماما من الأسماء المستعارة). في هذه العملية ، تقوم SROA بإدراج تعليمات phi في التعليمات البرمجية. تشكل تعليمات phi جوهر تمثيل SSA ، ويخبرنا نقص phi في التعليمات البرمجية التي ينشئها Clang أن Clang يولد إصدارًا تافهًا من SSA ، حيث يتم توصيل الكتل الأساسية من خلال الذاكرة وليس من خلال سجلات SSA.
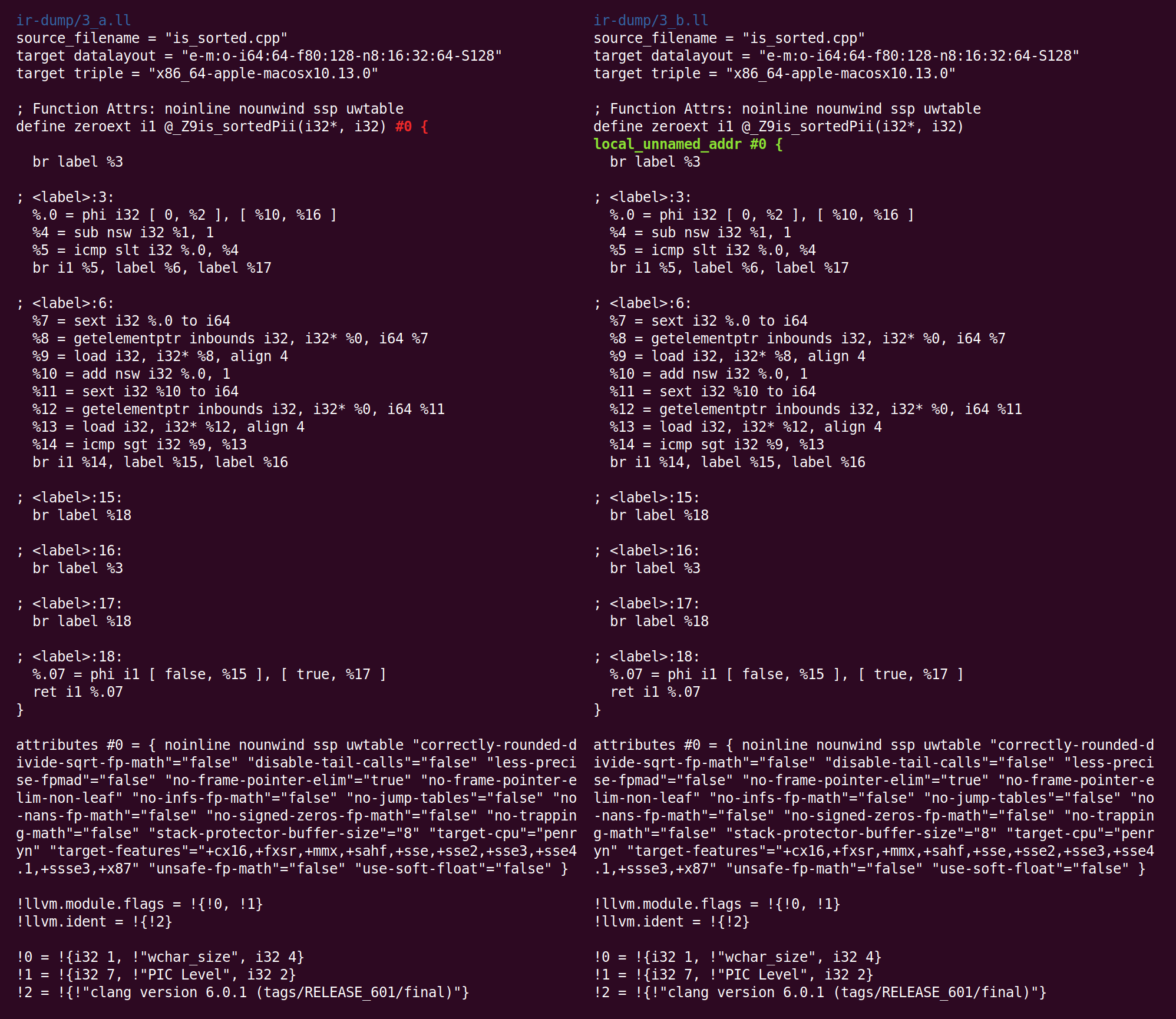
ما يلي هو "
التخلص المبكر من التعبير الشائع " ، CSE (الإزالة المبكرة للمصطلحات الفرعية الشائعة). يحاول CSE التخلص من حالات التعبيرات الفرعية المفرطة التي يمكن أن تحدث في الشفرة المكتوبة بواسطة الإنسان وفي الشفرة المحسنة جزئيًا. "CSE المبكر" هو إصدار سريع وسهل من CSE يحدد الحسابات التافهة التافهة.

هنا ، يقوم٪ 10 و٪ 17 بعمل نفس الشيء ، أي أنه يمكن إعادة كتابة الرمز بحيث يتم استخدام قيمة واحدة ويتم حذف الثانية. هذا يعطي بعض نظرة ثاقبة فوائد SSA: عندما يتم تعيين كل سجل مرة واحدة فقط ، لا يوجد شيء مثل إصدارات متعددة من سجل واحد. وبالتالي ، يمكن اكتشاف العمليات الحسابية الزائدة باستخدام معادلة النحوية ، دون استخدام تحليل متعمق للبرنامج (هذا ليس هو الحال بالنسبة لمواقع الذاكرة الموجودة خارج عالم SSA).
بعد ذلك ، يتم إطلاق العديد من التصاريح التي ليس لها أي تأثير في حالتنا ، ثم يتم إطلاق "
مُحسِّن المتغير الشامل " ، الموضح على النحو التالي:
, . , , , , ..يجري هذا المقطع التغييرات التالية:
وأضاف سمة دالة: بيانات التعريف المستخدمة من قبل جزء واحد من المترجم لتخزين المعلومات حول ما قد يكون مفيدا لجزء آخر من المترجم. يمكنك أن تقرأ عن الغرض من هذه السمة
هنا .
على عكس التحسينات الأخرى التي أخذناها في الاعتبار ، فإن مُحسِّن المتغيرات العامة هو interprocedural ؛ فهو ينظر تمامًا إلى وحدة LLVM. الوحدة النمطية (أكثر أو أقل) تعادل وحدة التحويل البرمجي في C و C ++. على عكس التحسين interprocedural ، ترى intraprocedural وظيفة واحدة فقط في كل مرة.
يجمع المقطع التالي بين الإرشادات ويسمى "
إرشادات الجمع" ، InstCombine. هذه مجموعة كبيرة ومتنوعة من
تحسينات ثقب الباب ، والتي (عادةً) تعيد كتابة بعض التعليمات ، مجتمعةً ببيانات مشتركة ، في شكل أكثر كفاءة. InstCombine لا يغير تدفق السيطرة على وظيفة. في المثال أعلاه ، لم يغير الكثير:
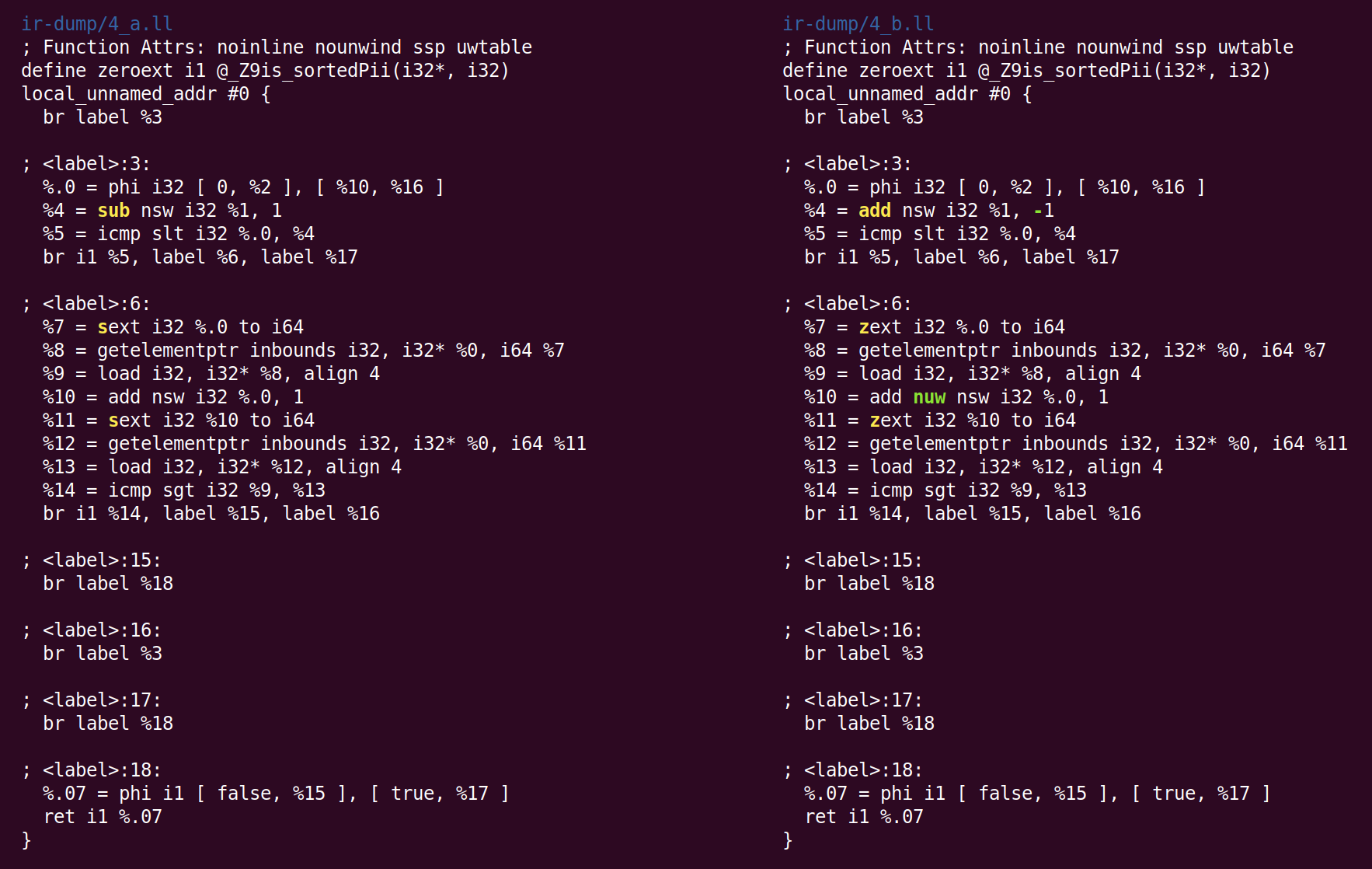
هنا ، بدلاً من طرح 1 من٪ 1 ، من أجل حساب٪ 4 ، نضيف -1. هذا ليس الأمثلية ، ولكن الكنسي. عندما يكون هناك العديد من الطرق لإجراء العملية الحسابية ، تحاول LLVM إحضارها إلى النموذج الأساسي (الذي يتم اختياره عشوائيًا في كثير من الأحيان) والذي يتوقعه المروري والواجهة الخلفية اللاحقة. التغيير الثاني الذي تم إجراؤه InstCombine هو الشكل المتعارف عليه لعمليات التوسيع الموقعة (تعليمة sext) ، والتي تحسب٪ 7 و٪ 11 محولة إلى صفر توسع (zext). هذا التحويل آمن عندما يستطيع المترجم أن يثبت أن معامل sext غير سالب. في هذه الحالة ، يكون هذا بسبب تغير متغير الحلقة من 0 إلى n (إذا كانت n سالبة ، لا يتم تنفيذ الحلقة على الإطلاق). كان آخر تغيير هو إضافة علامة "nuw" (بدون غلاف غير موقّع) إلى التعليمات التي تحسب٪ 10. يمكننا أن نرى أنه آمن ، من حقيقة أن (1) متغير الحلقة دائمًا يزداد و (2) إذا كان المتغير يبدأ من الصفر ويزيد ، فسيصبح غير محدد عند تغيير علامة التقاطع عند تقاطع INT_MAX قبل أن يصل إلى تجاوز سعة غير موقعة ، بعد UINT_MAX. يمكن استخدام هذه العلامة للتحسينات اللاحقة.
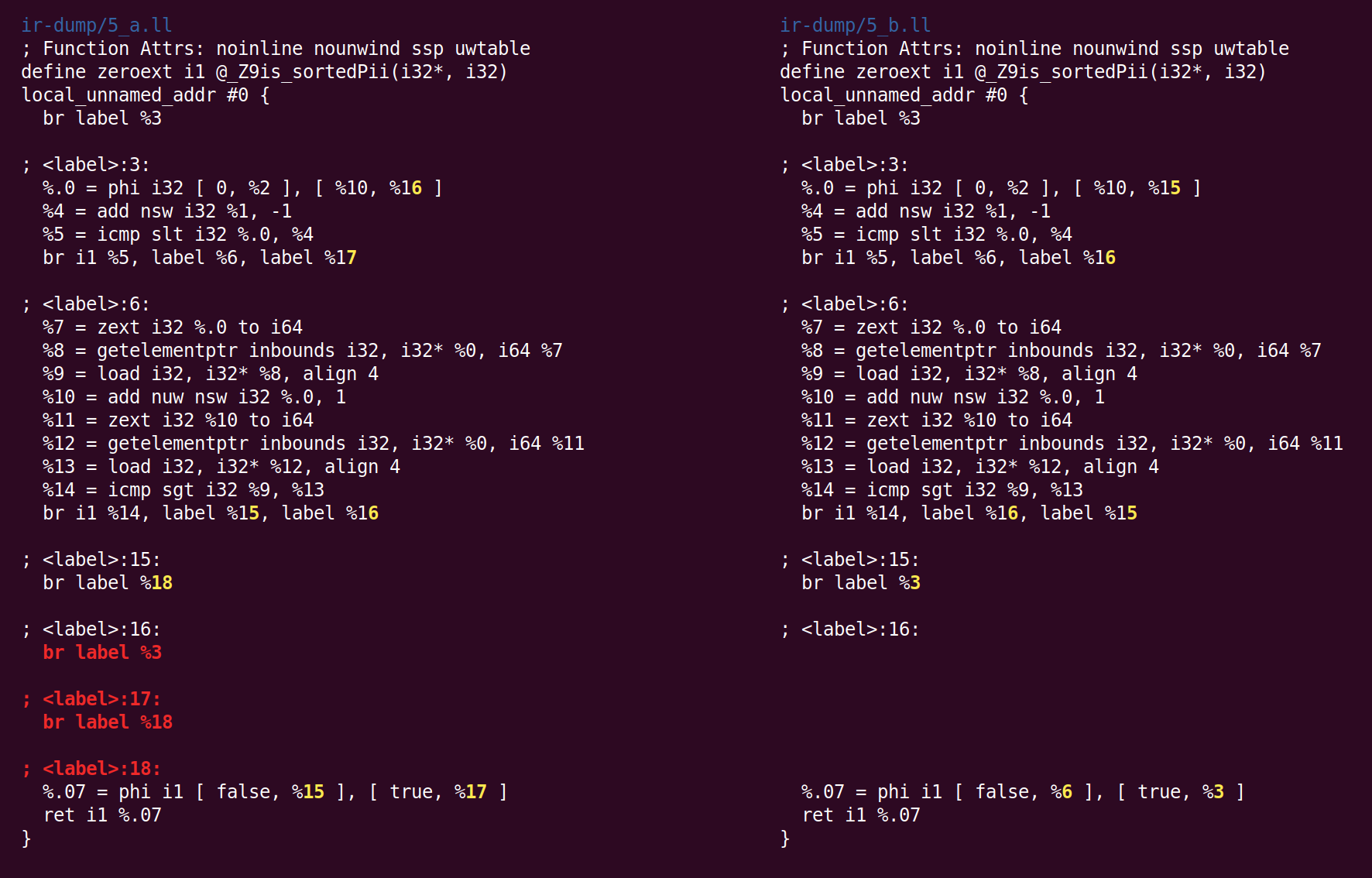
بعد ذلك ، يبدأ SimplifyCFG للمرة الثانية ، ويزيل كتلتين أساسيتين فارغتين:
بعد ذلك ، تقوم وظيفة "استنتاج سمات الدالة" بتعليق الوظيفة:

"Norecurse" تعني أن الوظيفة ليست مدرجة في أي مكالمات متكررة ، يعني "readonly" أن الوظيفة لا تغير الحالة العالمية. تعني سمة المعلمة "nocapture" أن المعلمة لا يتم حفظها في أي مكان بعد الخروج من الوظيفة ، و "للقراءة فقط" تعني أن الذاكرة لا يتم تعديلها بواسطة الوظيفة. يمكنك الاطلاع على
قائمة بسمات الوظائف وسمات المعلمات .
ثم يقوم تمرير "
تدوير الحلقات " بنقل الكود في محاولة لتحسين شروط التحسينات اللاحقة:

على الرغم من أن الفارق يبدو مخيفًا ، إلا أن التغييرات صغيرة بالفعل. يمكننا أن نرى ما حدث ، بطريقة أكثر قابلية للقراءة ، إذا طلبنا من LLVM أن ترسم رسمًا بيانيًا لنقل التحكم قبل وبعد دورات التناوب. هنا وجهة نظرهم قبل (يسار) وبعد (يمين):
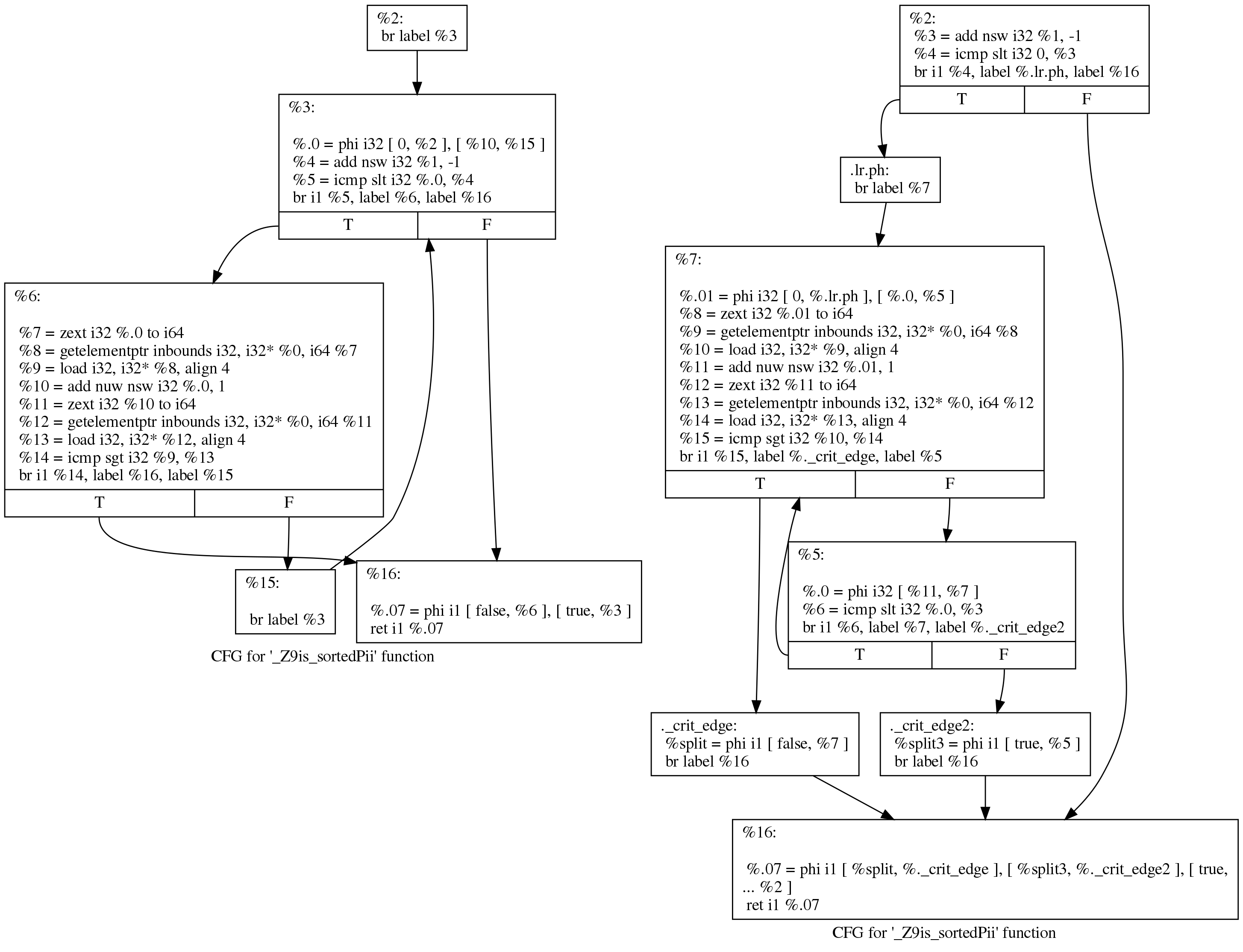
لا يزال الكود الأصلي يتبع بنية الحلقة التي أنشأها Clang:
initializer goto COND COND: if (condition) goto BODY else goto EXIT BODY: body modifier goto COND EXIT:
بعد التشغيل ، تبدو الحلقة كما يلي:
initializer if (condition) goto BODY else goto EXIT BODY: body modifier if (condition) goto BODY else goto EXIT EXIT:
(تصحيحات مقترحة من قبل Johannes Durfert مذكورة أدناه - شكرًا!)
الغرض من تمرير دوران الحلقة هو إزالة فرع واحد ، مما يسمح بمزيد من التحسينات. لم أجد وصفًا أفضل لهذا التحويل على الإنترنت.
يقلل تمرير تبسيط CFG من كتلتين أساسيتين لا تحتويان إلا على إرشادات phi تنكس (إدخال واحد):

يتحول مسار دمج التعليمات "٪ 4 = 0 s <(٪ 1 - 1)" إلى "٪ 4 =٪ 1 s> 1 ″ (حيث <s و و s> عمليات لمقارنة المعاملات الموقعة) ، هذا تحويل مفيد ، فهو يقلل من طول سلاسل التبعية ويمكنه أيضًا إنشاء تعليمات "ميتة" (يتعذر الوصول إليها) (انظر
التصحيح الذي يفعل هذا). يزيل هذا المرور أيضًا إرشادات phi التافهة التي تمت إضافتها بواسطة تمرير دوران الحلقة.

فيما يلي المقطع "
تعميم الحلقات الطبيعية " ، الموضح في الكود المصدري الخاص به على النحو التالي:
, .
(Loop pre-header) , , . ,, LICM.
, , ( ) ( ). , , "store-sinking", LICM.
, (backedge).
Indirectbr . , . , , .
, simplifycfg , , , .
, , CFG, .
هنا نرى أنه تم إدراج كتلة الإخراج:
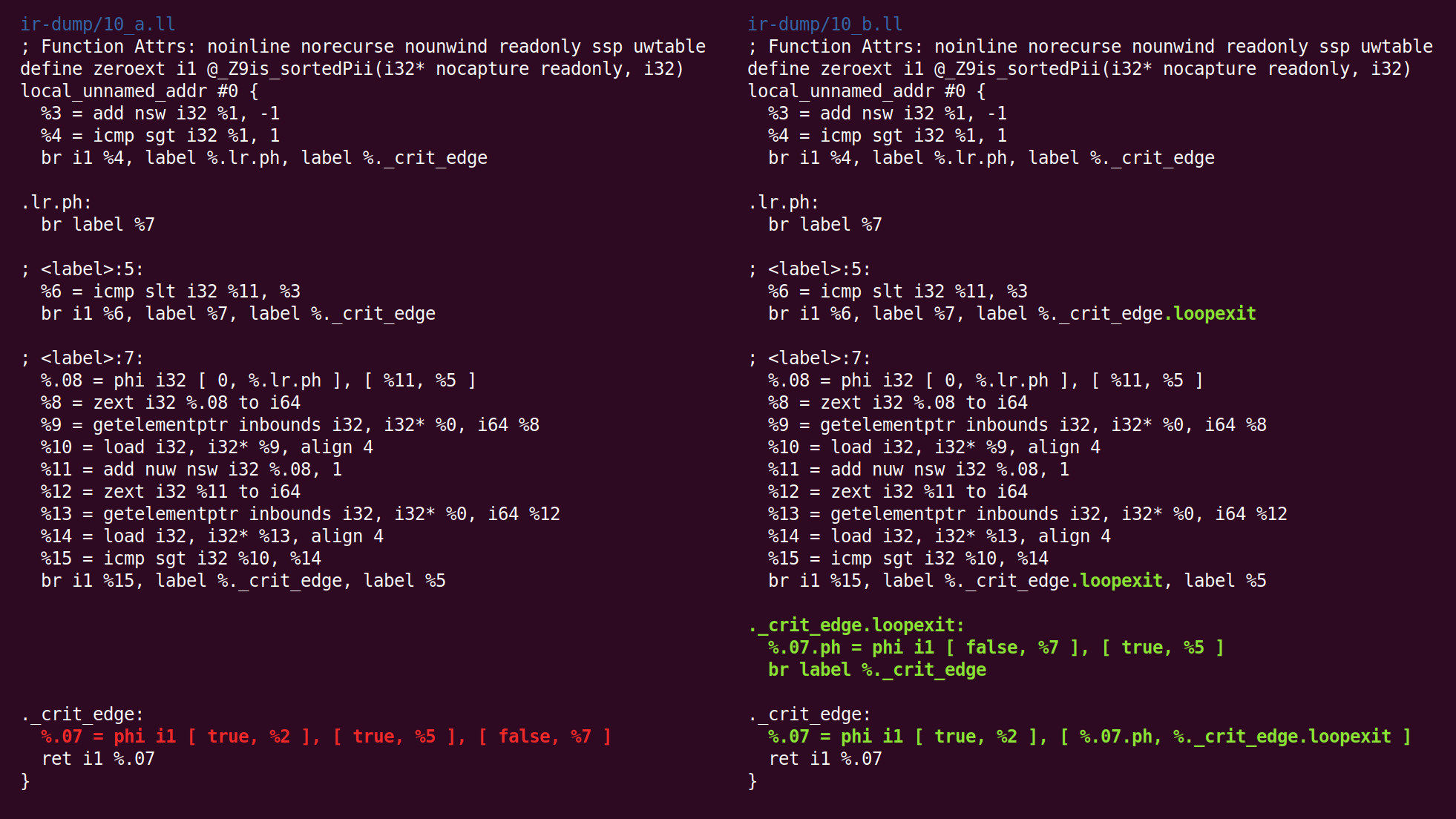
ثم يتبع "
تبسيط متغير الحلقة ":
( , ), , .
, :
, . , 'for (i = 7; i*i < 1000; ++i)' 'for (i = 0; i != 25; ++i)'.
indvar , . , "".
سيكون تأثير هذا التمرير لتغيير المتغير حلقة 32 بت إلى 64 بت:
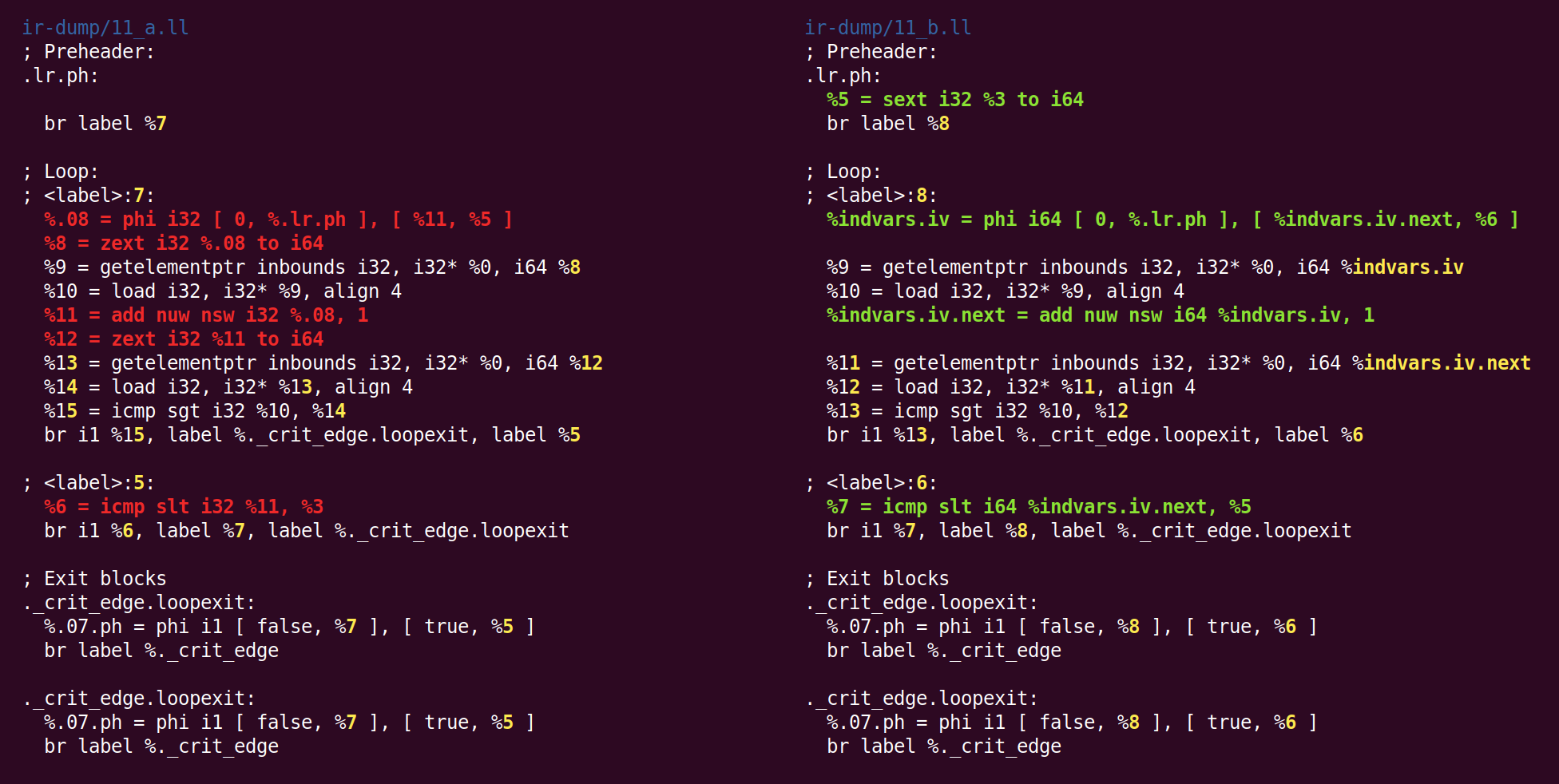
أنا لا أعرف لماذا zext - يلقي سابقا إلى شكل الكنسي من sext ، عاد مرة أخرى إلى sext.
الآن يمر "
ترقيم القيمة العالمية " بتحسين ذكي للغاية. أحد أسباب كتابة هذا المنشور هو الرغبة في إظهاره. هل تستطيع رؤيتها هنا؟

هل رأيت نعم ، إرشادات التحميل في الحلقة الموجودة على اليسار ، المقابلة لـ [i] و [i + 1]. هنا ، وجدت GVN أن [i] ليست هناك حاجة للتحميل ، لأنه [i + 1] من تكرار واحد للحلقة يمكن نقلها إلى التالي ، مثل [i]. هذه الخدعة البسيطة تقلل من عدد قراءات الذاكرة التي تؤديها الوظيفة بمقدار النصف. لقد تعلمت كل من LLVM و
GCC أداء هذا التحول في الآونة الأخيرة فقط.
قد تسأل نفسك ما إذا كانت هذه الحيلة ستعمل إذا قارنا [i] بـ [i + 2]. اتضح أنه لا ، ولكن يمكن لمجلس التعاون الخليجي تخصيص
ما يصل إلى أربعة سجلات لمثل هذه الحالات.
ثم يبدأ تمرير "
إزالة كود ميت ميت ":
"Bit-Tracking Dead Code Elimination". (, "" "" ..) "" . , "" .لكن اتضح هنا أن مثل هذه الحيل ليست مطلوبة ، لأن الكود الوحيد الميت هو تعليمة GEP (مؤشر عنصر get) ، وأنه ميت بشكل تافه (حذف GVN تمريرة التحميل التي استخدمت العنوان المحسوب بهذه التعليمات):
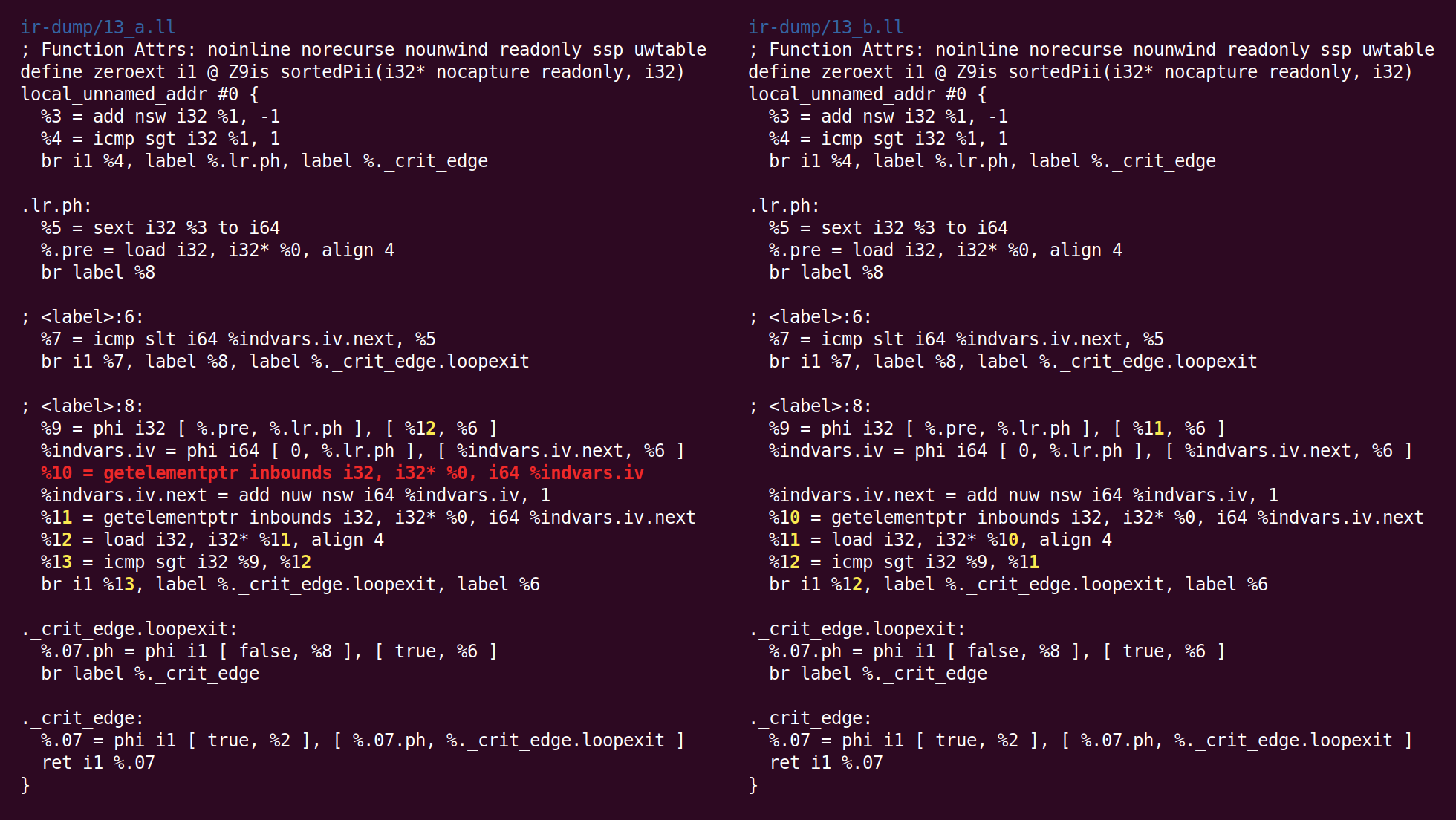
الآن وضعت خوارزمية الجمع بين التعليمات إضافة في وحدة أساسية أخرى. المنطق الذي وضع به هذا التحول في InstCombine ليس واضحًا بالنسبة لي ، ربما لم يكن هناك مكان واضح يمكن وضعه فيه:

يحدث شيء أكثر غرابة الآن: لقد
نجح تمريرة
القفز السريع في حذف ما قام به التمرير المعياري للحلقات الطبيعية من قبل:

ثم نحن مرة أخرى يلقي على شكل الكنسي:
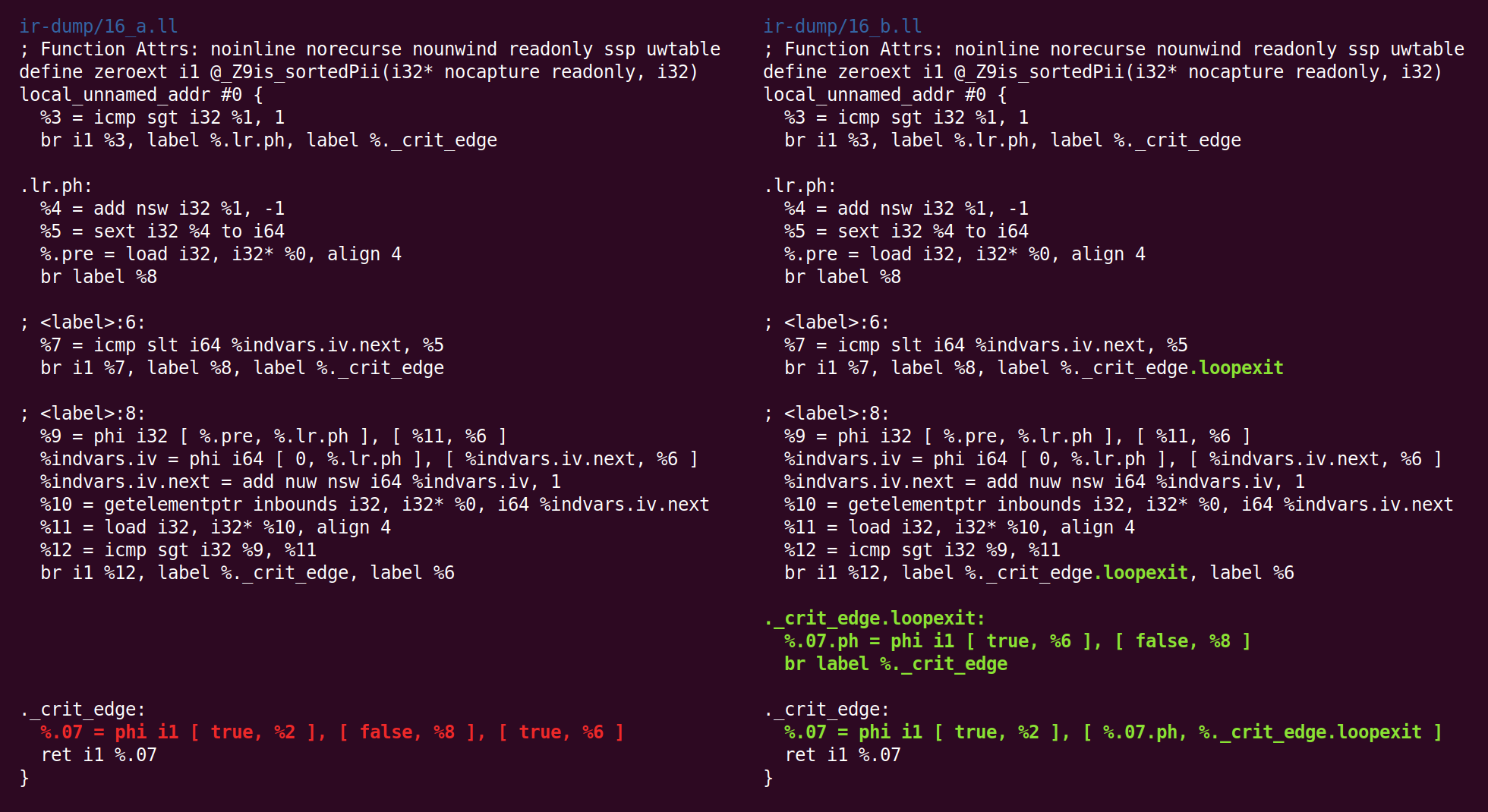
وتبسيط CFG يحولها بطريقة مختلفة:
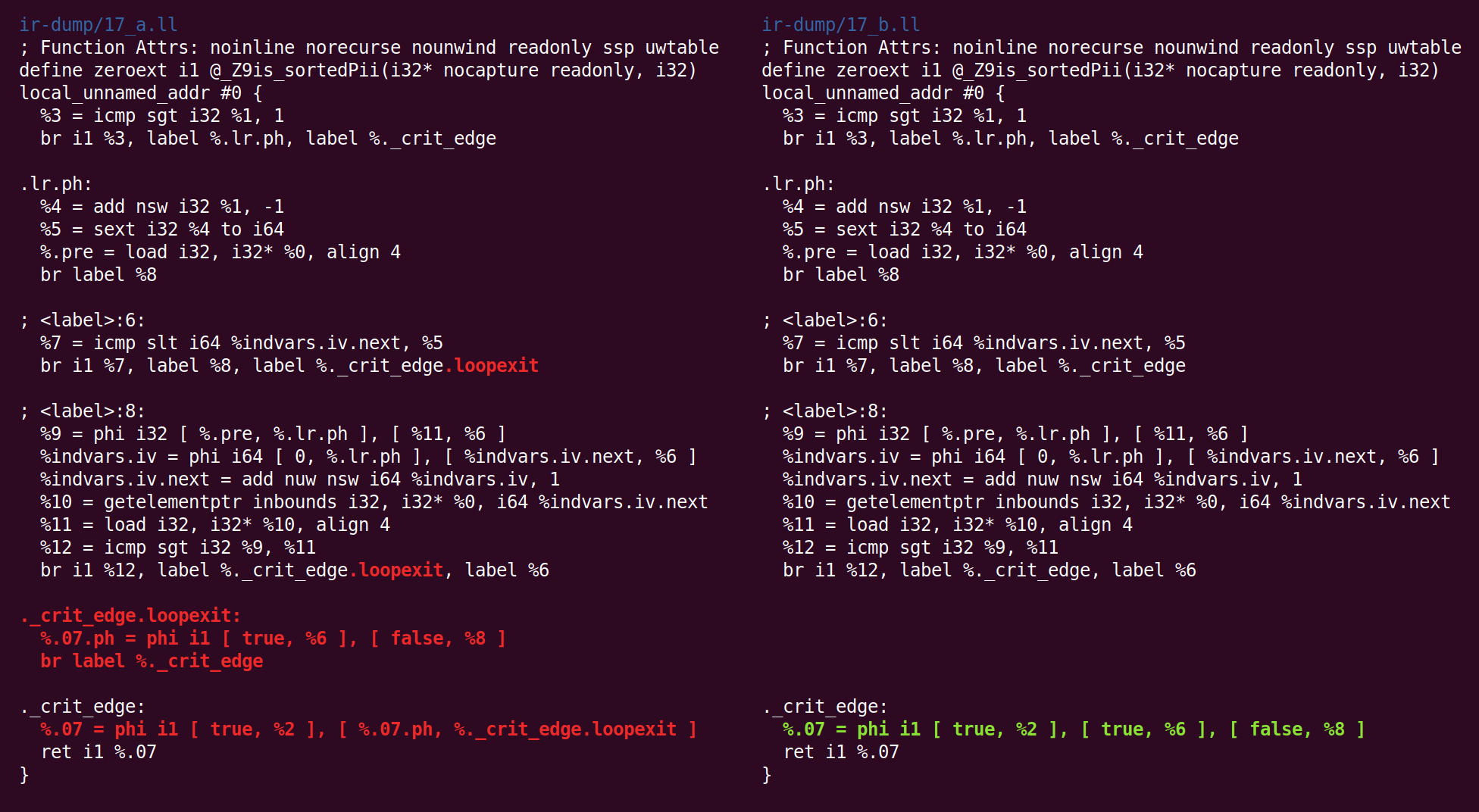
والعودة:
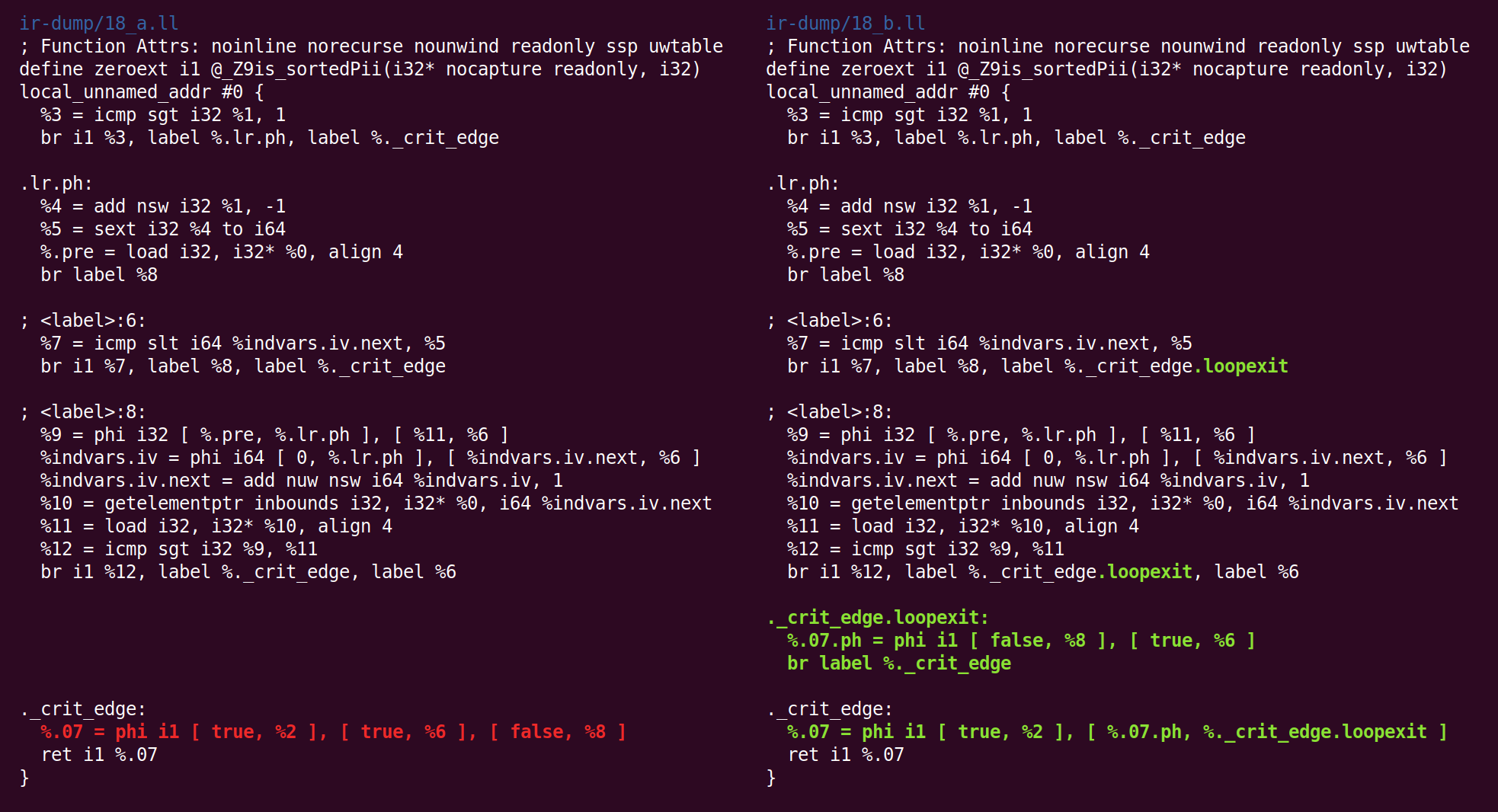
وهناك مرة أخرى:

والعودة:
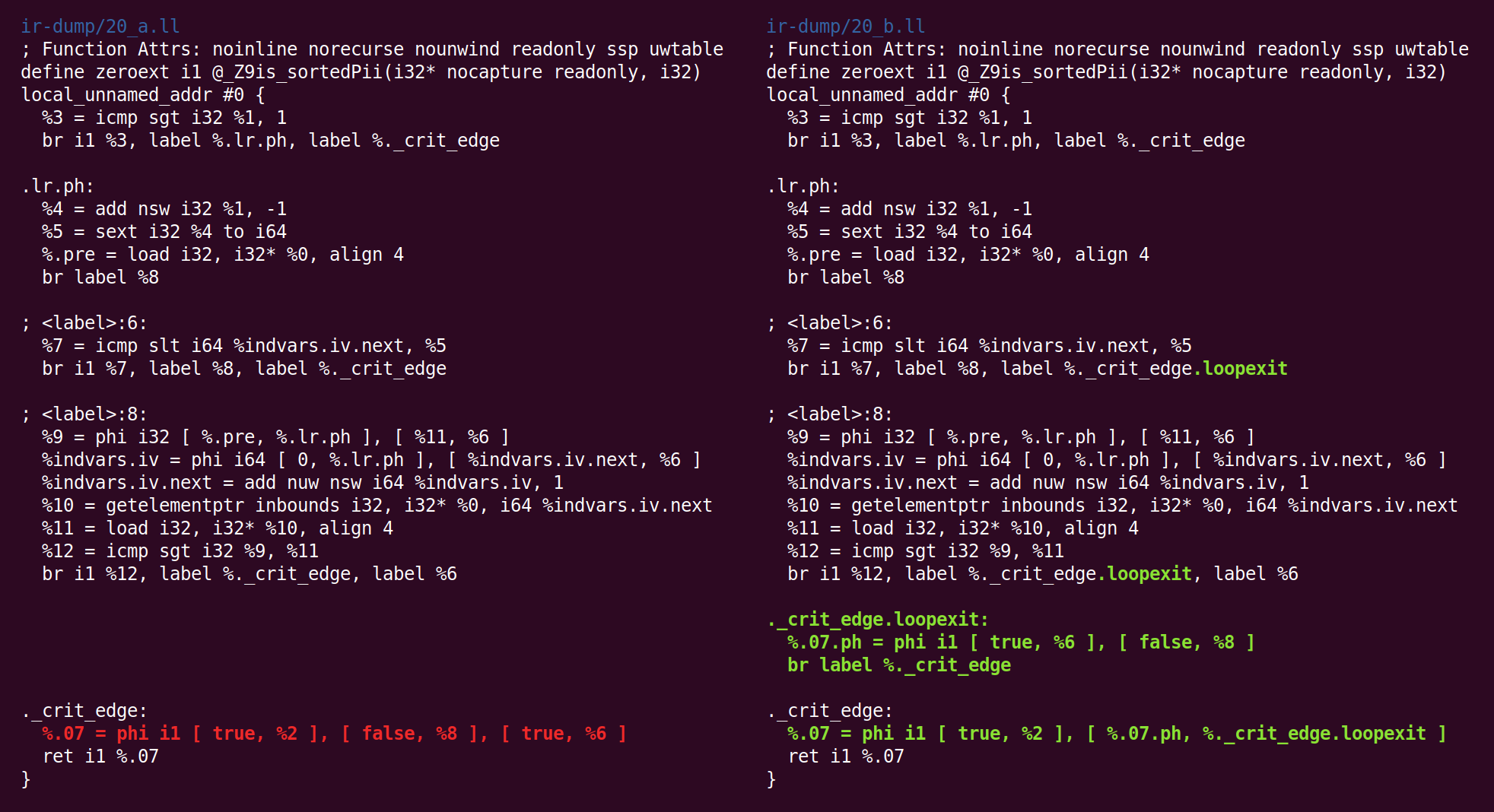
وهناك:

وأخيرا ، لقد انتهينا من ميدلاند! الرمز الموجود على اليمين هو الرمز الذي سننقله (في حالتنا) إلى الواجهة الخلفية x86-64.
قد تكون فضولياً إذا كانت التقلبات في السلوك في نهاية خط الأنابيب ناتجة عن خطأ في برنامج التحويل البرمجي ، ولكن دعنا نأخذ في الاعتبار أن هذه الوظيفة بسيطة للغاية وهناك الكثير من التمريرات التي تدخل في معالجتها ، لكنني لم أذكرها لأنهم لم تقم بإجراء أي تغييرات على الكود. خلال النصف الثاني من خط أنابيب التحسين ، نلاحظ بشكل رئيسي الحالات المتدهورة لهذه الوظيفة.
شكر وتقدير: ترك بعض الطلاب في دورة المترجم المتعمق في هذا الخريف تعليقاتهم على مسودة لهذا المنشور (كما أنني استخدمت هذه المادة في الواجب المنزلي). مشيت من خلال الوظائف التي تمت مناقشتها هنا في
هذه المجموعة الجيدة من المحاضرات حول تحسين الحلقة.