 من أحد المترجمين:
من أحد المترجمين: ننشر اليوم لك مقالًا مشتركًا من قبل ثلاثة مطورين ، وهم أكاش تشيكارمان وإرت بابلو ونيخيل غور ، الذي يصف طريقة التنبؤ بتصنيف التطبيقات في متجر Google Play.
في هذه المقالة ، سنعرض كيفية معالجة المعلومات التي نستخدمها للتنبؤ بالتصنيفات. سنشرح أيضًا لماذا نستخدم هؤلاء أو هؤلاء. سنتحدث عن تحويلات حزمة البيانات التي نعمل معها وحول ما يمكن تحقيقه باستخدام التصور.
توصي Skillbox بما يلي: دورة تدريبية لمدة عامين "أنا مطور ويب للمحترفين" .
نذكرك: لجميع قراء "Habr" - خصم بقيمة 10،000 روبل عند التسجيل في أي دورة تدريبية في Skillbox باستخدام الرمز الترويجي "Habr".
لماذا قررنا أن نفعل ذلك
أصبحت التطبيقات النقالة جزءًا لا يتجزأ من الحياة منذ فترة طويلة ، ويشارك المزيد والمزيد من المطورين في ابتكارهم وحدهم. علاوة على ذلك ، يعتمد الكثيرون بشكل مباشر على الدخل الذي تجلبه التطبيقات. لذلك ، فإن التنبؤ بالنجاح له أهمية كبيرة بالنسبة لهم.
هدفنا هو تحديد التصنيف الكلي للتطبيق ، للقيام بذلك بشكل شامل ، لأن الكثير من الناس يحكمون على البرنامج ، ويعتمدون فقط على عدد "النجوم" التي حددها المستخدمون. التطبيقات مع 4-5 نقاط هي أكثر مصداقية.
التحضير
يعمل معظم هذا المشروع مع البيانات ، بما في ذلك المعالجة المسبقة. نظرًا لأن جميع المعلومات مأخوذة من متجر Google Play ، فقد احتوت الصفائف الناتجة على الكثير من الأخطاء. استخدمنا العديد من نماذج الانحدار ، بما في ذلك Gradient-Boosting Regressor من حزمة XGBoost و Linear Regression و RidgeRegression.
جمع البيانات وتحليلها
يمكن
العثور على مجموعة البيانات التي عملنا
عليها هنا . يتكون من جزأين. الأول هو المعلومات الموضوعية ، مثل حجم التطبيق ، وعدد عمليات التثبيت ، والفئة ، وعدد المراجعات ، ونوع التطبيق ، ونوعه ، وتاريخ آخر تحديث ، وما إلى ذلك ، وذاتية ، أي مراجعات المستخدم.
تعرض المراجعات أنفسهم للتحليل. بعد مقارنة النتائج ، قررنا تضمين أو عدم تضمين بيانات المسح في النموذج النهائي.
شكلنا مجموعة بيانات موضوعية من 12 وظيفة ومتغير هدف واحد (تصنيف). وشملت الحزمة 10.8 ألف وحدة من المعلومات. أما بالنسبة لمراجعات المستخدمين ، فقد اخترنا أكثر 100 وظيفة ذات صلة واستخدمنا 64.3 ألف عنصر. تم جمع جميع البيانات مباشرة من متجر Google Play ، وكانت آخر مرة تم تحديثها قبل ثلاثة أشهر.
معالجة البيانات مسبقا
كانت المجموعة الأولى من المعلومات تبدو كالتالي:
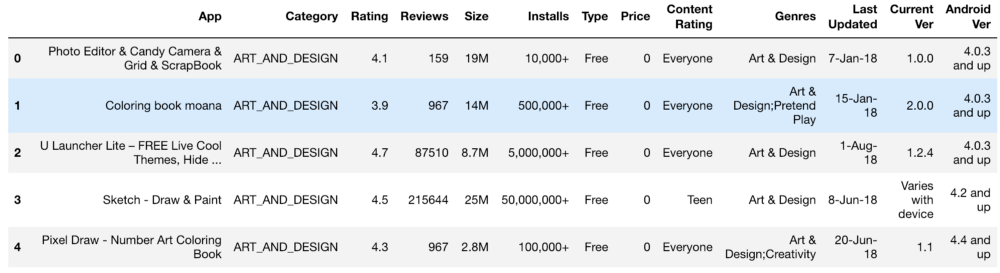
الإعدادات والتصنيف والتكلفة والحجم - لقد عالجنا كل هذا بطريقة للحصول على أرقام مفهومة للجهاز. عند معالجة الوظائف المختلفة ، نشأت مشاكل ، مثل الحاجة إلى إزالة "+". في التكلفة أزلنا $. تبين أن حجم التطبيق هو الأكثر إشكالية من حيث المعالجة ، حيث تم العثور على كل من KB و MB ، لذلك كان من الضروري القيام ببعض الأعمال لتقليل كل شيء إلى تنسيق واحد. يتم عرض البيانات الأساسية أدناه وهي أيضًا بعد المعالجة.
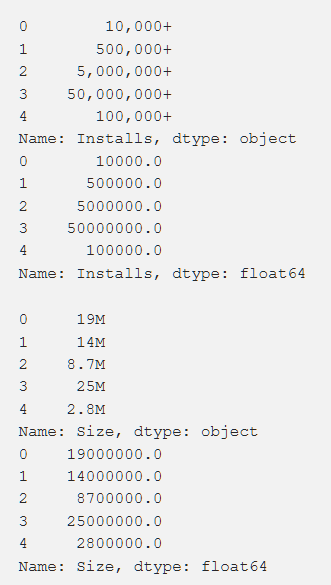
بالإضافة إلى ذلك ، قمنا بتحويل بعض البيانات ، وجعلها أكثر صلة بعملنا. على سبيل المثال ، لم تكن المعلومات حول آخر تحديث للتطبيق مفيدة للغاية. لجعلها أكثر معنى ، قمنا بتحويلها إلى معلومات حول الوقت المنقضي منذ التحديث الأخير. يظهر رمز هذه المهمة أدناه.
from datetime import datetime from dateutil.relativedelta import relativedelta n = 3
كان من الضروري أيضًا إحضار متغيرات قياسية مفردة ذات قيم مختلفة (على سبيل المثال ، "النوع"). كيف تم القيام بذلك هو مبين أدناه.
from copy import deepcopy from sklearn.preprocessing import LabelEncoder def one_hot_encode_by_label(df, labels): df_new = deepcopy(df) for label in labels: dummies = df_new[label].str.get_dummies(sep = ";") df_new = df_new.drop(labels = label, axis = 1) df_new = df_new.join(dummies) return df_new def label_encode_by_label(df, labels): df_new = deepcopy(df) le = LabelEncoder() for label in labels: print(label + " is label encoded") le.fit(df_new[label]) dummies = le.transform(df_new[label]) df_new.drop(label, axis = 1) df_new[label] = pd.Series(dummies) return df_new
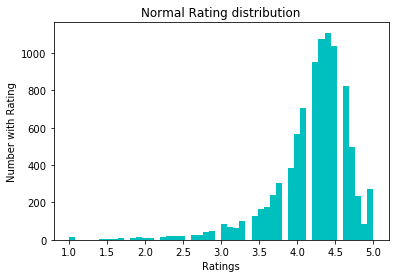
لتطبيع البيانات ، حاولنا تحويل log1p. قبله:
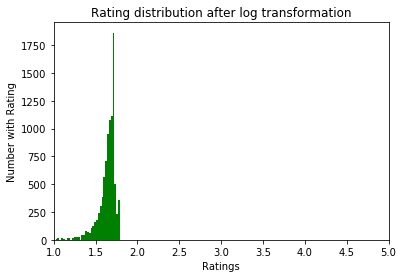
بعد:
استكشاف البيانات
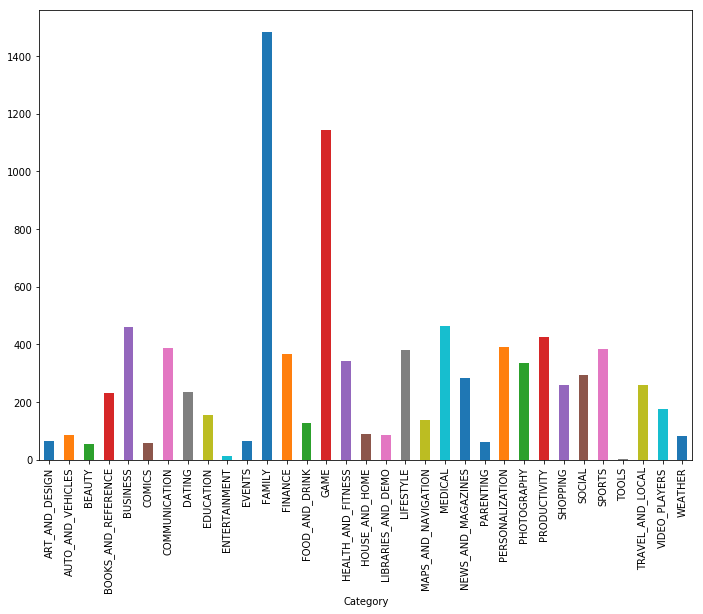
كما ترون ، الألعاب والتطبيقات للعائلة هي الفئتان الأكثر شعبية. وكانت معظم التطبيقات أيضا في فئة "لجميع الأعمار".
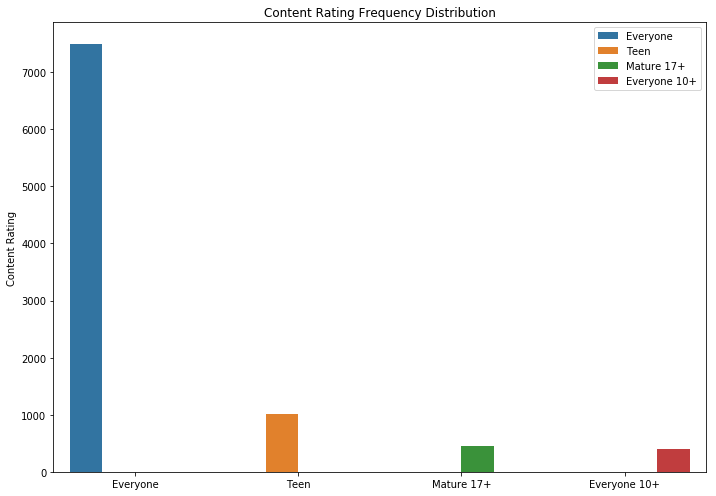

من المنطقي أن تحتوي التطبيقات ذات التصنيف الأقصى على تعليقات أكثر من التطبيقات ذات التصنيف المنخفض. البعض منهم قد الاستعراضات أكثر بكثير من جميع الآخرين. ربما يكون السبب في ذلك هو ظهور رسالة منبثقة أو دعوة للتقييم أو أساليب أخرى مماثلة.

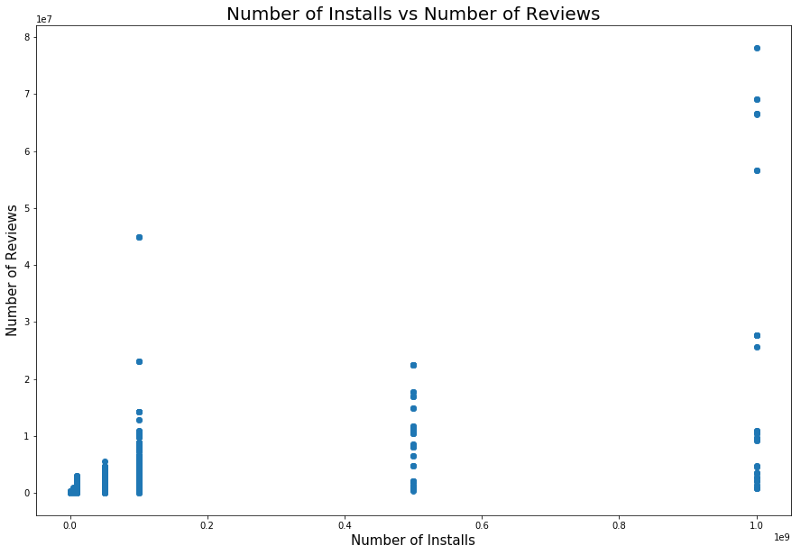
هناك أيضًا علاقة بين عدد المنشآت وعدد المراجعات. يظهر الارتباط في الصورة أدناه.
يمكن أن يقدم تحليل مفصل لهذا الاعتماد تفهمًا لماذا تحتوي فئات التطبيقات الشائعة على المزيد من عمليات التثبيت والمزيد من المراجعات.
النماذج والنتائج
استخدمنا تقسيم الاختبار لتقسيم البيانات إلى مجموعات اختبار وتدريب. تم استخدام التحقق من الصحة التبادلي مع GridSearchCV لتحسين نتائج التدريب النموذجية من أجل العثور على أفضل ألفا مع Lasso و Ridge Regression و XGBRegressor من حزمة XGBoost. النموذج الأخير فعال للغاية بشكل عام ، لكن عند استخدامه ، يجب أن يحذر المرء من تعديل النتائج - هذا أحد الأخطار التي تنتظر الباحثين. كانت قيمة جذر متوسط التربيع الأولي دون أي معالجة دقيقة للأشياء (الترميز والتنظيف فقط) حوالي 0.228.
بعد التحويل اللوغاريتمي للتقييمات ، انخفض الخطأ القياسي إلى 0.219 ، وكان هذا تحسنًا طفيفًا ، لكننا أدركنا أننا فعلنا كل شيء بشكل صحيح.
استخدمنا الانحدار الخطي بعد تقييم العلاقة بين المراجعات والمواقف والتصنيفات. على وجه الخصوص ، قمنا بتحليل المعلومات الإحصائية لهذه المتغيرات ، بما في ذلك r-squared و p ، واتخاذ قرار بشأن الانحدار الخطي نتيجة لذلك. أظهر نموذج الانحدار الخطي الأول المستخدم وجود علاقة بين الإعدادات وتصنيف 0.2233 ، ونموذج الانحدار الخطي أعطت مراجعاتنا وتقييماتنا MSE 0.207 ، ونموذج الانحدار الخطي المدمج ، والدراسات الاستقصائية ، والإعدادات ، والتصنيفات "، أعطانا MSE من 0.214.
بالإضافة إلى ذلك ، استخدمنا نموذج KNe neighbourresRegressor. نتائج استخدامه موضحة أدناه.

الاستنتاجات
بعد تحويل البيانات الأساسية من متجر Google Play إلى تنسيق قابل للاستخدام ، قمنا برسم واستخلاص وظائف لفهم الارتباط بين القيم الفردية. ثم تم استخدام هذه النتائج من أجل بناء نموذج مثالي.
في البداية ، اعتقدنا أنه لن يكون من الصعب العثور عليه ، حتى نتمكن من بناء نموذج دقيق. لكن المهمة كانت أكثر صعوبة مما توقعنا.
بالإضافة إلى ما تم إنجازه ، يمكنك أيضًا:
- إنشاء نموذج منفصل لكل نوع ؛
- إنشاء ميزات جديدة من إصدارات نظام التشغيل أندرويد ، كما فعلنا سابقًا مع التواريخ ؛
- لمعرفة الخوارزمية بشكل أعمق - كان لدينا عدد كافٍ من نقاط البيانات الفئوية والرقمية ؛
- تحليل البيانات بشكل واضح ومسحها من متجر تطبيقات Google.
جميع النتائج
متوفرة هنا .
توصي Skillbox بما يلي: