مرحبا بالجميع!
لنتحدث عن الشبكات العصبية والتعلم الآلي ، كما قد تفكر. من الواضح أن ما سيتم إخبارك به حول شبكات Mixture Density Networks ، ثم MDN فقط ، لا أريد ترجمة الاسم وتركه كما هو. نعم ، نعم ، نعم ... سيكون هناك القليل من الرياضيات ونظرية الاحتمالات المملة ، ولكن بدونها ، لسوء الحظ ، أو لحسن الحظ ، يعود الأمر لك لتقرير ما إذا كان من الصعب تخيل عالم التعلم الآلي. لكنني أسارع إلى طمأنتك ، ستكون صغيرة نسبيًا ولن تكون صعبة للغاية. على أي حال ، يمكنك تخطي ذلك ، لكن انظر فقط إلى كمية صغيرة من التعليمات البرمجية في Python و PyTorch ، هذا صحيح ، سنكتب الشبكة باستخدام PyTorch ، بالإضافة إلى الرسوم البيانية المختلفة مع النتائج. ولكن الشيء الأكثر أهمية هو أنه ستكون هناك فرصة لفهم القليل وفهم ما هي شبكات MD.
حسنًا ، لنبدأ!
الانحدار
بادئ ذي بدء ، دعنا نجدد معرفتنا قليلاً ونتذكر ، باختصار شديد ، ما
هو الانحدار الخطي .
لدينا ناقلات
X = \ {x_1 ، x_2 ، ... ، x_n \}X = \ {x_1 ، x_2 ، ... ، x_n \} نحن بحاجة إلى التنبؤ القيمة
Y ، والتي تعتمد بطريقة أو بأخرى على
X باستخدام بعض النماذج الخطية:
hatY=XT hat beta
كدالة خطأ ، سوف نستخدم الخطأ التربيعي:
SE( beta)= sumni=1(yi− hatyi)2= sumNi=1(yi−xTi hat beta)2
يمكن حل هذه المشكلة مباشرة عن طريق أخذ مشتق SE وتحديد قيمته على الصفر:
frac deltaSE( beta) delta beta=2XT( mathbfy−X beta)=0
وبالتالي ، نجد ببساطة الحد الأدنى ، و SE هي وظيفة من الدرجة الثانية ، مما يعني أن الحد الأدنى سيكون موجودًا دائمًا. بعد ذلك ، يمكنك بالفعل العثور بسهولة
beta :
hat beta=(XTX)−1XT mathbfy
هذا كل شيء ، تم حل المشكلة. هذا هو المكان الذي ننهي فيه تذكر ما هو الانحدار الخطي.
بالطبع ، يمكن أن يكون الاعتماد الملازم لطبيعة توليد البيانات مختلفًا ومن ثم يجب إضافة بعض اللاخطية بالفعل إلى نموذجنا. يعد حل مشكلة الانحدار مباشرةً للبيانات الكبيرة والحقيقية فكرة سيئة ، نظرًا لوجود مصفوفة
XTX الأبعاد
n مرةn ، ولا يزال يحتاج المرء إلى العثور على مصفوفة معكوس ، وغالبا ما يحدث أن مثل هذه المصفوفة ببساطة غير موجودة. في هذه الحالة ، فإن الطرق المختلفة التي تعتمد على النسب المتدرج تأتي لمساعدتنا. يمكن تطبيق عدم خطية النماذج بطرق مختلفة ، بما في ذلك استخدام الشبكات العصبية.
ولكن الآن ، دعونا نتحدث ليس عن هذا ، ولكن عن وظائف الخطأ. ما هو الفرق بين SE و Log-مرجح عندما يمكن أن يكون للبيانات علاقة غير خطية؟
نحن نتعامل مع حديقة الحيوان ، وهي: OLS ، LS ، SE ، MSE ، RSSكل هذا واحد في جوهره ، RSS - مجموع المربعات المتبقية ، OLS - المربعات الصغرى العادية ، LS المربعات الصغرى ، MSE - يعني خطأ تربيعي ، خطأ مربّع SE. في مصادر مختلفة ، يمكنك العثور على أسماء مختلفة. جوهر هذا هو واحد فقط:
الانحراف التربيعي . يمكنك الخلط بالطبع ، لكنك تعتاد على ذلك بسرعة.
تجدر الإشارة إلى أن MSE هي الانحراف المعياري ، وهو متوسط قيمة معينة للخطأ لمجموعة بيانات التدريب بأكملها. في الممارسة العملية ، وعادة ما تستخدم MSE. الصيغة لا تختلف بشكل خاص:
MSE( beta)= frac1N sumni=1(yi− hatyi)2
N - حجم مجموعة البيانات ،
hatyi - نموذج التنبؤ ل
yi .
توقف عن ذلك! احتمال؟ هذا شيء من نظرية الاحتمالات. هذا صحيح - إنها نظرية احتمال محضة. ولكن كيف يمكن أن يرتبط الانحراف التربيعي بوظيفة الاحتمال؟ وكيف اتضح. إنه مرتبط بإيجاد الاحتمال الأقصى (الاحتمالية القصوى) والتوزيع الطبيعي ، ليكون أكثر دقة ، بمتوسطه
mu .
من أجل إدراك أن هذا صحيح ، دعنا ننظر مرة أخرى إلى وظيفة الانحراف المربعي:
RSS( beta)= sumni=1(yi− hatyi)2 qquad qquad(1)
لنفترض الآن أن وظيفة الاحتمال لها شكل عادي ، أي توزيع غاوسي أو عادي:
L(X)=p(X| theta)= prodX mathcalN(xi؛ mu، sigma2)
بشكل عام ، ما هي وظيفة الاحتمال وما هو المعنى الذي لن أقوله ، يمكنك أن تقرأ عنها في مكان آخر ، وعليك أيضًا أن تتعرف على مفهوم الاحتمال المشروط ، ونظرية بايز ، وأكثر من ذلك بكثير ، لفهم أعمق. كل هذا يذهب إلى نظرية الاحتمال البحتة ، والتي تدرس في المدرسة والجامعة.
الآن ، مع تذكر صيغة التوزيع العادية ، نحصل على:
L(X؛ mu، sigma2)= prodX frac1 sqrt2 pi sigma2e− frac(xi− mu)22 sigma2 qquad qquad(2)
ماذا لو وضعنا الانحراف المعياري
sigma2=1 وإزالة جميع الثوابت في الصيغة (2) ، فقط قم بإزالة ، لا تقلل ، لأن العثور على الحد الأدنى من الوظيفة لا يعتمد عليها. ثم سوف نرى هذا:
L(X؛ mu، sigma2) sim prodXe−(xi− mu)2
لا يزال لا شيء مثل؟ لا؟ حسنا ، ماذا لو أخذنا لوغاريتم الوظيفة؟ من اللوغاريتم ، بشكل عام ، هناك بعض الإيجابيات: الضرب سوف يتحول إلى مبلغ ، درجة إلى ضرب ، و
loge=1 - بالنسبة لهذه الخاصية ، تجدر الإشارة إلى أننا نتحدث عن اللوغاريتم الطبيعي ، وبشكل صارم
lne=1دولا . وبشكل عام ، لا يغير لوغاريتم الوظيفة حدها الأقصى ، وهذه هي أهم ميزة بالنسبة لنا. سيتم وصف الارتباط مع احتمال الأرجحية والاحتمالية ولماذا سيكون ذلك مفيدًا أدناه في انحدار صغير. وهكذا فعلنا: أزلنا جميع الثوابت ، وأخذنا لوغاريتم دالة الاحتمالية. لقد قاموا أيضًا بإزالة علامة الطرح ، وبالتالي تحويل "احتمال الدخول" إلى "احتمال الدخول السلبي" (NLL) ، كما سيتم وصف العلاقة بينهما كمكافأة. نتيجة لذلك ، حصلنا على وظيفة NLL:
logL(X؛ mu،I2) sim sum(X− mu)2
ألق نظرة أخرى على وظيفة RSS (1). نعم ، هم نفس الشيء! بالضبط! وينظر أيضا ذلك
mu= haty .
إذا كنت تستخدم دالة الانحراف المعياري لـ MSE ، فسنحصل على ما يلي:
operatornameargminMSE( beta) sim operatornameargmax mathbbEX simPdata logPmodel(x؛ beta)
اين
mathbbE - التوقع الرياضي
beta - معلمات النموذج ، في المستقبل سوف نشير إليها على النحو التالي:
theta .
الخلاصة: إذا استخدمنا عائلة LS كدالة للخطأ في سؤال الانحدار ، فنحن نحل بشكل أساسي مشكلة إيجاد الحد الأقصى لوظيفة الاحتمال في الحالة التي يكون فيها التوزيع غاوسي. والقيمة المتوقعة
haty يساوي المتوسط في التوزيع الطبيعي. والآن نحن نعرف كيف يرتبط كل هذا ، وكيف ترتبط نظرية الاحتمالات (مع وظيفة الاحتمال والتوزيع الطبيعي) وطرق الانحراف المعياري أو OLS. يمكن العثور على مزيد من التفاصيل حول هذا في [2].
وهنا المكافأة الموعودة. نظرًا لأننا نتحدث عن العلاقات بين وظائف الخطأ المختلفة ، فسوف نأخذ في الاعتبار (ليس بالضرورة قراءتها):
العلاقة بين الانتروبيا ، الاحتمالية ، احتمالية تسجيل الدخول ، الاحتمالية السلبية للسجللنفترض أن لدينا بيانات
X = \ {x_1 ، x_2 ، x_3 ، x_4 ، ... \} ، كل نقطة تنتمي إلى فئة معينة ، على سبيل المثال
\ {x_1 \ rightarrow1 ، x_2 \ rightarrow2 ، x_3 \ rightarrow n ، ... \} . المجموع هناك
ن الطبقات ، في حين تحدث الفئة 1
c1 مرات ، فئة 2 -
c2دولا مرات والطبقة
ن -
cn مرات. على هذه البيانات قمنا بتدريب بعض النموذج
theta . ستبدو دالة الاحتمالية (الاحتمالية) لذلك كما يلي:
P(البيانات| theta)=P(0،1،...،n| theta)=P(0| theta)P(1| theta)...P(n| theta)
P(1| theta)P(2| theta)...P(n| theta)= prodc1 haty1 prodc2 haty2... prodcn hatyn= hatyc11 hatyc22... hatycnn
اين
P(n| theta)= hatyn - الاحتمال المتوقع للفصل
ن .
نأخذ لوغاريتم دالة الاحتمالات ونحصل على سجل الاحتمالية:
logP(data| theta)= log( hatyc11... hatycnn)=c1 log haty1+...+cn log hatyn= sumnici log hatyi
الاحتمال
haty in[0،1] يكمن في المدى من 0 إلى 1 ، بناءً على تعريف الاحتمال. لذلك ، سيكون لوغاريتم قيمة سالبة. وإذا ضاعفنا من احتمال الدخول بواقع -1 ، فسنحصل على دالة احتمال الدخول السلبي (NLL):
NLL=− logP(data| theta)=− sumnici log hatyi
إذا قمنا بتقسيم NLL على عدد النقاط في
X ،
N=c1+c2+...+cn ثم نحصل على:
− frac1N logP(data| theta)=− sumni fracciN log hatyi
تجدر الإشارة إلى أن الاحتمال الحقيقي للفصل
ن يساوي:
yn= fraccnN . من هنا نحصل على:
NLL=− sumniyi log hatyi
الآن إذا نظرتم إلى تعريف إنتروبيا
H(p،q)=− sump logq ثم نحصل على:
NLL=H(yi، hatyi)
في حالة وجود فصلين فقط
ن=2دولا (التصنيف الثنائي) نحصل على صيغة إنتروبيا المتقاطعة (يمكنك أيضًا تلبية الاسم المشهور Log-Loss):
H(y، haty)=−(y log haty+(1−y) log(1− haty))
من هذا كله ، يمكن أن يكون مفهوما أن التقليل من التداخل المتداخل في بعض الحالات يكون معادلًا لتقليل NLL أو العثور على الحد الأقصى من دالة الاحتمالية (الاحتمالية) أو احتمال الدخول.
مثال النظر في تصنيف ثنائي. لدينا قيم طبقية:
y = np.array([0, 1, 1, 1, 1, 0, 1, 1]).astype(np.float32)
احتمال حقيقي
ذ للفئة 0 تساوي

، للفئة 1 تساوي

. لنفترض أن لدينا مصنف ثنائي يتنبأ باحتمالية الفصل 0
haty لكل مثال ، على التوالي ، للفئة 1 ، الاحتمال هو
(1− haty) . لنرسم قيم وظيفة Log-Loss لتوقعات مختلفة
haty :
على الرسم البياني يمكنك أن ترى أن الحد الأدنى من وظيفة Log-Loss يتوافق مع النقطة 0.75 ، أي إذا "استفاد" نموذجنا تمامًا من توزيع البيانات المصدر ، haty=y . انحدار الشبكة العصبية
لذلك وصلنا إلى ممارسة أكثر إثارة للاهتمام. دعونا نرى كيف يمكنك حل مشكلة الانحدار باستخدام الشبكات العصبية (الشبكات العصبية). سننفذ كل شيء في لغة برمجة Python ، لإنشاء شبكة نستخدم مكتبة PyTorch للتعلم العميق.
توليد البيانات المصدر
إدخال البيانات
mathbfX in mathbbRN توليد باستخدام توزيع موحد ، تأخذ الفاصل الزمني من -15 إلى 15 ،
mathbfX inU[−15،15] . نقاط
mathbfY نحصل عليها باستخدام المعادلة:
mathbfY=0.5 mathbfX+8 sin(0.3 mathbfX)+noise qquad qquad(3)
اين
الضوضاء هو ناقل الضوضاء البعد
N تم الحصول عليها باستخدام التوزيع الطبيعي مع المعلمات:
mu=0، sigma2=1 .
الرسم البياني للبيانات المستلمة.بناء الشبكة
إنشاء شبكة تغذية عصبية إلى الأمام العادية أو FFNN.
بناء FFNN class Net(nn.Module): def __init__(self, input_dim=IN_DIM, out_dim=OUT_DIM, layer_size=40): super(Net, self).__init__() self.fc = nn.Linear(input_dim, layer_size) self.logit = nn.Linear(layer_size, out_dim) def forward(self, x): x = F.tanh(self.fc(x))
تتكون شبكتنا من طبقة واحدة مخفية بأبعاد من 40 خلية عصبية مع وظيفة تنشيط - الظل الزائدي:
tanhx= fracex−e−xex+e−x qquad qquad(4)
طبقة الخرج عبارة عن تحويل خطي عادي بدون وظيفة تنشيط.
التعلم والحصول على النتائج
كمحسن سوف نستخدم AdamOptimizer. عدد مرات الدراسة = 2000 ، معدل التعلم (معدل التعلم أو التعلم) = 0.1.
تدريب FFNN def train(net, x_train, y_train, x_test, y_test, epoches=2000, lr=0.1): criterion = nn.MSELoss() optimizer = optim.Adam(net.parameters(), lr=lr) N_EPOCHES = epoches BS = 1500 n_batches = int(np.ceil(x_train.shape[0] / BS)) train_losses = [] test_losses = [] for i in range(N_EPOCHES): for bi in range(n_batches): x_batch, y_batch = fetch_batch(x_train, y_train, bi, BS) x_train_var = Variable(torch.from_numpy(x_batch)) y_train_var = Variable(torch.from_numpy(y_batch)) optimizer.zero_grad() outputs = net(x_train_var) loss = criterion(outputs, y_train_var) loss.backward() optimizer.step() with torch.no_grad(): x_test_var = Variable(torch.from_numpy(x_test)) y_test_var = Variable(torch.from_numpy(y_test)) outputs = net(x_test_var) test_loss = criterion(outputs, y_test_var) test_losses.append(test_loss.item()) train_losses.append(loss.item()) if i%100 == 0: sys.stdout.write('\r Iter: %d, test loss: %.5f, train loss: %.5f' %(i, test_loss.item(), loss.item())) sys.stdout.flush() return train_losses, test_losses net = Net() train_losses, test_losses = train(net, x_train, y_train, x_test, y_test)
الآن دعونا نلقي نظرة على نتائج التعلم.
رسم بياني لقيم وظيفة MSE اعتمادًا على تكرار التدريب ؛ رسم بياني لقيم بيانات التدريب وبيانات الاختبار.النتائج الحقيقية والمتوقعة على بيانات الاختبار.البيانات المقلوبة
نحن تعقيد المهمة وعكس البيانات.
انقلاب البيانات x_train_inv = y_train y_train_inv = x_train x_test_inv = y_train y_test_inv = x_train
الرسم البياني للبيانات المقلوبة.للتنبؤ
mathbf hatY دعنا نستخدم شبكة التوزيع المباشر من القسم السابق ونرى كيف تعالج هذا.
inv_train_losses, inv_test_losses = train(net, x_train_inv, y_train_inv, x_test_inv, y_test_inv)
رسم بياني لقيم وظيفة MSE اعتمادًا على تكرار التدريب ؛ رسم بياني لقيم بيانات التدريب وبيانات الاختبار.النتائج الحقيقية والمتوقعة على بيانات الاختبار.كما ترون من الرسوم البيانية أعلاه ، فإن شبكتنا
لم تتعامل مع هذه البيانات على الإطلاق ، فهي ببساطة غير قادرة على التنبؤ بها. وحدث كل هذا لأنه في مثل هذه المشكلة المقلوبة لنقطة واحدة
x قد تتوافق مع عدة نقاط
ذ . أنت تسأل ، ماذا عن الضوضاء؟ انه خلق أيضا موقف فيه لأحد
x يمكن الحصول على بعض القيم
ذ . نعم هذا صحيح. لكن بيت القصيد هو أنه ، على الرغم من الضوضاء ، كان كل توزيع واحد واضح. وبما أن نموذجنا تنبأ بشكل أساسي
p(y|x) وفي حالة MSE ، كان متوسط قيمة التوزيع الطبيعي (لماذا هو موصوف في الجزء الأول من المقالة) ، ثم تعامل بشكل جيد مع المهمة "المباشرة". خلاف ذلك ، نحصل على عدة توزيعات مختلفة لواحد
x وبناءً على ذلك ، لا يمكننا الحصول على نتيجة جيدة بتوزيع واحد عادي فقط.
شبكة كثافة الخليط
المرح يبدأ! ما هي شبكة Mixture Density (فيما يلي شبكة MDN أو MD)؟ بشكل عام ، هذا نموذج معين قادر على محاكاة عدة توزيعات في وقت واحد:
p( mathbfy| mathbfx؛ theta)= sumKk pik( mathbfx) mathcalN( mathbfy؛ muk( mathbfx)، sigma2( mathbfx)) qquad qquad(5)
يا له من صيغة غريبة ، كما تقول. دعونا معرفة ذلك. تتعلم شبكة MD لدينا نمذجة الوسط
mu والتباين
سيجما2 لتوزيعات
متعددة . في الصيغة (5)
pik( mathbfx) - ما يسمى عوامل الأهمية لتوزيع منفصل لكل نقطة
xi in mathbfx ، عامل خلط معين ، أو مقدار مساهمة كل من التوزيعات في نقطة معينة. المجموع هناك
K توزيعات.
بضع كلمات أخرى عنه
pik( mathbfx) - في الواقع ، هذا هو أيضا توزيع ويمثل الاحتمال أن نقطة
xi in mathbfx سوف يكون شرطا
ك .
فوه ، مرة أخرى ، هذه الرياضيات ، دعنا نكتب شيئًا بالفعل. وهكذا ، سوف نبدأ في تحقيق شبكة. لشبكتنا نأخذ
ك=30دولا .
self.fc = nn.Linear(input_dim, layer_size) self.fc2 = nn.Linear(layer_size, 50) self.pi = nn.Linear(layer_size, coefs) self.mu = nn.Linear(layer_size, out_dim*coefs)
حدد طبقات الإخراج لشبكتنا:
x = F.relu(self.fc(x)) x = F.relu(self.fc2(x)) pi = F.softmax(self.pi(x), dim=1) sigma_sq = torch.exp(self.sigma_sq(x)) mu = self.mu(x)
نكتب وظيفة الخطأ أو وظيفة الخسارة ، الصيغة (5):
def gaussian_pdf(x, mu, sigma_sq): return (1/torch.sqrt(2*np.pi*sigma_sq)) * torch.exp((-1/(2*sigma_sq)) * torch.norm((x-mu), 2, 1)**2) losses = Variable(torch.zeros(y.shape[0]))
استكمال بناء رمز MDN COEFS = 30 class MDN(nn.Module): def __init__(self, input_dim=IN_DIM, out_dim=OUT_DIM, layer_size=50, coefs=COEFS): super(MDN, self).__init__() self.fc = nn.Linear(input_dim, layer_size) self.fc2 = nn.Linear(layer_size, 50) self.pi = nn.Linear(layer_size, coefs) self.mu = nn.Linear(layer_size, out_dim*coefs)
شبكة MD لدينا جاهزة للعمل. جاهز تقريبا. يبقى لتدريبها والنظر في النتائج.
تدريب MDN def train_mdn(net, x_train, y_train, x_test, y_test, epoches=1000): optimizer = optim.Adam(net.parameters(), lr=0.01) N_EPOCHES = epoches BS = 1500 n_batches = int(np.ceil(x_train.shape[0] / BS)) train_losses = [] test_losses = [] for i in range(N_EPOCHES): for bi in range(n_batches): x_batch, y_batch = fetch_batch(x_train, y_train, bi, BS) x_train_var = Variable(torch.from_numpy(x_batch)) y_train_var = Variable(torch.from_numpy(y_batch)) optimizer.zero_grad() pi, mu, sigma_sq = net(x_train_var) loss = loss_fn(y_train_var, pi, mu, sigma_sq) loss.backward() optimizer.step() with torch.no_grad(): if i%10 == 0: x_test_var = Variable(torch.from_numpy(x_test)) y_test_var = Variable(torch.from_numpy(y_test)) pi, mu, sigma_sq = net(x_test_var) test_loss = loss_fn(y_test_var, pi, mu, sigma_sq) train_losses.append(loss.item()) test_losses.append(test_loss.item()) sys.stdout.write('\r Iter: %d, test loss: %.5f, train loss: %.5f' %(i, test_loss.item(), loss.item())) sys.stdout.flush() return train_losses, test_losses mdn_net = MDN() mdn_train_losses, mdn_test_losses = train_mdn(mdn_net, x_train_inv, y_train_inv, x_test_inv, y_test_inv)
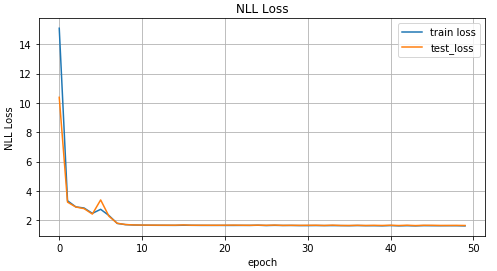
نظرًا لأن شبكتنا قد تعلمت القيم المتوسطة لعدة توزيعات ، فلنلقِ نظرة على هذا:
pi, mu, sigma_sq = mdn_net(Variable(torch.from_numpy(x_test_inv)))
رسم بياني للقيمتين المتوسطتين الأكثر احتمالا لكل نقطة (يسار). الرسم البياني للقيم الأربعة على الأرجح تعني القيم لكل نقطة (يمين).الرسم البياني لجميع القيم يعني لكل نقطة.للتنبؤ بالبيانات ، سنختار عدة قيم بشكل عشوائي
mu و
سيجما2 بناء على القيمة
pik( mathbfx) . وبعد ذلك بناء عليها لإنشاء البيانات المستهدفة
haty باستخدام التوزيع الطبيعي.
التنبؤ بالنتيجة def rand_n_sample_cumulative(pi, mu, sigmasq, samples=10): n = pi.shape[0] out = Variable(torch.zeros(n, samples, OUT_DIM)) for i in range(n): for j in range(samples): u = np.random.uniform() prob_sum = 0 for k in range(COEFS): prob_sum += pi.data[i, k] if u < prob_sum: for od in range(OUT_DIM): sample = np.random.normal(mu.data[i, k*OUT_DIM+od], np.sqrt(sigmasq.data[i, k])) out[i, j, od] = sample break return out pi, mu, sigma_sq = mdn_net(Variable(torch.from_numpy(x_test_inv))) preds = rand_n_sample_cumulative(pi, mu, sigma_sq, samples=10)
البيانات المتوقعة لمدة 10 القيم المحددة عشوائيا mu و سيجما2 (يسار) واثنان (يمين).من خلال الأرقام ، يمكن أن نرى أن MDN قامت بعمل ممتاز من خلال المهمة "العكسية".
باستخدام بيانات أكثر تعقيدا
دعونا نرى كيف تتعامل شبكة MD لدينا مع بيانات أكثر تعقيدًا ، مثل البيانات الحلزونية. معادلة دوامة القطعي في الإحداثيات الديكارتية:
x= rho cos phi qquad qquad qquad qquad qquad qquad(6)y= rho sin phi
توليد البيانات الحلزونية N = 2000 x_train_compl = [] y_train_compl = [] x_test_compl = [] y_test_compl = [] noise_train = np.random.uniform(-1, 1, (N, IN_DIM)).astype(np.float32) noise_test = np.random.uniform(-1, 1, (N, IN_DIM)).astype(np.float32) for i, theta in enumerate(np.linspace(0, 5*np.pi, N).astype(np.float32)):
الرسم البياني للبيانات دوامة.للمتعة ، دعنا نرى كيف ستتعامل شبكة التغذية المباشرة مع هذه المهمة.
كما هو متوقع ، شبكة Feed-Forward غير قادرة على حل مشكلة الانحدار لمثل هذه البيانات.نحن نستخدم شبكة MD الموصوفة والمُنشأة مسبقًا للتدريب على البيانات الحلزونية.
قامت شبكة Mixture Density بعمل رائع في هذا الموقف.الخاتمة
في بداية هذه المقالة ، ذكرنا أساسيات الانحدار الخطي. رأينا ذلك مشتركًا بين إيجاد المتوسط للتوزيع الطبيعي و MSE. تفكيك كيفية اتصال NLL وعبر إنتروبيا. والأهم من ذلك ، اكتشفنا نموذج MDN ، والذي هو قادر على التعلم من البيانات التي تم الحصول عليها من توزيع مختلط. آمل أن تكون المقالة مفهومة ومثيرة للاهتمام ، على الرغم من حقيقة وجود القليل من الرياضيات.
يمكن الاطلاع على الكود الكامل على
جيثب .
الأدب
- مزيج شبكات الكثافة (كريستوفر م. بيشوب ، مجموعة أبحاث الحوسبة العصبية ، قسم علوم الحاسوب والرياضيات التطبيقية ، جامعة أستون ، برمنغهام) - تصف المقالة بشكل كامل نظرية شبكات MD.
- المربعات الصغرى والاحتمالية القصوى (MROsborne)