المقالة الثانية من سلسلة "تطوير التطبيقات التي تعتمد على الاختبار على Spring Spring" وهذه المرة سأتحدث عن اختبار الوصول إلى قاعدة البيانات ، وهو جانب هام من جوانب اختبار التكامل. سوف أخبرك بكيفية تحديد واجهة خدمة مستقبلية للوصول إلى البيانات من خلال الاختبارات ، وكيفية استخدام قواعد البيانات المدمجة في الذاكرة للاختبار ، والعمل مع المعاملات ، وتحميل بيانات الاختبار إلى قاعدة البيانات.
أنا لا أتحدث كثيرًا عن TDD والاختبار بشكل عام ، وأدعو الجميع إلى قراءة المقال الأول - كيفية بناء هرم في تطوير تطبيقات جذع أو يحركها الاختبار في مجلة Spring Boot / geek
سأبدأ ، كآخر مرة ، بجزء نظري صغير ، وانتقل إلى الاختبار الشامل.
اختبار الهرم
بادئ ذي بدء ، وصف صغير ولكنه ضروري لمثل هذا الكيان المهم في الاختبار مثل هرم الاختبار أو هرم الاختبار .
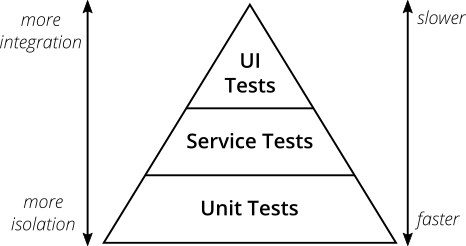
(مأخوذة من هرم الاختبار العملي )
هرم الاختبار هو النهج عند تنظيم الاختبارات على عدة مستويات.
- اختبارات واجهة المستخدم (أو من البداية إلى النهاية ، E2E ) قليلة وهي بطيئة ، لكنها تختبر التطبيق الحقيقي - لا تسخر من النظراء والاختبار. غالبًا ما يفكر رجال الأعمال في هذا المستوى وتعيش جميع أطر BDD هنا (انظر الخيار في مقالة سابقة).
- وتليها اختبارات التكامل (الخدمة ، المكون - كل واحد له مصطلحاته الخاصة) ، والتي تركز بالفعل على مكون معين (الخدمة) من النظام ، وعزله عن المكونات الأخرى من خلال moki / الزوجي ، ولكن لا يزال التحقق من التكامل مع أنظمة خارجية حقيقية - ترتبط هذه الاختبارات إلى قاعدة البيانات ، وإرسال طلبات REST ، وأنا أعمل مع قائمة انتظار الرسائل. في الواقع ، هذه اختبارات تتحقق من تكامل منطق العمل مع العالم الخارجي.
- في الجزء السفلي للغاية ، توجد اختبارات سريعة للوحدة تختبر الكتل الدنيا من الكود (الفئات ، الطرق) بمعزل تام.
يساعد Spring في كتابة اختبارات لكل مستوى - حتى بالنسبة لاختبارات الوحدات ، على الرغم من أن هذا قد يبدو غريباً ، لأنه في عالم اختبارات الوحدة ، يجب ألا تكون هناك معرفة على الإطلاق بالإطار. بعد كتابة اختبار E2E ، سأوضح فقط كيف أن Spring يسمح حتى بأشياء "تكامل" بحتة مثل وحدات التحكم في الاختبار بمعزل عن غيرها.
لكنني سأبدأ من قمة الهرم - اختبار واجهة المستخدم البطيء ، والذي يبدأ ويختبر تطبيقًا كاملاً.
اختبار نهاية إلى نهاية
لذلك ، ميزة جديدة:
Feature: A list of available cakes Background: catalogue is updated Given the following items are promoted | Title | Price | | Red Velvet | 3.95 | | Victoria Sponge | 5.50 | Scenario: a user visiting the web-site sees the list of items Given a new user, Alice When she visits Cake Factory web-site Then she sees that "Red Velvet" is available with price £3.95 And she sees that "Victoria Sponge" is available with price £5.50
وهنا جانب مثير للاهتمام على الفور - ما يجب القيام به مع الاختبار السابق ، حول التحية على الصفحة الرئيسية؟ يبدو أنه لم يعد ذا صلة ، بعد إطلاق الموقع على الصفحة الرئيسية سيكون هناك بالفعل دليل ، وليس تحية. لا يوجد إجابة واحدة ، أود أن أقول - هذا يعتمد على الوضع. لكن النصيحة الرئيسية - لا تعلق على الاختبارات! احذفها عندما تفقد أهميتها ، وأعد كتابتها لتسهيل قراءتها. لا سيما اختبارات E2E - يجب أن يكون ، في الواقع ، مواصفات حية وحالية . في حالتي ، قمت فقط بحذف الاختبارات القديمة ، واستبدلت بها بأخرى جديدة ، باستخدام بعض الخطوات السابقة وإضافة أخرى غير موجودة.
لقد وصلت الآن إلى نقطة مهمة - اختيار التكنولوجيا لتخزين البيانات. وفقًا للنهج الهزيل ، أود تأجيل الاختيار حتى آخر لحظة - عندما أعرف على وجه اليقين ما إذا كان النموذج العلائقي أم لا ، ما هي متطلبات الاتساق والمعاملة. بشكل عام ، توجد حلول لهذا - على سبيل المثال ، إنشاء توائم اختبار ومخازن متنوعة داخل الذاكرة ، لكن حتى الآن لا أريد تعقيد المقالة واختيار قواعد البيانات ذات الصلة على الفور. ولكن من أجل الحفاظ على بعض الاحتمالات على الأقل لاختيار قاعدة بيانات ، سأضيف مجموعة تجريبية - Spring Data JPA . JPA نفسها هي مواصفات مجردة إلى حد ما للوصول إلى قواعد البيانات العلائقية ، و Spring Data يجعل استخدامها أسهل.
يستخدم Spring Data JPA Hibernate كموفر افتراضيًا ، ولكنه يدعم أيضًا التقنيات الأخرى ، مثل EclipseLink و MyBatis. للأشخاص الذين ليسوا على دراية بواجهة برمجة تطبيقات Java Persistence - يشبه JPA واجهة ، و Hibernate هي فئة تنفذها.
لذلك ، لإضافة دعم JPA ، أضفت بعض التبعيات:
implementation('org.springframework.boot:spring-boot-starter-data-jpa') runtime('com.h2database:h2')
كقاعدة بيانات ، سأستخدم H2 - قاعدة بيانات مدمجة مكتوبة بلغة Java ، مع القدرة على العمل في وضع الذاكرة.
باستخدام Spring Data JPA ، أقوم على الفور بتعريف واجهة للوصول إلى البيانات:
interface CakeRepository extends CrudRepository<CakeEntity, String> { }
والجوهر:
@Entity @Builder @AllArgsConstructor @Table(name = "cakes") class CakeEntity { public CakeEntity() { } @Id @GeneratedValue(strategy = GenerationType.IDENTITY) Long id; @NotBlank String title; @Positive BigDecimal price; @NotBlank @NaturalId String sku; boolean promoted; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; CakeEntity cakeEntity = (CakeEntity) o; return Objects.equals(title, cakeEntity.title); } @Override public int hashCode() { return Objects.hash(title); } }
هناك بضعة أشياء أقل وضوحًا في وصف الكيان.
@NaturalId يستخدم هذا الحقل كـ "معرّف طبيعي" للتحقق من equals الكيانات - باستخدام جميع الحقول أو حقول @Id في أساليب equals / hashCode هي بالأحرى نمط مضاد. مكتوب بشكل جيد حول كيفية التحقق بشكل صحيح من المساواة بين الكيانات ، على سبيل المثال ، هنا .- لتخفيض شفرة الغليان قليلاً ، أستخدم Project Lombok - anotation processor for Java. يتيح لك إضافة أشياء مفيدة
@Builder ، مثل @Builder - لإنشاء منشئ تلقائيًا للفئة و @AllArgsConstructor لإنشاء مُنشئ لجميع الحقول.
سيتم توفير تطبيق واجهة تلقائيًا بواسطة Spring Data.
أسفل الهرم
لقد حان الوقت للنزول إلى المستوى التالي من الهرم. كقاعدة عامة ، أوصي بأن تبدأ دائمًا في اختبار e2e ، لأن هذا سيتيح لك تحديد "الهدف النهائي" وحدود الميزة الجديدة ، ولكن لا توجد قواعد صارمة أخرى. ليس من الضروري كتابة اختبار التكامل أولاً ، قبل الانتقال إلى مستوى الوحدة. غالبًا ما يكون الأمر أكثر ملاءمة وبساطة - ومن الطبيعي جدًا النزول.
لكن على وجه التحديد الآن ، أود كسر هذه القاعدة على الفور وكتابة اختبار وحدة من شأنها أن تساعد في تحديد واجهة وعقد مكون جديد غير موجود حتى الآن. يجب أن تقوم وحدة التحكم بإرجاع نموذج يتم ملؤه من مكون X معين ، وقد كتبت هذا الاختبار:
@ExtendWith(MockitoExtension.class) class IndexControllerTest { @Mock CakeFinder cakeFinder; @InjectMocks IndexController indexController; private Set<Cake> cakes = Set.of(new Cake("Test 1", "£10"), new Cake("Test 2", "£10")); @BeforeEach void setUp() { when(cakeFinder.findPromotedCakes()).thenReturn(cakes); } @Test void shouldReturnAListOfFoundPromotedCakes() { ModelAndView index = indexController.index(); assertThat(index.getModel()).extracting("cakes").contains(cakes); } }
هذا اختبار وحدة خالصة - لا سياقات ، لا توجد قواعد بيانات هنا ، فقط Mockito لـ mok . وهذا الاختبار هو مجرد عرض جيد لكيفية مساعدة Spring في اختبارات الوحدة - وحدة التحكم في Spring MVC هي مجرد فئة تدرس أساليبها المعلمات الخاصة بالأنواع العادية وتعيد كائنات POJO - عرض النماذج . لا توجد طلبات HTTP ، لا توجد ردود ، رؤوس ، JSON ، XML - كل هذا سوف يتم تطبيقه تلقائيًا على المكدس في شكل محولات ومسلسلات. نعم ، هناك "تلميح" صغير إلى Spring في شكل ModelAndView ، ولكن هذا POJO منتظم ويمكنك حتى التخلص منه إذا كنت ترغب في ذلك ، هناك حاجة خاصة لوحدات التحكم UI.
لن أتحدث كثيرا عن موكيتو ، يمكنك قراءة كل شيء في الوثائق الرسمية. على وجه التحديد ، هناك نقاط مثيرة للاهتمام فقط في هذا الاختبار - يمكنني استخدام MockitoExtension.class للاختبار ، وسيؤدي تلقائيًا إلى إنشاء mokas للحقول @Mock بواسطة @Mock ثم حقن هذه mokas كتبعيات في مُنشئ الكائن في الحقل المحدد بـ @InjectMocks . يمكنك القيام بكل هذا يدويًا باستخدام الأسلوب Mockito.mock() ثم إنشاء فصل Mockito.mock() .
ويساعد هذا الاختبار في تحديد طريقة المكون الجديد - findPromotedCakes ، وهي قائمة بالكعك التي نريد عرضها على الصفحة الرئيسية. لا يحدد ما هو عليه ، أو كيف يجب أن يعمل مع قاعدة البيانات. مسؤولية وحدة التحكم هي أخذ ما تم نقله إليه وإرجاع النماذج ("الكعك") في حقل معين. ومع ذلك ، فإن CakeFinder لديه بالفعل الطريقة الأولى في CakeFinder ، مما يعني أنه يمكنك كتابة اختبار تكامل له.
لقد قمت عمداً بجعل جميع الفصول داخل حزمة cakes خاصة حتى لا يمكن لأي شخص خارج الحزمة استخدامها. الطريقة الوحيدة للحصول على البيانات من قاعدة البيانات هي من خلال واجهة CakeFinder ، والتي هي "المكون العاشر" للوصول إلى قاعدة البيانات. يصبح "موصلًا" طبيعيًا ، يمكنني قفله بسهولة إذا احتجت إلى اختبار شيء بمعزل عن عدم لمس القاعدة. وتنفيذها الوحيد هو JpaCakeFinder. وإذا تغير ، على سبيل المثال ، نوع قاعدة البيانات أو مصدر البيانات في المستقبل ، فستحتاج إلى إضافة تطبيق لواجهة CakeFinder دون تغيير الكود الذي يستخدمه.
اختبار التكامل ل JPA باستخدامDataJpaTest
اختبارات التكامل هي خبز الربيع والزبدة. في الواقع ، تم إجراء كل شيء جيدًا لاختبار التكامل ، حيث لا يرغب المطورون في بعض الأحيان في الانتقال إلى مستوى الوحدة أو إهمال مستوى واجهة المستخدم. هذا ليس سيئًا ولا جيدًا - وأكرر أن الهدف الرئيسي للاختبارات هو الثقة. وقد تكون مجموعة من اختبارات التكامل السريعة والفعالة كافية لتوفير هذه الثقة. ومع ذلك ، هناك خطر أنه بمرور الوقت ، ستكون هذه الاختبارات إما أبطأ أو أبطأ ، أو ببساطة تبدأ في اختبار المكونات بمعزل ، بدلاً من التكامل.
يمكن أن تعمل اختبارات التكامل على تشغيل التطبيق كما هو ( @SpringBootTest ) ، أو @SpringBootTest المنفصل (JPA ، الويب). في حالتي ، أريد أن أكتب اختبارًا مركّزًا لـ JPA - لذلك لست بحاجة إلى تكوين وحدات التحكم أو أي مكونات أخرى. يعد التعليق التوضيحي @DataJpaTest مسؤولاً عن ذلك في اختبار اختبار التمهيد الربيعي. هذا تعليق توضيحي ، على سبيل المثال فهو يجمع بين العديد من التعليقات التوضيحية المختلفة التي تقوم بتكوين جوانب مختلفة من الاختبار.
- تضمين التغريدة
- AutoConfigureTestDatabase
- تضمين التغريدة
- ردًا علىAutoConfigureTestEntityManager
- تضمين التغريدة
أولاً ، سأخبرك عن كل واحدة على حدة ، ثم سأعرض لك الاختبار النهائي.
تضمين التغريدة
يقوم بتحميل مجموعة كاملة من التكوينات وإعداد مستودعات ( CrudRepositories الخاصة بـ CrudRepositories ) ، وأدوات الترحيل لقواعد بيانات FlyWay و Liquibase ، والاتصال بقاعدة البيانات باستخدام DataSource ، ومدير المعاملات ، وأخيرا Hibernate. في الواقع ، هذه مجرد مجموعة من التكوينات ذات الصلة للوصول إلى البيانات - لا يتم تضمين DispatcherServlet من Web MVC ، أو المكونات الأخرى هنا.
AutoConfigureTestDatabase
هذا هو واحد من أكثر الجوانب إثارة للاهتمام في اختبار JPA. يبحث هذا التكوين في classpath عن إحدى قواعد البيانات المدمجة المضمنة ويعيد تكوين السياق بحيث يشير مصدر البيانات إلى قاعدة بيانات في الذاكرة تم إنشاؤها عشوائيًا . نظرًا لأنني أضفت التبعية إلى قاعدة H2 ، فأنا لست بحاجة إلى القيام بأي شيء آخر ، فقط بعد تقديم هذا التعليق التوضيحي تلقائيًا لكل تشغيل تجريبي سيوفر قاعدة فارغة ، وهذا ببساطة مناسب بشكل لا يصدق.
تجدر الإشارة إلى أن هذه القاعدة ستكون فارغة تمامًا ، بدون مخطط. لتوليد الدائرة ، هناك بضعة خيارات.
- استخدم ميزة DDL التلقائية من الإسبات. سيقوم Spring Boot Test تلقائيًا بتعيين هذه القيمة على
create-drop بحيث ينشئ الإسبات مخططًا من وصف الكيان وحذفه في نهاية الجلسة. هذه هي ميزة قوية بشكل لا يصدق من السبات ، وهو مفيد جدا للاختبارات. - استخدام الهجرات التي أنشأتها Flyway أو Liquibase .
يمكنك قراءة المزيد حول الطرق المختلفة لتهيئة قاعدة البيانات في الوثائق .
تضمين التغريدة
يقوم فقط بتكوين ذاكرة التخزين المؤقت لاستخدام NoOpCacheManager - أي لا تخبئ أي شيء. هذا مفيد لتجنب المفاجآت في الاختبارات.
ردًا علىAutoConfigureTestEntityManager
يضيف كائن TestEntityManager خاصًا إلى TestEntityManager ، وهو بحد ذاته وحش مثير للاهتمام. EntityManager هي الفئة الرئيسية من JPA ، المسؤولة عن إضافة كيانات إلى الجلسة وحذفها وأشياء مماثلة. فقط عندما يتم تشغيل Hibernate ، على سبيل المثال - لا يعني إضافة كيان إلى الجلسة أنه سيتم تنفيذ طلب إلى قاعدة البيانات ، ولا يعني التحميل من جلسة أنه سيتم تنفيذ طلب تحديد. نظرًا للآليات الداخلية لـ Hibernate ، سيتم تنفيذ عمليات حقيقية باستخدام قاعدة البيانات في الوقت المناسب ، والتي يحددها الإطار نفسه. ولكن في الاختبارات ، قد يكون من الضروري إرسال شيء بقوة إلى قاعدة البيانات ، لأن الغرض من الاختبارات هو اختبار التكامل. و TestEntityManager هو مجرد المساعد الذي سيساعد بعض العمليات مع قاعدة البيانات التي سيتم تنفيذها بالقوة - على سبيل المثال ، سوف persistAndFlush() فرض إسبات لتنفيذ جميع الطلبات.
تضمين التغريدة
هذا الشرح يجعل جميع الاختبارات في المعاملات الصفية ، مع التراجع التلقائي للمعاملة عند الانتهاء من الاختبار. هذه مجرد آلية "لتنظيف" قاعدة البيانات قبل كل اختبار ، لأنه وإلا فسيتعين عليك حذف البيانات يدويًا من كل جدول.
ما إذا كان الاختبار يجب أن يدير معاملة ما ، فهذا ليس سؤالًا بسيطًا وواضحًا كما قد يبدو. على الرغم من راحة الحالة "النظيفة" لقاعدة البيانات ، يمكن أن يكون وجود @Transactional في الاختبارات مفاجأة غير سارة إذا لم يبدأ رمز "المعركة" في المعاملة بنفسه ، ولكنه يتطلب وجودًا @Transactional . يمكن أن يؤدي هذا إلى حقيقة أن اختبار التكامل يمر ، ولكن عندما يتم تنفيذ الكود الحقيقي من وحدة التحكم ، وليس من الاختبار ، لن يكون للخدمة معاملة نشطة وستتخلص الطريقة من ذلك. على الرغم من أن هذا يبدو خطيرًا ، إلا أن اختبارات المعاملات ليست سيئة للغاية مع الاختبارات عالية المستوى لاختبارات واجهة المستخدم. في تجربتي ، رأيت مرة واحدة فقط ، عندما تعطل اختبار الاندماج الناجح رمز الإنتاج ، الأمر الذي تطلب بوضوح وجود معاملة موجودة. ولكن إذا كنت لا تزال بحاجة إلى التحقق من أن الخدمات والمكونات نفسها تدير المعاملات بشكل صحيح ، فيمكنك "حظر" التعليق التوضيحي على @Transactional في الاختبار @Transactional المرغوب فيه (على سبيل المثال ، لا تبدأ المعاملة).
اختبار التكامل معSpringBootTest
أريد أيضًا أن @DataJpaTest إلى أن @DataJpaTest ليس مثالًا فريدًا على اختبار التكامل البؤري ، فهناك @WebMvcTest و @DataMongoTest والعديد غيرها. ولكن يبقى أحد أهم التعليقات التوضيحية للاختبار هو @SpringBootTest ، الذي يقوم بتشغيل التطبيق "كما هو" للاختبارات - مع جميع المكونات والتكاملات التي تم تكوينها. يطرح سؤال منطقي - إذا كان يمكنك تشغيل التطبيق بالكامل ، فلماذا اختبارات DataJpa المحورية ، على سبيل المثال؟ أود أن أقول أنه لا توجد قواعد صارمة هنا مرة أخرى.
إذا كان من الممكن تشغيل التطبيقات في كل مرة ، فقم بعزل الأعطال في الاختبارات ، ولا تفرط في التحميل ولا تقم بإعادة إعداد برنامج الإعداد للاختبار ، ثم يمكنك بالطبع استخدامSpringBootTest.
ومع ذلك ، في الحياة الواقعية ، يمكن أن تتطلب التطبيقات العديد من الإعدادات المختلفة ، والاتصال بأنظمة مختلفة ، ولا أريد أن تسقط اختبارات الوصول إلى قاعدة البيانات الخاصة بي ، لأن لم يتم تكوين الاتصال إلى قائمة انتظار الرسائل. لذلك ، من المهم استخدام الفطرة السليمة ، وإذا كنت ترغب في إجراء اختبار مع التعليق التوضيحيSpringBootTest للعمل ، فأنت بحاجة إلى قفل نصف النظام - هل من المنطقي إذن على الإطلاق فيSpringBootTest؟
إعداد البيانات للاختبار
واحدة من النقاط الرئيسية للاختبار هو إعداد البيانات. يجب إجراء كل اختبار بمعزل ، وإعداد البيئة قبل البدء ، وبذلك يصل النظام إلى حالته الأصلية المطلوبة. الخيار الأسهل للقيام بذلك هو استخدام التعليقات التوضيحية @BeforeAll / @BeforeAll وإضافة إدخالات إلى قاعدة البيانات هناك باستخدام المستودع أو TestEntityManager أو TestEntityManager . ولكن هناك خيار آخر يسمح لك بتشغيل برنامج نصي مُعد أو تنفيذ استعلام SQL المطلوب ، وهو تعليق توضيحي @Sql . قبل إجراء الاختبار ، سيعمل اختبار تمهيد التمهيد تلقائيًا على تشغيل البرنامج النصي المحدد ، مما يلغي الحاجة إلى إضافة @BeforeAll block ، @Transactional العناية @Transactional البيانات.
@DataJpaTest class JpaCakeFinderTest { private static final String PROMOTED_CAKE = "Red Velvet"; private static final String NON_PROMOTED_CAKE = "Victoria Sponge"; private CakeFinder finder; @Autowired CakeRepository cakeRepository; @Autowired TestEntityManager testEntityManager; @BeforeEach void setUp() { this.testEntityManager.persistAndFlush(CakeEntity.builder().title(PROMOTED_CAKE) .sku("SKU1").price(BigDecimal.TEN).promoted(true).build()); this.testEntityManager.persistAndFlush(CakeEntity.builder().sku("SKU2") .title(NON_PROMOTED_CAKE).price(BigDecimal.ONE).promoted(false).build()); finder = new JpaCakeFinder(cakeRepository); } ... }
دورة الأحمر والأخضر ريفاكتور
على الرغم من هذا القدر من النص ، بالنسبة للمطور ، لا يزال الاختبار يبدو كصف دراسي بسيط مع التعليق التوضيحيDataJpaTest ، لكنني آمل أن أتمكن من إظهار مقدار الأشياء المفيدة التي تحدث تحت الغطاء ، والتي لا يستطيع المطور التفكير فيها. الآن يمكننا الانتقال إلى دورة TDD وهذه المرة سأعرض بضع تكرارات TDD ، مع أمثلة لإعادة التجهيز والحد الأدنى من الكود. لجعله أكثر وضوحًا ، أوصي بشدة أن تنظر إلى السجل في جيت ، حيث يكون كل التزام خطوة منفصلة وهامة مع وصف لما وكيف وكيف.
إعداد البيانات
يمكنني استخدام النهج مع @BeforeAll / @BeforeEach وإنشاء جميع السجلات في قاعدة البيانات يدويًا. يتم نقل المثال مع التعليق التوضيحي @Sql إلى فئة منفصلة JpaCakeFinderTestWithScriptSetup ، وهو يكرر الاختبارات ، التي ، بالطبع ، لا ينبغي أن تكون ، وموجودة لغرض وحيد هو توضيح النهج.
الحالة الأولية للنظام - هناك إدخالان في النظام ، كعكة واحدة تشارك في العرض الترويجي ويجب تضمينها في النتيجة التي يتم إرجاعها بواسطة الطريقة ، والثانية - لا.
أول اختبار التكامل الاختبار
الاختبار الأول هو أبسط - findPromotedCakes يجب أن يتضمن وصفا وسعر الكعكة المشاركة في العرض.
احمر
@Test void shouldReturnPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle).contains(PROMOTED_CAKE); assertThat(promotedCakes).extracting(Cake::getPrice).contains("£10.00"); }
الاختبار ، بالطبع ، تعطل - إرجاع التطبيق الافتراضي مجموعة فارغة.
الأخضر
بطبيعة الحال ، نود كتابة التصفية على الفور ، وتقديم طلب إلى قاعدة البيانات مع where وهلم جرا. ولكن بعد ممارسة TDD ، لا بد لي من كتابة الحد الأدنى من رمز للاختبار لاجتياز . وهذا الرمز الحد الأدنى هو إرجاع جميع السجلات في قاعدة البيانات. نعم ، بسيط جدا ومريح.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); } private String formatPrice(BigDecimal price) { return "£" + price.setScale(2, RoundingMode.DOWN).toPlainString(); }
ربما يجادل البعض بأنه يمكنك هنا إجراء الاختبار باللون الأخضر حتى بدون وجود قاعدة - فقط قم بتصحيح النتيجة المتوقعة من الاختبار. أسمع أحيانًا مثل هذه الحجة ، لكنني أعتقد أن الجميع يفهم أن TDD ليس عقيدة أو ديانة ، فليس من المنطقي إيصال ذلك إلى حد العبثية. ولكن إذا كنت ترغب حقًا في ذلك ، فيمكنك ، على سبيل المثال ، إجراء عملية عشوائية على البيانات الموجودة على التثبيت بحيث لا يتم ترميزها.
ريفاكتور
لا أرى الكثير من إعادة البناء هنا ، لذلك يمكن تخطي هذه المرحلة لهذا الاختبار المحدد. لكنني ما زلت لا أوصي بتجاهل هذه المرحلة ، فمن الأفضل التوقف والتفكير في كل مرة في الحالة "الخضراء" للنظام - هل من الممكن إعادة تشكيل شيء لجعله أفضل وأسهل؟
الاختبار الثاني
لكن الاختبار الثاني سوف يتحقق بالفعل من عدم وجود كعكة تمت ترقيتها ضمن النتيجة التي يتم إرجاعها بواسطة findPromotedCakes .
@Test void shouldNotReturnNonPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle) .doesNotContain(NON_PROMOTED_CAKE); }
احمر
الاختبار ، كما هو متوقع ، تعطل - هناك سجلان في قاعدة البيانات والرمز ببساطة إرجاع كل منهم.
الأخضر
ومرة أخرى يمكنك التفكير - وما هو الحد الأدنى للكود الذي يمكنك كتابته لاجتياز الاختبار؟ نظرًا لوجود دفق وتجميعه بالفعل ، يمكنك ببساطة إضافة كتلة filter هناك.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false) .filter(cakeEntity -> cakeEntity.promoted) .map(cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
نقوم بإعادة تشغيل الاختبارات - اختبارات التكامل أصبحت الآن خضراء. لقد حان لحظة مهمة - نظرًا للجمع بين اختبار الوحدة لوحدة التحكم واختبار التكامل للعمل مع قاعدة البيانات ، أصبحت الميزة جاهزة - ويمر اختبار واجهة المستخدم الآن!
ريفاكتور
وبما أن جميع الاختبارات خضراء - فقد حان وقت إعادة التفاعل. أعتقد أنه ليست هناك حاجة لتوضيح أن التصفية في الذاكرة ليست فكرة جيدة ، فمن الأفضل القيام بذلك في قاعدة البيانات. للقيام بذلك ، أضفت طريقة جديدة في CakesRepository - findByPromotedIsTrue :
interface CakeRepository extends CrudRepository<CakeEntity, String> { Iterable<CakeEntity> findByPromotedIsTrue(); }
لهذه الطريقة ، قامت Spring Data تلقائيًا بإنشاء طريقة من شأنها تنفيذ استعلام من النموذج select from cakes where promoted = true . اقرأ المزيد حول إنشاء الاستعلام في وثائق Spring Data.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findByPromotedIsTrue() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
هذا مثال جيد على المرونة التي يوفرها اختبار التكامل ونهج الصندوق الأسود. إذا تم تأمين المستودع ، فلن يكون من المستحيل إضافة طريقة جديدة دون تغيير الاختبارات.
اتصال إلى قاعدة الإنتاج
لإضافة القليل من "الواقعية" وإظهار كيف يمكنك فصل التكوين للاختبارات والتطبيق الرئيسي ، سأضيف تكوين وصول إلى البيانات لتطبيق "الإنتاج".
تتم إضافة كل شيء تقليديًا بواسطة القسم الموجود في application.yml :
datasource: url: jdbc:h2:./data/cake-factory
سيؤدي هذا تلقائيًا إلى حفظ البيانات في نظام الملفات إلى مجلد ./data . ألاحظ أنه لن يتم إنشاء هذا المجلد في الاختبارات - @DataJpaTest تلقائيًا محل اتصال قاعدة بيانات الملف بقاعدة بيانات عشوائية في الذاكرة بسبب وجود تعليق توضيحي @AutoConfigureTestDatabase .
, — data.sql schema.sql . , Spring Boot . , , , .
الخاتمة
, , , TDD .
Spring Security — Spring, .