تلقى دلالات اللغة الروسية المفتوحة ، حول التاريخ الذي يمكن أن تقرأ
هنا وهنا ، تحديث كبير. لقد جمعنا ما يكفي من البيانات لتطبيق التعلم الآلي أعلى العلامات المجمعة وبناء نموذج لغوي دلالي. ما خرج منه ، انظر تحت القطع.

ماذا نفعل
خذ مجموعتين من الكلمات:
- الجري ، إطلاق النار ، التخطيط ، المشي ، المشي ؛
- عداء ، مصور ، مهندس ، سائح ، رياضي.
ليس من الصعب على أي شخص تحديد أن المجموعة الأولى تحتوي على أسماء تسمي
أفعالًا أو أحداثًا ؛ في الثانية - دعوة
الناس . هدفنا هو تعليم آلة لحل مثل هذه المشاكل.
للقيام بذلك ، يجب عليك:
- تعرف على الطبقات الطبيعية الموجودة في اللغة.
- حدد عددًا كافيًا من الكلمات حول موضوع الانتماء إلى الفئات في الفقرة 1 .
- قم بإنشاء خوارزمية تتعلم على الترميز من العنصر 2 وتعيد إنتاج التصنيف بكلمات غير مألوفة.
هل من الممكن حل هذه المشكلة بمساعدة دلالات التوزيع؟word2vec هي أداة ممتازة ، لكنها ما زالت تفضل القرب الموضوعي للكلمات ، بدلاً من تشابه الطبقات الدلالية. لإظهار هذه الحقيقة ، قم بتشغيل الخوارزمية بالكلمات من المثال:
w1 | w2 | cosine_sim | | | | | | 1.0000 | | | 0.6618 | | | 0.5410 | | | 0.3389 | | | 0.1531 | | | 0.1342 | | | 0.1067 | | | 0.0681 | | | 0.0458 | | | 0.0373 | | | | | | 1.0000 | | | 0.5782 | | | 0.2525 | | | 0.2116 | | | 0.1644 | | | 0.1579 | | | 0.1342 | | | 0.1275 | | | 0.1100 | | | 0.0975 | | | | | | 1.0000 | | | 0.3575 | | | 0.2116 | | | 0.1587 | | | 0.1207 | | | 0.1067 | | | 0.0889 | | | 0.0794 | | | 0.0705 | | | 0.0430 | | | | | | 1.0000 | | | 0.1896 | | | 0.1753 | | | 0.1644 | | | 0.1548 | | | 0.1531 | | | 0.0889 | | | 0.0794 | | | 0.0568 | | | -0.0013 | | | | | | 1.0000 | | | 0.5410 | | | 0.3442 | | | 0.2469 | | | 0.1753 | | | 0.1650 | | | 0.1207 | | | 0.1100 | | | 0.0673 | | | 0.0642 | | | | | | 1.0000 | | | 0.6618 | | | 0.4909 | | | 0.3442 | | | 0.1548 | | | 0.1427 | | | 0.1422 | | | 0.1275 | | | 0.1209 | | | 0.0705 | | | | | | 1.0000 | | | 0.5782 | | | 0.3687 | | | 0.2334 | | | 0.1911 | | | 0.1587 | | | 0.1209 | | | 0.0642 | | | 0.0373 | | | -0.0013 | | | | | | 1.0000 | | | 0.3575 | | | 0.2334 | | | 0.1579 | | | 0.1503 | | | 0.1447 | | | 0.1422 | | | 0.0673 | | | 0.0568 | | | 0.0458 | | | | | | 1.0000 | | | 0.3687 | | | 0.2525 | | | 0.1896 | | | 0.1650 | | | 0.1503 | | | 0.1495 | | | 0.1427 | | | 0.0681 | | | 0.0430 | | | | | | 1.0000 | | | 0.4909 | | | 0.3389 | | | 0.2469 | | | 0.1911 | | | 0.1495 | | | 0.1447 | | | 0.0975 | | | 0.0889 | | | 0.0889 |
كيف الدلالات المفتوحة يحل هذه المشكلةالبحث في
القاموس الدلالي يعطي النتيجة التالية:
| | | | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | HUMAN | | HUMAN | | HUMAN | | HUMAN | | HUMAN |
ما تم القيام به وأين لتحميل
إن نتيجة العمل المنشور في
المستودع على GC والمتاحة للتنزيل هي وصف للتسلسل الهرمي للفئة وترميز (يدوي وتلقائي) للأسماء لهذه الفئات.
للتعرف على مجموعة البيانات ، يمكنك استخدام المستعرض التفاعلي (الرابط في المستودع). هناك أيضًا نسخة مبسطة من المجموعة التي أزلنا فيها التسلسل الهرمي بأكمله وقمنا بتعيين علامة فردية كبيرة واحدة لكل كلمة: "أشخاص" ، "حيوانات" ، "أماكن" ، "أشياء" ، "إجراءات" ، إلخ.
رابط إلى جيثب: دلالات اللغة الروسية المفتوحة (مجموعة البيانات) .
حول فصول الكلمات
في مشكلات التصنيف ، غالبًا ما تملي الفئات نفسها المشكلة التي يتم حلها ، وينتهي عمل مهندس البيانات إلى العثور على مجموعة ناجحة من السمات التي يمكنك بناء نموذج عمل عليها.
في مشكلتنا ، فصول الكلمات ، بالمعنى الدقيق للكلمة ، غير معروفة مسبقًا. هنا توجد مجموعة كبيرة من أبحاث الدلالات التي أجراها اللغويون المحليون والأجانب ، والألفة مع القواميس الدلالية الموجودة و WordNet'es تأتي في طور الإنقاذ.
هذه مساعدة جيدة ، ولكن لا يزال يتم تشكيل القرار النهائي بالفعل ضمن بحثنا الخاص. هذا هو الشيء. بدأ إنشاء العديد من الموارد الدلالية في عصر ما قبل الكمبيوتر (على الأقل في الفهم الحديث للكمبيوتر) وتم اختيار الطبقات إلى حد كبير بسبب الحدس اللغوي لمبدعيها. في نهاية القرن الماضي ، تم استخدام WordNet بنشاط في مهام تحليل النص التلقائي ، وتم شحذ العديد من الموارد التي تم إنشاؤها حديثًا لتطبيقات عملية محددة.
وكانت النتيجة أن هذه الموارد اللغوية تحتوي في وقت واحد على معلومات لغوية وخارجية ، موسوعية حول وحدات اللغة. من المنطقي أن نفترض أنه من المستحيل بناء نموذج من شأنه أن يتحقق من المعلومات اللامنهجية ، بالاعتماد فقط على التحليل الإحصائي للنصوص ، لأن مصدر البيانات ببساطة لا يحتوي على المعلومات اللازمة.
بناءً على هذا الافتراض ، نحن نبحث فقط عن الطبقات الطبيعية التي يمكن اكتشافها والتحقق منها تلقائيًا بناءً على نموذج لغوي بحت. في الوقت نفسه ، تسمح بنية النظام بإضافة عدد كبير بشكل تعسفي من طبقات إضافية من المعلومات حول الوحدات اللغوية ، والتي يمكن أن تكون مفيدة في التطبيقات العملية.
سنعرض ما ذكر أعلاه مع مثال محدد ، من خلال تحليل كلمة "الثلاجة". من النموذج اللغوي ، يمكننا أن نعرف أن "الثلاجة" هي كائن مادي ، أو تصميم ، أو حاوية من نوع "box أو bag" ، أي غير مخصص لتخزين السوائل أو المواد الصلبة دون حاوية إضافية. علاوة على ذلك ، ليس من الواضح من هذا النموذج أن "الثلاجة" هي سلعة ، علاوة على ذلك ، منتج دائم ، وليس من الواضح أيضًا أن هذه قطعة أثرية ، أي كائن من صنع الإنسان. هذه معلومات غير لغوية ، ويجب توفيرها بشكل منفصل.
نتيجة نموذج لكلمة "ثلاجة" لماذا كل هذا مطلوب
سواء كان الأمر كذلك ، في عملية التعلم والإدراك للواقع ، يقوم الشخص بربط المعلومات الإضافية حول الأشياء والظواهر المحيطة به على الإطار الطبيعي ، الذي تعلمه في الطفولة. ومع ذلك ، فإن بعض المفاهيم عالمية ومستقلة عن مجال الموضوع ، ويمكن إعادة استخدامها بنجاح.
قل "البائع" هو
شخص +
دور وظيفي . في بعض الحالات ، قد يكون البائع مجموعة من الأشخاص أو مؤسسة ، ولكن يتم الحفاظ على الذاتية دائمًا: وإلا ، فلن يكون الإجراء المستهدف ممكنًا. تشير عبارة "تبادل" أو "تدريب" إلى الإجراءات ، أي لديهم المشاركين ، والمدة والنتائج. يمكن أن يختلف المحتوى الدقيق لهذه الإجراءات اختلافًا كبيرًا تبعًا للموقف ومجال الموضوع ، ولكن بعض الجوانب ستكون ثابتة. هذا هو الإطار اللغوي الذي تعتمد عليه المعرفة اللغوية المتغيرة.
هدفنا هو إيجاد واستكشاف الحد الأقصى من المعلومات اللغوية المتاحة وبناء نموذج توضيحي للغة على أساسها. سيؤدي ذلك إلى تحسين الخوارزميات الموجودة لمعالجة الكلمات تلقائيًا ، بما في ذلك مثل تلك المعقدة مثل حل الغموض المعجمي ، وحل الجاذبية ، والحالات المعقدة للعلامات المورفولوجية. في هذه العملية ، سنكون بالضرورة في مكان ما ضد الحاجة لاجتذاب المعرفة اللغوية ، لكننا سنعرف على الأقل إلى أين تذهب الحدود ذاتها عندما لم تعد المعرفة الداخلية باللغة كافية.
التصنيف والتدريب ، مجموعة من الصفات
في الوقت الحالي ، نعمل فقط مع الأسماء ، وبالتالي أدناه ، عندما نقول "كلمة" ، فإننا نعني العلامات التي تتعلق فقط بهذا الجزء من الكلام. نظرًا لأننا قررنا استخدام المعلومات اللغوية فقط ، فسنعمل مع النصوص المزودة بالعلامات المورفولوجية.
كعلامات ، نأخذ جميع النصوص المصغرة الممكنة التي تحدث فيها هذه الكلمة. بالنسبة للأسماء ، ستكون هذه:
- APP + X (جميلة X: عيون)
- GLAG + X (vdite X: thread)
- VL + PRED + X (أدخل X: door)
- X + SUSCH_ROD (X: حافة الجدول)
- SUSHCH + X_ROD (مقبض X: السيوف)
- X_ SUBJECT + GL (X: المؤامرة قيد التطوير)
هناك المزيد من أنواع النصوص المصغرة ، ولكن ما سبق هو الأكثر تكرارًا ويعطي بالفعل نتيجة جيدة عند التعلم.
جميع النصوص المصغرة يتم اختزالها إلى الشكل الأساسي ونؤلف مجموعة من الميزات منها. بعد ذلك ، بالنسبة لكل كلمة ، نؤلف متجهًا يرتبط إحداثيته ithth مع حدوث كلمة معينة في النص
الصغير i .
جدول Microcontext لكلمة "ظهره" | | | | | | | | | VBP_ | 3043 | 1.0000 | | ADJ | 2426 | 0.9717 | | NX_NG | 1438 | 0.9065 | | VBP_ | 1415 | 0.9045 | | VBP__ | 1300 | 0.8940 | | NX_NG | 1292 | 0.8932 | | NX_NG | 1259 | 0.8900 | | ADJ | 1230 | 0.8871 | | ADJ | 1116 | 0.8749 | | ADJ | 903 | 0.8485 | | ADJ | 849 | 0.8408 | | NX_NG | 814 | 0.8356 | | ADJ | 795 | 0.8326 | | ADJ | 794 | 0.8325 | | VBP_ | 728 | 0.8217 | | ADJ | 587 | 0.7948 | | ADJ | 587 | 0.7948 | | VBP__ | 567 | 0.7905 | | VBP_ | 549 | 0.7865 | | VBP__ | 538 | 0.7840 | | VBP_ | 495 | 0.7736 | | VBP_ | 484 | 0.7708 | | NX_NG | 476 | 0.7687 | | ADJ | 463 | 0.7652 | | NX_NG | 459 | 0.7642 |
القيمة المستهدفة ، التسلسل الهرمي للتقسيم الدلالي
للغة آليات طبيعية لإعادة استخدام الكلمات ، مما يسبب ظهور ظاهرة مثل polysemy. علاوة على ذلك ، في بعض الأحيان لا يتم استخدام الكلمات الفردية فقط ، ولكن يتم إجراء نقل مجازي لمفاهيم بأكملها. هذا ملحوظ بشكل خاص في الانتقال من المفاهيم المادية إلى المفاهيم المجردة.
تفرض هذه الحقيقة الحاجة إلى التصنيف الهرمي ، حيث يتم ترتيب المقاطع الدلالية في بنية شجرة ويحدث القسم في كل عقدة داخلية. هذا يتيح لك التعامل مع الغموض في النصوص الدقيقة بشكل أكثر فعالية.
أمثلة على نقل المفهوم المجازيبالإضافة إلى حل المشكلات العملية الملحة في اللغويات الحاسوبية ، يهدف عملنا إلى دراسة الكلمة والظواهر اللغوية المختلفة. يعتبر الانتقال المجازي للمفاهيم من المستوى الحقيقي إلى الملخص ظاهرة معروفة لدى اللغويين الإدراكيين. لذلك ، على سبيل المثال ، واحدة من ألمع المفاهيم في العالم المادي هي "الحاوية" الطبقية (في الأدب باللغة الروسية يُشار إليها غالبًا باسم "الحاوية").
الاستعارة الوجودية الأخرى في كل مكان هي استعارة الحاوية ، أو الحاوية ، مما يعني رسم الحدود في استمرارية تجربتنا وفهمها من خلال الفئات المكانية. وفقًا للمؤلفين ، فإن الطريقة التي ينظر بها الشخص إلى العالم من حوله تتحدد بتجربته في التعامل مع الأشياء المادية المنفصلة ، ولا سيما تصوره لجسده. الرجل مخلوق محدد من بقية العالم بالجلد. إنه حاوية ، وبالتالي من الشائع أن يرى كيانات أخرى كحاويات ذات جزء داخلي وسطح خارجي.
Skrebtsova T. G. اللغويات المعرفية: النظريات الكلاسيكية ، جديد
النهج
يعمل النموذج الذي أنشأناه في مساحة واحدة من السمات ويسمح لنا بالتعلم من أمثلة حقيقية ، والتنبؤات في مجال الملخص. هذا يسمح لك بالقيام بعملية النقل الموضحة أعلاه. لذلك ، على سبيل المثال ، الكلمات التالية عبارة عن حاويات مجردة ، والتي تتوافق مع الفكرة البديهية:

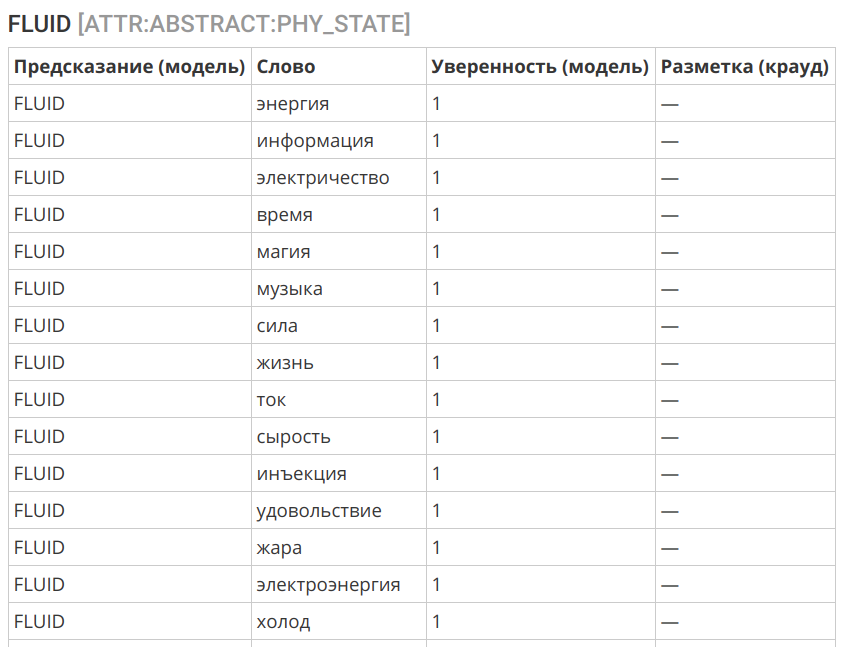
مثال آخر مثير للاهتمام هو نقل مفهوم "السائل" إلى مجال غير الملموس:
اختيار الخوارزمية
كخوارزمية ، استخدمنا الانحدار اللوجستي. هذا بسبب عدة عوامل:
- بطريقة أو بأخرى ، تحتوي العلامات الأولية على قدر معين من الأخطاء والضوضاء.
- يمكن أن تكون العلامات غير متوازنة وتحتوي أيضًا على أخطاء - استخدام polysemy والاستعاري (المجازي) للكلمة.
- يشير التحليل الأولي إلى ضرورة إصلاح واجهة محددة بشكل مناسب باستخدام خوارزمية بسيطة إلى حد ما.
- التفسير الجيد للخوارزمية هو المهم.
أظهرت الخوارزمية دقة جيدة للغاية:
سجلات خوارزمية العلامات == ENTITY == slice | label | count | correctCount | accuracy | | | | | | ENTITY | PHYSICAL | 12249 | 11777 | 0.9615 | ENTITY | ABSTRACT | 9854 | 9298 | 0.9436 | | | | | | | | | | 0.9535 | == PHYSICAL:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:ROLE | ORGANIC | 7001 | 6525 | 0.9320 | PHYSICAL:ROLE | INORGANIC | 3805 | 3496 | 0.9188 | | | | | | | | | | 0.9274 | == PHYSICAL:ORGANIC:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:ORGANIC:ROLE | HUMAN | 4879 | 4759 | 0.9754 | PHYSICAL:ORGANIC:ROLE | ANIMAL | 675 | 629 | 0.9319 | PHYSICAL:ORGANIC:ROLE | FOOD | 488 | 411 | 0.8422 | PHYSICAL:ORGANIC:ROLE | ANATOMY | 190 | 154 | 0.8105 | PHYSICAL:ORGANIC:ROLE | PLANT | 285 | 221 | 0.7754 | | | | | | | | | | 0.9474 | == PHYSICAL:INORGANIC:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:INORGANIC:ROLE | CONSTRUCTION | 1045 | 933 | 0.8928 | PHYSICAL:INORGANIC:ROLE | THING | 2385 | 2123 | 0.8901 | PHYSICAL:INORGANIC:ROLE | SUBSTANCE | 399 | 336 | 0.8421 | | | | | | | | | | 0.8859 | == PHYSICAL:CONSTRUCTION:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:CONSTRUCTION:ROLE | TRANSPORT | 188 | 178 | 0.9468 | PHYSICAL:CONSTRUCTION:ROLE | APARTMENT | 270 | 241 | 0.8926 | PHYSICAL:CONSTRUCTION:ROLE | TERRAIN | 285 | 253 | 0.8877 | | | | | | | | | | 0.9044 | == PHYSICAL:THING:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:THING:ROLE | WEARABLE | 386 | 357 | 0.9249 | PHYSICAL:THING:ROLE | TOOLS | 792 | 701 | 0.8851 | PHYSICAL:THING:ROLE | DISHES | 199 | 174 | 0.8744 | PHYSICAL:THING:ROLE | MUSIC_INSTRUMENTS | 63 | 51 | 0.8095 | PHYSICAL:THING:ROLE | WEAPONS | 107 | 69 | 0.6449 | | | | | | | | | | 0.8739 | == PHYSICAL:TOOLS:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:TOOLS:ROLE | PHY_INTERACTION | 213 | 190 | 0.8920 | PHYSICAL:TOOLS:ROLE | INFORMATION | 101 | 71 | 0.7030 | PHYSICAL:TOOLS:ROLE | EM_ENERGY | 72 | 49 | 0.6806 | | | | | | | | | | 0.8031 | == ATTR:INORGANIC:WEARABLE == slice | label | count | correctCount | accuracy | | | | | | ATTR:INORGANIC:WEARABLE | NON_WEARABLE | 538 | 526 | 0.9777 | ATTR:INORGANIC:WEARABLE | WEARABLE | 282 | 269 | 0.9539 | | | | | | | | | | 0.9695 | == ATTR:PHYSICAL:CONTAINER == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:CONTAINER | CONTAINER | 636 | 627 | 0.9858 | ATTR:PHYSICAL:CONTAINER | NOT_A_CONTAINER | 1225 | 1116 | 0.9110 | | | | | | | | | | 0.9366 | == ATTR:PHYSICAL:CONTAINER:TYPE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:CONTAINER:TYPE | CONFINED_SPACE | 291 | 287 | 0.9863 | ATTR:PHYSICAL:CONTAINER:TYPE | CONTAINER | 140 | 131 | 0.9357 | ATTR:PHYSICAL:CONTAINER:TYPE | OPEN_AIR | 72 | 64 | 0.8889 | ATTR:PHYSICAL:CONTAINER:TYPE | BAG_OR_BOX | 43 | 31 | 0.7209 | ATTR:PHYSICAL:CONTAINER:TYPE | CAVITY | 30 | 20 | 0.6667 | | | | | | | | | | 0.9253 | == ATTR:PHYSICAL:PHY_STATE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:PHY_STATE | SOLID | 308 | 274 | 0.8896 | ATTR:PHYSICAL:PHY_STATE | FLUID | 250 | 213 | 0.8520 | ATTR:PHYSICAL:PHY_STATE | FABRIC | 72 | 51 | 0.7083 | ATTR:PHYSICAL:PHY_STATE | PLASTIC | 78 | 42 | 0.5385 | ATTR:PHYSICAL:PHY_STATE | SAND | 70 | 31 | 0.4429 | | | | | | | | | | 0.7853 | == ATTR:PHYSICAL:PLACE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:PLACE | NOT_A_PLACE | 855 | 821 | 0.9602 | ATTR:PHYSICAL:PLACE | PLACE | 954 | 914 | 0.9581 | | | | | | | | | | 0.9591 | == ABSTRACT:ROLE == slice | label | count | correctCount | accuracy | | | | | | ABSTRACT:ROLE | ACTION | 1497 | 1330 | 0.8884 | ABSTRACT:ROLE | HUMAN | 473 | 327 | 0.6913 | ABSTRACT:ROLE | PHYSICS | 257 | 171 | 0.6654 | ABSTRACT:ROLE | INFORMATION | 222 | 146 | 0.6577 | ABSTRACT:ROLE | ABSTRACT | 70 | 15 | 0.2143 | | | | | | | | | | 0.7896 |
تحليل الأخطاء
الأخطاء الناجمة عن التصنيف التلقائي ناتجة عن ثلاثة عوامل رئيسية:
- Homonymy و polysemy: الكلمات التي لها نفس النوع يمكن أن يكون لها معان مختلفة (عذاب a و m u ka ، تتوقف كعملية وتتوقف كموقع ). يمكن أن يشمل ذلك أيضًا الاستخدام المجازي للكلمات و metonymy (على سبيل المثال ، سيتم تصنيف الباب كمساحة مغلقة - وهذه ميزة متوقعة من اللغة).
- عدم التوازن في سياق استخدام الكلمة. قد لا تتوفر بعض الاستخدامات العضوية في الحزمة الأصلية ، مما يؤدي إلى أخطاء التصنيف.
- حدود الفئة غير صالحة. يمكنك رسم حدود غير قابلة للحساب من السياقات وتتطلب مشاركة المعرفة اللغوية. هنا ستكون الخوارزمية عاجزة.
في هذه المرحلة ، نولي اهتمامًا فقط للأخطاء من النوع الثالث وضبط الحدود المحددة بين الفصول الدراسية. لا يمكن القضاء على أخطاء النوعين الأولين في تكوين معين للنظام ، ولكن مع وجود كمية كافية من البيانات المصنفة ، فإنها لا تمثل مشكلة كبيرة - يمكن ملاحظة ذلك من خلال دقة تمييز الإسقاطات العليا.
ما التالي
في الوقت الحالي ، تغطي مجموعة البيانات معظم الأسماء الموجودة في اللغة الروسية وممثلة في المجموعة في مجموعة متنوعة كافية من السياقات. تم التركيز بشكل رئيسي على الأشياء المادية - كما هو الأكثر تفهماً وتفصيلاً في الأعمال العلمية. تبقى المهام لتحسين الترميز الحالي ، مع مراعاة البيانات الواردة من الخوارزمية ، والعمل مع الطبقات على المستويات الدنيا ، حيث لوحظ انخفاض في دقة التنبؤ ، بسبب عدم وضوح الحدود بين الفئات.
ولكن هذا هو نوع من العمل الروتيني ، الذي هو دائما هناك. ستتعلق طبقة بحثية جديدة نوعيًا بإمكانية تصنيف كلمة معينة في سياق أو جملة محددة ، مما سيسمح بأخذ ظواهر homonymy و polysemy بعين الاعتبار ، بما في ذلك الاستعارة (المعاني المجازية).
أيضًا ، نحن نعمل حاليًا على العديد من المشاريع ذات الصلة:
- قاموس التعرّف على الكلمات RY: تباين في قاموس التكرار ، حيث يتم تقييم شمولية الكلمة وإلمامها كنتيجة لترميز التعهيد الجماعي ، ولا يتم حسابها وفقًا لمجموعة النصوص.
- فيلق مفتوح لحل الغموض المعجمي: بناءً على مسابقة RUSSE 2018 WSI & D للمهام المشتركة التي عقدت كجزء من مؤتمر Dialogue 2018 ، أصبحت فائدة المجموعة مع الغموض المعجمي الذي تم إزالته لاختبار الخوارزميات التلقائية لإزالة الغموض وتجميع معاني الكلمات واضحة. سنحتاج أيضًا إلى هذه الهيئة للذهاب إلى مرحلة العمل حول الدلالات المفتوحة الموضحة في الفقرة السابقة.
قاموس نغمي للغة الروسية
القاموس النغمي هو الكلمات والتعبيرات من OJ ، تتميز النغمة وقوة شدة شحنة التقييم العاطفي. ببساطة ، كم كلمة معينة هي "سيئة" أو "جيدة".
في الوقت الحالي ، يتم تمييز 67.392 حرفًا (منها 55.532 كلمة و 11.860 تعبيرًا).
ردود الفعل والتوزيع
نرحب بأي تعليقات في التعليقات - من نقد العمل ونُهُجنا إلى روابط إلى دراسات مثيرة للاهتمام ومقالات ذات صلة.
إذا كان لديك معارف أو زملاء قد يكونوا مهتمين بمجموعة البيانات المنشورة ، فأرسل لهم رابطًا للمقال أو المستودع للمساعدة في نشر البيانات المفتوحة.
رابط التحميل والترخيص
مجموعة البيانات: دلالات مفتوحة للغة الروسيةمجموعة البيانات مرخصة بموجب
CC BY-NC-SA 4.0 .