لقد
تحدثنا مؤخرًا عن كيفية الحصول على تدريب داخلي في Google. بالإضافة إلى Google ، يجرب طلابنا أيديهم في JetBrains و Yandex و Acronis وغيرها من الشركات.
في هذه المقالة ، سوف أشارك تجربتي في التدريب الداخلي في
JetBrains Research ، وأتحدث عن المهام التي يحلونها هناك ، وسأشرح كيف يمكن أن يبحث التعليم الآلي عن الأخطاء في رمز البرنامج.

عن نفسي
اسمي إيغور بوغومولوف ، أنا طالب في السنة الرابعة من درجة سانت بطرسبرغ للصحة والسلامة والبيئة في الرياضيات التطبيقية وعلوم الكمبيوتر. خلال السنوات الثلاث الأولى ، درست ، مثل زملائي في الفصل الدراسي ، في الجامعة الأكاديمية ، ومنذ سبتمبر انتقلنا إلى الكلية العليا للاقتصاد مع القسم بأكمله.
بعد السنة الثانية ذهبت إلى دورة تدريبية صيفية في Google Zurich. هناك أمضيت ثلاثة أشهر في فريق Android Calendar ، وأغلب الوقت أقوم بعمل frontend'om وقليلًا من أبحاث UX. كان الجزء الأكثر إثارة للاهتمام من عملي هو البحث عن كيفية ظهور واجهات التقويم في المستقبل. اتضح أنه من الجيد أن كل العمل الذي قمت به تقريبًا بنهاية فترة التدريب الداخلي انتهى به المطاف في الإصدار الرئيسي من التطبيق. لكن موضوع التدريب الداخلي في Google تمت تغطيته جيدًا في منشور سابق ، لذلك سأتحدث عما فعلته هذا الصيف.
ما هو البحث JB؟
JetBrains Research هي مجموعة من المختبرات العاملة في مختلف المجالات: لغات البرمجة والرياضيات التطبيقية والتعلم الآلي والروبوتات وغيرها. داخل كل مجال هناك العديد من المجموعات العلمية. بسبب توجهي ، فأنا أفضل معرفة بأنشطة المجموعات في مجال التعلم الآلي. يستضيف كل منهم حلقات دراسية أسبوعية يتحدث فيها أعضاء المجموعة أو الضيوف المدعوين عن عملهم أو مقالات مثيرة في مجالهم. يأتي العديد من الطلاب من HSE إلى هذه الندوات ، لأنهم يعبرون الطريق من المبنى الرئيسي لحرم HSE في سانت بطرسبرغ.
في برنامج البكالوريوس لدينا ، نشارك بشكل إلزامي في العمل البحثي (R&D) ونقدم نتائج البحث مرتين في السنة. في كثير من الأحيان هذا العمل يتطور تدريجيا إلى التدريب الصيفي. حدث هذا أيضًا مع عملي البحثي: قمت هذا الصيف بفترة تدريب داخلي في مختبر "أساليب التعلم الآلي في هندسة البرمجيات" مع المشرف البحثي الخاص بي Timofey Bryksin. تتضمن المهام التي يتم العمل عليها في هذا المختبر اقتراحات إعادة التخزين التلقائي ، وتحليل نمط الكود للمبرمجين ، واستكمال الكود ، والبحث عن الأخطاء في كود البرنامج.
استمر التدريب لمدة شهرين (يوليو وأغسطس) ، وفي الخريف واصلت المشاركة في المهام الموكلة في إطار البحث. لقد عملت في عدة مجالات ، أكثرها إثارة للاهتمام ، في رأيي ، كانت البحث التلقائي عن الأخطاء في الكود ، وأريد أن أتحدث عنها. كانت نقطة البداية
مقالة كتبها مايكل براديل .
البحث التلقائي عن الأخطاء
كيف يتم البحث عن الأخطاء الآن؟
لماذا تبدو الأخطاء أكثر أو أقل وضوحًا. دعونا نرى كيف يفعلون الآن. تستند أجهزة كشف الأخطاء الحديثة بشكل أساسي إلى تحليل الشفرة الثابتة. لكل نوع من الأخطاء ، ابحث عن الأنماط التي تم ملاحظتها مسبقًا والتي يمكن من خلالها تحديدها. ثم ، لتقليل عدد الإيجابيات الخاطئة ، يتم اختراع الاستدلال ، اخترع لكل حالة على حدة. يمكن البحث عن الأنماط على حد سواء في شجرة بناء الجملة المجردة (AST) التي تم إنشاؤها بواسطة رمز وفي الرسوم البيانية لتدفق التحكم أو البيانات.
int foo() { if ((x < 0) || x > MAX) { return -1; } int ret = bar(x); if (ret != 0) { return -1; } else { return 1; } }
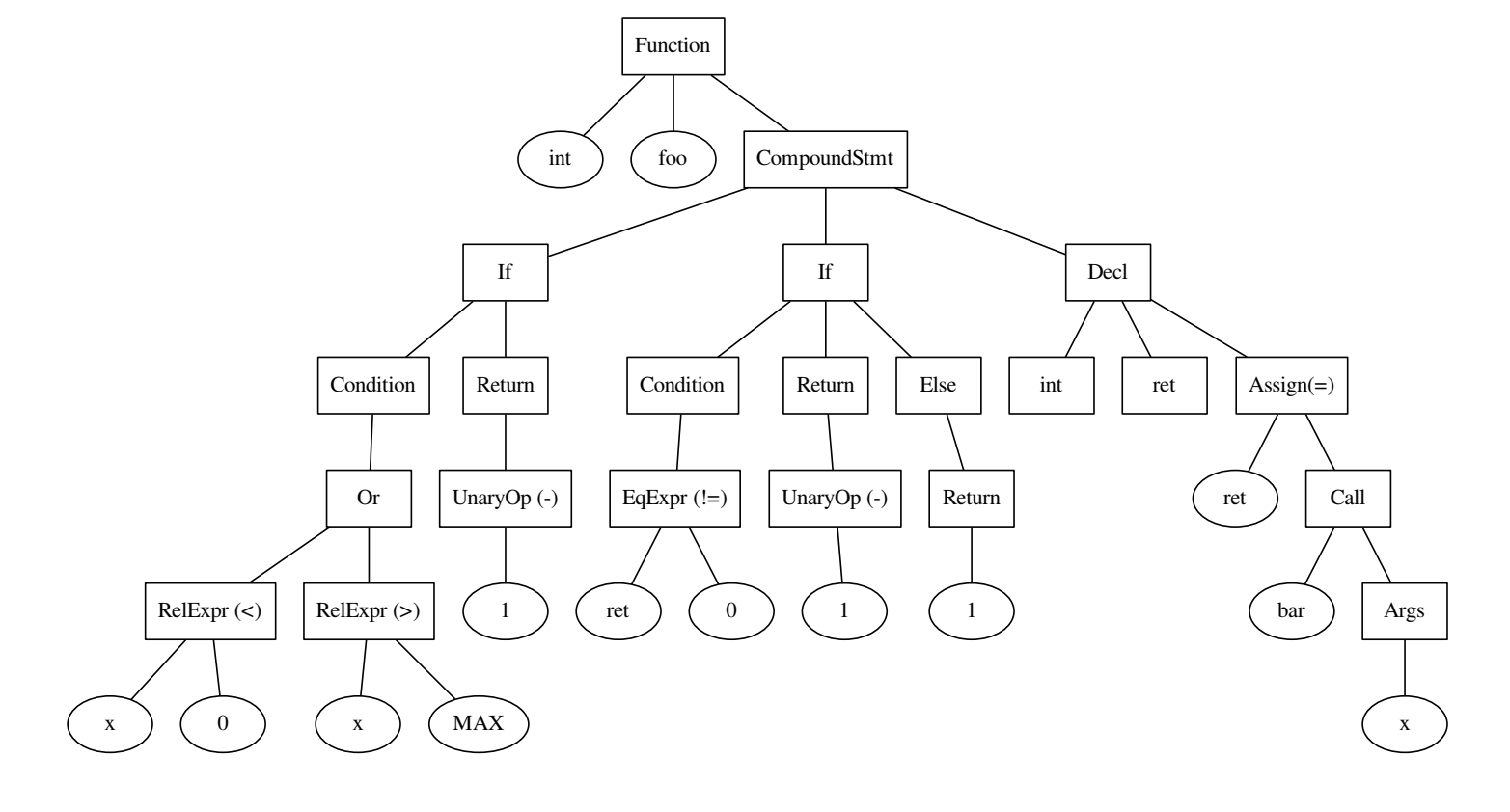
الكود والشجرة التي بنيت عليه.
لفهم كيف يعمل هذا ، فكر في مثال. يمكن أن يكون نوع الأخطاء استخدام = بدلاً من == في C ++. لنلقِ نظرة على الكود التالي:
int value = 0; … if (value = 1) { ... } else { … }
حدث خطأ في التعبير الشرطي ، في حين أن أول = في تعيين القيمة للمتغير صحيح. يأتي النموذج من هنا: إذا تم استخدام الواجب داخل الشرط في ، فهذا خطأ محتمل. تبحث عن مثل هذا النمط في AST ، يمكننا اكتشاف الخطأ وتصحيحه.
int value = 0; … if (value == 1) { ... } else { … }
في حالة أكثر عمومية ، لن نتمكن من العثور بسهولة على طريقة لوصف الخطأ. لنفترض أننا نريد تحديد الترتيب الصحيح للمعاملات. مرة أخرى ، انظر إلى أجزاء الكود:
for (int i = 2; i < n; i++) { a[i] = a[1 - i] + a[i - 2]; }
int bitReverse(int i) { return 1 - i; }
في الحالة الأولى ، كان استخدام 1-i خاطئًا ، وفي الحالة الثانية كان صحيحًا تمامًا ، وهو واضح من السياق. ولكن كيف تصفها في شكل نمط؟ مع تعقيد نوع الأخطاء ، يتعين علينا النظر في قسم أكبر من التعليمات البرمجية وتحليل المزيد من الحالات الفردية.
المثال التحفيزي الأخير: المعلومات المفيدة موجودة أيضًا في أسماء الطرق والمتغيرات. من الصعب التعبير عن بعض الشروط المحددة يدويًا.
int getSquare(int xDim, int yDim) { … } int x = 3, y = 4; int s = getSquare(y, x);
يدرك الشخص ، على الأرجح ، أن الحجج في استدعاء الوظيفة يتم خلطها ، لأن لدينا فهم أن x يشبه xDim أكثر من yDim. ولكن كيف تبلغ عن هذا للكاشف؟ يمكنك إضافة بعض الأساليب البحثية للنموذج "اسم المتغير هو بادئة اسم الوسيطة" ، ولكن لنفترض أن x هو في كثير من الأحيان عرض من ارتفاع ، لذلك لم يعد صريحًا.
خلاصة القول: إن المشكلة في النهج الحديث لإيجاد الأخطاء هي أنه يجب القيام بالكثير من العمل بيديك: لتحديد الأنماط ، وإضافة الاستدلال ، ولهذا السبب ، فإن إضافة دعم لنوع جديد من الأخطاء في الكاشف يستغرق وقتًا طويلاً. بالإضافة إلى ذلك ، من الصعب استخدام جزء مهم من المعلومات التي تركها المطور في الشفرة: أسماء المتغيرات والأساليب.
كيف يمكن تعلم الآلة المساعدة؟
كما لاحظت ، في العديد من الأمثلة ، تكون الأخطاء مرئية للبشر ، لكن يصعب وصفها رسميًا. في مثل هذه الحالات ، يمكن أن تساعد أساليب التعلم الآلي في كثير من الأحيان. دعونا نتوقف عن البحث عن الوسائط التي تم إعادة ترتيبها في استدعاء دالة وفهم ما نحتاج إلى البحث عنه باستخدام التعلم الآلي:
- عدد كبير من نموذج التعليمات البرمجية دون أخطاء
- كمية كبيرة من التعليمات البرمجية مع أخطاء من نوع معين
- طريقة لتوجيه شظايا رمز
- النموذج الذي سنعلمه التمييز بين الشفرة مع وبدون أخطاء
يمكننا أن نأمل أن تكون الوسيطات في استدعاءات الوظائف في الترتيب الصحيح في معظم الكود الموصول في المجال العام. لذلك ، للحصول على نموذج التعليمات البرمجية دون أخطاء ، يمكنك أن تأخذ بعض مجموعة البيانات الكبيرة. في حالة مؤلف المقال الأصلي ، كان JS 150K (150 ألف ملف في Javascript) ، في حالتنا ، مجموعة بيانات مماثلة لبيثون.
العثور على رمز مع الأخطاء هو أصعب بكثير. لكن لا يمكننا البحث عن أخطاء شخص آخر ، لكننا نفعل ذلك بنفسك! بالنسبة لنوع الأخطاء ، تحتاج إلى تحديد وظيفة ، وفقًا لرمز التعليمات البرمجية الصحيح ، ستجعلها تالفة. في حالتنا ، أعد ترتيب الوسائط في استدعاء الوظيفة.
كيف تتجه الكود؟
مسلحين بالكثير من الشفرات الجيدة والسيئة ، نحن مستعدون تقريبًا لتدريس شيء ما. قبل ذلك ، ما زلنا بحاجة للإجابة على السؤال: كيف نقدم شظايا الكود؟
يمكن تمثيل استدعاء دالة على أنه tuple من اسم الطريقة ، واسم طريقة ذلك ، أسماء وأنواع الوسائط التي تم تمريرها إلى المتغيرات. إذا تعلمنا كيفية توجيه الرموز المميزة الفردية (أسماء المتغيرات والأساليب ، وكل "الكلمات" الموجودة في الكود) ، فيمكننا أخذ سلسلة متجهات الرموز المميزة التي تهمنا والحصول على المتجه المرغوب فيه للجزء.
لتوجيه الرموز ، دعنا نلقي نظرة على كيفية تعبير الكلمات في النصوص العادية. واحدة من أنجح الطرق والشعبية هي word2vec المقترحة في عام 2013.
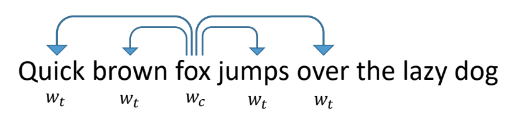
إنه يعمل على النحو التالي: نحن نعلم الشبكة أن تتنبأ بكلمة كلمات أخرى تظهر بجانبها في النصوص. تبدو الشبكة في نفس الوقت كطبقة إدخال بحجم القاموس ، وطبقة خفية من حجم الاتجاه الذي نريد الحصول عليه ، وطبقة مخرجات ، وكذلك حجم القاموس. أثناء التدريب ، يتم تغذية الشبكات بموجه وحدة إدخال مع وحدة واحدة بدلاً من الكلمة المعنية (fox) ، وفي المخرجات نريد الحصول على كلمات تحدث داخل النافذة حول هذه الكلمة (سريعة ، بنية اللون ، تقفز ، أكثر). في هذه الحالة ، تقوم الشبكة أولاً بترجمة جميع الكلمات إلى متجه على طبقة مخفية ، ثم تقوم بالتنبؤ.
المتجهات الناتجة للكلمات الفردية لها خصائص جيدة. على سبيل المثال ، تكون متجهات الكلمات ذات المعنى المماثل قريبة من بعضها البعض ، ومجموع وفرق المتجهات يمثلان إضافة واختلاف "معاني" الكلمات.
لإنشاء اتجاه مشابه للرموز في الكود ، تحتاج إلى ضبط البيئة التي سيتم التنبؤ بها بطريقة أو بأخرى. قد تكون معلومات من AST: أنواع القمم حولها ، الرموز التي تمت مواجهتها ، والموضع في شجرة.
بعد تلقي الاتجاه ، يمكنك معرفة الرموز المميزة التي تشبه بعضها البعض. للقيام بذلك ، وحساب المسافة جيب التمام بينهما. نتيجة لذلك ، يتم الحصول على المتجهات المجاورة التالية لـ Javascript (الرقم هو مسافة جيب التمام):
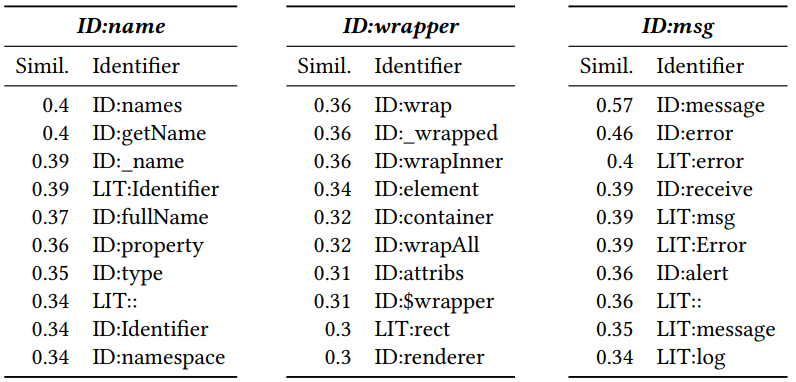
يشير المعرف و LIT المضافة في البداية إلى ما إذا كان الرمز المميز هو معرف (اسم متغير أو طريقة) أو حرفي (ثابت). يمكن أن نرى أن القرب له مغزى.
تدريب المصنف
بعد تلقي الاتجاه الخاص برموز رمزية فردية ، أصبح الحصول على عرض لرمز ما مع وجود خطأ محتمل أمرًا بسيطًا للغاية: إنه عبارة عن تسلسل للناقلات المهمة لتصنيف الرموز المميزة. يتم تدريب مادة الإدراك الخارجي المكونة من طبقتين في أجزاء من التعليمات البرمجية مع ReLU كوظيفة تنشيط وتسرب لتقليل التداخل الزائد. يتقارب التعلم بسرعة ، والنموذج الناتج صغير ويمكنه التنبؤ بمئات الأمثلة في الثانية. يتيح لك ذلك استخدامه في الوقت الفعلي ، والذي سيتم مناقشته لاحقًا.
النتائج
تم تقسيم تقييم جودة المصنف الناتج إلى قسمين: تقييم لعدد كبير من الأمثلة المصطنعة والتحقق اليدوي على عدد صغير (50 لكل كاشف) من الأمثلة ذات أعلى احتمال متوقع. وكانت النتائج للكشف عن ثلاثة (الحجج ترتيبها ، صحة المشغل الثنائي والمعامل الثنائي) كالتالي:
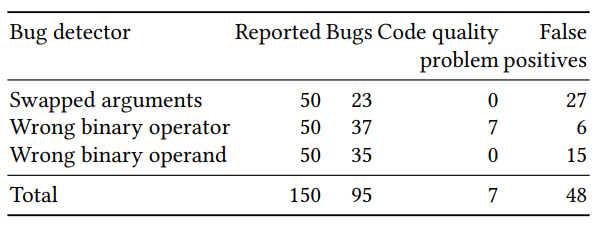
سيكون من الصعب العثور على بعض الأخطاء المتوقعة باستخدام طرق البحث الكلاسيكية. مثال مع res ترتيبها وخطأ في استدعاء p.done:
var p = new Promise (); if ( promises === null || promises . length === 0) { p. done (error , result ) } else { promises [0](error, result).then( function(res, err) { p.done(res, err); }); }
كانت هناك أيضًا أمثلة على عدم وجود خطأ ، ولكن يجب إعادة تسمية المتغيرات حتى لا تضليل الشخص الذي يحاول معرفة الكود. على سبيل المثال ، لا يبدو إضافة عرض وكل فكرة فكرة جيدة ، على الرغم من أنه تبين أنها ليست خطأ:
var cw = cs[i].width + each;
بيثون ترقية
لقد شاركت في نقل عمل Michael Pradel من js إلى python ، ثم قمت بإنشاء مكون إضافي لـ PyCharm يقوم بتنفيذ عمليات التفتيش وفقًا للطريقة الموضحة أعلاه. استخدمنا مجموعة بيانات
Python 150K (150 ألف ملف Python متوفرة على GitHub).
أولاً ، اتضح أنه في بيثون ، هناك رموز مختلفة أكثر من الجافا سكريبت. بالنسبة إلى js ، تمثل الرموز الأكثر شهرة والتي يبلغ عددها 10000 أكثر من 90٪ من إجمالي المصادفة ، بينما كان من الضروري بالنسبة لبيثون استخدام حوالي 40،000 ، مما أدى إلى زيادة حجم الرموز المميزة في المتجهات ، مما جعل من الصعب الانتقال إلى المكون الإضافي.
ثانياً ، بعد أن نفذت لبيثون بحثًا عن وسيطات غير صحيحة في استدعاءات الوظائف ونظرت في النتائج يدويًا ، حصلت على معدل خطأ بأكثر من 90٪ ، وهو ما يتعارض مع نتائج js. بعد فهم الأسباب ، اتضح أنه في جافا سكريبت ، تم الإعلان عن المزيد من الوظائف في نفس الملف مثل مكالماتهم. أنا ، باتباع مثال كاتب المقال ، في البداية لم أسمح بالإعلان عن الوظائف من ملفات أخرى ، مما أدى إلى نتائج سيئة.
قرب نهاية شهر أغسطس ، أكملت تطبيق Python وكتبت أساس المكون الإضافي. يستمر تطوير المكوّن الإضافي ، وتشارك الآن الطالبة Anastasia Tuchina من مختبرنا في هذا.
يمكنك العثور على الخطوات لتجربة كيفية عمل المكوّن الإضافي في الويكي.
روابط على جيثب:
مستودع مع تنفيذ بيثونمستودع مع البرنامج المساعد