في أوائل ديسمبر ، استضافت مونتريال المؤتمر السنوي الثاني والثلاثين
لنظم معالجة المعلومات العصبية حول التعلم الآلي. وفقًا لجدول تصنيف غير رسمي ، يعد هذا المؤتمر الحدث الأول من نوعه في العالم. تم بيع جميع تذاكر المؤتمر هذا العام في 13 دقيقة قياسية. لدينا فريق كبير من علماء البيانات MTS ، لكن واحدًا منهم فقط - مارينا ياروسلافتسيفا (
magoli ) - كان محظوظًا بما فيه الكفاية للوصول إلى مونتريال. مع دانيلا سافينكوف (
danila_savenkov ) ، التي تركت بدون تأشيرة وتابعت المؤتمر من موسكو ، سنتحدث عن الأعمال التي بدت لنا الأكثر إثارة للاهتمام. هذه العينة ذاتية للغاية ، ولكن نأمل أن تهمك.
 الشبكات العصبية المتكررة العلائقيةمجردةكود
الشبكات العصبية المتكررة العلائقيةمجردةكودعند العمل بالتسلسل ، غالبًا ما يكون من المهم جدًا كيف ترتبط عناصر التسلسل ببعضها البعض. الهندسة المعمارية القياسية لشبكات التكرار (GRU ، LSTM) بالكاد يمكن أن تشكل نموذجًا للعلاقة بين عنصرين بعيدان تمامًا عن بعضهما البعض. إلى حد ما ، يساعد الانتباه على التعامل مع هذا (
https://youtu.be/SysgYptB198 ،
https://youtu.be/quoGRI-1l0A ) ، ولكن لا يزال هذا غير صحيح تمامًا. يسمح لك Attention بتحديد الوزن الذي ستؤثر به الحالة المخفية من كل خطوة من خطوات التسلسل على الحالة المخفية النهائية ، وبالتالي على التنبؤ. نحن مهتمون بعلاقة عناصر التسلسل.
في العام الماضي ، مرة أخرى على NIPS ، اقترحت google التخلي عن التكرار تمامًا واستخدام
الاهتمام الذاتي . أثبت النهج أنه جيد جدًا ، على الرغم من ذلك بشكل أساسي في مهام seq2seq (توفر المقالة نتائج حول الترجمة الآلية).
يستخدم مؤلفو هذا العام فكرة الاهتمام الذاتي كجزء من LSTM. لا توجد تغييرات كثيرة:
- نقوم بتغيير متجه حالة الخلية إلى مصفوفة "الذاكرة" M. إلى حد ما ، مصفوفة الذاكرة هي العديد من متجهات حالة الخلية (العديد من خلايا الذاكرة). للحصول على عنصر جديد في التسلسل ، نحدد مقدار تحديث هذا العنصر لكل خلية من خلايا الذاكرة.
- لكل عنصر من عناصر التسلسل ، سنقوم بتحديث هذه المصفوفة باستخدام انتباه المنتج متعدد الرؤوس (MHDPA ، يمكنك أن تقرأ عن هذه الطريقة في المقالة المذكورة من google). يتم تشغيل نتيجة MHPDA للعنصر الحالي للتسلسل والمصفوفة M عبر شبكة متصلة تمامًا ، السيني ومن ثم يتم تحديث المصفوفة M بنفس طريقة حالة الخلية في LSTM
يقال أنه بسبب MHDPA أن الشبكة يمكن أن تأخذ في الاعتبار ترابط عناصر التسلسل حتى عندما يتم إزالتها من بعضها البعض.
كمشكلة لعبة ، يُطلب من النموذج في تسلسل المتجهات العثور على المتجه Nth من خلال المسافة من Mth من حيث المسافة الإقليدية. على سبيل المثال ، يوجد تسلسل مكون من 10 متجهات ونطلب منك العثور على متجه في المرتبة الثالثة بالقرب من الخامس. من الواضح أنه من أجل الإجابة على سؤال النموذج ، من الضروري تقييم المسافات من جميع النواقل إلى الخامس وترتيبها بطريقة أو بأخرى. هنا ، فإن النموذج المقترح من قبل المؤلفين يهزم بثقة LSTM و
DNC . بالإضافة إلى ذلك ، يقارن المؤلفون نموذجهم مع بنيات أخرى حول "التعلم للتنفيذ" (نحصل على بضعة أسطر من التعليمات البرمجية لإدخالها ، وإعطاء النتيجة) ، و Mini-Pacman ، و Language Modeling ، وفي كل مكان يقدمون أفضل النتائج.
سلسلة زمنية متعددة المتغيرات بتر مع شبكات الخصومة التوليديةمجردةالكود (على الرغم من عدم ارتباطهم هنا في المقال)
في السلاسل الزمنية متعددة الأبعاد ، كقاعدة عامة ، هناك عدد كبير من الإغفالات ، مما يمنع استخدام الأساليب الإحصائية المتقدمة. الحلول القياسية - ملء مع متوسط / صفر ، وحذف الحالات غير المكتملة ، واستعادة البيانات على أساس التوسعات المصفوفة في هذه الحالة ، لا تعمل في كثير من الأحيان ، لأنها لا يمكن إعادة إنتاج التبعيات الزمنية والتوزيع المعقد للسلسلة الزمنية متعددة الأبعاد.
قدرة الشبكات العدائية التوليدية (GAN) على تقليد أي توزيع للبيانات ، ولا سيما في مهام "رسم" الوجوه وتوليد الجمل ، معروفة على نطاق واسع. ولكن كقاعدة عامة ، تتطلب هذه النماذج إما تدريبًا أوليًا على مجموعة بيانات كاملة دون وجود ثغرات ، أو لا تأخذ في الاعتبار الطبيعة المتسقة للبيانات.
يقترح المؤلفون استكمال GAN بعنصر جديد - الوحدة المتكررة لبوابات البتر (GRUI). الفرق الرئيسي عن GRU المعتاد هو أن GRUI يمكن أن تتعلم من البيانات على فترات زمنية مختلفة بين الملاحظات وتعديل تأثير الملاحظات اعتمادا على المسافة في الوقت المناسب من النقطة الحالية. تُحسب معلمة التوهين الخاصة، ، وتتراوح قيمتها من 0 إلى 1 والأصغر ، وكلما زاد الفارق الزمني بين الملاحظة الحالية والأخرى غير الفارغة.


يتكون كل من أداة التمييز ومولد GAN من طبقة GRUI وطبقة متصلة بالكامل. كالمعتاد في شبكات GAN ، يتعلم المولد محاكاة البيانات المصدر (في هذه الحالة ، ما عليك سوى ملء الفجوات الموجودة في الصفوف) ، ويتعلم المميّز تمييز الصفوف المملوءة بالمولد عن تلك الحقيقية.
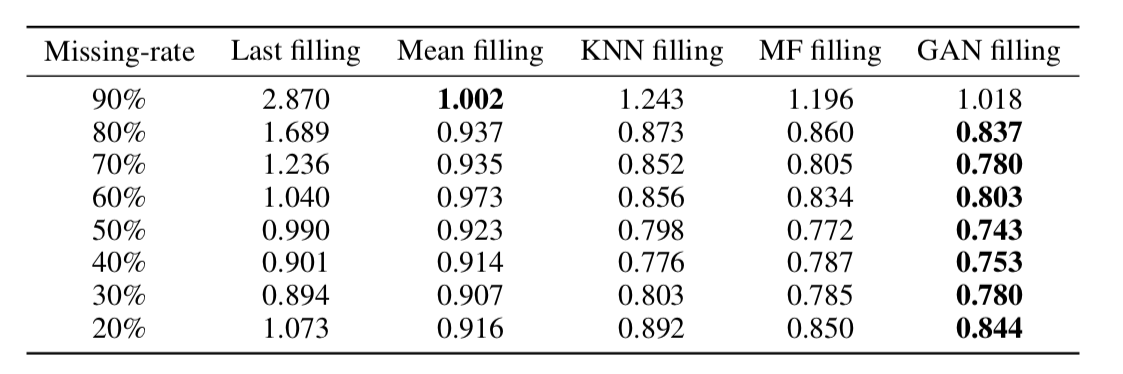
كما اتضح فيما بعد ، فإن هذا النهج يسترجع البيانات بشكل كافٍ حتى في السلاسل الزمنية مع وجود حصة كبيرة جدًا من الإغفالات (في الجدول أدناه - استعادة بيانات MSE في مجموعة بيانات KDD اعتمادًا على نسبة الإغفال وطريقة الاسترداد. في معظم الحالات ، تعطي الطريقة المستندة إلى GAN أكبر قدر من الدقة الانتعاش).
 على البعد من حفلات الزفاف كلمةمجردةكود
على البعد من حفلات الزفاف كلمةمجردةكوديمثل دمج الكلمات / ناقلات الكلمات طريقة تستخدم على نطاق واسع لتطبيقات البرمجة اللغوية العصبية المختلفة: من أنظمة التوصية إلى تحليل التلوين العاطفي للنصوص والترجمة الآلية.
علاوة على ذلك ، تظل مسألة كيفية تعيين مثل هذا البارامتر الفائق الهام مثل بُعد المتجهات مفتوحة. في الممارسة العملية ، غالبًا ما يتم تحديده عن طريق البحث الشامل التجريبي أو تعيينه افتراضيًا ، على سبيل المثال ، على مستوى 300. في الوقت نفسه ، لا يسمح البعد الصغير جدًا بعكس جميع العلاقات المهمة بين الكلمات ، وقد يؤدي التعيين الكبير جدًا إلى إعادة التدريب.
يقترح مؤلفو الدراسة حل هذه المشكلة عن طريق تقليل معامل فقد PIP ، وهو مقياس جديد للفرق بين خياري التضمين.
يعتمد الحساب على مصفوفات PIP التي تحتوي على المنتجات العددية لجميع أزواج تمثيلات المتجهات للكلمات في المجموعة. يتم احتساب خسارة PIP كمعيار Frobenius بين مصفوفات PIP لتزيينين: تدريب على البيانات (تضمين تضمين E_hat) ومثالية ، مدربة على بيانات صاخبة (oracle embedding E).
قد يبدو الأمر بسيطًا: تحتاج إلى اختيار بُعد يقلل من فقد PIP ، واللحظة الوحيدة غير المفهومة هي المكان الذي يمكنك فيه الحصول على التضمين أوراكل. في الفترة 2015-2017 ، تم نشر عدد من الأعمال التي تبين فيها أن الطرق المختلفة لبناء حفلات الزفاف (word2vec ، GloVe ، LSA) تحدد ضمنيًا (خفض البعد) مصفوفة إشارة الحالة. في حالة word2vec (skip-gram) ، تكون مصفوفة الإشارة هي
PMI ، في حالة GloVe هي مصفوفة تسجيل الدخول. يُقترح أخذ قاموس غير كبير الحجم ، وإنشاء مصفوفة إشارة واستخدام SVD للحصول على تضمين أوراكل. وبالتالي ، فإن بُعد تضمين أوراكل يساوي رتبة مصفوفة الإشارة (في الممارسة العملية ، بالنسبة لقاموس يتكون من 10 آلاف كلمة ، سيكون البعد بترتيب 2 كيلو). ومع ذلك ، لدينا مصفوفة إشارة تجريبية دائما صاخبة وعلينا اللجوء إلى مخططات صعبة للحصول على تضمين أوراكل وتقدير الخسارة PIP بواسطة مصفوفة صاخبة.
يجادل المؤلفون بأنه لتحديد بُعد التضمين الأمثل ، يكفي استخدام قاموس يتكون من 10 آلاف كلمة ، وهذا ليس كثيرًا جدًا ويسمح لك بتشغيل هذا الإجراء في فترة زمنية معقولة.
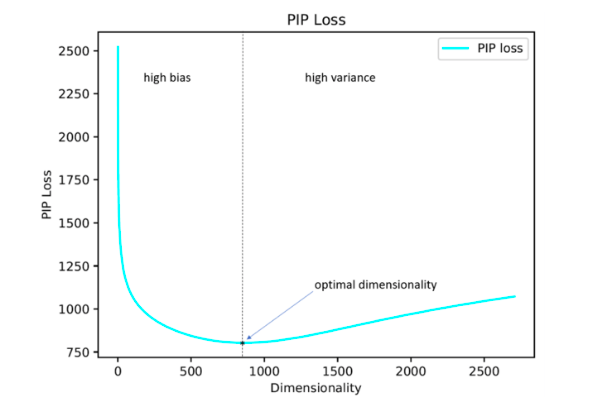
كما اتضح فيما بعد ، فإن بُعد التضمين المحسوب بهذه الطريقة في معظم الحالات مع وجود خطأ يصل إلى 5٪ يتزامن مع البعد الأمثل المحدد على أساس تقديرات الخبراء. اتضح (من المتوقع) أن Word2Vec و GloVe لم يعاد تدريبهما عمليًا (لا ينخفض فقدان PIP بأبعاد كبيرة جدًا) ، ولكن يتم إعادة تدريب LSA بقوة.
باستخدام الكود الذي نشره المؤلفون على جيثب ، يمكن للمرء البحث عن البعد الأمثل لـ Word2Vec (skip-gram) ، GloVe ، LSA.
FRAGE: تردد كلمة لاأدريمجردةكوديتحدث المؤلفون عن كيفية عمل حفلات الزفاف بطريقة مختلفة عن الكلمات النادرة والشائعة. بشكل عام ، أعني عدم إيقاف الكلمات (لا نعتبرها على الإطلاق) ، ولكن الكلمات المفيدة ليست نادرة جدًا.
الملاحظات هي كما يلي:
إذا كنا نتحدث عن الكلمات الشائعة ، فإن قربها من جيب التمام يعكس جيدًا
- تقاربهم الدلالي. بالنسبة للكلمات النادرة ، فإن الأمر ليس كذلك (ما هو متوقع) ، و (ما هو أقل توقعًا) من أعلى أقرب كلمات جيب التمام لكلمة نادرة هي أيضًا نادرة وفي نفس الوقت لا علاقة لها بدلالة. هذا هو ، كلمات نادرة ومتكررة في مساحة حفلات الزفاف تعيش في أماكن مختلفة (في مخاريط مختلفة ، إذا كنا نتحدث عن جيب التمام)
- أثناء التدريب ، يتم تحديث متجهات الكلمات الشائعة في كثير من الأحيان ، وفي المتوسط ، تكون المسافة بعيدة عن التهيئة بقدر ضعف متجهات الكلمات النادرة. هذا يؤدي إلى حقيقة أن تضمين الكلمات النادرة في المتوسط أقرب إلى الأصل. لكي أكون أمينًا ، كنت أؤمن دائمًا ، على العكس من ذلك ، بالكلمات النادرة التي تكون فيها حفلات الزينة في المتوسط أطول ولا أعرف كيف تتصل ببيان المؤلفين =)
مهما كانت العلاقة بين قواعد L2 من حفلات الزفاف ، فإن فصل الكلمات الشائعة والنادرة ليس ظاهرة جيدة جدًا. نريد أن تعكس حفلات الزفاف دلالات الكلمة ، وليس ترددها.
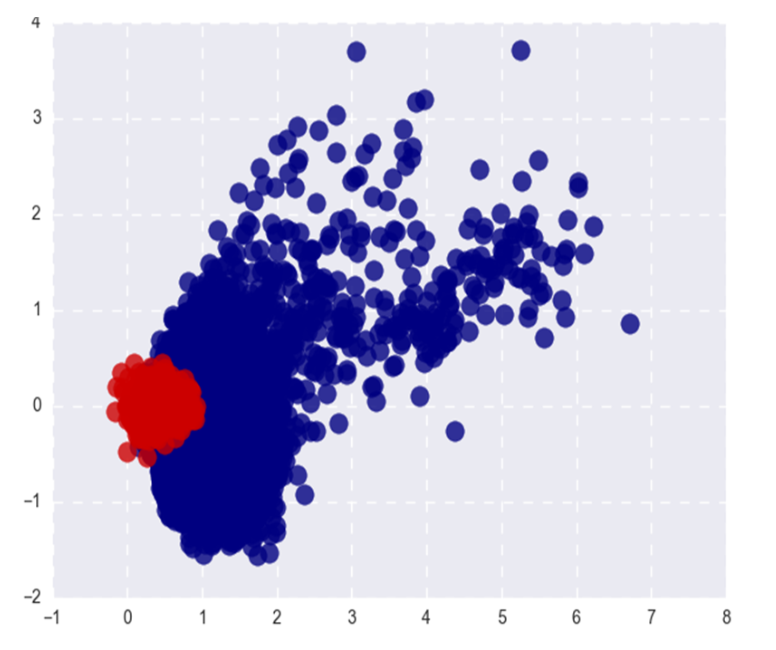
تُظهر الصورة Word2Vec الشائعة (الحمراء) والكلمات النادرة (الزرقاء) بعد SVD. شعبية هنا تشير إلى أعلى 20 ٪ من الكلمات في التردد.
إذا كانت المشكلة فقط في قواعد L2 من حفلات الزفاف ، يمكننا تطبيعها والعيش بسعادة ، ولكن ، كما قلت في الفقرة الأولى ، يتم فصل الكلمات النادرة أيضًا عن تلك الشائعة عن طريق التقارب التمامي (في الإحداثيات القطبية).
يقترح المؤلفون ، بالطبع ، GAN. دعونا نفعل الشيء نفسه كما كان من قبل ، ولكن أضف أداة تمييز ستحاول التمييز بين الكلمات الشائعة والكلمات النادرة (مرة أخرى ، نعتبر أن أعلى٪ n من الكلمات في التكرار تكون شائعة).
يبدو شيء مثل هذا:
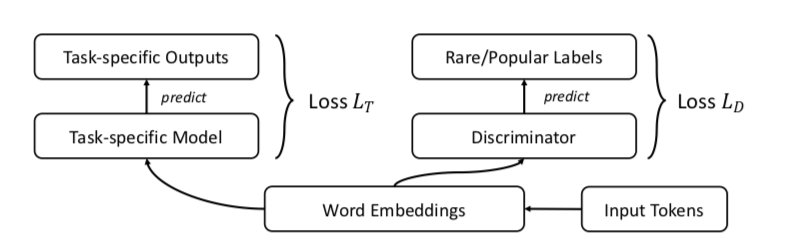
يختبر المؤلفون النهج الخاص بمهام تشابه الكلمات والترجمة الآلية وتصنيف النص ونمذجة اللغة وفي كل مكان يؤدون أداءً أفضل من الخط الأساسي. في تشابه الكلمات ، ذكر أن الجودة تنمو بشكل خاص على الكلمات النادرة.
مثال واحد: الجنسية. تخطي غرام القضايا: النعيم ، الباكستانيين ، ورفض ، ويعزز. قضايا FRAGE: السكان ، städtischen ، والكرامة ، برجر. توجد عبارة "المواطن والمواطنون في FRAGE" في المرتبة 79 و 7 ، على التوالي (على مقربة من الجنسية) ، في تخطي غرام ليسوا في قائمة أفضل 10000.
لسبب ما ، نشر المؤلفون الشفرة فقط للترجمة الآلية ونمذجة اللغة ومهام تشابه الكلمات وتصنيف النص في المستودع ، لسوء الحظ ، لا يتم تمثيلها.
غير مشروط محاذاة عبر الوسائط محاذاة الكلام و نص تضمين المسافاتمجردةالرمز: لا يوجد كود ، لكنني أود
أظهرت الدراسات الحديثة أن مساحتين متجهتين تم تدريبهما باستخدام خوارزميات التضمين (على سبيل المثال ، word2vec) على نصوص بلغتين مختلفتين يمكن أن تتطابق مع بعضها البعض دون ترميز ومطابقة المحتوى بين المبنيين. على وجه الخصوص ، يتم استخدام هذا النهج للترجمة الآلية على Facebook. يتم استخدام إحدى الخصائص الرئيسية لمسافات التضمين: في داخلها ، يجب أن تكون الكلمات المتشابهة قريبة من الناحية الهندسية ، وعلى العكس من ذلك ، يجب أن تكون متباينة عن بعضها البعض. من المفترض ، بشكل عام ، أن يتم الحفاظ على بنية فضاء المتجه بغض النظر عن اللغة التي كان المراد بها التدريس.
ذهب مؤلفو المقال إلى أبعد من ذلك وطبقوا نهجًا مشابهًا في مجال التعرف التلقائي على الكلام والترجمة. يُقترح تدريب مساحة المتجه بشكل منفصل عن مجموعة النص باللغة التي تهمها (على سبيل المثال ، ويكيبيديا) ، بشكل منفصل عن مجموعة الكلام المسجل (بتنسيق صوتي) ، ربما بلغة أخرى ، تم تقسيمها مسبقًا إلى كلمات ، ثم مقارنة هذين الفضاءين بنفس الطريقة كما هو الحال مع اثنين حالات النص.
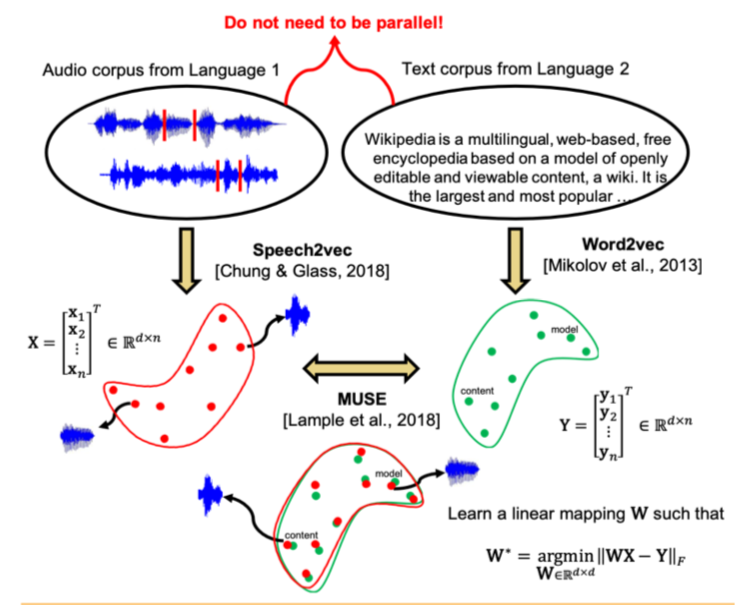
بالنسبة إلى مجموعة النص ، يتم استخدام word2vec ، وبالنسبة للكلام ، فإن الأسلوب المماثل ، الذي يدعى Speech2vec ، يعتمد على LSTM والمنهجيات المستخدمة في word2vec (CBOW / skip-gram) ، لذلك من المفترض أنه يجمع بين الكلمات بدقة حسب الخصائص السياقية والدلالية ، لا السبر.
بعد تدريب كلتا الحاملتين المتجهتين وهناك مجموعتان من الزخارف - S (على نص الكلام) ، تتكون من n embeds من البعد d1 و T (على نص النص) ، تتكون من m embeds من البعد d2 ، تحتاج إلى مقارنتها. من الناحية المثالية ، لدينا قاموس يحدد المتجه من S يتوافق مع المتجه من T. ثم يتم تشكيل مصففتين للمقارنة: يتم اختيار k embeddings من S ، والتي تشكل مصفوفة X من الحجم d1 xk ؛ من T ، يتم أيضًا اختيار حفلات الزينة المطابقة (وفقًا للقاموس) المحددة مسبقًا من S ، ويتم الحصول على مصفوفة Y بالحجم d2 x k. بعد ذلك ، تحتاج إلى العثور على تعيين خطي W بحيث:
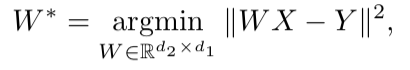
ولكن نظرًا لأن المقالة تتناول النهج غير الخاضع للإشراف ، في البداية لا يوجد قاموس ، لذلك ، يُقترح إجراء لإنشاء قاموس اصطناعي يتكون من جزأين. أولاً ، نحصل على أول تقدير تقريبي لـ W باستخدام تدريب خصوم المجال (نموذج تنافسي مثل GAN ، ولكن بدلاً من المولد - خريطة خطية لـ W ، نحاول أن نجعل من خلالها S و T غير قابلين للتمييز ، ويحاول المميّز تحديد الأصل الحقيقي للتضمين). ثم ، بناءً على الكلمات التي أظهرت زخارفها أفضل تطابق لبعضها البعض وغالبًا ما توجد في كلا المبنيين ، يتم إنشاء قاموس. بعد ذلك ، يحدث تنقيح W وفقًا للصيغة أعلاه.
يعطي هذا النهج نتائج مماثلة للتعلم على البيانات التي تحمل علامات ، والتي يمكن أن تكون مفيدة للغاية في مهمة التعرف على الكلام وترجمته من اللغات النادرة التي يوجد بها عدد قليل جدًا من حالات نص الكلام المتوازية ، أو أنها غائبة.
اكتشاف الشذوذ العميق باستخدام التحولات الهندسيةمجردةكودنهج غير عادي إلى حد ما في الكشف عن الشذوذ ، والذي ، وفقا للمؤلفين ، يهزم بشكل كبير المناهج الأخرى.
الفكرة هي: دعونا نتوصل إلى تحولات هندسية مختلفة K (مزيج من التحولات ، 90 درجة دوران وانعكاس) وتطبيقها على كل صورة من مجموعة البيانات الأصلية. الصورة التي تم الحصول عليها نتيجة للتحول رقم i ستنتمي الآن إلى الفئة i ، أي أنه ستكون هناك فئات K في المجموع ، وسيتم تمثيل كل منها بعدد الصور التي كانت في الأصل في مجموعة البيانات. الآن سنقوم بتدريس تصنيف متعدد الطبقات على هذه العلامات (اختار المؤلفون إعادة resnet واسعة).
الآن يمكننا الحصول على متجهات K y (Ti (x)) من البعد K لصورة جديدة ، حيث يمثل Ti التحول رقم i ، و x هو الصورة ، و y هو خرج الطراز. التعريف الأساسي لـ "الحالة الطبيعية" هو كما يلي:
هنا ، بالنسبة للصورة x ، أضفنا الاحتمالات المتوقعة للفئات الصحيحة لجميع التحويلات. كلما زادت "الحالة الطبيعية" ، زاد احتمال أخذ الصورة من نفس التوزيع مثل عينة التدريب. يدعي المؤلفون أن هذا يعمل بالفعل بشكل رائع للغاية ، ولكن مع ذلك يقدم طريقة أكثر تعقيدًا تعمل بشكل أفضل قليلاً. سنفترض أن المتجه y (Ti (x)) لكل تحويل Ti يتم توزيعه
Dirichlet وسنتخذ لوغاريتم الاحتمال كمقياس لـ "الحالة الطبيعية" للصورة. وتقدر المعلمات توزيع Dirichlet على مجموعة التدريب.
تقرير المؤلفين عن تعزيز الأداء لا يصدق مقارنة مع النهج الأخرى.
إطار عمل موحد بسيط لاكتشاف العينات خارج التوزيع والهجمات العدائيةمجردةكوديعد التحديد في العينة لتطبيق نموذج الحالات المختلفة اختلافًا كبيرًا عن توزيع عينة التدريب أحد المتطلبات الرئيسية للحصول على نتائج تصنيف موثوقة. في الوقت نفسه ، تُعرف الشبكات العصبية بميزتها بدرجة عالية من الثقة (وغير صحيحة) لتصنيف الكائنات التي لم تصادف في التدريب ، أو تالفة عن قصد (أمثلة عدوانية).
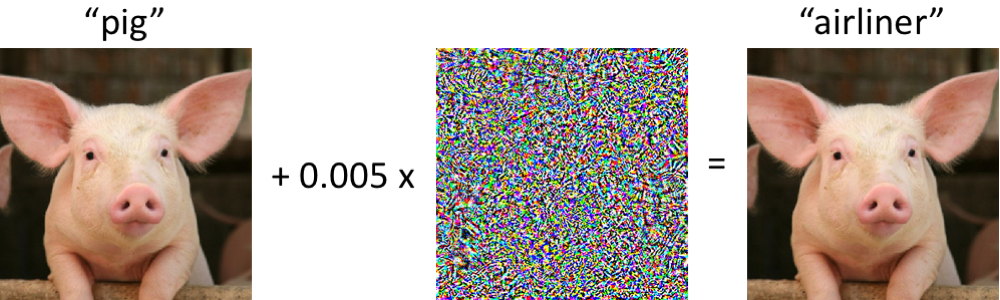
يقدم مؤلفو المقالة طريقة جديدة لتحديد كل من هذه الحالات "السيئة". يتم تنفيذ النهج على النحو التالي: أولاً ، يتم تدريب شبكة عصبية مع ناتج softmax المعتاد ، ثم يتم أخذ إخراج الطبقة قبل الأخيرة ، ويتم تدريب المصنف التوليدي عليها. دع هناك x - يتم تغذيتها لإدخال النموذج لكائن تصنيف معين ، y - تسمية الفصل المقابلة ، ثم افترض أن لدينا مصنف softmax مدرّب مسبقًا للنموذج:
حيث wc و bc هما الأوزان والثابتة لطبقة softmax للفئة c ، و f (.) هو ناتج DNN لفول الصويا قبل الأخير.
علاوة على ذلك ، دون أي تغييرات على المصنف المُدرَّب مسبقًا ، يتم الانتقال إلى المصنف التوليدي ، أي التحليل التمييزي. من المفترض أن الميزات المأخوذة من الطبقة قبل الأخيرة من مصنف softmax لها توزيع طبيعي متعدد الأبعاد ، كل مكون منها يتوافق مع فئة واحدة. بعد ذلك ، يمكن تحديد التوزيع الشرطي من خلال ناقل وسائل التوزيع متعدد الأبعاد ومصفوفة التباين:
لتقييم معلمات المصنف التوليفي ، يتم حساب المتوسطات التجريبية لكل فصل ، وكذلك التباين في الحالات من عينة التدريب {(x1 ، y1) ، ... ، (xN ، yN)}:
حيث N هو عدد حالات الفصل المقابل في مجموعة التدريب. بعد ذلك ، يتم حساب قدر من الموثوقية على عينة الاختبار - المسافة Mahalanobis بين حالة الاختبار وتوزيع الطبقة العادية الأقرب إلى هذه الحالة.
كما اتضح ، فإن مثل هذا المقياس يعمل بشكل أكثر موثوقية على الكائنات غير التقليدية أو التالفة ، دون إعطاء تقديرات عالية ، مثل طبقة softmax. في معظم المقارنات على البيانات المختلفة ، أظهرت الطريقة المقترحة نتائج تجاوزت أحدث ما توصلت إليه في العثور على كلتا الحالتين التي لم تكن في التدريب ، وأفسدت عن عمد.
علاوة على ذلك ، ينظر المؤلفون في تطبيق آخر مثير للاهتمام لمنهجيتهم: استخدم المصنف التوليفي لتسليط الضوء على فصول جديدة في الاختبار الذي لم يكن في التدريب ، ثم تحديث معلمات المصنف نفسه حتى يتمكن من تحديد هذه الفئة الجديدة في المستقبل.
أمثلة عدائية تخدع كل من رؤية الكمبيوتر والبشر المحدود الوقتالخلاصة:
https://arxiv.org/abs/1802.08195يدرس المؤلفون ما هي الخصومة من حيث الإدراك البشري. اليوم ، ليس من المستغرب لأي شخص أنه لا يمكنك تقريبًا تغيير الصورة لجعل الشبكة تخطئ فيها. ومع ذلك ، فإنه ليس من الواضح تمامًا كم تختلف الصورة الأصلية عن مثال الخصم لشخص ما وما إذا كانت تختلف على الإطلاق. من الواضح أن أياً من الناس لن يطلق على الصورة الموجودة على اليمين نعامة ، ولكن ربما ، لا تكون الصورة الموجودة على اليمين بالنسبة لشخص ما متطابقة تمامًا مع الصورة الموجودة على اليسار ، وإذا كان الأمر كذلك ، يمكن أن يتعرض الشخص أيضًا لهجمات خصومة. يحاول المؤلفون تقييم مدى قدرة الشخص على تصنيف أمثلة الخصومة. للحصول على أمثلة عدائية ، يتم استخدام تقنية لا تملك الوصول إلى بنية شبكة المصدر (منطق المؤلفين هو أنه لن يتم منحهم الوصول إلى بنية الدماغ البشري على أي حال).لذلك ، يُظهر الشخص مثالًا عدائيًا ، كما في الصورة أعلاه ، ويُطلب منه تصنيفه. من الواضح أنه في ظل الظروف العادية ستكون النتيجة قابلة للتنبؤ ، ولكن هنا تظهر صورة واحدة لشخص في غضون 63 مللي ثانية ، وبعد ذلك يجب عليه اختيار واحد من فصلين. في ظل هذه الظروف ، كانت الدقة في الصور المصدر أعلى بنسبة 10 ٪ مما كانت عليه في الخصومة. من حيث المبدأ ، يمكن تفسير ذلك من خلال حقيقة أن الصورة العدائية هي ببساطة صاخبة وبالتالي ، في ظروف ضغط الوقت ، يصنفها الناس بشكل غير صحيح ، ولكن هذا يدحض التجربة التالية. إذا قبل إضافة الاضطراب إلى الصورة ، فإننا نعكس هذا الاضطراب عموديًا ، فلن تتغير الدقة بصعوبة مقارنة بالصورة الأصلية.
يحاول المؤلفون تقييم مدى قدرة الشخص على تصنيف أمثلة الخصومة. للحصول على أمثلة عدائية ، يتم استخدام تقنية لا تملك الوصول إلى بنية شبكة المصدر (منطق المؤلفين هو أنه لن يتم منحهم الوصول إلى بنية الدماغ البشري على أي حال).لذلك ، يُظهر الشخص مثالًا عدائيًا ، كما في الصورة أعلاه ، ويُطلب منه تصنيفه. من الواضح أنه في ظل الظروف العادية ستكون النتيجة قابلة للتنبؤ ، ولكن هنا تظهر صورة واحدة لشخص في غضون 63 مللي ثانية ، وبعد ذلك يجب عليه اختيار واحد من فصلين. في ظل هذه الظروف ، كانت الدقة في الصور المصدر أعلى بنسبة 10 ٪ مما كانت عليه في الخصومة. من حيث المبدأ ، يمكن تفسير ذلك من خلال حقيقة أن الصورة العدائية هي ببساطة صاخبة وبالتالي ، في ظروف ضغط الوقت ، يصنفها الناس بشكل غير صحيح ، ولكن هذا يدحض التجربة التالية. إذا قبل إضافة الاضطراب إلى الصورة ، فإننا نعكس هذا الاضطراب عموديًا ، فلن تتغير الدقة بصعوبة مقارنة بالصورة الأصلية.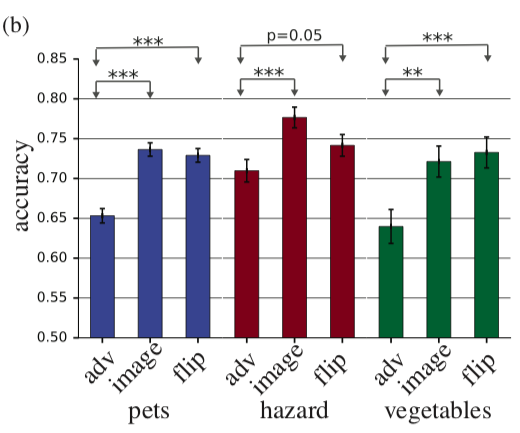 في الرسم البياني ، يعد adv مثالًا للخصم ، والصورة هي الصورة الأصلية ، والوجه هو الصورة الأصلية + اضطراب الخصومة ، وينعكس عموديًا.التدقيقات المعقولة لخرائط الملحة يعد تفسير نموذجالملخصأحد أكثر المواضيع التي تمت مناقشتها اليوم. عندما يتعلق الأمر بالتعلم العميق ، عادة ما يتحدثون عن خرائط الملاءمة. تحاول خرائط الملاءمة الإجابة على سؤال حول كيفية تغير القيمة في أحد مخرجات الشبكة عندما تتغير قيم الإدخال. قد يبدو هذا كخريطة ملحة ، والتي توضح البيكسلات التي أثرت في حقيقة أن الصورة تم تصنيفها على أنها "كلب".
في الرسم البياني ، يعد adv مثالًا للخصم ، والصورة هي الصورة الأصلية ، والوجه هو الصورة الأصلية + اضطراب الخصومة ، وينعكس عموديًا.التدقيقات المعقولة لخرائط الملحة يعد تفسير نموذجالملخصأحد أكثر المواضيع التي تمت مناقشتها اليوم. عندما يتعلق الأمر بالتعلم العميق ، عادة ما يتحدثون عن خرائط الملاءمة. تحاول خرائط الملاءمة الإجابة على سؤال حول كيفية تغير القيمة في أحد مخرجات الشبكة عندما تتغير قيم الإدخال. قد يبدو هذا كخريطة ملحة ، والتي توضح البيكسلات التي أثرت في حقيقة أن الصورة تم تصنيفها على أنها "كلب". يطرح المؤلفون سؤالًا معقولًا جدًا: "كيف يمكننا التحقق من صحة طرق إنشاء خرائط الملوحة؟" تم طرح نقطتين واضحتين يتم اقتراحهما للتحقق:
يطرح المؤلفون سؤالًا معقولًا جدًا: "كيف يمكننا التحقق من صحة طرق إنشاء خرائط الملوحة؟" تم طرح نقطتين واضحتين يتم اقتراحهما للتحقق:- يجب أن تعتمد خريطة الملوحة على أوزان الشبكة
- Saliency map ,
سنقوم بفحص الأطروحة الأولى عن طريق استبدال الأوزان في الشبكة المدربة بعشوائية: العشوائية المتتالية (العشوائية طبقات من الماضي ونرى كيف تتغير خريطة الملاءمة) والعشوائية المستقلة (العشوائية طبقة معينة). سوف نتحقق من الأطروحة الثانية على هذا النحو: مزج جميع الملصقات بشكل عشوائي في القطار ، وقم بتجهيز القطار وإلقاء نظرة على خرائط الملاءمة.إذا كانت طريقة إنشاء خريطة الملاءمة جيدة حقًا وتتيح لك فهم كيفية عمل النموذج ، فيجب أن تؤدي هذه العشوائيات إلى تغيير خرائط الملوحة إلى حد كبير. ومع ذلك: "لدهشتنا ، بعض أساليب الملاءمة المنشورة على نطاق واسع مستقلة عن كل من البيانات التي تم تدريب النموذج عليها ، والمعلمات النموذجية" ، يقول المؤلفون. هنا ، على سبيل المثال ، يشبه خرائط الملاءمة التي تم الحصول عليها باستخدام خوارزميات متنوعة بعد التوزيع العشوائي المتتالي: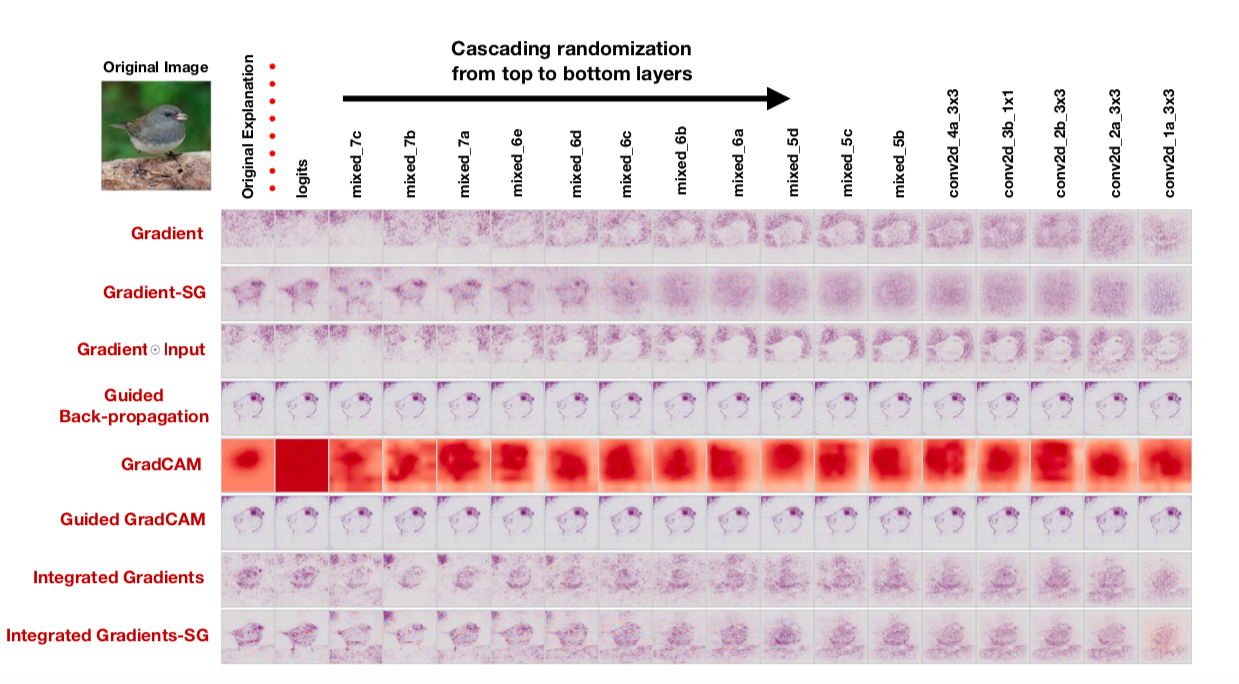 لاحظ حقيقة أن العمود الأخير يتوافق مع شبكة ذات أوزان عشوائية في جميع الطبقات. أي أن الشبكة تتنبأ عشوائيًا ، لكن بعض خرائط الملوحة لا تزال ترسم طيرًا.يقول المؤلفون بحق - إن تقييم خرائط الأهمية من خلال قابليتها للفهم ومنطقها وعدم كفاية الانتباه إلى مدى ارتباط النتيجة عمومًا بكيفية عمل النموذج يؤدي إلى تحيز التأكيد. على ما يبدو ، بما في ذلك لهذا السبب ، اتضح أن الأساليب الشائعة لتفسير النماذج لا تفسرها على الإطلاق.فشل مثير للاهتمام في الشبكات العصبية التلافيفية وحل CoordConvالملخص: https://arxiv.org/abs/1807.03247الكود: يوجد بالفعل العديد من التطبيقات وبصفة عامة الفكرة جميلة وبسيطة بحيث تتم كتابتها حرفيًا في 10 سطور.سهلة التنفيذ وفكرة واعدة من اوبر. تم تشديد الشبكات التلافيفية في الأصل من أجل ثبات القص ، وبالتالي فإن المهام المرتبطة بتحديد إحداثيات كائن صعبة للغاية بالنسبة لهذه الشبكات. لا تستطيع الشبكات التلافيفية التقليدية حتى حل مشكلات الألعاب مثل تحديد إحداثيات نقطة ما في صورة ما أو رسم نقطة بالإحداثيات:
لاحظ حقيقة أن العمود الأخير يتوافق مع شبكة ذات أوزان عشوائية في جميع الطبقات. أي أن الشبكة تتنبأ عشوائيًا ، لكن بعض خرائط الملوحة لا تزال ترسم طيرًا.يقول المؤلفون بحق - إن تقييم خرائط الأهمية من خلال قابليتها للفهم ومنطقها وعدم كفاية الانتباه إلى مدى ارتباط النتيجة عمومًا بكيفية عمل النموذج يؤدي إلى تحيز التأكيد. على ما يبدو ، بما في ذلك لهذا السبب ، اتضح أن الأساليب الشائعة لتفسير النماذج لا تفسرها على الإطلاق.فشل مثير للاهتمام في الشبكات العصبية التلافيفية وحل CoordConvالملخص: https://arxiv.org/abs/1807.03247الكود: يوجد بالفعل العديد من التطبيقات وبصفة عامة الفكرة جميلة وبسيطة بحيث تتم كتابتها حرفيًا في 10 سطور.سهلة التنفيذ وفكرة واعدة من اوبر. تم تشديد الشبكات التلافيفية في الأصل من أجل ثبات القص ، وبالتالي فإن المهام المرتبطة بتحديد إحداثيات كائن صعبة للغاية بالنسبة لهذه الشبكات. لا تستطيع الشبكات التلافيفية التقليدية حتى حل مشكلات الألعاب مثل تحديد إحداثيات نقطة ما في صورة ما أو رسم نقطة بالإحداثيات: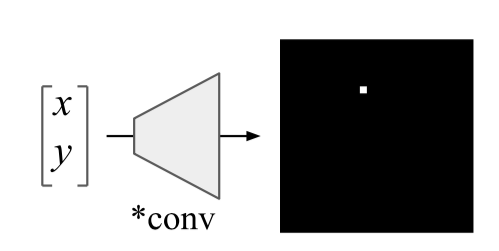 يُقترح الاختراق الأنيق: إضافة مصففتين i و j إلى الصورة (بشكل عام ، إلى إدخال طبقة CoodrConv) ، حيث يحتوي على الإحداثيات الرأسية والأفقية للبكسلات المقابلة:
يُقترح الاختراق الأنيق: إضافة مصففتين i و j إلى الصورة (بشكل عام ، إلى إدخال طبقة CoodrConv) ، حيث يحتوي على الإحداثيات الرأسية والأفقية للبكسلات المقابلة: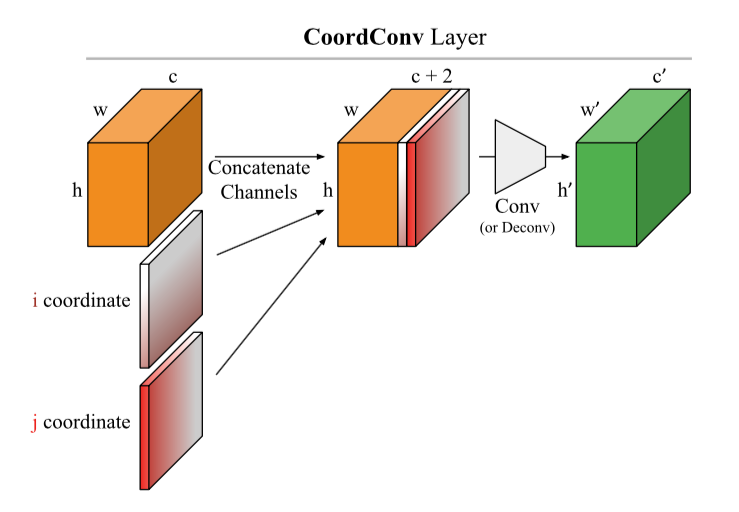 يُزعم أن:
يُزعم أن:- ImageNet'. , , , ,
- CoordConv object detection. MNIST, Faster R-CNN, IoU 21%
- CoordConv GAN .
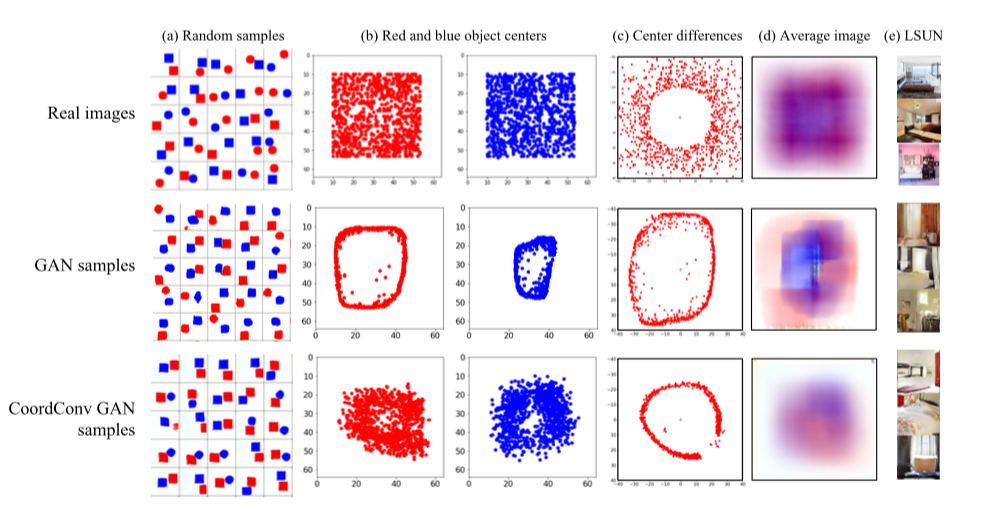
GAN' : LSUN. , — c. , GAN' , , . CoordConv , . LSUN d , , CoordConv GAN,
- 4. باستخدام CoordConv في A2C يعطي زيادة في بعض (وليس كل) الألعاب.
أنا شخصياً مهتم للغاية بهذه النقطة الثانية ، وأود أن أرى النتائج في مجموعات البيانات الحقيقية ، لكن لا يوجد شيء على الفور. وفي الوقت نفسه ، تعمل CoordConv بالفعل على الاندماج بنشاط كبير في شبكة U : https://arxiv.org/abs/1812.01429 ، https://www.kaggle.com/c/tgs-salt-identification-challenge/discussion/69274 ، https: //github.com/mjDelta/Kaggle-RSNA- الالتهاب الرئوي- كشف- تحدي .هناك فيديو جيد وأكثر تفصيلا من المؤلف .بواسطة تباين النظامي من التنشيط 'على عينة الفروقخلاصةالمدونةيقدم المؤلفون بديلاً ممتعًا لتطبيع الدُفعات. سنقوم بتقسيم الشبكة لتباين تشتت التنشيطات على بعض الطبقات. في الممارسة العملية ، يقومون بتنفيذها بهذه الطريقة: خذ مجموعتين فرعيتين منفصلتين S1 و S2 من الدفعة وحساب شيء من هذا القبيل:حيث σ2 هي عينات متباينة في S1 و S2 ، على التوالي ، β هو المعامل الإيجابي المدرب. يطلق المؤلفون على هذا الشيء تباين فقدان الخسارة (VCL) وإضافته إلى الخسارة الكلية.
في القسم الخاص بالتجارب ، يشتكي المؤلفون من كيفية عدم تكرار نتائج مقالات الأشخاص الآخرين ويلتزمون بوضع رمز قابل للتكرار (تم وضعه). أولاً ، جربوا شبكة صغيرة من 11 طبقة على مجموعة من الصور الصغيرة (CIFAR-10 و CIFAR-100). لقد أثبتنا أن VCL يثبت ، إذا كنت تستخدم Leaky ReLU أو ELU كتنشيطات ، لكن تطبيع الدُفعات يعمل بشكل أفضل مع ReLU. ثم يقومون بزيادة عدد الطبقات مرتين ويتحولون إلى Tiny Imagenet - نسخة مبسطة من Imagenet مع 200 فئة ودقة 64x64. في التحقق من الصحة ، يتفوق VCL على تسوية الدُفعات على الشبكة باستخدام ELU ، وكذلك ResNet-110 و DenseNet-40 ، ولكن يتفوق على Wide-ResNet-32. النقطة المهمة هي أنه يتم الحصول على أفضل النتائج عندما تتكون المجموعتان الفرعيتان S1 و S2 من عينتين.
بالإضافة إلى ذلك ، يختبر المؤلفون VCL في شبكات التغذية الأمامية ويفوز VCL إلى حد ما في كثير من الأحيان أكثر من شبكة بتطبيع الدُفعات أو بدون تنظيم.
DropMax: التكيف التبايني Softmaxمجردةكوديُقترح في مشكلة التصنيف متعدد الطبقات عند كل تكرار نزول التدرج لكل عينة لإسقاط عدد من الفئات غير الصحيحة عشوائيًا. علاوة على ذلك ، يتم أيضًا تدريب احتمال إسقاط فصل أو فصل لواحد أو آخر. نتيجة لذلك ، اتضح أن الشبكة "تركز" على التمييز بين أصعب الفصول.
تُظهر التجارب على مجموعات فرعية MNIST و CIFAR و Imagenet أن DropMax يعمل بشكل أفضل من كل من SoftMax القياسي وبعض التعديلات الخاصة به.
نماذج دقيقة دقيقة مع التفاعلات الزوجية(لا يسمح الأصدقاء للأصدقاء بنشر نماذج الصندوق الأسود: أهمية الذكاء في التعلم الآلي)
الخلاصة:
http://www.cs.cornell.edu/~yinlou/papers/lou-kdd13.pdfالرمز: ليس هناك. أنا مهتم جدًا بكيفية قيام المؤلفين بتطبيق هذا الاسم الضروري قليلاً مع عدم وجود كود. الأكاديميون ، سيدي =)
يمكنك الاطلاع على هذه الحزمة ، على سبيل المثال:
https://github.com/dswah/pyGAM . تمت إضافة تفاعلات الميزات إليها منذ وقت ليس ببعيد (مما يميز فعليًا GAM عن GA2M).
تم تقديم هذه المقالة في إطار ورشة العمل "التفسير والقوة في الصوت والكلام واللغة" ، على الرغم من أنها مكرسة لتفسير النماذج بشكل عام ، وليس في مجال تحليل الصوت والكلام.ربما ، واجه الجميع إلى حد ما معضلة الاختيار بين التفسير النموذجي و دقتها. إذا استخدمنا الانحدار الخطي المعتاد ، فيمكننا أن نفهم من خلال المعاملات كيف يؤثر كل متغير مستقل على التابع. إذا استخدمنا نماذج الصندوق الأسود ، على سبيل المثال ، زيادة التدرج اللوني دون قيود على التعقيد أو الشبكات العصبية العميقة ، فسيكون النموذج الذي تم ضبطه بشكل صحيح على البيانات المناسبة دقيقًا للغاية ، لكن تتبع وشرح جميع الأنماط التي وجدها النموذج في البيانات سيكون مشكلة. وفقًا لذلك ، سيكون من الصعب شرح النموذج للعميل وتتبع ما إذا كانت قد تعلمت شيئًا لا نرغب فيه. يقدم الجدول أدناه تقديرات للتفسير النسبي والدقة لأنواع مختلفة من النماذج.

مثال على الموقف الذي يرتبط فيه ضعف تفسير النموذج بمخاطر كبيرة: في واحدة من مجموعات البيانات الطبية ، تم حل مشكلة التنبؤ باحتمال وفاة المريض بالتهاب رئوي. تم العثور على النمط المثير للاهتمام التالي في البيانات: إذا كان الشخص مصابًا بالربو القصبي ، فإن احتمال الوفاة بسبب الالتهاب الرئوي يكون أقل منه في الأشخاص الذين لا يعانون من هذا المرض. عندما تحول الباحثون إلى أطباء ممارسين ، اتضح أن هذا النمط موجود بالفعل ، لأن المصابين بالربو في حالة الالتهاب الرئوي يتلقون المساعدة العاجلة والأدوية القوية. إذا قمنا بتدريب xgboost على مجموعة البيانات هذه ، فمن المحتمل أن يكون قد اكتشف هذا النمط ، وسيقوم نموذجنا بتصنيف المرضى الذين يعانون من الربو على أنهم فئة منخفضة المخاطر ، وبناءً على ذلك ، فإنهم سيوصون بأولوية أقل وكثافة علاجية لهم.
يقدم مؤلفو المقالة بديلاً يمكن تفسيره ودقته في نفس الوقت - وهذا هو GA2M ، وهو نوع فرعي من النماذج المضافة المعممة.
يمكن اعتبار GAM الكلاسيكية بمثابة تعميم إضافي لـ GLM: النموذج عبارة عن مبلغ ، كل مصطلح يعكس تأثير متغير مستقل واحد فقط على المعتمد ، ولكن لا يتم التعبير عن التأثير بمعامل وزن واحد ، كما هو الحال في GLM ، ولكن من خلال دالة nonparametric متجانسة (كقاعدة ، يتم تعريفها بشكل تدريجي وظائف - شرائح أو أشجار ذات عمق صغير ، بما في ذلك "جذوعها"). بسبب هذه الميزة ، يمكن لنماذج GAM تشكيل علاقات أكثر تعقيدًا من نموذج خطي بسيط. من ناحية أخرى ، يمكن تصور التبعيات المستفادة (الوظائف) وتفسيرها.
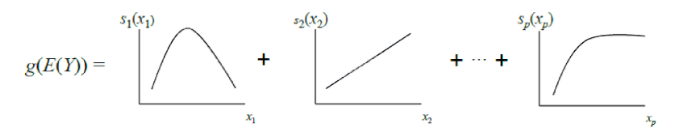
ومع ذلك ، لا تزال GAMs القياسية في كثير من الأحيان لا تصل إلى دقة خوارزميات الصندوق الأسود. لإصلاح ذلك ، يقدم مؤلفو المقالة حلاً وسطًا - لإضافة إلى معادلة النموذج ، بالإضافة إلى وظائف متغير واحد ، عدد صغير من وظائف متغيرين - أزواج مختارة بعناية يكون تفاعلها مهمًا للتنبؤ بالمتغير التابع. وبالتالي ، يتم الحصول على GA2M.
أولاً ، تم إنشاء GAM القياسي (دون مراعاة تفاعل المتغيرات) ، ثم تتم إضافة أزواج من المتغيرات خطوة بخطوة (يتم استخدام GAM المتبقي كمتغير مستهدف). في حالة وجود الكثير من المتغيرات وتحديث النموذج بعد كل خطوة صعبة من الناحية الحسابية ، يُقترح خوارزمية ترتيب FAST ، والتي يمكنك من خلالها تحديد أزواج يحتمل أن تكون مفيدة وتجنب التعداد الكامل.
يتيح لنا هذا النهج تحقيق جودة قريبة من نماذج التعقيد غير المحدود. يوضح الجدول معدل الخطأ لنماذج المضافات المعممة مقارنةً بغابة عشوائية لحل مشكلة التصنيف في مجموعات البيانات المختلفة ، وفي معظم الحالات ، لا تختلف جودة التنبؤ بـ GA2M مع FAST وللغابات العشوائية اختلافًا كبيرًا.
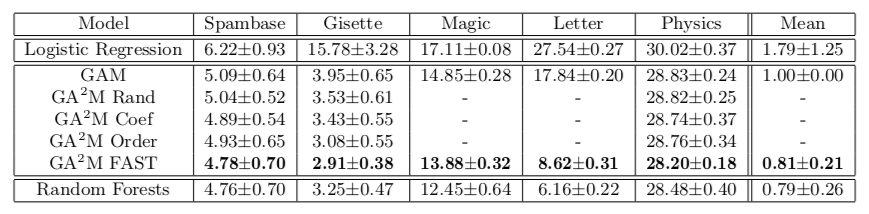
أود أن ألفت الانتباه إلى ميزات عمل الأكاديميين الذين يعرضون إرسال هذه التعزيزات والأرباح العميقة إلى الفرن. يرجى ملاحظة أن مجموعات البيانات التي يتم تقديم النتائج عليها لا تحتوي على أكثر من 20 ألف كائن (جميع مجموعات البيانات من مستودع UCI). يطرح سؤال طبيعي: ألا يوجد بالفعل مجموعة بيانات مفتوحة بالحجم الطبيعي لمثل هذه التجارب في عام 2018؟ يمكنك الذهاب أبعد من ذلك ومقارنتها بمجموعة بيانات من 50 كائنًا - هناك احتمال ألا يختلف النموذج الثابت اختلافًا كبيرًا عن مجموعة عشوائية.
النقطة التالية هي التنظيم. في عدد كبير من العلامات ، من السهل جدًا إعادة التدريب حتى بدون تفاعلات. قد يعتقد المؤلفون أن هذه المشكلة غير موجودة ، والمشكلة الوحيدة هي نموذج الصندوق الأسود. على الأقل في المقال ، لا يتم التحدث عن التنظيم في أي مكان ، على الرغم من أنه من الواضح أنه ضروري.
والأخير ، حول التفسير. لا يمكن تفسير النماذج الخطية حتى إذا كان لدينا الكثير من الميزات. عندما يكون لديك 10 آلاف من الأوزان الموزعة بشكل طبيعي (في حالة استخدام L2 - التنظيم سيكون شيئًا كهذا) ، فمن المستحيل تحديد بالضبط أي العلامات هي المسؤولة عن حقيقة أن Forecast_proba تعطي 0.86. من أجل التفسير ، نحن لا نريد فقط نموذجًا خطيًا ، بل نريد نموذجًا خطيًا بأوزان قليلة. يبدو أنه يمكن تحقيق ذلك عن طريق L1- التنظيم ، ولكن هنا ، أيضا ، ليست بهذه البساطة. من مجموعة من الميزات المترابطة بشدة ، ستختار L1-regularization ميزة واحدة تقريبًا عن طريق الصدفة. سيحصل وزن الباقي على 0 ، رغم أنه إذا كانت إحدى هذه الميزات تتمتع بقدرة تنبؤية ، فمن الواضح أن الميزات الأخرى ليست مجرد ضوضاء. فيما يتعلق بتفسير النموذج ، قد يكون هذا جيدًا ، من حيث فهم العلاقة بين الميزات والمتغير المستهدف ، هذا سيء جدًا. وهذا يعني أنه حتى في النماذج الخطية ، فليس كل شيء في غاية البساطة ، ويمكن العثور على مزيد من التفاصيل حول النماذج القابلة للتفسير والمصداقية
هنا .
التصور للتعلم الآلي: UMAPاستخلصكودفي يوم الدروس ، كان من بين أول من قاموا بـ "التصور للتعلم الآلي" من قِبل Google Brain. كجزء من البرنامج التعليمي ، تم إطلاعنا على تاريخ المرئيات ، بدءًا من منشئ الرسوم البيانية الأولى ، بالإضافة إلى الميزات المختلفة للعقل البشري والإدراك والتقنيات التي يمكن استخدامها لجذب الانتباه إلى أهم شيء في الصورة ، حتى تحتوي على العديد من التفاصيل الصغيرة - على سبيل المثال ، تسليط الضوء على الشكل واللون والإطار ، وما إلى ذلك ، كما في الصورة أدناه. سوف أتخطى هذا الجزء ، لكن هناك
مراجعة جيدة .

شخصياً ، كنت مهتمًا بشكل كبير بموضوع تصور مجموعات البيانات المتعددة الأبعاد ، لا سيما نهج التقريب والإسقاط المنوع الموحد (UMAP) - طريقة جديدة غير خطية لتقليل البعد. لقد تم اقتراحه في شهر فبراير من هذا العام ، لذا قلة قليلة من الناس يستخدمونه حتى الآن ، لكنه يبدو واعداً سواء من حيث وقت العمل أو من حيث جودة الفصل بين الطبقات في تصورات ثنائية الأبعاد. لذلك ، على مجموعات البيانات المختلفة ، UMAP يتفوق 2-10 مرات على t-SNE وغيرها من الطرق من حيث السرعة ، وكلما زاد حجم البيانات ، زادت الفجوة في الأداء:
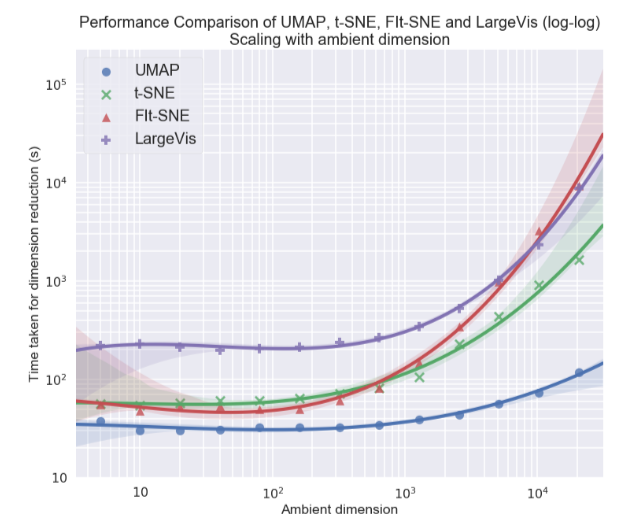
بالإضافة إلى ذلك ، بخلاف t-SNE ، فإن وقت تشغيل UMAP مستقل تقريبًا عن بعد المساحة الجديدة التي سنضم إليها مجموعة البيانات الخاصة بنا (انظر الشكل أدناه) ، مما يجعله أداة مناسبة للمهام الأخرى (إلى جانب التصور) - على وجه الخصوص ، للحد من البعد قبل تدريب النموذج.
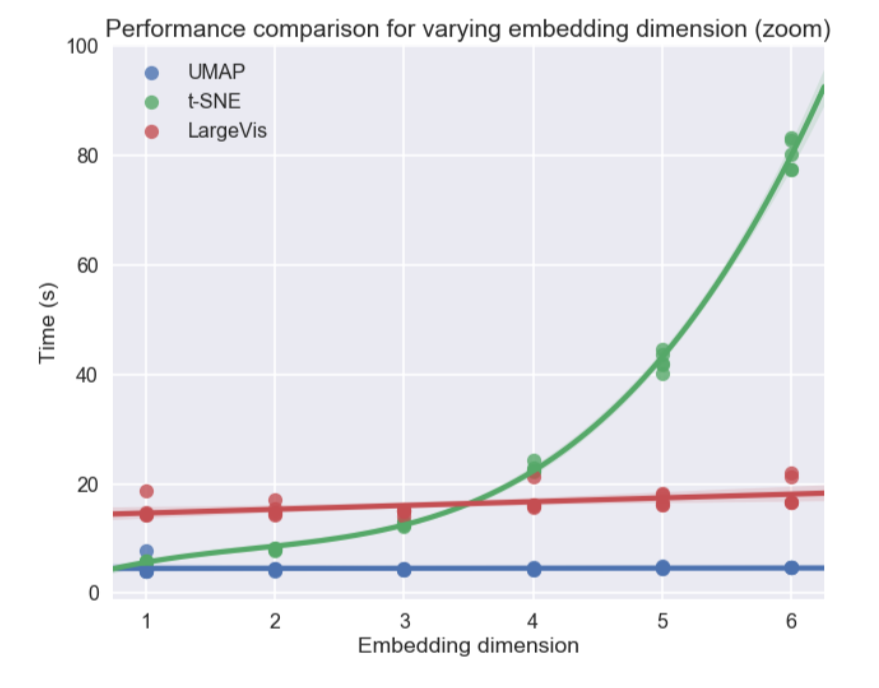
في الوقت نفسه ، أظهر الاختبار على مجموعات بيانات مختلفة أن UMAP لا يعمل بشكل سيء للتصور ، وأن t-SNE أفضل في الأماكن: على سبيل المثال ، في مجموعات البيانات MNIST و Fashion MNIST ، يتم فصل الفئات بشكل أفضل في الإصدار باستخدام UMAP:
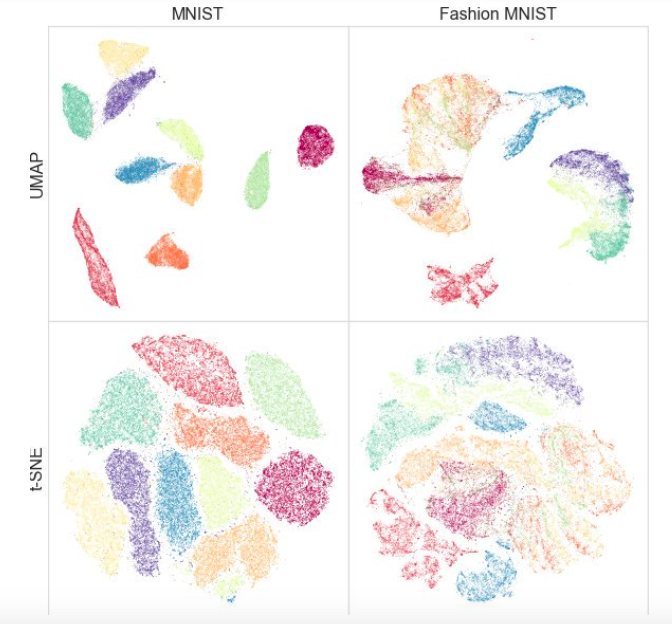
ميزة إضافية هي تطبيق مناسب: فئة UMAP ترث من فئات sklearn ، بحيث يمكنك استخدامها كمحول منتظم في خط أنابيب sklearn. بالإضافة إلى ذلك ، يقال إن UMAP أكثر قابلية للتفسير من t-SNE ، مثل يحافظ بشكل أفضل على بنية بيانات عالمية.
في المستقبل ، يخطط المؤلفون لإضافة دعم للتدريب شبه الخاضع للإشراف - أي إذا كان لدينا علامات لبعض الكائنات على الأقل ، فيمكننا إنشاء UMAP استنادًا إلى هذه المعلومات.
ما هي المواد التي أعجبك؟ اكتب التعليقات وطرح الأسئلة ، وسوف نجيب عليها.