مرحبا الزملاء!

في المنشور الأخير من السنة المنتهية ولايته ، أردنا أن نذكر برنامج تعزيز التعلم - وهو موضوع نترجم
كتابًا إليه بالفعل.
الحكم على نفسك: كان هناك مقال أولي مع متوسط ، والذي أوضح سياق المشكلة ، ووصف أبسط الخوارزمية مع التنفيذ في بيثون. المقالة لها عدة صور. والدافع والمكافأة واختيار الاستراتيجية الصحيحة على طريق النجاح هي أشياء ستكون مفيدة للغاية لكل واحد منا في العام المقبل.
هل لديك قراءة لطيفة!
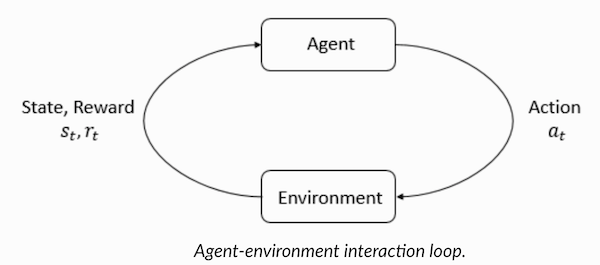
التعلم المعزز هو شكل من أشكال التعلم الآلي الذي يتعلم فيه الوكيل التصرف في البيئة ، وأداء الإجراءات ، وبالتالي تطوير الحدس ، وبعد ذلك يلاحظ نتائج أفعاله. سأخبرك في هذا المقال عن كيفية فهم وصياغة مشكلة التعلم مع التعزيز ، ثم حلها في بيثون.
لقد اعتدنا مؤخرًا على حقيقة أن أجهزة الكمبيوتر تلعب ألعابًا ضد البشر - إما كالبوتات في ألعاب متعددة اللاعبين أو كمنافسين في ألعاب فردية: على سبيل المثال ، في Dota2 و PUB-G و Mario.
أثارت شركة الأبحاث
Deepmind ضجة حول الأخبار عندما فاز برنامج AlphaGo 2016 على بطل كوريا الجنوبية في عام 2016. إذا كنت لاعبة متعطشة ، يمكنك أن تسمع عن المباريات الخمس في Dota 2 OpenAI Five ، حيث قاتلت السيارات ضد الناس وهزمت أفضل اللاعبين في Dota2 في عدة مباريات. (إذا كنت مهتمًا بالتفاصيل ، يتم تحليل الخوارزمية بالتفصيل
هنا وسيتم فحص كيفية تشغيل الآلات).

أحدث نسخة من OpenAI Five
تأخذ روشان .
لذلك ، لنبدأ بالسؤال المركزي. لماذا نحتاج إلى تدريب معزز؟ هل يستخدم فقط في الألعاب ، أم أنه قابل للتطبيق في سيناريوهات واقعية لحل المشكلات المطبقة؟ إذا كانت هذه هي المرة الأولى التي تقرأ فيها التدريب على التعزيز ، فلا يمكنك ببساطة تخيل الإجابة عن هذه الأسئلة. في الواقع ، يعد التعلم المعزز واحدًا من أكثر التقنيات استخدامًا والأكثر تطوراً بسرعة في مجال الذكاء الاصطناعي.
فيما يلي عدد من المجالات التي تتطلب فيها أنظمة تعلم التعزيز بشكل خاص:
- المركبات غير المأهولة
- صناعة اللعبة
- الروبوتات
- نظم التوصية
- الإعلان والتسويق
نظرة عامة وخلفية التعلم التعزيزلذلك ، كيف تتشكل ظاهرة التعلم مع التعزيز عندما يكون لدينا الكثير من أساليب التعلم العميق والآلي تحت تصرفنا؟ "لقد اخترعه ريتش ساتون وأندرو بارتو ، مشرف أبحاث ريتش الذي ساعده في إعداد الدكتوراه". بدأ النموذج لأول مرة في الثمانينيات وكان قديمًا. في وقت لاحق ، اعتقدت ريتش أن لها مستقبلًا عظيمًا ، وستحصل في النهاية على تقدير.
يدعم التعلم المعزز الأتمتة في البيئة التي يتم نشرها فيها. يعمل كل من الآلة والتعلم العميق بنفس الطريقة تقريبًا - يتم ترتيبهما استراتيجياً بشكل مختلف ، لكن كلا النموذجين يدعمان التشغيل الآلي. فلماذا التدريب التعزيز تنشأ؟
إنها تذكرنا بشدة بعملية التعلم الطبيعية ، حيث تتصرف العملية / النموذج وتتلقى تعليقات حول كيفية إدارتها للتعامل مع المهمة: جيدة وليس.
يعد التعليم الآلي والتعلم العميق من خيارات التدريب ، ومع ذلك ، فقد تم تصميمهما بشكل أكبر لتحديد أنماط البيانات المتاحة. في التعلم المعزز ، من ناحية أخرى ، يتم اكتساب هذه التجربة من خلال التجربة والخطأ ؛ النظام يجد تدريجيا الخيارات الصحيحة أو العالمية الأمثل. من الميزات الإضافية الجادة للتعليم المعزز أنه في هذه الحالة ، ليس من الضروري توفير مجموعة واسعة من بيانات التدريب ، كما هو الحال مع التدريس مع المعلم. وهناك عدد قليل من شظايا صغيرة تكفي.
مفهوم التعلم التعزيزتخيل تعليم القطط حيل جديدة. لكن لسوء الحظ ، فإن القطط لا تفهم اللغة البشرية ، لذلك لا يمكنك أخذها وإخبارها بما ستلعب به. لذلك ، سوف تتصرف بشكل مختلف: تقليد الموقف ، وسوف تحاول القط الاستجابة بطريقة أو بأخرى استجابة. إذا كان رد فعل القطة بالطريقة التي تريدها ، فقم بسكب الحليب عليها. هل تفهم ماذا سيحدث بعد ذلك؟ مرة أخرى ، في وضع مماثل ، ستنفذ القطة الإجراء المطلوب مرة أخرى ، وبقدر أكبر من الحماس ، على أمل أن يتم تغذيتها بشكل أفضل. هذه هي الطريقة التي يحدث بها التعلم في مثال إيجابي ؛ ولكن ، إذا حاولت "تثقيف" قطة ذات حوافز سلبية ، على سبيل المثال ، أن تنظر إليها بدقة وتهيج ، فإنها عادة لا تتعلم في مثل هذه الحالات.
التعلم المعزز يعمل بالمثل. نقول للآلة بعض المدخلات والإجراءات ، ثم نكافئ الجهاز وفقًا للإخراج. هدفنا النهائي هو تعظيم المكافآت. الآن دعونا نلقي نظرة على كيفية إعادة صياغة المشكلة أعلاه من حيث التعلم التعزيز.
- القط بمثابة "وكيل" تتعرض ل "البيئة".
- البيئة عبارة عن منطقة للعب أو المنزل ، اعتمادًا على ما تقوم بتدريسه للقط.
- الحالات الناشئة عن التدريب تسمى "الدول". في حالة قطة ، أمثلة على الحالات هي عندما "القط" يركض أو "يزحف تحت السرير".
- يتفاعل وكلاء من خلال أداء الإجراءات والانتقال من "حالة" إلى أخرى.
- بعد تغيير الحالة ، يتلقى الوكيل "مكافأة" أو "غرامة" حسب الإجراء الذي اتخذه.
- "الإستراتيجية" هي منهجية لاختيار إجراء للحصول على أفضل النتائج.
الآن وبعد أن اكتشفنا ماهية تعلم التعزيز ، دعونا نتحدث بالتفصيل عن أصول وتطور التعلم التعزيز والتعلم العميق مع التعزيز ، وناقش كيف يسمح لنا هذا النموذج بحل المشكلات التي يتعذر تعلمها مع أو بدون معلم ، ولاحظ أيضًا ما يلي حقيقة غريبة: في الوقت الحالي ، تم تحسين محرك بحث Google باستخدام خوارزميات التعلم المعزز.
فهم التعزيز مصطلحات التعلميلعب العامل والبيئة أدوارًا رئيسية في خوارزمية التعلم المعزز. البيئة هي العالم الذي يجب على الوكيل البقاء فيه. بالإضافة إلى ذلك ، يتلقى العامل إشارات التعزيز من البيئة (المكافأة): هذا هو الرقم الذي يصف كيف جيدة أو سيئة الحالة الراهنة في العالم يمكن النظر فيها. الغرض من الوكيل هو تعظيم المكافأة الكلية ، ما يسمى "المكسب". قبل كتابة خوارزميات تعلم التعزيز الأولى ، تحتاج إلى فهم المصطلحات التالية.

- الدول : الدولة هي وصف كامل لعالم لا يوجد فيه جزء واحد من المعلومات التي تميز هذا العالم مفقود. يمكن أن يكون الموقف ، ثابت أو ديناميكي. وكقاعدة عامة ، تتم كتابة مثل هذه الحالات في شكل صفائف أو مصفوفات أو موترات من الدرجة العليا.
- الإجراء : يعتمد الإجراء عادةً على الظروف البيئية ، وفي البيئات المختلفة ، يتخذ العامل إجراءات مختلفة. يتم تسجيل العديد من إجراءات الوكيل الصحيحة في مساحة تسمى "مساحة الإجراء". عادةً ما يكون عدد الإجراءات في الفضاء محدودًا.
- البيئة : هذا هو المكان الذي يوجد فيه الوكيل والذي يتفاعل معه. تُستخدم أنواع مختلفة من المكافآت والاستراتيجيات وما إلى ذلك في بيئات مختلفة.
- المكافآت والأرباح : تحتاج إلى مراقبة وظيفة المكافأة R باستمرار عند التدريب باستخدام التعزيزات. من المهم للغاية عند إعداد خوارزمية ، وتحسينها ، وكذلك عند التوقف عن التعلم. يعتمد الأمر على الحالة الراهنة للعالم ، والإجراء الذي اتخذ للتو والحالة التالية في العالم.
- الإستراتيجيات : الإستراتيجية هي القاعدة التي بموجبها يختار الوكيل الإجراء التالي. يشار أيضًا إلى مجموعة الاستراتيجيات باسم "دماغ" العامل.
الآن وقد أصبحنا على دراية بمصطلحات التعلم المعزز ، فلنحل المشكلة باستخدام الخوارزميات المناسبة. قبل ذلك ، تحتاج إلى فهم كيفية صياغة مثل هذه المشكلة ، وعند حل هذه المشكلة ، تعتمد على مصطلحات التدريب مع التعزيز.
حل التاكسيلذلك ، ننتقل إلى حل المشكلة باستخدام خوارزميات التعزيز.
لنفترض أن لدينا منطقة تدريب لسيارة أجرة غير مأهولة ، والتي نقوم بتدريبها لتسليم الركاب إلى موقف السيارات في أربع نقاط مختلفة (
R,G,Y,B ). قبل ذلك ، تحتاج إلى فهم وتعيين البيئة التي نبدأ بها البرمجة في Python. إذا كنت بدأت للتو في تعلم بايثون ، فإنني أوصي
بهذا المقال .
يمكن تهيئة بيئة حل مشكلة التاكسي باستخدام OpenAI's
Gym - وهي واحدة من أكثر المكتبات شعبية لحل المشكلات من خلال التدريب على التعزيز. حسنًا ، قبل استخدام الصالة الرياضية ، تحتاج إلى تثبيته على جهازك ، ومدير حزمة Python يسمى pip مناسب لذلك. ما يلي هو أمر التثبيت.
pip install gymبعد ذلك ، لنرى كيف سيتم عرض بيئتنا. تم بالفعل تكوين جميع النماذج والواجهة الخاصة بهذه المهمة في صالة الألعاب الرياضية وتم تسميتها ضمن
Taxi-V2 . يتم استخدام مقتطف الشفرة أدناه لعرض هذه البيئة.
"لدينا 4 مواقع (يشار إليها بأحرف مختلفة) ؛ مهمتنا هي التقاط أحد الركاب في وقت ما وإسقاطه في مكان آخر. نحصل على +20 نقطة لعملية هبوط ناجحة للركاب ونخسر نقطة واحدة لكل خطوة تنفق عليها. هناك عقوبة من 10 نقاط لكل صعود غير مقصود ونزول راكب ". (المصدر:
gym.openai.com/envs/Taxi-v2 )
فيما يلي الإخراج الذي سنراه في وحدة التحكم الخاصة بنا:

تاكسي V2 ENV
رائع ،
env هو قلب OpenAi Gym ، إنه واجهة بيئة موحدة. فيما يلي طرق env التي نجدها مفيدة:
env.reset : إعادة تعيين البيئة وإرجاع حالة أولية عشوائية.
env.step(action) : تقدم
env.step(action) تطوير البيئة خطوة واحدة في الوقت المناسب.
env.step(action) : تُرجع المتغيرات التالية
observation : مراقبة البيئة.reward : reward ما إذا كان عملك مفيدًا.done : يشير إلى ما إذا كنا نجحنا في التقاط الركاب وتوصيلهم بشكل صحيح ، ويشار إليهم أيضًا باسم "حلقة واحدة".info : info إضافية مثل الأداء والكمون اللازمة لأغراض التصحيح.env.render : يعرض إطارًا واحدًا للبيئة (مفيدًا env.render )
لذلك ، بعد فحص البيئة ، دعونا نحاول فهم المشكلة بشكل أفضل. سيارات الأجرة هي السيارة الوحيدة في موقف السيارات هذا. يمكن تقسيم مواقف السيارات إلى شبكة
5x5 ، حيث نحصل على 25 موقعًا لسيارات الأجرة. هذه القيم 25 هي واحدة من عناصر الفضاء دولتنا. يرجى ملاحظة: في الوقت الحالي ، تقع سيارة أجرة لدينا في نقطة مع الإحداثيات (3 ، 1).
هناك 4 نقاط في البيئة يُسمح للمسافرين بالركوب فيها:
R, G, Y, B أو
[(0,0), (0,4), (4,0), (4,3)] في الإحداثيات ( أفقيا ، رأسيا) ، إذا كان من الممكن تفسير البيئة المذكورة أعلاه في الإحداثيات الديكارتية. إذا كنت تأخذ أيضًا في الحسبان حالة واحدة (1) من الركاب: داخل سيارة الأجرة ، يمكنك أخذ جميع مجموعات مواقع الركاب ووجهاتهم من أجل حساب إجمالي عدد الدول في بيئتنا لتدريب سيارات الأجرة: لدينا أربع (4) وجهات وخمس (4+) 1) مواقع الركاب.
لذلك ، في بيئتنا لسيارة أجرة ، هناك 5 × 5 × 5 × 4 = 500 حالة ممكنة. يتعامل الوكيل مع واحد من 500 حالة ويتخذ إجراءً. في حالتنا ، تكون الخيارات كما يلي: التحرك في اتجاه واحد أو آخر ، أو قرار التقاط / إنزال الركاب. بمعنى آخر ، لدينا تحت تصرفنا ستة إجراءات ممكنة:
لاقط ، إسقاط ، شمال ، شرق ، جنوب ، غرب (القيم الأربعة الأخيرة هي اتجاهات يمكن لسيارة أجرة أن تتحرك بها.)
هذه هي
action space : مجموعة من الإجراءات التي يمكن أن يتخذها وكيلنا في حالة معينة.
كما هو واضح من الرسم التوضيحي أعلاه ، لا يمكن لسيارة أجرة القيام ببعض الإجراءات في بعض الحالات (تتداخل الجدران). في الكود الذي يصف البيئة ، نحن ببساطة نحدد غرامة قدرها -1 لكل ضربة في الحائط ، وسيارة أجرة تصطدم بالجدار. وبالتالي ، سوف تتراكم مثل هذه الغرامات ، وبالتالي ستحاول سيارة الأجرة عدم ضرب الجدران.
جدول المكافآت: عند إنشاء بيئة سيارات الأجرة ، يمكن أيضًا إنشاء جدول مكافأة أولي يسمى P. يمكنك اعتباره مصفوفة ، حيث يتوافق عدد الحالات مع عدد الصفوف وعدد الإجراءات بعدد الأعمدة. بمعنى ، نحن نتحدث عن مصفوفة
states × actions .
نظرًا لأنه يتم تسجيل جميع الشروط في هذه المصفوفة ، يمكنك عرض قيم المكافآت الافتراضية المخصصة للحالة التي اخترناها لتوضيح:
>>> import gym >>> env = gym.make("Taxi-v2").env >>> env.P[328] {0: [(1.0, 433, -1, False)], 1: [(1.0, 233, -1, False)], 2: [(1.0, 353, -1, False)], 3: [(1.0, 333, -1, False)], 4: [(1.0, 333, -10, False)], 5: [(1.0, 333, -10, False)] }
بنية هذا القاموس هي كما يلي:
{action: [(probability, nextstate, reward, done)]} .
- تتوافق القيم من 0 إلى 5 مع الإجراءات (الجنوب والشمال والشرق والغرب والبيك اب والإسقاط) التي يمكن أن تؤديها سيارة أجرة في الحالة الحالية الموضحة في الرسم التوضيحي.
- القيام به يسمح لك بالحكم عندما ننزل الراكب بنجاح في النقطة المطلوبة.
لحل هذه المشكلة دون أي تدريب مع التعزيزات ، يمكنك تعيين الحالة المستهدفة ، واختيار مساحات ، ومن ثم ، إذا كنت تستطيع الوصول إلى الحالة المستهدفة لعدد معين من التكرار ، افترض أن هذه اللحظة تتوافق مع الحد الأقصى للمكافأة. في حالات أخرى ، تقترب قيمة المكافأة من الحد الأقصى إذا كان البرنامج يعمل بشكل صحيح (يقترب من الهدف) أو يتراكم الغرامات إذا ارتكب أخطاء. علاوة على ذلك ، لا يمكن أن تصل قيمة الغرامة إلى أقل من -10.
دعنا نكتب كود لحل هذه المشكلة دون التدريب التعزيز.
نظرًا لأن لدينا P-table مع قيم المكافآت الافتراضية لكل ولاية ، يمكننا محاولة تنظيم التنقل لسيارات الأجرة لدينا بناءً على هذا الجدول.
ننشئ حلقة لا نهائية ، نمرر حتى يصل المسافر إلى الوجهة (حلقة واحدة) ، أو بعبارة أخرى ، إلى أن يصل معدل المكافأة إلى 20.
env.action_space.sample() طريقة
env.action_space.sample() تلقائيًا إجراء عشوائي من مجموعة جميع الإجراءات المتاحة . النظر في ما يحدث:
import gym from time import sleep
الخلاصة:
ائتمانات: OpenAI
تم حل المشكلة ، ولكن لم يتم تحسينها ، أو لن تعمل هذه الخوارزمية في جميع الحالات. نحتاج إلى عامل تفاعل مناسب حتى يظل عدد التكرارات التي تنفقها الآلة / الخوارزمية لحل المشكلة في حده الأدنى. هنا سوف تساعدنا خوارزمية Q-Learning ، والتي سننظر في تنفيذها في القسم التالي.
تقديم Q- التعلمأدناه هو الأكثر شعبية واحدة من أبسط خوارزميات التعلم التعزيز. تكافئ البيئة وكيل التدريب التدريجي وحقيقة أنه في حالة معينة يتخذ الخطوة المثلى. في التنفيذ الذي تمت مناقشته أعلاه ، كان لدينا جدول مكافآت "P" ، وفقًا لتعلم وكيلنا. استنادًا إلى جدول المكافآت ، يختار الإجراء التالي وفقًا لمدى فائدته ، ثم يقوم بتحديث قيمة أخرى تسمى القيمة Q. نتيجة لذلك ، يتم إنشاء جدول جديد يسمى جدول Q-المعروض على المجموعة (الحالة ، الإجراء). إذا كانت قيم Q أفضل ، فسنحصل على مكافآت أفضل.
على سبيل المثال ، إذا كانت سيارة أجرة في ولاية يكون فيها الراكب في نفس نقطة سيارة الأجرة ، فمن المحتمل جدًا أن تكون قيمة Q بالنسبة لتصرف "الالتقاط" أعلى من الإجراءات الأخرى ، على سبيل المثال ، "إنزال الركاب" أو "الذهاب شمالًا" ".
تتم تهيئة قيم Q بقيم عشوائية ، وبما أن العامل يتفاعل مع البيئة ويتلقى مكافآت متنوعة من خلال القيام بإجراءات معينة ، يتم تحديث قيم Q وفقًا للمعادلة التالية:

هذا يطرح السؤال: كيفية تهيئة قيم Q وكيفية حسابها. عند تنفيذ الإجراءات ، يتم تنفيذ قيم Q في هذه المعادلة.
هنا ، ألفا وجاما هي معلمات خوارزمية Q- التعلم. ألفا هي سرعة التعلم ، وجاما هي عامل الخصم. يمكن أن تتراوح القيمتان من 0 إلى 1 وتكون في بعض الأحيان مساوية واحدة. يمكن أن تكون جاما مساوية للصفر ، ولكن لا يمكن لـ alpha ، لأن قيمة الخسائر أثناء التحديث يجب تعويضها (معدل التعلم إيجابي). قيمة ألفا هنا هي نفسها عند التدريس مع المعلم. تحدد جاما مدى أهمية أننا نريد منح المكافآت التي تنتظرنا في المستقبل.
هذه الخوارزمية ملخصة أدناه:
- الخطوة 1: تهيئة جدول Q- ، وملئه بالأصفار ، وبالنسبة لقيم Q- نضع ثوابت تعسفية.
- الخطوة 2: اسمح للعامل بالرد على البيئة وحاول القيام بإجراءات مختلفة. لكل تغيير حالة ، نختار واحدًا من جميع الإجراءات الممكنة في هذه الحالة (S).
- الخطوة 3: انتقل إلى الحالة التالية (S ') استنادًا إلى نتائج الإجراء السابق (أ).
- الخطوة 4: لجميع الإجراءات الممكنة من الحالة (S ') ، حدد إجراءًا له أعلى قيمة Q.
- الخطوة 5: تحديث قيم جدول Q- وفقًا للمعادلة أعلاه.
- الخطوة 6: حول الحالة التالية إلى الحالة الحالية.
- الخطوة 7: إذا تم الوصول إلى الحالة المستهدفة ، فإننا نكمل العملية ، ثم نكررها.
كيو التعلم في بيثون import gym import numpy as np import random from IPython.display import clear_output
رائع ، الآن سيتم تخزين جميع القيم الخاصة بك في المتغير
q_table .
لذلك ، تم تدريب النموذج الخاص بك على الظروف البيئية ، ويعرف الآن كيفية اختيار الركاب بدقة أكبر. وقد تعرفت على ظاهرة التعلم التعزيز ، ويمكنك برمجة الخوارزمية لحل مشكلة جديدة.
تقنيات التعلم التعزيز الأخرى:
- عمليات صنع القرار في ماركوف (MDP) ومعادلات بيلمان
- البرمجة الديناميكية: RL المستندة إلى النموذج ، وتكرار الإستراتيجية ، وتكرار القيمة
- عميق Q- التدريب
- أساليب النسب التدرج الاستراتيجية
- سارسا
رمز هذا التمرين موجود في:
vihar / بيثون التعزيز التعلم