لقد وجدنا في OpenAI أن مقياس ضوضاء التدرج ، طريقة إحصائية بسيطة ، تتنبأ بتوازي تعلم شبكة محايدة عبر مجموعة واسعة من المهام. نظرًا لأن التدرج اللوني عادة ما يكون أكثر ضوضاءً للمهام الأكثر تعقيدًا ، فإن زيادة حجم الحزم المتاحة للمعالجة المتزامنة ستكون مفيدة في المستقبل ، وستزيل أحد القيود المحتملة على أنظمة الذكاء الاصطناعي. في الحالة العامة ، تبين هذه النتائج أن تدريب الشبكات العصبية لا ينبغي اعتباره فنًا غامضًا ، وأنه يمكن إعطاؤه الدقة والمنهجية.
خلال السنوات القليلة الماضية ، نجح باحثو الذكاء الاصطناعى بشكل متزايد في تسريع تعلم الشبكات العصبية من خلال موازاة البيانات ، وكسر حزم كبيرة من البيانات إلى أجهزة كمبيوتر متعددة. استخدم الباحثون بنجاح عشرات الآلاف من الوحدات
لتصنيف الصور ونمذجة اللغة ، وحتى بالنسبة للملايين
من وكلاء التعلم المعززين الذين لعبوا Dota 2. يمكن لهذه الحزم الكبيرة أن تزيد من مقدار القدرة الحاسوبية التي تشارك بشكل فعال في تدريس نموذج واحد ، وهي واحدة القوى الدافعة
للنمو في التدريب على الذكاء الاصطناعى. ومع ذلك ، مع وجود حزم بيانات كبيرة جدًا ، يوجد انخفاض سريع في عوائد الخوارزميات ، وليس من الواضح لماذا تتضح أن هذه القيود أكبر بالنسبة لبعض المهام وأصغر بالنسبة للبعض الآخر.
 يمثل تدرج الضوضاء المتدرجة ، الذي يتم حسابه على أساس أساليب التدريب ، معظم (ص 2 = 80٪) من الاختلافات في حجم رزمة البيانات الحرجة للمشاكل المختلفة ، والتي تختلف بمقدار ستة أوامر من حيث الحجم. يتم قياس أحجام العبوات في عدد الصور أو الرموز (لطرز اللغة) أو الملاحظات (للألعاب).
يمثل تدرج الضوضاء المتدرجة ، الذي يتم حسابه على أساس أساليب التدريب ، معظم (ص 2 = 80٪) من الاختلافات في حجم رزمة البيانات الحرجة للمشاكل المختلفة ، والتي تختلف بمقدار ستة أوامر من حيث الحجم. يتم قياس أحجام العبوات في عدد الصور أو الرموز (لطرز اللغة) أو الملاحظات (للألعاب).لقد وجدنا أنه بقياس مقياس ضوضاء التدرج ، إحصائيات بسيطة تحدد عدديًا نسبة الإشارة إلى الضوضاء في التدرجات اللونية للشبكة ، يمكننا تقريبًا الحد الأقصى لحجم الحزمة. إرشاديًا ، يقيس مقياس الضوضاء تباين البيانات من وجهة نظر النموذج (في مرحلة معينة من التدريب). عندما يكون مقياس الضوضاء صغيرًا ، يصبح التعلم الموازي على كمية كبيرة من البيانات سريعًا زائداً ، وعندما يكون حجمه كبيرًا ، يمكننا أن نتعلم الكثير عن مجموعات البيانات الكبيرة.
تستخدم الإحصائيات من هذا النوع على نطاق واسع
لتحديد حجم العينة ، وقد
اقترح استخدامها في
التعلم العميق ، لكنها لم تستخدم بشكل منهجي للتدريب العصري على الشبكات العصبية. لقد أكدنا هذا التنبؤ لمجموعة كبيرة من مهام التعلم الآلي الموضحة في الرسم البياني أعلاه ، بما في ذلك التعرف على الأنماط ونمذجة اللغة وألعاب Atari و Dota. على وجه الخصوص ، قمنا بتدريب الشبكات العصبية المصممة لحل كل من هذه المشاكل على حزم البيانات من مختلف الأحجام (بشكل منفصل ضبط سرعة التعلم لكل منها) ، وقارننا تسريع التعلم مع تلك المتوقعة من قبل مقياس الضوضاء. نظرًا لأن حزم البيانات كبيرة الحجم تتطلب غالبًا ضبطًا دقيقًا ومكلفًا أو جدولًا خاصًا لسرعة التدريب حتى يكون التدريب فعالًا ومعرفة الحد الأعلى مقدمًا ، يمكنك الحصول على ميزة كبيرة عند تدريب نماذج جديدة.
لقد وجدنا أنه من المفيد تصور نتائج هذه التجارب كحل وسط بين وقت التدريب الفعلي والمبلغ الإجمالي للحساب المطلوب للتدريب (بما يتناسب مع تكلفته بالمال). في حزم البيانات الصغيرة جدًا ، يسمح مضاعفة حجم الحزمة بتنفيذ التدريب مرتين بالسرعة دون استخدام طاقة حوسبة إضافية (ندير ضعف عدد مؤشرات الترابط الفردية التي تعمل مرتين بأسرع). على نماذج كبيرة الحجم للبيانات ، التوازي لا يسرع التعلم. ينحني المنحنى في المنتصف الأوسط ، ويتوقع مقياس الضوضاء المتدرجة مكان حدوث الانحناء بالضبط.
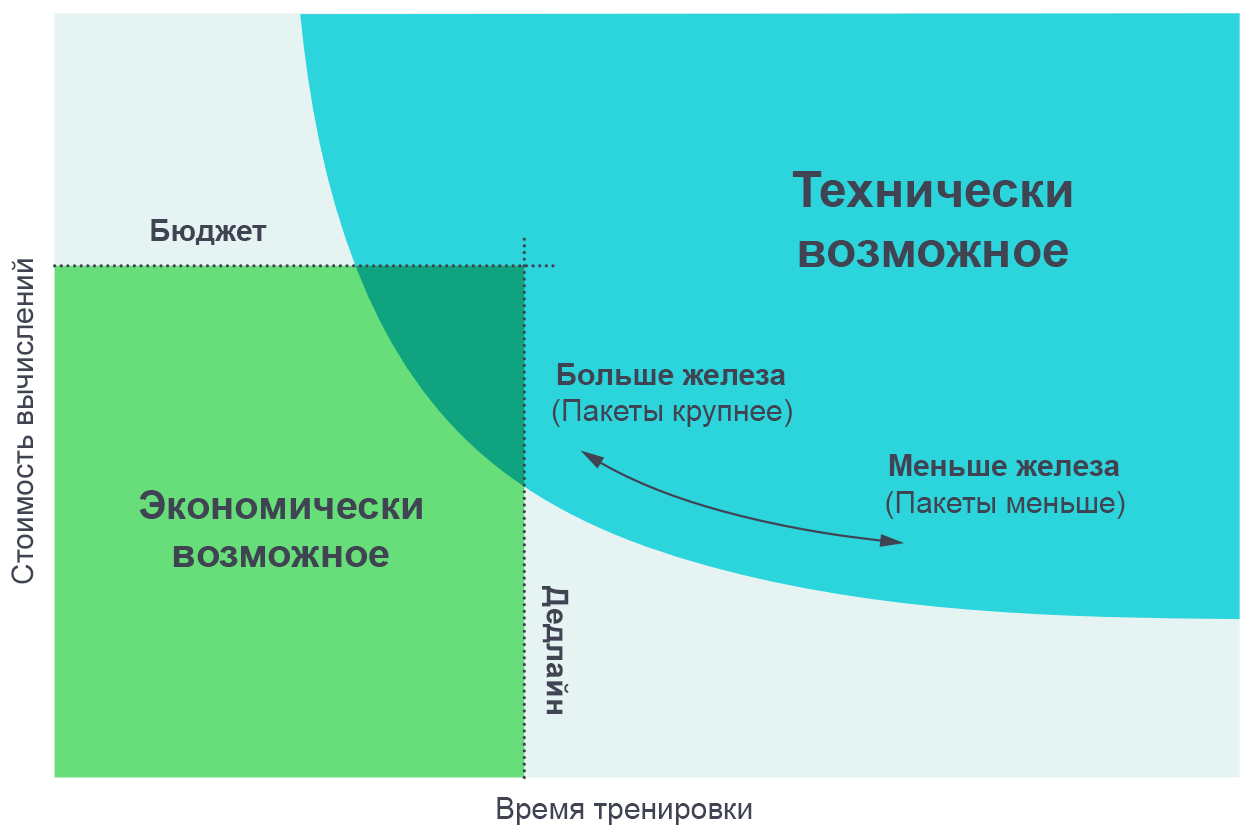 تتيح لك زيادة عدد العمليات الموازية تدريب نماذج أكثر تعقيدًا في وقت معقول. يعد مخطط الحدود Pareto هو الطريقة الأكثر سهولة لتصور مقارنات الخوارزميات والمقاييس.
تتيح لك زيادة عدد العمليات الموازية تدريب نماذج أكثر تعقيدًا في وقت معقول. يعد مخطط الحدود Pareto هو الطريقة الأكثر سهولة لتصور مقارنات الخوارزميات والمقاييس.نحصل على هذه المنحنيات من خلال تعيين هدف لمهمة (على سبيل المثال ، 1000 نقطة في لعبة Beam Rider الخاصة بـ Atari) ومراقبة الوقت الذي يستغرقه تدريب شبكة عصبية لتحقيق هذا الهدف بأحجام حزم مختلفة. تتزامن النتائج بدقة تامة مع تنبؤات نموذجنا ، مع مراعاة القيم المختلفة للأهداف التي حددناها.
[
تعرض الصفحة مع المقالة الأصلية رسومات بيانية تفاعلية لحل وسط بين التجربة ووقت التدريب الضروري لتحقيق هدف معين ]
أنماط مقياس الضوضاء التدرج
صادفنا العديد من الأنماط في مقياس ضوضاء التدرج ، والتي يمكننا على أساسها افتراضات حول مستقبل تدريب الذكاء الاصطناعى.
أولاً ، في تجاربنا في عملية التعلم ، يزداد مقياس الضوضاء عادةً بمقدار أو أكثر. على ما يبدو ، هذا يعني أن الشبكة تتعلم المزيد من الميزات "الواضحة" للمشكلة في بداية التدريب ، ثم تدرس التفاصيل الأصغر. على سبيل المثال ، في مهمة تصنيف الصور ، يمكن للشبكة العصبية أن تتعلم أولاً تحديد ميزات ذات نطاق صغير ، مثل الحواف أو القوام المعروضة في معظم الصور ، وقارن هذه الأشياء الصغيرة معًا لاحقًا فقط ، وخلق مفاهيم عامة أكثر ، مثل القطط أو الكلاب. للحصول على فكرة عن مجموعة كاملة من الوجوه والقوام ، تحتاج الشبكات العصبية إلى رؤية عدد صغير من الصور ، بحيث يكون نطاق الضوضاء أصغر ؛ بمجرد أن تعرف الشبكة المزيد عن الكائنات الكبيرة ، ستتمكن من معالجة المزيد من الصور في نفس الوقت دون التفكير في تكرار البيانات.
لقد رأينا بعض
المؤشرات الأولية التي تفيد بأن هناك تأثيرًا مشابهًا يعمل أيضًا على الطرز الأخرى التي تتعامل مع نفس مجموعة البيانات - بالنسبة للطرز الأكثر قوة ، يكون مقياس ضوضاء التدرج أعلى ، ولكن فقط لأن لديهم خسائر أقل. لذلك ، هناك بعض الدلائل على أن زيادة حجم الضوضاء أثناء التدريب ليست مجرد أثر تقارب ، ولكن بسبب تحسن في النموذج. إذا كان الأمر كذلك ، فبإمكاننا أن نتوقع أن يكون للنماذج المحسنة في المستقبل نطاق كبير من الضوضاء وسيكون أكثر ملاءمة للموازنة.
ثانياً ، المهام الأكثر تعقيداً بشكل موضوعي تكون أكثر قابلية للتوافق. في سياق التدريس مع المعلم ، يظهر تقدم واضح في الانتقال من MNIST إلى SVHN و ImageNet. في سياق التدريب على التعزيزات ، تم إحراز تقدم واضح في الانتقال من Atari Pong إلى
Dota 1v1 و
Dota 5v5 ، ويختلف حجم حزمة البيانات المثلى عن 10،000 مرة. لذلك ، نظرًا لأن مهام الذكاء الاصطناعي تتعامل مع المهام المتزايدة التعقيد ، فمن المتوقع أن تتعامل النماذج مع مجموعات البيانات الكبيرة بشكل متزايد.
العواقب
تؤثر درجة موازنة البيانات بشكل خطير على سرعة تطوير قدرات الذكاء الاصطناعي. يجعل تسريع التعلم من الممكن إنشاء نماذج أكثر قدرة وتسريع البحث ، مما يتيح لك تقصير وقت كل تكرار.
في دراسة سابقة ، "
الذكاء الاصطناعي والحسابات "
، رأينا أن الحسابات لتدريب أكبر النماذج تتضاعف كل 3.5 أشهر ، ولاحظنا أن هذا الاتجاه يعتمد على مزيج من الاقتصاد (الرغبة في إنفاق الأموال على العمليات الحسابية) وقدرات حسابية لموازنة التعلم. . من الصعب التنبؤ بالعامل الأخير (التوازي الخوارزمي) ، ولم يتم بعد دراسة حدوده بالكامل ، لكن نتائجنا الحالية تمثل خطوة للأمام في تنظيمه وتعبيره العددي. على وجه الخصوص ، لدينا أدلة على أن المهام الأكثر تعقيدًا ، أو النماذج الأكثر قوة التي تستهدف مهمة معروفة ، ستسمح بمزيد من العمل المتوازي مع البيانات. سيكون هذا عاملاً رئيسيًا يدعم النمو الهائل للحوسبة المتعلقة بالتعلم. ونحن لا ننظر حتى في
التطورات الأخيرة في مجال النماذج المتوازية ، والتي يمكن أن تسمح لنا بزيادة تعزيز الموازاة عن طريق إضافتها إلى معالجة البيانات الموازية الحالية.
إن النمو المستمر في مجال الحوسبة التدريبية وقاعدته الحسابية التي يمكن التنبؤ بها يتحدث عن احتمال حدوث زيادة هائلة في قدرات الذكاء الاصطناعي في السنوات القليلة المقبلة ، ويؤكد على الحاجة إلى إجراء
دراسة مبكرة للاستخدام الآمن
والمسؤول لهذه الأنظمة. تتمثل الصعوبة الرئيسية في إنشاء سياسة الذكاء الاصطناعي في تحديد كيفية استخدام مثل هذه التدابير للتنبؤ بخصائص أنظمة الذكاء الاصطناعي المستقبلية ، واستخدام هذه المعرفة لإنشاء قواعد تسمح للمجتمع بزيادة فائدته وتقليل ضرر هذه التقنيات إلى الحد الأدنى.
تعتزم OpenAI إجراء تحليل دقيق للتنبؤ بمستقبل الذكاء الاصطناعى ، ومعالجة التحديات التي يثيرها هذا التحليل بشكل استباقي.