
لذا ، فقد حان الوقت للحديث عن الجيل التالي من المعالجات متعددة الخلايا: MultiClet S1. إذا كانت هذه هي المرة الأولى التي تسمع فيها عنها ، فتأكد من مراجعة تاريخ أيديولوجية الهندسة المعمارية في هذه المقالات:
في الوقت الحالي ، لا يزال المعالج الجديد قيد التطوير ، لكن النتائج الأولى ظهرت بالفعل ويمكنك تقييم ما سيكون قادرًا عليه.
لنبدأ مع أكبر التغييرات: الميزات الأساسية.
الخصائص
من المخطط تحقيق المؤشرات التالية:
- عدد الخلايا: 64
- العملية التقنية: 28 نانومتر
- تردد الساعة: 1.6 جيجا هرتز
- حجم الذاكرة على الرقاقة: 8 ميجابايت
- منطقة الكريستال: 40 مم 2
- استهلاك الطاقة: 6 واط
سيتم الإعلان عن الأرقام الحقيقية بناءً على نتائج اختبارات العينات المصنعة في عام 2019. بالإضافة إلى خصائص الشريحة نفسها ، سيدعم المعالج ما يصل إلى 16 جيجابايت من ذاكرة الوصول العشوائي القياسية DDR4 3200MHz ، ناقل PCI Express و PLL.
تجدر الإشارة إلى أن عملية التصنيع 28 نانومتر هي أقل مجموعة منزلية لا تتطلب أذونات خاصة للاستخدام ، لذلك كان هو الذي تم اختياره. حسب عدد الخلايا ، تم النظر في خيارات مختلفة: 128 و 256 ، ولكن مع زيادة مساحة البلورة ، تزداد نسبة الرفض. لقد استقرنا على 64 خلية ، وبناءً على ذلك ، مساحة صغيرة نسبيًا ، والتي ستوفر عائدًا أكبر من البلورات المناسبة على اللوحة. مزيد من التطوير ممكن في إطار
ICS (نظام في الحالة) ، حيث سيكون من الممكن الجمع بين العديد من بلورات 64 خلية في حالة واحدة.
يجب أن يقال أن الغرض من المعالج واستخدامه يتغيران جذريًا. لن يكون S1 معالجًا دقيقًا مصممًا للتضمين ، مثلما هو الحال في P1 و R1 ، ولكن معجل للحسابات. تمامًا مثل GPGPU ، يمكن إدراج لوحة قائمة على S1 في اللوحة الأم PCI Express لجهاز كمبيوتر عادي واستخدامها لمعالجة البيانات.
العمارة
في S1 ، أصبح "multicell" الآن الوحدة الحسابية الدنيا: مجموعة من 4 خلايا تنفذ سلسلة معينة من الأوامر. في البداية ، تم التخطيط لدمج multicells في مجموعات تسمى الكتلة للتنفيذ المشترك للأوامر: يجب أن تحتوي المجموعة على 4 خلايا متعددة ، في المجموع كان هناك 4 مجموعات منفصلة على البلورة. ومع ذلك ، فإن كل خلية لديها اتصال كامل مع جميع الخلايا الأخرى في المجموعة ، ومع زيادة في مجموعة الروابط ، تصبح أكثر من اللازم ، مما يعقد إلى حد كبير التصميم الطوبوغرافي للدائرة الصغيرة ويقلل من خصائصها. لذلك ، قرروا التخلي عن الانقسام العنقودي ، لأن المضاعفات لا تبرر النتائج. بالإضافة إلى ذلك ، للحصول على أقصى أداء ، من المفيد للغاية تشغيل التعليمات البرمجية بالتوازي على كل خلية متعددة. المجموع ، والآن يحتوي المعالج على 16 multicells منفصلة.
تختلف الخلايا المتعددة ، على الرغم من أنها تتكون من 4 خلايا ، عن الخلية R1 المكونة من 4 خلايا ، والتي يكون لكل خلية ذاكرتها الخاصة بها ، وهي كتلة أوامر العينة الخاصة بها ، وهي ALU الخاصة بها. يتم ترتيب S1 بشكل مختلف قليلا. يتكون ALU من جزأين: كتلة حسابية بنقطة عائمة وكتلة حسابية عدد صحيح. تحتوي كل خلية على كتلة عدد صحيح منفصلة ، ولكن لا يوجد سوى كتلتين مع نقطة عائمة في multicell ، وبالتالي يقسمها زوجان من الخلايا بينهما. تم القيام بذلك بشكل أساسي لتقليل مساحة البلورة: يأخذ حساب الفاصلة العائمة 64 بت ، على عكس الحساب الصحيح ، مساحة كبيرة. اتضح أن وجود ALU على كل خلية لا لزوم له: لا يؤدي جلب الأوامر إلى تحميل ALU وهي خاملة. أثناء تقليل عدد كتل ALU والمحافظة على سرعة أوامر وبيانات العينة ، كما أظهرت الممارسة ، لا يتغير الوقت الإجمالي لحل المشكلات عمليًا أو يتغير قليلاً ، ويتم تحميل كتل ALU بالكامل. بالإضافة إلى ذلك ، لا يتم استخدام حساب الفاصلة العائمة كما هو الحال مع عدد صحيح.
يظهر عرض تخطيطي لكتل المعالجات R1 و S1 في الرسم البياني أدناه. هنا:
- CU (وحدة التحكم) - وحدة جلب التعليم
- ALU FX - وحدة المنطق الحسابي للحساب الصحيح
- ALU FP - وحدة المنطق الحسابي للحساب الفاصلة العائمة
- DMS (جدولة ذاكرة البيانات) - وحدة التحكم في ذاكرة البيانات
- بلدية دبي - ذاكرة البيانات
- PMS (Program Memory Scheduler) - وحدة التحكم في ذاكرة البرنامج
- PM - ذاكرة البرنامج
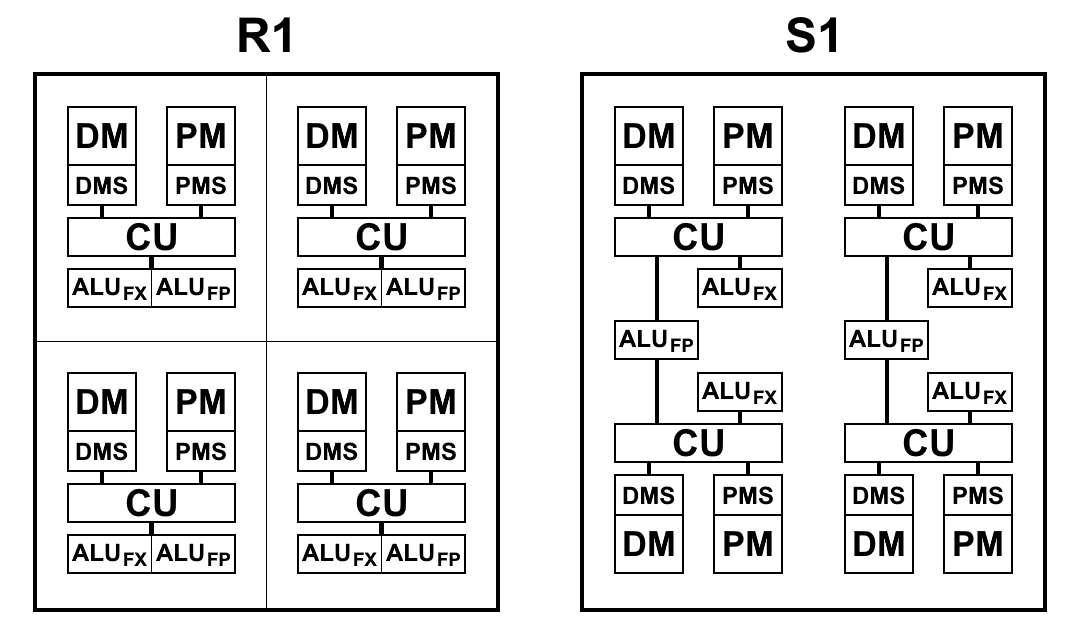
الاختلافات المعمارية S1:
- يمكن للفرق الآن الوصول إلى نتائج الفريق من الفقرات السابقة. هذا تغيير مهم للغاية يتيح لك تسريع التحولات بشكل ملحوظ عند تشفير الرمز. لم يكن أمام المعالجات P1 و R1 أي خيار سوى كتابة النتائج المرغوبة على الذاكرة وقراءتها فورًا مع الأوامر الأولى في الفقرة الجديدة. حتى عند استخدام الذاكرة على الرقاقة ، تستغرق عمليات الكتابة والقراءة من 2 إلى 5 دورات لكل منها ، والتي يمكن حفظها بمجرد الرجوع إلى نتيجة الأمر من الفقرة السابقة
- تحدث الكتابة إلى الذاكرة والسجلات الآن على الفور ، وليس في نهاية فقرة ، مما يسمح لك ببدء كتابة أوامر قبل نهاية الفقرة. نتيجة لذلك ، يتم تقليل وقت التوقف المحتمل بين الفقرات.
- تم تحسين نظام القيادة ، وهو:
- إضافة عدد صحيح من 64 بت: الجمع والطرح وضرب الأرقام 32 بت ، والتي تُرجع نتيجة 64 بت.
- تم تغيير طريقة القراءة من الذاكرة: الآن بالنسبة لأي أمر ، يمكنك ببساطة تحديد العنوان الذي تريد منه قراءة البيانات كوسيطة ، بينما يتم الحفاظ على تسلسل أوامر القراءة والكتابة.
جعلت أيضا ذاكرة منفصلة قراءة أمر عفا عليه الزمن. بدلاً من ذلك ، يتم استخدام الأمر load value في مفتاح التبديل load (سابقًا ، get ) ، مع تحديد العنوان في الذاكرة كوسيطة:
.data foo: .long 0x1234 .text habr: load_l foo ; foo load_l [foo] ; 0x1234 add_l [foo], 0xABCD ; ; complete
- تمت إضافة تنسيق أمر يتيح استخدام وسيطين ثابتين.
في السابق ، يمكنك تحديد ثابت فقط كوسيطة ثانية ، يجب أن تكون الوسيطة الأولى دائمًا رابطًا للنتيجة في المحول. ينطبق التغيير على جميع فرق الوسيطة. يكون الحقل الثابت دائمًا 32 بت ، لذلك يسمح هذا التنسيق ، على سبيل المثال ، بإنشاء ثوابت 64 بت بأمر واحد.
كان:
load_l 0x12345678 patch_q @1, 0xDEADBEEF
أصبح:
patch_q 0x12345678, 0xDEADBEEF
- أنواع بيانات ناقلات معدلة ومكملة.
إن ما كان يطلق عليه أنواع البيانات "المحزومة" يمكن الآن أن يسمى بأمان. في P1 و R1 ، استغرقت العمليات على الأرقام المعبأة ثابتًا فقط كالوسيطة الثانية ، على سبيل المثال ، عند الإضافة ، تمت إضافة كل عنصر من عناصر المتجه بنفس العدد ، ولا يمكن تطبيق هذا بذكاء. الآن ، يمكن تطبيق عمليات مماثلة على متجهين كاملين. علاوة على ذلك ، تتوافق طريقة العمل هذه مع المتجهات تمامًا مع آلية المتجهات في LLVM ، والتي تسمح الآن للمترجم بإنشاء كود باستخدام أنواع المتجهات.
patch_q 0x00010002, 0x00030004 patch_q 0x00020003, 0x00040005 mul_ps @1, @2 ; - 00020006000C0014
- أعلام المعالج إزالتها.
نتيجة لذلك ، تمت إزالة حوالي 40 فريقًا بناءً على قيم الأعلام فقط. قلل هذا بشكل كبير من عدد الفرق ، وبالتالي مساحة البلورة. ويتم الآن تخزين جميع المعلومات اللازمة مباشرة في خلية التبديل.
- عند المقارنة مع صفر ، بدلاً من علامة الصفر ، يتم الآن استخدام القيمة الموجودة في رمز التبديل فقط
- بدلاً من علامة الإشارة ، يتم الآن استخدام بعض الشيء المطابق لنوع الأمر: 7 للبايت ، 15 للاختصار ، 31 للطول ، 63 للربع. نظرًا لحقيقة أن الحرف يتضاعف حتى 63 بت ، بغض النظر عن الكتابة ، يمكنك مقارنة أرقام الأنواع المختلفة:
.data long: .long -0x1000 byte: .byte -0x10 .text habr: a := load_b [byte] ; 0xFFFFFFFFFFFFFFF0, ; byte 7 63. b := loadu_b [byte] ; 0x00000000000000F0, ; .. loadu_b c := load_l [long] ; 0xFFFFFFFFFFFFF000. ge_l @a, @c ; " " 1: ; 31 , . lt_s @a, @b ; 1, .. b complete
- لم تعد هناك حاجة إلى علامة الحمل ، حيث يوجد حساب 64 بت
- تم تقليل وقت الانتقال من فقرة إلى فقرة إلى مقياس واحد (بدلاً من 2-3 في R1)
مترجم LLVM مقرها
يشبه برنامج التحويل البرمجي للغة C لـ S1 R1 ، وبما أن البنية لم تتغير بشكل أساسي ، فإن المشاكل الموضحة في المقالة السابقة ، للأسف ، لم تختف.
ومع ذلك ، في عملية تطبيق نظام الأوامر الجديد ، انخفض مقدار رمز الإخراج في حد ذاته ، وذلك ببساطة بسبب تحديث نظام الأوامر. بالإضافة إلى ذلك ، هناك العديد من التحسينات الطفيفة التي تقلل من عدد الإرشادات الموجودة في الكود ، وبعضها تم بالفعل (على سبيل المثال ، إنشاء ثوابت 64 بت مع تعليمة واحدة). ولكن هناك تحسينات أكثر خطورة يجب القيام بها ، ويمكن بناؤها بترتيب تصاعدي لكل من كفاءة وتعقيد التنفيذ:
- القدرة على إنشاء كل الأوامر ذات الحجة اثنين مع ثوابت.
توليد ثابت 64 بت عبر patch_q هو مجرد حالة خاصة ، لكننا نحتاج إلى حالة عامة. في الواقع ، فإن الهدف من هذا التحسين هو السماح للفرق باستبدال الوسيطة الأولى باعتبارها ثابتة ، لأن الوسيطة الثانية يمكن أن تكون دائمًا ثابتة ، وقد تم تنفيذها منذ وقت طويل. هذه ليست حالة متكررة للغاية ، ولكن ، على سبيل المثال ، عندما تحتاج إلى استدعاء دالة وكتابة عنوان المرسل منها إلى أعلى المكدس ، يمكنك
load_l func wr_l @1, #SP
الأمثل ل
wr_l func, #SP
- القدرة على استبدال الوصول إلى الذاكرة من خلال وسيطة في أي أمر.
على سبيل المثال ، إذا كنت بحاجة إلى إضافة رقمين من الذاكرة ، فيمكنك ذلك
load_l [foo] load_l [bar] add_l @1, @2
الأمثل ل
add_l [foo], [bar]
هذا التحسين هو امتداد للتطبيق السابق ، ومع ذلك ، هناك حاجة بالفعل إلى التحليل هنا: لا يمكن إجراء هذا الاستبدال إلا إذا تم استخدام القيم المحملة مرة واحدة فقط في أمر الإضافة هذا وفي أي مكان آخر. إذا تم استخدام نتيجة القراءة حتى في أمرين فقط ، فمن الأفضل أن تقرأ من الذاكرة مرة واحدة كأمر منفصل ، وفي الأمرين الآخرين للإشارة إليها من خلال رمز التبديل.
- تعظيم نقل السجلات الافتراضية بين الوحدات الأساسية.
بالنسبة إلى R1 ، تم نقل جميع السجلات الافتراضية من خلال الذاكرة ، مما أدى إلى عدد كبير جدًا من القراءة والكتابة إلى الذاكرة ، ولكن ببساطة لم يكن هناك طريقة أخرى لنقل البيانات بين الفقرات. يسمح لك S1 بالوصول إلى نتائج أوامر الفقرات السابقة ، وبالتالي ، من الناحية النظرية ، يمكن إزالة العديد من عمليات الذاكرة ، مما يعطي التأثير الأكبر بين جميع عمليات التحسين. ومع ذلك ، لا يزال هذا النهج مقيدًا بالمفتاح: لا يمكن تنفيذ أكثر من 63 نتيجة سابقة ، حتى الآن يمكن إجراء مثل هذا التحويل في كل عملية نقل. كيفية القيام بذلك ليست مهمة تافهة ، ولا يزال يتعين إجراء تحليل لإمكانيات حلها. قد تظهر مصادر المترجم في المجال العام ، لذا إذا كان لدى أي شخص أفكار وتريد الانضمام إلى التطوير ، فيمكنك القيام بذلك.
المعايير
نظرًا لأنه لم يتم إصدار المعالج حتى الآن على الرقاقة ، فمن الصعب تقييم أدائه الحقيقي. ومع ذلك ، فإن كود RTL kernel جاهز بالفعل ، مما يعني أنه يمكنك إجراء تقييم باستخدام المحاكاة أو FPGA. لتشغيل المعايير التالية ، استخدمنا محاكاة باستخدام برنامج ModelSim لحساب وقت التنفيذ الدقيق (في التدابير). نظرًا لأنه من الصعب محاكاة البلورة بأكملها وتستغرق الكثير من الوقت ، لذلك ، تم محاكاة multicell واحدًا وتضاعفت النتيجة بـ 16 (إذا كانت المهمة مصممة من أجل multithreading) ، حيث يمكن لكل multicell العمل بشكل مستقل تمامًا عن الآخرين.
في الوقت نفسه ، تم إجراء النمذجة متعددة الخلايا على Xilinx Virtex-6 لاختبار أداء رمز المعالج على الأجهزة الحقيقية.
Coremark
CoreMark - مجموعة من الاختبارات لإجراء تقييم شامل لأداء ميكروكنترولر والمعالجات المركزية ، وكذلك المترجمين C. كما ترى ، فإن معالج S1 ليس واحدًا أو الآخر. ومع ذلك ، فإنه يهدف إلى تنفيذ قانون التحكيم على الإطلاق ، أي أي شخص يمكن أن تعمل على المعالج المركزي. لذا CoreMark مناسب لتقييم أداء S1 ليس أسوأ.
يحتوي CoreMark على العمل مع القوائم المرتبطة ، المصفوفات ، آلة الحالة وحساب مبلغ
CRC . بشكل عام ، يتضح أن معظم الشفرة متسلسلة بدقة (والتي تختبر
توازي الأجهزة متعددة الخلايا من أجل القوة) ومع العديد من الفروع ، وهذا هو السبب في أن قدرات المجمّع تلعب دورًا مهمًا في الأداء النهائي. تحتوي التعليمات البرمجية المترجمة على عدد قليل من الفقرات القصيرة وعلى الرغم من زيادة سرعة الانتقال بينهما ، فإن التفريع يشمل العمل مع الذاكرة ، والتي نود تجنبها إلى الحد الأقصى.
بطاقة الأداء CoreMark:
| Multiclet R1 (مترجم llvm) | Multiclet S1 (مترجم llvm) | Elbrus-4C (R500 / E) | تكساس انست AM5728 ARM Cortex-A15 | بايكال T1 | Intel Core i7 7700K |
|---|
| سنة الصنع | 2015 | 2019 | 2014 | 2018 | 2016 | 2017 |
| تردد الساعة ، ميغاهيرتز | 100 | 1600 | 700 | 1500 | 1200 | 4500 |
| النتيجة الأساسية CoreMark | 59 | 18356 | 1214 | 15789 | 13142 | 182128 |
| Coremark / ميغاهرتز | 0.59 | 11.47 | 5.05 | 10.53 | 10.95 | 40.47 |
نتيجة multicell واحد هو 1147 أو 0.72 / MHz ، وهو أعلى من R1. هذا يتحدث عن مزايا تطوير البنية متعددة الخلايا في المعالج الجديد.
ويتستون
المشحذ - مجموعة من الاختبارات لقياس أداء المعالج عند العمل بأرقام الفاصلة العائمة. الوضع هنا أفضل بكثير: الرمز أيضًا متسلسل ، لكن بدون عدد كبير من الفروع وبتزامن داخلي جيد.
يتكون المشحذ من العديد من الوحدات ، والتي تتيح لك قياس ليس فقط النتيجة الإجمالية ، ولكن أيضًا الأداء على كل وحدة نمطية محددة:
- عناصر الصفيف
- صف كمعلمة
- يقفز الشرطي
- عدد صحيح الحساب
- الدوال المثلثية (tan ، sin ، cos)
- إجراء المكالمات
- مراجع المصفوفة
- وظائف قياسية (sqrt ، exp ، سجل)
وهي مقسمة إلى فئات: الوحدات 1 و 2 و 6 تقيس أداء عمليات الفاصلة العائمة (الخطوط MFLOPS1-3) ؛ الوحدةان 5 و 8 - الوظائف الرياضية (COS MOPS ، EXP MOPS) ؛ الوحدات 4 و 7 - حساب عدد صحيح (FIXPT MOPS ، EOPAL MOPS) ؛ الوحدة 3 - يقفز الشرطي (إذا MOPS). في الجدول أدناه ، الصف الثاني من MWIPS هو مؤشر عام.
على عكس CoreMark ، سيتم مقارنة Whetstone على جوهر واحد أو ، كما هو الحال في حالتنا ، على خلية متعددة. نظرًا لأن عدد النوى مختلف تمامًا في المعالجات المختلفة ، إذن ، من أجل نقاء التجربة ، فإننا نعتبر المؤشرات لكل ميغاهيرتز.
بطاقة النتائج المشحذ:
| وحدة المعالجة المركزية | MultiClet R1 | MultiClet S1 | كور i7 4820K | ARM v8-A53 |
|---|
| التردد ، ميغاهيرتز | 100 | 1600 | 3900 | 1300 |
| MWIPS / MHz | 0.311 | 0.343 | 0.887 | 0.642 |
| MFLOPS1 / MHz | 0.157 | 0.156 | 0.341 | 0.268 |
| MFLOPS2 / MHz | 0.153 | 0.111 | 0.308 | 0.241 |
| MFLOPS3 / MHz | 0.029 | 0.124 | 0.167 | 0.239 |
| COS MOPS / MHz | 0.018 | 0.008 | 0.023 | 0.028 |
| EXP MOPS / MHz | 0.008 | 0.005 | 0.014 | 0.004 |
| FIXPT MOPS / MHz | 0.714 | 0.116 | 0.998 | 1.197 |
| إذا MOPS / MHz | 0.081 | 0.196 | 1.504 | 1.436 |
| MQUS MOPS / MHz | 0.143 | 0.149 | 0.251 | 0.439 |
يحتوي Whetstone على عمليات حسابية مباشرة أكثر بكثير من CoreMark (وهي ملحوظة للغاية عند النظر إلى الكود أدناه) ، لذلك من المهم أن نتذكر هنا: عدد وحدات ALU الفاصلة العائمة إلى النصف. ومع ذلك ، لم تتأثر سرعة الحساب تقريبًا ، بالمقارنة مع R1.
بعض الوحدات تناسب بشكل جيد للغاية على بنية متعددة الخلايا. على سبيل المثال ، تحسب الوحدة 2 الكثير من القيم في دورة ما ، وبفضل الدعم الكامل لأرقام الفاصلة العائمة مزدوجة الدقة من قبل كل من المعالج والمترجم ، بعد التجميع نحصل على فقرات كبيرة وجميلة تكشف حقًا عن القدرات الحسابية لهندسة متعددة الخلايا:
فقرة كبيرة وجميلة لـ 120 فريق pa: SR4 := loadu_q [#SP + 16] SR5 := loadu_q [#SP + 8] SR6 := loadu_l [#SP + 4] SR7 := loadu_l [#SP] setjf_l @0, @SR7 SR8 := add_l @SR6, 0x8 SR9 := add_l @SR6, 0x10 SR10 := add_l @SR6, 0x18 SR11 := loadu_q [@SR6] SR12 := loadu_q [@SR8] SR13 := loadu_q [@SR9] SR14 := loadu_q [@SR10] SR15 := add_d @SR11, @SR12 SR11 := add_d @SR15, @SR13 SR15 := sub_d @SR11, @SR14 SR11 := mul_d @SR15, @SR5 SR15 := add_d @SR12, @SR11 SR12 := sub_d @SR15, @SR13 SR15 := add_d @SR14, @SR12 SR12 := mul_d @SR15, @SR5 SR15 := sub_d @SR11, @SR12 SR16 := sub_d @SR12, @SR11 SR17 := add_d @SR11, @SR12 SR11 := add_d @SR13, @SR15 SR13 := add_d @SR14, @SR11 SR11 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR11 SR15 := add_d @SR17, @SR11 SR16 := add_d @SR14, @SR13 SR13 := div_d @SR16, @SR4 SR14 := sub_d @SR15, @SR13 SR15 := mul_d @SR14, @SR5 SR14 := add_d @SR12, @SR15 SR12 := sub_d @SR14, @SR11 SR14 := add_d @SR13, @SR12 SR12 := mul_d @SR14, @SR5 SR14 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR11, @SR14 SR11 := add_d @SR13, @SR15 SR14 := mul_d @SR11, @SR5 SR11 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR13, @SR11 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR4 := loadu_q @SR4 SR5 := loadu_q @SR5 SR6 := loadu_q @SR6 SR7 := loadu_q @SR7 SR15 := mul_d @SR13, @SR5 SR8 := loadu_q @SR8 SR9 := loadu_q @SR9 SR10 := loadu_q @SR10 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR15, @SR12 SR15 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR15 SR14 := mul_d @SR13, @SR5 SR13 := add_d @SR16, @SR14 SR15 := add_d @SR17, @SR14 SR16 := add_d @SR11, @SR13 SR11 := div_d @SR16, @SR4 SR13 := sub_d @SR15, @SR11 SR15 := mul_d @SR13, @SR5 SR13 := add_d @SR12, @SR15 SR12 := sub_d @SR13, @SR14 SR13 := add_d @SR11, @SR12 SR12 := mul_d @SR13, @SR5 SR13 := sub_d @SR15, @SR12 SR16 := sub_d @SR12, @SR15 SR17 := add_d @SR14, @SR13 SR13 := add_d @SR11, @SR17 SR14 := mul_d @SR13, @SR5 SR5 := add_d @SR16, @SR14 SR13 := add_d @SR11, @SR5 SR5 := div_d @SR13, @SR4 wr_q @SR15, @SR6 wr_q @SR12, @SR8 wr_q @SR14, @SR9 wr_q @SR5, @SR10 complete
popcnt
لعكس خصائص البنية نفسها (بغض النظر عن المترجم) ، سنقوم بقياس شيء مكتوب في المجمع مع مراعاة جميع ميزات الهندسة المعمارية. على سبيل المثال ، عدد وحدات البتات في رقم 512 بت (popcnt). للتوضيح ، سنأخذ نتائج multicell واحدة ، بحيث يمكن مقارنتها بـ R1.
جدول المقارنة ، عدد دورات الساعة لكل دورة حسابية 32 بت:
| خوارزمية | Multiclet r1 | Multiclet S1 (multicell واحد) |
|---|
| Bithacks | 5.0 | 2.625 |
تم استخدام إرشادات الموجه المحدثة الجديدة هنا ، مما سمح لنا بتخفيض عدد الإرشادات إلى النصف مقارنة بالخوارزمية نفسها المطبقة في مجمّع R1. سرعة العمل ، على التوالي ، زادت بنسبة 2 مرات تقريبا.
popcnt bithacks: b0 := patch_q 0x1, 0x1 v0 := loadu_q [v] v1 := loadu_q [v+8] v2 := loadu_q [v+16] v3 := loadu_q [v+24] v4 := loadu_q [v+32] v5 := loadu_q [v+40] v6 := loadu_q [v+48] v7 := loadu_q [v+56] b1 := patch_q 0x55555555, 0x55555555 i00 := slr_pl @v0, @b0 i01 := slr_pl @v1, @b0 i02 := slr_pl @v2, @b0 i03 := slr_pl @v3, @b0 i04 := slr_pl @v4, @b0 i05 := slr_pl @v5, @b0 i06 := slr_pl @v6, @b0 i07 := slr_pl @v7, @b0 b2 := patch_q 0x33333333, 0x33333333 i10 := and_q @i00, @b1 i11 := and_q @i01, @b1 i12 := and_q @i02, @b1 i13 := and_q @i03, @b1 i14 := and_q @i04, @b1 i15 := and_q @i05, @b1 i16 := and_q @i06, @b1 i17 := and_q @i07, @b1 b3 := patch_q 0x2, 0x2 i20 := sub_pl @v0, @i10 i21 := sub_pl @v1, @i11 i22 := sub_pl @v2, @i12 i23 := sub_pl @v3, @i13 i24 := sub_pl @v4, @i14 i25 := sub_pl @v5, @i15 i26 := sub_pl @v6, @i16 i27 := sub_pl @v7, @i17 i30 := and_q @i20, @b2 i31 := and_q @i21, @b2 i32 := and_q @i22, @b2 i33 := and_q @i23, @b2 i34 := and_q @i24, @b2 i35 := and_q @i25, @b2 i36 := and_q @i26, @b2 i37 := and_q @i27, @b2 i40 := slr_pl @i20, @b3 i41 := slr_pl @i21, @b3 i42 := slr_pl @i22, @b3 i43 := slr_pl @i23, @b3 i44 := slr_pl @i24, @b3 i45 := slr_pl @i25, @b3 i46 := slr_pl @i26, @b3 i47 := slr_pl @i27, @b3 b4 := patch_q 0x4, 0x4 i50 := and_q @i40, @b2 i51 := and_q @i41, @b2 i52 := and_q @i42, @b2 i53 := and_q @i43, @b2 i54 := and_q @i44, @b2 i55 := and_q @i45, @b2 i56 := and_q @i46, @b2 i57 := and_q @i47, @b2 i60 := add_pl @i50, @i30 i61 := add_pl @i51, @i31 i62 := add_pl @i52, @i32 i63 := add_pl @i53, @i33 i64 := add_pl @i54, @i34 i65 := add_pl @i55, @i35 i66 := add_pl @i56, @i36 i67 := add_pl @i57, @i37 b5 := patch_q 0xf0f0f0f, 0xf0f0f0f i70 := slr_pl @i60, @b4 i71 := slr_pl @i61, @b4 i72 := slr_pl @i62, @b4 i73 := slr_pl @i63, @b4 i74 := slr_pl @i64, @b4 i75 := slr_pl @i65, @b4 i76 := slr_pl @i66, @b4 i77 := slr_pl @i67, @b4 b6 := patch_q 0x1010101, 0x1010101 i80 := add_pl @i70, @i60 i81 := add_pl @i71, @i61 i82 := add_pl @i72, @i62 i83 := add_pl @i73, @i63 i84 := add_pl @i74, @i64 i85 := add_pl @i75, @i65 i86 := add_pl @i76, @i66 i87 := add_pl @i77, @i67 b7 := patch_q 0x18, 0x18 i90 := and_q @i80, @b5 i91 := and_q @i81, @b5 i92 := and_q @i82, @b5 i93 := and_q @i83, @b5 i94 := and_q @i84, @b5 i95 := and_q @i85, @b5 i96 := and_q @i86, @b5 i97 := and_q @i87, @b5 iA0 := mul_pl @i90, @b6 iA1 := mul_pl @i91, @b6 iA2 := mul_pl @i92, @b6 iA3 := mul_pl @i93, @b6 iA4 := mul_pl @i94, @b6 iA5 := mul_pl @i95, @b6 iA6 := mul_pl @i96, @b6 iA7 := mul_pl @i97, @b6 iB0 := slr_pl @iA0, @b7 iB1 := slr_pl @iA1, @b7 iB2 := slr_pl @iA2, @b7 iB3 := slr_pl @iA3, @b7 iB4 := slr_pl @iA4, @b7 iB5 := slr_pl @iA5, @b7 iB6 := slr_pl @iA6, @b7 iB7 := slr_pl @iA7, @b7 wr_q @iB0, c wr_q @iB1, c+8 wr_q @iB2, c+16 wr_q @iB3, c+24 wr_q @iB4, c+32 wr_q @iB5, c+40 wr_q @iB6, c+48 wr_q @iB7, c+56 complete
Ethereum
تعد المقاييس جيدة بالطبع ، ولكن لدينا مهمة محددة: صنع مسرّع حساب ، وسيكون من الجيد معرفة كيفية تعامله مع مهام العالم الحقيقي. العملات المشفرة الحديثة هي الأنسب لمثل هذا التحقق ، لأن خوارزميات التعدين تعمل على العديد من الأجهزة المختلفة ، وبالتالي يمكن أن تكون معيارًا للمقارنة. بدأنا مع Ethereum وخوارزمية Ethash ، التي تعمل مباشرة على جهاز التعدين.
كان اختيار Ethereum بسبب الاعتبارات التالية. كما تعلمون ، يتم تنفيذ خوارزميات مثل Bitcoin بكفاءة عالية بواسطة شرائح ASIC المتخصصة ، لذلك يصبح استخدام المعالجات أو بطاقات الفيديو لتعدين Bitcoin واستنساخه غير مواتين اقتصاديًا بسبب الأداء المنخفض واستهلاك الطاقة العالي. يقوم مجتمع عمال المناجم ، في محاولة للابتعاد عن هذا الموقف ، بتطوير عملات مشفرة على مبادئ حسابية أخرى ، مع التركيز على تطوير الخوارزميات التي تستخدم معالجات للأغراض العامة أو بطاقات الفيديو للتعدين. من المرجح أن يستمر هذا الاتجاه في المستقبل. Ethereum هي أشهر عملة مشفرة تعتمد على هذا النهج. الأداة الرئيسية للتعدين Ethereum هي بطاقات الفيديو ، والتي من حيث الكفاءة (hashrate / TDP) هي متقدمة (عدة مرات) على معالجات للأغراض العامة.
إيثاش هو ما يسمى خوارزمية
مرتبطة بالذاكرة ، أي يقتصر وقت الحساب في المقام الأول على كمية وسرعة الذاكرة ، وليس بسبب سرعة الحسابات نفسها. الآن فيما يتعلق بالتعدين في Ethereum ، تعد بطاقات الفيديو هي الأنسب ، لكن قدرتها على أداء العديد من العمليات في وقت واحد لا تساعد كثيرًا ، ولا تزال تعتمد على سرعة ذاكرة الوصول العشوائي (RAM) ، والتي يتم توضيحها بوضوح في
هذه المقالة . من هناك ، يمكنك التقاط صورة توضح تشغيل الخوارزمية لشرح سبب حدوث ذلك.
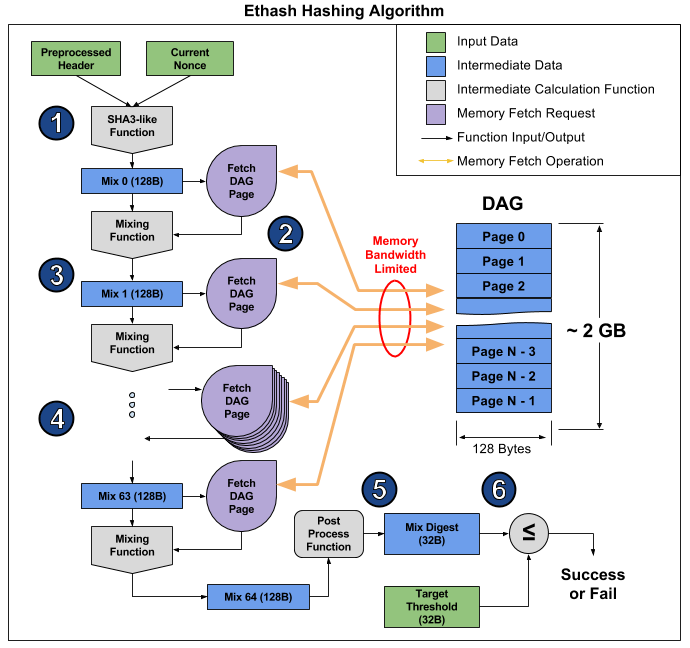
تقسم المقالة الخوارزمية إلى 6 نقاط ، ولكن يمكن تمييز 3 مراحل لمزيد من الوضوح:
- البدء: SHA-3 (512) لحساب المزيج 128 بايت الأصلي 0 (النقطة 1)
- إعادة حساب 64 صفيفًا لمزيج المزيج من خلال قراءة 128 بايت التالية وخلطها بالباقات السابقة من خلال وظيفة الخلط ، ليصبح المجموع 8 كيلو بايت (الفقرات 2-4)
- الانتهاء من والتحقق من النتيجة
قراءة عشوائية 128 بايت من ذاكرة الوصول العشوائي يستغرق وقتا أطول بكثير مما يبدو. إذا كنت تأخذ بطاقة الرسومات MSI RX 470 ، التي تحتوي على 2048 من أجهزة الحوسبة وعرض النطاق الترددي الأقصى للذاكرة يبلغ 211.2 جيجابايت / ثانية ، ثم لتجهيز كل جهاز ، تحتاج إلى 1 / (211.2 GB / (128 b * 2048)) = 1241 ns ، أو حوالي 1496 دورات على تردد معين. نظرًا لحجم وظيفة الخلط ، يمكننا أن نفترض أن قراءة الذاكرة من بطاقة الفيديو تستغرق وقتًا أطول من إعادة حساب المعلومات المستلمة. نتيجة لذلك ، تستغرق المرحلة الثانية من الخوارزمية الكثير من الوقت ، أطول بكثير من المرحلتين 1 و 3 ، والتي في النهاية لها تأثير ضئيل على الأداء ، على الرغم من احتوائها على المزيد من العمليات الحسابية (بشكل أساسي في SHA-3). يمكنك فقط إلقاء نظرة على تجزئة بطاقة الفيديو هذه: 26.375 ميجا شيش / ثانية نظريًا (محدود فقط بواسطة عرض النطاق الترددي للذاكرة) مقابل 24 ميغابايت / ثانية فعليًا ، أي أن المرحلتين 1 و 3 تستغرقان 10٪ فقط من الوقت.
على S1 ، يمكن لجميع 16 multicells العمل بالتوازي وعلى رمز مختلف. بالإضافة إلى ذلك ، سيتم تثبيت RAM مزدوجة القناة ، على طول قناة واحدة ل 8 خلايا متعددة. في المرحلة الثانية من خوارزمية إيثاش ، خطتنا هي كما يلي: تقرأ multicell 128 بايت من الذاكرة وتبدأ في إعادة حسابها ، ثم تقرأ الثانية التالية الذاكرة وتُعيد فرز الأصوات ، وهكذا حتى الثامنة ، أي يحتوي multicell واحد ، بعد قراءة 128 بايت من الذاكرة ، على 7 * [وقت قراءة 128 بايت] لإعادة حساب الصفيف. من المفترض أن تستغرق هذه القراءة 16 دورة ، أي يتم توفير 112 تدابير لإعادة فرز الأصوات. يستغرق حساب وظيفة الخلط نفس دورة الساعة ، لذا فإن S1 قريب من النسبة المثالية لعرض النطاق الترددي للذاكرة إلى أداء المعالج. نظرًا لعدم تضييع الوقت في المرحلة الثانية ، يجب تحسين الأجزاء المتبقية من الخوارزمية إلى أقصى حد ممكن ، لأنها تؤثر حقًا على الأداء.
لتقييم سرعة حساب SHA-3 (Keccak) ، تم تطوير واختبار برنامج لغة C ، على أساس أنه يتم إنشاء إصداره الأمثل في المجمّع حاليًا. توضح برمجة التقييم أن حساب multicell واحد يقوم بحساب SHA-3 (Keccak) في 1550 دورة على مدار الساعة. وبالتالي ، فإن إجمالي وقت حساب تجزئة واحدة بواحد متعدد الخلايا سيكون 1550 + 64 * (16 + 112) = 9742 دورة. مع تردد 1.6 جيجاهرتز و 16 خلية متعددة متوازية ، سيكون معدل تجزئة المعالج 2.6 MHash / s.| مسرع | MultiClet S1 | NVIDIA GeForce GTX 980 Ti | Radeon RX 470 | Radeon RX Vega 64 | NVIDIA GeForce GTX 1060 | NVIDIA GeForce GTX 1080 Ti |
|---|
| السعر | | 650 دولار | 180 دولار | 500 دولار | 300 دولار | 700 دولار |
| معدل التجزئة | 2.6 MHash / ثانية | 21.6 MHash / s | 25.8 MHash / s | 43.5 MHash / s | 25 MHash / ثانية | 55 MHash / ثانية |
| TDP | 6 واط | 250 واط | 120 واط | 295 واط | 120 واط | 250 واط |
| Hashrate / TDP | 0.43 | 0.09 | 0.22 | 0.15 | 0.22 | 0.21 |
| تكنولوجيا العملية | 28 نانومتر | 28 نانومتر | 14 نانومتر | 14 نانومتر | 16 نانومتر | 16 نانومتر |
عند استخدام MultiClet S1 كأداة تعدين ، يمكن بالفعل تثبيت 20 معالجًا أو أكثر على اللوحات. في هذه الحالة ، فإن تجزئة لوحة من هذا القبيل ستكون مساوية أو أعلى من هاشرات بطاقات الفيديو الحالية ، في حين أن استهلاك الطاقة للوحة مع S1 سيكون نصف ، حتى من بطاقات الفيديو مع المعايير الطبوغرافية 16 و 14 نانومتر.في الختام ، لا بد لي من القول إن المهمة الرئيسية الآن هي تصنيع لوحة متعددة المعالجات لعمال المناجم المشفرة متعددة الخلايا والعامل الحوسبة الفائقة. من المخطط تحقيق القدرة التنافسية نظرًا لاستهلاك الطاقة الصغيرة وهندستها ، وهو مناسب تمامًا للحوسبة التعسفية.لا يزال المعالج قيد التطوير ، ولكن يمكنك بالفعل بدء البرمجة في المجمّع ، وكذلك تقييم الإصدار الحالي من المحول البرمجي. يوجد بالفعل حد أدنى من أدوات تطوير البرامج (SDK) يحتوي على المجمّع والرابط والمترجم والطراز الوظيفي ، والتي يمكنك من خلالها بدء تشغيل البرامج واختبارها.