
ذات مرة ، عندما كانت السماء زرقاء ، كان العشب أكثر خضرة وتجولت الديناصورات على الأرض ... لا ، انسوا الديناصورات. حسنًا ، بشكل عام ، كانت الفكرة تتبادر إلى الذهن لتشتت الانتباه عن برمجة الويب القياسية والقيام بشيء أكثر جنونًا. بالطبع ، يمكن أن يكون أي شيء ، لكن الخيار وقع على كتابة مترجمك الخاص. ماذا يمكنني أن أقول ...
لا تكتب أبدًا لغات البرمجة الخاصة بك . لكنني اكتسبت بعض الخبرة من كل هذا ، لذلك قررت أن أشاركه. دعنا نبدأ مع الأساس - lexer.
مقدمة
قبل أن تبدأ في فهم نوع "lexer" الحيواني ، من الجدير معرفة ما تصنعه YaPs.
في العالم الحديث ، يتم تقسيم كل مترجم / مترجم / مترجم / شيء ما-مثله (دعنا ، سأطلق عليه ببساطة "مترجم" إضافي ، دون تمييز بين الأنواع) إلى قسمين. في مصطلحات الأعمام الذكية ، تسمى هذه القطع "الواجهة الأمامية" و "الواجهة الخلفية". لا ، هذا ليس على الإطلاق ما ، عند العمل مع الويب ، ما اعتدنا على الاتصال به ولم تتم كتابة الواجهة في JS باستخدام HTML. على الرغم من ... حسنا.
تتمثل مهمة الواجهة الأولى في أخذ
النص وتحويله إلى
AST (شجرة بناء جملة مجردة) ، والتحقق من بناء الجملة (وأحيانًا دلالات) في الطريق. مهمة الواجهة الخلفية الثانية هي جعل كل شيء يعمل. إذا تم تجميع الشفرة داخل المترجم الفوري ، فإن AST تنشئ مجموعة من الإرشادات للمعالج الظاهري (الجهاز الظاهري) ، إذا كان المترجم ، ثم مجموعة الإرشادات للمعالج الحقيقي. في الحياة ، كل شيء أكثر تعقيدًا وقد لا يتم تنفيذه على هذا النحو. على سبيل المثال ، في حالة برنامج التحويل البرمجي لدول مجلس التعاون الخليجي ، يتم خلط كل شيء ، لكن Clang أصبح بالفعل أكثر نشاطًا ، LLVM هو ممثل نموذجي لـ "الواجهة الخلفية" للمترجمين.
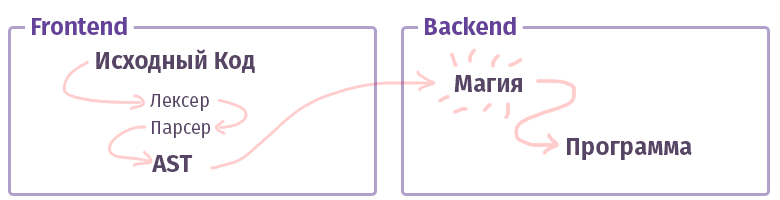
الآن دعونا نتعرف على قطعة تسمى الواجهة الأمامية.
تحليل معجمي
مهمة lexer ومرحلة التحليل المعجمية هي الحصول على العديد من الرسائل عند المدخل وتجميعها في بعض الفئات - "الرموز". لذلك ، فإن التحليل المعجمى يسمى أيضا "رمزية". هذه هي المرحلة الأولى من معالجة النصوص التي ينتجها كل مترجم موجود.
شيء مثل هذا:
$tokens = ['class', '\w+', '}', '{']; var_dump(lex('class Example {}', $tokens));
بالمناسبة ، لقد كتبنا هنا بالفعل مجموعة من الأدوات لجعل الحياة أسهل. نفس وظائف
preg التي اعتدنا استخدامها في تحليل النص
قادرة تمامًا
على هذه المهمة. ومع ذلك ، هناك أدوات أكثر ملاءمة لهذه المسألة:
- فيلكسي ، من تأليف نيكيتا بوبوف.
- هوا مجموعة أدوات تتكون من Lexer + Parser + Grammar.
- Port Yacc ، كتبه أنتوني فيرارا ، وهو أيضًا مجموعة أدوات معقدة ، والذي كتب عليه محلل Popov PHP المعروف ، والذي ينطبق على الأدوات التي تستخدم تحليل الكود.
- Railt Lexer تطبيقي لـ PHP 7.1+
- Parle هو امتداد لـ PHP يسمح بمجموعة محدودة من تعبيرات PCRE (بدون واجهة استخدام وبعض بنيات بناء الجملة الأخرى).
- وأخيرًا ، وظيفة php القياسية token_get_all ، والتي تهدف مباشرةً إلى التحليل المعجمي لـ PHP.
حسنًا ، من الواضح أن هناك الكثير من الأدوات التي يمكن أن تقسم النص على الرموز ، وربما نسيت حتى شيئًا ما ، مثل قاموس
المذهب . لكن ماذا بعد؟
أنواع Lexers
وكما هو الحال دائمًا ، ليس كل شيء بهذه البساطة. هناك ما لا يقل عن فئتين مختلفتين من lexers. هناك الخيار المعتاد ، تافه للغاية ، والذي يمكنك من خلاله التخلي عن القواعد ، وهو يقسم بالفعل كل شيء إلى رموز. لا يختلف تكوينها كثيرًا عن المثال الموضح أعلاه. ومع ذلك ، هناك خيار آخر يسمى
multistate . من الصعب فهم مثل هؤلاء المفجرين قليلاً ، لذلك ، أريد التحدث معهم أكثر قليلاً.
مهمة lexer متعدد المراحل هي عرض الرموز المميزة المختلفة بناءً على الحالة السابقة. حسنًا ، على سبيل المثال ، في PHP ، يتم تشكيل مثل هذه الحالات "الانتقالية" باستخدام العلامات <؟ Php +؟> والخطوط الداخلية والتعليقات
وبنيات HEREDOC /
NOWDOC .
تذكر المثال السابق مع 4 الرموز أعلاه؟ لنعدله قليلاً لفهم ماهية هذه الحالات:
class Example {
في هذه الحالة ، إذا كان لدينا أبسط lexer دون إمكانات PCRE الواسعة ، فسنحصل على مجموعة الرموز التالية:
var_dump(lex(...));
كما ترون ، حصلنا على عضاضة عادية تمامًا على العناصر 3-5: لقد تم اتخاذ التعليق بشكل غير متوقع تمامًا وتم تقسيمه إلى رموز ، على الرغم من أنه كان ينبغي اعتباره قطعة كاملة.
بطبيعة الحال ، مع PCRE الوظيفية ، يمكن هدم هذا الرمز المميز بمساعدة انتظام بسيط "
// [^ \ n] * \ n " ، ولكن إذا لم يكن كذلك؟ حسنًا ، أم أننا نريد أن ندفعها بأيدينا؟ باختصار ، في حالة أداة lexer متعددة الولايات - يمكننا أن نقول أن جميع الرموز يجب أن تكون في المجموعة رقم 1 ، بمجرد العثور على الرمز "
// " ، ثم يجب أن يحدث الانتقال إلى المجموعة
رقم 2 . وداخل المجموعة الثانية ، الانتقال العكسي ، إذا تم العثور على الرمز المميز "
\ n " - الانتقال إلى المجموعة الأولى.
شيء مثل هذا:
$tokens = [ 'group-1' => [ 'class', '\w+', '{', '}', '//' => 'group-2'
أعتقد الآن أن الأمر أصبح أكثر وضوحًا كيف يتم تحليل بعض HEREDOC ، لأنه حتى مع كل قوة PCRE ، فإن كتابة نص منتظم لهذه الحالة يمثل مشكلة كبيرة للغاية ، بالنظر إلى أن بناء جملة HEREDOC يدعم الاستيفاء المتغير. ما عليك
سوى محاولة تحليل شيء مثل هذا باستخدام الدالة
token_get_all المضمنة (ملاحظة> 12 رمزًا مميزًا):
<?php $example = 42; $a = <<<EOL Your answer is $example !!! EOL; var_dump(token_get_all(file_get_contents(__FILE__)));
حسنًا ، يبدو أننا مستعدون لبدء التدريب.
الممارسة
دعونا نتذكر ما لدينا في PHP لمثل هذه الأشياء؟ حسنا ، بالطبع ، preg_match! حسنًا ، هبط. يتم تنفيذ الخوارزمية المستندة إلى preg_match في
هوا وفي
هذا التنفيذ من Phelxy . مهمتها بسيطة جدا:
- لدينا في متناول اليد النص المصدر ومجموعة من النظامي.
- نطابق حتى يتم العثور على شيء مناسب.
- بمجرد العثور على قطعة ما ، قم بقصها وتطابقها أكثر.
في نموذج الشفرة ، سيبدو مثل هذا:
ورقة رمز <?php class SimpleLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[$name] = \sprintf('/\G%s/isSum', $definition); } } public function lex(string $sources): iterable { [$offset, $length] = [0, \strlen($sources)]; while ($offset < $length) { [$name, $token] = $this->next($sources, $offset); yield $name => $token; $offset += \strlen($token); } } private function next(string $sources, int $offset): array { foreach ($this->tokens as $name => $pcre) { \preg_match($pcre, $sources, $matches, 0, $offset); $token = \reset($matches); if (\count($matches) && \strpos($sources, $token, $offset) === $offset) { return [$name, $token]; } } throw new \RuntimeException('Unrecognized token at offset ' . $offset); } }
باستخدام ورقة رمز $lexer = new SimpleLexer([ 'T_CLASS' => 'class', 'T_CONST' => '\w+', 'T_BRACE_OPEN' => '{', 'T_BRACE_CLOSE' => '}', 'T_WHITESPACE' => '\s+', ]); echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n"; foreach ($lexer->lex('class Example {}') as $name => $token) { echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n"; }
هذا النهج تافه للغاية ويسمح لبضع دفعات لوحة المفاتيح بتعديل lexer في المنطقة من الطريقة التالية () ، إضافة الانتقال بين الدول وتحويل هذا التقسيم من الاستمناء إلى lexer بدائية متعددة المراحل. في منطقة
$ this-> tokens ، فقط أضف شيئًا مثل
$ this-> tokens [$ this-> state] .
ومع ذلك ، بالإضافة إلى البدائية نفسها ، هناك عيب آخر ، ليس قاتلاً كما قد يحدث ، ولكن لا يزال ... مثل هذا التنفيذ بطيء بشكل لا يصدق. على i7 7600k ، التي صادفت أن صاحبها - خوارزمية مماثلة تعالج حوالي 400 رمز في الثانية الواحدة ، ومع زيادة أشكالها (أي التعاريف التي نقلناها إلى المنشئ) - يمكن أن تبطئ سرعة تغيير الرؤساء في روسيا ... مهم اسف أردت أن أقول ، بالطبع ، إنها ستعمل
ببطء شديد .
حسنا ، ماذا يمكننا أن نفعل؟ بالنسبة للمبتدئين ، يمكنك فهم ما يحدث. الحقيقة هي أنه في كل مرة نسميها
preg_match داخل براري اللغة ، يرتفع مترجم مع JIT الخاص به يسمى PCRE (ومع PHP 7.3 ، يكون PCRE2 بالفعل). في كل مرة يقوم بتوزيع المواد النظامية بأنفسهم ويجمع محللًا خاصًا بهم ، حيث نقوم بتحليل النص لإنشاء الرموز. يبدو غريبا بعض الشيء وتوتولوجية. ولكن باختصار ، يتطلب كل رمز تجميع من 1 إلى N النظامي ، حيث N هو عدد تعريفات هذه الرموز المميزة. في الوقت نفسه ، تجدر الإشارة إلى أنه حتى علامة "
S " المطبقة والتحسين باستخدام "
\ G " في المنشئ ، حيث يتم إنشاء التعبيرات العادية للرموز ، لا تساعد.
لا يوجد سوى طريقة واحدة للخروج من هذا الموقف - تحتاج إلى تحليل كل هذا النص في مسار واحد ، أي عن طريق تنفيذ وظيفة واحدة فقط
preg_match . يبقى لحل مشكلتين:
- كيف تشير إلى أن نتيجة التعبير العادي N1 تتوافق مع الرمز المميز N2؟ أي كيف تشير إلى أن " \ w + " ، على سبيل المثال ، هو T_CONST .
- كيفية تحديد تسلسل الرموز نتيجة لذلك. كما تعلمون ، ستحتوي نتيجة preg_match أو preg_match_all على كل شيء مختلط. وحتى بمساعدة الأعلام التي تم تمريرها كحجة رابعة ، فإن الوضع لن يتغير.
هنا يمكنك التوقف والتفكير قليلا. حسنا ام لا.
حل المشكلة الأولى
يدعى مجموعات PCRE ، والتي تسمى أيضًا "المهام". باستخدام القواعد: "
(؟ <T_WHITESPACE> \ s + | <T_WORD> \ w + | ...) " يمكنك الحصول على جميع الرموز المميزة في
مسار واحد من خلال مقارنتها بأسمائها. كنتيجة للمطابقة ، سيتم تشكيل مجموعة
نقابية ، تتكون من الأزواج "
[TOKEN_NAME => TOKEN_VALUE] ".
والثاني هو أكثر تعقيدا قليلا. ولكن هنا يمكنك تطبيق خدعة تكتيكية واستخدام وظيفة
preg_replace_callback . خصوصيتها هي أن المجهول الذي تم تمريره كحجة ثانية سيتم استدعاؤه بالتتابع الدقيق لكل رمز ، من الأول إلى الأخير.
من أجل عدم التعرض - التنفيذ على النحو التالي:
رفرف آخر من التعليمات البرمجية class PregReplaceLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition); } } public function lex(string $sources): iterable { $result = []; \preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) { foreach (\array_reverse($matches) as $name => $value) { if (\is_string($name) && $value !== '') { $result[] = [$name, $value]; break; } } }, $sources); foreach ($result as [$name, $value]) { yield $name => $value; } } private function compilePcre(): string { return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens)); } }
واستخدامه لا يختلف عن الإصدار السابق. في الوقت نفسه ، تزداد سرعة العمل من
400 إلى
57000 رمز في الثانية. هذه هي الخوارزمية التي طبقتها
في عملي ، مع إعادة كتابة الكود المصدري هوا. بالمناسبة ، إذا كنت تستخدم Parle ، فيمكنك ضغط ما يصل إلى
600000 رمز في الثانية. وتبدو الصورة العامة مثل هذا (مع تشغيل XDebug في PHP 7.1 ، وبالتالي فإن الأرقام أقل ، ولكن يمكن تمثيل النسبة تقريبًا).
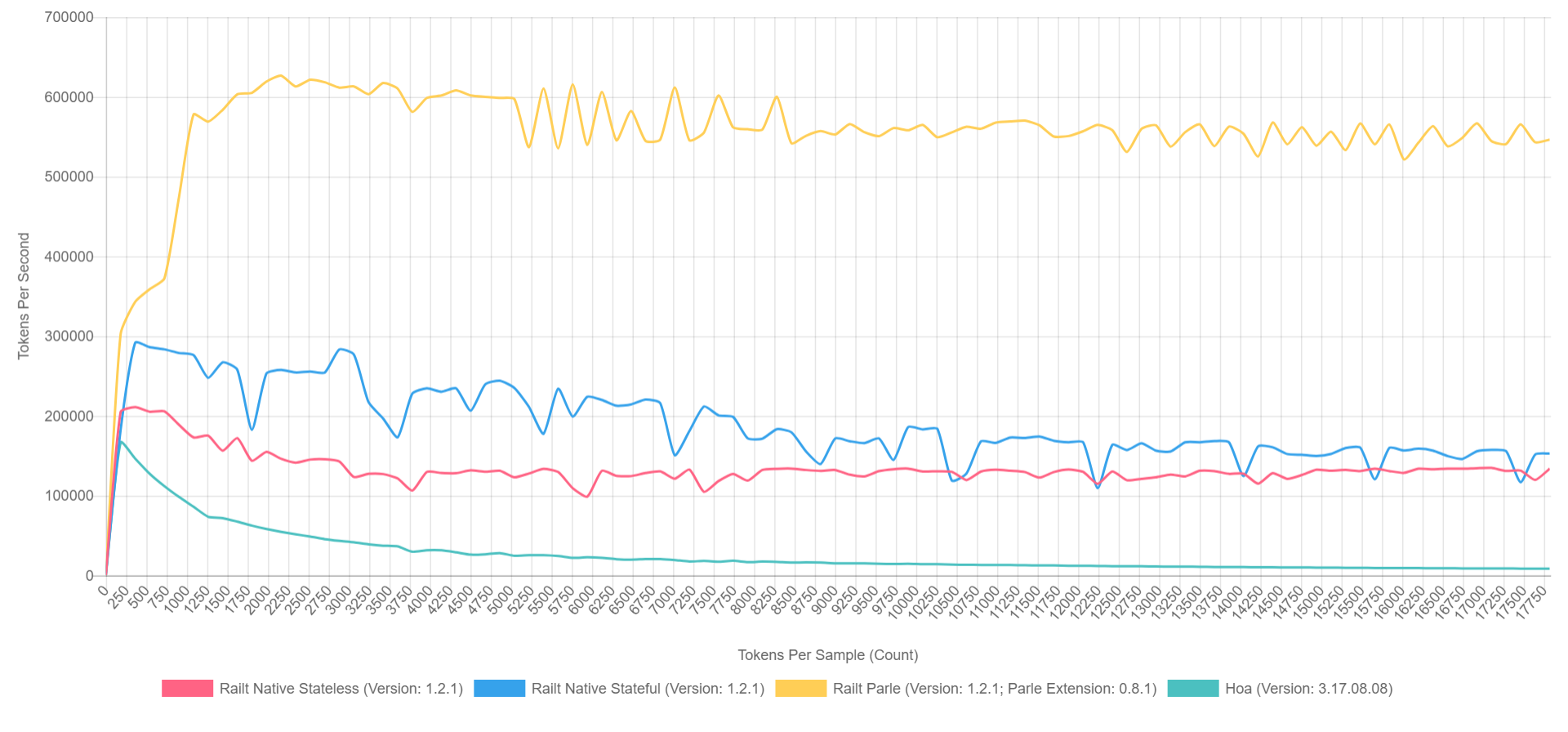
- الأصفر هو الامتداد الأصلي لبارلي.
- الأزرق - التنفيذ من خلال preg_replace_callback مع التجميع المسبق العادي.
- أحمر - كل ذلك ، ولكن مع انتظام تم إنشاؤه أثناء المكالمة إلى preg_replace_callback .
- الأخضر - التنفيذ من خلال preg_match .
لماذا؟
حسنًا ، كل هذا ، بالطبع ، شيء رائع ، لكن الصبر الذين يتوقون إلى طرح الأسئلة: "من يحتاج إلى هذا على الإطلاق؟" في العالم المجرد لـ PHP ، حيث يهيمن مبدأ "التين والتين والموقع جاهزين" - ليست هناك حاجة إلى مثل هذه المكتبات ، سنكون صادقين. ولكن إذا تحدثنا عن النظام الإيكولوجي ككل ، فيمكننا أن نتذكر المكتبات سيئة السمعة مثل
symfony / yaml أو
Doctrine . التعليقات التوضيحية في Symfony هي نفس اللغة الفرعية داخل PHP ، وتتطلب تحليل لغوي منفصل ونحوي منفصل. بالإضافة إلى ذلك ، يوجد عدد أقل قليلاً من مستشعرات القهوة ، و Less ، و Scss / Sass المعروفة في PHP. حسنا ، أو
ياي والمعالجة المسبقة على أساس ذلك. لن أذكر أدوات تحليل الكود مثل phpmd أو phpcs. ومولدات الوثائق مثل phpDocumentnor أو Sami تافهة للغاية. يستخدم كل مشروع من هذه المشروعات بدرجة أو بأخرى التحليل المعجمي في المرحلة الأولى من تحليل النص / الكود.
هذه ليست قائمة كاملة بالمشاريع ، وربما آمل أن تساعدك قصتي في اكتشاف شيء جديد وتجديده.
خاتمة
إذا نظرنا إلى المستقبل ، إذا كان هناك أي شخص مهتم بموضوع المحللون والمترجمين ، فهناك بعض التقارير المثيرة للاهتمام حول هذا الموضوع ، لا سيما من اللاعبين من JetBrains:
لا يزال ، بالطبع ، معظم عروض Andrei Breslav (
abreslav ) ، والتي يمكن العثور عليها على مساحة YouTube
الواسعة - أنصحك بمشاهدتها.
حسنًا ، بالنسبة لمحبي الخيال ،
هناك مورد كان مفيدًا للغاية بالنسبة لي.
نشر آخر النص. إذا كنت مختومًا في مكان ما في اتساع هذه الملحمة ، فيمكنك إبلاغ المؤلف بأمان بأي شكل مناسب لك.
على سبيل المكافأة ، أود أن أقدم
مثالًا على لغة PHP بسيطة ، يبدو أنها ليست مخيفة جدًا الآن ، والآن أصبح من الواضح ما الذي تفعله ، أليس كذلك؟ على الرغم من الذي أخدعه ، فإن العينين تنزفان من النظامي. =)
شكرا لك