مرحبا أنا ديما ، وأنا جالس في بيثون لبعض الوقت الآن. اليوم أريد أن أوضح لك الاختلافات بين إطارين غير متزامنين - تورنادو وأيوتاهت. سأحكي قصة الاختيار بين الأُطُر في مشروعنا ، ومدى اختلاف الخطوط الأساسية في تورنادو و AsyncIO ، وسوف أعرض معايير وأقدم بعض النصائح المفيدة حول كيفية الوصول إلى بروز الأطر والخروج منها بنجاح.

كما تعلمون ، Avito هي خدمة إعلانية كبيرة إلى حد ما. لدينا الكثير من البيانات والتحميل ، 35 مليون مستخدم شهريًا و 45 مليون إعلان نشط يوميًا. أنا أعمل مستشارًا تقنيًا لمجموعة تطوير التوصيات. يكتب فريقي خدمات ميكروية ، لدينا الآن حوالي عشرين منهم. حمولة تتراكم على كل هذا - مثل 5K RPS.
اختيار إطار غير متزامن
أولاً ، سوف أخبرك كيف انتهى بنا الأمر إلى ما نحن عليه الآن. في عام 2015 ، كنا بحاجة إلى اختيار إطار غير متزامن ، لأننا كنا نعرف:
- أن عليك تقديم الكثير من الطلبات إلى خدمات microservices الأخرى: http، json، rpc؛
- ستحتاج إلى جمع البيانات من مصادر مختلفة طوال الوقت: Redis و Postgres و MongoDB.
وبالتالي ، لدينا الكثير من مهام الشبكة ، ويشغل التطبيق أساسًا المدخلات / المخرجات. الإصدار الحالي من الثعبان في ذلك الوقت كان 3.4 ، غير متزامن وينتظر لم يظهر بعد. كان Aiohttp أيضًا - في الإصدار 0.x. ظهر فيسبوك غير متزامن تورنادو في عام 2010. تتم كتابة الكثير من برامج تشغيل قاعدة البيانات التي نحتاجها له. وأظهر اعصار نتائج مستقرة على المعايير. ثم توقفنا عن اختيارنا في هذا الإطار.
بعد ثلاث سنوات ، فهمنا الكثير.
أولاً ، خرج Python 3.5 بميكانيكا غير متزامن / في انتظار. لقد توصلنا إلى معرفة الفرق بين الغلة والعائد منها وكيف يتوافق تورنيدو مع الانتظار (المفسد: ليس جيدًا جدًا).
ثانياً ، واجهنا مشاكل غريبة في الأداء مع وجود كمية كبيرة من coroutine في برنامج الجدولة ، حتى عندما لا تكون وحدة المعالجة المركزية مشغولة تمامًا.
ثالثًا ، وجدنا أنه عند إجراء عدد كبير من طلبات http إلى خدمات Tornado الأخرى ، يجب أن تكون صديقًا بشكل خاص مع محلل نظام أسماء النطاقات غير المتزامن ، فهو لا يحترم مهلات إنشاء اتصال وإرسال الطلب الذي نحدده. وبشكل عام ، فإن أفضل طريقة لتقديم طلبات http في Tornado هي حليقة ، وهو أمر غريب في حد ذاته.
في
حديثه في PyCon Russia 2018 ، قال أندريه سفيتلوف: "إذا كنت تريد أن تكتب نوعًا من تطبيق الويب غير المتزامن ، فالرجاء كتابة التزامن فقط ، في انتظار. حلقة الحدث ، على الأرجح ، لن تحتاجها على الإطلاق قريبًا. لا تدخل في برية الأطر حتى لا تتشوش. لا تستخدم البدائل المنخفضة المستوى ، وسيكون كل شيء على ما يرام معك ... ". على مدار السنوات الثلاث الماضية ، لسوء الحظ ، اضطررنا إلى الصعود إلى داخل تورنادو في كثير من الأحيان ، وتعلم الكثير من الأشياء المثيرة للاهتمام من هناك ومشاهدة تراكساكس عملاقة من 30 إلى 40 مكالمة.
العائد مقابل العائد من
أحد أكبر المشكلات التي يجب فهمها في الثعبان غير المتزامن هو الفرق بين العائد من العائد.
كتب غيدو فان روسوم المزيد حول هذا الموضوع. أرفق الترجمة مع اختصارات بسيطة.
لقد سُئلت عدة مرات عن سبب إصرار PEP 3156 على استخدام العائد من العائد بدلاً من العائد ، والذي يستبعد إمكانية backporting في Python 3.2 أو حتى 2.7.
(...)
كلما كنت تريد نتيجة في المستقبل ، يمكنك استخدام العائد.
يتم تنفيذ هذا على النحو التالي. الوظيفة التي تحتوي على العائد هي (من الواضح) مولد ، لذلك يجب أن يكون هناك نوع من الكود التكراري. دعنا ندعوه مخطط. في الواقع ، لا "المجدول" "تكرار" بالمعنى الكلاسيكي (مع for-loop)؛ بدلاً من ذلك ، يدعم مجموعتين في المستقبل.
سأدعو المجموعة الأولى تسلسل "قابل للتنفيذ". هذا هو المستقبل ، ونتائجها متاحة. على الرغم من أن هذه القائمة ليست فارغة ، فإن المجدول يختار عنصرًا واحدًا ويأخذ خطوة التكرار. تستدعي هذه الخطوة طريقة منشئ .send () مع النتيجة من المستقبل (والتي قد تكون بيانات تمت قراءتها للتو من مأخذ التوصيل) ؛ في المولد ، تظهر هذه النتيجة كقيمة لإرجاع تعبير العائد. عندما تقوم send () بإرجاع نتيجة أو اكتمالها ، يقوم المجدول بتوزيع النتيجة (والتي قد تكون StopIteration أو استثناء آخر أو نوع من الكائنات).
(إذا كنت مرتبكًا ، فيجب أن تقرأ على الأرجح عن كيفية عمل المولدات ، على وجه الخصوص ، طريقة .send (). ربما تعد PEP 342 نقطة انطلاق جيدة).
(...)
تتكون المجموعة المستقبلية الثانية التي يدعمها المجدول من المستقبل ، والتي ما زالت تنتظر الإدخال / الإخراج. يتم تمريرها بطريقة أو بأخرى إلى select / poll / shell إلخ. الذي يعطي رد اتصال عندما يكون واصف الملف جاهزًا للإدخال / الإخراج. يقوم رد الاتصال فعليًا بعملية الإدخال / الإخراج المطلوبة في المستقبل ، وتعيين القيمة المستقبلية الناتجة إلى نتيجة عملية الإدخال / الإخراج ، وينقل المستقبل إلى قائمة انتظار التنفيذ.
(...)
الآن وصلنا إلى الأكثر إثارة للاهتمام. افترض أنك تكتب بروتوكولًا معقدًا. داخل البروتوكول ، تقرأ وحدات البايت من مأخذ التوصيل باستخدام طريقة recv (). هذه البايتات الوصول إلى المخزن المؤقت. يتم التفاف أسلوب recv () في غلاف غير متزامن ، والذي يقوم بتعيين I / O وإرجاع المستقبل ، والذي يتم تنفيذه عند اكتمال I / O ، كما هو موضح أعلاه. لنفترض الآن أن جزءًا آخر من التعليمات البرمجية يريد قراءة البيانات من سطر واحد في المرة الواحدة. افترض أنك استخدمت طريقة readline (). إذا كان حجم المخزن المؤقت أكبر من متوسط طول الخط ، يمكن لطريقة readline () الخاصة بك ببساطة الحصول على السطر التالي من المخزن المؤقت دون حظر ؛ ولكن في بعض الأحيان لا يحتوي المخزن المؤقت على خط كامل ، و readline () بدوره يستدعي recv () على المقبس.
السؤال: هل يجب أن تقرأ readline () المستقبل أم لا؟ لن يكون جيدًا جدًا إذا قام أحيانًا بإرجاع سلسلة بايت ، وفي بعض الأحيان في المستقبل ، مما اضطر المتصل إلى إجراء فحص النوع والعائد الشرطي. إذن الجواب هو أن readline () يجب أن يعود دائمًا إلى المستقبل. عندما يتم استدعاء readline () ، فإنه يتحقق من المخزن المؤقت ، وإذا عثر على سطر كامل على الأقل هناك ، فإنه ينشئ مستقبلًا ، ويحدد النتيجة المستقبلية لخط مأخوذ من المخزن المؤقت ، ويعود إلى المستقبل. إذا لم يكن للمخزن المؤقت سطر كامل ، فإنه يبدأ الإدخال / الإخراج ويتوقعه ، وعند اكتمال الإدخال / الإخراج ، يبدأ من جديد.
(...)
لكننا الآن نقوم بإنشاء العديد من المستقبلات التي لا تتطلب حظر إدخال / إخراج ، ولكن لا يزال يتعين فرض دعوة إلى المجدول ، لأن readline () يُرجع المستقبل ، العائد مطلوب من المتصل ، وهذا يعني استدعاء المجدول.
يمكن لجدولة نقل التحكم مباشرة إلى coroutine إذا رأى أن المستقبل ، الذي اكتمل بالفعل ، معروض ، أو يمكن أن يعيد المستقبل إلى قائمة انتظار التنفيذ. سوف يعمل هذا الأخير على إبطاء العمل إلى حد كبير (شريطة أن يكون هناك أكثر من coroutine قابل للتنفيذ) ، لأنه ليس من الضروري الانتظار فقط في نهاية قائمة الانتظار ، ولكن من المحتمل أيضًا فقدان مكان الذاكرة (إن وجد على الإطلاق).
(...)
التأثير الصافي لكل هذا هو أن المؤلفين الكوريين يحتاجون إلى معرفة مستقبل الغلة ، وبالتالي هناك حاجز نفسي أكبر لإعادة تنظيم الكود المعقد إلى كوروتينات أكثر قابلية للقراءة - أقوى بكثير من المقاومة الحالية ، لأن استدعاءات الوظائف في بيثون بطيئة للغاية. وأتذكر من محادثة مع Glyph أن السرعة مهمة في بنية I / O غير متزامنة نموذجية.
الآن دعنا نقارن هذا بالعائد من.
(...)
ربما تكون قد سمعت أن "العائد من S" مكافئ تقريبًا لـ "for i in S: yield i". في أبسط الحالات ، هذا صحيح ، لكن هذا لا يكفي لفهم coroutine. ضع في اعتبارك ما يلي (لا تفكر في الإدخال / الإخراج غير المتزامن حتى الآن):
def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
يطبع هذا الرمز سطرين يحتويان على "okay" و "42" (ثم ينتج عن StopIteration غير معالج ، والذي يمكنك قمعته بإضافة المحصول في نهاية gen1). يمكنك رؤية هذا الكود في العمل على pythontutor.com على الرابط .
الآن النظر في ما يلي:
def gen2(): yield from gen1() driver(gen2())
وهي تعمل بنفس الطريقة بالضبط . الآن فكر. كيف يعمل؟ لا يمكن هنا استخدام ملحق العائد البسيط في الحلقة for-loop ، نظرًا لأن الكود في هذه الحالة سيعود بلا. (جربه) . العائد من أعمال بمثابة "قناة شفافة" بين السائق و gen1. أي عندما يعطي gen1 القيمة "بخير" ، فإنه يخرج gen2 ، من خلال العائد من ، إلى السائق ، وعندما يرسل السائق 42 مرة أخرى إلى gen2 ، يتم إرجاع هذه القيمة من خلال العائد من العائد إلى gen1 مرة أخرى (حيث تصبح نتيجة العائد )
سيحدث نفس الشيء إذا ألقى السائق خطأ في المولد: ينتقل الخطأ إلى العائد من المولد الداخلي الذي يعالجه. على سبيل المثال:
def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
سيعطي الرمز "okay" و "bah" ، وكذلك الكود التالي:
def gen2(): yield from gen1()
(انظر هنا: goo.gl/8tnjk )
أود الآن تقديم رسومات بسيطة (ASCII) حتى أتمكن من التحدث عن هذا النوع من الشفرات. يمكنني استخدام [f1 -> f2 -> ... -> fN) لتمثيل المكدس مع f1 في الجزء السفلي (أقدم إطار للمكالمات) و fN في الأعلى (أحدث إطار للمكالمات) ، حيث يكون كل عنصر في القائمة عبارة عن مولد ، و -> ناتج عن . المثال الأول ، لا يحتوي برنامج التشغيل (gen1 ()) على العائد من ، ولكن يحتوي على مولد gen1 ، لذلك يبدو كما يلي:
[ gen1 )
في المثال الثاني ، يستدعي gen2 gen1 باستخدام العائد من ، لذلك يبدو كما يلي:
[ gen2 -> gen1 )
أستخدم الترميز الرياضي للفاصل الزمني نصف المفتوح [...) لإظهار أنه يمكن إضافة إطار آخر إلى اليمين عندما يستخدم المولد الموجود في أقصى اليمين العائد من لاستدعاء مولد آخر ، في حين أن الطرف الأيسر ثابت إلى حد ما. النهاية اليسرى هي ما يراه السائق (على سبيل المثال ، المجدول).
أنا الآن جاهز للعودة إلى المثال readline (). يمكننا إعادة كتابة readline () كمولد يستدعي read () ، مولد آخر يستخدم العائد من ؛ هذا الأخير ، بدوره ، يستدعي recv () ، والذي يقوم بإجراء الإدخال / الإخراج الفعلي من المقبس. على اليسار لدينا هو التطبيق ، الذي نعتبره أيضًا مولدًا يستدعي readline () ، مرة أخرى باستخدام العائد من. المخطط كما يلي:
[ app -> readline -> read -> recv )
الآن يقوم مولد recv () بتعيين الإدخال / الإخراج ، ويربطه بالمستقبل ، ويمرره إلى المجدول باستخدام * yield * (وليس العائد من!). المستقبل يذهب إلى اليسار على طول كلا العائد من الأسهم في المجدول (الموجود على يسار "["). لاحظ أن المجدول لا يعرف أنه يحتوي على مجموعة من المولدات ؛ كل ما يعرفه هو أنه يحتوي على مولد أقصى اليسار وأنه أصدر للتو مستقبلاً. عند اكتمال الإدخال / الإخراج ، يعين المجدول النتيجة المستقبلية ويرسلها مرة أخرى إلى المولد ؛ تنتقل النتيجة إلى اليمين على طول كلا السهمين yiled - من مولد recv ، الذي يستقبل البايتات التي يريد قراءتها من المقبس كنتيجة للإنتاج.
بمعنى آخر ، يعالج برنامج جدولة العائد من إطار عمليات الإدخال / الإخراج تمامًا مثل جدولة إطار العمل المستند إلى العائد التي وصفتها سابقًا. * لكن: * لا يحتاج للقلق بشأن التحسين عندما يتم تنفيذ المستقبل بالفعل ، حيث لا يشارك المجدول في نقل السيطرة بين readline () و read () أو بين read () و recv () ، والعكس بالعكس. لذلك ، لا يشارك برنامج الجدولة على الإطلاق عندما يستدعي التطبيق () مكالمات readline () ، ويمكن أن يقرأ readline () الطلب من المخزن المؤقت (بدون استدعاء read ()) - تتم معالجة التفاعل بين التطبيق () و readline () في هذه الحالة بالكامل بواسطة مترجم bytecode بيثون يمكن أن يكون المجدول أكثر بساطة ، ويكون عدد المستقبل الذي يتم إنشاؤه وإدارته بواسطة المجدول أقل ، لأنه لا توجد مستقبليات يتم إنشاؤها وتدميرها مع كل مكالمة من coroutine. المستقبل الوحيد الذي لا تزال هناك حاجة إليه هو تلك التي تمثل الإدخال / الإخراج الفعلي ، على سبيل المثال ، تم إنشاؤه بواسطة recv ().
إذا كنت قد قرأت هذه النقطة ، فأنت تستحق مكافأة. لقد حذفت العديد من تفاصيل التنفيذ ، لكن الرسم التوضيحي أعلاه يعكس الصورة بشكل صحيح.
شيء آخر أود أن أشير إليه. * يمكنك * جعل جزءًا من الكود يستخدم العائد من ، والجزء الآخر يستخدم العائد. لكن العائد يتطلب أن يكون لكل رابط في السلسلة مستقبل ، وليس فقط coroutine. نظرًا لوجود العديد من المزايا لاستخدام العائد من ، أريد أن لا يضطر المستخدم إلى تذكر وقت استخدام العائد ، وعندما يكون العائد من الأسهل دائمًا استخدام العائد من. يتيح الحل البسيط حتى لـ recv () استخدام العائد من تمرير الإدخال / الإخراج المستقبلي إلى المجدول: طريقة __iter__ هي في الواقع المولد الذي يصدره المستقبل.
(...)
وأكثر شيء واحد. ما قيمة العائد من العائد؟ اتضح أن هذه هي القيمة المرجعة للمولد * الخارجي *.
(...)
وبالتالي ، بينما تربط الأسهم بين الإطارات اليمنى واليسرى للهدف * ذات العائد * ، فإنها أيضًا تمرر قيم الإرجاع المعتادة بالطريقة المعتادة ، إطار مكدس واحد في المرة الواحدة. يتم نقل الاستثناءات بنفس الطريقة ؛ بالطبع ، في كل مستوى ، جرب / باستثناء ما هو مطلوب للقبض عليهم.
يتحول العائد من هو نفسه إلى حد كبير في انتظار.
العائد من vs المتزامن
def coro () ^ ذ = العائد من | async def async_coro (): ص = انتظر |
| 0 load_global | 0 load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4 load_const | 4 load_const |
| 6 العائد | 6 العائد |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const
|
| 12 return_value | 12 return_value |
لا يوجد اختلاف كبير في الفرق بين المدرستين القديمتين والجددتين - احصل على العائد من iter مقابل الحصول على الانتظار.
لماذا هذا كله؟ يستخدم تورنادو غلة بسيطة. قبل الإصدار 5 ، فإنه يربط سلسلة كاملة من المكالمات من خلال العائد ، وهو ما يتوافق بشكل سيء مع العائد الرائع الجديد من / تنتظر النموذج.
أبسط معيار غير متزامن
من الصعب إيجاد إطار جيد حقًا ، باختياره فقط وفقًا للاختبارات الاصطناعية. في الحياة الحقيقية ، يمكن أن يحدث الكثير من الأشياء.
أخذت Aiohttp الإصدار 3.4.4 ، و Tornado 5.1.1 ، و uvloop 0.11 ، وأخذت معالج خادم Intel Xeon ، و CPU E5 v4 ، و 3.6 GHz ، وبدأت مع Python 3.6.5 التحقق من خوادم الويب من أجل التنافسية.
المشكلة النموذجية التي نحلها بمساعدة خدمات microservices ، والتي تعمل في وضع غير متزامن ، تبدو هكذا. سوف نتلقى الطلبات. لكل منهم ، سنقدم طلبًا واحدًا لبعض الخدمات الميكروية ، ونحصل على البيانات من هناك ، ثم نذهب إلى اثنين أو ثلاثة من الخدمات الصغيرة الأخرى ، بشكل غير متزامن أيضًا ، ثم نكتب البيانات في مكان ما إلى قاعدة البيانات ونعيد النتيجة. اتضح العديد من النقاط حيث سننتظر.
نقوم بتنفيذ عملية أبسط. ندير الخادم ونجعله ينام 50 مللي ثانية. إنشاء coroutine واستكماله. لن يكون لدينا RPS كبير جدًا (قد لا يكون ترتيبًا مشابهًا لما هو موضح في معايير تركيبية كاملة) بتأخير مقبول بسبب حقيقة أن الكثير من coroutine سوف يدور بشكل متزامن في خادم تنافسي.
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME)
تحميل - الحصول على طلبات HTTP. المدة - 300 ثانية ، 1 ثانية - الإحماء ، 5 تكرار للحمل.
 النتائج على النسب المئوية لوقت استجابة الخدمة.
النتائج على النسب المئوية لوقت استجابة الخدمة.ما هي النسب المئوية؟لديك عدد كبير من الأرقام. تعني النسبة المئوية 95 للنسبة X أن 95٪ من القيم في هذه العينة أقل من X. مع احتمال 5٪ ، سيكون رقمك أكبر من X.
نرى أن Aiohttp قام بعمل جيد في 1000 RPS في مثل هذا الاختبار البسيط. كل ذلك حتى الآن دون
uvloop .
قارن بين تورنادو و coroutines في المدارس القديمة (الغلة) والمدارس الجديدة (غير المتزامنة). يوصي المؤلفون بشدة باستخدام المتزامن. يمكننا التأكد من أنها أسرع بكثير بالفعل.
في 1200 RPS ، بدأت Tornado ، حتى مع مجموعة المدارس الجديدة ، بالتنازل بالفعل ، وتم تفجير Tornado مع coroutines المدرسة القديمة تمامًا. إذا كنا ننام لمدة 50 مللي ثانية ، وكانت microservice مسؤولة عن 80 مللي ثانية - هذا لا يدخل في أي بوابة على الإطلاق.
لقد استسلمت مدرسة تورنادو الجديدة ، التي تبلغ مساحتها 1500 روبية ، تمامًا ، بينما لا تزال Aiohttp بعيدة عن الحد الأقصى البالغ 3000 RPS. الأكثر إثارة للاهتمام لم يأت بعد.
Pyflame ، التنميط microservice العمل
دعونا نرى ما يحدث في هذه اللحظة مع المعالج.

عندما اكتشفنا كيف تعمل خدمات بيثون غير المتزامنة في الإنتاج ، حاولنا أن نفهم ما تصطدم به جميعها. في معظم الحالات ، كانت المشكلة في وحدة المعالجة المركزية أو مع الواصفات. هناك أداة إنشاء ملفات تعريف رائعة تم إنشاؤها في Uber ، Profiler
Pyflame ، والتي تستند إلى استدعاء نظام ptrace.
نبدأ بعض الخدمات في الحاوية ونبدأ في رمي عبء قتالي عليها. في كثير من الأحيان ، هذه ليست مهمة تافهة للغاية - لإنشاء مثل هذا العبء الموجود في المعركة ، لأنه غالبًا ما يحدث أن تقوم بإجراء اختبارات تركيبية على اختبار الحمل ، والشكل ، وكل شيء يعمل بشكل جيد. أنت تدفع عبء القتال عليه ، وهنا تبدأ الخدمة الميكروية في التخفيف.
أثناء العملية ، يقوم هذا المحلل بتقديم لقطات من مكدس الاستدعاءات بالنسبة لنا. لا يمكنك تغيير الخدمة على الإطلاق ، فقط قم بتشغيل pyflame في مكان قريب. سيقوم بتجميع تتبع مكدس مرة واحدة في فترة زمنية معينة ، ثم يقوم بتصور رائع. يعطي هذا الملف التعريفي مقدارًا ضئيلًا جدًا من النفقات العامة ، لا سيما عند مقارنته بـ cProfile. Pyflame يدعم أيضا برامج متعددة مؤشرات الترابط. لقد أطلقنا هذا الشيء مباشرةً في المنتج ، ولم يقل الأداء كثيرًا.
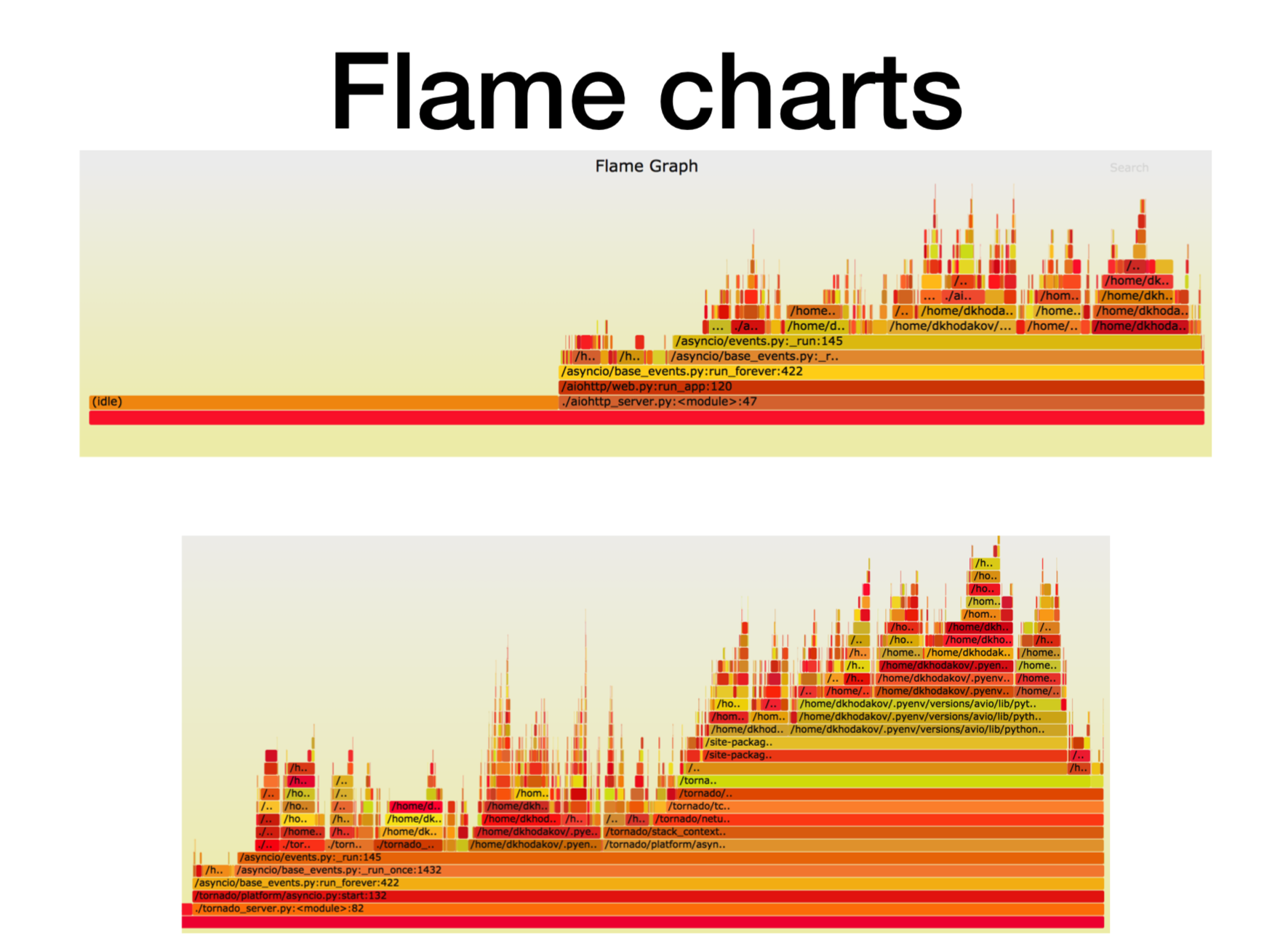
هنا ، محور X هو مقدار الوقت ، وعدد المكالمات ، عندما كان إطار المكدس في قائمة جميع إطارات مكدس Python. هذا هو المقدار التقريبي لوقت المعالج الذي قضيناه في هذا الإطار المحدد للمكدس.
كما ترون ، هنا معظم الوقت في aiohttp يذهب إلى الخمول. حسنًا: هذا هو ما نريده من خدمة غير متزامنة بحيث تتعامل مع مكالمات الشبكة معظم الوقت. عمق المكدس في هذه الحالة هو حوالي 15 لقطة.
في Tornado (الصورة الثانية) مع نفس الحمل ، يتم قضاء وقت أقل بكثير على الخمول وعمق المكدس في هذه الحالة حوالي 30 لقطة.
هنا
رابط ل svg ، يمكنك تحريف نفسك.
معيار غير متزامن أكثر تعقيدًا
async def work():
توقع وقت تشغيل 125 مللي ثانية.

اعصار مع uvloop يحمل أفضل. لكن Aiohttp uvloop يساعد أكثر من ذلك بكثير. يبدأ Aiohttp في التصرف بشكل سيء على 2300-2400 RPS ، ومع uvloop يوسع نطاق الحمل بشكل كبير. سطر واحد للاستيراد ، والآن لديك خدمة أكثر إنتاجية.
ملخص
سألخص ما أردت أن أنقل إليكم اليوم.
- أولاً ، لقد أطلقت معيارًا مصطنعًا معينًا ، حيث كان هناك قدر لا بأس به من coroutine الطويل. في اختبارنا ، كان أداء Aiohttp أفضل مرتين ونصف من Tornado.
- الحقيقة الثانية. Uvloop بشكل جيد للغاية يساعد على تحسين أداء Aiohttp (أفضل من تورنادو).
- لقد أخبرتك عن Pyflame ، والتي غالبًا ما نعرض عليها التطبيق مباشرة في الإنتاج.
- وتحدثنا أيضًا عن العائد من (في انتظار) مقابل العائد.
كنتيجة لهذه المعايير ، انتقل فريق توصياتنا (وبعض التوصيات الأخرى) تقريبًا بالكامل إلى Aiohttp مع Tornado لتقديم خدمات ميكروية في Python قيد الإنتاج.
- بالنسبة للخدمات القتالية ، انخفض استهلاك وحدة المعالجة المركزية بأكثر من مرتين.
- بدأنا نحترم مهلات طلبات HTTP.
- انخفضت خدمات الكمون 2 إلى 5 مرات.
هنا
رابط إلى المعيار . إذا كانت مهتمة ، يمكنك تكرار ذلك. شكرا لكم جميعا على اهتمامكم. طرح الأسئلة ، سأحاول الإجابة عليها.