النظر في التنبؤ سلسلة زمنية. دعنا نحاول التنبؤ بعروض الأسعار أو أي شيء آخر مفيد.
لنأخذ كأساس للتنبؤ الوارد في المقالة
نموذج التنبؤ بالسلسلة الزمنية لعينة التشابه القصوى: التوضيح والمثال (هذه المقالة ليست لي). تتمثل النقطة المختصرة في أن الجزء الأكثر تشابهًا من الرسم البياني يتم السعي إلى يسار التنبؤ به بين التاريخ الماضي ، ومن الأفضل ، يتم أخذ القيم إلى يمين الرسم البياني واستخدامها كتوقع.
سأذهب أبعد من ذلك. عند حساب التوقعات ، لن أتناول حالة واحدة هي الأفضل في العلاقة ، ولكن حزمة من الأفضل. وستكون التوقعات هي متوسط نتائج هذه الحزمة. هذا سيجعل من الممكن أن نفهم أن القيمة الموجودة هي انتظام ، وليست صدفة عرضية مع التوقعات المرغوبة ، أو انحراف عشوائي إذا انحرفت التوقعات عن القيمة الفعلية.
استخدام الخيار الأفضل الفردي كما في هذه المقالة غير صحيح ، وكذلك تحديد توزيع الاحتمال بقيمة واحدة من هذا التوزيع. إذا قمت بإنشاء رسم بياني كبير جدًا للبيانات العشوائية وشرعت في البحث عنها ، فستكون هناك بالتأكيد شرائح مترابطة فيها ، وربما حتى مع معامل 0.9999 ، لكن ليس من الضروري على الإطلاق أن تستمر الشرائح المماثلة في متابعة هذه الشرائح - لا يزال كل شيء عشوائي. ونحن بحاجة إلى أخذ حزمة فقط من هذه الأجزاء وحساب أن تباين البيانات اللاحقة أقل من التباين الذي يتم تشكيله من عينة عشوائية من هذه البيانات. وإذا كان تشتت الحزمة أقل - فهذا هو التوقع. على الرغم من أن هذا لا يمثل أيضًا تمثيلًا دقيقًا للأخطاء المحتملة ، إلا أن هذا يكفي الآن.
أي
التنبؤ ليس
هو مبدأ أخذ العينات والارتباط بين الأجزاء المقارنة التي نستخدمها ، والشيء الرئيسي هو أنه نتيجة لتطبيق هذه العينة ، سيكون تباين القيم المطلوبة أقل من نتيجة أخذ العينات العشوائية.
كذلك ، فإن تباين هذه الحزمة سيمكن من تقييم الخيار الأفضل لاستخدام خيار التحديد من الحالات السابقة. بعد كل شيء ، من الممكن تحديد ليس قطاعًا واحدًا من البيانات المرتبطة دائمًا ، وليس دائمًا استخدام ارتباط بيرسون. ويمكن إجراء مثل هذا الاختيار لكل نقطة متوقعة بشكل منفصل. بالنسبة لأي نوع من العينات يكون التباين أقل ، يكون هذا الخيار أفضل للنقطة الحالية.
ما حجم حزمة يجب أن يكون؟ هذا يعتمد على مسألة فواصل الثقة. حتى لا يتم التحميل كثيرًا ، هناك إشارة إلى أنه من الأفضل أخذ 30 مثالًا على الأقل لتحديد متوسط القيمة. إذا كان هناك فائض في بيانات الاختبار ، فسأخذ 100 على الأقل.
يمكن تسمية نسبة الانحرافات المعيارية للعينة وفقًا للخوارزمية والعشوائية بالمعامل النظري لنجاح خوارزمية التنبؤ للنقطة الحالية لأغراض المقارنة مع خوارزميات أخذ العينات الأخرى ، أو لتحديد مدى فائدة هذه التوقعات بشكل عام ، في حين أن القيمة الفعلية ليست متاحة بعد.
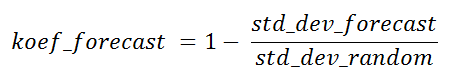
قد يأخذ هذا المعامل في بعض الحالات قيمًا سلبية. النقاط التي يحدث فيها هذا هي ذات أهمية ضئيلة ، وكذلك النقاط ذات معامل الصفر. في حالة القدرة على التنبؤ بنسبة 100 ٪ ، سيكون مساويا لواحد.
دعنا ننتقل إلى الأمثلة العملية ، مرة أخرى من هذه المادة. بعد تصحيح الأخطاء الصغيرة هناك ، نحصل على النتيجة التالية ، بما يتوافق مع تلك المادة وهذه الخوارزمية:
حساب التوقعات في وقت 9/1/2012 23:00 موقف 52631
إجمالي القيم التحقق من التشابه 2184
أفضل ارتباط 0.958174 موقف 52295
معاملات النقل alpha (1/2) 1.03117 -11.1992
خطأ في التنبؤ من حقيقة mape 5.210 ٪mape - المصطلح من المقال الأصلي Mean Error Percentage Error ، يتم حسابه بواسطة الصيغة
القيمة المطلقة (توقعات - حقيقة) / حقيقةوالآن دعنا نختار مجموعة من أفضل أوجه التشابه ، ولكن حزم الأفضل وأفضل ما يمكن التنبؤ به للحظة واحدة في الوقت المناسب ونرى ما سيحدث:
0 corr 0.958174 pos 52295 mape 5.210٪
1 corr 0.953571 pos 52151 mape 6.566٪
2 corr 0.953532 pos 45599 mape 11.642٪
3 corr 0.951462 pos 45743 mape 7.033٪
4 corr 0.950921 pos 45575 mape 3.300٪
5 corr 0.950789 pos 38687 mape 3.538٪
تتغير قيمة الارتباط هنا من قيمة إلى قيمة لا تذكر. في الوقت نفسه ، تتراوح قيمة النتيجة المتوقعة من 3٪ إلى 11٪. أي أن 5 ٪ الأولي ليس أكثر من مجرد صدفة ، يمكن أن يكون 11 ٪ و 3 ٪.
تحت شروط التشابه المحددة في هذه المقالة ، يمكن مقارنة 2184 القيم في المجموع. من هذه ، أخذت حزمة من الأفضل في 1500 قطعة ، مرتبة حسب تناقص الارتباط ، وعرضتها في رسم بياني. انخفض الارتباط في هذه الحزمة من أفضل 0.958 إلى 0.715 من اليسار إلى اليمين. لكن تقلب النتيجة عمليا لم يتغير:

يمكن أن نرى أن اعتماد النتيجة على الارتباط منخفض للغاية ، لكن يبدو أنه مع ذلك. بشكل عام ، نأخذ حزمة من أفضل 100 قيمة ونحسب التوقعات ، كما ذكرت ، بمتوسط هذه الحزمة. والنتيجة هي كما يلي:
mape 5.824٪ ، stddev mape 7.035٪ . ولكن هذا لم يعد 5.8٪ من قبيل الصدفة ، ولكن متوسط التوزيع - على الأرجح التوقعات. الانحراف المعياري لل mape أكبر من mape نفسه ، ولكن هذا بسبب وجود توزيع غير متماثل لل mape.
حسبت أيضًا نفس التوقعات ، لكن باستخدام عينة عشوائية مشروطة ، وبشكل أدق ، تم حساب متوسط من كل الخيارات الممكنة ، كانت نتيجة
mape هي 8.246٪ . عن طريق أخذ العينات العشوائية ، يكون الخطأ أكبر قليلاً ، لكن هذه القيمة لا تزال في نطاق الانتثار المحسوب من أفضل عينة. بالنسبة للنقطة المحسوبة ، فإن معامل التنبؤ النظري الذي أشير إليه يقترب من الصفر ، وبشكل أكثر دقة
koef_forecast = -0.041 . لم أحسبها من mapdev mape (تتضمن التوقعات الفعلية) ، ولكن من القيم المطلقة للتنبؤ ، إذا نظرت إلى البرنامج ، يتم إعطاء الأرقام الأولية لذلك هناك.
ولكن هذا هو الحال فيما يتعلق بالطابع الزمني ، والذي تم ذكره في المقال الأصلي. ولكن إذا أخذنا القول "9/4/2012 23:00" (شهر / يوم / سنة) ، فإن معامل الكفاءة النظري هو
koef_forecast = 0.21 ، و
mape = 3.126٪ ، mape_rand = 7.147٪ . أي أظهر koef_forecast مقدمًا أنه سيتم احتساب النقطة الحالية بشكل أكثر دقة من النقطة السابقة. إن جوهر فائدة هذا المعامل هو أنه يمكنك على الأقل تقييم النتيجة بطريقة ما على الأقل حتى قبل الحصول على البيانات الفعلية ، لأن البيانات الفعلية لا تشارك في ذلك. كلما كان ذلك أفضل. لقد ذكرت بالفعل أن النقطة المتوقعة تمامًا سيكون لها معامل واحد.
يمكنك أن ترى بنفسك كيف تتغير كل هذه الأرقام في برنامجي التوضيحي على Qt C ++ ، حيث يمكنك اختيار تاريخ وحجم الحزمة:
المصادر على جيثبيتم اختيار أفضل القيم وفقًا للخوارزمية التالية:
inline void OrdPack::add_value(double koef, int i_pos) { if (std::isfinite(koef)==false) return; if (koef <= 0.0) return; if (mmap_ord.size() < ma_count_for_pack) { if (mmap_ord.size()==0) mi_koef = koef; mi_koef = std::min(mi_koef, koef); mmap_ord.insert({-koef,i_pos}); } else if (koef > mi_koef) { mmap_ord.insert({-koef,i_pos}); while (mmap_ord.size() > ma_count_for_pack) mmap_ord.erase(--mmap_ord.end()); mi_koef = -(--mmap_ord.end())->first; } }
ليس هناك فائدة من نشر المصدر بأكمله هنا ، إنه ليس معقدًا هناك ، ومع التعليقات. الأساس في الإجراء MainWindow :: to_do_test () في ملف
mainwindow.cpp .
في الوقت الحالي ، سأواصل محاولة التنبؤ بشيء ما في الجزء التالي.
PS. يرجى ترك تعليقاتكم حول ما إذا كان كل شيء واضحًا بشأن ما هو مفقود. لقد قمت بالفعل بتكوين خطة تقريبية لما سأكتبه بعد ذلك ، لكن مع تعليقاتك سأفعل ذلك بشكل أفضل.