في مقال سابق من St. Petersburg HSE ، أظهرنا كيف يمكن للتعلم الآلي أن يبحث عن الأخطاء في رمز البرنامج. في هذا المنشور ، سنتحدث عن الطريقة التي نحاول بها ، مع JetBrains Research ، استخدام أحد أكثر أقسام التعلم الآلي إثارة للاهتمام والحديثة والمتنامية بسرعة - تعلم التعزيز - في كل من المشاكل العملية الحقيقية وفي الأمثلة النموذجية.

عن نفسي
اسمي نيكيتا سزانوفيتش. حتى يونيو 2018 ، درست في SPbAU لمدة ثلاث سنوات ، وبعد ذلك ، مع زملائي الآخرين في الصف ، انتقلت إلى HSE سان بطرسبرج ، حيث أنا الآن على الانتهاء من دراستي الجامعية. في الآونة الأخيرة ، أعمل أيضًا باحثًا في JetBrains Research. قبل دخول الجامعة ، كنت مولعا بالبرمجة الرياضية ولعبت مع المنتخب الوطني في بيلاروسيا.
التدريب التعزيز
تعلم التعزيز هو فرع للتعلم الآلي حيث يتلقى العامل ، الذي يتفاعل مع البيئة ، التعزيزات (ومن ثم الاسم) في شكل مكافأة إيجابية أو سلبية. بناءً على هذه المطالبات ، يغير الوكيل سلوكه. الهدف النهائي من هذه العملية هو الحصول على أكبر مكافأة ممكنة ، أو بطريقة أخرى ، لتحقيق الإجراءات التي حددها الوكيل.
وكلاء تعمل على الظروف واختيار الإجراءات. على سبيل المثال ، في مشكلة الخروج من المتاهة ، ستكون ولايتنا هي إحداثيات x و y ، وستكون الإجراءات أعلى / أسفل / يسار / يمين. المخطط العام يشبه هذا:
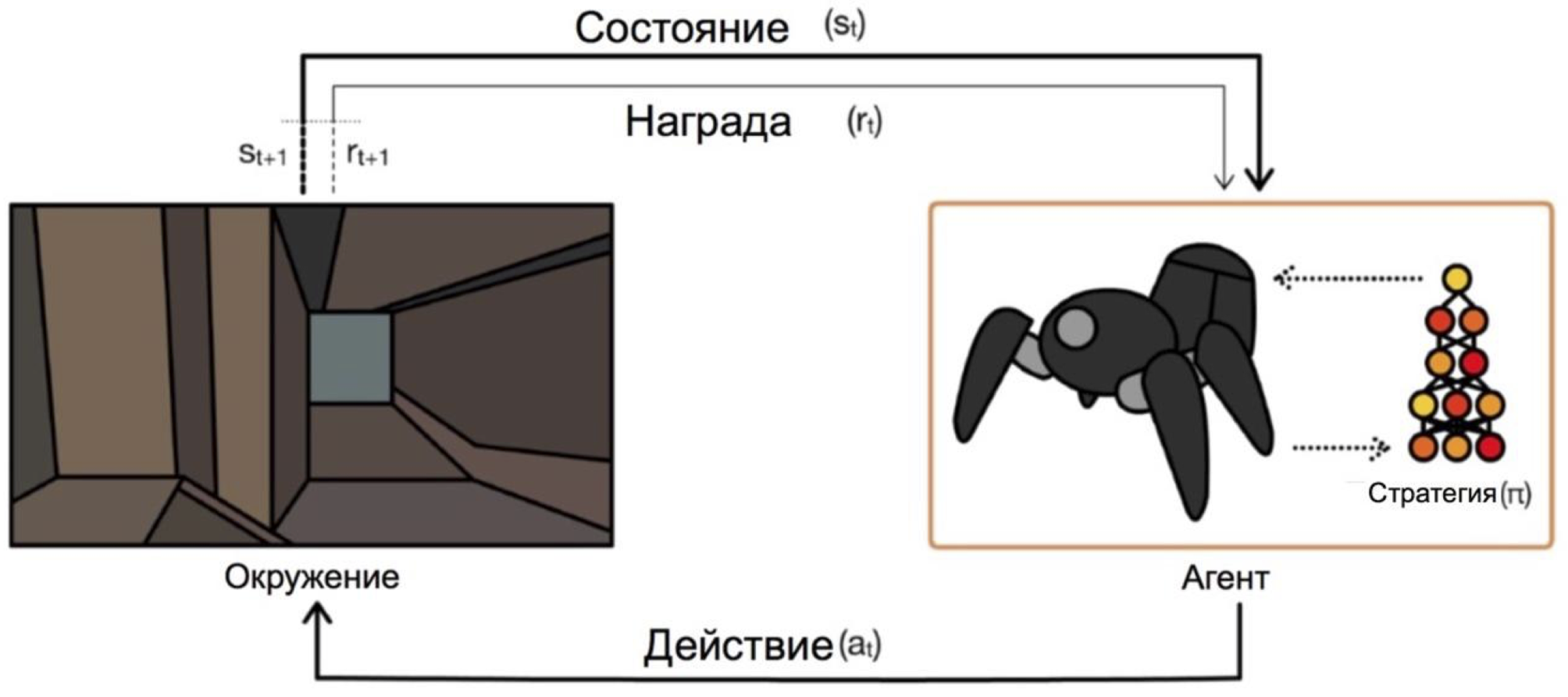
المشكلة الرئيسية في الانتقال من المهام الخيالية / البسيطة (مثل نفس المتاهة) إلى المهام الحقيقية / العملية هي: المكافآت في مثل هذه المشاكل عادة ما تكون نادرة للغاية. إذا أردنا أن يقوم وكيل ، على سبيل المثال ، بتسليم البيتزا على خريطة المدينة ، فسوف يفهم أنه قام بعمل جيد ، فقط من خلال تسليم الطلب إلى الباب ، وهذا لن يحدث إلا إذا اتبعت سلسلة طويلة وصحيحة من الإجراءات.
يمكن حل هذه المشكلة عن طريق إعطاء الوكيل في البداية أمثلة حول كيفية "اللعب" - ما يسمى بمظاهرات الخبراء.
مهمة للتعلم
المشكلة النموذجية التي سيتم مناقشتها في المقالة هي Dota 2.
Dota 2 هي لعبة موبا الشعبية التي فيها فريق من خمسة أبطال يجب أن يهزم فريق معارضة بتدمير "القلعة". تعتبر Dota 2 لعبة معقدة إلى حد ما ، فهي تمتلك رياضات مع جوائز في البطولة الرئيسية بمبلغ 25000000 دولار .
يمكنك أن تسمع عن النجاحات الأخيرة التي حققتها OpenAI في Dota 2. أولاً ، ابتكروا روبوتًا فرديًا وهزموا لاعبين محترفين ، ثم تحولوا إلى لعبة 5 × 5 وأظهروا نتائج رائعة هذا الصيف ، على الرغم من أنهم خسروا أمام فرق محترفة.

المشكلة الوحيدة هي أنهم قاموا بتدريب الوكيل على لعبة فردية ، وفقًا لما ذكروه ، على 60.000 وحدة المعالجة المركزية و 256 K80 وحدة معالجة الرسومات على سحابة أزور. لديهم ، بالطبع ، الفرصة لطلب الكثير من القوة. ولكن إذا كان لديك طاقة أقل ، فعليك استخدام الحيل. واحدة من هذه الحيل هي استخدام الألعاب التي يلعبها الناس بالفعل.
العروض التوضيحية في اللعبة
في معظم الحالات ، يتم تسجيل العروض التوضيحية بشكل مصطنع: يمكنك إكمال مهمة / لعب لعبة وتجميع الإجراءات التي اتخذتها بطريقة أو بأخرى. لذلك تقوم بجمع بعض البيانات التي يمكن تضمينها في التدريب بطرق مختلفة. لقد فعلت ذلك حتى الآن ، ولكن كيف بالضبط - سيكون واضحًا بعد الجزء الخاص بمخطط التفاعل مع عميل اللعبة.
الهدف الأكبر والأكثر مغامرة هو الحصول على المزيد من البيانات من الوصول المفتوح. أحد الأسباب التي أدت إلى اختيار Dota 2 لتسريع عملية التعلم كانت موردًا مثل dotabuff . يتم جمع إحصائيات مختلفة عن اللعبة ، ولكن الأهم من ذلك ، هناك إعادة كاملة للألعاب. ويمكن فرزها حسب التصنيف.
لم أحاول حتى الآن كيف ستساعد غيغابايت من هذه البيانات بشكل كبير مقارنة بالعديد من الحلقات. كان تحقيق مجموعة البيانات بسيطًا جدًا: يمكنك الحصول على روابط لألعاب dotabuff وتنزيل الألعاب واستخدام محلل ألعاب Dota 2 .
حزمة مع ألعاب العميل للتدريب
لدينا لعبة Dota 2 يوجد عميل لها ضمن أنظمة Windows و Linux و macOS. ومع ذلك ، عادة ما يتم التدريب في نوع من أنواع الثعبان ، وفيه يمكنك إنشاء بيئة ، سواء أكانت متاهة ، أو جهازًا يتسلق التل أو شيء من هذا القبيل. ولكن لا توجد بيئة لدوتا 2. لذلك ، أنا نفسي اضطررت لإنشاء هذا المجمع ، الذي كان مثيرا للاهتمام من الناحية الفنية. اتضح أن تفعل ذلك مثل هذا:
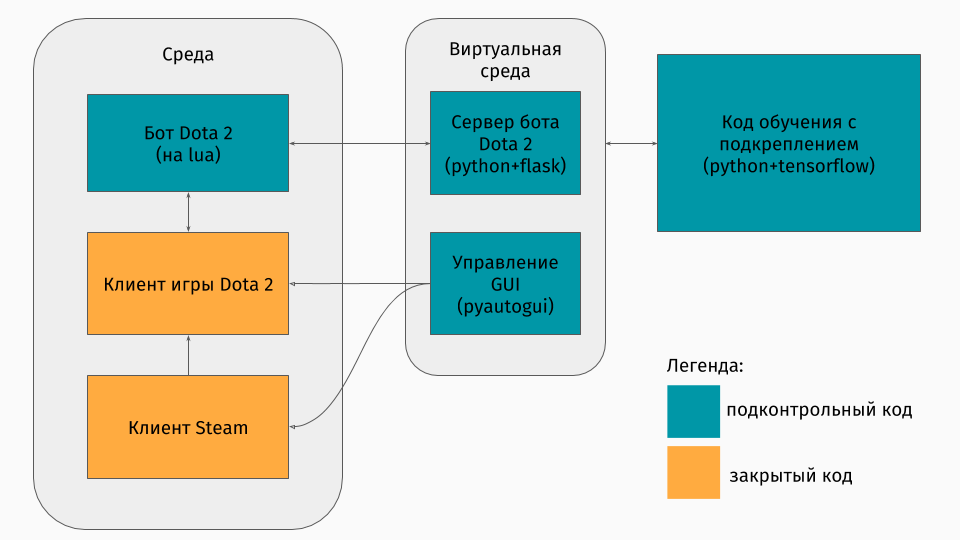
الجزء الأول هو برنامج نصي للتواصل مع عميل اللعبة. لحسن الحظ ، بالنسبة إلى Dota 2 ، هناك واجهة برمجة تطبيقات رسمية لإنشاء برامج الروبوت: Dota Bot Scripting . يتم تطبيقه كإدراج في لغة Lua ، والتي ، كما اتضح فيما بعد ، تحظى بشعبية في تطوير اللعبة. يقوم البرنامج النصي ، الذي يتفاعل مع عميل اللعبة ، بالانسحاب في الوقت المناسب من المعلومات التي نهتم بها (على سبيل المثال ، الإحداثيات على الخريطة ، مواقف المعارضين) ويرسل json معها إلى الخادم.
الجزء الثاني هو المجمع نفسه. تم تصميم هذا كخادم يعالج كل منطق إطلاق Steam و Dota واستقبال json من برنامج نصي داخل اللعبة. يتم ترتيب إدارة إطلاق الألعاب والعملاء من خلال pyautogui ، ويتم التواصل مع lua-insert في اللعبة من خلال خادم Flask.
الجزء الثالث يتكون من خوارزمية التعلم نفسها. تحدد هذه الخوارزمية الإجراءات ، وتتلقى الحالات والمكافآت التالية من الخادم ، والتي يتم من خلالها إخفاء كل الاتصالات باللعبة ، وتحسين سلوكها.
التعلم من الخبراء
الخوارزمية نفسها ليست ذات أهمية خاصة في هذه المقالة ، لأنه يمكن استخدام هذه التقنيات مع أي خوارزمية. استخدمنا DQN (والتي يمكنك أن تقرأ عنها على المحور ). في جوهرها ، هذه شبكة عصبية عميقة + خوارزمية تعلم Q. نعم ، هذا هو بالضبط DQN الذي أنشأه DeepMind للعب ألعاب أتاري.
كما أنه من المثير للاهتمام التحدث عن كيفية استخدام الألعاب السابقة. جربت طريقتين: تشكيل المكافآت القائمة على الإرشاد والمشورة العملية.
الفكرة العامة للمناهج هي أن الموظف سوف يحصل على مكافأة ليس فقط لأهداف المهمة (على سبيل المثال ، في نهاية المتاهة أو لتسلق الجبال) ، ولكن أيضًا أثناء التدريب في كل خطوة. ستوضح هذه المكافأة الإضافية مدى نجاح الوكيل في تحقيق الهدف النهائي. بالطبع ، أود أن أسألها تلقائيًا ، وليس تحديد القواعد / الشروط. النهج التالية تساعد على تحقيق هذا.
إن جوهر تشكيل المكافآت القائمة على الإمكانات هو أن بعض الدول تبدو لنا في البداية واعدة أكثر من غيرها ، وبناءً على ذلك نقوم بتعديل المكافآت الحقيقية التي تحصل عليها الخوارزمية. نحن نفعل ذلك مثل هذا: اين - جائزة معدلة ، - المكافأة حقيقية ، - عامل الخصم من خوارزمية التعلم (ليست مهمة بالنسبة لنا) ، ولكن وهناك إمكاناتنا للحالة التي زرناها خلال . مثال بسيط هو التغلب على متاهة.
لنفترض أن هناك متاهة نريد أن نأتي من الخلية (0،0) إلى الخلية (5،5). ثم ، يمكن أن تكون إمكاناتنا للحالة (x ، y) مطروحًا منها المسافة الإقليدية من (x ، y) إلى هدفنا (5.5): . أي أنه كلما اقتربنا من خط النهاية ، زادت إمكانات الدولة (على سبيل المثال ، ، ، ) لذلك نحن نحفز الوكيل بأي وسيلة للوصول إلى الهدف.
بالنسبة إلى Dota 2 ، الفكرة هي نفسها ، ولكن يتم تعيين إمكانات أكثر تعقيدًا:

تخيل أننا نريد فقط أن نذهب إلى نفس حالات المتظاهر. ثم كلما مررت الدول ، كلما زادت الإمكانيات. نضع إمكانات الدولة بنسبة النسبة المئوية لاستكمال إعادة التشغيل ، إذا كان هناك شرط قريب من حالتنا. هذا له معان مختلفة في المهام المختلفة. ولكن في Dota 2 ، هذا يعني أننا في البداية نريد أن يصل الروبوت إلى الوسط (بعد كل شيء ، في بداية المظاهرات ، لا توجد سوى خطوات إلى الوسط) ، ثم يتم الاحتفاظ بحالة اللاعب البشري (صحة كبيرة ، مسافة آمنة للمعارضين ، إلخ.) )
الطريقة الثانية ، الإجراء - المشورة ، مأخوذة من هذه المقالة . جوهرها هو أننا الآن ننصح الوكيل ليس بفائدة الدول ، ولكن فائدة الإجراءات. على سبيل المثال ، قد تكون هناك نصيحة من هذا القبيل في لعبة Dota 2: إذا كان هناك عميل عدو بالقرب منك ، فهاجمه ؛ إذا لم تصل إلى المركز ، فاذهب في اتجاهه ؛ إذا فقدت صحتك ، فتراجع إلى برجك. وتصف هذه المقالة طريقة لتحديد مثل هذه النصائح دون أي تفكير من قبل المبرمج نفسه - تلقائيًا.
يتم إنشاء إمكانات وفقا لهذا المبدأ: العمل المحتملة قادر على
الزيادات في وجود الشروط ذات الصلة مع نفسه
العمل في المظاهرات. مكافأة إضافية للعمل في الرسم البياني أعلاه
يختلف كما .
تجدر الإشارة هنا إلى أننا نضع إمكانات بالفعل لاتخاذ إجراءات في الولايات.
النتائج
بادئ ذي بدء ، لاحظت أن الهدف من اللعبة كان بسيطًا بعض الشيء ، لأنني علمت كل شيء على جهاز الكمبيوتر المحمول. كان هدف العميل هو إلحاق أكبر عدد ممكن من الهجمات ، والتي تبدو وكأنها هدف حقيقي في بعض التقريب. للقيام بذلك ، تحتاج أولاً إلى الوصول إلى وسط الخريطة ثم مهاجمة المعارضين ، في محاولة لا تموت. لتسريع عملية التعلم ، تم تسجيل بعض المظاهرات التي استغرقت دقيقتين (من 1 إلى 3 دقائق).
يستغرق تدريب وكيل باستخدام أي من الطرق 20 ساعة فقط على جهاز كمبيوتر شخصي (معظم الوقت يستغرقه لتقديم لعبة Dota 2) ، واستنادا إلى الرسوم البيانية OpenAI ، يستغرق التدريب على خوادمهم عدة أسابيع.
تعرض قصير للعبة عند استخدام نهج تشكيل المكافآت المحتملة:
وللحصول على نهج المشورة العملية:
وقدمت هذه الملاحظات في سرعة التدريب من x10. لا تزال عدم دقة سلوك الوكيل عند الانتقال إلى المركز مرئية ، ولكن لا يزال الصراع في المركز يوضح المناورات المستفادة. على سبيل المثال ، التراجع في حالة صحية منخفضة.
يمكنك أيضًا رؤية الاختلافات في الأساليب: من خلال تشكيل المكافآت القائمة على الإمكانات ، يتحرك العامل بسلاسة لأن "يذهب بالإمكانات" ؛ بنصيحة الحركة ، يلعب الروبوت بشكل أكثر نشاطًا في الوسط ، حيث يتلقى تلميحات حول الهجوم.
ملخص
ألاحظ على الفور أنه تم حذف بعض النقاط عمداً: ما هي الخوارزمية بالضبط ، وكيف تم تمثيل الدولة ، وما إذا كان من الممكن تدريب وكيل للعب مع لاعبين حقيقيين ، إلخ.
بادئ ذي بدء ، في هذا المقال أردت أن أوضح أنه في حالة التدريب التعزيز ، لا تحتاج دائمًا إلى الاختيار بين بيئة بسيطة جدًا (الهروب من المتاهة) أو تكلفة تدريب عالية جدًا (وفقًا لحساباتي السريعة ، كلف OpenAI هذه الخوادم للتدريب على Azure $ 4715 في الساعة). هناك تقنيات يمكنها تسريع عملية التعلم ، وتحدثت عن واحدة منها فقط - استخدام المظاهرات. من المهم أن نلاحظ أنه بهذه الطريقة لا تكرر المتظاهر فحسب ، بل فقط "تطرد" منه. من المهم أنه مع مزيد من التدريب ، يكون لدى الوكيل الفرصة لتجاوز الخبراء.
إذا كنت مهتمًا بالتفاصيل ، فيمكنك العثور على رمز عملية التدريب على GitHub .