
المهمة الرئيسية للخدمات التجارية (وغير التجارية ، أيضًا) هي أن تكون دائمًا متاحة للمستخدم. على الرغم من تعطل الجميع ، فإن السؤال هو ما يفعله فريق تقنية المعلومات لتقليلها. لقد قمنا بترجمة مقال بقلم Ben Treynor و Mike Dahlin و Vivek Rau و Betsy Beyer "حساب موثوقية الخدمة" ، والذي يوضح ، بما في ذلك ، باستخدام مثال Google ، سبب كون 100٪ نقطة مرجعية غير صحيحة لمؤشر الموثوقية ، ما هي "قاعدة الأربعة" كيف ، في الممارسة العملية ، تتنبأ رياضياً بجدوى الانقطاعات الكبيرة والصغيرة في الخدمة و / أو مكوناتها الهامة - مقدار التعطل المتوقع والوقت المستغرق للكشف عن الفشل ووقت استعادة الخدمة.
حساب موثوقية الخدمة
نظامك موثوق مثل مكوناته
بن ترينور ، مايك دالين ، فيفيك راو ، بيتسي باير
كما هو موضح في كتاب " هندسة موثوقية الموقع: الموثوقية والموثوقية كما هو الحال في Google " (المشار إليها فيما يلي باسم كتاب SRE) ، فإن تطوير منتجات وخدمات Google يمكن أن يحقق سرعة عالية في إطلاق وظائف جديدة ، مع الحفاظ على SLO (أهداف مستوى الخدمة ، أهداف مستوى الخدمة) ) لضمان موثوقية عالية والاستجابة السريعة. تتطلب SLOs أن تكون الخدمة دائمًا بحالة جيدة وسريعة دائمًا تقريبًا. علاوة على ذلك ، تشير SLOs أيضًا إلى القيم الدقيقة لهذا "دائمًا تقريبًا" لخدمة معينة. تستند SLOs إلى الملاحظات التالية:
في الحالة العامة ، بالنسبة لأي خدمة أو نظام برنامج ، تمثل 100٪ نقطة مرجعية خاطئة لمؤشر الموثوقية ، حيث لا يمكن لأي مستخدم ملاحظة الفرق بين توفر 100٪ و 99،999٪. بين المستخدم والخدمة ، هناك العديد من الأنظمة الأخرى (كمبيوتره المحمول ، شبكة Wi-Fi المنزلية ، المزود ، مزود الطاقة ...) ، وجميع هذه الأنظمة في المجموع غير متوفرة في 99.999٪ من الحالات ، ولكن أقل كثيرًا. لذلك ، يتم فقد الفرق بين 99.999٪ و 100٪ بسبب عوامل عشوائية ناتجة عن عدم إمكانية الوصول إلى الأنظمة الأخرى ، ولا يستفيد المستخدم من حقيقة أننا قضينا الكثير من الجهد في تحقيق هذا الكسر الأخير من نسبة توفر النظام. استثناءات خطيرة لهذه القاعدة هي الفرامل المضادة للقفل وأجهزة ضبط نبضات القلب!
للاطلاع على مناقشة تفصيلية حول كيفية ارتباط SLOs بـ SLIs (مؤشرات مستوى الخدمة) و SLAs (اتفاقيات مستوى الخدمة) ، راجع فصل SRE Target Level of Service. يصف هذا الفصل أيضًا بالتفصيل كيفية اختيار المقاييس ذات الصلة بخدمة أو نظام معين ، والذي يحدد بدوره اختيار SLO المناسب لتلك الخدمة أو النظام.
تمدد هذه المقالة موضوع SLO للتركيز على مكونات الخدمة. على وجه الخصوص ، سوف ندرس كيفية تأثير موثوقية المكونات الأساسية على موثوقية الخدمة ، وكذلك كيفية تصميم أنظمة للتخفيف من التأثير أو تقليل عدد المكونات الهامة.
تهدف معظم الخدمات التي تقدمها Google إلى توفير إمكانية وصول للمستخدمين بنسبة 99.99 بالمائة (تسمى أحيانًا "الأربعة"). بالنسبة لبعض الخدمات ، يشار إلى عدد أقل في اتفاقية المستخدم ، ومع ذلك ، يتم تخزين الهدف 99.99 ٪ داخل الشركة. يمنح هذا الشريط العالي ميزة في المواقف التي يشتكي فيها المستخدمون من أداء الخدمة قبل فترة طويلة من انتهاك شروط الاتفاقية ، لأن الهدف رقم 1 لفريق SRE هو جعل المستخدمين سعداء بالخدمات. بالنسبة للعديد من الخدمات ، يمثل الهدف الداخلي البالغ 99.99٪ المستوى المتوسط ، والذي يوازن بين التكلفة والتعقيد والموثوقية. بالنسبة للبعض الآخر ، ولا سيما الخدمات السحابية العالمية ، فإن الهدف الداخلي هو 99.999 ٪.
الموثوقية 99.99 ٪: الملاحظات والاستنتاجات
دعونا نلقي نظرة على بعض الملاحظات والاستنتاجات الرئيسية حول تصميم وتشغيل الخدمة مع موثوقية 99.99 ٪ ، ثم انتقل إلى الممارسة.
الملاحظة رقم 1: أسباب الفشل
تحدث الأعطال لسببين رئيسيين: مشاكل في الخدمة نفسها ومشاكل مع المكونات المهمة للخدمة. المكون الحاسم هو مكون يؤدي في حالة حدوث عطل إلى حدوث عطل مماثل في تشغيل الخدمة بأكملها.
الملاحظة رقم 2: رياضيات الموثوقية
تعتمد الموثوقية على وتيرة ومدة التوقف. يتم قياسه من خلال:
- تردد الخمول ، أو معكوس: MTTF (يعني الوقت إلى الفشل).
- التوقف ، MTTR (يعني الوقت لإصلاح). يتم تحديد وقت التعطل بواسطة وقت المستخدم: من بداية العطل إلى استئناف التشغيل العادي للخدمة.
وبالتالي ، يتم تعريف الموثوقية رياضيا على أنها MTTF / (MTTF + MTTR) باستخدام الوحدات المناسبة.
الاستنتاج رقم 1: قاعدة التسع الإضافية
لا يمكن أن تكون الخدمة أكثر موثوقية من جميع مكوناتها الأساسية مجتمعة. إذا كانت خدمتك تسعى إلى ضمان توفرها عند مستوى 99.99 ٪ ، فيجب أن تكون جميع المكونات الأساسية متاحة بشكل ملحوظ أكثر من 99.99 ٪ من الوقت.
داخل Google ، نستخدم القاعدة التالية: يجب أن توفر المكونات الأساسية تسعة إضافية مقارنة بالموثوقية المزعومة لخدمتك - في المثال أعلاه ، توفر 99.999 في المئة - لأن أي خدمة سيكون لها العديد من المكونات الهامة ، وكذلك مشاكلها الخاصة. وهذا ما يسمى "قاعدة تسعة اضافية".
إذا كان لديك مكون حرج لا يوفر ما يكفي من التسع (مشكلة شائعة نسبيًا!) ، فيجب عليك تقليل العواقب السلبية.
الاستنتاج رقم 2: الرياضيات من التردد ، وقت الكشف ووقت الاسترداد
لا يمكن أن تكون الخدمة أكثر موثوقية من منتج تكرار الحوادث ووقت الكشف والاسترداد. على سبيل المثال ، تؤدي ثلاث عمليات إيقاف تشغيل شاملة كل عام تبلغ 20 دقيقة لكل منها إلى 60 دقيقة من التوقف. حتى لو كانت الخدمة تعمل بشكل جيد في بقية العام ، فإن تحقيق الموثوقية بنسبة 99.99 بالمائة (لا تزيد عن 53 دقيقة من التوقف في السنة) سيكون مستحيلاً.
هذه ملاحظة رياضية بسيطة ، لكنها غالبًا ما يتم تجاهله.
استنتاج من الاستنتاجات رقم 1 ورقم 2
إذا تعذر تحقيق مستوى الموثوقية الذي تعتمد عليه خدمتك ، فيجب بذل الجهود لتصحيح الموقف - إما عن طريق زيادة توفر الخدمة ، أو عن طريق تقليل العواقب السلبية ، كما هو موضح أعلاه. يعد خفض التوقعات (أي الموثوقية المعلنة) أيضًا أحد الخيارات ، وغالبًا ما يكون الخيار الأكثر صدقًا: توضيح الخدمة التي تعتمد عليك فيجب عليها إما إعادة بناء نظامها لتعويض الخطأ في موثوقية خدمتك ، أو تقليل أهداف مستوى الخدمة الخاصة بها. . إذا لم تقم أنت بنفسك بإزالة هذا التناقض ، فسيتطلب الأمر حتماً إجراء إخفاقات طويلة بما فيه الكفاية.
تطبيق عملي
دعونا نلقي نظرة على مثال على خدمة ذات موثوقية مستهدفة قدرها 99.99 ٪ والعمل على تحديد متطلبات مكوناتها والعمل مع إخفاقاتها.
الأرقام
افترض أن خدمة 99.99 بالمائة متوفرة مع الخصائص التالية:
- انقطاع كبير واحد وثلاثة انقطاع طفيف في السنة. يبدو الأمر مخيفًا ، لكن لاحظ أن مستوى الثقة 99.99٪ يعني توقفًا كبيرًا لمدة 20 إلى 30 دقيقة وبعض الإغلاق الجزئي القصير كل عام. (تشير الرياضيات إلى ما يلي: أ) لا يعتبر فشل مقطع واحد فشلًا للنظام بأكمله من وجهة نظر SLO ، و ب) يتم حساب الموثوقية الإجمالية من خلال مجموع موثوقية القطاعات.)
- خمسة مكونات حاسمة في شكل خدمات مستقلة أخرى مع موثوقية 99.999 ٪.
- خمسة قطاعات مستقلة لا يمكن أن تفشل واحدة تلو الأخرى.
- يتم تنفيذ جميع التغييرات تدريجيا ، شريحة واحدة في وقت واحد.
سيكون الحساب الرياضي للموثوقية كما يلي:
متطلبات المكون
- الحد الأقصى للخطأ في السنة هو 0.01 بالمائة من 525،600 دقيقة في السنة ، أو 53 دقيقة (استنادًا إلى سنة 365 يومًا ، في أسوأ سيناريو).
- الحد المخصص لإغلاق المكونات المهمة هو خمسة مكونات أساسية مستقلة بحد أقصى 0.001٪ لكل منها = 0.005٪ ؛ 0.005 ٪ من 525600 دقيقة في السنة ، أو 26 دقيقة.
- حد الخطأ المتبقي في خدمتك هو 53-26 = 27 دقيقة.
متطلبات الاستجابة للإغلاق
- فترة التوقف المتوقعة: 4 (إيقاف تشغيل كامل و 3 عمليات إيقاف تؤثر على جزء واحد فقط)
- التأثير التراكمي للانقطاعات المتوقعة: (1 × 100٪) + (3 × 20٪) = 1.6
- الكشف عن الفشل والانتعاش بعد ذلك: 27 / 1.6 = 17 دقيقة
- الوقت المخصص للمراقبة لاكتشاف الفشل والإبلاغ عنه: دقيقتان
- الوقت الممنوح للأخصائي المناوب لبدء تحليل التنبيه: 5 دقائق. (يجب على نظام المراقبة تتبع انتهاكات SLO وإرسال إشارة إلى جهاز النداء في كل مرة يحدث فيها عطل في النظام. يتم دعم العديد من خدمات Google عن طريق مهندسي SR shift shift الذين يقومون بالرد على الأسئلة العاجلة.)
- الوقت المتبقي لتقليل الآثار الضارة بشكل فعال: 10 دقائق
الخلاصة: النفوذ لزيادة موثوقية الخدمة
يجدر النظر بعناية إلى الأرقام المعروضة ، لأنها تؤكد على النقطة الأساسية: هناك ثلاث أدوات رئيسية لزيادة موثوقية الخدمة.
- تقليل وتيرة الانقطاعات - من خلال سياسات الإصدار والاختبار والتقييمات الدورية لهيكل المشروع ، إلخ.
- قلل متوسط وقت التوقف عن العمل من خلال التجزئة أو العزلة الجغرافية أو التدهور التدريجي أو عزل العملاء.
- تقليل وقت الاسترداد - من خلال المراقبة وعمليات الإنقاذ بضغطة واحدة (على سبيل المثال ، العودة إلى الحالة السابقة أو إضافة طاقة احتياطية) ، وممارسات الاستعداد التشغيلي ، إلخ.
يمكنك تحقيق التوازن بين هذه الطرق الثلاثة لتبسيط تنفيذ التسامح مع الخطأ. على سبيل المثال ، إذا كان من الصعب تحقيق MTTR لمدة 17 دقيقة ، فركز على تقليل متوسط وقت التوقف عن العمل. تمت مناقشة استراتيجيات الحد من الآثار الضارة وتخفيف تأثيرات المكونات الهامة بمزيد من التفصيل لاحقًا في هذه المقالة.
توضيح "قواعد التسع الإضافية" للمكونات المتداخلة
قد يخلص القارئ العشوائي إلى أن كل رابط إضافي في سلسلة التبعية يتطلب تسع إضافي ، لذلك يلزم وجود تسع إضافيتين للتبعيات من الدرجة الثانية ، وهناك حاجة إلى ثلاثة روابط إضافية للتبعيات من الدرجة الثالثة ، إلخ.
هذا هو الاستنتاج الخاطئ. يعتمد على نموذج ساذج لتسلسل هرمي للمكونات في شكل شجرة ذات تفرع ثابت في كل مستوى. في مثل هذا النموذج ، كما هو مبين في الشكل. 1 ، هناك 10 مكونات فريدة من نوعها من الدرجة الأولى ، و 100 من مكونات فريدة من الدرجة الثانية ، و 1000 من مكونات فريدة من الدرجة الثالثة ، وما إلى ذلك ، مما أدى إلى ما مجموعه 1111 خدمات فريدة من نوعها ، حتى لو كان الهيكل يقتصر على أربع طبقات. النظام الإيكولوجي للخدمات الموثوق بها للغاية مع العديد من المكونات الهامة المستقلة غير واقعي بشكل واضح.
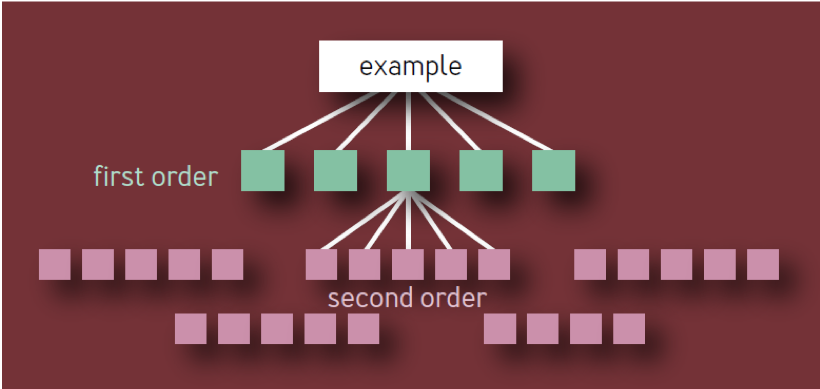
شكل 1 - التسلسل الهرمي للمكون: نموذج غير صالح
يمكن أن يتسبب المكون الحاسم في حد ذاته في فشل الخدمة بأكملها (أو شريحة الخدمة) ، بغض النظر عن مكان وجودها في شجرة التبعية. لذلك ، إذا تم عرض مكون معين من X كتبعية لعدة مكونات من الدرجة الأولى ، فيجب حساب X مرة واحدة فقط ، لأن فشلها سيؤدي في النهاية إلى فشل الخدمة بغض النظر عن عدد الخدمات الوسيطة التي تتأثر أيضًا.
القراءة الصحيحة للقاعدة هي كما يلي:
- إذا كانت الخدمة تحتوي على مكونات هامة فريدة من نوعها ، يساهم كل منها في 1 / N في عدم موثوقية الخدمة بأكملها التي تسببها هذا المكون ، بغض النظر عن مدى انخفاضها في التسلسل الهرمي للمكونات.
- يجب حساب كل مكون مرة واحدة فقط ، حتى إذا ظهر عدة مرات في التسلسل الهرمي للمكون (بمعنى آخر ، يتم حساب المكونات الفريدة فقط). على سبيل المثال ، عند حساب مكونات الخدمة A في الشكل. 2 ، يجب اعتبار الخدمة B مرة واحدة فقط.
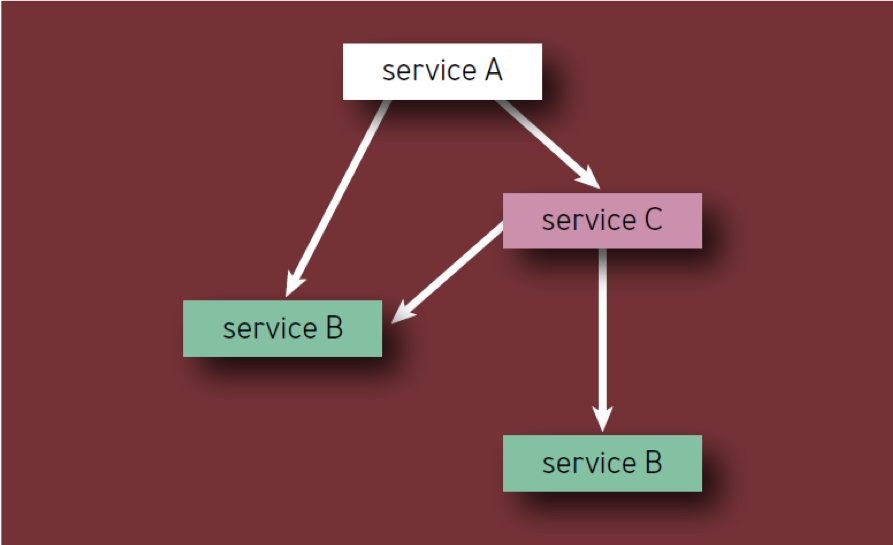
شكل 2 - مكونات في التسلسل الهرمي
على سبيل المثال ، خذ بعين الاعتبار خدمة افتراضية A مع وجود حد خطأ قدره 0.01 بالمائة. مالكي الخدمات مستعدون لإنفاق نصف هذا الحد على أخطائهم وخسائرهم ، والنصف الآخر على المكونات الأساسية. إذا كانت الخدمة تحتوي على N مثل هذه المكونات ، فسيحصل كل منهم على 1 / N من الحد الأقصى للخطأ المتبقي. غالبًا ما تشتمل الخدمات النموذجية على 5 إلى 10 مكونات مهمة ، وبالتالي لا يمكن لكل منها أن يرفض سوى عُشر أو عشرين واحدًا من الحد الأقصى للخطأ في الخدمة أ. لذلك ، كقاعدة عامة ، يجب أن يكون للأجزاء المهمة من الخدمة اعتمادية إضافية واحدة.
حدود الخطأ
يتم تناول مفهوم حدود الخطأ في بعض التفاصيل في كتاب SRE ، ولكن هنا يجب ذكره. يستخدم مهندسو Google SR حدود الأخطاء لتحقيق التوازن بين موثوقية وسرعة التحديثات. يحدد هذا الحد مستوى الفشل المقبول للخدمة لفترة زمنية معينة (عادةً شهر واحد). الحد الأقصى للخطأ هو 1 ناقص SLO للخدمة ، وبالتالي فإن الخدمة المتوفرة التي تمت مناقشتها مسبقًا بنسبة 99.99 بالمائة لها "حد" 0.01٪ على عدم الموثوقية. إلى أن تستفيد الخدمة من حد الخطأ الخاص بها في غضون شهر ، يكون فريق التطوير مجانيًا (في حدود المعقول) لإطلاق وظائف وتحديثات جديدة وما إلى ذلك.
في حالة استخدام حد الخطأ ، يتم تعليق التغييرات على الخدمة (باستثناء إصلاحات الأمان العاجلة والتغييرات التي تهدف إلى التسبب في حدوث انتهاك في المقام الأول) حتى تقوم الخدمة بتجديد الاحتياطي في حد الخطأ أو حتى يتغير الشهر. تستخدم العديد من الخدمات في Google طريقة نافذة انزلاقية لـ SLO بحيث تتم استعادة حد الخطأ تدريجيًا. بالنسبة إلى الخدمات الجادة ذات SLO التي تزيد عن 99.99٪ ، يُنصح باستخدام إعادة تعيين ربع سنوي بدلاً من إعادة تعيين شهرية ، لأن عدد فترات التوقف المسموح بها صغير.
تعمل حدود الأخطاء على إزالة التوتر بين الأقسام التي قد تنشأ خلاف ذلك بين مهندسي SR ومطوري المنتجات ، وتزويدهم بأداة تقييم المخاطر الشائعة القائمة على البيانات لإطلاق منتج ما. كما أنها توفر لمهندسي SR وفرق التطوير هدفًا مشتركًا لتطوير الأساليب والتقنيات التي ستمكنهم من الابتكار بشكل أسرع وإطلاق منتجات دون "ميزانية منتفخة".
استراتيجيات الحد من المكونات الحرجة والتخفيف من حدتها
في هذه المرحلة ، في هذه المقالة ، أنشأنا ما يمكن تسميته "القاعدة الذهبية لموثوقية المكون" . هذا يعني أن موثوقية أي مكون حرج يجب أن تكون أعلى بعشرة أضعاف من المستوى المستهدف لموثوقية النظام بأكمله بحيث تظل مساهمته في عدم موثوقية النظام عند مستوى الخطأ. ويترتب على ذلك في الحالة المثالية أن المهمة هي جعل أكبر عدد ممكن من المكونات غير حرجة. وهذا يعني أن المكونات يمكن أن تلتزم بمستوى أقل من الموثوقية ، مما يتيح للمطورين الفرصة للابتكار والمخاطر.
تتمثل أبسط وأوضح استراتيجية لتقليل التبعيات الحرجة في القضاء على نقاط الفشل الفردية كلما أمكن ذلك. يجب أن يكون النظام الأكبر قادرًا على العمل بشكل مقبول دون أي مكون معين لا يمثل تبعية حرجة أو SPOF.
في الواقع ، من المرجح أنك لا تستطيع التخلص من جميع التبعيات الحرجة ؛ ولكن يمكنك اتباع بعض إرشادات تصميم النظام لتحسين الموثوقية. على الرغم من أن هذا غير ممكن دائمًا ، إلا أنه من الأسهل والأكثر كفاءة تحقيق موثوقية عالية للنظام إذا وضعت موثوقية في مراحل التصميم والتخطيط ، وليس بعد أن يعمل النظام ويؤثر على المستخدمين الفعليين.
تقييم هيكل المشروع
عند تخطيط نظام أو خدمة جديدة ، أو عند إعادة تصميم أو تحسين نظام أو خدمة حالية ، قد تكشف مراجعة الهيكل أو المشروع عن بنية أساسية مشتركة ، وكذلك التبعيات الداخلية والخارجية.
البنية التحتية المشتركة
إذا كانت خدمتك تستخدم بنية تحتية مشتركة (على سبيل المثال ، خدمة قاعدة البيانات الرئيسية المستخدمة من قبل العديد من المنتجات المتاحة للمستخدمين) ، فكر في استخدام هذه البنية الأساسية بشكل صحيح. حدد بوضوح أصحاب البنية التحتية المشتركة كمشاركين إضافيين في المشروع. احذر أيضًا من الأحمال الزائدة للمكونات - للقيام بذلك ، قم بتنسيق عملية بدء التشغيل بعناية مع مالكي هذه المكونات.
التبعيات الداخلية والخارجية
في بعض الأحيان يعتمد منتج أو خدمة على عوامل خارجة عن سيطرة شركتك - على سبيل المثال ، من مكتبات البرامج أو الخدمات والبيانات من الجهات الخارجية. تحديد هذه العوامل سوف يقلل من العواقب غير المتوقعة لاستخدامها.
تخطيط وتصميم النظم بعناية
عند تصميم نظامك ، انتبه للمبادئ التالية:
التكرار والعزلة
يمكنك محاولة تقليل تأثير المكون الحرج عن طريق إنشاء عدة مثيلات مستقلة منه. على سبيل المثال ، إذا كان تخزين البيانات في حالة واحدة يضمن إتاحة هذه البيانات بنسبة 99.9 في المائة ، فإن تخزين ثلاث نسخ في ثلاث نسخ موزعة على نطاق واسع سيوفر ، من الناحية النظرية ، مستوى إتاحة يتراوح من 1 - 0.013 أو تسع تسع إذا فشل المثيل بشكل مستقل مع عدم وجود ارتباط صفري.
في العالم الواقعي ، لا يكون الارتباط مطلقًا أبدًا (انظر إلى إخفاقات الشبكة الأساسية التي تؤثر على العديد من الخلايا في نفس الوقت) ، وبالتالي فإن الموثوقية الفعلية لن تقترب أبدًا من تسعة تسع ، لكنها تتجاوز ثلاثة تسع.
وبالمثل ، يمكن أن يوفر إرسال RPC (استدعاء الإجراء عن بُعد) إلى تجمع خادم واحد في نفس المجموعة توفرًا بنسبة 99 بالمائة للنتائج ، في حين أن إرسال ثلاث نسخ متزامنة من RPC إلى ثلاثة تجمعات مختلفة للخوادم وسيساعد قبول الاستجابة الأولى في الوصول إلى مستوى التوافر أعلى من ثلاثة تسعة (انظر أعلاه). يمكن أن تقصر هذه الاستراتيجية أيضًا ذيل تأخير وقت الاستجابة إذا كانت تجمعات الخوادم متساوية من مرسل RPC. (نظرًا لأن تكلفة إرسال ثلاث RPC في نفس الوقت مرتفعة ، فإن Google غالباً ما تخصص وقتًا استراتيجيًا لهذه المكالمات: تتوقع معظم أنظمتنا جزءًا من الوقت المخصص قبل إرسال RPC الثاني ووقتًا أطول بقليل قبل إرسال RPC الثالث.)
الاحتياطي وتطبيقه
قم بإعداد تشغيل البرنامج وتحديثه بحيث تستمر الأنظمة في العمل عند فشل الأجزاء الفردية (تفشل آمنة) وعزل نفسها عند حدوث المشاكل. المبدأ الأساسي هنا هو أنه بحلول الوقت الذي تقوم فيه بتوصيل الشخص لتشغيل الاحتياطي ، من المحتمل أن تتجاوز حد الخطأ الخاص بك.
تزامن
لمنع المكونات من أن تصبح حرجة ، صممها بشكل غير متزامن كلما كان ذلك ممكنًا. إذا كانت إحدى الخدمات تتوقع استجابة RPC من أحد أجزائها غير الحرجة ، مما يدل على تباطؤ حاد في وقت الاستجابة ، فإن هذا التباطؤ سوف يؤدي إلى تفاقم أداء الخدمة الأم بشكل غير ضروري. سيؤدي تعيين RPC لمكون غير حاسم إلى الوضع غير المتزامن إلى توفير وقت استجابة الخدمة الأصلية من الارتباط بأداء هذا المكون. وعلى الرغم من أن عدم التزامن يمكن أن يعقد الكود والبنية التحتية للخدمة ، إلا أن هذا الحل الوسط يستحق ذلك.
تخطيط الموارد
تأكد من تزويد جميع المكونات بكل ما تحتاجه. , — .
, \ .
, . . . , .
SLO. , , . , , , MTTR .
, . :
, , , . :
, : , , . — , . , , , .
, . , Google , 10 .
الخاتمة
على الرغم من أن القراء قد يكونون على دراية ببعض أو العديد من المفاهيم الموضحة في هذه المقالة ، فإن الأمثلة المحددة لاستخدامها سوف تساعدهم على فهم جوهرهم بشكل أفضل ونقل هذه المعرفة للآخرين. توصياتنا ليست بسيطة ، ولكنها غير قابلة للتحقيق. أظهرت عدد من خدمات Google مرارًا وتكرارًا الموثوقية التي تتجاوز أربعة مجالات ليس بسبب الجهود الخارقة أو الذكاء ، ولكن بسبب التطبيق المدروس للمبادئ وأفضل الممارسات التي تم تطويرها على مدار سنوات عديدة (راجع SRE ، الملحق ب: إرشادات عملية للخدمات في العمليات الصناعية).