
يعد
تصنيف النص من أكثر المهام شيوعًا في
البرمجة اللغوية العصبية وتدريب المعلمين ، عندما تحتوي مجموعة البيانات على مستندات نصية ويتم استخدام الملصقات لتدريب مصنف النص.
من وجهة نظر البرمجة اللغوية العصبية ، يتم إنجاز مهمة تصنيف النص عن طريق تدريس التمثيل على مستوى الكلمات باستخدام دمج الكلمات ثم تمثيل التدريب على مستوى النص المستخدم كدالة للتصنيف.
يتجاهل نوع الأساليب المستندة إلى الترميز التفاصيل الصغيرة ومفاتيح التصنيف (نظرًا لأن التمثيل العام على مستوى النص يدرس بضغط التمثيلات على مستوى الكلمة).
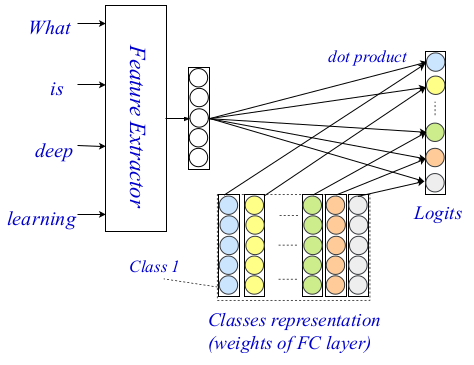 الأساليب القائمة على الترميز لتصنيف النص مع مطابقة لمستوى النص
الأساليب القائمة على الترميز لتصنيف النص مع مطابقة لمستوى النصالامتحان - طريقة تصنيف النص الجديد
اقترح باحثون من جامعة شاندونغ وجامعة سنغافورة الوطنية
نموذجًا جديدًا لتصنيف النصوص يتضمن إشارات مطابقة لمستوى الكلمات في مهمة تصنيف النصوص. تستخدم طريقتهم آلية تفاعل لإدخال تلميحات مفصلة على مستوى الكلمة في عملية التصنيف.
لحل مشكلة تضمين إشارات مطابقة أكثر دقة على مستوى الكلمات ، اقترح الباحثون
حساب تقديرات المراسلات بين الكلمات والفصول بشكل صريح .
الفكرة الرئيسية هي حساب مصفوفة التفاعل من تمثيل على مستوى الكلمات يحمل المفاتيح المقابلة على مستوى الكلمة. كل إدخال في هذه المصفوفة هو تقييم المراسلات بين كلمة وفئة محددة.
يحتوي هيكل تصنيف النص المقترح المسمى EXAM - EXPlicit interAction Model (
GitHub ) على ثلاثة مكونات رئيسية:
- تشفير مستوى الكلمات ،
- طبقة التفاعل و
- طبقة التجميع.
تسمح لك هذه البنية ثلاثية الطبقات بترميز وتصنيف النص باستخدام كل من الإشارات والتلميحات الصغيرة والمعممة. يظهر العمارة بأكملها في الصورة أدناه.
 الامتحان العمارة
الامتحان العمارةفي الماضي ، تم إجراء تشفير مكثف على مستوى الكلمات في مجتمع البرمجة اللغوية العصبية (NLP) ، وظهرت برامج تشفير قوية جدًا. يستخدم المؤلفون طريقة sovermenny كتشفير على مستوى الكلمات ، وفي أعمالهم يصفون بالتفصيل عنصرين آخرين من بنيانهم: مستوى التفاعل والتجميع.
تعتمد طبقة التفاعل والمساهمة الرئيسية والجدة في الطريقة المقترحة على آلية التفاعل المعروفة. يستخدم الباحثون
مصفوفة عرضية مدربة لتشفير كل فصل حتى يتمكنوا من حساب تقديرات التفاعل فيما بين الفصول. يتم لصق النقاط النهائية باستخدام منتج نقطة كدالة للتفاعل بين الكلمة الهدف وكل فئة. لم يتم النظر في المزيد من المهام المعقدة بسبب التعقيد المتزايد للحسابات.
 التصور طبقة
التصور طبقةأخيرًا ، يستخدمون MLP بسيط ، متصل بشكل كامل ، من طبقتين كطبقة تجميع. يذكرون أيضًا أن مستوى التجميع الأكثر تعقيدًا ، بما في ذلك CNN أو LSTM ، يمكن استخدامه هنا. يستخدم MLP لحساب سجلات التصنيف النهائية باستخدام مصفوفة التفاعل وترميزات مستوى الكلمات. يستخدم الانتروبيا المتقاطعة كدالة للخسارة في التحسين.
الدرجات
لتقييم الإطار المقترح لتصنيف النص ، أجرى الباحثون تجارب مكثفة في كل من الشروط متعددة الطبقات والعلامات. أنها تظهر أن طريقتهم هي أعلى بكثير من الأساليب الحديثة ذات الصلة الحديثة.
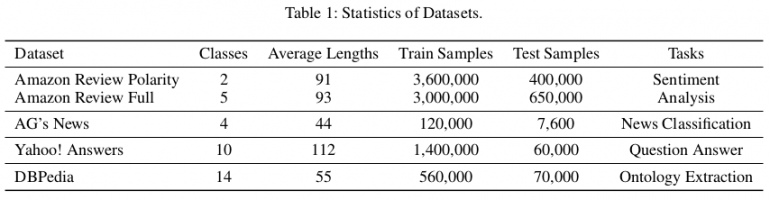 إحصائيات مجموعات البيانات المستخدمة للتقييم
إحصائيات مجموعات البيانات المستخدمة للتقييمللتقييم ، يقومون بإنشاء ثلاثة أنواع أساسية مختلفة من النماذج:
- النماذج القائمة على تطوير السمات ؛
- نماذج عميقة قائمة على الشخصية
- نماذج عميقة قائمة على الكلمات.
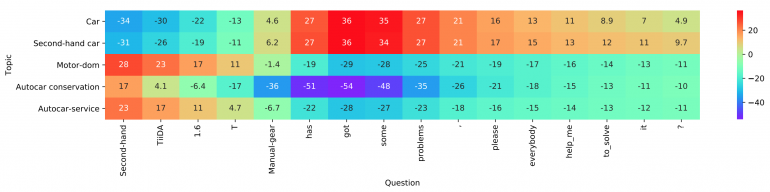
استخدم المؤلفون مجموعات البيانات المرجعية المتاحة للجمهور (تشانغ وتشاو وليكون 2015) لتقييم الطريقة المقترحة. في المجموع ، هناك ست مجموعات من بيانات نص التصنيف التي تتوافق مع مهام تحليل الحالة المزاجية وتصنيف الأخبار والأسئلة والأجوبة واستخراج الأنطولوجيا ، على التوالي. في المقالة ، يظهرون أن الاختبار يحقق أفضل أداء بين ثلاث مجموعات من البيانات: AG ، Yah. A. و DBP. يمكن الاطلاع على التقييم والمقارنة مع الطرق الأخرى في الجداول أدناه.
![مجموعة اختبار الدقة [٪] في مهام تصنيف المستندات متعددة الفئات والمقارنة مع الطرق الأخرى](https://habrastorage.org/getpro/habr/post_images/de7/8d8/b60/de78d8b6017c9624c347b0fb645ae0ae.png)

الاستنتاجات
هذا العمل هو مساهمة مهمة في مجال معالجة اللغات الطبيعية (NLP). هذا هو العمل الأول الذي يقدم تلميحات مطابقة أكثر دقة على مستوى الكلمات في تصنيف النص في نماذج الشبكات العصبية العميقة. يوفر النموذج المقترح أحدث المؤشرات لعديد من مجموعات البيانات.
ترجمة - ستانيسلاف ليتفينوف