هذا هو الجزء الثاني من
Kubernetes الخاص بي
في سلسلة
منشورات Enterprise . كما ذكرت في تقريري الأخير ، من المهم جدًا عند الانتقال إلى
"أدلة التصميم والتنفيذ" أن يكون الجميع على نفس المستوى من فهم Kubernetes (K8s).
لا أريد استخدام الطريقة التقليدية هنا لشرح بنية وتقنيات Kubernetes ، لكنني سأشرح كل شيء من خلال المقارنة مع نظام vSphere ، الذي تعرفه أنت كمستخدمين لبرنامج VMware. سيتيح لك ذلك التغلب على الارتباك الواضح وثقل فهم Kubernetes. لقد استخدمت هذا النهج داخل برنامج VMware لتقديم Kubernetes إلى جمهور مختلف من المستمعين ، وأثبت أنه يعمل بشكل رائع ويساعد الأشخاص على التعود على المفاهيم الأساسية بشكل أسرع.
ملاحظة مهمة قبل أن نبدأ. لا أستخدم هذه المقارنة لإثبات أي أوجه تشابه أو اختلافات بين vSphere و Kubernetes. كلاهما ، والآخر ، في جوهرهما ، عبارة عن أنظمة موزعة ، وبالتالي ، يجب أن يكون هناك تشابه مع أي نظام آخر مماثل. لذلك ، في النهاية ، أحاول تقديم تقنية رائعة مثل Kubernetes إلى مجتمع واسع من مستخدميها.

قليلا من التاريخ
تتضمن قراءة هذا المنشور التعرف على الحاويات. لن أصف المفاهيم الأساسية للحاويات ، حيث أن هناك العديد من الموارد التي تتحدث عن هذا. التحدث مع العملاء في كثير من الأحيان ، أرى أنهم لا يستطيعون فهم لماذا استولت الحاويات على صناعتنا وأصبحت شائعة للغاية في وقت قياسي. للإجابة على هذا السؤال ، سأتحدث عن تجربتي العملية في فهم التغييرات التي تحدث في صناعتنا.
قبل استكشاف عالم الاتصالات السلكية واللاسلكية ، كنت مطور ويب (2003).
كانت هذه وظيفتي الثانية مدفوعة الأجر بعد أن عملت كمهندس / مدير شبكة (أعرف أنني كنت مقبسًا لجميع المهن). أنا وضعت في PHP. لقد طورت جميع أنواع التطبيقات ، بدءًا من التطبيقات الصغيرة التي استخدمها صاحب العمل ، وانتهت مع تطبيق التصويت الاحترافي للبرامج التلفزيونية ، وحتى تطبيقات الاتصالات التي تتفاعل مع مراكز VSAT وأنظمة الأقمار الصناعية. كانت الحياة رائعة ، باستثناء عقبة رئيسية واحدة يعرفها كل مطور ، إنها إدمان.
في البداية قمت بتطوير التطبيق على جهاز الكمبيوتر المحمول الخاص بي ، باستخدام شيء مثل مكدس LAMP ، عندما عملت بشكل جيد على جهاز الكمبيوتر المحمول ، قمت بتنزيل الكود المصدري على الخوادم المضيفة (يتذكر الجميع RackShack؟) أو على خوادم العميل الخاصة. يمكنك أن تتخيل أنه بمجرد القيام بذلك ، تعطل التطبيق ولم يعمل على هذه الخوادم. السبب في ذلك هو الإدمان. تحتوي الخوادم على إصدارات أخرى من البرنامج (Apache ، PHP ، MySQL ، وما إلى ذلك) غير تلك المستخدمة من قبلي على الكمبيوتر المحمول. لذلك كنت بحاجة لإيجاد طريقة لتحديث إصدارات البرامج على الخوادم البعيدة (فكرة سيئة) أو إعادة كتابة الكود على الكمبيوتر المحمول لمطابقة الإصدارات الموجودة على الخوادم البعيدة (أسوأ فكرة). لقد كان كابوسًا ، وفي بعض الأحيان كرهت نفسي وتساءلت عن سبب رزقني.
مرت 10 سنوات ، ظهرت الشركة دوكر. كمستشار لبرنامج VMware في Professional Services (2013) ، سمعت عن Docker ، واسمحوا لي أن أقول أنني لم أستطع فهم هذه التكنولوجيا في تلك الأيام. واصلت قول شيء مثل: لماذا استخدام الحاويات إذا كان هناك أجهزة افتراضية. لماذا تتخلى عن التقنيات المهمة مثل vSphere HA أو DRS أو vMotion بسبب مزايا غريبة مثل الإطلاق الفوري للحاوية أو التخلص من حمولة برنامج Hypervisor. بعد كل شيء ، يعمل الجميع مع الأجهزة الافتراضية ويعمل بشكل مثالي. باختصار ، نظرت إليه من حيث البنية التحتية.
ولكن بعد ذلك بدأت أنظر عن كثب وقد بزغ فجرًا. كل ما يتعلق Docker يرتبط بالمطورين. بدأت للتو التفكير كمطور ، أدركت على الفور أنه إذا كان لدي هذه التكنولوجيا في عام 2003 ، يمكنني أن حزمة كل التبعيات الخاصة بي. يمكن أن تعمل تطبيقات الويب الخاصة بي بغض النظر عن الخادم المستخدم. علاوة على ذلك ، لن يكون من الضروري تنزيل التعليمات البرمجية المصدر أو تكوين شيء ما. يمكنك ببساطة "تجميع" طلبي في صورة واطلب من العملاء تنزيل هذه الصورة وتشغيلها. هذا هو حلم أي مطور ويب!
كل هذا رائع. عامل الميناء حل مشكلة التفاعل والتعبئة الضخمة ، ولكن ماذا بعد؟ هل يمكنني ، كعميل مشترك ، إدارة هذه التطبيقات أثناء التوسع؟ ما زلت أريد استخدام HA و DRS و vMotion و DR. حل Docker لمشاكل مطوريي وخلق مجموعة كاملة من المشكلات للمسؤولين (فريق DevOps). يحتاجون إلى منصة لإطلاق الحاويات ، مثل منصة إطلاق الأجهزة الافتراضية. وعدنا مرة أخرى إلى البداية.
ولكن بعد ذلك ظهرت Google ، وهي تخبر العالم عن استخدام الحاويات لسنوات عديدة (في الواقع ، تم اختراع الحاويات من قِبل Google: cgroups) وحول الطريقة الصحيحة لاستخدامها ، من خلال منصة أطلقوا عليها اسم Kubernetes. ثم فتحوا شفرة المصدر ل Kubernetes. قدمت إلى المجتمع Kubernetes. وهذا تغير كل شيء مرة أخرى.
فهم Kubernetes مقابل vSphere
إذن ما هو Kubernetes؟ ببساطة ، Kubernetes للحاويات هو نفس vSphere للأجهزة الافتراضية في مركز بيانات حديث. إذا استخدمت VMware Workstation في أوائل عام 2000 ، فأنت تعلم أن هذا الحل قد تم اعتباره بجدية كحل لمراكز البيانات. عندما ظهر VI / vSphere مع مضيفي vCenter و ESXi ، تغير عالم الأجهزة الافتراضية بشكل كبير. تقوم Kubernetes بالشيء نفسه اليوم مع عالم الحاويات ، مما يوفر القدرة على إطلاق وإدارة الحاويات في الإنتاج. وهذا هو السبب في أننا سنبدأ مقارنة vSphere جنبًا إلى جنب مع Kubernetes لشرح تفاصيل هذا النظام الموزع لفهم وظائفه وتقنياته.

نظرة عامة على النظام
كما هو الحال في vSphere ، هناك مضيفان vCenter و ESXi في مفهوم Kubernetes ، يوجد Master و Node's. في هذا السياق ، يعد Master in K8s مكافئًا لـ vCenter ، بمعنى أنه الطائرة الإدارية للنظام الموزع. إنه أيضًا نقطة الدخول لواجهة برمجة التطبيقات التي تتفاعل معها عند إدارة عبء العمل. بنفس الطريقة ، تعمل K8s Nodes كموارد حسابية ، على غرار مضيفات ESXi. تقوم بتشغيل عبء العمل عليها (في حالة K8s ، نسميها Pods). يمكن أن تكون العقد أجهزة افتراضية أو خوادم فعلية. بالطبع ، مع vSphere ESXi ، يجب أن تكون الأجهزة المضيفة دائمًا مادية.

يمكنك أن ترى أن K8s لديها متجر ذو قيمة رئيسية يسمى "etcd". تشبه وحدة التخزين هذه قاعدة بيانات vCenter ، حيث تقوم بحفظ تكوين الكتلة الذي تريد الالتزام به.
بالنسبة للاختلافات: في Master K8s ، يمكنك أيضًا تشغيل أحمال العمل ، لكن على vCenter لا يمكنك ذلك. vCenter هو جهاز افتراضي مخصص للإدارة فقط. في حالة K8s ، يعتبر Master موردًا للحوسبة ، لكن تشغيل تطبيقات Enterprise عليه ليس فكرة جيدة.
فكيف سيبدو في الواقع؟ ستستخدم CLI بشكل أساسي للتفاعل مع Kubernetes (لكن واجهة المستخدم الرسومية لا تزال خيارًا قابلاً للتطبيق). توضح لقطة الشاشة أدناه أنني أستخدم جهاز Windows للاتصال بمجموعة Kubernetes الخاصة بي عبر سطر الأوامر (أستخدم cmder إذا كنت مهتمًا). في لقطة الشاشة لدي عقدة Master واحدة و 4 عقدة. إنها تعمل تحت سيطرة الإصدار 1.8 من K8s ، ويتم تثبيت نظام التشغيل (OS) Ubuntu 16.04 على العقد. في وقت كتابة هذا المنشور ، نعيش بشكل رئيسي في عالم Linux ، حيث يعمل Master و Node دائمًا على توزيع Linux.
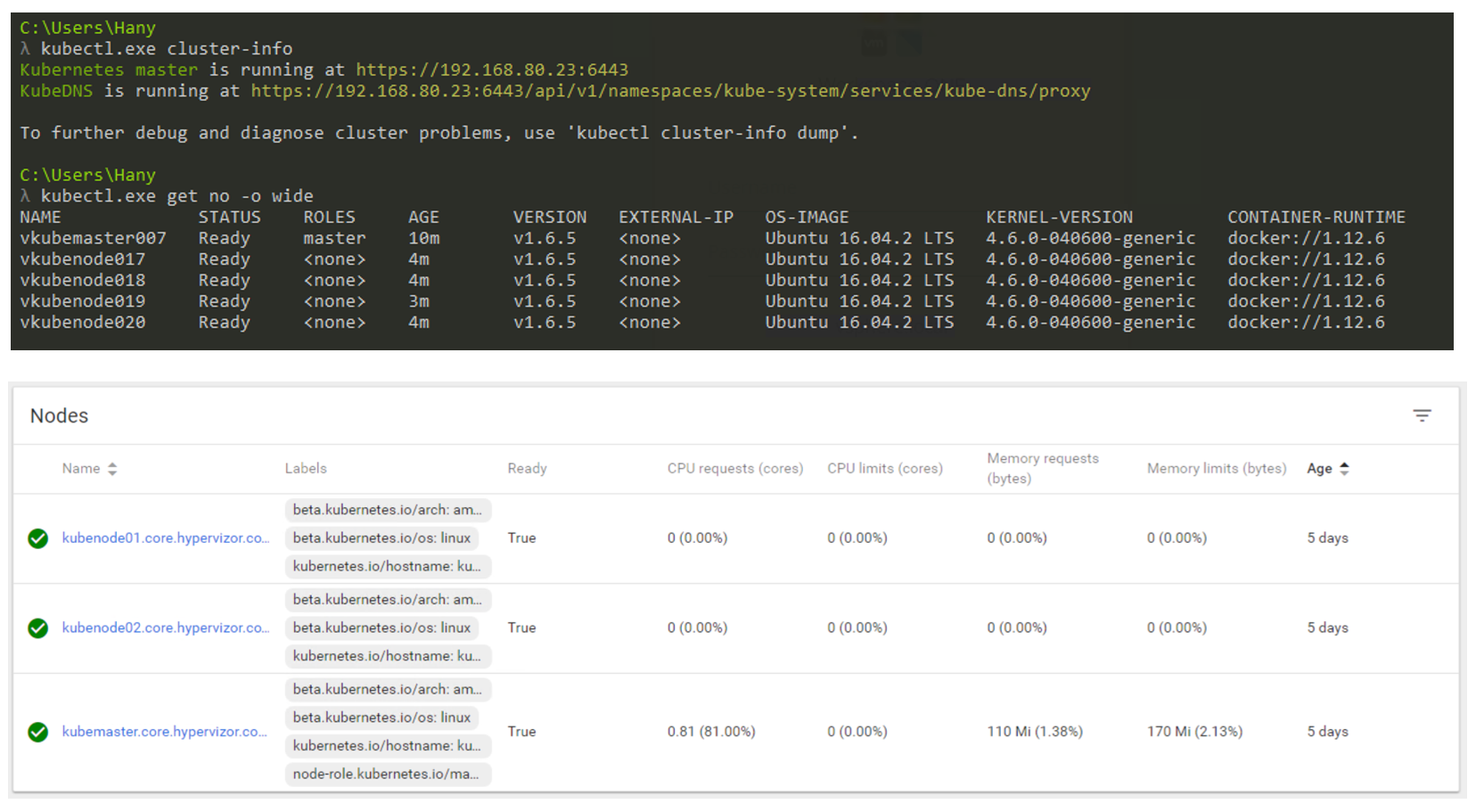 إدارة نظام K8s من خلال CLI و GUI.
إدارة نظام K8s من خلال CLI و GUI.عامل شكل عبء العمل
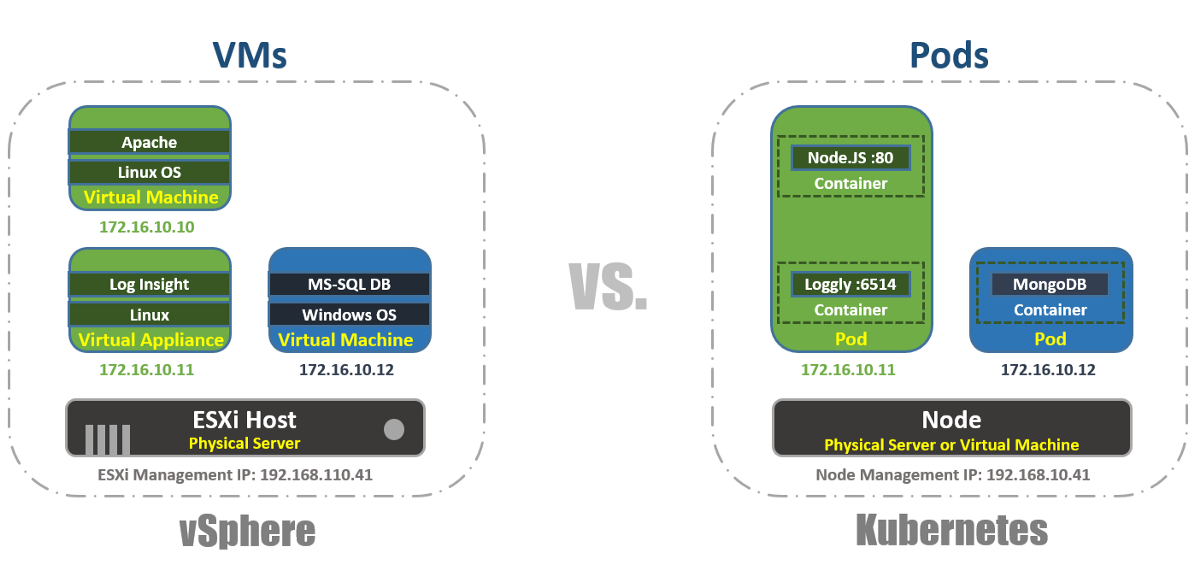
في vSphere ، الجهاز الظاهري هو الحد المنطقي لنظام التشغيل. في Kubernetes ، تعد Pods حدودًا للحاويات ، تمامًا مثل مضيف ESXi ، الذي يمكنه تشغيل أجهزة افتراضية متعددة في وقت واحد. يمكن لكل عقدة تشغيل عدة قرون. يتلقى كل Pod عنوان IP قابلاً للتوجيه ، مثل الأجهزة الظاهرية ، حتى يتمكن Pods من التواصل مع بعضهم البعض.
في vSphere ، تعمل التطبيقات داخل نظام التشغيل ، وفي Kubernetes ، تعمل التطبيقات داخل حاويات. لا يمكن للجهاز الظاهري العمل إلا مع نظام تشغيل واحد في المرة الواحدة ، ويمكن للجهاز تشغيل حاويات متعددة.
هذه هي الطريقة التي يمكنك من خلالها إدراج قائمة Pods داخل مجموعة K8s باستخدام أداة kubectl من خلال CLI ، والتحقق من وظائف Pods وعمرهم وعنوان IP والعقد التي يعملون عليها حاليًا.

الإدارة
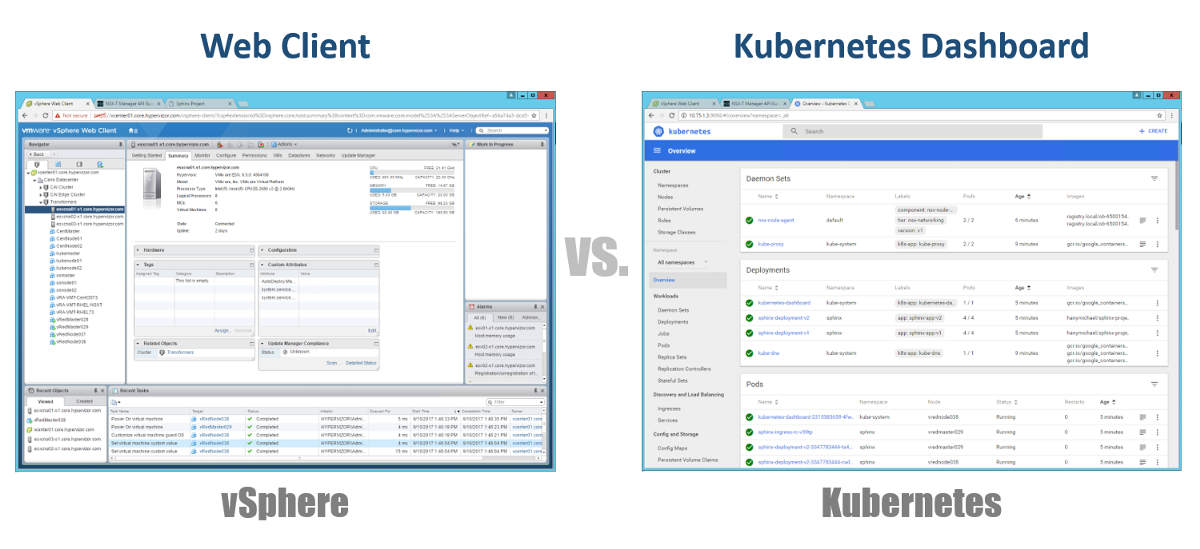
لذا ، كيف ندير برامج الماجستير والعُقد والقرون الخاصة بنا؟ في vSphere ، نستخدم عميل الويب لإدارة معظم (إن لم يكن جميع) مكونات البنية التحتية الافتراضية لدينا. ل Kubernetes ، بالمثل ، باستخدام Dashboard. هذه بوابة ويب جيدة تعتمد على واجهة المستخدم الرسومية والتي يمكنك الوصول إليها من خلال متصفحك بنفس الطريقة مثل عميل vSphere Web. من الأقسام السابقة ، يمكنك أن ترى أنه يمكنك إدارة مجموعة K8s الخاصة بك باستخدام الأمر kubeclt من CLI. يكون دائمًا موضع نقاش حيث ستقضي معظم وقتك في CLI أو في لوحة المعلومات الرسومية. نظرًا لأن هذا الأخير أصبح أداة قوية بشكل متزايد كل يوم (يمكنك مشاهدة هذا الفيديو للتأكد). شخصياً ، أعتقد أن لوحة المعلومات مريحة جدًا لمراقبة الحالة أو عرض تفاصيل مختلف مكونات K8 بسرعة ، مما يلغي الحاجة إلى إدخال أوامر طويلة في CLI. ستجد التوازن بينهما بطريقة طبيعية.
التكوينات
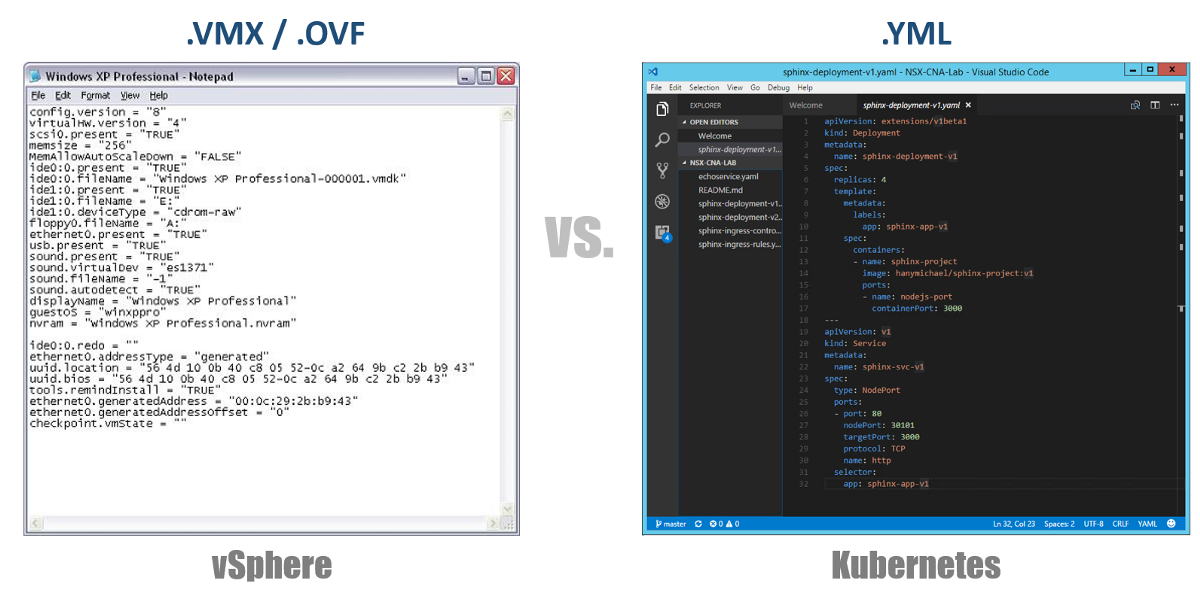
واحدة من أهم المفاهيم في Kubernetes هي الحالة المطلوبة للتكوينات. أنت تعلن أنك تريد لأي مكون Kubernetes تقريبًا عبر ملف YAML ، ويمكنك إنشاء كل هذا باستخدام kubectl (أو من خلال لوحة معلومات رسومية) كحالتك المطلوبة. من الآن فصاعدًا ، ستسعى Kubernetes دائمًا للحفاظ على محيطك في حالة تشغيلية معينة. على سبيل المثال ، إذا كنت ترغب في الحصول على 4 نسخ متماثلة من Pod واحد ، فسوف تستمر K8s في مراقبة هذه Pods ، وإذا مات أحدهم أو واجهت العقدة التي واجهتها مشاكل ، فسوف تقوم K8s بالتعافي الذاتي وإنشاء هذا تلقائيًا قرنة في مكان آخر.
بالرجوع إلى ملفات تكوين YAML الخاصة بنا ، يمكنك اعتبارها كملف .VMX لجهاز ظاهري أو واصف .OVF لجهاز ظاهري تريد توزيعه على vSphere. تحدد هذه الملفات تكوين عبء العمل / المكون الذي تريد تشغيله. بخلاف ملفات VMX / OVF ، والتي تعتبر حصرية لأجهزة VMs / الأجهزة الافتراضية ، يتم استخدام ملفات تكوين YAML لتحديد أي مكون K8s ، مثل ReplicaSets ، والخدمات ، وعمليات النشر ، إلخ. النظر في هذا في الأقسام التالية.
مجموعات افتراضية
في vSphere ، لدينا مضيفات ESXi مادية يتم تجميعها منطقيا في مجموعات. يمكن تقسيم هذه المجموعات إلى مجموعات افتراضية أخرى تسمى "تجمعات الموارد". تستخدم هذه "المجمعات" بشكل أساسي للحد من الموارد. في Kubernetes ، لدينا شيء مشابه للغاية. نحن نسميها "مساحات الأسماء" ، كما يمكن استخدامها لتوفير حدود الموارد ، والتي ستنعكس في القسم التالي. ومع ذلك ، غالبًا ما تستخدم "مساحات الأسماء" كأداة متعددة الاستئجار للتطبيقات (أو المستخدمين ، إذا كنت تستخدم مجموعات K8s الشائعة). هذا أيضًا أحد الخيارات التي يمكنك من خلالها تنفيذ تجزئة الشبكة باستخدام NSX-T. النظر في هذا في المنشورات التالية.
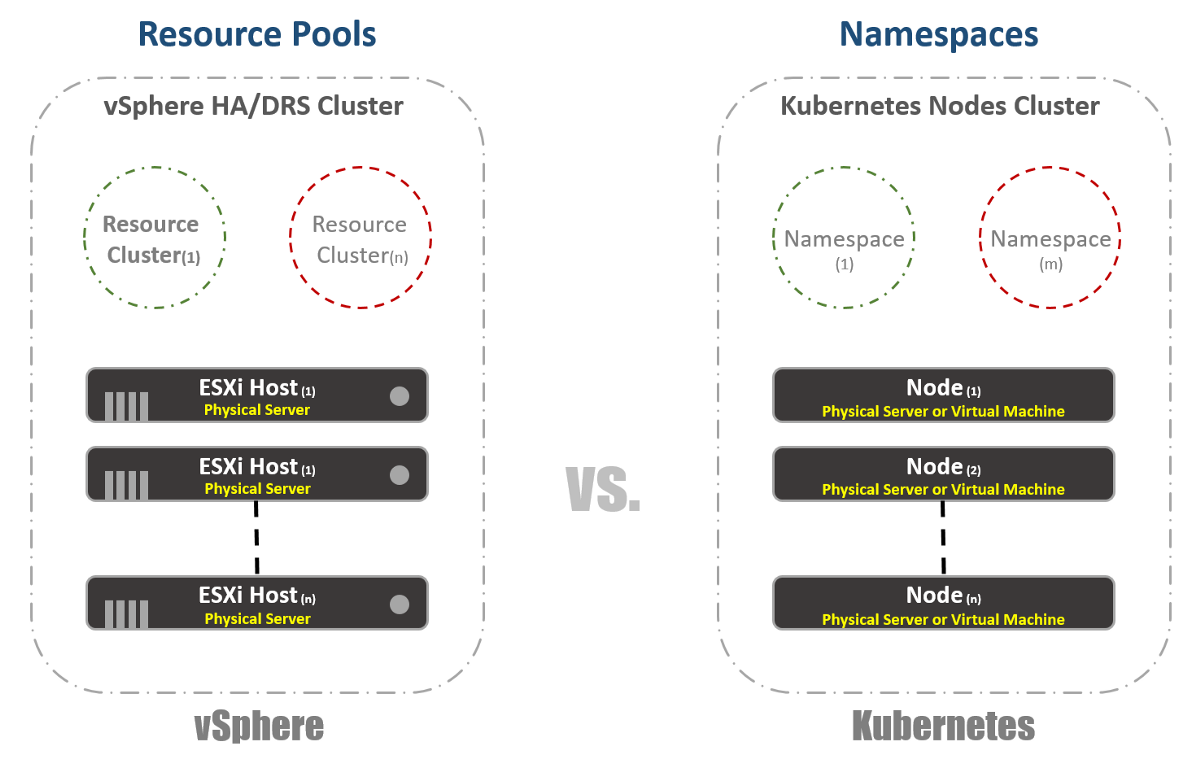
إدارة الموارد
كما ذكرت في القسم السابق ، شائع استخدام مساحات الأسماء في Kubernetes كوسيلة للتجزئة. استخدام آخر من مساحات الأسماء هو تخصيص الموارد. يسمى هذا الخيار "حصص الموارد". كما يلي من الأقسام السابقة ، يحدث تعريف هذا في ملفات التكوين YAML ، والتي يتم الإعلان عن الحالة المطلوبة. في vSphere ، كما يظهر في لقطة الشاشة أدناه ، نحدد ذلك من إعدادات Resource Pools.

تحديد عبء العمل
هذا بسيط جدًا وتقريباً بالنسبة إلى vSphere و Kubernetes. في الحالة الأولى ، نستخدم مفاهيم العلامات لتعريف (أو تجميع) أعباء العمل المتشابهة ، وفي الحالة الثانية نستخدم المصطلح "تسميات". في حالة Kubernetes ، يعد تحديد عبء العمل إلزاميًا.

تحفظ
الآن للمتعة الحقيقية. إذا كنت من محبي vSphere FT ، مثلي ، فأنت ستحب هذه الميزة في Kubernetes ، على الرغم من بعض الاختلافات في التقنيتين. في vSphere ، إنه جهاز ظاهري به مثيل ظل يعمل على مضيف مختلف. نقوم بتسجيل الإرشادات على الجهاز الظاهري الرئيسي وإعادة تشغيلها على الجهاز الظاهري للظل. إذا توقف الجهاز الرئيسي عن العمل ، يتم تشغيل الجهاز الظاهري للظلال على الفور. ثم يحاول vSphere العثور على مضيف ESXi آخر لإنشاء مثيل ظل جديد للجهاز الظاهري للحفاظ على التكرار نفسه. في Kubernetes ، لدينا شيء مشابه للغاية. ReplicaSets هو المبلغ الذي تحدده لتشغيل مثيلات متعددة من السنفات. في حالة فشل قرنة واحدة ، تتوفر مثيلات أخرى لخدمة حركة المرور. في الوقت نفسه ، ستحاول K8s إطلاق Pod جديد على أي عقدة متاحة من أجل الحفاظ على حالة التكوين المطلوبة. الفرق الرئيسي ، كما لاحظتم بالفعل ، هو أنه في حالة K8s ، تعمل Pods دائمًا وتخدم حركة المرور. فهي ليست عبء العمل الظل.

تحميل موازنة
على الرغم من أن هذا قد لا يكون وظيفة مضمنة في vSphere ، فمن الضروري جدًا في الغالب تشغيل موازنات التحميل على النظام الأساسي. في عالم vSphere ، يوجد موازن تحميل افتراضي أو فعلي لتوزيع حركة مرور الشبكة بين أجهزة افتراضية متعددة. قد يكون هناك العديد من أوضاع التكوين المختلفة ، ولكن لنفترض أننا نعني التكوين أحادي السلاح. في هذه الحالة ، يمكنك موازنة عبء حركة المرور بين الشرق والغرب على أجهزتك الافتراضية.
وبالمثل ، لدى Kubernetes مفهوم "الخدمات". يمكن أيضًا استخدام الخدمة في K8s في أوضاع تكوين مختلفة. دعنا نختار تكوين "ClusterIP" لمقارنته مع موازن التحميل الأحادي. في هذه الحالة ، سيكون للخدمة في K8s عنوان IP ظاهري (VIP) ، ثابت دائمًا ولا يتغير. سيقوم VIP هذا بتوزيع حركة المرور بين عدة قرون. هذا مهم بشكل خاص في عالم Kubernetes ، حيث تكون Pods بطبيعتها سريعة الزوال ، وتفقد عنوان IP الخاص بـ Pod في لحظة وفاته أو حذفه. لذلك ، يجب عليك دائمًا تقديم VIP ثابت.
كما ذكرت سابقًا ، تشتمل الخدمة على العديد من التكوينات الأخرى ، على سبيل المثال ، "NodePort" ، حيث تقوم بتعيين منفذ على مستوى العقدة ثم تقوم بإجراء ترجمة ترجمة عنوان المنفذ لـ Pods. يوجد أيضًا "LoadBalancer" حيث تقوم بتشغيل مثيل Load Balancer من جهة خارجية أو موفر سحابة.

لدى Kuberentes آلية أخرى مهمة للغاية لموازنة الحمل تسمى "مراقب الدخول". يمكنك اعتباره موازن تحميل تطبيق مضمن. الفكرة الرئيسية هي أن وحدة التحكم في الدخول (في شكل قرنة) سيتم إطلاقها بعنوان IP مرئي من الخارج. قد يحتوي عنوان IP هذا على شيء مثل سجلات Wildcard DNS. عندما تصل حركة المرور إلى Ingress Controller باستخدام عنوان IP خارجي ، فإنها تتحقق من الرؤوس وتحدد باستخدام مجموعة القواعد التي قمت بتعيينها مسبقًا على اسم Pod الذي ينتمي إليه. على سبيل المثال: سيتم توجيه sphinx-v1.esxcloud.net إلى Service sphinx-svc-1 ، وسيتم توجيه sphinx-v2.esxcloud.net إلى Service sphinx-svc2 ، إلخ.

التخزين والشبكة
تعتبر التخزين والتواصل من المواضيع الواسعة للغاية عندما يتعلق الأمر بـ Kubernetes. يكاد يكون من المستحيل التحدث باختصار عن هذين الموضوعين في منشور تمهيدي ، لكنني سأتحدث قريبًا بالتفصيل عن المفاهيم والخيارات المختلفة لكل موضوع من هذه الموضوعات. في غضون ذلك ، دعونا ننظر بسرعة في كيفية عمل مكدس الشبكة في Kubernetes ، حيث سنحتاجه في القسم التالي.
يوجد لدى Kubernetes العديد من "الإضافات" التي يمكنك استخدامها لتكوين شبكة العقد والعقد. أحد المكونات الإضافية الشائعة هو "kubenet" ، والذي يستخدم حاليًا في السحب الضخمة مثل GCP و AWS. هنا سأتحدث باختصار عن تنفيذ برنامج "شركاء Google المعتمدون" ، ثم أعرض مثالًا عمليًا للتنفيذ في GKE.

للوهلة الأولى ، قد يبدو هذا الأمر معقدًا للغاية ، لكنني آمل أن تتمكن من فهم كل هذا بنهاية هذا المنشور. أولاً ، نرى أن لدينا عقدة Kubernetes: Node 1 و Node (m). كل عقدة لها واجهة eth0 ، مثل أي جهاز Linux. تحتوي هذه الواجهة على عنوان IP للعالم الخارجي ، في حالتنا ، على الشبكة الفرعية 10.140.0.0/24. يعمل جهاز Upstream L3 كبوابة افتراضية لتوجيه حركة المرور الخاصة بنا. يمكن أن يكون مفتاح L3 في مركز البيانات الخاص بك أو جهاز توجيه VPC في السحابة ، مثل GCP ، كما سنرى لاحقًا. هل كل شيء على ما يرام؟
كذلك نرى أن لدينا واجهة جسر cbr0 داخل العقدة. هذه الواجهة هي البوابة الافتراضية لشبكة IP الفرعية 10.40.1.0/24 في حالة العقدة 1. تم تعيين هذه الشبكة الفرعية بواسطة Kubernetes لكل عقدة. تحصل العقد عادةً على / 24 شبكة فرعية ، ولكن يمكنك تغيير ذلك باستخدام NSX-T (سنقوم بتغطية ذلك في المنشورات التالية). في الوقت الحالي ، هذه الشبكة الفرعية هي الشبكة التي سنصدر منها عناوين IP لـ Pods. بهذه الطريقة ، سيحصل أي قرنة داخل العقدة 1 على عنوان IP من هذه الشبكة الفرعية. في حالتنا ، يحتوي Pod 1 على عنوان IP بقيمة 10.40.1.10. ومع ذلك ، لاحظت أن هناك حاويات متداخلة اثنين في هذا قرنة. لقد سبق أن قلنا أنه يمكن إطلاق حاوية واحدة أو عدة حاويات ، والتي ترتبط ارتباطًا وثيقًا ببعضها البعض من حيث الوظيفة. هذا هو ما نراه في الشكل. يستمع الحاوية 1 على المنفذ 80 ، ويستمع الحاوية 2 على المنفذ 90. كلتا الحاويتين لهما نفس عنوان IP 10.40.1.10 ، لكنهما لا يملكان مساحة شبكة الاتصال. حسنًا ، إذن من يمتلك مكدس الشبكة هذا؟ في الواقع هناك حاوية خاصة تسمى "إيقاف مؤقت للحاوية". يوضح المخطط أن عنوان IP الخاص به هو عنوان IP الخاص بـ Pod للتواصل مع العالم الخارجي. وبالتالي ، فإن Pause Container تمتلك رصة الشبكة هذه ، بما في ذلك عنوان IP 10.40.1.10 نفسه ، وبطبيعة الحال ، فإنه يعيد توجيه حركة المرور إلى الحاوية 1 إلى المنفذ 80 ، وكذلك يعيد توجيه حركة المرور إلى الحاوية 2 إلى المنفذ 90.
الآن عليك أن تسأل كيف يتم إعادة توجيه حركة المرور إلى العالم الخارجي؟ لقد تم تمكين Linux IP Forwarding القياسي لإعادة توجيه حركة المرور من cbr0 إلى eth0. هذا شيء رائع ، ولكن بعد ذلك ليس من الواضح كيف يمكن لجهاز L3 تعلم كيفية إعادة توجيه حركة المرور إلى وجهتها؟ في هذا المثال المحدد ، ليس لدينا توجيه ديناميكي للإعلان عن هذه الشبكة. لذلك ، يجب أن يكون لدينا نوع من التوجيهات الثابتة على جهاز L3. للوصول إلى الشبكة الفرعية 10.40.1.0/24 ، تحتاج إلى إعادة توجيه حركة المرور إلى عنوان IP Node 1 (10.140.0.11) والوصول إلى 10.40.2.0/24 الشبكة الفرعية الأمل التالي هو Node (m) بعنوان IP 10.140.0.12.
كل هذا رائع ، لكنه طريقة غير عملية لإدارة شبكاتك. سيكون دعم كل هذه المسارات مع توسيع نطاق نظامك بمثابة كابوس مطلق لمسؤولي الشبكات. هذا هو السبب في أن بعض الحلول ، مثل CNI (واجهة شبكة الحاويات) في Kuberentes ، ضرورية لإدارة اتصال الشبكة. NSX-T هو واحد من هذه الحلول مع وظائف واسعة للغاية لكل من تفاعل الشبكة والأمن.
تذكر أننا نظرنا إلى البرنامج المساعد kubenet ، وليس CNI. المكوّن الإضافي kubenet هو ما يستخدمه Google Container Engine (GKE) ، وطريقة القيام به ممتعة جدًا لأنه يتم تعريف البرنامج بالكامل وأتمتة في السحابة الخاصة به. , GCP. .
ما التالي؟
Kuberentes. ,
.
الجزء الثاني.. .
.