
 أنطون شاينيكوف ، مطور علوم البيانات ، Redmadrobot
أنطون شاينيكوف ، مطور علوم البيانات ، Redmadrobot
مرحبا يا هبر! سأتحدث اليوم عن المصاعب التي هي في الطريق إلى chatbot ، مما يسهل عمل مشغلي الدردشة في شركة التأمين. بتعبير أدق ، كيف علمنا الروبوت لتمييز الطلبات عن بعضها البعض باستخدام التعلم الآلي. ما هي النماذج التي جربتها وأي منها حصلت على النتائج. كيف قامت أربعة طرق لتنظيف وإثراء البيانات ذات الجودة اللائقة وخمس محاولات لتنظيف البيانات ذات الجودة "غير اللائقة".
التحدي
تستقبل دردشة شركة التأمين +100500 مكالمة عميل يوميًا. معظم الأسئلة بسيطة ومتكررة ، لكن المشغلين ليسوا أسهل ، ولا يزال يتعين على العملاء الانتظار من خمس إلى عشر دقائق. كيف يمكن تحسين جودة الخدمة وتحسين تكاليف العمالة بحيث يكون لدى المشغلين روتين أقل ويكون لدى المستخدمين أحاسيس أكثر متعة من حل مشكلاتهم بسرعة؟
ونحن سوف نفعل chatbot. دعه يقرأ رسائل المستخدم ، ويقدم تعليمات للحالات البسيطة ، وطرح أسئلة قياسية للحالات المعقدة للحصول على المعلومات التي يحتاجها المشغل. لدى المشغل المباشر شجرة نصية - برنامج نصي (أو مخطط انسيابي) يوضح الأسئلة التي قد يطرحها المستخدمون وكيفية الرد عليها. سنأخذ هذا المخطط ونضعه في دردشة chatbot ، لكنه سيء - لا يفهم chatbot إنسانيًا ولا يعرف كيفية ربط سؤال المستخدم بفرع البرنامج النصي.
لذلك ، سوف نعلمه بمساعدة تعلم الآلة القديم الجيد. لكن لا يمكنك فقط أخذ جزء من البيانات التي تم إنشاؤها بواسطة المستخدمين وتعليمه نموذجًا جيدًا للجودة. للقيام بذلك ، تحتاج إلى تجربة بنية النموذج والبيانات لتنظيفه ، وجمعه مرة أخرى في بعض الأحيان.
كيفية تدريس الروبوت:
- النظر في خيارات النموذج: كيف يتم الجمع بين حجم مجموعة البيانات ، وتفاصيل اتجاه النصوص ، وخفض البعد ، والمصنف والدقة النهائية.
- لنقم بتنظيف البيانات المناسبة: سنجد فصولًا يمكن إلقاؤها بأمان ؛ سنكتشف لماذا الأشهر الستة الأخيرة من الترميز أفضل من الثلاثة السابقة ؛ تحديد المكان الذي يكمن فيه النموذج ، ومكان العلامات ؛ اكتشف كيف يمكن أن تكون الأخطاء المطبعية مفيدة.
- سنقوم بتنظيف البيانات "غير اللائقة": سنكتشف في الحالات التي يكون فيها التجميع مفيدًا وغير مجدي ، حيث يتحدث المستخدمون والمشغلون عندما حان الوقت للتوقف عن المعاناة والانتقال لجمع العلامات.
الملمس
كان لدينا عميلان - شركات التأمين مع الدردشات عبر الإنترنت - ومشاريع التدريب chatbot (لن ندعو لهم ، وهذا ليس بالأهمية) ، مع جودة البيانات المختلفة بشكل حاد. حسنًا ، إذا تم حل نصف مشاكل المشروع الثاني عن طريق التلاعب من الأول. التفاصيل أدناه.
من وجهة نظر تقنية ، مهمتنا هي تصنيف النصوص. يتم ذلك على مرحلتين: أولاً يتم توجيه النصوص (باستخدام tf-idf ، doc2vec ، وما إلى ذلك) ، ثم يتم تدريب نموذج التصنيف على المتجهات (والفئات) التي تم الحصول عليها - مجموعة عشوائية ، SVM ، شبكة عصبية ، وما إلى ذلك. و هكذا.
من أين تأتي البيانات؟
- SQL تحميل سجل الدردشة. حقول التحميل ذات الصلة: نص الرسالة ؛ المؤلف (العميل أو المشغل) ؛ تجميع الرسائل في مربعات الحوار ؛ الطابع الزمني فئة الاتصال بالعملاء (أسئلة حول التأمين الإلزامي للمسؤولية الحركية ، التأمين على البدن ، التأمين الطبي الطوعي ، أسئلة حول الموقع ، أسئلة حول برامج الولاء ، أسئلة حول تغيير شروط التأمين ، إلخ).
- مجموعة من النصوص أو تسلسل الأسئلة والأجوبة من المشغلين للعملاء مع طلبات مختلفة.
دون التحقق من الصحة ، بالطبع ، في أي مكان. تم تدريب جميع النماذج على 70 ٪ من البيانات وتقييمها وفقا للنتائج على 30 ٪ المتبقية.
مقاييس الجودة للنماذج التي استخدمناها:
- في التدريب: logloss ، من أجل التباين ؛
- عند كتابة التقارير: دقة التصنيف في عينة اختبار ، من أجل البساطة والوضوح (بما في ذلك للعميل) ؛
- عند اختيار الاتجاه لمزيد من الإجراءات: الحدس من عالم البيانات الذي يحدق باهتمام في النتائج.
تجارب نموذجية
من النادر أن توضح المهمة فورًا النموذج الذي سيعطي أفضل النتائج. حتى هنا: دون التجريب ، في أي مكان.
سنحاول خيارات vectorization:
- tf-idf في كلمات واحدة ؛
- tf-idf على ثلاثة أضعاف الشخصيات (فيما يلي: 3 غرامات) ؛
- tf-idf على 2- ، 3- ، 4- ، 5 غرام بشكل منفصل ؛
- tf-idf على 2- ، 3- ، 4- ، 5 غرامات مجمعة ؛
- كل ما سبق + اختزال الكلمات في النص المصدر إلى نموذج القاموس ؛
- كل ما سبق + انخفاض في البعد بواسطة أسلوب SVD مبتوراً ؛
- مع عدد القياسات: 10 ، 30 ، 100 ، 300 ؛
- doc2vec ، المدربين على نصوص من المهمة.
تبدو خيارات التصنيف في ظل هذه الخلفية ضعيفة: SVM و XGBoost و LSTM والغابات العشوائية والخلجان الساذجة والغابات العشوائية أعلى تنبؤات SVM و XGB.
وعلى الرغم من أننا فحصنا إمكانية استنساخ النتائج في ثلاث مجموعات بيانات مجمعة بشكل مستقل وشظاياها ، إلا أننا لا يمكننا إلا أن نضمن إمكانية التطبيق على نطاق واسع.
نتائج التجارب:
- في سلسلة "تصنيف أبعاد خفض المعالجة قبل المعالجة" ، يكون تأثير الاختيار في كل خطوة شبه مستقل عن الخطوات الأخرى. وهو ملائم للغاية ، لا يمكنك المرور بعشرات الخيارات مع كل فكرة جديدة واستخدام الخيار الأكثر شهرة في كل خطوة.
- tf-idf في الكلمات يفقد إلى 3 غرامات (دقة 0.72 مقابل 0.78). 2- ، 4 ، 5 غرام تخسر إلى 3 غرامات (0،75-0،76 مقابل 0،78). {2 ؛ 5} - يتفوق كل المرات معًا تمامًا على 3 غرامات. نظرًا للزيادة الحادة في الذاكرة المطلوبة ، قررنا إهمال التدريب بزيادة قدرها 0.4٪ من الدقة.
- مقارنة بـ tf-idf لجميع الأصناف ، كان doc2vec عاجزًا (دقة 0.4 وتحت). يجدر محاولة تدريبه ليس على السلك من المهمة (حوالي 250000 نص) ، ولكن على نص أكبر بكثير (2.5 - 25 مليون نص) ، ولكن حتى الآن ، للأسف ، لم تصل يديك.
- لم SVD اقتطاع لا يساعد. تزداد الدقة بشكل رتيب مع زيادة القياس ، وتحقيق الدقة بسلاسة دون TSVD.
- من بين المصنفين ، يفوز XGBoost بهامش ملحوظ (+ 5-10 ٪). أقرب المنافسين هم SVM والغابات العشوائية. السذاجة بايز ليست منافسا حتى للغابات عشوائية.
- يعتمد نجاح LSTM اعتمادًا كبيرًا على حجم مجموعة البيانات: على عينة مكونة من 100000 كائن ، يمكنها المنافسة مع XGB. على عينة من 6000 - في المتخلفة جنبا إلى جنب مع Bayes.
- غابة عشوائية على رأس SVM و XGB إما يتفق دائما مع XGB ، أو هو مخطئ أكثر. هذا أمر محزن جدًا ، نأمل أن تجد SVM في البيانات على الأقل بعض الأنماط غير المتوفرة لـ XGB ، ولكن للأسف.
- XGBoost معقد مع الاستقرار. على سبيل المثال ، أدت ترقيته من الإصدار 0.72 إلى 0.80 بشكل غير مفهوم إلى تقليل دقة النماذج المدربة بنسبة 5-10٪. وهناك شيء آخر: يدعم XGBoost تغيير معلمات التدريب أثناء التدريب والتوافق مع واجهة برمجة تطبيقات scikit-Learn القياسية ، ولكن بشكل منفصل تمامًا. لا يمكنك القيام بالأمرين معا. كان لاصلاحها.
- إذا قمت بإحضار كلمات إلى نموذج القاموس ، فسيؤدي ذلك إلى تحسين الجودة قليلاً ، بالاقتران مع tf-idf بالكلمات ، لكنه غير مجدي في جميع الحالات الأخرى. في النهاية ، قمنا بإيقاف تشغيله لتوفير الوقت.
تجربة 1. تنظيف البيانات ، أو ما يجب القيام به مع العلامات
مشغلي الدردشة هم مجرد أشخاص. عند تحديد فئات استعلامات المستخدم ، غالبًا ما تكون خاطئة ولديها تفسيرات مختلفة للحدود بين الفئات. لذلك ، يجب تنظيف البيانات المصدر بلا رحمة ومكثفة.
بياناتنا عن التدريب النموذجي على المشروع الأول:
- تاريخ رسائل الدردشة عبر الإنترنت على مدار عدة سنوات. هذا هو 250،000 وظيفة في 60،000 المحادثات. في نهاية الحوار ، اختار المشغل الفئة التي تنتمي إليها دعوة المستخدم. هناك حوالي 50 فئة في مجموعة البيانات هذه.
- شجرة البرنامج النصي. في حالتنا ، لم يكن لدى المشغلين نصوص عمل.
ما هي بالضبط البيانات السيئة ، قمنا بصياغتها كفرضيات ، ثم فحصناها وتصحيحها ، حيثما أمكن. إليك ما حدث:
النهج الأول. من بين قائمة الدروس الضخمة بأكملها ، يمكنك ترك 5-10 بأمان.
نتجاهل الفصول الصغيرة (<1٪ من العينة): بيانات قليلة + تأثير صغير. نحن نوحِّد الطبقات التي يصعب التمييز بينها ، والتي لا يزال المشغلون يتفاعلون معها بنفس الطريقة. على سبيل المثال:
"dms" + "كيفية تحديد موعد مع الطبيب" + "سؤال حول ملء البرنامج"
"الإلغاء" + "حالة الإلغاء" + "إلغاء السياسة المدفوعة"
"سؤال التجديد" + "كيفية تجديد السياسة؟"
بعد ذلك ، نطرح فئات مثل "أخرى" و "أخرى" وما شابه ذلك: بالنسبة إلى chatbot ، فهي عديمة الفائدة (إعادة التوجيه إلى المشغل على أي حال) ، وفي الوقت نفسه فإنها تلحق الضرر بدرجة كبيرة من الدقة ، حيث يتم تصنيف 20٪ من الطلبات (30 ، 50 ، 90) من قبل المشغلين بشكل غير لائق و هنا. الآن نطرد الفصل الذي لا يعمل chatbot معه (بعد).
النتيجة: في حالة واحدة ، النمو من دقة 0.40 إلى 0.69 ، في حالة أخرى ، من 0.66 إلى 0.77.
النهج الثاني. في بداية الدردشة ، يفهم المشغلون أنفسهم بشكل سيئ كيفية اختيار فصل دراسي للمستخدم للاتصال به ، لذلك هناك الكثير من "الضوضاء" والأخطاء في البيانات.
التجربة: نحن نأخذ فقط شهرين (ثلاثة ، ستة ، ...) من الحوارات ونقوم بتدريب النموذج
لهم.
النتيجة: في إحدى الحالات الرائعة ، زادت الدقة من 0.40 إلى 0.60 ، وفي حالة أخرى - من 0.69 إلى 0.78.
النهج الثالث. في بعض الأحيان ، لا تعني الدقة التي تبلغ 0.70 "النموذج خاطئ في 30٪ من الحالات" ، ولكن "في 30٪ من الحالات يكذب الترميز ، ويصححه النموذج بشكل معقول للغاية".
من خلال مقاييس مثل الدقة أو logloss ، لا يمكن التحقق من هذه الفرضية. لأغراض التجربة ، اقتصرنا على نظرة عالم البيانات ، ولكن في الحالة المثالية ، تحتاج إلى إعادة ترتيب مجموعة البيانات نوعيًا ، دون أن ننسى التحقق المتبادل.
للعمل مع هذه العينات ، توصلنا إلى عملية "التخصيب التكراري":
- قسم مجموعة البيانات إلى 3-4 أجزاء.
- تدريب النموذج على الجزء الأول.
- التنبؤ بفصول الثاني من نموذج المدربين.
- إلقاء نظرة فاحصة على الطبقات المتوقعة ودرجة ثقة النموذج ، اختر قيمة حدود الثقة.
- قم بإزالة النصوص (الكائنات) المتوقعة بثقة أسفل الحد من الجزء الثاني ، وقم بتدريب النموذج على هذا.
- كرر ذلك حتى تتعب الشظايا أو تنفد.
من ناحية ، كانت النتائج ممتازة: نموذج التكرار الأول لديه دقة 70 ٪ ، والثاني - 95 ٪ ، والثالث - 99 + ٪. إن إلقاء نظرة فاحصة على نتائج التنبؤات يؤكد هذه الدقة تمامًا.
من ناحية أخرى ، كيف يمكن للمرء التحقق بشكل منهجي في هذه العملية من أن النماذج التالية لا تتعلم أخطاء النماذج السابقة؟ هناك فكرة لاختبار العملية على مجموعة بيانات "صاخبة" يدويًا مع ترميز أولي عالي الجودة ، مثل MNIST. ولكن ، للأسف ، لم يكن هناك ما يكفي من الوقت لذلك. وبدون تحقق ، لم نجرؤ على إطلاق التخصيب التكراري والنماذج الناتجة في الإنتاج.
النهج الرابع. يمكن توسيع مجموعة البيانات - وبالتالي زيادة الدقة وتقليل إعادة التدريب ، إضافة العديد من الأخطاء المطبعية إلى النصوص الموجودة.
الأخطاء المطبعية هي أخطاء مطبعية - مضاعفة حرف ، وتخطي حرف ، وإعادة ترتيب الحروف المجاورة في الأماكن ، واستبدال حرف بحرف مجاور على لوحة المفاتيح.
التجربة: نسبة الحروف p التي سيحدث فيها خطأ مطبعي: 2٪ ، 4٪ ، 6٪ ، 8٪ ، 10٪ ، 12٪. زيادة مجموعة البيانات: عادةً ما يصل إلى 60000 نسخة متماثلة. اعتمادًا على الحجم الأولي (بعد المرشحات) ، يعني هذا زيادة قدرها 3-30 مرة.
النتيجة: يعتمد على مجموعة البيانات. في مجموعة بيانات صغيرة (حوالي 300 نسخة متماثلة) ، تعطي نسبة تتراوح من 4 إلى 6٪ من الأخطاء المطبعية زيادة ثابتة ودقة في الدقة (0.40 → 0.60). في مجموعات البيانات الكبيرة ، كل شيء أسوأ. مع نسبة الأخطاء المطبعية 8٪ أو أكثر ، تتحول النصوص إلى هراء وتنخفض الدقة. عند معدل خطأ يتراوح بين 2 إلى 8٪ ، تتقلب الدقة في حدود بضعة بالمائة ، ونادراً ما تتجاوز الدقة بدون أخطاء مطبعية ، وكما يبدو ، ليست هناك حاجة لزيادة وقت التدريب عدة مرات.
نتيجة لذلك ، حصلنا على نموذج يميز 5 فئات من المكالمات بدقة 0.86. نحن ننسق مع العميل نصوص الأسئلة والأجوبة لكل من الشوكات الخمسة ، ونربط النصوص إلى chatbot ، ونرسلها إلى QA.
تجربة 2. الركبة في البيانات ، أو ما يجب القيام به دون العلامات
بعد الحصول على نتائج جيدة في المشروع الأول ، اقتربنا من المشروع الثاني بكل ثقة. لكن لحسن الحظ ، لم ننسى كيف نتفاجأ.
ما التقينا به:
- شجرة نصية من خمسة فروع متفق عليها مع العميل منذ حوالي عام.
- عينة معلمة من 500 رسالة و 11 فئة من أصل غير معروف.
- يتم تمييزها بواسطة مشغلي الدردشة من 220،000 رسالة و 21000 محادثة و 50 فصلًا آخر.
- نموذج SVM ، المدربين على العينة الأولى ، بدقة 0.69 ، التي ورثتها من الفريق السابق من علماء البيانات. لماذا SVM ، التاريخ صامت.
بادئ ذي بدء ، ننظر إلى الفئات: في شجرة البرنامج النصي ، في نموذج نموذج SVM ، في العينة الرئيسية. وهنا ما نراه:
- تتوافق فئات نموذج SVM تقريبًا مع فروع البرامج النصية ، ولكن لا تتوافق بأي حال مع فئات من عينة كبيرة.
- تمت كتابة شجرة البرنامج النصي على العمليات التجارية قبل عام ، وهي عديمة الجدوى تقريبًا. تم إهمال طراز SVM به.
- أكبر فئتين في العينة الكبيرة هي المبيعات (50٪) والأخرى (45٪).
- من بين الفئات الخمس الأكبر التالية ، هناك ثلاثة فئات عامة مثل المبيعات.
- تحتوي الفئات 45 المتبقية على أقل من 30 مربع حوار لكل منهما. أي ليس لدينا شجرة نصية ، لا توجد قائمة بالصفوف ولا علامات.
ماذا تفعل في مثل هذه الحالات؟ لقد طبعنا عن سواعدنا وذهبنا لوحدنا للحصول على دروس وترميز من البيانات.
المحاولة الأولى. دعنا نحاول تجميع أسئلة المستخدمين ، أي الرسائل الأولى في الحوار ، باستثناء التحيات.
نحن نتحقق. نحن نوجه النسخ المتماثلة عن طريق حساب 3 غرامات. نحن خفض البعد إلى القياسات العشرة الأولى من TSVD. نتجمع عن طريق التكتل العنقودي مع المسافة الإقليدية ووظيفة وارد المستهدفة. قم بخفض البعد مرة أخرى باستخدام t-SNE (حتى قياسين حتى تتمكن من رؤية النتائج بعينيك). نرسم نقاط طبق الأصل على متن الطائرة ، نرسم بألوان المجموعات.
النتيجة: الخوف والرعب. مجموعات Sane ، يمكننا أن نفترض أنه لا يوجد:
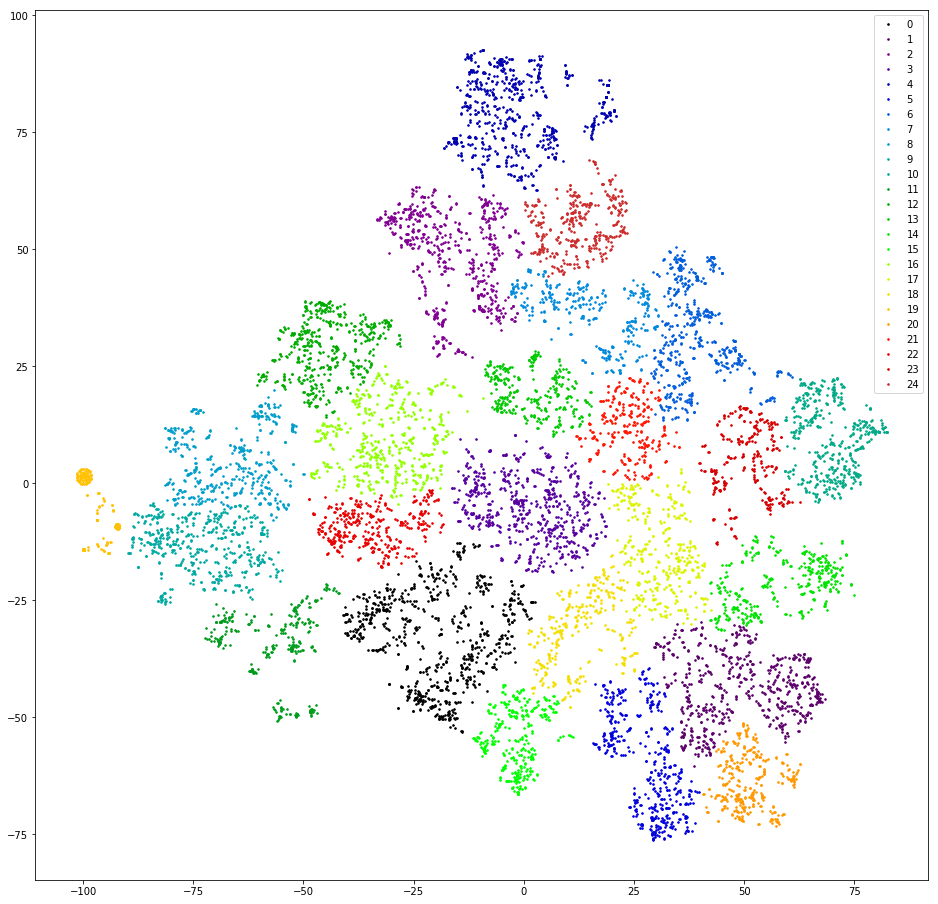
لا تقريبًا - هناك برتقالة واحدة على اليسار ، وذلك لأن جميع الرسائل الموجودة فيها تحتوي على "@" 3 غرامات. هذا 3 غرام هو قطعة أثرية قبل المعالجة. في مكان ما أثناء عملية تصفية علامات الترقيم ، لم يتم تصفية "@" فحسب ، بل أيضًا تم تضخيمه بمسافات. لكن الأداة مفيدة. تتضمن هذه المجموعة المستخدمين الذين يكتبون بريدهم الإلكتروني أولاً. لسوء الحظ ، فقط من خلال توفر البريد ، من غير الواضح تمامًا ما هو طلب المستخدم. نحن نمضي قدما.
المحاولة الثانية. ماذا لو كان المشغلون يستجيبون في الغالب بروابط قياسية أو أكثر؟
نحن نتحقق. نقوم باستخراج سلاسل فرعية تشبه الارتباط من رسائل المشغل ، ونصحح الارتباطات قليلاً ، ونختلف في التهجئة ، ولكن نفس المعنى (http / https ، / search؟ المدينة =٪ city٪) ، نحن نعتبر ترددات الارتباط.
النتيجة: غير واعدة. أولاً ، يستجيب المشغلون فقط لجزء صغير من الطلبات (أقل من 10٪) مع الارتباطات. ثانياً ، حتى بعد التنظيف اليدوي وتصفية الروابط التي حدثت مرة واحدة ، هناك أكثر من ثلاثين منها. ثالثًا ، في سلوك المستخدمين الذين ينهون الحوار مع رابط ، لا يوجد تشابه معين.
المحاولة الثالثة. دعنا نبحث عن الإجابات القياسية للمشغلين - ماذا لو كانت مؤشرات لأي تصنيف للرسائل؟
نحن نتحقق. في كل حوار ، نأخذ آخر نسخة طبق الأصل من المشغل (بغض النظر عن الوداع: "يمكنني مساعدة شيء آخر ،" وما إلى ذلك) والنظر في تكرار النسخ المتماثلة الفريدة.
النتيجة: واعدة ، ولكن غير مريح. 50٪ من استجابات المشغل فريدة من نوعها ، وتم العثور على 10-20٪ أخرى مرتين ، بينما تمت تغطية 30 إلى 40٪ المتبقية بعدد صغير نسبيًا من القوالب الشائعة. صغيرة نسبيا - حوالي ثلاثمائة. تكشف نظرة فاحصة على هذه القوالب أن العديد منها عبارة عن أشكال مختلفة من نفس الإجابة من حيث المعنى - فهي تختلف من مكان إلى آخر بحرف ، ومن كلمة واحدة ، ومن خلال فقرة واحدة. أرغب في تجميع هذه الإجابات القريبة في المعنى.
المحاولة الرابعة. تقسيم أحدث النسخ المتماثلة للبيانات. يتم تجميعها بشكل أفضل بكثير:
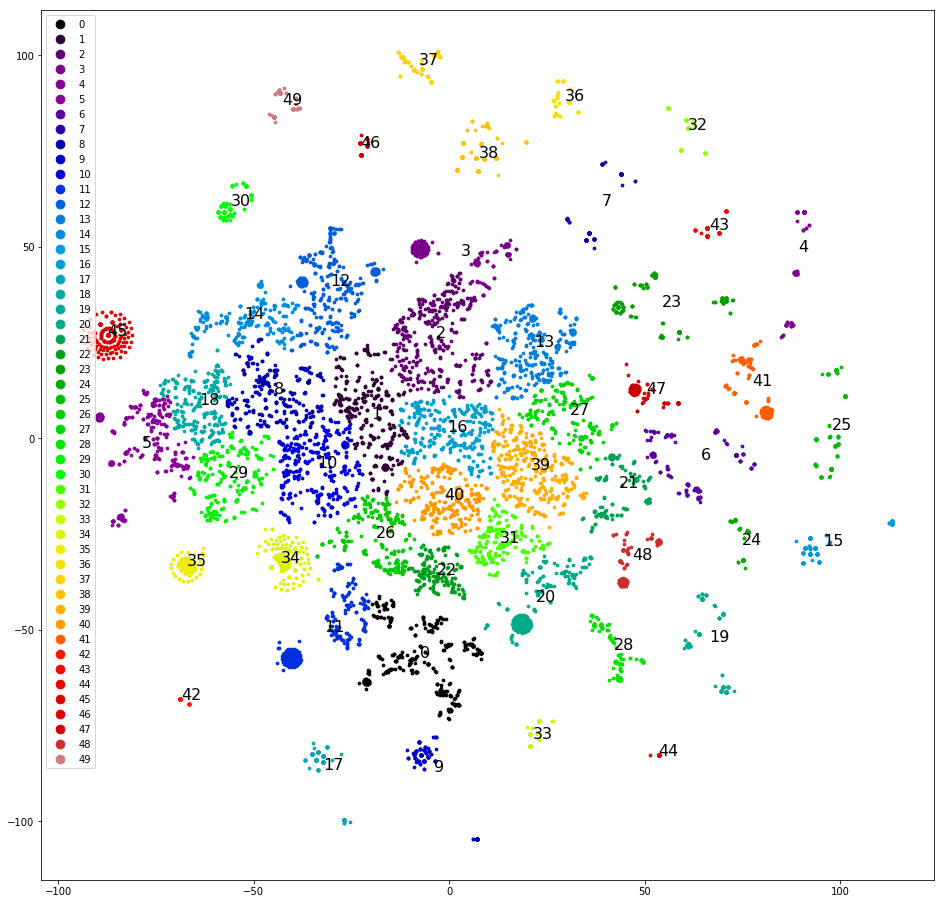
يمكنك بالفعل العمل مع هذا.
نحن نجمع ونرسم نسخاً متماثلة على متن الطائرة ، كما في المحاولة الأولى ، نحدد يدويًا المجموعات الأكثر فصلًا بشكل واضح ، ونقوم بإزالتها من مجموعة البيانات والتكتل مرة أخرى. بعد فصل حوالي نصف مجموعة البيانات ، تنتهي مجموعات المسح ، ونبدأ في التفكير في الفئات التي يجب تعيينها لهم. نحن نثرثر المجموعات وفقًا للفئات الخمسة الأصلية - العينة "منحرفة" ، ولا تتلقى ثلاثة من الفئات الخمسة الأصلية مجموعة واحدة. سيء للغاية نوزع المجموعات في خمس فئات ، نقوم بتعيينها بشكل عشوائي ، على: "call" ، "come" ، "انتظر يومًا للحصول على إجابة" ، "مشاكل مع captcha" ، "other". الانحراف أقل ، لكن الدقة لا تتجاوز 0.4-0.5. سيئة مرة أخرى. عيّن كل مجموعة من المجموعات الثلاثين + فئة خاصة بها. تم تحريف العينة مرة أخرى وكانت الدقة 0.5 مرة أخرى ، على الرغم من أن حوالي خمس فئات محددة تتمتع بالدقة الكاملة والكمال (0.8 وما فوق). لكن النتيجة لا تزال غير مؤثرة.
المحاولة الخامسة. نحن بحاجة إلى كل خصوصيات وعموميات التجميع. نقوم باسترداد dendrogram التجميع الكامل بدلاً من المجموعات الثلاثين الأعلى. نقوم بحفظه بتنسيق يمكن لمحللي العملاء الوصول إليه ومساعدتهم على وضع العلامات - نرسم قائمة الفئات.
لكل رسالة ، نحسب سلسلة من المجموعات ، والتي تتضمن كل رسالة ، بدءًا من الجذر. نحن نبني جدولًا يحتوي على أعمدة: النص ، معرف المجموعة الأولى في السلسلة ، معرف المجموعة الثانية في السلسلة ، ... ، معرف الكتلة المطابق للنص. نحفظ الجدول في CSV / XLS. علاوة على ذلك يمكنك العمل مع أدوات المكتب.
نحن نقدم البيانات ورسم لقائمة الفئات للتمييز للعميل. إعادة تحليل محللي العميل ~ 10000 من رسائل المستخدم الأولى. طلبنا ، من خلال التجربة بالفعل ، وضع علامة على كل رسالة مرتين على الأقل. وليس من دون جدوى - يجب التخلص من 4000 من هؤلاء 10،000 ، لأن المحللان تميزتا بشكل مختلف. في الـ 6000 المتبقية ، كررنا بسرعة نجاحات المشروع الأول:
- خط الأساس: لا توجد تصفية على الإطلاق - الدقة 0.66.
- نحن نجمع بين الفئات التي هي نفسها من وجهة نظر المشغل. نحصل على دقة 0.73.
- نزيل فئة "أخرى" - تزداد الدقة إلى 0.79.
النموذج جاهز ، والآن تحتاج إلى رسم شجرة نصية. لأسباب لا يمكننا شرحها ، لم نتمكن من الوصول إلى البرامج النصية لاستجابات المشغل. لم نتفاجأ ، لقد تظاهرنا بأننا مستخدمون ، وبضع ساعات في هذا المجال ، قمنا بجمع قوالب الاستجابة وتوضيح أسئلة المشغل لجميع المناسبات. قاموا بتزيينها في شجرة ، وعبأوها في روبوت وذهبوا للاختبار. وافق العملاء.
الاستنتاجات ، أو ما أظهرت التجربة:
- يمكنك تجربة أجزاء من النموذج (المعالجة المسبقة ، الموجه ، التصنيف ، إلخ) بشكل فردي.
- لا يزال XGBoost يحكم الكرة ، على الرغم من أنك إذا كنت بحاجة إلى شيء غير عادي ، فإنك تواجه مشكلات.
- المستخدم هو جهاز طرفي للإدخال الفوضوي ، لذلك تحتاج إلى تنظيف بيانات المستخدم.
- الإثراء التكراري بارد ، وإن كان خطيرًا.
- في بعض الأحيان ، من المفيد إعادة البيانات إلى العميل للترميز. ولكن لا تنس مساعدته في الحصول على نتيجة جيدة.
أن تنتهي.