
يركز موضوع المقالة بشكل ضيق ، ولكنه قد يكون مفيدًا لأولئك الذين يقومون بتطوير مستودعات البيانات الخاصة بهم والتفكير في التكامل مع Spring Framework.
الخلفية
عادةً لا يرغب المطورون في تغيير عاداتهم (غالبًا ما يتم تضمين الأُطُر أيضًا في قائمة العادات). عندما بدأت العمل مع CUBA ، لم يكن من الضروري أن أتعلم الكثير من الأشياء الجديدة ، فقد كان من الممكن أن أشارك بنشاط في العمل في المشروع على الفور تقريبًا. ولكن كان هناك شيء واحد اضطررت إلى الجلوس لفترة أطول - كان العمل مع البيانات.
يحتوي Spring على العديد من المكتبات التي يمكن استخدامها للعمل مع قاعدة البيانات ، واحدة من أكثرها شعبية هي spring-data-jpa ، والتي تسمح في معظم الحالات بعدم كتابة SQL أو JPQL. تحتاج فقط إلى إنشاء واجهة خاصة مع الأساليب التي يتم تسميتها بطريقة خاصة ، وسوف يقوم Spring بإنشاء والقيام ببقية العمل من أجلك على جلب البيانات من قاعدة البيانات وإنشاء مثيلات لكائنات الكيان.
يوجد أدناه الواجهة ، مع طريقة لحساب العملاء باسم العائلة المعطى.
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
يمكن استخدام هذه الواجهة مباشرة في خدمات Spring دون إنشاء أي تنفيذ ، مما يسرع العمل إلى حد كبير.
تحتوي CUBA على واجهة برمجة التطبيقات للتعامل مع البيانات ، والتي تتضمن وظائف متنوعة مثل الكيانات المحملة جزئيًا أو نظام أمان صعب مع التحكم في الوصول إلى سمات الكيانات والصفوف في جداول قاعدة البيانات. لكن واجهة برمجة التطبيقات هذه تختلف قليلاً عن ما اعتاد عليه المطورون في Spring Data أو JPA / Hibernate.
لماذا لا توجد مستودعات JPA في CUBA وهل يمكنني إضافتها؟
العمل مع البيانات في كوبا
في CUBA ، هناك ثلاث فئات رئيسية مسؤولة عن العمل مع البيانات: DataStore و EntityManager و DataManager.
DataStore عبارة عن تجريد عالي المستوى لأي تخزين للبيانات: قاعدة البيانات أو نظام الملفات أو التخزين السحابي. تسمح لك واجهة برمجة التطبيقات هذه بإجراء العمليات الأساسية على البيانات. في معظم الحالات ، لا يحتاج المطورون إلى العمل مع DataStore مباشرةً ، إلا عند تطوير مستودع التخزين الخاص بهم ، أو إذا كان هناك حاجة إلى وصول خاص للغاية إلى البيانات في المخزون.
EntityManager هو نسخة من JPA EntityManager المعروفة. بخلاف التنفيذ القياسي ، فإنه يحتوي على أساليب خاصة للعمل مع تمثيلات CUBA ، لحذف البيانات "المنطقي" (المنطقي) ، وأيضًا للعمل مع الاستعلامات في CUBA . كما هو الحال في DataStore ، في 90٪ من المشاريع ، لن يضطر المطور العادي إلى التعامل مع EntityManager ، إلا عندما يكون ذلك ضروريًا لتلبية بعض الطلبات التي تتجاوز نظام تقييد الوصول إلى البيانات.
DataManager هي الفئة الرئيسية للعمل مع البيانات في CUBA. يوفر واجهة برمجة تطبيقات لمعالجة البيانات ويدعم التحكم في الوصول إلى البيانات ، بما في ذلك الوصول إلى السمات وقيود مستوى الصف. يعدل DataManager ضمنيًا كافة الاستعلامات التي تعمل في CUBA. على سبيل المثال ، يمكن أن يستثني حقول الجدول التي لا يتمتع المستخدم الحالي بإمكانية الوصول إليها من عبارة select وإضافة شروط استبعاد صفوف الجدول من التحديد. وهذا يجعل الحياة أسهل للمطورين ، لأنه لا يتعين عليك التفكير في كيفية كتابة الاستعلامات بشكل صحيح مع مراعاة حقوق الوصول ، تقوم CUBA بذلك تلقائيًا بناءً على البيانات من جداول خدمة قاعدة البيانات.
فيما يلي رسم تخطيطي لتفاعل مكونات CUBA التي تشارك في جلب البيانات من خلال DataManager.
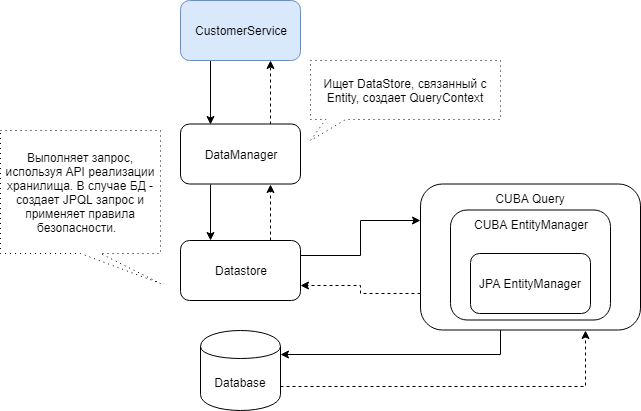
باستخدام DataManager ، يمكنك بسهولة تحميل كيانات هرمية كاملة من الكيانات باستخدام طرق عرض CUBA. في أبسط أشكاله ، يبدو الاستعلام كما يلي:
dataManager.load(Customer.class).list();
كما ذكرنا سابقًا ، ستقوم DataManager بتصفية السجلات "المحذوفة منطقياً" ، وإزالة السمات الممنوعة من الطلب ، وأيضًا فتح المعاملة وإغلاقها تلقائيًا.
ولكن ، عندما يتعلق الأمر باستفسارات أكثر تعقيدًا ، يجب عليك كتابة JPQL في CUBA.
على سبيل المثال ، إذا كنت بحاجة إلى حساب العملاء باسم العائلة المحدد ، كما هو موضح في المثال السابق ، فأنت بحاجة إلى كتابة شيء مثل هذا الرمز:
public Long countByLastName(String lastName) { return dataManager .loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class) .parameter("lastName", lastName) .one(); }
أو هكذا:
public Long countByLastName(String lastName) { LoadContext<Customer> loadContext = LoadContext.create(Customer.class); loadContext .setQueryString("select c from sample$Customer c where c.lastName = :lastName") .setParameter("lastName", lastName); return dataManager.getCount(loadContext); }
في واجهة برمجة تطبيقات CUBA ، تحتاج إلى تمرير تعبير JPQL كسلسلة (لم يتم دعم واجهة برمجة التطبيقات للمعايير) ، وهذه طريقة يمكن قراءتها ومفهومة لإنشاء استعلامات ، لكن تصحيح مثل هذه الاستعلامات يمكن أن يجلب الكثير من الدقائق الممتعة. بالإضافة إلى ذلك ، لا يتم التحقق من سلاسل JPQL بواسطة المترجم أو Spring Framework أثناء تهيئة الحاوية ، مما يؤدي إلى حدوث أخطاء فقط في وقت التشغيل.
قارن هذا مع Spring JPA:
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
الرمز أقصر ثلاث مرات ، ولا توجد خطوط. بالإضافة إلى ذلك ، countByLastName التحقق من اسم الأسلوب countByLastName أثناء تهيئة الحاوية Spring. إذا كان هناك خطأ مطبعي وقمت بكتابة countByLastNsme ، فسوف يتعطل التطبيق مع وجود خطأ أثناء النشر:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNsme found for type Customer!
تم تصميم CUBA حول Spring Framework ، بحيث يمكنك استخدام مكتبة spring-data-jpa في تطبيق مكتوب باستخدام CUBA ، ولكن هناك مشكلة صغيرة - التحكم في الوصول. يستخدم تطبيق Spring CrudRepository EntityManager الخاص به. وبالتالي ، سيتم تنفيذ جميع الاستعلامات لتجاوز DataManager. وبالتالي ، لاستخدام مستودعات JPA في CUBA ، تحتاج إلى استبدال جميع مكالمات EntityManager بمكالمات DataManager وإضافة دعم لعروض CUBA.
قد يقول شخص ما أن spring-data-jpa عبارة عن صندوق أسود غير متحكم فيه ويفضل دائمًا كتابة JPQL خالص أو حتى SQL. هذه هي المشكلة الأبدية للتوازن بين الراحة ومستوى التجريد. يختار الجميع الطريقة التي يفضلها ، ولكن لن يكون هناك أي تأثير على طريقة إضافية للتعامل مع البيانات الموجودة في الترسانة. بالنسبة لأولئك الذين يحتاجون إلى مزيد من التحكم ، لدى Spring طريقة لتحديد طلبهم الخاص بطرق مستودع تخزين JPA.
التنفيذ
يتم تنفيذ مستودعات JPA كوحدة نمطية CUBA باستخدام مكتبة بيانات الربيع . لقد تخلينا عن فكرة تعديل spring-data-jpa ، لأن حجم العمل سيكون أكبر بكثير من كتابة مولد الاستعلامات الخاص بنا. خاصة وأن البيانات المشتركة في الربيع تقوم بمعظم العمل. على سبيل المثال ، يتم تحليل اسم الطريقة وربط الاسم بالفئات والخصائص بالكامل في هذه المكتبة. تحتوي بيانات البيانات المشتركة على جميع الفئات الأساسية اللازمة لتنفيذ مستودعاتك الخاصة ولا يتطلب الأمر الكثير من الجهد لتنفيذ ذلك. على سبيل المثال ، يتم استخدام هذه المكتبة في ربيع البيانات mongodb .
كان أصعب شيء هو تطبيق جيل JPQL بدقة بناءً على تسلسل هرمي للكائنات - نتيجة تحليل اسم الطريقة. ولكن لحسن الحظ ، تم تنفيذ مهمة مماثلة بالفعل في Apache Ignite ، لذلك تم أخذ الرمز من هناك وتكييفه قليلاً لإنشاء JPQL بدلاً من SQL ودعم مشغل delete .
يستخدم الربيع - البيانات المشتركة الوكلاء لإنشاء تطبيقات واجهة بشكل حيوي. عند تهيئة سياق تطبيق CUBA ، يتم استبدال جميع الروابط إلى الواجهات بروابط إلى صناديق الوكيل التي تم نشرها في السياق. عند استدعاء طريقة الواجهة ، يتم اعتراضها بواسطة كائن الوكيل المقابل. ثم يقوم هذا الكائن بإنشاء استعلام JPQL باسم الطريقة واستبدال المعلمات وإرسال الاستعلام مع المعلمات إلى DataManager للتنفيذ. يوضح المخطط التالي عملية مبسطة للتفاعل بين المكونات الرئيسية للوحدة.

استخدام المستودعات في كوبا
لاستخدام المستودعات في CUBA ، تحتاج فقط إلى توصيل الوحدة النمطية في ملف بناء المشروع:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")
يمكنك استخدام تكوين XML "لتمكين" المستودعات:
<?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns:beans="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.cuba-platform.org/schema/data/jpa http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd"> <context:component-scan base-package="com.company.sample"/> <repositories:repositories base-package="com.company.sample.core.repositories"/> </beans:beans>
ويمكنك استخدام التعليقات التوضيحية:
@Configuration @EnableCubaRepositories public class AppConfig {
بعد تنشيط دعم المستودعات ، يمكنك إنشائها بالشكل المعتاد ، على سبيل المثال:
public interface CustomerRepository extends CubaJpaRepository<Customer, UUID> { long countByLastName(String lastName); List<Customer> findByNameIsIn(List<String> names); @CubaView("_minimal") @JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')") List<Customer> findByNameStartingWith(String name); }
لكل طريقة ، يمكنك استخدام التعليقات التوضيحية:
@CubaView - لضبط عرض CUBA ليتم استخدامه في DataManager@JpqlQuery - لتحديد استعلام JPQL الذي سيتم تنفيذه ، بغض النظر عن اسم الطريقة.
يتم استخدام هذه الوحدة في الوحدة النمطية global لإطار CUBA ، وبالتالي ، يمكن استخدام المستودعات في كل من الوحدة core وعلى web . الشيء الوحيد الذي تحتاج إلى تذكره هو تنشيط المستودعات في ملفات التكوين لكلتا الوحدتين.
مثال على استخدام المستودع في خدمة CUBA:
@Service(CustomerService.NAME) public class CustomerServiceBean implements PersonService { @Inject private CustomerRepository customerRepository; @Override public List<Date> getCustomersBirthDatesByLastName(String name) { return customerRepository.findByNameStartingWith(name) .stream().map(Customer::getBirthDate).collect(Collectors.toList()); } }
الخاتمة
كوبا هي إطار مرن. إذا كنت ترغب في إضافة شيء ما إليه ، فلا داعي لإصلاح النواة بنفسك أو انتظار إصدار جديد. آمل أن تجعل هذه الوحدة تطوير CUBA أكثر كفاءة وأسرع. يتوفر الإصدار الأول من الوحدة النمطية على GitHub ، الذي تم اختباره على CUBA الإصدار 6.10