
تعد الجارديان واحدة من أكبر الصحف البريطانية ، وقد تأسست عام 1821. منذ ما يقرب من 200 عام من وجودها ، تراكمت الأرشيفات بنسبة لا بأس بها. لحسن الحظ ، لا يتم تخزين كل شيء على الموقع - في العقدين الأخيرين فقط. تحتوي قاعدة البيانات ، التي أطلق عليها البريطانيون أنفسهم "مصدر الحقيقة" لجميع محتويات الإنترنت ، حوالي 2.3 مليون عنصر. وعند نقطة واحدة ، أدركوا الحاجة إلى الترحيل من Mongo إلى Postgres SQL - بعد يوم واحد حار في يوليو 2015 ، تم اختبار إجراءات تجاوز الفشل بشدة. استغرق الهجرة ما يقرب من 3 سنوات! ..
لقد ترجمنا
مقالًا يصف كيفية سير عملية الترحيل وما الصعوبات التي يواجهها المسؤولون. العملية طويلة ، لكن الملخص بسيط: الوصول إلى المهمة الكبيرة ، التوفيق بين أن الأخطاء ستكون ضرورية. ولكن في النهاية ، بعد 3 سنوات ، تمكن الزملاء البريطانيون من الاحتفال بنهاية الهجرة. والنوم.
الجزء الأول: البداية
في Guardian ، يتم إنتاج معظم المحتوى ، بما في ذلك المقالات والمدونات ومعارض الصور ومقاطع الفيديو ، ضمن CMS الخاص بنا ، الملحن. حتى وقت قريب ، عمل الملحن مع Mongo DB المستندة إلى AWS. كانت قاعدة البيانات هذه في الأساس "مصدر الحقيقة" لجميع محتويات الجارديان على الإنترنت - حوالي 2.3 مليون عنصر. وأكملنا للتو الترحيل من Mongo إلى Postgres SQL.
تم استضافة الملحن وقواعد بياناته في الأصل على Guardian Cloud ، وهو مركز بيانات في الطابق السفلي من مكتبنا بالقرب من Kings Cross ، مع تجاوز الفشل في أماكن أخرى في لندن. في أحد
أيام يوليو الحارة في عام 2015 ، تعرضت إجراءات تجاوز الفشل لاختبار شديد إلى حد ما.
 الحرارة: جيدة للرقص في النافورة ، كارثية لمركز البيانات. الصورة: سارة لي / الجارديان
الحرارة: جيدة للرقص في النافورة ، كارثية لمركز البيانات. الصورة: سارة لي / الجارديانمنذ ذلك الحين ، أصبحت هجرة الجارديان إلى AWS مسألة حياة أو موت. للانتقال إلى السحابة ، قررنا شراء
OpsManager ، برنامج إدارة Mongo DB ، وتوقيع عقد دعم فني Mongo. استخدمنا OpsManager لإدارة النسخ الاحتياطية ، وتنظيم ومراقبة مجموعة قاعدة البيانات الخاصة بنا.
نظرًا لمتطلبات التحرير ، نحتاج لبدء مجموعة قاعدة البيانات و OpsManager على البنية التحتية الخاصة بنا في AWS ، وعدم استخدام الحل المدار من قبل Mongo. كان علينا أن نتعرق لأن Mongo لم يقدم أي أدوات للتكوين السهل على AWS: لقد صممنا يدويًا البنية التحتية بالكامل وكتبنا
مئات من نصوص Ruby لتثبيت وكلاء المراقبة / الأتمتة وتنسيق مثيلات قواعد البيانات الجديدة. كنتيجة لذلك ، كان علينا تنظيم فريق من البرامج التعليمية حول إدارة قواعد البيانات في الفريق - ما كنا نأمل أن يقوم به OpsManager.
منذ الانتقال إلى AWS ، واجهنا إخفاقين هامين بسبب مشاكل قاعدة البيانات ، كل منها لم يسمح بالنشر على الموقع theguardian.com لمدة ساعة على الأقل. في كلتا الحالتين ، لم يكن بمقدور OpsManager أو موظفي الدعم الفني لشركة Mongo تزويدنا بالمساعدة الكافية ، وقد حللنا المشكلة بأنفسنا - في إحدى الحالات ، بفضل أحد
أعضاء فريقنا الذي تمكن من التعامل مع الموقف عبر الهاتف من الصحراء في ضواحي أبو ظبي.
تستحق كل مشكلة من المشكلات وظيفة منفصلة ، ولكن فيما يلي النقاط العامة:
- انتبه جيدًا للوقت - لا تمنع الوصول إلى VPC الخاص بك إلى الحد الذي يتوقف فيه NTP عن العمل.
- يعد إنشاء فهارس قاعدة البيانات تلقائيًا عند بدء تشغيل التطبيق فكرة سيئة.
- إدارة قواعد البيانات مهمة للغاية وصعبة - ولا نريد أن نفعل ذلك بأنفسنا.
لم تفي OpsManager بوعدها بإدارة قاعدة بيانات بسيطة. على سبيل المثال ، تطلبت الإدارة الفعلية لـ OpsManager نفسها - على وجه الخصوص ، الترقية من OpsManager الإصدار 1 إلى الإصدار 2 - الكثير من الوقت ومعرفة خاصة حول إعداد OpsManager الخاص بنا. فشل أيضًا في الوفاء بوعده "بتحديث بنقرة واحدة" بسبب التغييرات في نظام المصادقة بين إصدارات مختلفة من Mongo DB. فقدنا ما لا يقل عن شهرين من المهندسين سنويًا في إدارة قاعدة البيانات.
كل هذه المشكلات ، بالاقتران مع الرسوم السنوية الكبيرة التي دفعناها مقابل عقد الدعم و OpsManager ، أجبرتنا على البحث عن خيار قاعدة بيانات بديلة بالخصائص التالية:
- الحد الأدنى من الجهد لإدارة قاعدة البيانات.
- التشفير في الراحة.
- طريق هجرة مقبول مع Mongo.
نظرًا لأن جميع خدماتنا الأخرى تعمل بنظام AWS ، فإن الخيار الواضح هو Dynamo ، قاعدة بيانات NoSQL من Amazon. لسوء الحظ ، في ذلك الوقت ، لم يدعم Dynamo التشفير أثناء الراحة. بعد انتظار حوالي تسعة أشهر حتى تتم إضافة هذه الميزة ، انتهى بنا الأمر إلى التخلي عن هذه الفكرة من خلال اتخاذ قرار باستخدام Postgres على AWS RDS.
"لكن بوستجرس ليس مستودع وثائق!" - أنت غاضب ... حسنًا ، نعم ، هذا ليس مستودعًا لرسو السفن ، لكنه يحتوي على جداول مماثلة لأعمدة JSONB ، مع دعم للفهارس في حقول أداة JSON Blob. كنا نأمل أن نتمكن من استخدام JSONB من الترحيل من Mongo إلى Postgres مع إجراء تغييرات طفيفة على نموذج البيانات الخاص بنا. بالإضافة إلى ذلك ، إذا أردنا الانتقال إلى نموذج أكثر ارتباطية في المستقبل ، فستكون لدينا مثل هذه الفرصة. شيء رائع آخر حول Postgres هو مدى نجاحه: بالنسبة لكل سؤال كان لدينا ، في معظم الحالات ، تم تقديم الإجابة بالفعل في Stack Overflow.
فيما يتعلق بالأداء ، كنا على يقين من أن Postgres يمكنها القيام بذلك: يعد Composer أداة حصرية لتسجيل المحتوى (يكتب إلى قاعدة البيانات في كل مرة يتوقف فيها الصحفي عن الطباعة) ، وعادة لا يتجاوز عدد المستخدمين المتزامنين عدة مئات - وهو ما لا يتطلب النظام قوة عظمى عظمى!
الجزء الثاني: هاجر المحتوى من عقدين ذهب دون توقف
خطةتتضمن معظم عمليات ترحيل قواعد البيانات نفس الإجراءات ، ولم تكن استثناءاتنا استثناء. إليك ما فعلناه:
- إنشاء قاعدة بيانات جديدة.
- قاموا بإنشاء طريقة للكتابة إلى قاعدة بيانات جديدة (API جديد).
- أنشأنا خادم وكيل يرسل حركة المرور إلى كل من قاعدة البيانات القديمة والجديدة ، باستخدام القديم مثل الرئيسي.
- تم نقل السجلات من قاعدة البيانات القديمة إلى الجديدة.
- جعلوا قاعدة البيانات الجديدة الرئيسية.
- إزالة قاعدة البيانات القديمة.
بالنظر إلى أن قاعدة البيانات التي قمنا بترحيلها وفرت سير عمل CMS الخاص بنا ، كان من الضروري أن تتسبب الهجرة في مشاكل قليلة قدر الإمكان بالنسبة للصحفيين. في النهاية ، الأخبار لا تنتهي أبدًا.
واجهة برمجة تطبيقات جديدةبدأ العمل على واجهة برمجة التطبيقات الجديدة المستندة إلى Postgres في نهاية يوليو 2017. كانت هذه بداية رحلتنا. ولكن لكي نفهم كيف كان الأمر ، يجب علينا أولاً توضيح أين بدأنا.
كانت بنية CMS المبسطة الخاصة بنا مثل هذا: قاعدة بيانات وواجهة برمجة تطبيقات والعديد من التطبيقات المرتبطة بها (مثل واجهة المستخدم). تم بناء المكدس ويعمل لمدة 4 سنوات الآن على أساس
Scala و
Scalatra Framework و
Angular.js .
بعد إجراء بعض التحليلات ، توصلنا إلى استنتاج مفاده أنه قبل أن نتمكن من ترحيل المحتوى الحالي ، نحتاج إلى وسيلة للاتصال بقاعدة بيانات PostgreSQL الجديدة ، مع الحفاظ على واجهة برمجة التطبيقات القديمة قيد التشغيل. بعد كل شيء ، Mongo DB هو "مصدر الحقيقة". لقد خدمتنا كشريان حياة أثناء قيامنا بتجربة واجهة برمجة التطبيقات الجديدة.
هذا أحد الأسباب التي تجعل البناء على واجهة برمجة التطبيقات القديمة لم يكن جزءًا من خططنا. كان فصل الوظائف في واجهة برمجة التطبيقات الأصلية ضئيلًا للغاية ، ويمكن العثور على الطرق المحددة اللازمة للعمل بشكل خاص مع Mongo DB حتى على مستوى جهاز التحكم. نتيجة لذلك ، كانت مهمة إضافة نوع آخر من قواعد البيانات إلى واجهة برمجة التطبيقات الحالية محفوفة بالمخاطر.
ذهبنا في الاتجاه الآخر وتكرار API القديمة. هكذا ولد APIV2. كانت نسخة أكثر أو أقل من واجهة برمجة التطبيقات القديمة ذات الصلة باللغة Mongo ، وتضمنت نفس نقاط النهاية والوظائف. استخدمنا
doobie ، طبقة ميزات JDBC الخالصة لـ Scala ، وأضاف
Docker للتشغيل والاختبار محليًا ، وتحسين تسجيل العمليات ومشاركة المسؤولية. كان من المفترض أن يكون APIV2 نسخة سريعة وحديثة من API.
بحلول نهاية أغسطس 2017 ، كان لدينا واجهة برمجة تطبيقات جديدة تم نشرها تستخدم PostgreSQL كقاعدة بيانات. لكن تلك كانت البداية فقط. هناك مقالات في Mongo DB تم إنشاؤها لأول مرة منذ أكثر من عقدين ، وكان عليهم جميعًا الترحيل إلى قاعدة بيانات Postgres.
الهجرةيجب أن نكون قادرين على تحرير أي مقال على الموقع ، بغض النظر عن تاريخ نشره ، وبالتالي فإن جميع المقالات موجودة في قاعدة البيانات لدينا باعتبارها "مصدرًا للحقيقة" واحدًا.
على الرغم من أن جميع المقالات موجودة
في واجهة برمجة تطبيقات Content Guardian (API) ، والتي تخدم التطبيقات والموقع ، كان من المهم للغاية بالنسبة لنا أن ننتقل دون أي خلل ، لأن قاعدة البيانات لدينا هي "مصدر الحقيقة" لدينا. إذا حدث شيء ما في مجموعة Elasticsearch CAPI ، فسنراجعه من قاعدة بيانات الملحن.
لذلك ، قبل تعطيل Mongo ، كان علينا التأكد من أن نفس الطلب لواجهة برمجة التطبيقات التي تعمل على Postgres وأن API التي تعمل على Mongo ستُرجع إجابات متطابقة.
للقيام بذلك ، نحتاج إلى نسخ كل المحتوى في قاعدة بيانات Postgres الجديدة. تم ذلك باستخدام برنامج نصي تفاعلت مباشرةً مع واجهات برمجة التطبيقات القديمة والجديدة. كانت ميزة هذه الطريقة هي أن كلاً من واجهات برمجة التطبيقات (APIs) قد وفرت بالفعل واجهة تم اختبارها جيدًا لقراءة وكتابة المقالات داخل وخارج قواعد البيانات ، بدلاً من كتابة شيء يمكن الوصول إليه مباشرةً من قواعد البيانات المعنية.
كان ترتيب الترحيل الأساسي كما يلي:
- الحصول على محتوى من Mongo.
- نشر المحتوى إلى بوستجرس.
- الحصول على محتوى من بوستجرس.
- تأكد من أن الإجابات منها متطابقة.
لا يمكن اعتبار ترحيل قاعدة البيانات ناجحًا إلا إذا لم يلاحظ المستخدمون النهائيون أن هذا قد حدث ، وسيكون دائمًا النص البرمجي للترحيل الجيد مفتاح هذا النجاح. نحتاج إلى نص يمكنه:
- تنفيذ طلبات HTTP.
- تأكد من أنه بعد ترحيل بعض المحتوى ، تكون استجابة كلا واجهات برمجة التطبيقات هي نفسها.
- توقف عند حدوث خطأ.
- قم بإنشاء سجل تشغيل مفصل لتشخيص المشكلات.
- أعد التشغيل بعد خطأ من النقطة الصحيحة.
بدأنا باستخدام
العموني . يتيح لك كتابة البرامج النصية بلغة Scala ، والتي هي جوهر فريقنا. كانت فرصة جيدة لتجربة شيء لم نستخدمه من قبل لمعرفة ما إذا كان سيكون مفيدًا لنا. على الرغم من أن العموني سمح لنا باستخدام لغة مألوفة ، وجدنا العديد من أوجه القصور في العمل عليها.
تدعم Intellij حاليًا Ammonite ، لكنها لم تفعل ذلك أثناء ترحيلنا - وفقدنا الإكمال التلقائي والاستيراد التلقائي. بالإضافة إلى ذلك ، لفترة طويلة من الزمن ، فشل البرنامج النصي العموني.
في النهاية ، لم يكن Ammonite الأداة المناسبة لهذا العمل ، وبدلاً من ذلك استخدمنا مشروع sbt للقيام بالهجرة. هذا سمح لنا بالعمل بلغة كنا واثقين بها ، بالإضافة إلى إجراء العديد من "هجرات الاختبار" قبل البدء في بيئة العمل الرئيسية.
كان غير متوقع هو مدى فائدة ذلك في التحقق من إصدار API الذي يعمل على بوستجرس. لقد وجدنا العديد من الأخطاء التي يصعب العثور عليها والحد من الحالات التي لم نعثر عليها سابقًا.
تقدم سريعًا إلى يناير 2018 عندما حان الوقت لاختبار الترحيل الكامل في بيئة الكود المسبق.
مثل معظم أنظمتنا ، فإن التشابه الوحيد بين CODE و PROD هو إصدار التطبيق الذي يتم تشغيله. كانت البنية التحتية لـ AWS التي تدعم CODE أقل قوة من PROD ، ببساطة لأنها تحصل على عبء عمل أقل بكثير.
كنا نأمل أن تساعد اختبار الترحيل في بيئة CODE:
- تقدير المدة التي ستستغرقها عملية الترحيل في بيئة PROD.
- تقييم كيف (إن وجدت) تؤثر الهجرة على الإنتاجية.
من أجل الحصول على قياسات دقيقة لهذه المؤشرات ، كان علينا أن نجعل البيئتين في المراسلات المتبادلة كاملة. وشمل ذلك استعادة نسخة احتياطية Mongo DB من PROD إلى CODE ورفع مستوى البنية التحتية التي تدعمها AWS.
كان يجب أن يستغرق ترحيل ما يزيد عن 2 مليون عنصر بيانات وقتًا أطول بكثير مما سيسمح به يوم العمل القياسي. لذلك ، ركضنا السيناريو في
الشاشة ليلا.
لقياس تقدم عملية الترحيل ، أرسلنا استعلامات منظمة (باستخدام الرموز) إلى مكدس ELK الخاص بنا (Elasticsearch و Logstash و Kibana). من هناك ، يمكننا إنشاء لوحات معلومات مفصلة عن طريق تتبع عدد المقالات التي تم نقلها بنجاح ، وعدد الأعطال والتقدم العام. بالإضافة إلى ذلك ، تم عرض جميع المؤشرات على الشاشة الكبيرة حتى يتمكن الفريق بأكمله من رؤية التفاصيل.
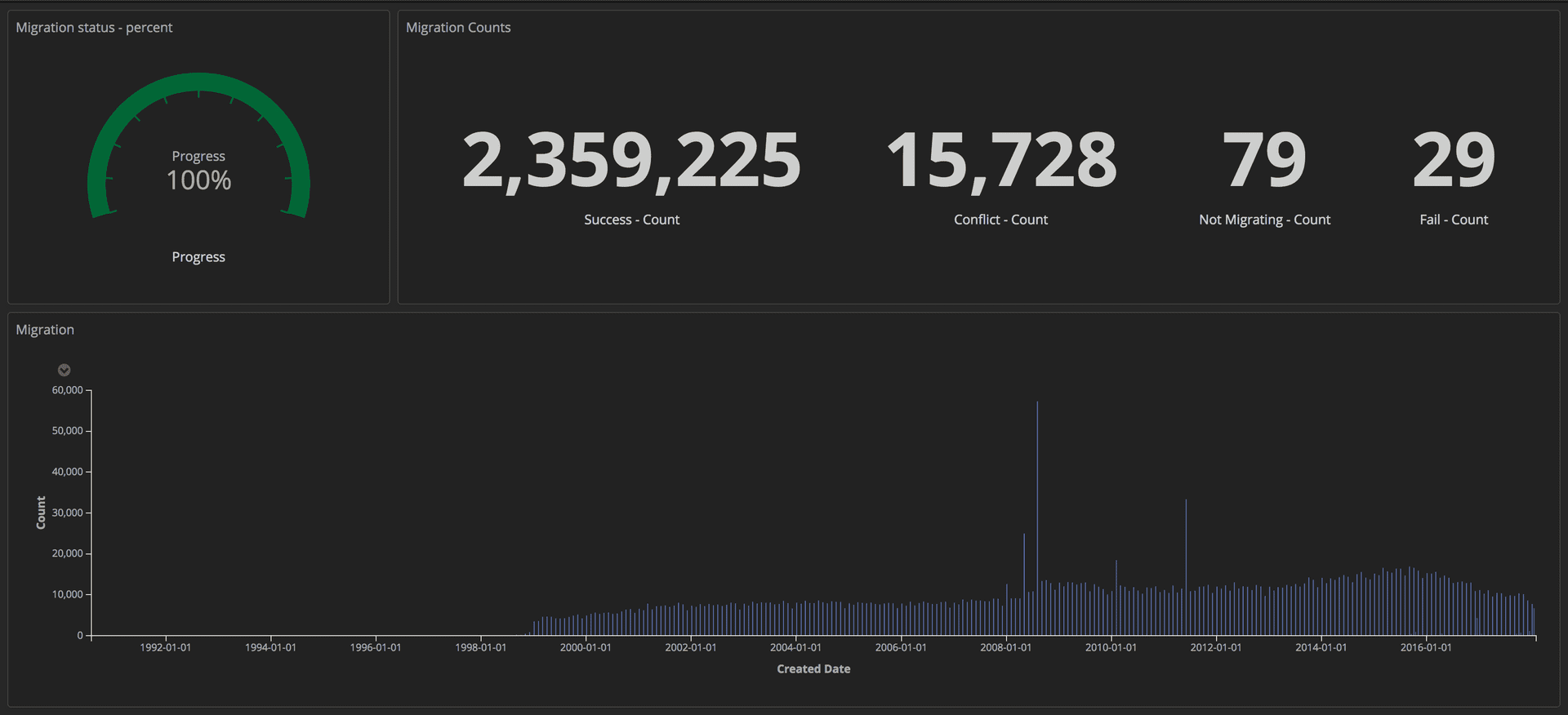 لوحة القيادة تبين التقدم المحرز في الهجرة: أدوات التحرير / الجارديان
لوحة القيادة تبين التقدم المحرز في الهجرة: أدوات التحرير / الجارديانبمجرد اكتمال الترحيل ، بحثنا عن تطابق لكل مستند في Postgres وفي Mongo.
الجزء الثالث: الوكلاء وإطلاق Prod
الوكلاءالآن وقد تم إطلاق واجهة برمجة التطبيقات (API) الجديدة التي تعمل على Postgres ، نحتاج إلى اختبارها باستخدام أنماط حقيقية لحركة المرور والوصول إلى البيانات للتأكد من موثوقيتها وثباتها. هناك طريقتان محتملتان للقيام بذلك: تحديث كل عميل يصل إلى واجهة برمجة تطبيقات Mongo بحيث يصل إلى كلا واجهات برمجة التطبيقات ؛ أو تشغيل وكيل من شأنها أن تفعل ذلك بالنسبة لنا. كتبنا وكلاء على سكالا باستخدام
Akka Streams .
الوكيل كان بسيطًا جدًا:
- تلقي حركة المرور من موازن التحميل.
- إعادة توجيه حركة المرور إلى واجهة برمجة التطبيقات الرئيسية والعكس صحيح.
- إعادة توجيه نفس حركة المرور بشكل غير متزامن إلى API إضافية.
- حساب التناقضات بين الإجابات اثنين وتسجيلها في سجل.
في البداية ، سجل الوكيل العديد من التناقضات ، بما في ذلك بعض الاختلافات السلوكية التي يصعب العثور عليها ولكنها مهمة في واجهات برمجة التطبيقات التي تحتاج إلى إصلاح.
تسجيل منظمفي Guardian ، نقوم بتسجيل الدخول باستخدام مكدس
ELK (Elasticsearch و Logstash و Kibana). باستخدام Kibana أعطانا الفرصة لتصور المجلة في الطريقة الأكثر ملاءمة بالنسبة لنا. يستخدم Kibana
بناء جملة استعلام Lucene ، وهو سهل التعلم. ولكن سرعان ما أدركنا أنه كان من المستحيل تصفية أو تجميع إدخالات دفتر اليومية في الإعداد الحالي. على سبيل المثال ، لم نتمكن من تصفية تلك التي تم إرسالها نتيجة لطلبات GET.
قررنا إرسال المزيد من البيانات المنظمة إلى Kibana ، وليس فقط الرسائل. يحتوي إدخال السجل الواحد على عدة حقول ، على سبيل المثال ، الطابع الزمني واسم الحزمة أو التطبيق الذي أرسل الطلب. إضافة حقول جديدة أمر سهل للغاية. تسمى هذه الحقول المنظمة علامات ويمكن تنفيذها باستخدام مكتبة
تشفير logstash-logback-encoder . لكل طلب ، استخرجنا معلومات مفيدة (على سبيل المثال ، المسار ، الطريقة ، رمز الحالة) وقمنا بإنشاء خريطة تحتوي على معلومات إضافية ضرورية للسجل. هنا مثال:
import akka.http.scaladsl.model.HttpRequest import ch.qos.logback.classic.{Logger => LogbackLogger} import net.logstash.logback.marker.Markers import org.slf4j.{LoggerFactory, Logger => SLFLogger} import scala.collection.JavaConverters._ object Logging { val rootLogger: LogbackLogger = LoggerFactory.getLogger(SLFLogger.ROOT_LOGGER_NAME).asInstanceOf[LogbackLogger] private def setMarkers(request: HttpRequest) = { val markers = Map( "path" -> request.uri.path.toString(), "method" -> request.method.value ) Markers.appendEntries(markers.asJava) } def infoWithMarkers(message: String, akkaRequest: HttpRequest) = rootLogger.info(setMarkers(akkaRequest), message) }
سمحت لنا الحقول الإضافية في سجلاتنا بإنشاء لوحات معلومات مفيدة وإضافة المزيد من السياق إلى التناقضات ، مما ساعدنا على تحديد بعض التناقضات الطفيفة بين واجهات برمجة التطبيقات.
تكرار حركة المرور وإعادة هيكلة الوكيلبعد نقل المحتويات إلى قاعدة بيانات CODE ، حصلنا على نسخة دقيقة تقريبًا من قاعدة بيانات PROD. الفارق الرئيسي هو أن الكود لا يوجد لديه حركة المرور. لتكرار حركة المرور الحقيقية إلى بيئة CODE ، استخدمنا أداة المصدر المفتوح
GoReplay (المشار
إليها فيما يلي باسم gor). إنه سهل التثبيت ومرن للتخصيص وفقًا لمتطلباتك.
نظرًا لأن كل حركة المرور القادمة إلى واجهات برمجة التطبيقات الخاصة بنا ذهبت أولاً إلى الوكلاء ، فمن المنطقي تثبيت gor على حاويات الوكيل. انظر أدناه كيفية تحميل gor في الحاوية الخاصة بك وكيفية بدء مراقبة حركة المرور على المنفذ 80 وإرسالها إلى خادم آخر.
wget https://github.com/buger/goreplay/releases/download/v0.16.0.2/gor_0.16.0_x64.tar.gz tar -xzf gor_0.16.0_x64.tar.gz gor sudo gor --input-raw :80 --output-http http://apiv2.code.co.uk
لبعض الوقت سار كل شيء على ما يرام ، ولكن سرعان ما حدث خلل عندما أصبح الوكيل غير متاح لعدة دقائق. في التحليل ، وجدنا أن الحاويات البروكسي الثلاث جميعها معلقة بشكل دوري في نفس الوقت. في البداية اعتقدنا أن الوكيل كان يتعطل لأن gor كان يستخدم الكثير من الموارد. بناءً على مزيد من التحليل لوحدة التحكم AWS ، وجدنا أن حاويات البروكسي معلقة بانتظام ، ولكن ليس في نفس الوقت.
قبل الخوض في المشكلة بشكل أكبر ، حاولنا إيجاد طريقة لتشغيل gor ، لكن هذه المرة دون تحميل إضافي على الخادم الوكيل. جاء الحل من مجموعتنا الثانوية في الملحن. يتم استخدام هذه المجموعة فقط في حالة الطوارئ ، وتقوم
أداة مراقبة العمل لدينا
باختبارها باستمرار. هذه المرة ، تم تشغيل حركة المرور من هذا المكدس إلى CODE بسرعة مضاعفة دون أي مشاكل.
أثارت النتائج الجديدة العديد من الأسئلة. تم تصميم البروكسي كأداة مؤقتة ، لذلك ربما لم يتم تصميمه بعناية مثل التطبيقات الأخرى. بالإضافة إلى ذلك ، تم تصميمه باستخدام
Akka Http ، والذي لم يكن أي من فريقنا على دراية به. كان الرمز فوضوي ومليئة بإصلاحات سريعة. قررنا أن نبدأ كثيرًا من إعادة البناء لتحسين قابلية القراءة. هذه المرة استخدمنا المولدات الكهربائية بدلاً من المنطق المتداخل المتزايد الذي استخدمناه من قبل. وأضاف المزيد من علامات التسجيل.
كنا نأمل أن نتمكن من منع حاويات البروكسي من التجمد إذا دخلنا في تفاصيل ما يحدث داخل النظام وتبسيط منطق تشغيله. لكن هذا لم ينجح. بعد أسبوعين من محاولة جعل الوكيل أكثر موثوقية ، شعرنا بالحصار. كان من الضروري اتخاذ قرار. قررنا المخاطرة وترك البروكسي كما هو ، لأنه من الأفضل قضاء بعض الوقت في عملية الترحيل نفسها بدلاً من محاولة إصلاح جزء من البرامج التي ستصبح غير ضرورية في غضون شهر. لقد دفعنا ثمن هذا الحل بفشلين آخرين - دقيقتان تقريبًا لكل منهما - ولكن يجب القيام به.
تقدم سريعًا إلى مارس 2018 ، عندما أكملنا بالفعل الترحيل إلى CODE دون التضحية بأداء API أو تجربة العميل في CMS. الآن يمكننا أن نبدأ في التفكير في شطب الوكلاء من CODE.
كانت الخطوة الأولى هي تغيير أولويات واجهة برمجة التطبيقات بحيث تفاعل الوكيل أولاً مع Postgres. كما قلنا أعلاه ، فقد تقرر ذلك عن طريق تغيير في الإعدادات. ومع ذلك ، كان هناك صعوبة واحدة.
يرسل الملحن رسائل إلى دفق Kinesis بعد تحديث المستند. هناك حاجة لواجهة برمجة التطبيقات واحدة فقط لإرسال الرسائل لمنع الازدواجية. لهذا ، فإن واجهات برمجة التطبيقات لديها علامة في التكوين: صحيح بالنسبة لواجهة برمجة التطبيقات التي يدعمها Mongo ، وخطأ بالنسبة إلى Postgres المدعومة. لم يكن تغيير الوكيل للتفاعل مع Postgres أولاً كافيًا ، حيث لن يتم إرسال الرسالة إلى دفق Kinesis حتى يصل الطلب إلى Mongo. لقد كان طويلا جدا.
لحل هذه المشكلة ، أنشأنا نقاط نهاية HTTP لتغيير تكوين جميع مثيلات موازن التحميل فورًا. هذا سمح لنا بتوصيل واجهة برمجة التطبيقات الرئيسية بسرعة كبيرة دون الحاجة إلى تعديل ملف التكوين وإعادة الانتشار. بالإضافة إلى ذلك ، يمكن أتمتة هذا ، مما يقلل من التفاعل البشري واحتمال الأخطاء.
الآن تم إرسال جميع الطلبات إلى Postgres أولاً ، وتفاعل API2 مع Kinesis. يمكن إجراء استبدال دائم مع تغييرات التكوين وإعادة النشر.
كانت الخطوة التالية هي إزالة الوكيل تمامًا وإجبار العملاء على الوصول إلى واجهة برمجة تطبيقات Postgres بشكل حصري. نظرًا لأن لدينا العديد من العملاء ، لم يكن تحديث كل منهم على حدة ممكنًا. لذلك ، رفعنا هذه المهمة إلى مستوى DNS. وهذا يعني أننا أنشأنا CNAME في DNS أشار أولاً إلى وكيل ELB وسوف يتغير ليشير إلى API ELB. هذا سمح بإجراء تغيير واحد بدلاً من تحديث كل عميل API فردي.
حان الوقت لتحريك PROD. على الرغم من أنها كانت مخيفة بعض الشيء ، حسناً ، لأن هذه هي بيئة العمل الرئيسية. كانت العملية بسيطة نسبيًا ، حيث تم تحديد كل شيء عن طريق تغيير الإعدادات. بالإضافة إلى ذلك ، عند إضافة علامة مرحلة إلى السجلات ، أصبح من الممكن إعادة تشكيل لوحات المعلومات التي تم إنشاؤها مسبقًا عن طريق تحديث مرشح Kibana.
تعطيل الوكلاء و Mongo DBبعد 10 أشهر و 2.4 مليون مقالة تم ترحيلها ، تمكنا أخيرًا من تعطيل جميع البنية التحتية المتعلقة بـ Mongo. لكن أولاً ، كان علينا أن نفعل ما كنا ننتظره جميعًا: قتل الوكيل.
 سجلات توضح تعطيل تطبيق API المرن. الصورة: أدوات التحرير / الجارديان
سجلات توضح تعطيل تطبيق API المرن. الصورة: أدوات التحرير / الجارديانتسببت هذه قطعة صغيرة من البرمجيات لنا الكثير من المشاكل التي نتوق لفصلها قريبا! كل ما كان علينا فعله هو تحديث سجل CNAME للإشارة مباشرةً إلى موازن التحميل APIV2.
اجتمع الفريق بأكمله حول كمبيوتر واحد. كان من الضروري جعل ضغطة واحدة فقط. احتفظ الجميع أنفاسهم! الصمت التام ... انقر! تم الانتهاء من المهمة. ولا شيء طار! نحن جميعا الزفير بفرح.
ومع ذلك ، كانت إزالة واجهة برمجة تطبيقات Mongo DB القديمة محفوفة باختبار آخر. يائسًا لإزالة الشفرة القديمة ، وجدنا أن اختبارات التكامل الخاصة بنا لم يتم ضبطها مطلقًا لاستخدام واجهة برمجة التطبيقات الجديدة. كل شيء سرعان ما تحولت إلى اللون الأحمر. لحسن الحظ ، كانت معظم المشكلات متعلقة بالتهيئة وقمنا بإصلاحها بسهولة. كانت هناك عدة مشاكل مع استعلامات PostgreSQL التي تم اكتشافها بواسطة الاختبارات. بالتفكير فيما يمكن عمله لتجنب هذا الخطأ ، تعلمنا درسًا واحدًا: عند بدء مهمة كبيرة ، التوفيق بين أنه سيكون هناك أخطاء.
بعد ذلك ، كل شيء يعمل بسلاسة. قمنا بفصل جميع مثيلات Mongo عن OpsManager ، ثم قطعناها. الشيء الوحيد المتبقي هو الاحتفال. والنوم.