مرحبا يا هبر! بعد الحصول على قسط كافٍ من الراحة بعد أيام العطلة الطويلة ، نحن مستعدون مرة أخرى للقيام بعمل جيد بكل الطرق المتاحة. الزملاء من قسم تقنية المعلومات لديهم دائمًا ما يمكن أن يقولوه ، واليوم نحن نشارككم تقريرًا من ألكسندر بريزوف ، مسؤول نظام Yandex.Money ، من اجتماع JavaJam.
كيف قمنا ببناء تدفق ملاحظات للكشف عن إصدارات المشاكل باستخدام الجرافيت و Moira. سنخبرك بكيفية جمع وتحليل مقاييس عدد الأخطاء في التطبيق.
- مرحباً بالجميع ، اسمي ألكسندر بريزوف ، أعمل في قسم التشغيل الآلي للتشغيل في Yandex.Money ، وسأخبرك اليوم عن كيفية جمع ومعالجة وتحليل المعلومات حول نظامنا.
ربما كنت قد تساءلت عن سبب تسمية التقرير بالطريقة الثانية (اسم التقرير الخاص بالاجتماع هو ed.). كل شيء بسيط جدا. في صميم DevOps ، يوجد عدد من المبادئ التي تنقسم بشروط إلى ثلاث مجموعات.
الطريقة الأولى هي مبدأ التدفق. الطريقة الثانية تنطوي على مبدأ ردود الفعل. الطريقة الثالثة هي التعلم المستمر والتجريب.
كقاعدة عامة ، فيما يتعلق بتطوير وتشغيل منتجات البرمجيات ، فإن التغذية الراجعة تعني القياس عن بُعد ، الذي نجمعه عن نظامنا ، والحالة الأكثر شيوعًا هي جمع المقاييس ومعالجتها.
لماذا نحتاج هذه المقاييس؟ بمساعدة المقاييس ، نحصل على تعقيبات من النظام ويمكننا معرفة الحالة التي يتواجد بها نظامنا ، وما إذا كان كل شيء يسير على ما يرام ، وكيف أثرت تغييراتنا على تشغيله ، وما إذا كان أي تدخل ضروريًا لحل بعض المشكلات.
ما المقاييس التي نجمعها؟
نحن نجمع المقاييس من ثلاثة مستويات.
يتضمن مستوى العمل مؤشرات مثيرة للاهتمام من وجهة نظر أي مهام أعمال. على سبيل المثال ، يمكننا الحصول على إجابات لأسئلة مثل عدد المستخدمين الذين سجلناهم ، وعدد مرات تسجيل دخول المستخدمين إلى نظامنا ، وعدد المستخدمين النشطين الذين يمتلك تطبيق الهاتف المحمول الخاص بنا.
المستوى التالي هو مستوى التطبيق . غالبًا ما يتم عرض مقاييس هذا المستوى بواسطة المطورين ، نظرًا لأن هذه المؤشرات تقدم إجابة على سؤال حول مدى جودة أداء التطبيق لدينا ، ومدى سرعة معالجة الطلبات ، هل هناك أي عيوب في الأداء. يتضمن ذلك وقت الاستجابة وعدد الطلبات وطول قائمة الانتظار وغير ذلك الكثير.
وأخيرا ، على مستوى البنية التحتية . كل شيء واضح جدا هنا. باستخدام هذه المقاييس ، يمكننا تقدير مقدار الموارد المستهلكة ، وكيفية التنبؤ بها وتحديد المشكلات المتعلقة بالبنية التحتية.
الآن ، باختصار ، سوف أصف كيفية إرسال هذه المقاييس ومعالجتها ومكان تخزينها. بجانب التطبيق ، لدينا جامع المقاييس. في حالتنا ، هذه خدمة Heka تستمع إلى منفذ UDP وتتوقع أن تكون المدخلات في تنسيق StatsD مدخلات.
تنسيق StatsD كالتالي:

أي أننا نحدد اسم المقياس ، ونشير إلى قيمة هذا المقياس ، وهو 1 و 26 وما إلى ذلك ، ونشير إلى نوعه. إجمالاً ، لدى StatsD حوالي أربعة أو خمسة أنواع. إذا كنت مهتمًا فجأة ، يمكنك أن ترى بالتفصيل وصف هذه الأنواع .
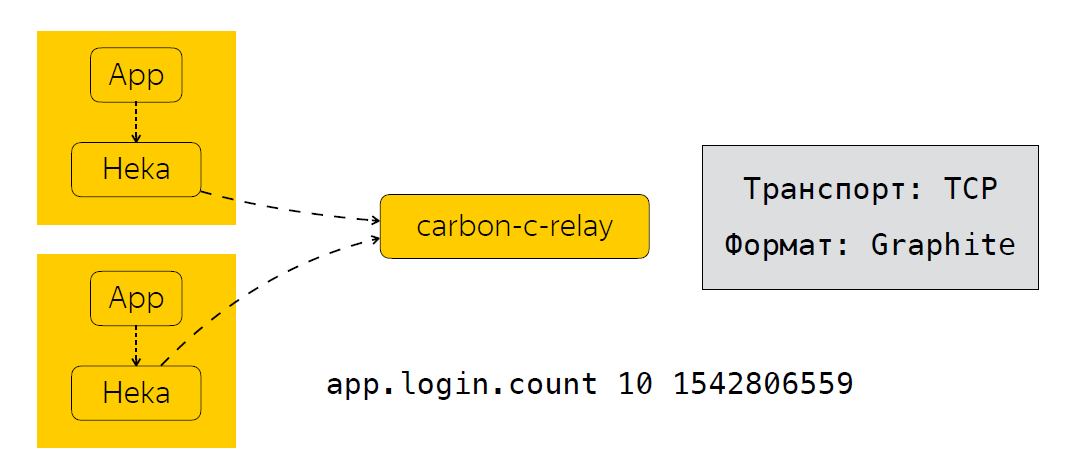
بعد أن يرسل التطبيق بيانات Heka ، يتم تجميع المقاييس لفترة معينة. في حالتنا ، هذه 30 ثانية ، وبعدها يرسل Heka البيانات إلى مرحل الكربون ، والذي ينفذ وظيفة التصفية والتوجيه وتحديث المقاييس ، والتي بدورها ترسل المقاييس إلى التخزين الخاص بنا ، فإننا نستخدم clickhouse (نعم ، لا يؤدي إلى إبطاء ) ، وكذلك في مويرا. إذا كان أي شخص لا يعرف ، فهذه خدمة تتيح لك تكوين مشغلات معينة للمقاييس. سأتحدث عن مويرا لاحقًا. لذلك ، نظرنا في المقاييس التي نجمعها ، وكيف نرسلها ونعالجها. والخطوة المنطقية التالية هي تحليل هذه المقاييس.
كيف نحلل المقاييس؟
سأقدم وضعا حقيقيا حيث أعطانا تحليل المقاييس نتائج ملموسة. خذ عملية الإصدار كمثال. بشكل عام ، يشمل الخطوات التالية.
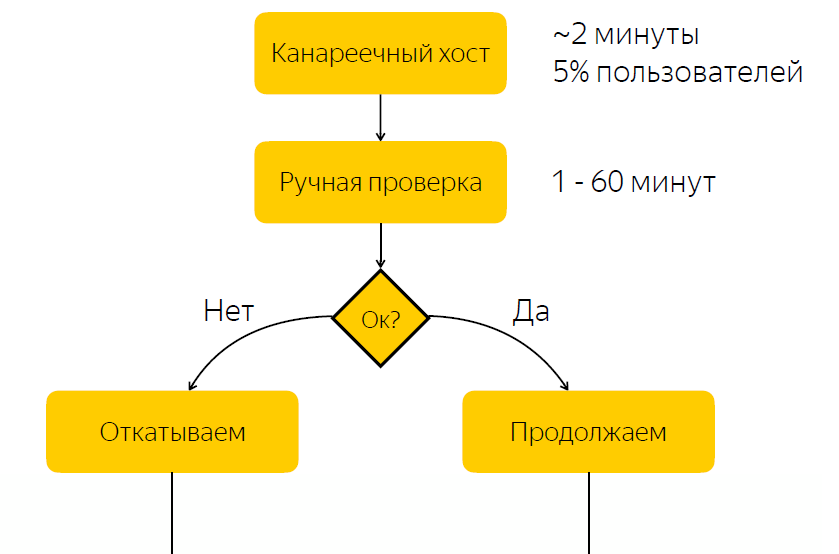
يتم نشر الإصدار إلى مضيف الكناري. يمثل حوالي خمسة بالمائة من حركة مرور المستخدم. بعد اكتمال الإصدار إلى مضيف الكناري ، نعلم الشخص المسؤول عن الإصدار بأنه يجب عليه التحقق مما إذا كان كل شيء متوافقًا مع الإصدار. وعليه إعطاء رد فعل ، والرد على هذا الإصدار والنقر على الزر مع اتخاذ قرار بشأن ما إذا كان ينبغي أن يتدحرج هذا الإصدار ، أو ينبغي أن يتراجع.
ليس من الصعب تخمين وجود عيب كبير في هذا المخطط ، أي أننا نتوقع رد فعل مسؤول. إذا كان الشخص المسؤول في الوقت الحالي لسبب ما غير قادر على الاستجابة بسرعة ، فعندئذ يكون لدينا إصدار خطأ ، ثم لبعض الوقت يأتي خمسة في المئة من حركة المرور إلى عقدة المشكلة. إذا كان كل شيء متوافقًا مع الإصدار ، فنحن ببساطة نقضي الوقت في الانتظار ، وبالتالي نبطئ عملية الإصدار.
لا أخطاء - نحن تبطئ عملية الإصدار
مع البق - المودة المستخدم
مع فهم هذه المشكلة ، قررنا معرفة ما إذا كان من الممكن أتمتة عملية صنع القرار بشأن ما إذا كان الإصدار مشكلة أم لا.
بالطبع ، لجأنا إلى مطورينا لفهم كيفية إجراء فحص الإصدار. اتضح ، ويبدو أنه من المنطقي بما فيه الكفاية ، أن المؤشر الرئيسي الذي يشير إلى أن الإصدار يمثل مشكلة هو الزيادة في عدد الأخطاء في سجلات هذا التطبيق.
ماذا فعل المطورين؟ قاموا بفتح Kibana ، وقاموا باختيار وفقًا لمستوى الخطأ في كتلة التطبيق ، وإذا رأوا القوائم ، ظنوا أن هناك خطأ ما في التطبيق. تجدر الإشارة إلى أن سجلات تطبيقنا يتم تخزينها في مرن ، ويبدو أن كل شيء يبدو بسيطًا للغاية. لدينا سجلات في مرن ، علينا فقط إنشاء طلب في مرن ، وجعل الاختيار وفهم بناء على هذه البيانات ما إذا كان الإصدار هو إشكالية أم لا. لكن هذا القرار بدا لنا غير جيد للغاية.
لماذا لا مرنة؟
بادئ ذي بدء ، كنا قلقين من أننا قد لا نكون قادرين على تلقي البيانات بسرعة من المرونة. هناك مثل هذه الحالات ، على سبيل المثال ، أثناء اختبار الإجهاد ، عندما يكون لدينا تدفق كبير من البيانات ، وقد لا تتمكن المجموعة من التعامل ، وفي نهاية المطاف ، هناك تأخير في إرسال السجلات لحوالي 10-15 دقيقة.
كانت هناك أيضًا أسباب ثانوية ، على سبيل المثال ، عدم وجود اسم موحد للفهارس. يجب أخذ ذلك في الاعتبار في أداة التشغيل الآلي. وكذلك التطبيقات على منصات مختلفة يمكن أن يكون لها تنسيقات سجل مختلفة.
لقد فكرنا ، لماذا لا نحاول عمل نوع من المقاييس على أساسها يمكننا أن نقرر ما إذا كان الإصدار مشكلة أم لا. في الوقت نفسه ، لم نكن نرغب في تحميل مطورينا إجراء تغييرات على قاعدة الشفرة. وكما يبدو لنا ، وجدنا حلاً أنيقًا إلى حد ما عن طريق إضافة ملحق إضافي إلى log4j.
كيف تبدو؟
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status="warn" name="${sys:application.name}" > <Properties> <Property name="logsCountStatsDFormat">app_name.logs.%level:1|c</Property> </Properties> ... <Appenders> <Socket name="STATSD" host="127.0.0.1" port="8125" protocol="UDP"> <PatternLayout pattern="${logsCountStatsDFormat}"/> </Socket> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="STATSD"/> </Root> </Loggers> </Configuration>
أولاً ، نحدد تنسيق المقياس الذي نرسله. فيما يلي مُضيف إضافي يرسل سجلات بالتنسيق الموجود أعلاه إلى المنفذ 8125 عبر UDP ، أي إلى Heka. ماذا يعطينا هذا؟ يرسل Log4j مقياس نوع عداد لكل إدخال سجل بمستوى السجل المحدد ERROR و INFO و WARN وما إلى ذلك.
ومع ذلك ، فقد أدركنا بسرعة أن إرسال قياس إلى كل إدخال سجل يمكن أن يؤدي إلى تحميل كبير ، وكتبنا مكتبة تجمع المقاييس لفترة زمنية معينة وترسل المقياس المجمع بالفعل إلى خدمة Heka. في الواقع ، نحن نضيف هذا المُسجل إلى المُسجِّلين ، وبهذا الأسلوب ، نعرف الآن مقدار ما يكتبه تطبيقنا لسجلات التسوية ، ولدينا اسم موحد للمقاييس ، بغض النظر عن النظام الأساسي المستخدم. يمكننا بسهولة فهم عدد الأخطاء الموجودة في سجل التطبيق. وأخيرا ، تمكنا من أتمتة عملية صنع القرار لإصدار إشكالية.
الأتمتة
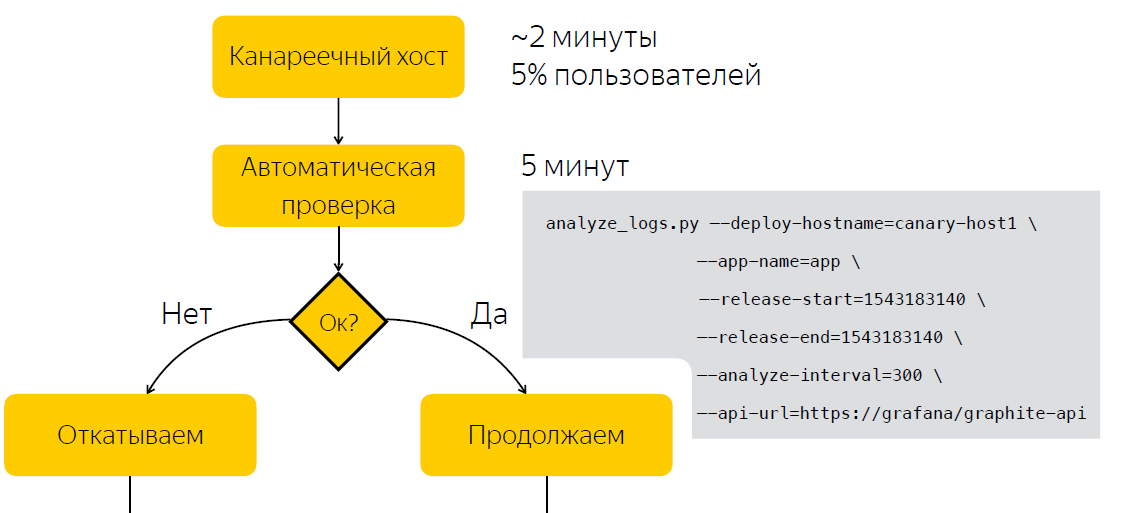
بدلاً من التحقق يدويًا بعد الإصدار ، ننتظر خمس دقائق ، وبعدها نقوم بجمع البيانات حول عدد الإدخالات في سجلات التطبيق. بعد قيامنا بتشغيل البرنامج النصي ، الذي ، على أساس عينتين ، قبل الإصدار وبعده ، يقرر ما إذا كان الإصدار يمثل مشكلة. وبالتالي ، قمنا بتقليل مقدار الوقت الذي نقضيه في اتخاذ القرار إلى خمس دقائق.
إلى جانب حقيقة أن المعلومات المتعلقة بعدد الأخطاء في السجلات مفيدة أثناء الإصدار ، فقد تبيَّن أنها مكافأة لطيفة تفيد أنها مفيدة أيضًا أثناء العملية. لذلك ، على سبيل المثال ، يمكننا تصور عدد الأخطاء في سجلات Grafana وتسجيل الزيادات الشاذة في سجلات التطبيق.
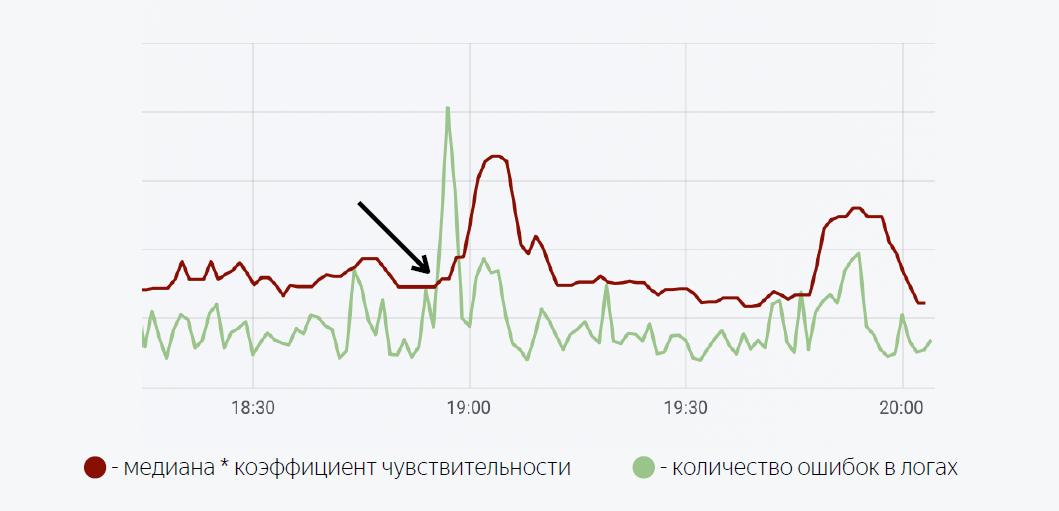
يستخدم هنا نموذج رياضي بسيط إلى حد ما. الخط الأخضر هو عدد الأخطاء في سجلات التطبيق. الأحمر الداكن هو متوسط الأوقات عامل الحساسية. في حالة تجاوز عدد الأخطاء في السجلات الوسيط ، يتم تشغيل المشغل ، وعندما يتم تشغيله ، يتم إرسال إشعار عبر Moira.
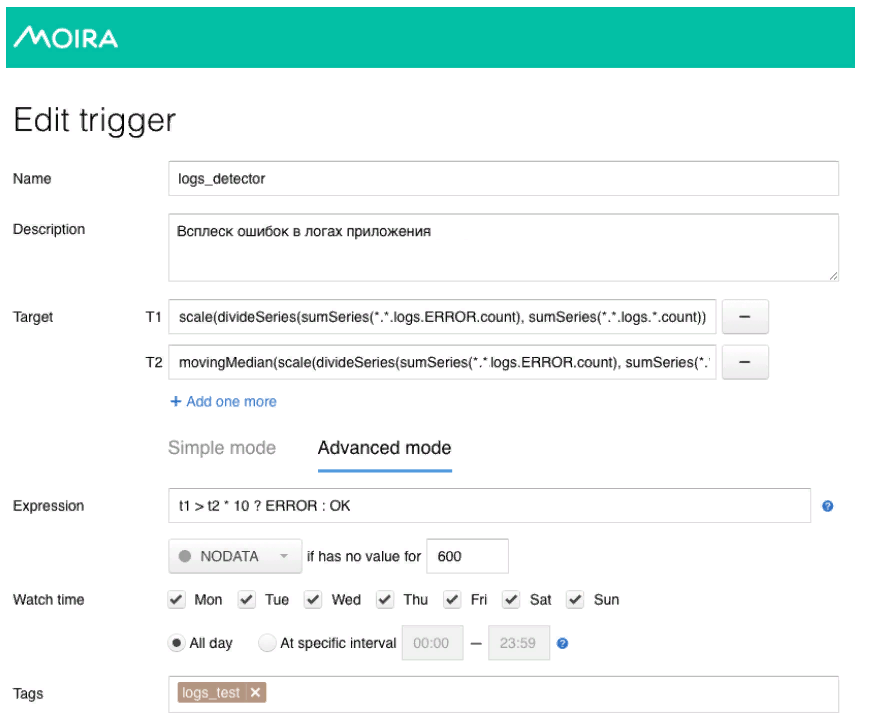
كما وعدت ، سوف أخبركم قليلاً عن مويرا ، كيف تعمل. نحدد المقاييس المستهدفة التي نريد مراعاتها. هذا هو عدد الأخطاء والوسيط المتحرك ، وكذلك الشروط التي سيعمل بها هذا المشغل ، أي عندما يتجاوز عدد الأخطاء في السجلات الوسيط مضروبًا في معامل الحساسية. عندما يتم تشغيل المشغل ، يتلقى المطور إخطارًا بأنه قد تم تسجيل انفجار غير طبيعي للأخطاء في التطبيق ، ويجب اتخاذ بعض الإجراءات.

ماذا لدينا في النهاية؟ لقد طورنا آلية مشتركة لجميع تطبيقاتنا الخلفية ، والتي تتيح لنا الحصول على معلومات حول عدد الإدخالات في سجلات مستوى معين. أيضًا ، باستخدام مقاييس حول عدد الأخطاء في سجلات التطبيق ، تمكنا من أتمتة عملية اتخاذ القرار بشأن ما إذا كان الإصدار يمثل مشكلة أم لا. كما كتبوا مكتبة لـ log4j ، والتي يمكنك استخدامها إذا كنت تريد تجربة النهج الذي وصفته. رابط إلى المكتبة أدناه.
ربما هذا كل شيء بالنسبة لي. شكرا لك
روابط مفيدة
Log4j-count-appender
مويرا