في هذه المقالة ، نقدم
صفحات ، نظام إدارة ذاكرة شائع جدًا نطبقه أيضًا على نظام التشغيل الخاص بنا. تشرح المقالة سبب الحاجة إلى عزل الذاكرة ، وكيفية عمل
التجزئة ، وما
هي الذاكرة الافتراضية ، وكيف تحل الصفحات مشكلة التجزئة. نستكشف أيضًا مخطط جداول الصفحات متعددة المستويات في بنية x86_64.
تم نشر هذه المدونة على
جيثب . إذا كان لديك أي أسئلة أو مشاكل ، افتح الطلب المقابل هناك.
حماية الذاكرة
إحدى المهام الرئيسية لنظام التشغيل هي عزل البرامج عن بعضها البعض. على سبيل المثال ، يجب ألا يتداخل المستعرض مع محرر النصوص. هناك طرق مختلفة حسب الأجهزة وتطبيق نظام التشغيل.
على سبيل المثال ، تحتوي بعض معالجات ARM Cortex-M (في الأنظمة المضمّنة)
على وحدة حماية للذاكرة (MPU) تحدد عددًا صغيرًا (على سبيل المثال ، 8) من مناطق الذاكرة بأذونات وصول مختلفة (على سبيل المثال ، لا يوجد وصول ، للقراءة فقط ، قراءة و السجلات). في كل مرة يتم الوصول إلى الذاكرة ، تضمن وحدة MPU أن العنوان موجود في المنطقة مع الأذونات الصحيحة ، وإلا فإنه يلقي استثناء. من خلال تغيير النطاق وأذونات الوصول ، يضمن نظام التشغيل أن كل عملية لديها وصول فقط إلى ذاكرتها من أجل عزل العمليات عن بعضها البعض.
في x86 ، يتم دعم طريقتين مختلفتين لحماية الذاكرة:
التجزئة والترحيل .
تجزئة
تم تنفيذ التقسيم مرة أخرى في عام 1978 ، في البداية لزيادة مقدار الذاكرة عنونة. في ذلك الوقت ، كانت وحدة المعالجة المركزية تدعم عناوين 16 بت فقط ، مما حد من كمية الذاكرة القابلة للتوجيه إلى 64 كيلو بايت. لزيادة هذا الحجم ، تم تقديم سجلات قطعة إضافية ، كل منها يحتوي على عنوان إزاحة. تضيف وحدة المعالجة المركزية هذه الإزاحة تلقائيًا عند كل وصول إلى الذاكرة ، وبالتالي معالجة ما يصل إلى 1 ميغابايت من الذاكرة.
تقوم وحدة المعالجة المركزية تلقائيًا بتحديد سجل قطعة اعتمادًا على نوع الوصول إلى الذاكرة: يتم استخدام سجل قطعة كود
CS لتلقي الإرشادات ، ويستخدم سجل شريحة مكدس
SS لعمليات المكدس (الضغط / البوب). إرشادات أخرى استخدم سجل مقطع بيانات
DS أو سجل مقطع
ES الاختياري. في وقت لاحق ، تم إضافة اثنين من سجلات القطاع
FS و
GS للاستخدام المجاني.
في الإصدار الأول من التجزئة ، احتوت السجلات مباشرةً على الإزاحة ولم يتم إجراء التحكم في الوصول. مع ظهور
الوضع المحمي ، تغيرت الآلية. عندما تعمل وحدة المعالجة المركزية في هذا الوضع ، تخزن واصفات القطعة الفهرس في جدول واصف محلي أو عالمي ، والذي يحتوي بالإضافة إلى عنوان الإزاحة على حجم القطعة وأذونات الوصول. عن طريق تحميل جداول وصف عام / محلي منفصلة لكل عملية ، يمكن لنظام التشغيل عزل العمليات عن بعضها البعض.
من خلال تغيير عناوين الذاكرة قبل الوصول الفعلي ، طبق التجزيء طريقة يتم استخدامها الآن في كل مكان تقريبًا: إنها
ذاكرة افتراضية .
الذاكرة الافتراضية
فكرة الذاكرة الافتراضية هي تجريد عناوين الذاكرة من جهاز فعلي. بدلاً من الوصول مباشرة إلى جهاز التخزين ، يتم تنفيذ خطوة التحويل أولاً. في حالة التجزئة ، تتم إضافة عنوان الإزاحة للجزء النشط في مرحلة الترجمة. تخيل البرنامج الذي يصل إلى عنوان الذاكرة
0x1234000 في قطعة مع إزاحة
0x1111000 : في الواقع ، ينتقل العنوان إلى
0x2345000 .
للتمييز بين نوعين من العناوين ، تسمى العناوين قبل التحويل "
افتراضية" ، وتسمى العناوين بعد التحويل "
الفعلي" . هناك اختلاف مهم واحد بينهما: العناوين الفعلية فريدة من نوعها وتشير دائمًا إلى نفس الموقع الفريد في الذاكرة. العناوين الافتراضية ، من ناحية أخرى ، تعتمد على وظيفة الترجمة. قد يشير عنوانان افتراضيان مختلفان إلى نفس العنوان الفعلي. بالإضافة إلى ذلك ، يمكن أن تشير العناوين الافتراضية المتطابقة إلى عناوين فعلية مختلفة بعد التحويل.
مثال على الاستخدام المفيد لهذه الخاصية هو التشغيل المتوازي لنفس البرنامج مرتين:
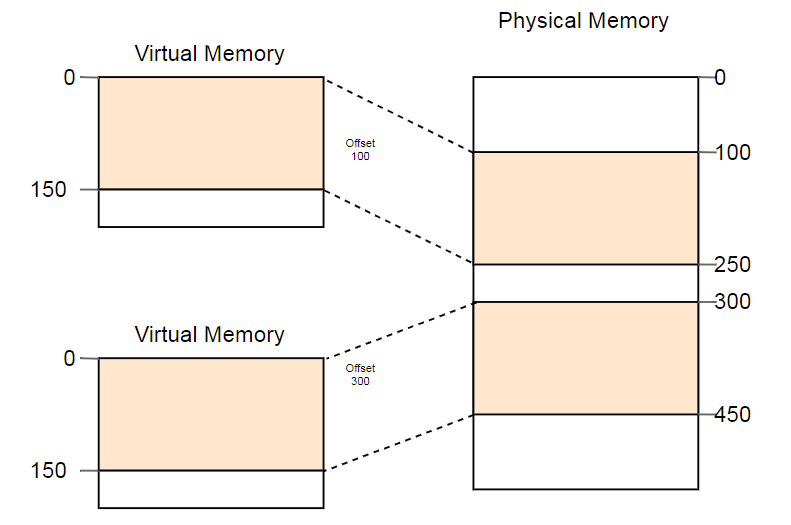
هنا ، يتم تشغيل البرنامج نفسه مرتين ، ولكن مع وظائف تحويل مختلفة. لدى المثيل الأول إزاحة قطاعية قدرها 100 ، لذلك يتم تحويل عناوينها الافتراضية 0-150 إلى عناوين فعلية 100-250. لدى المثيل الثاني إزاحة 300 ، والذي يترجم العناوين الافتراضية 0-150 إلى عناوين فعلية 300-450. هذا يسمح لكلا البرنامجين بتنفيذ نفس الكود واستخدام نفس العناوين الافتراضية دون التدخل في بعضهما البعض.
ميزة أخرى هي أنه يمكن الآن وضع البرامج في أماكن عشوائية على الذاكرة الفعلية. وبالتالي ، يستخدم نظام التشغيل كامل مقدار الذاكرة المتوفرة دون الحاجة إلى إعادة ترجمة البرامج.
التفتت
الفرق بين العناوين الافتراضية والمادية هو إنجاز حقيقي للتجزئة. ولكن هناك مشكلة. تخيل أننا نريد تشغيل النسخة الثالثة من البرنامج التي رأيناها أعلاه:
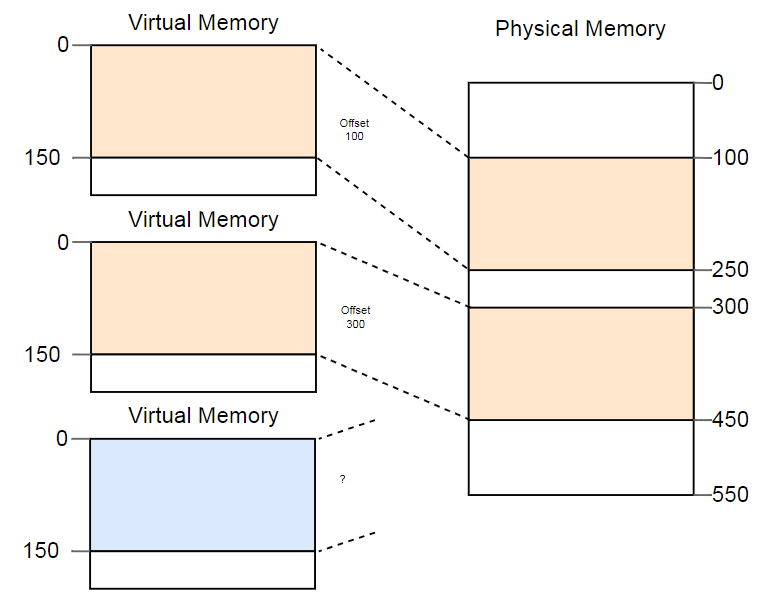
على الرغم من وجود مساحة كافية في الذاكرة الفعلية ، إلا أن النسخة الثالثة لا تناسب أي مكان. المشكلة هي أنه يحتاج إلى جزء
متواصل من الذاكرة ولا يمكننا استخدام أقسام حرة منفصلة.
تتمثل إحدى طرق مكافحة التجزؤ في إيقاف تنفيذ البرنامج مؤقتًا ، ونقل أجزاء الذاكرة المستخدمة أقرب إلى بعضها البعض ، وتحديث التحويل ، ثم استئناف التنفيذ:
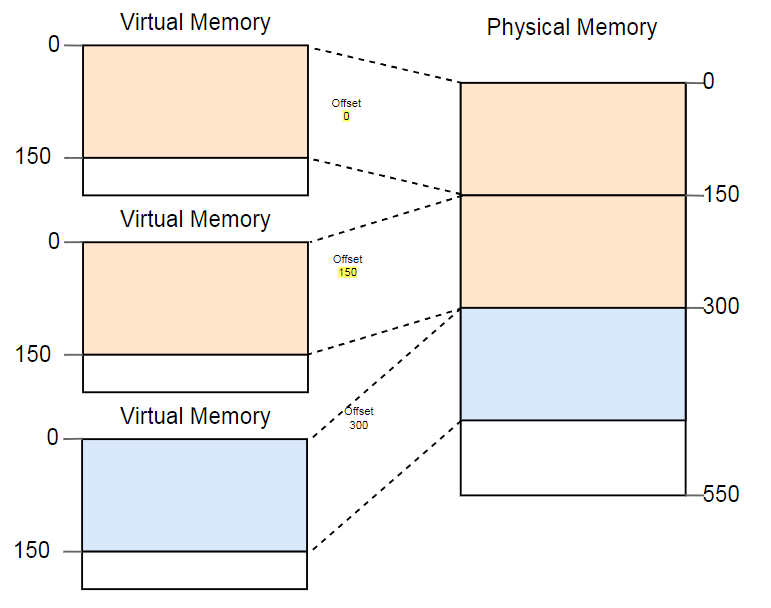
الآن هناك مساحة كافية لإطلاق المثيل الثالث.
عيب هذا إلغاء التجزئة هو الحاجة إلى نسخ كميات كبيرة من الذاكرة ، مما يقلل من الأداء. يجب تنفيذ هذا الإجراء بانتظام حتى تصبح الذاكرة مجزأة جدًا. يصبح الأداء غير متوقع ، وتتوقف البرامج في أي وقت وقد تتوقف عن الاستجابة.
التفتت هو أحد أسباب عدم استخدام التجزئة في معظم الأنظمة. في الواقع ، لم يعد مدعومًا حتى في وضع 64 بت على x86. بدلاً من التجزئة ، يتم استخدام الصفحات التي تقضي تمامًا على مشكلة التجزئة.
تنظيم الصفحة من الذاكرة
والفكرة هي تقسيم مساحة الذاكرة الظاهرية والفيزيائية إلى كتل صغيرة ذات حجم ثابت. تسمى كتل الذاكرة الظاهرية الصفحات ، وتسمى كتل مساحة العنوان الفعلية الإطارات. يتم تعيين كل صفحة بشكل منفرد إلى إطار ، والذي يسمح لك بتقسيم مساحات كبيرة من الذاكرة بين الإطارات المادية غير المجاورة.
تصبح الميزة واضحة إذا كررت المثال بمساحة ذاكرة مجزأة ، ولكن هذه المرة باستخدام الصفحات بدلاً من التجزئة:
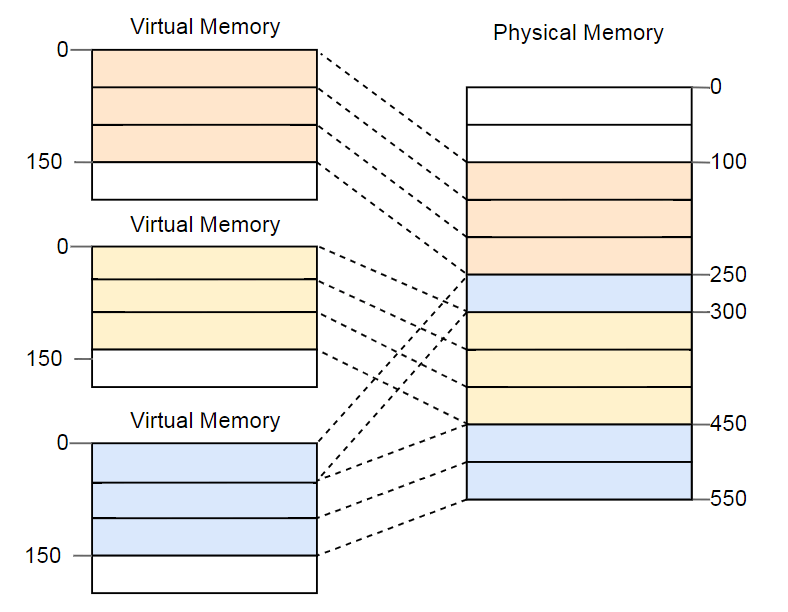
في هذا المثال ، يكون حجم الصفحة 50 بايت ، أي ، يتم تقسيم كل منطقة من مناطق الذاكرة إلى ثلاث صفحات. يتم تعيين كل صفحة إلى إطار منفصل ، بحيث يمكن تعيين منطقة متجاورة من الذاكرة الظاهرية إلى إطارات فعلية معزولة. هذا يسمح لك بتشغيل المثيل الثالث للبرنامج دون إلغاء التجزئة.
تجزئة خفية
بالمقارنة مع التجزئة ، تستخدم مؤسسة الترحيل العديد من مساحات الذاكرة الثابتة صغيرة الحجم بدلاً من العديد من المساحات الكبيرة والمتغيرة الحجم. كل إطار له نفس الحجم ، لذا فإن التجزئة بسبب الإطارات الصغيرة جدًا غير ممكن.
ولكن هذا ليس سوى
مظهر . في الواقع ، هناك شكل مخفي من التجزئة ، ما يسمى
التجزئة الداخلية بسبب حقيقة أن ليس كل منطقة الذاكرة هي بالضبط متعددة من حجم الصفحة. تخيل في المثال أعلاه ، برنامج بحجم 101: سيظل بحاجة إلى ثلاث صفحات بحجم 50 ، لذلك سوف يستغرق 49 بايت أكثر مما تحتاج. من أجل الوضوح ، يُطلق على التجزئة بسبب التجزئة.
لا يوجد شيء جيد في التشرذم الداخلي ، ولكن في كثير من الأحيان يكون أقل شر من التشرذم الخارجي. لا تزال تستهلك ذاكرة إضافية ، ولكن الآن لا تحتاج إلى إلغاء تجزئتها ، ويمكن توقع حجم التجزئة (في المتوسط ، نصف صفحة لكل منطقة ذاكرة).
الجداول الصفحة
لقد رأينا أن كل من ملايين الصفحات المحتملة يتم تعيينها بشكل فردي إلى إطار. يجب أن يتم تخزين معلومات ترجمة العنوان في مكان ما. عند التجزئة ، يتم استخدام سجلات قطعة منفصلة لكل منطقة ذاكرة نشطة ، وهو أمر مستحيل في حالة الصفحات ، لأن عددهم أكبر بكثير من السجلات. بدلاً من ذلك ، يستخدم بنية تسمى
جدول صفحة .
على سبيل المثال أعلاه ، ستبدو الجداول كما يلي:
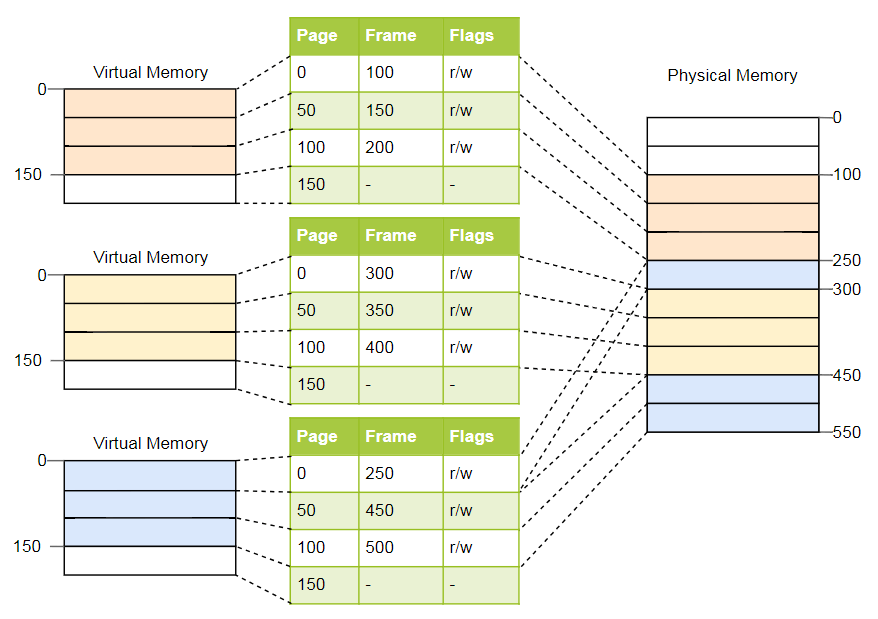
كما ترون ، كل مثيل للبرنامج لديه جدول صفحة خاص به. يتم تخزين مؤشر إلى الجدول النشط الحالي في سجل خاص من وحدة المعالجة المركزية. على
x86 يطلق عليه
CR3 . قبل بدء كل مثيل من البرنامج ، يجب أن يقوم نظام التشغيل بتحميل مؤشر إلى جدول الصفحة الصحيح هناك.
في كل مرة يتم الوصول إلى الذاكرة ، تقرأ وحدة المعالجة المركزية مؤشر الجدول من السجل وتبحث عن الإطار المقابل في الجدول. هذه هي وظيفة الأجهزة بالكامل التي تعمل بشفافية كاملة لبرنامج قيد التشغيل. لتسريع العملية ، تحتوي العديد من بنيات المعالج على ذاكرة تخزين مؤقت خاصة تتذكر نتائج آخر التحويلات.
بناءً على البنية ، يمكن أيضًا تخزين سمات مثل الأذونات في حقل العلامة بجدول الصفحة. في المثال أعلاه ، تجعل علامة
r/w الصفحة قابلة للقراءة والكتابة.
جداول صفحات الطبقات
تواجه جداول الصفحات البسيطة مشكلة في مساحات العناوين الكبيرة: يتم إهدار الذاكرة. على سبيل المثال ، يستخدم البرنامج أربع صفحات افتراضية
0 و
1_000_000 و
1_000_050 و
1_000_100 (نستخدم
_ كفاصل للأرقام):
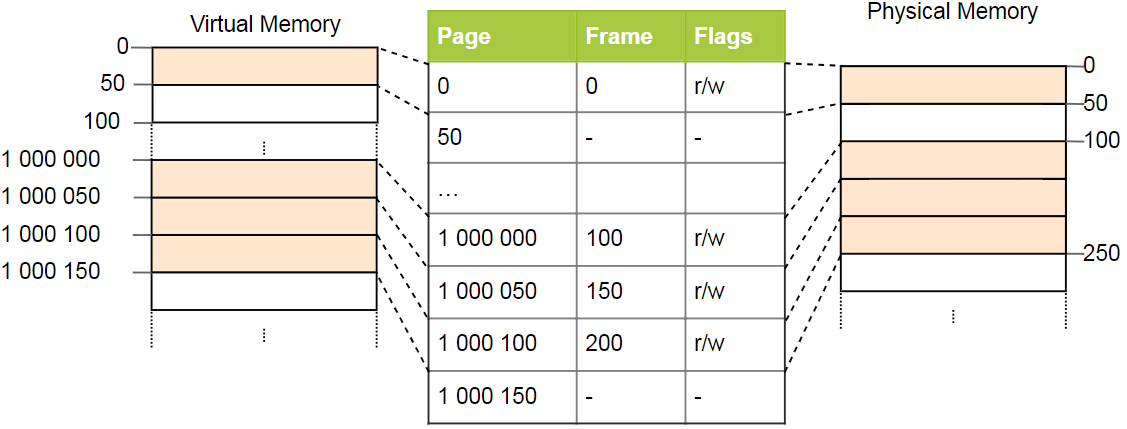
هناك أربعة إطارات فعلية مطلوبة فقط ، ولكن يوجد أكثر من مليون سجل في جدول الصفحات. لا يمكننا تخطي الإدخالات الفارغة ، لأن وحدة المعالجة المركزية أثناء عملية التحويل لن تتمكن من الانتقال مباشرةً إلى الإدخال الصحيح (على سبيل المثال ، لم يعد مضمونًا أن الصفحة الرابعة تستخدم الإدخال الرابع).
لتقليل فقد الذاكرة ، يمكنك استخدام منظمة
من مستويين . الفكرة هي أننا نستخدم جداول مختلفة للمناطق المختلفة. يتم تحويل جدول إضافي ، يسمى جدول صفحات
المستوى الثاني ، بين مساحات العناوين وجداول صفحات المستوى الأول.
وأفضل تفسير لهذا هو المثال. نحدد أن كل جدول من صفحات المستوى 1 مسؤول عن مساحة بحجم
10_000 . ثم في المثال أعلاه ، ستكون الجداول التالية موجودة:
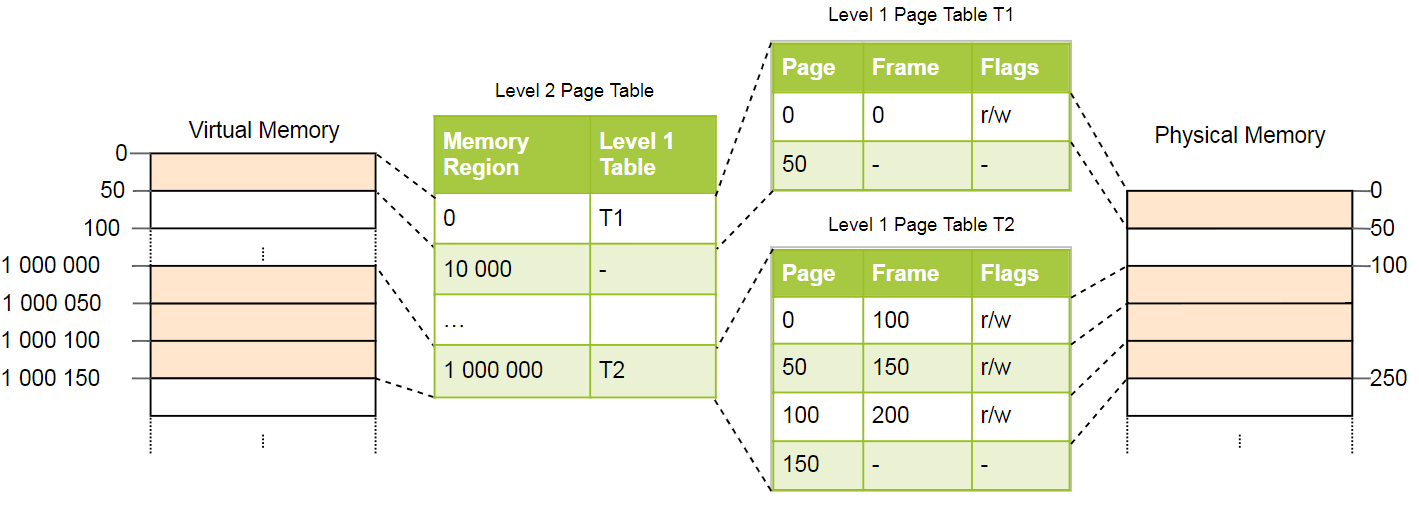
تقع الصفحة 0 في المساحة الأولى البالغة
10_000 بايت ، لذلك تستخدم السجل الأول في جدول صفحات المستوى الثاني. يشير هذا الإدخال إلى جدول صفحة المستوى الأول T1 ، والذي يحدد أن الصفحة 0 تشير إلى الإطار 0.
تقع الصفحات
1_000_000 و
1_000_050 و
1_000_100 في منطقة البايت 100 من
10_000 ، لذلك يستخدمون السجل 100 لجدول صفحة المستوى 2. يشير هذا السجل إلى جدول المستوى الأول الآخر T2 ، والذي يترجم ثلاث صفحات إلى إطارات 100 و 150 و 200. ملاحظة أن عنوان الصفحة في جداول المستوى الأول لا يحتوي على إزاحة منطقة ، لذلك ، على سبيل المثال ، سجل الصفحة
1_000_050 هو
50 فقط.
لا يزال لدينا 100 إدخال فارغ في جدول المستوى الثاني ، ولكن هذا أقل بكثير من المليون السابق. سبب التوفير هو أنك لست بحاجة إلى إنشاء جداول صفحات المستوى الأول لمناطق الذاكرة غير
10_000 بين
10_000 و
1_000_000 .
يمكن تمديد مبدأ الجداول ذات المستويين إلى ثلاثة أو أربعة مستويات أو أكثر. بشكل عام ، يُطلق على هذا النظام جدول صفحات
متعدد المستويات أو
هرمي .
عند معرفة تنظيم الصفحة والجداول متعددة المستويات ، يمكنك معرفة كيفية تنفيذ تنظيم الصفحة في بنية x86_64 (نفترض أن المعالج يعمل في وضع 64 بت).
تنظيم الصفحة على x86_64
تستخدم هندسة x86_64 جدولاً من أربعة مستويات بحجم صفحة 4 كيلوبايت. بغض النظر عن المستوى ، يحتوي كل جدول صفحة على 512 عنصر. يبلغ حجم كل سجل 8 بايت ، وبالتالي فإن حجم الجداول 512 × 8 بايت = 4 كيلوبايت.

كما ترون ، يحتوي كل فهرس جدول على 9 بتات ، وهذا أمر منطقي ، لأن الجداول تحتوي على 2 ^ 9 = 512 إدخال. أقل 12 بت هي إزاحة الصفحة 4 كيلوبايت (2 ^ 12 بايت = 4 كيلوبايت). يتم تجاهل البتات من 48 إلى 64 ، وبالتالي فإن x86_64 ليس في الواقع نظامًا 64 بت ، لكنه يدعم عناوين 48 بت فقط. هناك خطط لتوسيع حجم العنوان إلى 57 بت من خلال
جدول صفحات من 5 مستويات ، ولكن لم يتم إنشاء هذا المعالج بعد.
على الرغم من تجاهل البتات من 48 إلى 64 ، إلا أنه لا يمكن ضبطها على قيم عشوائية. يجب أن تكون جميع البتات في هذا النطاق نسخًا من البتة 47 للحفاظ على العناوين الفريدة والسماح بالتوسع في المستقبل ، على سبيل المثال ، إلى جدول صفحات من 5 مستويات. وهذا ما يسمى امتداد الإشارة ، لأنه يشبه إلى حد بعيد
امتداد علامة في رمز إضافي . إذا تم توسيع العنوان بشكل غير صحيح ، فإن وحدة المعالجة المركزية يتم طرح استثناء.
مثال التحويل
دعونا نلقي نظرة على مثال عن كيفية عمل ترجمة العنوان:
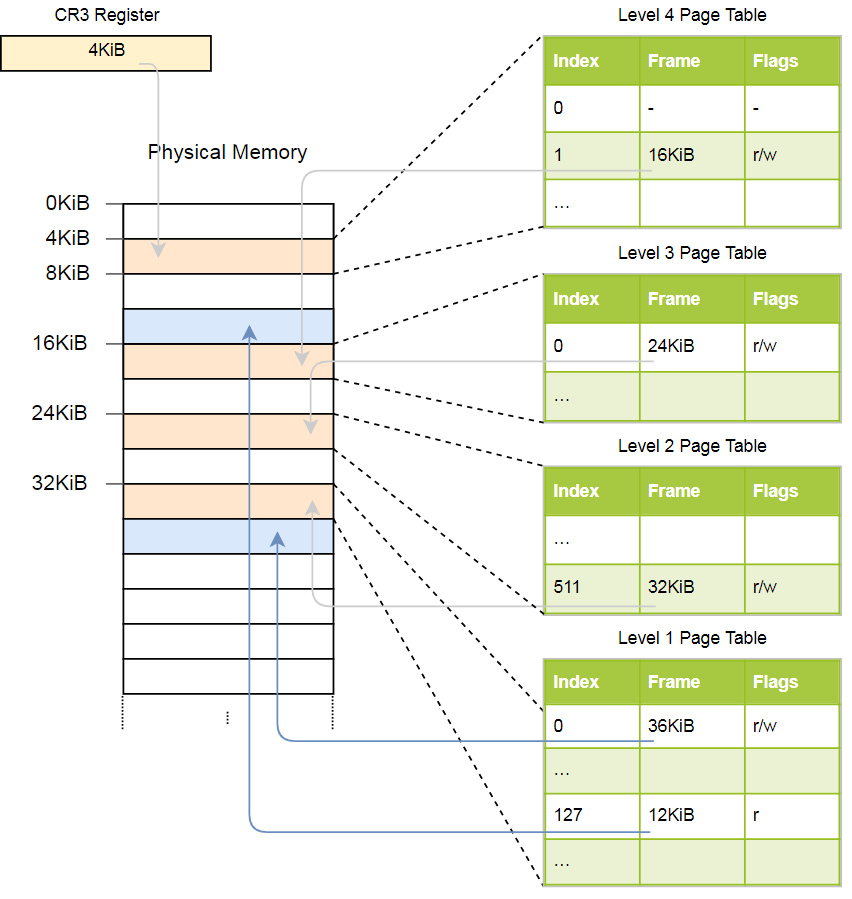
يتم تخزين العنوان الفعلي لجدول الصفحة النشط الحالي لصفحات المستوى 4 ، وهو الجدول الجذر لصفحات الصفحات في هذا المستوى ، في
CR3 . كل إدخال جدول صفحة ثم يشير إلى الإطار الفعلي لجدول المستوى التالي. يشير إدخال جدول المستوى الأول إلى الإطار المعروض. يرجى ملاحظة أن جميع العناوين الموجودة في جداول الصفحات مادية وليست افتراضية ، لأن وحدة المعالجة المركزية ستحتاج إلى تحويل هذه العناوين (مما قد يؤدي إلى تكرار غير محدود).
التسلسل الهرمي أعلاه يحول صفحتين (باللون الأزرق). من المؤشرات ، يمكننا أن نستنتج أن العناوين الافتراضية لهذه الصفحات هي
0x803fe7f000 و
0x803FE00000 . دعونا نرى ما يحدث عندما يحاول برنامج قراءة الذاكرة على العنوان
0x803FE7F5CE . أولاً ، قم بتحويل العنوان إلى ثنائي وحدد فهارس جدول الصفحة والإزاحة للعنوان:

باستخدام هذه الفهارس ، يمكننا الآن الاطلاع على التسلسل الهرمي لجداول الصفحات والعثور على الإطار المقابل:
- اقرأ عنوان جدول المستوى الرابع من
CR3 . - مؤشر المستوى الرابع هو 1 ، لذلك نحن ننظر إلى السجل مع الفهرس 1 في هذا الجدول. وتقول إن المستوى الثالث من الجدول يتم تخزينه على 16 كيلوبايت.
- نقوم بتحميل جدول المستوى الثالث من هذا العنوان وننظر إلى السجل مع الفهرس 0 ، والذي يشير إلى جدول المستوى الثاني على 24 كيلو بايت.
- مؤشر المستوى الثاني هو 511 ، لذلك نحن نبحث عن السجل الأخير في هذه الصفحة لمعرفة عنوان جدول المستوى الأول.
- من الإدخال الذي يحتوي على فهرس 127 في جدول المستوى الأول ، اكتشفنا أخيرًا أن الصفحة تتوافق مع إطار بحجم 12 كيلوبايت أو 0xc000 بتنسيق سداسي عشري.
- الخطوة الأخيرة هي إضافة إزاحة إلى عنوان الإطار للحصول على العنوان الفعلي: 0xc000 + 0x5ce = 0xc5ce.
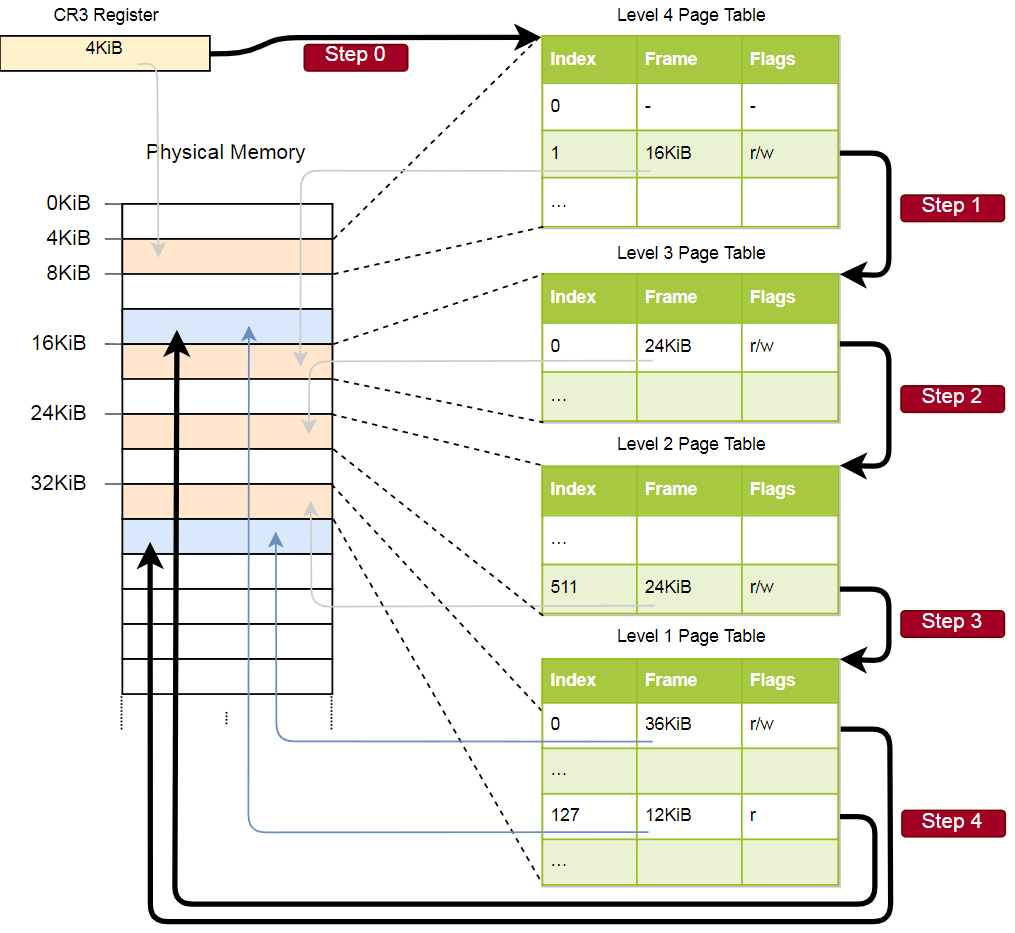
بالنسبة للصفحة الموجودة في جدول المستوى الأول ، يتم تحديد علامة
r ، أي يُسمح بالقراءة فقط. سيتم طرح استثناء على مستوى الأجهزة إذا حاولنا التسجيل هناك. تمتد أذونات الجداول ذات المستوى الأعلى إلى المستويات الأدنى ، لذا إذا وضعنا علامة القراءة فقط على المستوى الثالث ، فلن تكون هناك صفحة لاحقة من المستوى الأدنى قابلة للكتابة ، حتى إذا كانت هناك علامات تسمح بالكتابة.
على الرغم من أن هذا المثال يستخدم مثيل واحد فقط من كل جدول ، إلا أنه في كل مساحة عنوان توجد عدة مثيلات لكل مستوى. الحد الأقصى:
- جدول واحد من المستوى الرابع ،
- 512 جدولًا من المستوى الثالث (نظرًا لوجود 512 سجلًا في جدول المستوى الرابع) ،
- 512 * 512 الجداول المستوى الثاني (لأن كل من الجداول المستوى الثالث يحتوي على 512 إدخالات) ، و
- 512 * 512 * 512 الجداول من المستوى الأول (512 سجلات لكل جدول من المستوى الثاني).
تنسيق جدول الصفحة
في بنية x86_64 ، تعد جداول الصفحات في الأساس صفائف من 512 إدخال. في بناء جملة Rust:
#[repr(align(4096))] pub struct PageTable { entries: [PageTableEntry; 512], }
كما هو موضح في سمة
repr ، يجب محاذاة الجداول في الصفحة ، أي على الحد 4 كيلوبايت. يضمن هذا المتطلب أن يملأ الجدول دائمًا الصفحة بأكملها على النحو الأمثل ، مما يجعل الإدخالات مضغوطة جدًا.
حجم كل سجل 8 بايت (64 بت) والتنسيق التالي:
| بت (ق) | العنوان | القيمة |
|---|
| 0 | حاضر | صفحة في الذاكرة |
| 1 | قابل للكتابة | سجل المسموح بها |
| 2 | المستخدم في متناول | إذا لم يتم ضبط البتة ، عندها فقط يمكن للنواة الوصول إلى الصفحة |
| 3 | الكتابة من خلال التخزين المؤقت | اكتب مباشرة إلى الذاكرة |
| 4 | تعطيل ذاكرة التخزين المؤقت | تعطيل ذاكرة التخزين المؤقت لهذه الصفحة |
| 5 | الوصول إليها | تقوم وحدة المعالجة المركزية بتعيين هذا البت عندما تكون الصفحة قيد الاستخدام. |
| 6 | متسخ | تقوم وحدة المعالجة المركزية بتعيين هذا البت عند الكتابة إلى الصفحة |
| 7 | صفحة ضخمة / فارغة | ينشئ صفر بت في P1 و P4 صفحات 1 كيلو بايت في P3 ، صفحة 2 ميغابايت في P2 |
| 8 | العالمية | لا يتم تعبئة الصفحة من ذاكرة التخزين المؤقت عند تبديل مساحة العنوان (يجب تعيين بت PGE لسجل CR4) |
| 9-11 | متاح | يمكن لنظام التشغيل استخدامها بحرية |
| 12-51 | العنوان الفعلي | محاذاة الصفحة العنوان الفعلي 52 بت من الإطار أو الجدول الصفحة التالية |
| 52-62 | متاح | يمكن لنظام التشغيل استخدامها بحرية |
| 63 | لا تنفيذ | يحظر تنفيذ التعليمات البرمجية في هذه الصفحة (يجب تعيين بت NXE في سجل EFER) |
نرى أنه يتم استخدام البتات 12-51 فقط لتخزين العنوان الفعلي للإطار ، بينما يعمل الباقي كأعلام أو يمكن استخدامه بحرية بواسطة نظام التشغيل. هذا ممكن لأننا نشير دائمًا إما إلى عنوان محاذاة 4096 بايت ، أو إلى صفحة الجداول المحاذية ، أو إلى بداية الإطار المقابل. هذا يعني أن البتات من 0 إلى 11 تكون دائمًا صفرية ، لذا لا يمكن تخزينها ، فهي ببساطة تتم إعادة ضبطها على مستوى الجهاز قبل استخدام العنوان. ينطبق الشيء نفسه على البتات 52-63 ، حيث أن بنية x86_64 تدعم فقط العناوين الفعلية 52 بت (والعناوين الافتراضية 48 بت فقط).
دعونا نلقي نظرة فاحصة على الأعلام المتاحة:
- يميز العلم
present الصفحات المعروضة عن الصفحات غير المعروضة. يمكن استخدامه لحفظ الصفحات مؤقتًا على القرص عند امتلاء الذاكرة الرئيسية. في المرة التالية التي يتم فيها الوصول إلى الصفحة ، يحدث استثناء PageFault خاص ، يستجيب له نظام التشغيل عن طريق تبديل الصفحة من القرص - يستمر البرنامج في العمل. - تحدد العلامات
writable وعدم no execute ما إذا كان محتوى الصفحة قابل للكتابة أو يحتوي على إرشادات قابلة للتنفيذ ، على التوالي. - يتم تعيين الأعلام التي يتم
accessed dirty تلقائيًا بواسطة المعالج عند القراءة أو الكتابة إلى الصفحة. يمكن لنظام التشغيل استخدام هذه المعلومات ، على سبيل المثال ، في حالة تبديل الصفحات أو عند التحقق لمعرفة ما إذا كانت محتويات الصفحة قد تغيرت منذ آخر عملية ضخ على القرص. - تتيح لك
write through caching disable cache إشارات disable cache إدارة ذاكرة التخزين المؤقت لكل صفحة على حدة. - تجعل علامة
user accessible الصفحة قابلة للوصول للرمز من مساحة المستخدم ، وإلا فهي متوفرة فقط للنواة. يمكن استخدام هذه الوظيفة لتسريع مكالمات النظام مع الحفاظ على تعيين العناوين للنواة أثناء تشغيل برنامج المستخدم. ومع ذلك ، تسمح مشكلة عدم حصانة Specter بقراءة هذه الصفحات بواسطة البرامج من مساحة المستخدم. global , (. TLB ) (address space switch). user accessible .huge page , 2 3 . 512 : 2 = 512 × 4 , 1 = 512 × 2 . .
وتعرف X86_64 العمارة شكل جداول الصفحة و السجلات ، لذلك لم يكن لديك لإنشاء هذه الهياكل أنفسهم.الترجمة التحريرية الترابطية (TLB)
بسبب المستويات الأربعة ، يتطلب كل ترجمة عنوان أربعة عمليات الوصول إلى الذاكرة. لأسباب تتعلق بالأداء ، تقوم x86_64 بتخزين الترجمات القليلة الأخيرة في ما يسمى بمخزن مؤقت الترجمة الترابطية (TLB). يتيح لك هذا تخطي التحويل إذا كان لا يزال في ذاكرة التخزين المؤقت.بخلاف ذاكرة التخزين المؤقت للمعالجات الأخرى ، TLB غير شفاف تمامًا ، ولا يقوم بتحديث أو حذف التحويلات عند تغيير محتويات جداول الصفحات. هذا يعني أن النواة يجب أن تقوم بتحديث TLB نفسه كلما قام بتعديل جدول الصفحة. للقيام بذلك ، هناك تعليمة CPU خاصة تسمى invlpg(صفحة غير صالحة) ، والتي تزيل ترجمة الصفحة المحددة من TLB ، بحيث يتم تحميلها مرة أخرى من جدول الصفحة في المرة التالية. يتم مسح TLB تمامًا بواسطة تحديث السجلCR3أن يحاكي مفتاح مساحة العنوان. كلا الخيارين متاح من خلال وحدة tlb في Rust.من المهم ألا تنسى تنظيف TLB بعد تغيير جدول كل صفحة ، وإلا ستواصل وحدة المعالجة المركزية استخدام الترجمة القديمة ، مما سيؤدي إلى أخطاء غير متوقعة يصعب تصحيحها.التنفيذ
لم نذكر شيئًا واحدًا: جوهرنا يدعم بالفعل تنظيم الصفحة . أنشأ محمل الإقلاع من مقالة "Minimal Kernel on Rust" بالفعل تسلسل هرمي من أربعة مستويات يرسم كل صفحة من نواة لدينا إلى إطار مادي ، لأن تنظيم الصفحة مطلوب في وضع 64 بت على x86_64.هذا يعني أنه في جوهرنا جميع عناوين الذاكرة افتراضية. يعمل الوصول إلى المخزن المؤقت VGA في العنوان 0xb8000فقط لأن معرف أداة تحميل التشغيل ترجم هذه الصفحة إلى الذاكرة ، أي أنه قام بتعيين الخريطة الافتراضية 0xb8000إلى الإطار الفعلي 0xb8000.بفضل تنظيم الصفحة ، أصبح kernel آمنًا نسبيًا: كل وصول يتجاوز الذاكرة المسموح بها يتسبب في حدوث خطأ في الصفحة ، ولا يسمح بالكتابة إلى الذاكرة الفعلية. يقوم المحمل حتى بتعيين أذونات الوصول الصحيحة لكل صفحة: فقط الصفحات التي بها تعليمات برمجية ستكون قابلة للتنفيذ ، وتتوفر فقط الصفحات التي تحتوي على بيانات للكتابةأخطاء الصفحة (PageFault)
دعونا نحاول استدعاء PageFault عن طريق الوصول إلى الذاكرة خارج النواة. أولاً ، قم بإنشاء معالج خطأ وتسجيله في IDT الخاص بنا لرؤية استثناء محدد بدلاً من خطأ مزدوج من نوع عام:
في حالة فشل الصفحة ، تقوم وحدة المعالجة المركزية تلقائيًا بتعيين الحالة CR2. أنه يحتوي على العنوان الظاهري للصفحة التي تسببت في الفشل. لقراءة وعرض هذا العنوان ، استخدم الوظيفة Cr2::read. عادةً ما PageFaultErrorCodeيوفر النوع مزيدًا من المعلومات حول نوع الوصول إلى الذاكرة الذي تسبب في حدوث الخطأ ، ولكن يتم إرسال رمز خطأ غير صالح بسبب خطأ LLVM ، لذلك سنتجاهل هذه المعلومات في الوقت الحالي. لا يمكن متابعة تنفيذ البرنامج حتى يتم حل خطأ الصفحة ، لذلك ، أدخل في النهاية hlt_loop.نصل الآن إلى الذاكرة خارج النواة:
بعد البدء ، نرى أن معالج أخطاء الصفحة يسمى: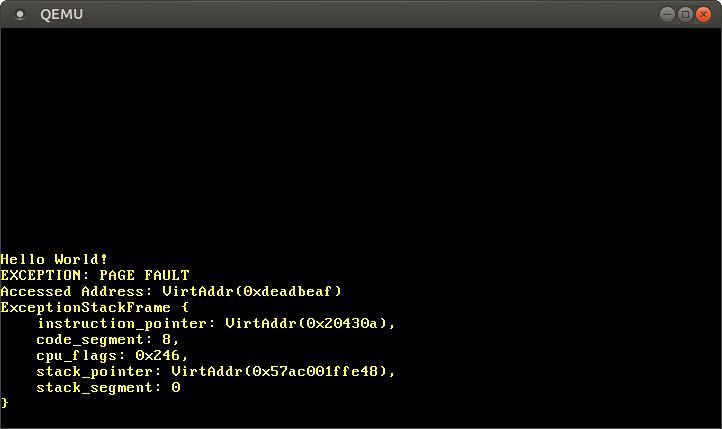 السجل
السجل CR2يحتوي حقًا على العنوان 0xdeadbeafالذي أردنا الوصول إليه.مؤشر التعليمات الحالي هو 0x20430a، لذلك نحن نعرف أن هذا العنوان يشير إلى صفحة الرموز. يتم عرض صفحات الرموز بواسطة أداة تحميل للقراءة فقط ، لذلك تعمل القراءة من هذا العنوان ، وستتسبب الكتابة في حدوث خطأ. حاول تغيير المؤشر 0xdeadbeafإلى 0x20430a:
إذا علقنا على السطر الأخير ، فيمكننا التأكد من أن القراءة تعمل وأن الكتابة تسبب خطأ PageFault.الوصول إلى جداول الصفحات
ألقِ نظرة الآن على جداول الصفحات الخاصة بالنواة:
الدالة Cr3::readمن x86_64إرجاع من تسجيل CR3الجدول النشط الحالي لصفحات المستوى الرابع. عوائد زوجين PhysFrameو Cr3Flags. نحن مهتمون فقط في الأول.بعد البدء ، نرى هذه النتيجة:Level 4 page table at: PhysAddr(0x1000)وهكذا ، في الوقت الحالي ، يتم تخزين الجدول النشط لصفحات المستوى الرابع في الذاكرة الفعلية على العنوان 0x1000كما هو موضح بالنوع PhysAddr. والسؤال الآن هو: كيفية الوصول إلى هذا الجدول من النواة؟مع تنظيم الصفحة ، لا يمكن الوصول المباشر إلى الذاكرة الفعلية ، وإلا ستتمكن البرامج من تجاوز الحماية بسهولة والوصول إلى ذاكرة البرامج الأخرى. وبالتالي ، فإن الطريقة الوحيدة للوصول إلى ذلك هي من خلال بعض الصفحات الافتراضية ، والتي تُترجم إلى إطار فعلي في0x1000. هذه مشكلة نموذجية لأنه يجب على kernel الوصول بانتظام إلى جداول الصفحات ، على سبيل المثال ، عند تخصيص مكدس لمؤشر ترابط جديد.سيتم وصف حلول هذه المشكلة بالتفصيل في المقالة التالية. الآن ، دعنا نقول فقط أن أداة التحميل تستخدم طريقة تسمى جداول الصفحات العودية . الصفحة الأخيرة من مساحة العنوان الافتراضية هي 0xffff_ffff_ffff_f000، نستخدمها لقراءة بعض الإدخالات في هذا الجدول:
لقد خفضنا عنوان الصفحة الافتراضية الأخيرة إلى مؤشر إلى u64. كما هو مذكور في القسم السابق ، يبلغ حجم إدخال جدول الصفحة 8 بايت (64 بت) ، وبالتالي u64يمثل إدخالًا واحدًا بالضبط. باستخدام الحلقة ، forنعرض السجلات العشرة الأولى من الجدول. داخل الحلقة ، نستخدم كتلة غير آمنة للقراءة مباشرة من المؤشر offsetولحساب المؤشر.بعد بدء نرى النتائج التالية: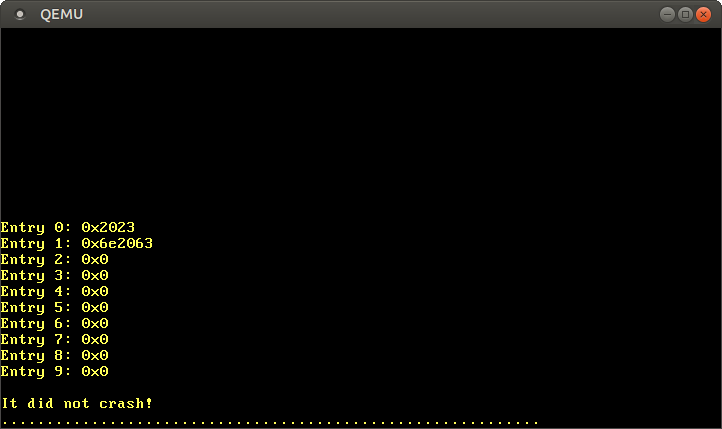 وفقا للصيغة المذكورة أعلاه، وقيمة
وفقا للصيغة المذكورة أعلاه، وقيمة 0x2023وسائل تسجيل وجود أعلام 0 present، writable، accessedوترجمتها إلى إطار 0x2000. يتم بث السجل 1 في الإطار 0x6e2000ولديه نفس العلامات ، بالإضافة إلىdirty. الإدخالات 2–9 مفقودة ، لذلك لا يتم تعيين نطاقات العناوين الافتراضية هذه إلى أي عناوين فعلية.بدلاً من العمل مع مؤشرات غير آمنة مباشرة ، يمكنك استخدام نوع PageTableمن x86_64:
0xffff_ffff_ffff_f000 , Rust. - , , .
&PageTable , ,
.
x86_64 , :

— 0 1 3. ,
0x2000 0x6e5000 , . .
ملخص
تقدم المقالة طريقتين لحماية الذاكرة: التجزئة وتنظيم الصفحة. تستخدم الطريقة الأولى مناطق ذاكرة متغيرة الحجم وتعاني من تجزئة خارجية ، بينما تستخدم الطريقة الثانية صفحات ذات حجم ثابت وتسمح بمزيد من التحكم الدقيق في حقوق الوصول.تخزن مؤسسة الصفحة معلومات ترجمة الصفحة في جداول بمستوى واحد أو أكثر. تستخدم هندسة x86_64 جداول من أربعة مستويات بحجم صفحة 4 كيلوبايت. تتجاوز المعدات تلقائيًا جداول الصفحات وتخزين نتائج التحويل مؤقتًا في مخزن الترجمة الترابطي (TLB). عند تغيير جداول الصفحات ، يجب إجبارها على التنظيف.لقد تعلمنا أن جوهرنا يدعم بالفعل تنظيم الصفحة ، وأن الوصول غير المصرح به إلى الذاكرة يسقط PageFault. لقد حاولنا الوصول إلى جداول الصفحات النشطة حاليًا ، لكننا تمكنا من الوصول إلى جدول المستوى الرابع فقط ، لأن عناوين الصفحات تخزن العناوين الفعلية ، ولا يمكننا الوصول إليها مباشرة من النواة.ما التالي؟
تستند المقالة التالية إلى الأسس الأساسية التي تعلمناها الآن. للوصول إلى جداول الصفحات من النواة ، يتم استخدام تقنية متقدمة تسمى جداول الصفحات العودية لاجتياز التسلسل الهرمي للجدول وتنفيذ ترجمة العنوان البرنامجي. يشرح المقال أيضًا كيفية إنشاء ترجمات جديدة في جداول الصفحات.