في عصرنا ، حققت الآلات بنجاح 99 ٪ من الدقة في فهم وتحديد الميزات والكائنات في الصور. نواجه هذا كل يوم ، على سبيل المثال: التعرف على الوجوه في كاميرا الهاتف الذكي ، والقدرة على البحث عن الصور على google ، ومسح النصوص من الرمز الشريطي أو الكتب بسرعة جيدة ، وما إلى ذلك. إن كفاءة الجهاز هذه ممكنة بفضل نوع خاص من الشبكات العصبية تدعى convolutional neural الشبكة. إذا كنت من عشاق التعلم العميق ، فربما تكون قد سمعت عنه ، ويمكنك تطوير عدة مصنفات للصور. تعمل أطر التعلم العميقة الحديثة مثل Tensorflow و PyTorch على تبسيط عملية التعلم من آلة الصورة. ومع ذلك ، يبقى السؤال: كيف تمر البيانات عبر طبقات الشبكة العصبية وكيف يتعلم الكمبيوتر منها؟ للحصول على رؤية واضحة من نقطة الصفر ، نغرق في الالتواء ونرى صورة كل طبقة.

الشبكات العصبية التلافيفية
قبل أن تبدأ في دراسة الشبكات العصبية التلافيفية (SNA) ، تحتاج إلى معرفة كيفية العمل مع الشبكات العصبية. تحاكي الشبكات العصبية العقل البشري لحل المشكلات المعقدة والبحث عن أنماط في البيانات. على مدار السنوات القليلة الماضية ، استبدلوا العديد من خوارزميات التعلم الآلي ورؤية الكمبيوتر. يتكون النموذج الأساسي للشبكة العصبية من خلايا عصبية منظمة في طبقات. تحتوي كل شبكة عصبية على طبقة إدخال وإخراج والعديد من الطبقات المخفية تضاف إليها اعتمادًا على تعقيد المشكلة. عند نقل البيانات عبر الطبقات ، يتم تدريب الخلايا العصبية والتعرف على العلامات. يسمى هذا التمثيل للشبكة العصبية نموذجًا. بعد تدريب النموذج ، نطلب من الشبكة عمل تنبؤات بناءً على بيانات الاختبار.
SNS هو نوع خاص من الشبكات العصبية التي تعمل بشكل جيد مع الصور. اقترحهم إيان ليكون في عام 1998 ، حيث أدركوا العدد الموجود في صورة الإدخال. يستخدم SNA أيضًا في التعرف على الكلام وتجزئة الصور ومعالجة النصوص. قبل إنشاء الشبكات العصبية التلافيفية ، تم استخدام الإدراك الحسي متعدد الطبقات في بناء مصنفات الصور. يشير تصنيف الصورة إلى مهمة استخراج الطبقات من صورة نقطية متعددة القنوات (ملونة ، بالأسود والأبيض). يستغرق الإدراك الحسي متعدد الطبقات وقتًا طويلاً للبحث عن المعلومات في الصور ، حيث يجب أن يرتبط كل إدخال بكل خلية عصبية في الطبقة التالية. ذهب SNA حولهم باستخدام مفهوم يسمى الاتصال المحلي. هذا يعني أننا سنربط كل خلية عصبية فقط بمنطقة الإدخال المحلية. هذا يقلل من عدد المعلمات ، مما يسمح لأجزاء مختلفة من الشبكة بالتخصص في سمات عالية المستوى مثل الملمس أو نمط التكرار. حائرة؟ دعونا نقارن كيفية نقل الصور من خلال الإدراك الحسي متعدد الطبقات (MPs) والشبكات العصبية التلافيفية.
مقارنة النائب و SNA
سيكون إجمالي عدد الإدخالات في طبقة الإدخال لـ perceptron متعدد الطبقات 784 ، نظرًا لأن حجم صورة الإدخال 28x28 = 784 (يتم اعتبار مجموعة بيانات MNIST). يجب أن تكون الشبكة قادرة على التنبؤ بالرقم الموجود في صورة الإدخال ، مما يعني أن الإخراج يمكن أن ينتمي إلى أي من الفئات التالية في النطاق من 0 إلى 9. في طبقة المخرجات ، نرجع تقديرات الفئة ، على سبيل المثال ، إذا كان هذا الإدخال هو الصورة ذات الرقم "3" ، ثم في طبقة الخرج تتمتع الخلية العصبية المقابلة "3" بقيمة أعلى مقارنة بالخلايا العصبية الأخرى. مرة أخرى ، يطرح السؤال: "كم عدد الطبقات المخفية التي نحتاجها وعدد الخلايا العصبية التي يجب أن تكون في كل منها؟" على سبيل المثال ، خذ شفرة MP التالية:
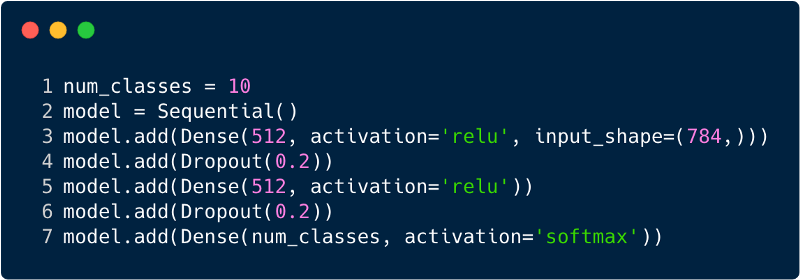
يتم تنفيذ التعليمات البرمجية أعلاه باستخدام إطار يسمى Keras. تحتوي الطبقة المخفية الأولى على 512 خلية عصبية متصلة بطبقة إدخال 784 خلية عصبية. الطبقة المخفية التالية: طبقة الاستبعاد ، والتي تحل مشكلة إعادة التدريب. 0.2 تعني أن هناك فرصة بنسبة 20٪ لعدم مراعاة الخلايا العصبية في الطبقة المخفية السابقة. لقد أضفنا مرة أخرى طبقة مخفية ثانية بنفس عدد الخلايا العصبية كما في الطبقة المخفية الأولى (512) ، ثم طبقة أخرى حصرية. أخيرًا ، إنهاء مجموعة الطبقات هذه بطبقة إخراج تتكون من 10 فئات. الفئة الأكثر أهمية هي الرقم الذي تنبأ به النموذج. هذه هي الطريقة التي تعتني بها شبكة متعددة الطبقات بعد تحديد جميع الطبقات. أحد عيوب جهاز الإدراك الحسي متعدد المستويات هو أنه متصل بشكل كامل ، الأمر الذي يستغرق الكثير من الوقت والمساحة.
لا تستخدم المتسابقات طبقات مترابطة بالكامل. يستخدمون طبقات متناثرة ، والتي تأخذ المصفوفات كمدخلات ، والتي تعطي ميزة على MP. في MP ، كل عقدة مسؤولة عن فهم الصورة كاملة. في نظام الحسابات القومية ، نقوم بتقسيم الصورة إلى مناطق (مناطق محلية صغيرة من وحدات البكسل). تجمع طبقة المخرجات البيانات المستلمة من كل عقدة مخفية للعثور على الأنماط. يوجد أدناه صورة لكيفية توصيل الطبقات.
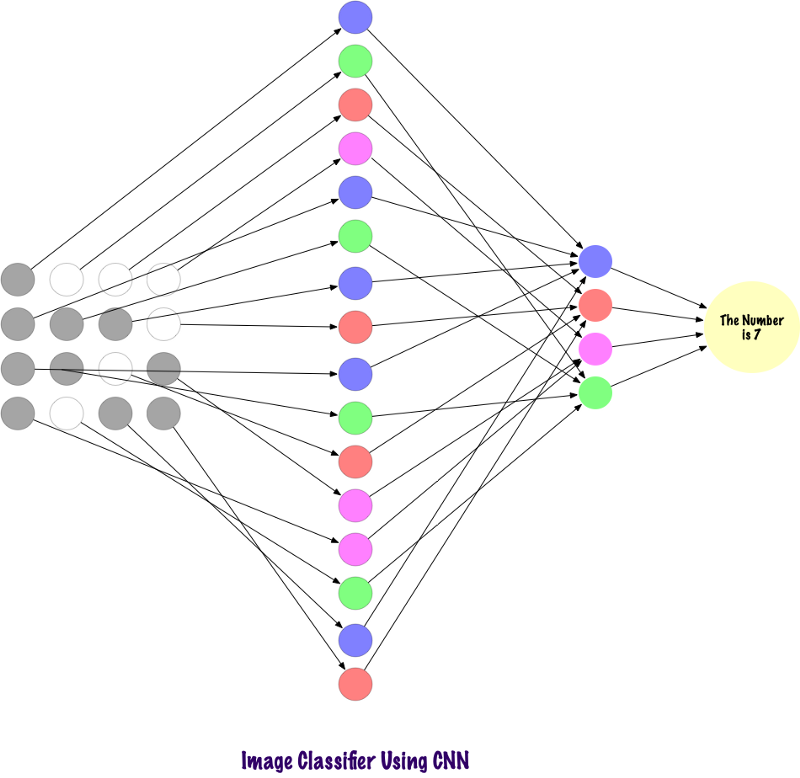
الآن دعونا نرى كيف يجد SNA معلومات في الصور. قبل ذلك ، نحن بحاجة إلى فهم كيفية استخراج العلامات. في نظام الحسابات القومية ، نستخدم طبقات مختلفة ، تحافظ كل طبقة على علامات الصورة ، على سبيل المثال ، تأخذ في الاعتبار صورة الكلب ، عندما تحتاج الشبكة إلى تصنيف الكلب ، يجب أن تحدد جميع العلامات ، مثل العيون والأذنين واللسان والساقين ، إلخ. هذه العلامات مكسورة ومعترف بها على مستويات الشبكة المحلية باستخدام المرشحات والنوى.
كيف تنظر أجهزة الكمبيوتر إلى صورة؟
الشخص الذي ينظر إلى الصورة وفهم معناها يبدو معقولاً للغاية. دعنا نقول أنك تمشي ، ولاحظ العديد من المناظر الطبيعية من حولك. كيف نفهم الطبيعة في هذه الحالة؟ نلتقط صورًا للبيئة باستخدام عضونا الحسي الرئيسي - العين ، ثم نرسلها إلى شبكية العين. كل شيء يبدو مثيرا للاهتمام ، أليس كذلك؟ الآن دعنا نتخيل أن الكمبيوتر يفعل نفس الشيء. في أجهزة الكمبيوتر ، يتم تفسير الصور باستخدام مجموعة من قيم البيكسل التي تتراوح من 0 إلى 255. يبحث الكمبيوتر في قيم البيكسل هذه ويفهمها. للوهلة الأولى ، لا يعرف الأشياء والألوان. إنه ببساطة يتعرف على قيم البيكسل ، والصورة مكافئة لمجموعة من قيم البيكسل للكمبيوتر. في وقت لاحق ، من خلال تحليل قيم البيكسل ، يتعلم تدريجياً ما إذا كانت الصورة رمادية أو ملونة. تحتوي الصور ذات التدرج الرمادي على قناة واحدة فقط ، حيث يمثل كل بكسل كثافة لون واحد. 0 تعني الأسود ، و 255 تعني الأبيض ، والمتغيرات الأخرى من الأسود والأبيض ، أي الرمادي ، هي بينهما.
الصور الملونة لها ثلاث قنوات ، الأحمر والأخضر والأزرق. إنها تمثل شدة 3 ألوان (مصفوفة ثلاثية الأبعاد) ، وعندما تتغير القيم في وقت واحد ، فإن هذا يعطي مجموعة كبيرة من الألوان ، في الحقيقة لوحة ألوان! بعد ذلك ، يتعرف الكمبيوتر على منحنيات ومحيط الكائنات في الصورة. كل هذا يمكن دراسته في الشبكة العصبية التلافيفية. لهذا ، سوف نستخدم PyTorch لتحميل مجموعة البيانات وتطبيق المرشحات على الصور. ما يلي هو مقتطف من الشفرة.
الآن دعونا نرى كيف يتم تغذية صورة واحدة في شبكة العصبية.
img = np.squeeze(images[7]) fig = plt.figure(figsize = (12,12)) ax = fig.add_subplot(111) ax.imshow(img, cmap='gray') width, height = img.shape thresh = img.max()/2.5 for x in range(width): for y in range(height): val = round(img[x][y],2) if img[x][y] !=0 else 0 ax.annotate(str(val), xy=(y,x), color='white' if img[x][y]<thresh else 'black')

هكذا يتم تقسيم الرقم "3" إلى وحدات بكسل. من مجموعة الأرقام المكتوبة بخط اليد ، يتم تحديد "3" بشكل عشوائي ، حيث يتم عرض قيم البيكسل. هنا ToTensor () تطبيع قيم بكسل الفعلية (0-255) ويقصرها على نطاق من 0 إلى 1. لماذا هذا؟ لأنه يسهل العمليات الحسابية في الأقسام التالية ، إما لتفسير الصور ، أو لإيجاد أنماط شائعة موجودة فيها.
قم بإنشاء الفلتر الخاص بك
المرشحات ، كما يوحي الاسم ، تصفية المعلومات. في حالة الشبكات العصبية التلافيفية ، عند العمل مع الصور ، يتم تصفية المعلومات المتعلقة بالبكسل. لماذا يجب علينا تصفية على الإطلاق؟ تذكر أن الكمبيوتر يجب أن يمر بعملية تعليمية لفهم الصور ، مشابهًا جدًا لكيفية قيام الطفل بذلك. في هذه الحالة ، لن نحتاج إلى سنوات عديدة! باختصار ، يتعلم من الصفر ثم يتقدم إلى الكل.
لذلك ، يجب أن تعرف الشبكة في البداية جميع الأجزاء الخشنة في الصورة ، أي الحواف والخطوط العريضة والعناصر الأخرى ذات المستوى المنخفض. بمجرد اكتشافها ، يتم تمهيد مسار الأعراض المعقدة. للوصول إليهم ، يجب أولاً استخراج السمات ذات المستوى المنخفض ، ثم الوسط ، ثم السمات ذات المستوى الأعلى. تعتبر الفلاتر طريقة لاستخراج المعلومات التي يحتاجها المستخدم ، وليس فقط نقل البيانات الأعمى ، بسبب عدم فهم الكمبيوتر لهيكلة الصور. في البداية ، يمكن استخراج الوظائف ذات المستوى المنخفض بناءً على مرشح معين. يعد عامل التصفية هنا أيضًا مجموعة من قيم البكسل ، تشبه الصورة. يمكن فهمه على أنه الأوزان التي تربط الطبقات في الشبكة العصبية التلافيفية. يتم ضرب هذه الأوزان أو المرشحات بقيم الإدخال لإنتاج صور وسيطة تمثل فهم الكمبيوتر للصورة. ثم يتم ضربهم بواسطة عدد قليل من المرشحات لتوسيع العرض. ثم يكتشف الأعضاء المرئية للشخص (بشرط أن يكون الشخص موجودًا في الصورة). فيما بعد ، مع تضمين العديد من المرشحات وعدة طبقات ، صرخ الكمبيوتر: "أوه ، نعم! هذا رجل ".
إذا تحدثنا عن المرشحات ، فلدينا العديد من الخيارات. قد ترغب في طمس الصورة ، ثم تطبيق مرشح طمس ، إذا كنت بحاجة إلى إضافة حدة ، فسيأتي مرشح الحدة إلى عملية الإنقاذ ، إلخ.
لنلقِ نظرة على مقتطفات برمجية قليلة لفهم وظيفة المرشحات.

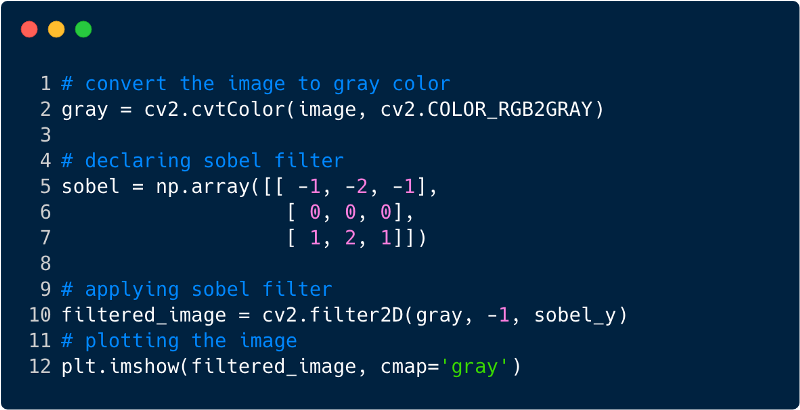

هكذا تبدو الصورة بعد تطبيق المرشح ، وفي هذه الحالة استخدمنا مرشح Sobel.
الشبكات العصبية التلافيفية
لقد رأينا حتى الآن كيفية استخدام المرشحات لاستخراج ميزات من الصور. الآن ، لاستكمال الشبكة العصبية التلافيفية بأكملها ، نحتاج إلى معرفة جميع الطبقات التي نستخدمها لتصميمها. الطبقات المستخدمة في نظام الحسابات القومية ،
- طبقة تلافيفية
- تجمع طبقة
- طبقة المستعبدين بالكامل
مع الطبقات الثلاث ، يبدو مصنف الصور التلافيفي كما يلي:
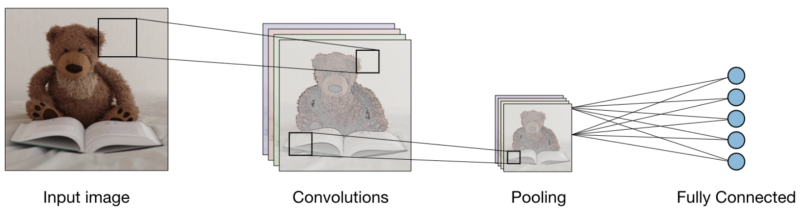
الآن دعونا نرى ما يفعله كل طبقة.
تستخدم الطبقة التلافيفية (CONV) المرشحات التي تؤدي عمليات الالتواء عن طريق مسح صورة الإدخال. تتضمن المعلمات الفائقة حجم مرشح ، والذي يمكن أن يكون 2x2 ، 3x3 ، 4x4 ، 5x5 (ولكن ليس على سبيل الحصر) والخطوة S. وتسمى النتيجة O خريطة المعالم أو خريطة التنشيط التي يتم فيها حساب جميع الميزات باستخدام طبقات الإدخال ومرشحات. فيما يلي صورة لتوليد خرائط المعالم عند تطبيق الإلتواء ،
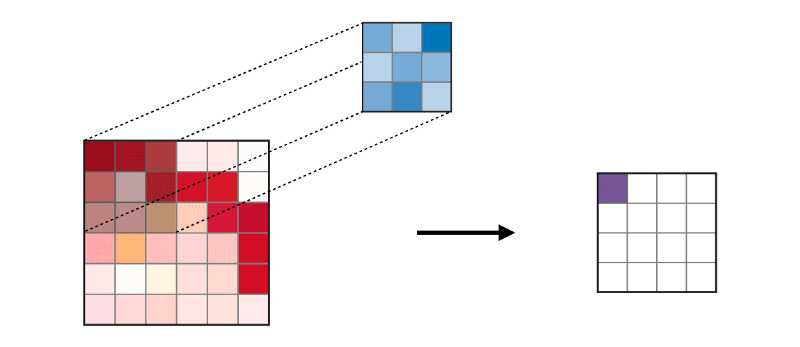 يتم استخدام طبقة الدمج (POOL)
يتم استخدام طبقة الدمج (POOL) لضغط الميزات المستخدمة عادة بعد طبقة الالتواء. هناك نوعان من عمليات الاتحاد - هذا هو الاتحاد الأقصى والمتوسط ، حيث يتم أخذ القيم القصوى والمتوسط للخصائص ، على التوالي. ما يلي هو تشغيل عمليات دمج ،
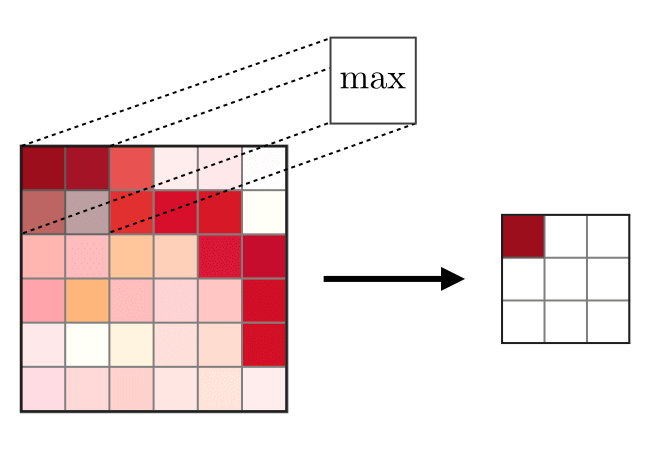
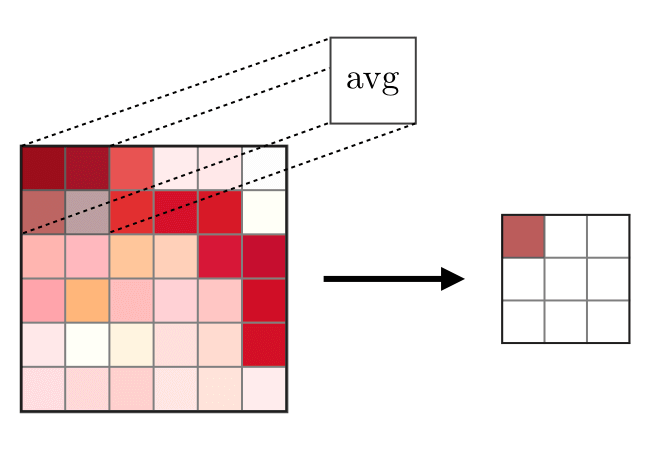
تعمل
الطبقات المتصلة بالكامل (FCs) مع إدخال مسطح ، حيث يتم توصيل كل إدخال بجميع الخلايا العصبية. يتم استخدامها عادةً في نهاية الشبكة لتوصيل الطبقات المخفية بطبقة الإخراج ، مما يساعد على تحسين نتائج الصف.
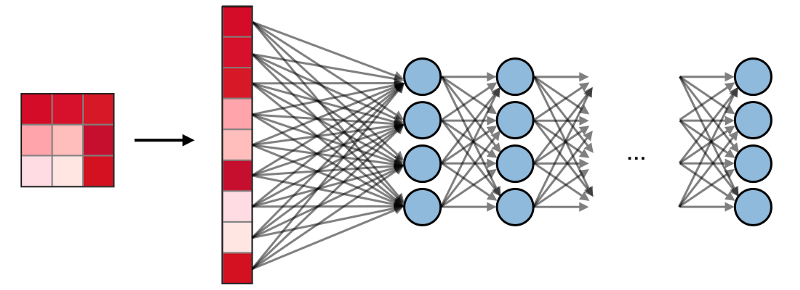
التصور SNA في PyTorch
الآن وقد أصبح لدينا الإيديولوجية الكاملة لبناء نظام الحسابات القومية ، فلننفذ نظام الحسابات القومية باستخدام إطار عمل PyTorch من Facebook.
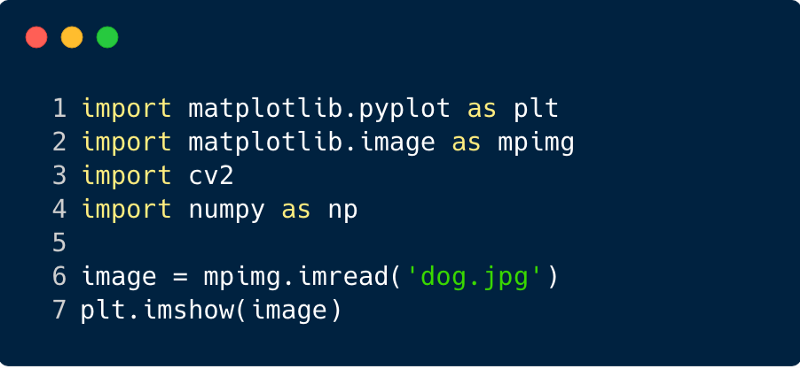
الخطوة 1 : قم بتنزيل صورة الإدخال المراد إرسالها عبر الشبكة. (هنا نفعل ذلك مع Numpy و OpenCV)
import cv2 import matplotlib.pyplot as plt %matplotlib inline img_path = 'dog.jpg' bgr_img = cv2.imread(img_path) gray_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2GRAY)
 الخطوة 2
الخطوة 2 : تقديم المرشحات
دعنا نتصور المرشحات لفهم المرشحات التي سنستخدمها بشكل أفضل ،
import numpy as np filter_vals = np.array([ [-1, -1, 1, 1], [-1, -1, 1, 1], [-1, -1, 1, 1], [-1, -1, 1, 1] ]) print('Filter shape: ', filter_vals.shape)
 الخطوة 3
الخطوة 3 : تحديد SNA
يحتوي نظام الحسابات القومية هذا على طبقة تلافيفية وطبقة تجميع ذات وظيفة قصوى ، وتتم تهيئة الأوزان باستخدام المرشحات الموضحة أعلاه ،
import torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self, weight): super(Net, self).__init__()
Net( (conv): Conv2d(1, 4, kernel_size=(4, 4), stride=(1, 1), bias=False) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) )
الخطوة 4 : تقديم المرشحات
نظرة سريعة على المرشحات المستخدمة ،
def viz_layer(layer, n_filters= 4): fig = plt.figure(figsize=(20, 20)) for i in range(n_filters): ax = fig.add_subplot(1, n_filters, i+1) ax.imshow(np.squeeze(layer[0,i].data.numpy()), cmap='gray') ax.set_title('Output %s' % str(i+1)) fig = plt.figure(figsize=(12, 6)) fig.subplots_adjust(left=0, right=1.5, bottom=0.8, top=1, hspace=0.05, wspace=0.05) for i in range(4): ax = fig.add_subplot(1, 4, i+1, xticks=[], yticks=[]) ax.imshow(filters[i], cmap='gray') ax.set_title('Filter %s' % str(i+1)) gray_img_tensor = torch.from_numpy(gray_img).unsqueeze(0).unsqueeze(1)
مرشحات:
 الخطوة 5
الخطوة 5 : تصفية النتائج حسب الطبقة
يتم عرض الصور التي تظهر في طبقة CONV و POOL أدناه.
viz_layer(activated_layer) viz_layer(pooled_layer)
طبقات تلافيفية

تجمع طبقات
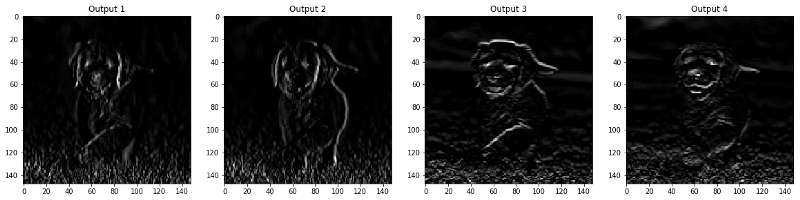 المصدر
المصدر