لذلك ، في 4 يناير ، الساعة 7:15 ، بعد أن قضيت على عيني من النوم ، وجدت حزمة من رسالة في مجموعة Telegram من خادم Zabbix تفيد بزيادة تحميل وحدة المعالجة المركزية على أحد خوادم المحاكاة الافتراضية:
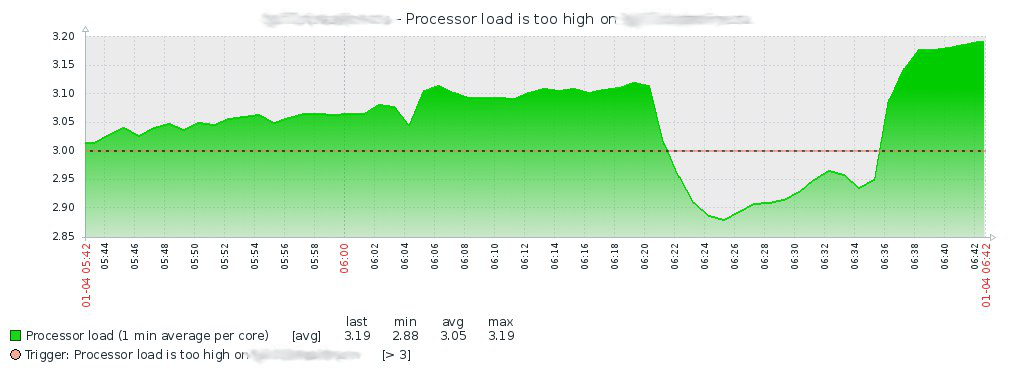
بعد النظر إلى السجل في Zabbix ، أتسلق إلى الخادم وأبحث في dmesg ، حيث أجد ما يلي:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter. [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
إنني أتسلق إلى وحدة التخزين حيث يبحث مهايئ QLogic FC ، أرى أنه في 1 يناير في الساعة 19:54 تم إخراج أحد محركات الأقراص في وحدة التخزين ، وتم التقاط محرك الأقراص الاحتياطية وتنتهي عملية إعادة الإرسال في 2 يناير في الساعة 9:11:

اعتقدت: ربما حدث شيء ما من المستودع أو مفتاح FC ، مما تسبب في غضب السائق من محول QLogic.
إنشاء مهمة في تعقب ، إعادة تشغيل الخادم ، كل شيء يعمل مرة أخرى كما ينبغي ، للوهلة الأولى.
على هذا ، قام بتأجيل المزيد من الإجراءات حتى نهاية عطلة رأس السنة الجديدة.
مع بداية أسبوع العمل في 9 يناير ، بدأ في حل سبب الفشل.
منذ الرسالة:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter.
ليست مفيدة للغاية ، ارتفع إلى مصدر السائق.
إذا حكمنا من خلال رمز برنامج التشغيل ، يتم إصدار رسالة عند إلغاء تحميل برنامج التشغيل بسبب خطأ في PCI (linux / drivers / scsi / qla2xxx / qla_os.c (kernel v4.15)):
qla2x00_disable_board_on_pci_error(struct work_struct *work) { struct qla_hw_data *ha = container_of(work, struct qla_hw_data, board_disable); struct pci_dev *pdev = ha->pdev; scsi_qla_host_t *base_vha = pci_get_drvdata(ha->pdev); /* * if UNLOAD flag is already set, then continue unload, * where it was set first. */ if (test_bit(UNLOADING, &base_vha->dpc_flags)) return; ql_log(ql_log_warn, base_vha, 0x015b, "Disabling adapter.\n");
بدأت الحفر أكثر ، حصلت على BMC ، أنا أنظر في سجل الأحداث:
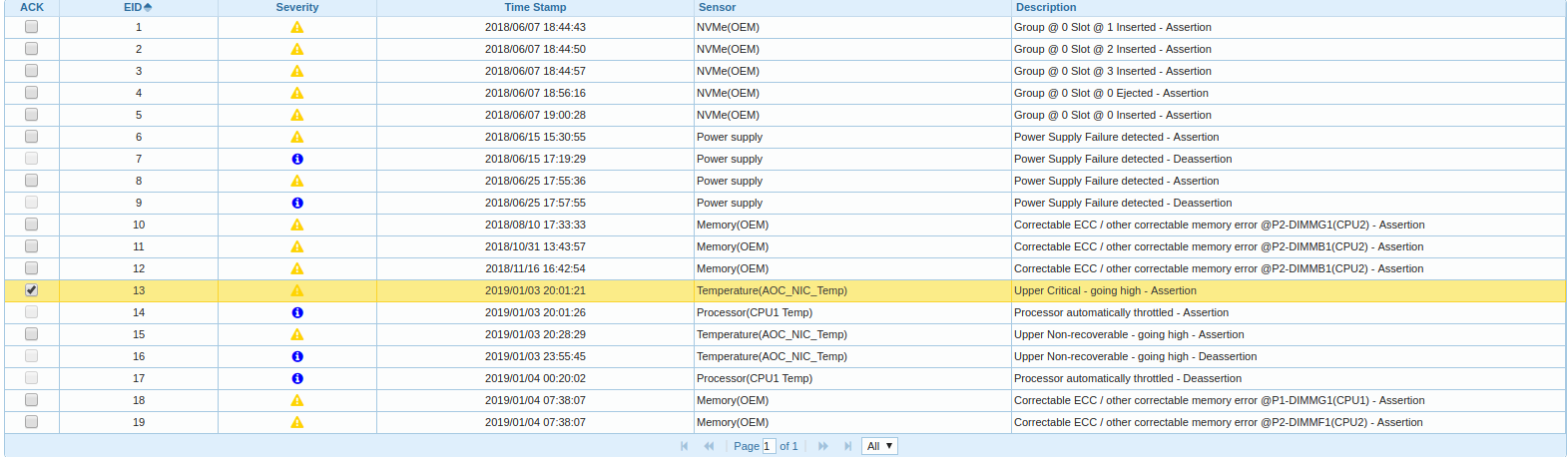
اتضح أن إحدى عقدتي CPU في النظام الأساسي هي الاحماء والاختناق ، ويرتبط وقت الرسالة المتعلقة بإلغاء تحميل برنامج تشغيل محول FC بوقت بدء التحكم.
تجدر الإشارة هنا إلى أن نظام الخادم الموجود لدينا هنا هو https://www.supermicro.com/Aplus/system/2U/2123/AS-2123BT-HNC0R.cfm مع جهازي EPYC 7601 لكل عقدة:
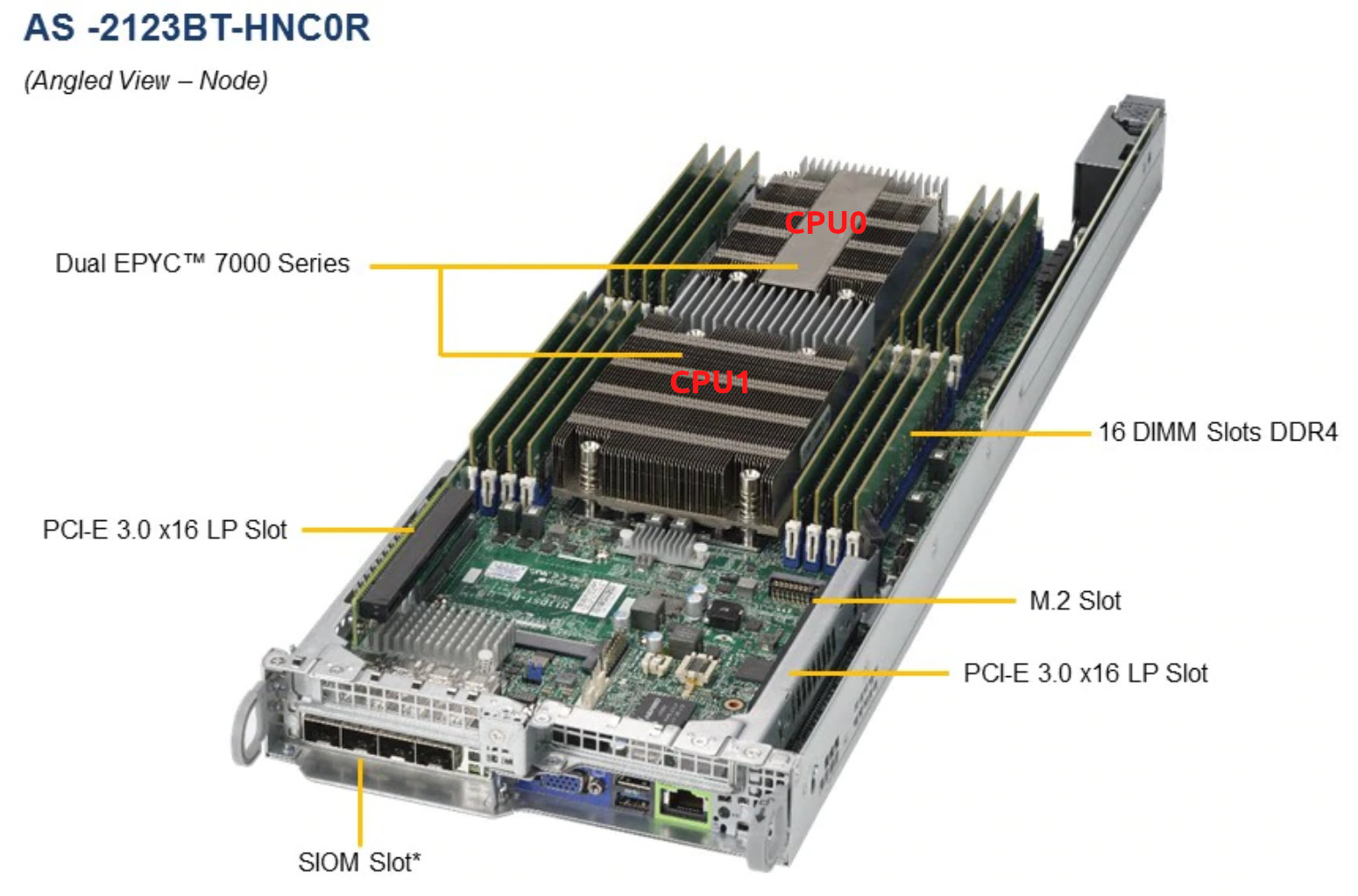
لقد نقلتها إلى مركز البيانات ، وقمت بإزالة العقدة من الخادم ، وقمت بتغيير اللصق الحراري ، وأوقفته مرة أخرى ، لكنها ما زالت ترتفع.
لقد لاحظنا أن تدفق الهواء في جزء واحد من الخادم ليس قوياً كما هو الحال في الجزء الآخر. بعد تحميل بعض العقد قليلاً مع الإجهاد-نانوغرام ، أصبح من الواضح أن معالجات العقدة على الجانب الأيمن من المنصة لا تنفجر بشكل صحيح وأن درجة حرارة وحدة المعالجة المركزية الثانية في عقدتين تصل بسرعة بالغة.
بعد محاولة تغيير معلمات النفخ في BMC ، اتضح أنه لم يكن لها أي تأثير:
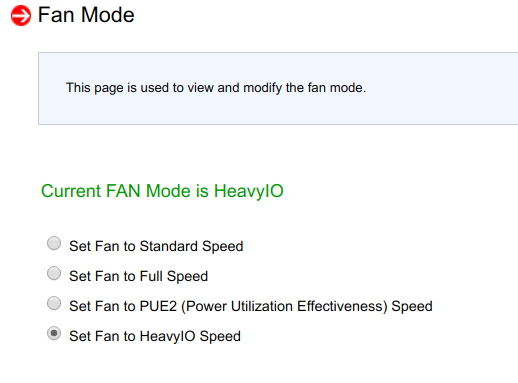
إعادة تشغيل BMC لم يكن له أي تأثير.
بعد الاطلاع على "قراءات المستشعرات" ، رأيت أنه على عقدة واحدة من أصل 53 مستشعرًا ، تم اكتشاف 4 فقط منها ، وعلى العقدة الأخرى 6 فقط:
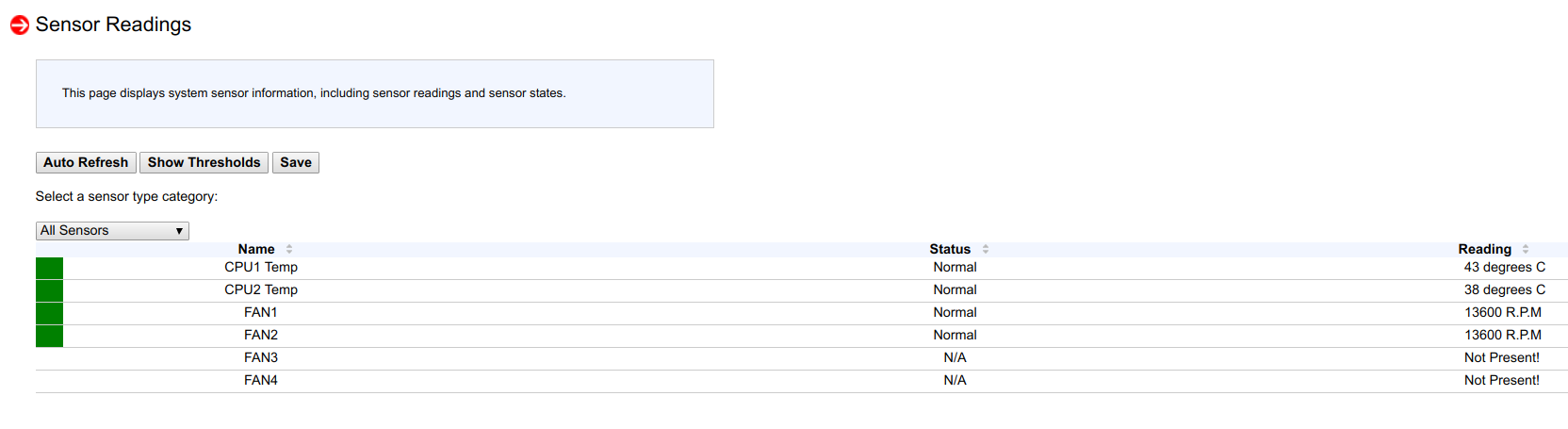
وبعد ذلك ، تذكرت أنه عند وميض إصدار BIOS جديد و BMC جديد في العقد قبل شهر أو شهرين ، على عقدتين لم أقم بإعادة ضبط تكوين BMC إلى معلمات المصنع (من أجل التحقق من حالة ضبط واحدة معينة).
بعد إعادة ضبط BMC وفقًا لمعايير المصنع ، تم اكتشاف جميع المستشعرات الـ 53 مرة أخرى ، وعمل التحكم في سرعة المروحة مرة أخرى ، وتوقف المعالجون عن الاحترار.
حقيقة أن سبب تفريغ برنامج تشغيل QLogic هو ارتفاع درجة حرارة المعالج ليست دقيقة ، لكنني لم أجد ارتباطات وثيقة أخرى.
الاستنتاجات:
- بعد البرامج الثابتة BMC ، حتى لو كان كل شيء يعمل بشكل جيد للوهلة الأولى ، فإنه لا يزال يستحق إعادة ضبط إعدادات المصنع ؛
- بالطبع ، يجب مراقبة رسائل خطأ درجة الحرارة و kernel وهذا أمر طبيعي في الخطط ، ولكن ليس كلها مرة واحدة.