بروميثيوس 2.6.0 تحميل WAL الأمثل ، مما يسرع عملية بدء التشغيل.
الهدف غير الرسمي لتطوير بروميثيوس 2.x TSDB هو تسريع عملية الإطلاق بحيث لا تستغرق أكثر من دقيقة. في الأشهر الأخيرة ، كانت هناك تقارير تفيد بأن العملية تستغرق وقتًا أطول قليلاً ، وإذا تم إعادة تشغيل Prometheus لسبب ما ، فهذه مشكلة بالفعل. طوال هذا الوقت تقريبًا ، يتم تحميل WAL (التسجيل المسبق) ، والذي يتضمن عينات من الساعات القليلة الماضية التي لم يتم ضغطها بعد في كتلة. في أواخر أكتوبر ، تمكنت أخيرًا من معرفة ذلك ؛ والنتيجة هي PR # 440 ، مما يقلل من وقت وحدة المعالجة المركزية بنسبة 6.5 مرة ووقت الحساب بنسبة 4 مرات. دعونا نرى كيف أجريت هذه التحسينات.

أولاً ، هناك حاجة إلى إعداد اختبار. لقد قمت بإنشاء برنامج Go صغير يولد TSDB مع WAL مع مليار عينة منتشرة في أكثر من 10،000 سلسلة زمنية. ثم فتحت TSDB ونظرت في مقدار الوقت الذي استغرقته في استخدام الأداة المساعدة time (وليس بنية مدمجة ، لأنها لا تتضمن إحصائيات الذاكرة) ، وأنشأت أيضًا ملف تعريف وحدة المعالجة المركزية باستخدام حزمة وقت التشغيل / pprof :
f, err := os.Create("cpu.prof") if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile()
لا يسمح لنا ملف تعريف وحدة المعالجة المركزية بتحديد وقت الحساب الذي يهمنا بشكل مباشر ، ومع ذلك ، هناك ارتباط كبير. نتيجةً لذلك ، استغرق التنزيل حوالي 4 دقائق وأقل قليلاً من 6 جيجابايت من ذاكرة الوصول العشوائي في ذروته: على كمبيوتر سطح المكتب (معالج i7-3770 مع 16 جيجابايت من ذاكرة الوصول العشوائي ومحركات أقراص الحالة الثابتة)
1727.50user 16.61system 4:01.12elapsed 723%CPU (0avgtext+0avgdata 5962812maxresident)k 23625165inputs+95outputs (196major+2042817minor)pagefaults 0swaps
هذا ليس go tool pprof cpu.prof ، لذا فلنقم بتحميل ملف التعريف باستخدام go tool pprof cpu.prof ونرى إلى متى ستستغرق العملية إذا كنت تستخدم الأمر top .

هنا flat هو مقدار الوقت الذي يقضيه على وظيفة معينة ، cum هو الوقت الذي يقضيه في هذه الوظيفة وجميع الوظائف التي تسمى بها. قد يكون من المفيد أيضًا عرض هذه البيانات في رسم بياني للحصول على فكرة عن السؤال. أفضل استخدام أمر web لهذا ، ولكن هناك خيارات أخرى ، بما في ذلك ملفات svg و png و pdf.
يمكن ملاحظة أن حوالي ثلث وحدة المعالجة المركزية الخاصة بنا يتم إنفاقها على إضافة عينات إلى قاعدة البيانات الداخلية ، وحوالي الثلثين على معالجة WAL بشكل عام ، وربع على تنظيف الذاكرة ( runtime.scanobject ). دعونا نلقي نظرة على الكود لأول هذه العمليات باستخدام list memSeries.*append :
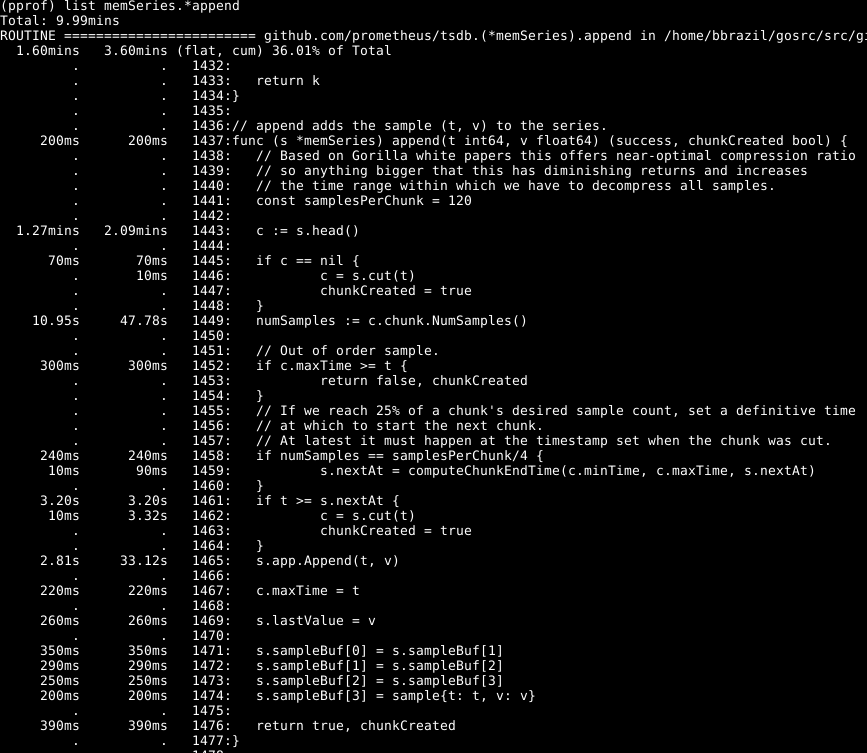
فيما يلي ملفت للنظر: يتم قضاء أكثر من نصف الوقت في الحصول على الجزء الرئيسي من البيانات للسلسلة على السطر 1443. وأيضًا ، لا يتم قضاء وقت قصير في تحديد عدد العينات في قطعة البيانات هذه على السطر 1449. الوقت المستغرق لإكمال السطر 1465 - من المتوقع ، لأن هذا هو جوهر عمل هذه الوظيفة. وفقًا لذلك ، كنت أتوقع أن تستغرق العملية معظم الوقت.
ألقِ نظرة على عنصر memSeries.head : يقوم بحساب جزء من البيانات التي يتم إرجاعها في كل مرة. يتغير جزء البيانات فقط بعد كل 120 إضافة ، وبالتالي ، يمكننا حفظ جزء الرأس الحالي في بنية البيانات في السلسلة . يأخذ هذا بعضًا من ذاكرة الوصول العشوائي ( التي سأعود إليها لاحقًا ) ، ولكنه يوفر كمية كبيرة من وحدة المعالجة المركزية. وعموما ، فإنه يسرع أيضا بروميثيوس.
ثم دعونا نلقي نظرة على Head.processWALSamples :
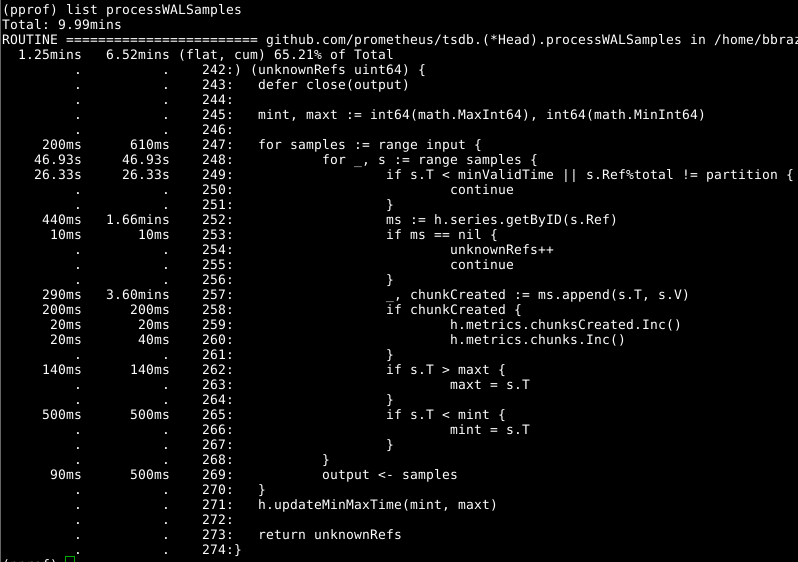
تم تحسين هذه الوظيفة الإضافية أعلاه بالفعل ، لذلك انظر إلى الجاني الواضح التالي ، getByID على السطر 252:
(كود)
يبدو أن هناك نوعًا من منع الصراع ، ويضيع الوقت في إجراء بحث على مستويين. مخبأ لكل معرف يقلل بشكل كبير هذا المؤشر.
يجدر إلقاء نظرة ثانية على Head.processWALSamples ، Head.processWALSamples من مقدار الوقت الذي تم إنفاقه في السطر 249. دعنا نعود قليلاً إلى السؤال حول كيفية عمل تحميل WAL: يتم إنشاء Head.processWALSamples Head.processWALSamples لكل وحدة المعالجة المركزية المتاحة ، بالإضافة إلى أخرى للقراءة فك WAL من القرص. يتم تقسيم الصفوف بواسطة هذه goroutines ، لذلك يمكن أن يكون التزامن ميزة. طريقة التنفيذ هي كما يلي: يتم إرسال جميع العينات إلى gorutin الأول ، والذي يعالج العناصر التي يحتاجها. ثم ترسل جميع العينات إلى gorutin الثاني ، الذي يعالج العناصر التي تحتاجها ، وهكذا ، حتى تقوم gorutin الأخيرة ، Head.processWALSamples بإرسال جميع البيانات مرة أخرى إلى gorutin التحكم.
في غضون ذلك ، يتم توزيع الوظائف الإضافية عبر النواة - وهو ما تحتاج إليه - ويتم تنفيذ العديد من المهام المكررة في كل gorutin ، والتي يجب أن تعالج جميع العينات وتحسب الوحدة النمطية. في الواقع ، كلما زاد عدد النوى ، زاد تكرار العمل. لقد أجريت تغييرات على تجزئة البيانات في gourutin وحدة التحكم ، بحيث يحصل كل gorutin من Head.processWALSamples الآن على العينات التي يحتاجها فقط . على جهاز الكمبيوتر الخاص بي - 8 يعمل بنظام gorutin - تم حفظ وقت الحساب قليلاً ، لكن حجم وحدة المعالجة المركزية كان لائقًا. بالنسبة لأجهزة الكمبيوتر التي تحتوي على عدد كبير من النوى ، يجب أن تكون الفوائد أكثر جوهرية.
ومرة أخرى نعود إلى السؤال: حان الوقت لمسح الذاكرة. لا يمكننا (عادة) تحديد ذلك من خلال ملفات تعريف وحدة المعالجة المركزية. بدلاً من ذلك ، انتبه إلى ملفات تعريف الذاكرة الديناميكية للعثور على العناصر التي تبرز. هذا يتطلب بعض توسيع التعليمات البرمجية في نهاية البرنامج:
runtime.GC() hf, err := os.Create("heap.prof") if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(hf)
يرتبط التنظيف الرسمي للذاكرة ببعض المعلومات في الذاكرة الديناميكية ، ويتم جمعها وتنظيفها فقط أثناء تنظيف الذاكرة.
نستخدم الأداة نفسها مرة أخرى ، لكننا -alloc_space علامة -alloc_space ، حيث أننا مهتمون بجميع عمليات تخصيص الذاكرة ، وليس فقط العمليات التي تستخدم الذاكرة في لحظة معينة ؛ وبالتالي ، قم بتشغيل go tool pprof -alloc_space heap.prof . إذا نظرت إلى الموزع العلوي ، فإن الجاني واضح:
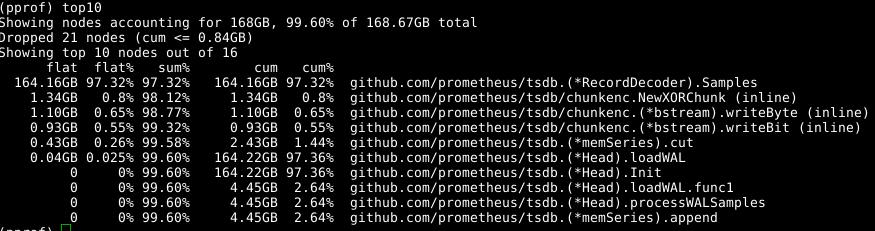
ألقِ نظرة على الكود:
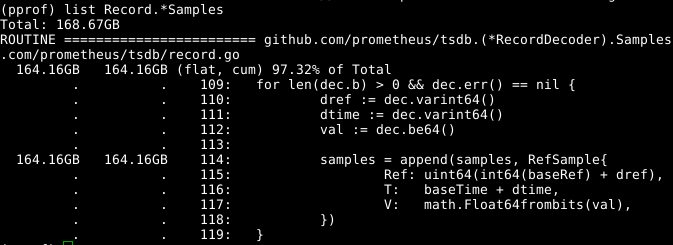
يبدو أن مجموعة samples القابلة للتوسيع مشكلة. إذا تمكنا من إعادة استخدام الصفيف في نفس الوقت الذي يتم فيه استدعاء RecordDecoder.Samples ، RecordDecoder.Samples هذا مقدارًا كبيرًا من الذاكرة. اتضح أن الكود تم تكوينه بهذه الطريقة ، لكن خطأ ترميز صغير أدى إلى حقيقة أنه لم ينجح. إذا قمت بإصلاحه ، يتم مسح الذاكرة في 8 ثوانٍ من وحدة المعالجة المركزية بدلاً من 151 ثانية.
النتائج الإجمالية ملموسة:
269.18user 10.69system 1:05.58elapsed 426%CPU (0avgtext+0avgdata 3529556maxresident)k 23174929inputs+70outputs (815major+1083172minor)pagefaults 0swap
لم نقم فقط بخفض وقت الحساب بمقدار 4 مرات ، ووقت وحدة المعالجة المركزية - بمقدار 6.5 مرة ، ولكن أيضًا تقليل حجم الذاكرة المشغولة بأكثر من 2 جيجابايت.
يبدو أن كل شيء بسيط ، ولكن الحيلة هي: لقد بحثت في قاعدة الشفرة بشكل جيد وأحلل كل شيء كما لو كان في فوات الأوان. عند دراسة الكود ، وصلت إلى طريق مسدود عدة مرات ، على سبيل المثال ، عند حذف مكالمة NumSamples ، والقراءة وفك التشفير في NumSamples منفصلة ، وكذلك بعدة طرق لتقسيم processWALSamples . أنا متأكد تقريبًا من أنه من خلال تنظيم عدد الجوروتينات ، يمكن تحقيق المزيد ، ولكن يجب إجراء هذه الاختبارات على أجهزة أقوى من الجهاز ، حتى يكون هناك عدد أكبر من النوى. لقد حققت هدفي: زيادة الإنتاجية ، وأدركت أنه من الأفضل عدم جعل سجل البرنامج كبيرًا جدًا ، ولذا قررت التوقف عند هذا الحد.