مرحبا اسمي إيفان سموروف ، وأدير مجموعة أبحاث البرمجة اللغوية العصبية في ABBYY. يمكنك أن تقرأ عن ما تفعله مجموعتنا
هنا . لقد ألقيت مؤخرًا محاضرة حول معالجة اللغات الطبيعية (NLP) في
كلية التعليم العميق - وهي مجموعة في كلية الفيزياء للرياضيات التطبيقية وعلوم الكمبيوتر في MIPT للطلاب الكبار المهتمين بالبرمجة والرياضيات. ربما تكون أطروحات محاضرتي مفيدة لشخص ما ، لذا سأشاركها مع هبر.
بما أنه لا يمكن فهم كل شيء في وقت واحد ، فسوف نقسم المقال إلى قسمين. سأتحدث اليوم عن كيفية استخدام الشبكات العصبية (أو التعلم العميق) في البرمجة اللغوية العصبية. في الجزء الثاني من المقالة ، سنركز على واحدة من أكثر مهام البرمجة اللغوية العصبية شيوعًا - مهمة استخراج الكيانات المسماة (التعرف على الكيانات المسماة ، NER) وتحليل هندسة حلولها بالتفصيل.
ما هو البرمجة اللغوية العصبية؟
هذه مجموعة واسعة من المهام لمعالجة النصوص بلغة طبيعية (أي اللغة التي يتحدثها الناس ويكتبونها). هناك مجموعة من مهام البرمجة اللغوية العصبية الكلاسيكية ، والتي يكون الحل للاستخدام العملي.
- المهمة الأولى والأكثر أهمية تاريخيا هي الترجمة الآلية. لقد تم ممارستها لفترة طويلة جدا ، وهناك تقدم هائل. لكن مهمة الحصول على ترجمة تلقائية بالكامل ذات جودة عالية (FAHQMT) لا تزال دون حل. بطريقة ما ، هذا هو محرك البرمجة اللغوية العصبية NLP ، أحد أكبر المهام التي يمكنك القيام بها.

- المهمة الثانية هي تصنيف النصوص. يتم توفير مجموعة من النصوص ، وتتمثل المهمة في تصنيف هذه النصوص في فئات. أي واحد؟ هذا سؤال للسلك.
تتمثل الطريقة الأولى والأكثر عملية لتطبيقه من وجهة نظر عملية في تصنيف الحروف إلى بريد عشوائي وغير مرغوب فيه (وليس بريدًا عشوائيًا).
هناك خيار كلاسيكي آخر وهو تصنيف الأخبار متعدد الفئات إلى فئات (تصنيف) - السياسة الخارجية ، والرياضة ، وأهم الأمور ، إلخ. أو ، على سبيل المثال ، تتلقى رسائل وتريد فصل الطلبات من المتجر عبر الإنترنت عن تذاكر الطيران وحجوزات الفنادق.
التطبيق الكلاسيكي الثالث لمشكلة تصنيف النص هو التحليل العاطفي. على سبيل المثال ، تصنيف المراجعات إيجابية وسلبية ومحايدة.
نظرًا لوجود العديد من الفئات الممكنة التي يمكنك تقسيم النصوص إليها ، يعتبر تصنيف النص من أكثر المهام العملية شعبية في البرمجة اللغوية العصبية. - المهمة الثالثة هي استرداد الكيانات المسماة ، NER. نختار في أقسام النص التي تتوافق مع مجموعة محددة مسبقًا من الكيانات ، على سبيل المثال ، تحتاج إلى البحث عن جميع المواقع والأشخاص والمؤسسات في النص. في النص "Ostap Bender - مدير مكتب" Horns and Hooves "، يجب أن تفهم أن Ostap Bender هو شخص ، وأن" Horns and Hooves "هي منظمة. لماذا هذه المهمة مطلوبة في الممارسة العملية وكيفية حلها ، سنتحدث في الجزء الثاني من مقالتنا.
 المهمة الرابعة مرتبطة بالمهمة الثالثة - مهمة استخراج الحقائق والعلاقات (استخراج العلاقة). على سبيل المثال ، هناك موقف العمل (الاحتلال). من النص "Ostap Bender - مدير مكتب" Horns and Hooves "، من الواضح أن بطلنا مرتبط بعلاقات مهنية مع" Horns and Hooves ". يمكن قول الشيء نفسه بعدة طرق أخرى: "مكتب Ostap Bender يرأسه مكتب" Horns and Hooves "، أو" Ostap Bender قد انتقل من الابن البسيط لللفتنانت شميدت إلى رئيس مكتب "Horns and Hooves". هذه الجمل لا تختلف فقط في المسند ، ولكن أيضًا في الهيكل.
المهمة الرابعة مرتبطة بالمهمة الثالثة - مهمة استخراج الحقائق والعلاقات (استخراج العلاقة). على سبيل المثال ، هناك موقف العمل (الاحتلال). من النص "Ostap Bender - مدير مكتب" Horns and Hooves "، من الواضح أن بطلنا مرتبط بعلاقات مهنية مع" Horns and Hooves ". يمكن قول الشيء نفسه بعدة طرق أخرى: "مكتب Ostap Bender يرأسه مكتب" Horns and Hooves "، أو" Ostap Bender قد انتقل من الابن البسيط لللفتنانت شميدت إلى رئيس مكتب "Horns and Hooves". هذه الجمل لا تختلف فقط في المسند ، ولكن أيضًا في الهيكل.
من الأمثلة على العلاقات الأخرى التي يتم إبرازها غالبًا الشراء والبيع ، والملكية ، وحقيقة الميلاد ذات السمات - التاريخ ، والمكان ، إلخ (الميلاد) وبعض العلاقات الأخرى.
يبدو أن المهمة ليس لها تطبيق عملي واضح ، ولكن ، مع ذلك ، يتم استخدامها في هيكلة المعلومات غير المنظمة. بالإضافة إلى ذلك ، يعد هذا الأمر مهمًا في أنظمة الإجابة على الأسئلة والحوار ، في محركات البحث - كلما احتجت إلى تحليل سؤال وفهم نوعه ، وكذلك القيود الموجودة على الإجابة.

- ربما تكون المهمتان التاليتان أكثر الضجيج. هذه هي أنظمة الإجابة على الأسئلة والحوار (برامج الدردشة). الأمازون أليكسا ، أليس هي أمثلة كلاسيكية على أنظمة المحادثة. بالنسبة لهم للعمل بشكل صحيح ، يجب حل العديد من مهام البرمجة اللغوية العصبية. على سبيل المثال ، يساعد تصنيف النص في تحديد ما إذا كنا نقع في أحد سيناريوهات chatbot الموجهة نحو الهدف. لنفترض ، "مسألة أسعار الصرف". هناك حاجة إلى استخراج العلاقة لتحديد العناصر النائبة لقالب البرنامج النصي ، وسوف تساعدنا مهمة إجراء حوار حول مواضيع مشتركة ("المتكلمون") في موقف لم نقع فيه في أي من النصوص.
أنظمة الإجابة على الأسئلة هي أيضًا شيء مفهوم ومفيد. أنت تسأل سيارة ، السيارة تبحث عن إجابة عليها في قاعدة بيانات أو نص نصي. ومن أمثلة هذه الأنظمة IBM Watson أو Wolfram Alpha. - مثال آخر على مشكلة البرمجة اللغوية العصبية الكلاسيكية هو أخذ العينات. بيان المشكلة بسيط - نظام الإدخال يقبل نصًا كبيرًا ، والإخراج عبارة عن نص أصغر ، يعكس بطريقة ما محتوى النص الكبير. على سبيل المثال ، هناك حاجة إلى آلة لإنشاء إعادة سرد للنص ، اسمها أو تعليق توضيحي.

- مهمة شائعة أخرى هي التنقيب عن الجدال ، البحث عن التبرير في النص. يتم منحك حقيقة ونص ، تحتاج إلى العثور على مبرر لهذه الحقيقة في النص.
هذا ليس بأي حال قائمة مهام البرمجة اللغوية العصبية بأكملها. هناك العشرات منهم. بشكل عام ، يمكن أن يعزى كل شيء يمكن القيام به مع النص في لغة طبيعية إلى مهام البرمجة اللغوية العصبية ، فقط الموضوعات المدرجة هي عن طريق الأذن ، ولها التطبيقات العملية الأكثر وضوحا.
لماذا يصعب حل مهام البرمجة اللغوية العصبية؟
صياغة المهام ليست معقدة للغاية ، ولكن المهام نفسها ليست بسيطة على الإطلاق ، لأننا نعمل مع اللغة الطبيعية. إن ظواهر polysemy (للكلمات polysemous لها معنى أولي مشترك) ، و homonymy (الكلمات ذات المعاني المختلفة واضحة ومكتوبة بالطريقة نفسها) هي سمة لأي لغة طبيعية. وإذا كان أحد المتحدثين باللغة الروسية يفهم جيدًا أن
الاستقبال الحار لا يشترك في الكثير من
أساليب القتال ، من ناحية ،
والبيرة الدافئة ، من ناحية أخرى ، فإن النظام الآلي يجب أن يتعلم هذا لفترة طويلة. لماذا من الأفضل ترجمة "
اضغط على شريط المسافة للاستمرار " إلى "ممل"
للمتابعة ، اضغط على "
مفتاح المسافة " بدلاً من "
سيستمر شريط المسافة في العمل ".
- Polysemy: توقف (عملية أو مبنى) ، طاولة (تنظيم أو كائن) ، نقار الخشب (طائر أو شخص).
- Homonymy: مفتاح ، القوس ، قفل ، موقد.

- مثال كلاسيكي آخر على تعقيد اللغة هو ضمير الجناس. على سبيل المثال ، دعنا نعطي النص " Janitor ساعتين من الثلج ، لقد كان غير راضٍ ." الضمير "هو" يمكن أن يشير إلى كل من البواب والثلوج. حسب السياق ، نفهم بسهولة أنه حارس ، وليس ثلجًا. ولكن لتحقيق ذلك الكمبيوتر فهمت أيضا هذا ليس بالأمر السهل. لا تزال مشكلة ضمير الجناس غير محسومة بشكل جيد ؛ تستمر المحاولات النشطة لتحسين جودة القرارات.
- تعقيد إضافي آخر هو القطع. على سبيل المثال ، " Petya أكل تفاحة خضراء ، وماشا أكلت واحدة حمراء ." نحن نفهم أن ماشا أكل تفاحة حمراء. ومع ذلك ، فإن جعل الآلة تفهم ذلك أيضًا ليس بالأمر السهل. الآن يتم حل مهمة استعادة علامة القطع في حالات صغيرة (عدة مئات من الجمل) ، ونوعية الاستعادة الكاملة ضعيفة بصراحة (حوالي 0.5). من الواضح أنه بالنسبة للتطبيقات العملية ، فإن هذه الجودة ليست جيدة.
بالمناسبة ، في هذا العام في مؤتمر
الحوار ، ستُعقد المسارات على حد سواء على الجناس وعلى الفجوات (نوع من القطع الناقص) للغة الروسية. بالنسبة لكلتا المهمتين ، تم تجميع الحالات بحجم أكبر عدة مرات من مجلدات المباني الموجودة حاليًا (علاوة على ذلك ، بالنسبة للفجوات ، يكون حجم الحالة أكبر من مجلدات الحالات ، ليس فقط للغة الروسية ، ولكن لجميع اللغات بشكل عام). إذا كنت ترغب في المشاركة في المسابقات في هذه المباني ،
انقر هنا (مع التسجيل ، ولكن بدون الرسائل القصيرة) .
كيف يتم حل مهام البرمجة اللغوية العصبية
بخلاف معالجة الصور ، لا يزال بإمكانك العثور على مقالات حول البرمجة اللغوية العصبية تصف الحلول التي تستخدم خوارزميات كلاسيكية مثل
SVM أو
Xgboost ، وليس الشبكات العصبية ، والتي تعرض نتائج لا تكون أدنى من الحلول الحديثة.
ومع ذلك ، قبل عدة سنوات ، بدأت الشبكات العصبية في هزيمة النماذج الكلاسيكية. من المهم ملاحظة أنه بالنسبة لمعظم المهام ، كانت الحلول المستندة إلى الأساليب الكلاسيكية فريدة من نوعها ، كقاعدة عامة ، لا تشبه الحلول للمشاكل الأخرى في الهندسة المعمارية وفي الطريقة التي يحدث بها تجميع ومعالجة السمات.
ومع ذلك ، فإن أبنية الشبكات العصبية أكثر عمومية. هندسة الشبكة نفسها ، على الأرجح ، مختلفة أيضًا ، ولكن أصغر بكثير ، هناك ميل نحو التعميم الكامل. ومع ذلك ، مع ما هي الميزات وكيف نعمل بالضبط ، فإنه بالفعل هو نفسه تقريبا بالنسبة لمعظم مهام البرمجة اللغوية العصبية. فقط الطبقات الأخيرة من الشبكات العصبية تختلف. وبالتالي ، يمكننا أن نفترض أن خط أنابيب NLP واحد قد تم تشكيله. حول كيفية ترتيبها ، سنخبرك الآن أكثر.
خط أنابيب البرمجة اللغوية العصبية
هذه الطريقة في العمل مع العلامات ، والتي هي نفسها إلى حد ما لجميع المهام.
عندما يتعلق الأمر باللغة ، فإن الوحدة الأساسية التي نعمل بها هي الكلمة. أو أكثر رسميا "رمزية". نستخدم هذا المصطلح لأنه ليس من الواضح جدًا ما هو 2128506 - هل هذه كلمة أم لا؟ الجواب غير واضح. عادةً ما يتم فصل الرمز المميز عن الرموز الأخرى بواسطة مسافات أو علامات الترقيم. وكما يمكنك أن تفهم من الصعوبات التي وصفناها أعلاه ، فإن سياق كل رمز مهم للغاية. هناك طرق مختلفة ، لكن في 95٪ من الحالات ، يكون السياق الذي يتم النظر فيه أثناء عمل النموذج هو اقتراح يتضمن الرمز الأولي.
يتم حل العديد من المهام بشكل عام على مستوى الاقتراح. على سبيل المثال ، الترجمة الآلية. في أكثر الأحيان ، نترجم جملة واحدة فقط ولا نستخدم سياقًا أوسع على الإطلاق. هناك مهام لا يكون فيها هذا هو الحال ، على سبيل المثال ، أنظمة الحوار. من المهم أن تتذكر ما تم طرحه من قبل حول النظام حتى يتمكن من الإجابة على الأسئلة. ومع ذلك ، فإن العرض هو أيضًا الوحدة الرئيسية التي نعمل بها.
لذلك ، فإن أول خطوتين من خط الأنابيب التي يتم تنفيذها لحل أي مهمة تقريبًا هي التجزئة (تقسيم النص إلى جمل) والرمز المميز (تقسيم الجمل إلى الرموز ، أي الكلمات الفردية). يتم ذلك باستخدام خوارزميات بسيطة.
بعد ذلك ، تحتاج إلى حساب خصائص كل رمز مميز. كقاعدة عامة ، يحدث هذا على مرحلتين. الأول هو حساب سمات الرمز المميز للسياق المستقل. هذه مجموعة من العلامات التي لا تعتمد بأي حال على الكلمات الأخرى المحيطة برمزنا المميز. السمات الشائعة للسياق المستقل هي:
- حفلات الزفاف
- علامات رمزية
- ميزات إضافية محددة لمهمة أو لغة معينة
سوف نتحدث عن الأعراس والعلامات الرمزية بمزيد من التفاصيل أدناه (حول العلامات الرمزية - ليس اليوم ، ولكن في الجزء الثاني من مقالتنا) ، ولكن الآن لنقدم أمثلة محتملة على علامات إضافية.
واحدة من الميزات الأكثر استخدامًا هي جزء الكلام أو علامة نقاط البيع (جزء من الكلام). قد تكون هذه الميزات مهمة لحل العديد من المشكلات ، على سبيل المثال ، تحليل المهام. بالنسبة للغات ذات التشكل المعقد ، مثل اللغة الروسية ، فإن الشخصيات المورفولوجية مهمة أيضًا: على سبيل المثال ، في هذه الحالة الاسم ، أي نوع من الصفات. من هذا يمكننا استخلاص استنتاجات مختلفة حول هيكل الاقتراح. أيضا ، هناك حاجة إلى التشكل ل lemmatization (اختزال الكلمات إلى الأشكال الأولية) ، مع المساعدة التي يمكننا تقليل البعد من مساحة الميزة ، وبالتالي يستخدم التحليل الصرفي بنشاط لمعظم مشاكل البرمجة اللغوية العصبية.
عندما نحل مشكلة حيث يكون التفاعل بين الكائنات المختلفة مهمًا (على سبيل المثال ، في مهمة استخراج العلاقة أو عند إنشاء نظام للإجابة على الأسئلة) ، نحتاج إلى معرفة الكثير عن بنية الاقتراح. هذا يتطلب تحليل. في المدرسة ، قام الجميع بتحليل جملة لموضوع ما ، أو تقييم ، أو إضافة ، وما إلى ذلك. التحليل النحوي هو شيء بهذه الروح ، لكنه أكثر تعقيدًا.
مثال آخر لميزة إضافية هو موضع الرمز في النص. يمكننا أن نعرف سلفًا أن بعض الكيانات غالبًا ما يتم العثور عليها في بداية النص أو العكس بالعكس في النهاية.
جميعها مجتمعة - زخارف ، علامات رمزية وإضافية - تشكل متجهًا للعلامات الرمزية التي لا تعتمد على السياق.
ميزات حساسة للسياق
العلامات الرمزية الحساسة للسياق هي مجموعة من العلامات التي تحتوي على معلومات ليس فقط حول الرمز المميز نفسه ، ولكن أيضًا عن جيرانه. هناك طرق مختلفة لحساب هذه الأعراض. في الخوارزميات الكلاسيكية ، غالبًا ما يسير الأشخاص بجوار "النافذة": لقد أخذوا عدة رموز (على سبيل المثال ، ثلاثة) إلى الرموز الأصلية وعدة رموز بعدها ، ثم قاموا بحساب جميع العلامات الموجودة في مثل هذه النافذة. لا يمكن الاعتماد على هذا النهج ، نظرًا لأن المعلومات المهمة للتحليل قد تكون أكبر من النافذة ، على التوالي ، فقد نفقد شيئًا ما.
لذلك ، يتم الآن حساب جميع الميزات الحساسة للسياق على مستوى الاقتراح بطريقة قياسية: استخدام الشبكات العصبية المتكررة ثنائية الاتجاه LSTM أو GRU. للحصول على السمات المميزة للسياق الحساسة للسياق من السمات المستقلة للسياق ، يتم تقديم السمات المميزة للسياق لجميع الرموز المميزة للعروض إلى RNN ثنائي الاتجاه (أحادي أو متعدد الطبقات). يعتبر إخراج RNN ثنائي الاتجاه في اللحظة الأولى من الوقت علامة حساسة للسياق من الرمز المميز ، والذي يحتوي على معلومات حول كلا الرموز المميزة السابقة (نظرًا لأن هذه المعلومات مضمنة في القيمة رقم i من RNN المباشرة) ، وعن الرموز اللاحقة (t هذه المعلومات موجودة في القيمة المقابلة لـ RNN معكوس).
علاوة على ذلك ، بالنسبة لكل مهمة فردية ، نقوم بعمل مختلف ، لكن الطبقات القليلة الأولى - حتى ثنائية الاتجاه RNN ، يمكن استخدامها في أي مهمة تقريبًا.
تسمى هذه الطريقة للحصول على ميزات خط أنابيب NLP.
تجدر الإشارة إلى أنه خلال العامين الماضيين ، حاول الباحثون بنشاط تحسين خط أنابيب NLP - سواء من حيث السرعة (على سبيل المثال ، المحول - بنية قائمة على الاهتمام الذاتي لا تحتوي على RNN وبالتالي فهي قادرة على التعلم والتطبيق بشكل أسرع) ، ومع وجهة نظر العلامات المستخدمة (الآن يستخدمون بنشاط الإشارات المستندة إلى نماذج اللغة المدربة مسبقًا ، على سبيل المثال
ELMo ، أو يستخدمون الطبقات الأولى من نموذج اللغة المُدرَّب مسبقًا وإعادة تدريبهم في الحالة المتاحة للمهمة -
ULMFit ،
BERT ).
كلمة شكل حفلات الزفاف
دعونا نلقي نظرة فاحصة على ما هو التضمين. بمعنى تقريبي ، التضمين عبارة عن تمثيل موجز لسياق الكلمة. ما أهمية معرفة سياق الكلمة؟ لأننا نؤمن بفرضية التوزيع - أن الكلمات المتشابهة في المعنى تستخدم في سياقات مماثلة.
دعنا الآن نحاول إعطاء تعريف دقيق للتضمين. التضمين عبارة عن مناظرة من ناقل منفصل للميزات الفئوية إلى متجه مستمر ذي بعد محدد مسبقًا.
من الأمثلة المتعارف عليها للتضمين تضمين الكلمات (تضمين شكل الكلمة).
ما الذي عادة ما يكون بمثابة ناقل ميزة منفصلة؟ متجه منطقي يتوافق مع جميع القيم الممكنة لفئة معينة (على سبيل المثال ، كل أجزاء الكلام الممكنة أو كل الكلمات الممكنة من بعض القاموس المحدود).
بالنسبة لحفلات الزفاف على شكل كلمة ، تكون هذه الفئة عادةً فهرس الكلمة في القاموس. دعنا نقول أن هناك قاموس بأبعاد 100 ألف. وفقًا لذلك ، تحتوي كل كلمة على متجه منفصل للعلامات - متجه منطقي ذو أبعاد 100 ألف ، حيث يوجد في مكان واحد (فهرس الكلمة في قاموسنا) ، والباقي أصفار.
لماذا نرغب في تعيين متجهات الميزات المنفصلة الخاصة بنا إلى أبعاد معينة متواصلة؟ نظرًا لأن المتجهات ذات البعد 100 ألف ليست ملائمة تمامًا للاستخدام في العمليات الحسابية ، ولكن المتجهات ذات الأعداد الصحيحة للأبعاد 100 أو 200 أو ، على سبيل المثال ، 300 ، هي أكثر ملاءمة.
من حيث المبدأ ، قد لا نحاول فرض أي قيود إضافية على مثل هذا التعيين. ولكن نظرًا لأننا نقوم ببناء مثل هذا التعيين ، فلنحاول التأكد من أن متجهات الكلمات ذات المعنى المماثل قريبة من بعض المعاني. يتم ذلك باستخدام شبكة عصبية بسيطة للتغذية.
تضمين التدريب
كيف يتم تدريب حفلات الزفاف؟ نحن نحاول حل مشكلة استعادة كلمة بسياق (أو العكس ، استعادة سياق كلمة). في أبسط الحالات ، نحصل على الفهرس في قاموس الكلمة السابقة (المتجه المنطقي لبعد القاموس) كمدخل ونحاول تحديد الفهرس في قاموس كلمتنا. يتم ذلك باستخدام شبكة ذات بنية بسيطة للغاية: طبقتان متصلتان تمامًا. أولاً ، تأتي طبقة متصلة تمامًا من متجه Boolean لبعد القاموس إلى الطبقة المخفية لبعد التضمين (أي ، ببساطة ضرب متجه Boolean بمصفوفة البعد المطلوب). والعكس بالعكس ، طبقة متصلة بالكامل مع softmax من طبقة مخفية من البعد تدمج في متجه أبعاد القاموس. بفضل وظيفة تنشيط softmax ، نحصل على توزيع الاحتمال لكلمتنا ويمكننا اختيار الخيار الأكثر احتمالا.
تضمين الكلمة ith هو ببساطة صف ith في مصفوفة الانتقال W.في النماذج المستخدمة في الممارسة العملية ، تكون البنية أكثر تعقيدًا ، لكن ليس كثيرًا. الفرق الرئيسي هو أننا لا نستخدم متجه واحد من السياق لتعريف كلمتنا ، ولكن عدة (على سبيل المثال ، كل شيء في نافذة بحجم 3). الخيار الأكثر شيوعًا هو عندما نحاول التنبؤ ليس بكلمة على حدة ، بل في السياق لكل كلمة. هذا النهج يسمى تخطي غرام.
دعنا نعطي مثالًا على تطبيق مهمة يتم حلها أثناء تدريب حفلات الزفاف (في متغير CBOW ، تنبؤات الكلمات حسب السياق). على سبيل المثال ، افترض أن سياق الرمز المميز يتكون من كلمتين سابقتين. “ ”, , , “”.
, ( ), , .
, , , (, , ). — .
, , . , , , .
, — ELMo, ULMFit, BERT. , ( , , , ).
?
, 2 .
- -, , , - 100 . – : , , .
- -, . -. . . , , . , , . . , , .
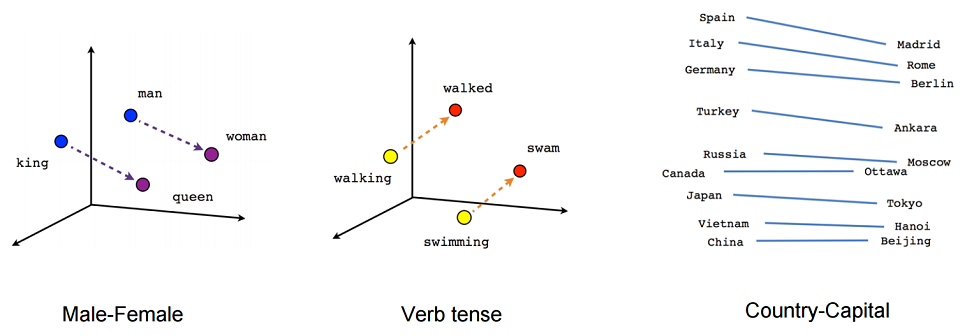
, .
, , , , , . , , , , .
NER. , , . , , , , .