
مرة أخرى في أوائل عام 2018 ، تم نشر مقال " التعلم العميق لا يعمل حتى الآن " ("التعلم مع التعزيز لا يعمل بعد."). الشكوى الرئيسية منها هي أن خوارزميات التعلم الحديثة مع التعزيز تتطلب تقريبًا نفس الوقت اللازم لحل مشكلة البحث العشوائي المنتظم.
هل تغير أي شيء منذ ذلك الحين؟ رقم
يعتبر التعلم المعزز أحد المسارات الرئيسية الثلاثة لبناء الذكاء الاصطناعى القوي. لكن الصعوبات التي تواجه هذا المجال من التعلم الآلي ، والأساليب التي يحاول العلماء التعامل مع هذه الصعوبات ، تشير إلى أنه قد تكون هناك مشاكل أساسية مع هذا النهج نفسه.
الانتظار ، ماذا يعني واحد من ثلاثة؟ ما هما الآخران؟
بالنظر إلى نجاح الشبكات العصبية في السنوات الأخيرة وتحليل كيفية عملها مع القدرات المعرفية الرفيعة المستوى ، والتي كانت تعتبر في السابق مميزة فقط للبشر والحيوانات العليا ، يوجد اليوم في المجتمع العلمي رأي مفاده أن هناك ثلاثة أساليب رئيسية لخلق الذكاء الاصطناعى القوي في أساس الشبكات العصبية ، والتي يمكن اعتبارها أكثر أو أقل واقعية:
1. معالجة الكلمات
لقد جمع العالم عددًا كبيرًا من الكتب والنصوص على الإنترنت ، بما في ذلك الكتب المدرسية والكتب المرجعية. النص مناسب وسريع للمعالجة على الكمبيوتر. من الناحية النظرية ، ينبغي أن تكون هذه المجموعة من النصوص كافية لتدريب منظمة العفو الدولية للمحادثة.
من الضمني أنه في هذه المصفوفات النصية ينعكس الهيكل الكامل للعالم (على الأقل ، يتم وصفه في الكتب المدرسية والكتب المرجعية). لكن هذه ليست حقيقة على الإطلاق. تُفصل النصوص ، كنوع من تقديم المعلومات ، بقوة عن العالم الحقيقي ثلاثي الأبعاد وعن الوقت الذي نعيش فيه.
أمثلة جيدة على الذكاء الاصطناعي المدربة على صفائف النص هي برامج الدردشة والمترجمين التلقائي. منذ أن قمت بترجمة النص ، عليك فهم معنى العبارة وإعادة بيعها بكلمات جديدة (بلغة أخرى). هناك اعتقاد خاطئ شائع بأن القواعد النحوية والبنية ، بما في ذلك وصف لجميع الاستثناءات المحتملة ، تصف تماما لغة معينة. هذا ليس كذلك. اللغة ليست سوى أداة مساعدة في الحياة ، فهي تتغير بسهولة وتتكيف مع المواقف الجديدة.
المشكلة في معالجة النصوص (حتى بواسطة الأنظمة الخبيرة ، وحتى الشبكات العصبية) هي عدم وجود مجموعة من القواعد ، أي العبارات يجب أن تطبق في أي المواقف. يرجى ملاحظة - وليس القواعد لبناء العبارات نفسها (ما يفعله النحو والقواعد اللغوية) ، ولكن ما العبارات التي في المواقف. في نفس الموقف ، ينطق الأشخاص عبارات بلغات مختلفة لا ترتبط عمومًا ببعضها البعض من حيث بنية اللغة. قارن عبارات المفاجأة الشديدة: "يا إلهي!" و "يا القرف المقدس!". حسنًا ، وكيفية عمل المراسلات بينهما ، مع العلم بنموذج اللغة؟ لا مفر لقد حدث بالصدفة تاريخيا. تحتاج إلى معرفة الموقف وما يتحدثون عادة بلغة معينة. ولهذا السبب فإن المترجمين الآليين غير كاملين.
إذا كانت هذه المعرفة يمكن تمييزها بحتة من مجموعة من النصوص غير معروف. ولكن إذا كان المترجمون التلقائيون يترجمون تمامًا دون ارتكاب أخطاء سخيفة ومثيرة للسخرية ، فسيكون هذا دليلًا على أن إنشاء الذكاء الاصطناعى القوي القائم على النص ممكن فقط.
2. التعرف على الصور
انظر الى هذه الصورة

بالنظر إلى هذه الصورة ، نفهم أن إطلاق النار قد تم في الليل. إذا حكمنا من خلال الأعلام ، تهب الرياح من اليمين إلى اليسار. واستنادا إلى حركة المرور اليمنى ، فإن القضية لا تحدث في إنجلترا أو أستراليا. لا يشار إلى أي من هذه المعلومات بشكل صريح في بكسل الصورة ، هذه هي المعرفة الخارجية. في الصورة هناك علامات فقط يمكننا من خلالها استخدام المعرفة التي تم الحصول عليها من مصادر أخرى.
هل تعرف أي شيء آخر يبحث في هذه الصورة؟عن ذلك والكلام ... وتجد نفسك فتاة أخيرًا
لذلك ، يُعتقد أنه إذا قمت بتدريب شبكة عصبية للتعرف على الكائنات في صورة ما ، فستكون لديها فكرة داخلية عن كيفية عمل العالم الحقيقي. وهذه النظرة ، التي تم الحصول عليها من الصور الفوتوغرافية ، ستتوافق بالتأكيد مع عالمنا الحقيقي والواقعي. على عكس صفائف النصوص التي لا يمكن ضمان ذلك.
إن قيمة الشبكات العصبية المدربة على مجموعة من ImageNet من الصور (والآن OpenImages V4 و COCO و KITTI و BDD100K وغيرها) ليست على الإطلاق حقيقة التعرف على قطة في صورة. ويتم تخزين ذلك في الطبقة قبل الأخيرة. هذا هو المكان الذي توجد فيه مجموعة من الميزات عالية المستوى التي تصف عالمنا. يكون المتجه الذي يتكون من 1024 رقمًا كافيًا للحصول على وصف لـ 1000 فئة مختلفة من الكائنات منه بدقة 80٪ (وفي 95٪ من الحالات ستكون الإجابة الصحيحة في الخيارات الخمسة الأقرب). مجرد التفكير في الأمر.
هذا هو السبب في أن هذه الميزات من الطبقة قبل الأخيرة تُستخدم بنجاح في مهام مختلفة تمامًا في رؤية الكمبيوتر. من خلال نقل التعلم وضبط. من هذا المتجه المكون من 1024 رقمًا ، يمكنك الحصول على خريطة عميقة من الصورة على سبيل المثال
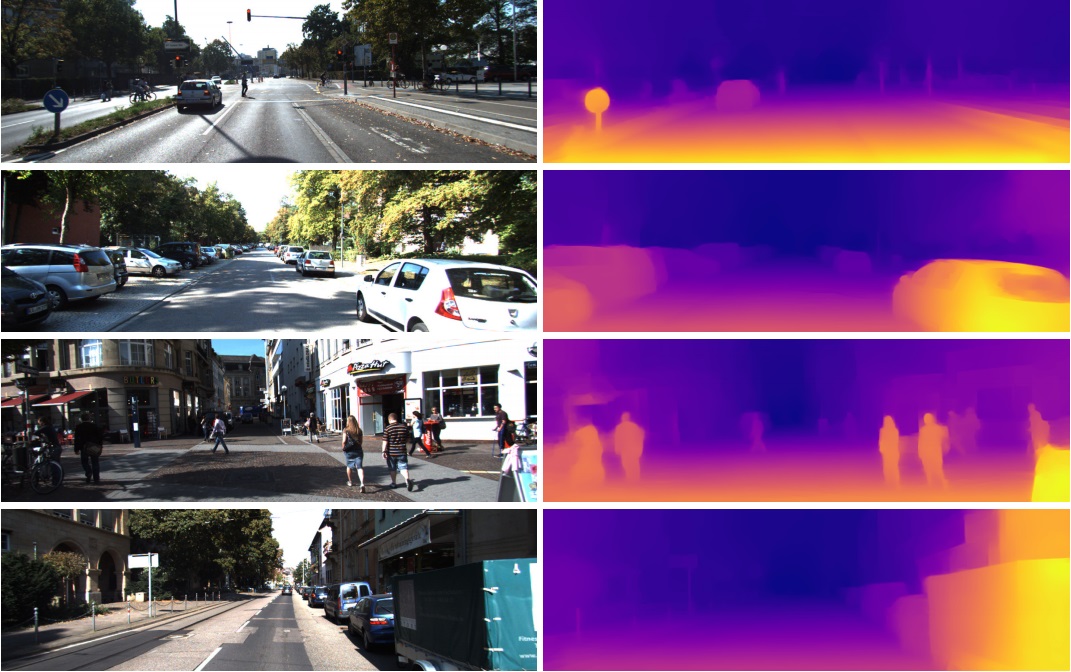
(مثال من العمل الذي يتم فيه استخدام شبكة Densenet-169 لم تتغير فعليًا)
أو تحديد تشكل شخص. هناك العديد من التطبيقات.
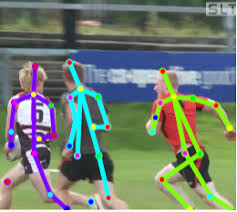
نتيجة لذلك ، يمكن استخدام التعرف على الصور لإنشاء الذكاء الاصطناعى القوي ، لأنه يعكس حقًا نموذج عالمنا الحقيقي. خطوة واحدة من التصوير الفوتوغرافي إلى الفيديو والفيديو هي حياتنا ، حيث نحصل على حوالي 99 ٪ من المعلومات بصريا.
لكن من الصورة غير المفهومة تمامًا كيف تحفز الشبكة العصبية على التفكير واستخلاص النتائج. يمكن تدريبها للإجابة على أسئلة مثل "كم عدد أقلام الرصاص على الطاولة؟" (يُطلق على فئة المهام هذه الإجابة على الأسئلة المرئية ، مثال على مجموعة البيانات هذه: https://visualqa.org ). أو إعطاء وصف نصي لما يحدث في الصورة. هذه هي فئة المهمة Image Captioning .

ولكن هل هذه الذكاء؟ بعد أن طورت هذا النهج ، في المستقبل القريب ، ستكون الشبكات العصبية قادرة على الإجابة عن أسئلة الفيديو مثل "جلس اثنان من العصافير على الأسلاك ، أحدهما طار بعيدًا ، كم عدد العصافير التي تركت؟". هذه هي رياضيات حقيقية ، في حالات أكثر تعقيدًا قليلاً ، يتعذر الوصول إليها على الحيوانات وعلى مستوى التعليم المدرسي البشري. خاصة إذا كان هناك ، باستثناء العصافير ، سيكون هناك ثدي يجلس بجانبهم ، لكن لا يلزم أخذهم في الاعتبار ، لأن السؤال كان فقط حول العصافير. نعم ، سيكون بالتأكيد ذكاء.
3. تعزيز التعلم
الفكرة بسيطة للغاية: تشجيع الإجراءات التي تؤدي إلى المكافأة ، وتجنب حدوث الفشل. هذه طريقة عالمية للتعلم ، ومن الواضح أنها يمكن أن تؤدي بالتأكيد إلى إنشاء منظمة العفو الدولية القوية. لذلك ، كان هناك الكثير من الاهتمام في تعزيز التعلم في السنوات الأخيرة.
خلط ولكن لا تهتزبالطبع ، من الأفضل إنشاء AI قوي من خلال الجمع بين جميع الأساليب الثلاثة. في الصور ومع التدريب التعزيز ، يمكنك الحصول على مستوى الحيوان AI. وإضافة أسماء نصية للكائنات إلى الصور (نكتة ، بالطبع - إجبار منظمة العفو الدولية على مشاهدة مقاطع الفيديو حيث يتفاعل الناس ويتحدثون ، كما هو الحال عند تعليم الطفل) ، وإعادة التدريب على مجموعة نصية لاكتساب المعرفة (نظيرتها في مدرستنا وجامعتنا) ، من الناحية النظرية يمكنك الحصول عليها المستوى البشري AI. قادرة على التحدث.
التعلم المعزز لديه واحد زائد كبير. في المحاكاة ، يمكنك إنشاء نموذج مبسط من العالم. لذلك ، بالنسبة لشخصية الإنسان ، فقط 17 درجة من الحرية كافية ، بدلاً من 700 في شخص حي (العدد التقريبي للعضلات). لذلك ، في محاكاة يمكنك حل المشكلة في بعد صغير جدا.
بالنظر إلى المستقبل ، لا تستطيع خوارزميات التعلم المعزز الحديثة التحكم بشكل تعسفي في نموذج الشخص ، حتى مع وجود 17 درجة من الحرية. أي أنهم لا يستطيعون حل مشكلة التحسين ، حيث يوجد 44 رقمًا في الإدخال و 17 عند المدخلات ، ويمكن القيام بذلك فقط في حالات بسيطة للغاية ، مع صقل الشروط الأولية والمعايير الفوقية. وحتى في هذه الحالة ، على سبيل المثال ، لتعليم نموذج بشري مع 17 درجة من الحرية في الركض ، والبدء من وضع الوقوف (وهو أبسط بكثير) ، فأنت بحاجة إلى عدة أيام من العمليات الحسابية على وحدة معالجة الرسومات القوية. والقضايا الأكثر تعقيدًا قليلاً ، على سبيل المثال ، تعلم الاستيقاظ من وضع تعسفي ، قد لا تتعلم أبدًا على الإطلاق. هذا هو الفشل.
بالإضافة إلى ذلك ، تعمل جميع خوارزميات التعلم المعزز مع شبكات عصبية صغيرة محبطة ، لكنها لا تستطيع التعامل مع الشبكات الكبيرة. تُستخدم شبكات الالتفاف الكبيرة فقط لتقليل بُعد الصورة إلى العديد من الميزات ، والتي يتم تغذيتها لخوارزميات التعلم مع التعزيز. يتم التحكم في نفس البشر الذي يجري تشغيله بواسطة شبكة التغذية الأمامية مع طبقتين أو ثلاث طبقات من 128 خلية عصبية. حقا؟ وبناءً على ذلك ، هل نحاول بناء الذكاء الاصطناعى القوي؟
لمحاولة فهم سبب حدوث ذلك وما هو الخطأ في تعلم التعزيز ، عليك أولاً أن تتعرف على الهياكل الأساسية في تعلم التعزيز الحديث.
يتم ضبط التركيب الفيزيائي للدماغ والجهاز العصبي عن طريق التطور لنوع معين من الحيوانات وظروف معيشتها. لذلك ، أثناء التطور ، طورت الذبابة مثل هذا الجهاز العصبي ومثل هذا العمل من جانب الناقلات العصبية في العقد (تناظرية الدماغ في الحشرات) لتفادي منشق الذبابة بسرعة. حسنًا ، ليس من منشه الذباب ، ولكن من الطيور التي تم صيدها لمدة 400 مليون عام (تمزح فقط ، ظهرت الطيور نفسها قبل 150 مليون عام ، على الأرجح من الضفادع 360 مليون عام). وحيد القرن بما فيه الكفاية مثل هذا الجهاز العصبي والدماغ لتحويل ببطء نحو الهدف والبدء في الجري. وهناك ، كما يقولون ، وحيد القرن ضعيف البصر ، لكن هذه ليست مشكلته.
لكن بالإضافة إلى التطور ، يعمل كل فرد بعينه ، بدءًا من الولادة وطوال الحياة ، على وجه التحديد على آلية التعلم المعتادة مع التعزيز. في حالة الثدييات والحشرات أيضًا ، يقوم نظام الدوبامين بهذا العمل. إن عملها مليء بالأسرار والفروق الدقيقة ، لكن كل ذلك يتلخص في حقيقة أن نظام الدوبامين ، من خلال آليات الذاكرة ، يعمل بشكل ما على إصلاح الروابط بين الخلايا العصبية التي كانت نشطة من قبل. هذه هي الطريقة التي يتم تشكيل الذاكرة النقابي.
والذي ، بسبب ارتباطه ، يستخدم بعد ذلك في صنع القرار. ببساطة ، إذا كان الوضع الحالي (الخلايا العصبية النشطة الحالية في هذه الحالة) من خلال الذاكرة الترابطية ينشط الخلايا العصبية اللطيفة ، عندها يختار الفرد الإجراءات التي قامت بها في موقف مماثل والتي تتذكرها. "يختار الإجراءات" هو تعريف ضعيف. لا يوجد خيار. ببساطة ، يتم تنشيط الخلايا العصبية ذات الذاكرة الممتعة ببساطة ، التي يحددها نظام الدوبامين لحالة معينة ، وتنشط الخلايا العصبية الحركية تلقائيًا ، مما يؤدي إلى تقلص العضلات. هذا إذا كانت هناك حاجة لاتخاذ إجراءات فورية.
التعلم الاصطناعي مع التعزيز ، كمجال للمعرفة ، فمن الضروري حل كل من هذه المشاكل:
1. اختر بنية الشبكة العصبية (ما الذي أحدثه التطور بالفعل بالنسبة لنا)
والخبر السار هو أن الوظائف المعرفية العليا التي يتم إجراؤها في القشرة المخية الحديثة في الثدييات (وفي المخطط في corvids ) يتم إجراؤها في بنية موحدة تقريبًا. على ما يبدو ، هذا لا يحتاج إلى بعض "الهندسة المعمارية" المقررة بشكل صارم.
ربما يرجع تنوع مناطق الدماغ إلى أسباب تاريخية بحتة. عندما تطورت أجزاء جديدة من الدماغ ، مع تطورها ، فوق الأجزاء الأساسية المتبقية من الحيوانات الأولى. من حيث المبدأ أنها تعمل - لا تلمس. من ناحية أخرى ، في مختلف الناس ، نفس أجزاء المخ تتفاعل مع نفس المواقف. يمكن تفسير ذلك من خلال كل من الارتباط (السمات و "الخلايا العصبية للجدة" التي تشكلت بشكل طبيعي في هذه الأماكن أثناء عملية التعلم) ، وعلم وظائف الأعضاء. تؤدي مسارات الإشارة المشفرة في الجينات إلى هذه المناطق على وجه التحديد. لا يوجد إجماع ، لكن يمكنك أن تقرأ ، على سبيل المثال ، هذا المقال الحديث: "الذكاء البيولوجي والاصطناعي" .
2. تعلم كيفية تدريب الشبكات العصبية وفقا لمبادئ التعلم مع التعزيز
هذا هو ما يقوم به التعلم المعزز الحديث بشكل أساسي. وما هي النجاحات؟ ليس حقا
نهج ساذج
يبدو أنه من السهل للغاية تدريب شبكة عصبية مع التعزيز: نقوم بأعمال عشوائية ، وإذا حصلنا على مكافأة ، فإننا نعتبر الإجراءات التي اتخذت "مرجعًا". وضعناها على إخراج الشبكة العصبية كتسميات قياسية ، وقمنا بتدريب الشبكة العصبية من خلال طريقة الانتشار الخلفي للخطأ ، بحيث تنتج مثل هذا الإخراج بالضبط. حسنا ، تدريب الشبكة العصبية الأكثر شيوعا. وإذا أدت الإجراءات إلى الفشل ، فإما أن تتجاهل هذه الحالة ، أو تقمع هذه الإجراءات (نضع بعض الإجراءات الأخرى كمخرجات ، على سبيل المثال ، أي إجراء عشوائي آخر). بشكل عام ، هذه الفكرة تكرر نظام الدوبامين.
ولكن إذا حاولت تدريب أي شبكة عصبية بهذه الطريقة ، فبغض النظر عن مدى تعقيد البنية ، أو التكرار ، أو التلافيفي ، أو التوزيع المباشر العادي ، فلن ينجح ذلك!
لماذا؟ غير معروف
يُعتقد أن الإشارة المفيدة صغيرة جدًا بحيث يتم فقدها على خلفية الضوضاء. لذلك ، فإن الشبكة لا تتعلم الطريقة القياسية لنشر الخطأ. نادراً ما تحدث المكافأة ، ربما مرة واحدة في مئات أو حتى آلاف الخطوات. وحتى LSTM يتذكر 100-500 نقطة كحد أقصى في التاريخ ، وبعد ذلك فقط في مهام بسيطة للغاية. لكن في النقاط الأكثر تعقيدًا ، إذا كان هناك 10-20 نقطة في التاريخ ، فهذا جيد بالفعل.
لكن جذر المشكلة هو بالتحديد في مكافآت نادرة للغاية (على الأقل في مهام ذات قيمة عملية). في الوقت الحالي ، لا نعرف كيفية تدريب الشبكات العصبية التي ستتذكر الحالات المعزولة. ما الدماغ يتأقلم مع الذكاء. يمكنك تذكر شيء حدث مرة واحدة فقط لمدى الحياة. وبالمناسبة ، فإن معظم التدريب وعمل الفكر مبنيان على مثل هذه الحالات فقط.
هذا شيء يشبه اختلالًا فظيعًا في الطبقات من مجال التعرف على الصور. ببساطة لا توجد طرق للتعامل مع هذا. أفضل ما تمكنوا من الوصول إليه حتى الآن هو ببساطة أن يقدموا لمدخلات الشبكة ، إلى جانب مواقف جديدة ، مواقف ناجحة من الماضي مخزنة في مخزن مؤقت خاص صناعي. وهذا هو ، لتعليم باستمرار ليس فقط الحالات الجديدة ، ولكن أيضا الحالات القديمة الناجحة. بطبيعة الحال ، لا يمكن زيادة هذا المخزن المؤقت بلا حدود ، وليس من الواضح ما الذي يجب تخزينه فيه بالضبط. ما زلت تحاول إصلاح المسارات داخل الشبكة العصبية بشكلٍ مؤقت ، والتي كانت نشطة أثناء إحدى الحالات الناجحة ، بحيث لا يحل التدريب اللاحق بها. تشبيهًا وثيقًا لما يحدث في الدماغ ، في رأيي ، رغم أنهم لم يحققوا نجاحًا كبيرًا في هذا الاتجاه أيضًا. نظرًا لأن المهام المدربة الجديدة في حسابها تستخدم نتائج الخلايا العصبية التي تغادر المسارات المجمدة ، ونتيجة لذلك ، تتداخل الإشارة فقط مع المسارات المجمدة الجديدة ، وتتوقف المهام القديمة عن العمل. هناك طريقة غريبة أخرى: تدريب الشبكة بأمثلة / مهام جديدة فقط في الاتجاه المتعامد للمهام السابقة ( https://arxiv.org/abs/1810.01256 ). هذا لا يحل محل التجربة السابقة ، ولكنه يحد بشكل كبير من سعة الشبكة.
يتم تطوير فئة منفصلة من الخوارزميات المصممة للتعامل مع هذه الكارثة (وفي الوقت نفسه إعطاء الأمل لتحقيق الذكاء الاصطناعى القوي) في Meta-Learning. هذه محاولات لتعليم شبكة عصبية عدة مهام في وقت واحد. ليس بمعنى أنه يتعرف على الصور المختلفة في مهمة واحدة ، أي المهام المختلفة في المجالات المختلفة (لكل منها توزيعها الخاص والحل الأفقي). قل ، تعرف على الصور وركوب دراجة في نفس الوقت. حتى الآن ، فإن النجاح ليس جيدًا أيضًا ، لأنه عادةً ما يرجع كل ذلك إلى إعداد شبكة عصبية مسبقًا بأوزان عامة عامة ، ثم بسرعة ، في بضع خطوات فقط من النسب المتدرجة ، لتكييفها مع مهمة محددة. أمثلة على خوارزميات التعلم الفوقية هي MAML و الزواحف .
بشكل عام ، فقط هذه المشكلة (عدم القدرة على التعلم من أمثلة ناجحة واحدة) هي التي تضع حدا للتدريب الحديث مع التعزيز. كل قوة الشبكات العصبية قبل هذه الحقيقة المحزنة هي عاجزة حتى الآن.
هذه الحقيقة ، أن الطريقة الأبسط والأكثر وضوحًا لا تنجح ، أجبرت الباحثين على العودة إلى التعلم المعزز الكلاسيكي القائم على الطاولة. الذي ، كعلم ، ظهر في العصور القديمة ، عندما لم تكن الشبكات العصبية موجودة في المشروع. ولكن الآن ، بدلاً من حساب القيم في الجداول والصيغ يدويًا ، دعونا نستخدم تقريبًا قويًا مثل الشبكات العصبية كوظائف موضوعية! هذا هو جوهر التعلم المعزز. والفرق الرئيسي بين التدريب المعتاد للشبكات العصبية.
كيو التعلم و DQN
وُلد التعلم المعزز (حتى قبل الشبكات العصبية) كفكرة بسيطة ومبتكرة: فلنفعل أعمالًا عشوائية ، وبعد ذلك بالنسبة لكل خلية في الجدول ولكل اتجاه للحركة ، نحسب وفقًا لصيغة خاصة (تسمى معادلة بيلمان ، هذه الكلمة التي سوف للقاء في كل عمل تقريبًا بتدريب التعزيز) مدى جودة هذه الخلية والاتجاه المختار. كلما زاد هذا العدد ، كلما زاد احتمال هذا المسار إلى النصر.
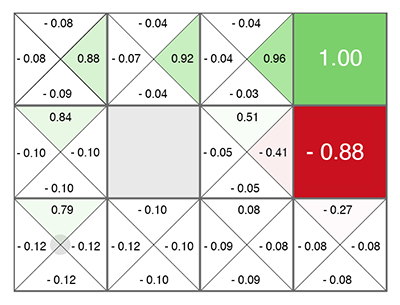
بغض النظر عن الخلية التي تظهر فيها ، تحرك على طول الأخضر المتزايد! (نحو الحد الأقصى لعدد على جانبي الخلية الحالية).
يسمى هذا الرقم Q (من جودة الكلمة - جودة الاختيار ، بشكل واضح) ، والطريقة هي Q- التعلم. استبدال صيغة حساب هذا الرقم بشبكة عصبية ، أو بالأحرى تعليم الشبكة العصبية باستخدام هذه الصيغة (بالإضافة إلى حيلتين أخريين متصلتين تمامًا برياضيات تدريب الشبكات العصبية) ، حصلت Deepmind على طريقة DQN . هذا هو الذي فاز في عام 2015 كومة من ألعاب أتاري وبدأت ثورة في التعلم العميق التعزيز.
لسوء الحظ ، تعمل هذه الطريقة في بنيتها فقط مع إجراءات منفصلة منفصلة. في DQN ، يتم تغذية الحالة الحالية (الوضع الحالي) إلى مدخلات الشبكة العصبية ، وعند الخرج تتوقع الشبكة العصبية الرقم Q. وبما أن إخراج الشبكة يسرد جميع الإجراءات الممكنة في وقت واحد (كل منها به Q المتوقع ،) فإن الشبكة العصبية في DQN تنفذ الوظيفة الكلاسيكية Q (ق ، أ) من Q- التعلم. Q state action ( Q(s,a) s a). argmax Q , .
Q, . , Q- (.. Q , ). . , (Exploration), , , . , .
, ? 5 Atari, continuous ? , -1..1 0.1, , Atari. . , . 10 . - , 10 . . DQN , 17 . , , .
DQN, , , continuous ( ): DDQN, DuDQN, BDQN, CDQN, NAF, Rainbow. , Direct Future Prediction (DFP) , DQN . Q , DFP , . . , . , , , .
, Reinforcement Learning.
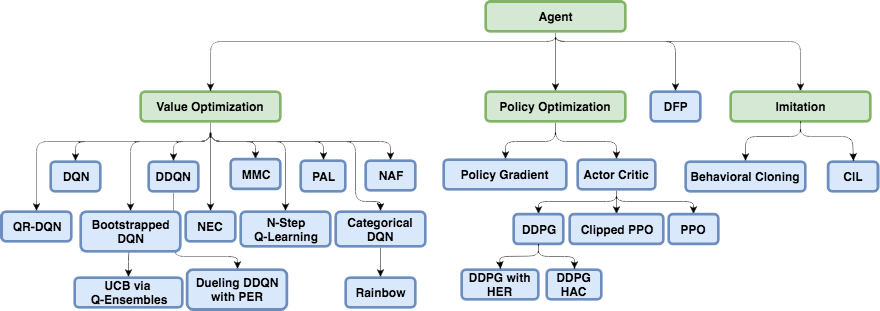
Policy Gradient
state, ( , ). , actions, . , R . ( ), ( ). . .
, R , , . ! . "" labels ( ), . , , R.
Policy Gradient. — , R, . — , , . , .
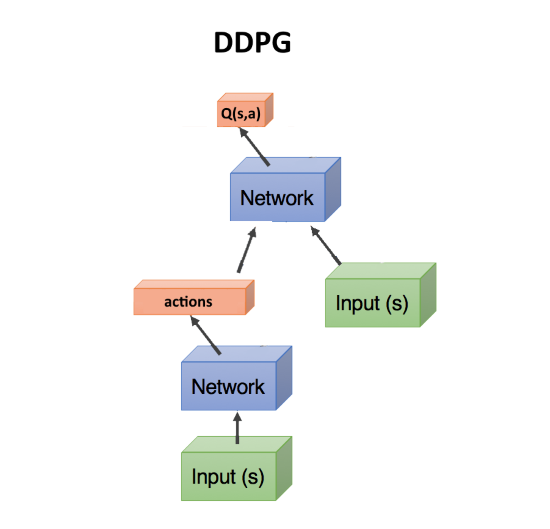
Actor-critic, DDPG
, — , . , Q- , DQN. state, action(s). state, action, , Q : Q(s,a).
, Q(s,a), ( critic, ), , ( , actor), R. , . actor-critic. Policy Gradient, , . .
DDPG. actions, continuous . DDPG continuous DQN .
Advantage Actor Critic (A3C/A2C)
critic Q(s,a) — , actor, DDPG. , .
, . , , , . , , , ( , ).
Q(s,a), Advantage: A(s,a) = Q(s,a) — V(s). A(s,a) Q(s,a) , — , V(s). A(s,a) > 0, , . A(s,a) < 0, , , .. .
V(s) state , ( s, a). — state, V(s). , state, V(s).
, Q(s,a) r, , A = r — V(s).
, V(s) ( ), — actor critic, ! state, head: actions, V(s). c , .. state. , .
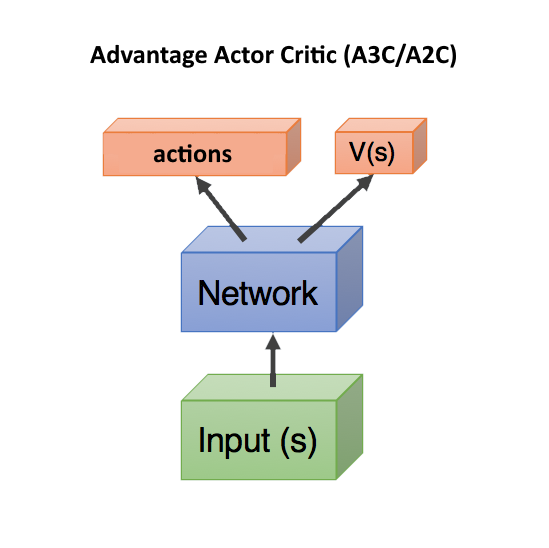
V(s) . V(s), action ( ), . Dueling Q-Network (DuDQN), Q(s,a) Q(s,a) = V(s) + A(a), .
Asynchronous Advantage Actor Critic (A3C) , , actor. batch . , actor. , , . , A2C — A3C, actor ( ). A2C , , .
TRPO, PPO, SAC
, .
, . Reinforcement Learning , , , — , . .
— TRPO PPO, state-of-the-art, Actor-Critic. PPO RL. , OpenAI Five Dota 2.
, TRPO PPO — , . , A3C/A2C , . , policy , . - gradient clipping , . , ( , ), , , - .
في الآونة الأخيرة ، اكتسبت خوارزمية Soft-Actor-Critic (SAC) شعبية. إنه لا يختلف تمامًا عن PPO ، فقد تم إضافة هدف فقط عند تعلم زيادة الانتروبيا في السياسة. اجعل سلوك الوكيل أكثر عشوائية. لا ، ليس هكذا. أن الوكيل كان قادرًا على التصرف في مواقف عشوائية أكثر. يؤدي هذا تلقائيًا إلى زيادة موثوقية السياسة ، بمجرد أن يكون الوكيل جاهزًا لأي مواقف عشوائية. بالإضافة إلى ذلك ، تتطلب SAC أمثلة تدريب أقل بقليل من PPO ، وأقل حساسية لإعدادات hyperparameter ، والتي تعد أيضًا ميزة إضافية. ومع ذلك ، حتى مع SAC ، من أجل تدريب الإنسان على الركض مع 17 درجة من الحرية ، بدءًا من وضع الوقوف ، فإنك تحتاج إلى حوالي 20 مليون إطار وحوالي يوم من الحساب على وحدة معالجة GPU واحدة. شروط أولية أكثر صعوبة ، على سبيل المثال ، لتعليم إنسان ما ينشأ من وضع تعسفي ، قد لا يتم تدريسها على الإطلاق.
المجموع ، التوصية العامة في التعلم المعزز الحديث: استخدام SAC ، PPO ، DDPG ، DQN (بهذا الترتيب ، تنازلي).
القائم على النموذج
هناك نهج آخر مثير للاهتمام ، يرتبط بشكل غير مباشر بتعلم التعزيز. هذا هو بناء نموذج للبيئة ، واستخدامه للتنبؤ بما سيحدث إذا اتخذنا بعض الإجراءات.
عيبه هو أنه لا يقول بأي طريقة الإجراءات التي ينبغي اتخاذها. فقط عن نتائجها. لكن مثل هذه الشبكة العصبية سهلة التدريب - فقط تدريب على أي إحصائيات. اتضح ما يشبه محاكاة العالم بناءً على شبكة عصبية.
بعد ذلك ، نقوم بإنشاء عدد كبير من الإجراءات العشوائية ، ويتم توجيه كل منها من خلال هذا المحاكاة (عبر شبكة عصبية). ونحن ننظر أي واحد سيجلب أقصى مكافأة. هناك تحسين بسيط - ليس فقط لتوليد تصرفات عشوائية ، ولكن منحرف وفقًا للقانون العادي عن المسار الحالي. وبالفعل ، إذا رفعنا أيدينا ، فعندئذ باحتمال كبير نحتاج إلى مواصلة رفعها. لذلك ، بادئ ذي بدء ، تحتاج إلى التحقق من الحد الأدنى للانحرافات عن المسار الحالي.
الحيلة هنا هي أنه حتى المحاكاة الفيزيائية البدائية مثل MuJoCo أو pyBullet تنتج حوالي 200 FPS. وإذا قمت بتدريب شبكة عصبية للتنبؤ بالأمام على الأقل بضع خطوات ، فبالنسبة للبيئات البسيطة ، يمكنك بسهولة الحصول على دفعات من 2000 إلى 5000 تنبؤات في وقت واحد. اعتمادًا على قوة وحدة معالجة الرسومات ، يمكنك الحصول على تنبؤات لعشرات الآلاف من الإجراءات العشوائية في الثانية الواحدة بسبب التوازي في وحدة معالجة الرسومات والسرعة الحاسوبية في الشبكة العصبية. تعمل الشبكة العصبية هنا ببساطة كمحاكاة سريعة جدًا للواقع.
بالإضافة إلى ذلك ، نظرًا لأن الشبكة العصبية يمكن أن تتنبأ بالعالم الحقيقي (وهذا نهج قائم على النموذج بالمعنى العام) ، عندئذٍ يمكن إجراء التدريب بالكامل في الخيال ، إذا جاز التعبير. يطلق على هذا المفهوم في التعلم المعزز حلم العوالم ، أو نماذج العالم. هذا يعمل بشكل جيد ، وصف جيد هنا: https://worldmodels.imtqy.com . بالإضافة إلى ذلك ، لديها نظير طبيعي - أحلام عادية. والتمرير متعددة من الأحداث الأخيرة أو المخطط لها في الرأس.
التعلم التقليد
نظرًا للعجز الذي لا تعمل خوارزميات تعلم التعزيز فيه على أبعاد كبيرة ومهام معقدة ، بدأ الأشخاص على الأقل في تكرار تصرفات الخبراء في شكل أشخاص. هنا ، تم تحقيق نتائج جيدة (يتعذر الوصول إليها عن طريق التعلم التعزيز التقليدي). لذلك ، تحولت OpenAI لتمرير لعبة Montezuma Revenge . تبين أن الحيلة بسيطة - وهي وضع الوكيل على الفور في نهاية اللعبة (في نهاية المسار الذي يظهره الشخص). هناك ، بمساعدة PPO ، بفضل قرب المكافأة النهائية ، يتعلم الوكيل بسرعة السير على طول المسار. بعد ذلك ، وضعناه قليلاً ، حيث يتعلم بسرعة الوصول إلى المكان الذي درسه بالفعل. وهكذا ، بالتحول التدريجي لنقطة "الفك" على طول المسار حتى بداية اللعبة ، يتعلم الوكيل اجتياز / محاكاة مسار الخبير طوال اللعبة.
هناك نتيجة أخرى مثيرة للإعجاب وهي تكرار حركات الأشخاص الذين تم تصويرهم على Motion Capture: DeepMimic . تشبه الوصفة طريقة OpenAI: لا تبدأ كل حلقة من بداية المسار ، ولكن من نقطة عشوائية على طول المسار. ثم PPO يدرس بنجاح محيط هذه النقطة.
يجب أن أقول إن خوارزمية Go-Explore المثيرة من Uber ، والتي مرت على الانتقام من Montezuma بنقاط قياسية ، ليست خوارزمية تعلم التعزيز على الإطلاق. هذا بحث عشوائي منتظم ، ولكنه يبدأ بخلية خلية تم زيارتها عشوائيًا (خلية خاملة تقع فيها عدة حالات). وفقط عندما يتم العثور على المسار حتى نهاية اللعبة من خلال هذا البحث العشوائي ، يتم تدريب الشبكة العصبية باستخدام Imitation Learning. بطريقة مشابهة لـ OpenAI ، أي بدءا من نهاية المسار.
الفضول (الفضول)
مفهوم مهم للغاية في تعزيز التعلم هو الفضول. في الطبيعة ، هو محرك للبحوث البيئية.
المشكلة هي أنه كمقياس للفضول ، لا يمكنك استخدام خطأ بسيط في التنبؤ بالشبكة ، ماذا سيحدث بعد ذلك. خلاف ذلك ، سوف يتعطل مثل هذه الشبكة أمام الشجرة الأولى مع أوراق الشجر المتمايلة. أو أمام جهاز تلفزيون مع تبديل قناة عشوائي. لأن النتيجة بسبب التعقيد سيكون من المستحيل التنبؤ بها والخطأ سيكون دائمًا كبيرًا. ومع ذلك ، هذا هو بالضبط السبب في أننا (الناس) نحب أن ننظر إلى أوراق الشجر والماء والنار. وكيف يعمل الآخرون =). ولكن لدينا آليات وقائية حتى لا نعلقها إلى الأبد.
اخترعت واحدة من هذه الآليات كنموذج معكوس في الاستكشاف بواسطة الفضول
التنبؤ بالإشراف الذاتي . باختصار ، يحاول الوكيل (الشبكة العصبية) ، بالإضافة إلى التنبؤ بالإجراءات الأفضل أداءً في موقف معين ، التنبؤ بما سيحدث للعالم بعد الإجراءات المتخذة. ويستخدم هذا التنبؤ للعالم للخطوة التالية ، حتى يتمكن هو والخطوة الحالية من توقع تصرفاته التي تم اتخاذها في وقت مبكر (نعم ، من الصعب ، لا يمكنك تحديد ذلك دون نصف لتر).
هذا يؤدي إلى تأثير فضولي: يصبح العامل فضوليًا فقط لما يمكنه التأثير عليه من خلال تصرفاته. لا يستطيع التأثير على الفروع المتأرجحة للشجرة ، حتى يصبحوا غير مهتمين به. لكنه يستطيع المشي في جميع أنحاء المنطقة ، لذلك فهو فضولي للمشي واستكشاف العالم.
ومع ذلك ، إذا كان لدى الوكيل جهاز تحكم عن بعد للتلفزيون يقوم بتبديل القنوات العشوائية ، فيمكنه التأثير عليه! وسيشعر بالفضول للنقر فوق القنوات التي لا نهاية لها (لأنه لا يمكنه التنبؤ بما ستكون عليه القناة التالية ، لأنها عشوائية). قامت Google بمحاولة للتحايل على هذه المشكلة في أعمال Episodic Curiosity من خلال Reachability .
ولكن ربما تكون أفضل نتيجة على الإطلاق هي الفضول ، تمتلك OpenAI حاليًا فكرة تقطير الشبكة العشوائية (RND) . جوهرها هو أنها تأخذ شبكة ثانية ، تمت تهيئتها بشكل عشوائي تمامًا ، ويتم تغذية الحالة الحالية بها. وتحاول شبكتنا العصبية العاملة الرئيسية تخمين ناتج هذه الشبكة العصبية. الشبكة الثانية غير مدربة ، تظل ثابتة طوال الوقت كما تمت تهيئة.
ما هي النقطة؟ النقطة المهمة هي أنه إذا تمت زيارة أي ولاية بالفعل ودراستها من قبل شبكة العمل الخاصة بنا ، فسيكون بإمكانها بشكل أو بآخر التنبؤ بنتيجة تلك الشبكة الثانية. وإذا كانت هذه حالة جديدة ، لم نكن فيها مطلقًا ، فلن تتمكن شبكتنا العصبية من التنبؤ بإخراج شبكة RND هذه. يتم استخدام هذا الخطأ في التنبؤ بمخرجات تلك الشبكة التي تمت تهيئتها عشوائيًا كمؤشر للفضول (يعطي مكافآت عالية إذا لم نتمكن من التنبؤ بإنتاجها في هذا الموقف).
لماذا هذا ليس واضحا تماما. لكنهم يكتبون أن هذا يحل المشكلة عندما يكون هدف التنبؤ عشوائيًا وعندما لا تكون هناك بيانات كافية للتنبؤ بما سيحدث بعد ذلك (والذي يعطي خطأً كبيراً في التنبؤ في خوارزميات الفضول العادية). بطريقة أو بأخرى ، لكن RND أظهر بالفعل نتائج بحثية ممتازة تستند إلى الفضول في الألعاب. ويتواءم مع مشكلة التلفزيون العشوائي.
مع RND ، اجتاز الفضول في OpenAI لأول مرة بأمانة (وليس من خلال البحث العشوائي الأولي ، كما هو الحال في Uber) المستوى الأول من الانتقام Montezuma. ليس في كل مرة وبشكل غير موثوق ، ولكن من وقت لآخر اتضح.

ما هي النتيجة؟
كما ترون ، في بضع سنوات فقط ، قطع التعلم المعزز طريقًا طويلاً. ليس فقط عدد قليل من الحلول الناجحة ، كما هو الحال في الشبكات التلافيفية ، حيث أتاحت اتصالات resudal وتخطي الشبكات تدريب مئات الطبقات بعمق ، بدلاً من عشرات الطبقات مع وظيفة تنشيط Relu وحدها ، والتي تغلبت على مشكلة اختفاء التدرجات اللونية في السيني والتان. في التعلم مع التعزيز ، كان هناك تقدم في المفاهيم وفهم الأسباب وراء عدم نجاح هذا الإصدار أو ذاك من التطبيق الساذج للتنفيذ. الكلمة الأساسية "لم تنجح".
ولكن من الناحية الفنية ، لا يزال كل شيء يعتمد على تنبؤات جميع قيم Q أو V أو A نفسها. لا توجد تبعيات زمنية بمقاييس مختلفة ، كما هو الحال في الدماغ (لا يُعتبر التعلم الهرمي للتعزيز ، التسلسل الهرمي بدائي للغاية فيه مقارنة مع الارتباط في الدماغ الحي). لا توجد محاولات للتوصل إلى بنية شبكة مصممة خصيصًا للتعلم التعزيز ، كما حدث مع LSTM والشبكات المتكررة الأخرى لتسلسل الوقت. التعزيز يتعلم التعلم إما على الفور أو يفرح في نجاحات صغيرة أو يتحرك في اتجاه خاطئ تمامًا.
أود أن أصدق أنه بمجرد تعلم التعزيز سيكون هناك طفرة في بنية الشبكات العصبية ، على غرار ما حدث في الشبكات التلافيفية. ونحن سوف نرى التعلم التعزيز العمل حقا. التعلم على أمثلة معزولة ، مع الذاكرة النقابية العاملة والعمل على نطاقات زمنية مختلفة.