تعد لغة R اليوم واحدة من أقوى الأدوات ومتعددة الوظائف للعمل مع البيانات ، ولكن كما نعرف دائمًا ، توجد ذبابة في المرهم في أي برميل من العسل. الحقيقة هي أن R مفردة بشكل افتراضي.
على الأرجح لن يزعجك هذا لفترة طويلة بما فيه الكفاية ، ومن غير المرجح أن تطرح هذا السؤال. ولكن على سبيل المثال ، إذا كنت تواجه مهمة جمع البيانات من عدد كبير من حسابات الإعلانات من واجهة برمجة التطبيقات ، على سبيل المثال Yandex.Direct ، فيمكنك بشكل كبير ، على الأقل مرتين إلى ثلاث مرات ، تقليل الوقت الذي يستغرقه جمع البيانات باستخدام تعدد العمليات.

موضوع تعدد مؤشرات الترابط في R ليس جديدًا ، وقد تم طرحه مرارًا وتكرارًا على Habré هنا ، هنا وهنا ، ولكن المنشور الأخير يعود إلى عام 2013 ، وكما يقولون أن كل ما هو جديد قديم جدًا. بالإضافة إلى ذلك ، تمت مناقشة تعدد العمليات في السابق لحساب النماذج وتدريب الشبكات العصبية ، وسنتحدث عن استخدام عدم التزامن للعمل مع واجهة برمجة التطبيقات. ومع ذلك ، أود أن أغتنم هذه الفرصة لأشكر مؤلفي هذه المقالات لأنه لقد ساعدوني كثيرا في كتابة هذا المقال مع منشوراتهم.
المحتويات
الجزء الثاني من المقالة ، والذي يتناول خيارات أكثر حداثة لتطبيق تعدد العمليات في R ، متاح هنا .
ما هو multithreading
مؤشر ترابط واحد (حسابات متسلسلة) - وضع حساب يتم فيه تنفيذ جميع الإجراءات (المهام) بالتتابع ، وستكون المدة الإجمالية لجميع العمليات المقدمة في هذه الحالة مساوية لمجموع مدة جميع العمليات.
تعدد العمليات (الحوسبة المتوازية) - وضع الحوسبة التي يتم فيها تنفيذ الإجراءات المحددة (المهام) بشكل متوازٍ ، أي في نفس الوقت ، في حين أن إجمالي وقت تنفيذ جميع العمليات لن يساوي مجموع مدة جميع العمليات.
لتبسيط التصور ، دعنا ننظر إلى الجدول التالي:
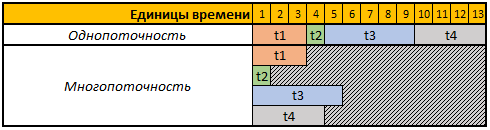
الصف الأول من الجدول المحدد هو وحدات زمنية مشروطة ، وفي هذه الحالة لا يهمنا ثوانٍ أو دقائق أو أي فترات زمنية أخرى.
في هذا المثال ، نحتاج إلى إجراء 4 عمليات ، كل عملية في هذه الحالة لها مدة حسابية مختلفة ، في الوضع المفرد ، سيتم تنفيذ جميع العمليات الأربع بالتتابع واحدة تلو الأخرى ، وبالتالي فإن إجمالي الوقت لتنفيذها سيكون t1 + t2 + t3 + t4 ، 3 + 1 + 5 + 4 = 13.
في الوضع متعدد الخيوط ، سيتم تنفيذ جميع المهام الأربع بالتوازي ، أي لبدء المهمة التالية ، ليست هناك حاجة إلى الانتظار حتى تكتمل المهمة السابقة ، لذلك إذا بدأنا مهمتنا في 4 سلاسل ، فإن وقت الحساب الإجمالي سيكون مساوياً لوقت حساب المهمة الأكبر ، وفي حالتنا هذه المهمة t3 ، ومدة الحساب في مثالنا هي 5 وحدات مؤقتة ، على التوالي ، ووقت تنفيذ جميع العمليات 4 في هذه الحالة سوف تساوي 5 وحدات مؤقتة.
ما الحزم سوف نستخدمها
بالنسبة للحسابات في الوضع متعدد مؤشرات الترابط ، doParallel foreach و doSNOW و doParallel .
تسمح لك حزمة foreach باستخدام بنية foreach ، والتي تعد في الأساس حلقة معززة.
تعد doParallel و doParallel أساسيين ، مما يتيح لك إنشاء مجموعات افتراضية واستخدامها لإجراء حسابات متوازية.
في نهاية المقالة ، باستخدام حزمة rbenchmark سنقوم بقياس ومقارنة مدة عمليات جمع البيانات من Yandex.Direct API باستخدام جميع الطرق الموضحة أدناه.
للعمل مع Yandex.Direct API ، سنستخدم حزمة ryandexdirect ، في هذه المقالة سوف نستخدمها كمثال ، يمكن العثور على مزيد من التفاصيل حول قدراتها ووظائفها في الوثائق الرسمية .
رمز لتثبيت جميع الحزم اللازمة:
install.packages("foreach") install.packages("doSNOW") install.packages("doParallel") install.packages("rbenchmark") install.packages("ryandexdirect")
التحدي
يجب عليك كتابة رمز سيطلب قائمة بالكلمات الرئيسية من أي عدد من حسابات إعلانات Yandex.Direct. يجب جمع النتيجة في إطار تاريخ واحد ، حيث سيكون هناك حقل إضافي بتسجيل الدخول إلى حساب الإعلان الذي تنتمي إليه الكلمة الرئيسية.
علاوة على ذلك ، تتمثل مهمتنا في كتابة رمز يؤدي هذه العملية في أسرع وقت ممكن على أي عدد من حسابات الإعلانات.
إذن في Yandex.Direct
للعمل مع واجهة برمجة التطبيقات لنظام Yandex.Direct للإعلانات ، من الضروري في البداية الانتقال إلى التفويض بموجب كل حساب نخطط منه لطلب قائمة بالكلمات الرئيسية.
تعكس كل الشفرة الواردة في هذه المقالة مثالًا على العمل مع حسابات الإعلان العادية في Yandex.Direct ، إذا كنت تعمل تحت حساب وكيل ، فستحتاج إلى استخدام وسيطة AgencyAccount وتمرير تسجيل الدخول إلى حساب الوكيل. يمكنك معرفة المزيد حول العمل مع حسابات الوكلاء في Yandex.Direct باستخدام حزمة ryandexdirect هنا .
للحصول على إذن ، يلزم تنفيذ وظيفة yadirAuth من حزمة yadirAuth ، لتكرار الكود أدناه ضروري لكل حساب ستطلب منه قائمة بالكلمات الرئيسية ومعلماتها.
ryandexdirect::yadirAuth(Login = " ")
تعتبر عملية التفويض في Yandex.Direct من خلال حزمة ryandexdirect آمنة تمامًا ، على الرغم من أنها تمر عبر موقع طرف ثالث. لقد تحدثت بالفعل بالتفصيل عن سلامة استخدامه في مقالة "مدى الأمان لاستخدام حزم R للعمل مع API Systems Systems" .
بعد التفويض ، سيتم إنشاء ملف login.yadirAuth.RData تحت كل حساب في دليل العمل الخاص بك ، والذي سيخزن بيانات الاعتماد لكل حساب. سيبدأ اسم الملف عند تسجيل الدخول المحدد في وسيطة تسجيل الدخول . إذا كنت بحاجة إلى حفظ الملفات ليس في دليل العمل الحالي ، ولكن في بعض المجلدات الأخرى ، استخدم وسيطة TokenPath ، ولكن في هذه الحالة عند الاستعلام عن الكلمات الرئيسية باستخدام وظيفة yadirGetKeyWords فإنك تحتاج أيضًا إلى استخدام وسيطة TokenPath وتحديد المسار إلى المجلد الذي قمت بحفظ الملفات فيه مع أوراق الاعتماد.
حل متسلسل واحد مترابطة باستخدام لحلقة
أسهل طريقة لجمع البيانات من حسابات متعددة في آن واحد هي استخدام الحلقة. بسيطة ولكنها ليست الأكثر فعالية ، لأن أحد مبادئ التطوير في اللغة R هو تجنب استخدام الحلقات في الكود.
فيما يلي رمز مثال لجمع البيانات من 4 حسابات باستخدام حلقة for ، في الواقع ، يمكنك استخدام هذا المثال لجمع البيانات من أي عدد من حسابات الإعلانات.
الكود 1: نعالج 4 حسابات باستخدام المعتاد للحلقة library(ryandexdirect) # logins <- c("login_1", "login_2", "login_3", "login_4") # res1 <- data.frame() # for (login in logins) { temp <- yadirGetKeyWords(Login = login) temp$login <- login res1 <- rbind(res1, temp) }
أظهر قياس وقت التشغيل باستخدام دالة system.time النتيجة التالية:
وقت العمل:
المستخدم: 178.83
النظام: 0.63
مرت: 320.39
استغرقت مجموعة الكلمات الأساسية لـ 4 حسابات 320 ثانية ، ومن رسائل المعلومات التي yadirGetKeyWords وظيفة yadirGetKeyWords أثناء التشغيل ، يتم رؤية أكبر حساب ، تم استلام 5970 كلمة أساسية منها ، وتمت معالجة 142 ثانية.
تعدد مؤشرات الترابط الحل في R
لقد سبق أن كتبت أعلاه أنه من أجل multithreading doParallel و doParallel .
أريد أن ألفت الانتباه إلى حقيقة أن أي واجهة برمجة تطبيقات تقريبًا لها حدودها الخاصة ، وأن Yandex.Direct API ليست استثناءً. في الواقع ، تقول تعليمات العمل مع Yandex.Direct API:
لا يُسمح بأكثر من خمسة طلبات API متزامنة نيابة عن مستخدم واحد.
لذلك ، على الرغم من أننا في هذه الحالة سننظر في مثال على إنشاء 4 تدفقات ، في العمل مع Yandex.Direct ، يمكنك إنشاء 5 تدفقات حتى إذا قمت بإرسال جميع الطلبات تحت نفس المستخدم. لكن من الأكثر منطقية استخدام خيط واحد لكل 1 نواة من المعالج ، يمكنك تحديد عدد نوى المعالج الفعلي باستخدام الأمر parallel::detectCores(logical = FALSE) ، ويمكن العثور على عدد النوى المنطقية باستخدام parallel::detectCores(logical = TRUE) . هناك فهم أكثر تفصيلاً لما يمكن أن يكون عليه هذا الأساس الجسدي والمنطقي على ويكيبيديا .
بالإضافة إلى الحد الأقصى لعدد الطلبات ، هناك حد يومي لعدد النقاط للوصول إلى Yandex.Direct API ، قد يكون مختلفًا بالنسبة لجميع الحسابات ، كما يستهلك كل طلب عددًا مختلفًا من النقاط حسب العملية التي يتم تنفيذها. على سبيل المثال ، للاستعلام عن قائمة بالكلمات الرئيسية ، سيتم خصم 15 نقطة لاستعلام مكتمل و 3 نقاط لكل 2000 كلمة ، يمكنك معرفة كيفية شطب النقاط في الشهادة الرسمية . يمكنك أيضًا مشاهدة معلومات حول عدد النقاط المسجلة والمتاحة ، وكذلك الحد اليومي لرسائل المعلومات التي يتم إرجاعها إلى وحدة التحكم بواسطة وظيفة yadirGetKeyWords .
Number of API points spent when executing the request: 60 Available balance of daily limit API points: 993530 Daily limit of API points:996000
دعونا نتعامل مع doSNOW و doParallel بالترتيب.
حزمة DoSNOW وميزات متعددة مؤشرات الترابط
نعيد كتابة نفس العملية لوضع الحسابات المتعددة الخيوط ، وننشئ 4 سلاسل في هذه الحالة ، وبدلاً من حلقة for ، نستخدم بنية foreach .
الكود 2: الحوسبة المتوازية مع doSNOW library(foreach) library(doSNOW) # logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoSNOW(cl) res2 <- foreach(login = logins, # - .combine = 'rbind', # .packages = "ryandexdirect", # .inorder=F ) %dopar% {cbind(yadirGetKeyWords(Login = login), login) } stopCluster(cl)
في هذه الحالة ، أظهر قياس وقت التشغيل باستخدام دالة system.time النتيجة التالية:
وقت العمل:
المستخدم: 0.17
النظام: 0.08
مرت: 151.47
نفس النتيجة ، أي تلقينا مجموعة من الكلمات الرئيسية من 4 حسابات Yandex.Direct في 151 ثانية ، أي 2 مرات أسرع. بالإضافة إلى ذلك ، كتبت للتو في المثال الأخير المدة التي استغرقتها لتحميل قائمة الكلمات الرئيسية من أكبر حساب (142 ثانية) ، أي في هذا المثال ، يكون إجمالي الوقت مطابقًا تقريبًا لوقت معالجة أكبر حساب. الحقيقة هي أنه بمساعدة وظيفة foreach ، أطلقنا في وقت واحد عملية جمع البيانات في 4 تدفقات ، أي في نفس الوقت الذي تم فيه جمع البيانات من جميع الحسابات الأربعة ، على التوالي ، فإن إجمالي الوقت يساوي وقت معالجة أكبر حساب.
سأقدم شرحًا بسيطًا للرمز 2 ، فإن وظيفة makeCluster المسؤولة عن عدد مؤشرات الترابط ، وفي هذه الحالة أنشأنا مجموعة من 4 مراكز للمعالجات ، ولكن كما كتبت سابقًا عند العمل مع Yandex.Direct API ، يمكنك إنشاء 5 سلاسل رسائل ، بغض النظر عن عدد الحسابات تحتاج إلى معالجة 5-15-100 أو أكثر ، يمكنك إرسال 5 طلبات إلى API في نفس الوقت.
بعد ذلك ، تبدأ الدالة registerDoSNOW الكتلة التي تم إنشاؤها.
بعد ذلك نستخدم بنية foreach ، كما قلت سابقًا ، تم تحسين هذه البنية للحلقة. قمت بتعيين العداد كحجة أولى ، في المثال الذي اتصلت به لتسجيل الدخول وسوف يتكرر على عناصر متجه logins في كل تكرار ، سنحصل على نفس النتيجة في حلقة for إذا كتبنا for ( login in logins) .
بعد ذلك ، تحتاج إلى الإشارة في وسيطة .combine إلى الوظيفة التي ستضم بها النتائج التي تم الحصول عليها في كل تكرار ، والخيارات الأكثر شيوعًا هي:
rbind - الانضمام إلى الجداول الناتجة صفًا تلو الآخر تحت بعضها البعض ؛cbind - cbind الجداول الناتجة في الأعمدة."+" - لخص النتيجة التي تم الحصول عليها في كل تكرار.
يمكنك أيضا استخدام أي وظيفة أخرى ، حتى مكتوبة ذاتيا.
تتيح لك الوسيطة .inorder = F تسريع الوظيفة أكثر قليلاً إذا كنت لا تهتم بترتيب الجمع بين النتائج ، وفي هذه الحالة ، فإن الترتيب ليس مهمًا بالنسبة لنا.
بعد ذلك يأتي المشغل %dopar% ، الذي يبدأ تشغيل الحلقة في وضع الحوسبة المتوازية ، إذا كنت تستخدم عامل %do% ، فسيتم تنفيذ التكرار بالتتابع ، وكذلك عند استخدام المعتاد للحلقة.
الدالة stopCluster توقف الكتلة.
تعدد مؤشرات الترابط ، أو بالأحرى بنية foreach في وضع متعدد مؤشرات الترابط ، لديه بعض الميزات ، في الواقع ، في هذه الحالة ، نبدأ كل عملية متوازية في جلسة R جديدة ونظيفة. لذلك ، من أجل استخدام الدوال والكائنات العامة بداخلها والتي تم تعريفها خارج بنية foreach ، تحتاج إلى تصديرها باستخدام وسيطة .export . تأخذ هذه الوسيطة متجه نص يحتوي على أسماء الكائنات التي ستستخدمها في foreach .
أيضًا ، foreach ، في الوضع المتوازي ، لا يرى الحزم المتصلة مسبقًا افتراضيًا ، لذلك يجب أيضًا تمريرها داخل foreach باستخدام وسيطة .packages . من الضروري أيضًا نقل الحزم عن طريق سرد أسمائها في متجه نص ، على سبيل المثال .packages = c("ryandexdirect", "dplyr", "lubridate") . في المثال 2 أعلاه ، قمنا فقط بتحميل حزمة ryandexdirect في كل تكرار لـ foreach .
حزمة DoParallel
كما كتبت أعلاه ، فإن doParallel و doParallel هما توأمان ، لذلك يكون لهما نفس الصيغة.
الرمز 5: الحوسبة المتوازية مع doParallel library(foreach) library(doParallel) logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoParallel(cl) res3 <- data.frame() res3 <- foreach(login=logins, .combine= 'rbind', .inorder=F) %dopar% {cbind(ryandexdirect::yadirGetKeyWords(Login = login), login) stopCluster(cl)
وقت العمل:
المستخدم: 0.25
النظام: 0.01
مرت: 173.28
كما ترون في هذه الحالة ، يختلف وقت التنفيذ قليلاً عن المثال السابق لرمز الحوسبة المتوازية باستخدام حزمة doSNOW .
اختبار السرعة بين النهج الثلاثة التي تمت مراجعتها
الآن قم بإجراء اختبار السرعة باستخدام حزمة rbenchmark .
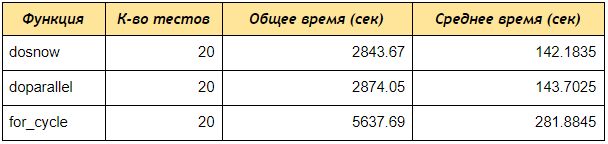
كما ترون ، حتى في اختبار 4 حسابات ، تلقت doParallel و doParallel البيانات عن طريق الكلمات الرئيسية أسرع مرتين من التسلسل للحلقة ، إذا قمت بإنشاء مجموعة مكونة من 5 مراكز ومعالجة 50 أو 100 حساب ، فإن الفرق سيكون أكثر أهمية.
الرمز 6: برنامج نصي لمقارنة سرعة تعدد العمليات والحوسبة المتسلسلة # library(ryandexdirect) library(foreach) library(doParallel) library(doSNOW) library(rbenchmark) # for for_fun <- function(logins) { res1 <- data.frame() for (login in logins) { temp <- yadirGetKeyWords(Login = login) res1 <- rbind(res1, temp) } return(res1) } # foreach doSNOW dosnow_fun <- function(logins) { cl <- makeCluster(4) registerDoSNOW(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login } }) stopCluster(cl) return(res2) } # foreach doParallel dopar_fun <- function(logins) { cl <- makeCluster(4) registerDoParallel(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login) } }) stopCluster(cl) return(res2) } # within(benchmark(for_cycle = for_fun(logins = logins), dosnow = dosnow_fun(logins = logins), doparallel = dopar_fun(logins = logins), replications = c(20), columns=c('test', 'replications', 'elapsed'), order=c('elapsed', 'test')), { average = elapsed/replications })
في الختام ، سأقدم شرحًا للشفرة 5 أعلاه ، والتي اختبرنا بها سرعة العمل.
في البداية ، أنشأنا ثلاث وظائف:
for_fun - دالة تطلب كلمات رئيسية من حسابات متعددة ، وتصنيفها بالتتابع خلال دورة عادية.
dosnow_fun - وظيفة تطلب قائمة من الكلمات الرئيسية في وضع متعدد مؤشرات الترابط ، وذلك باستخدام حزمة doSNOW .
dopar_fun - دالة تطلب قائمة من الكلمات الرئيسية في وضع متعدد مؤشرات الترابط ، وذلك باستخدام حزمة doParallel .
بعد ذلك ، داخل البنية الداخلية ، نقوم بتشغيل الدالة benchmark من حزمة rbenchmark ، وتحديد أسماء الاختبارات (for_cycle ، و dosnow ، و doparallel) ، وكل وظيفة for_fun(logins = logins) ، على التوالي: for_fun(logins = logins) ؛ dosnow_fun(logins = logins) ؛ dopar_fun(logins = logins) .
وسيطة النسخ المتماثل مسؤولة عن عدد الاختبارات ، أي كم مرة سنقوم بتشغيل كل وظيفة.
تتيح لك وسيطة الأعمدة تحديد الأعمدة التي ترغب في تلقيها ، في حالتنا "اختبار" ، و "نسخ متماثلة" ، و "المنقضي" تعني إرجاع الأعمدة: اسم الاختبار ، وعدد الاختبارات ، وإجمالي وقت التنفيذ لجميع الاختبارات.
يمكنك أيضًا إضافة أعمدة محسوبة ، ( { average = elapsed/replications } ) ، أي سيكون الإخراج عبارة عن عمود متوسط يقسم إجمالي الوقت على عدد الاختبارات ، لذلك نحسب متوسط وقت التنفيذ لكل وظيفة.
الترتيب مسؤول عن فرز نتائج الاختبار.
الخاتمة
في هذه المقالة ، من حيث المبدأ ، يتم وصف طريقة عالمية إلى حد ما لتسريع العمل مع واجهة برمجة التطبيقات ، ولكن لكل واجهة برمجة التطبيقات حدودها ، وبالتالي ، على وجه التحديد في هذا النموذج ، مع وجود العديد من سلاسل العمليات ، المثال أعلاه مناسب للعمل مع Yandex.Direct API ، لاستخدامه مع واجهة برمجة التطبيقات من الخدمات الأخرى ، من الضروري في البداية قراءة الوثائق المتعلقة بالحدود في واجهة برمجة التطبيقات لمعرفة عدد الطلبات المرسلة في وقت واحد ، وإلا فقد تحصل على خطأ " Too Many Requests .
استمرار هذا المقال متاح هنا .