
التعلم الآلي يستخدم بنشاط في العديد من مجالات حياتنا. تساعد الخوارزميات في التعرف على إشارات المرور وتصفية الرسائل غير المرغوب فيها والتعرف على وجوه أصدقائنا على Facebook وحتى المساعدة في التداول في البورصات. تتخذ الخوارزمية قرارات مهمة ، لذا عليك التأكد من أنه لا يمكن خداعها.
في هذه المقالة ، وهي الأولى من سلسلة ، سوف نقدم لك مشكلة سلامة خوارزميات التعلم الآلي. هذا لا يتطلب مستوى عالًا من المعرفة بالتعلم الآلي من القارئ ، يكفي أن يكون لديك فكرة عامة عن هذا المجال.
أولاً ، نقدم المصطلحات المستخدمة في موضوع أمان خوارزميات التعلم الآلي:
مثال خصم هو متجه يغذي مدخلات لخوارزمية تنتج عنها الخوارزمية مخرجات غير صحيحة.
الهجوم العدواني - خوارزمية الإجراء التي تهدف إلى الحصول على مثال الخصم.
لفهم مشكلة الأمثلة المعادية ، دعنا نتذكر إحدى مهام التعلم الآلي - التعلم مع معلم في التقدير. في هذه المشكلة ، لدينا أزواج "تسمية كائن" ، ويجب أن نتعلم التنبؤ بقيمة الكائنات الجديدة.
إذا أخذنا في الاعتبار هذه المشكلة من وجهة نظر هندسية ، فمن الضروري تقسيم المسافة بطريقة تنبئ بالفئة "الصحيحة" على الكائن الجديد. علاوة على ذلك ، إذا كان لدينا مجموعة بيانات عامة (على سبيل المثال ، لمجموعة من الأرقام المكتوبة بخط اليد MNIST للحصول على جميع أنواع الصور لجميع الأرقام) ، فيمكن تنفيذ هذه الطائرة التشعبية بشكل مثالي بشرط أن تكون الفئات قابلة للفصل. ولكن نظرًا لعدم وجود عامة السكان في أغلب الأحيان ، لحل هذه المشكلة ، نستخدم خوارزميات التعلم الآلي لتقريب الطائرة المفرطة "المثالية" بأكبر قدر ممكن من الدقة باستخدام البيانات الموجودة لدينا.
أي انحراف للطائرة المفرطة عن المثالية يؤدي إلى "فجوة" معينة ، والتي تصطدم بالأشياء بشكل غير صحيح. هذا هو السبب في ظهور أمثلة مثل الباندا المصنفة كـ gibbon. ويتم تقليل مهمة المهاجم لتغيير متجه معلمات الكائن بحيث يقع في هذه "الفجوة".
أمثلة على الهجمات العدائية
هناك شبكة عصبية تكتشف الوجه في صورة. انها تتكيف بنجاح مع المهمة (الصورة على اليسار). ولكن بعد إضافة القليل من الضوضاء لهذه الصورة (الصورة على اليمين) ، لم تعد الخوارزمية الموجودة في المثال التخاصمي الذي تم الحصول عليه (الصورة في المنتصف) تكتشف الوجه في الصورة.

هذا المثال ، الموضح في مقال " الهجمات العدائية على كاشفات الوجه باستخدام التحسين المقيد القائم على Neural Net " ، مثير للاهتمام لأن العديد من أنظمة التعرف على الوجوه الحقيقية تستخدم نهج الشبكة العصبية لاكتشاف الوجوه. لن يلاحظ الشخص الفرق عند النظر إلى كلتا الصورتين.
تم أخذ المثال التالي من السيارات ، وهي التعرف على إشارة المرور. هذا المثال مثير للاهتمام لأنه لا يجب أن يكون مثال الخصم كائنًا على الأقل قريبًا إلى حد ما من الكائنات التي تم تدريب الشبكة عليها. على سبيل المثال ، في إشارات Rogue: خداع التعرف على إشارة المرور مع الإعلانات والشعارات الضارة ، تم توضيح أن المثال العدائي لإشارة KFC سيتم "التعرف عليه" من قبل الشبكة العصبية الأصلية كعلامة توقف مع احتمال 100 ٪.
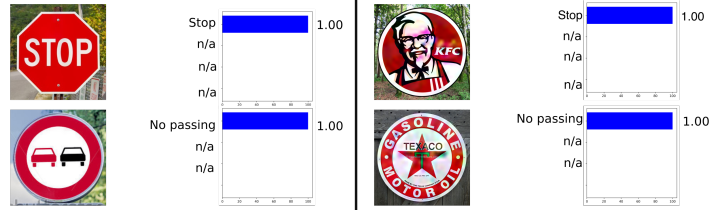
يمكن أن يشك الكثيرون في استخدام أمثلة عدوانية في العالم الواقعي ، حيث تم اختبار الأمثلة السابقة على جهاز كمبيوتر ، بينما في الواقع ، يصعب الحصول على مثل هذا الشيء. لكن هذا ليس كذلك. توليف قوي للخصم أظهرت الأمثلة أنه يمكن طباعة مثال عدائي مصنوع على جهاز كمبيوتر بنجاح على طابعة ثلاثية الأبعاد ، وسوف ترتكب الخوارزمية نفس الأخطاء كما في محاكاة الكمبيوتر.

هنا ترى سلحفاة مطبوعة على طابعة ثلاثية الأبعاد لم يتم التعرف عليها كسلحفاة في أي زاوية.
يوضح المثال التالي ما الذي يمكن فعله إذا تجاوزنا الفهم المعتاد لهجمات الخصوم. وهي ، إعادة برمجة الشبكة المصدر لاستخدام الحمولة الخاصة به. بمعنى آخر ، نتعلم استخدام الشبكة العصبية لشخص آخر لحل المشكلة التي يمثلها المهاجم. على سبيل المثال ، أوضحت إعادة برمجة Adversrial للشبكة العصبية كيف قامت شبكة مدربة على ImageNet بحساب عدد المربعات في صورة بشكل مثالي والتعرف على الأرقام من مجموعة MNIST.
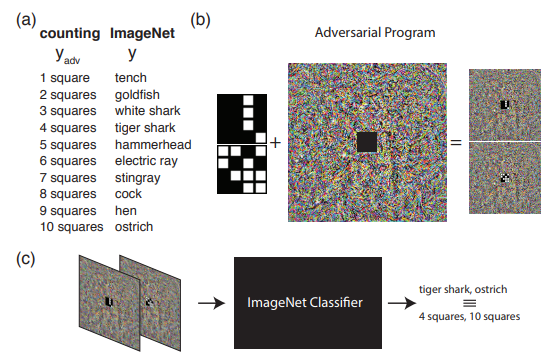
توضح الصورة خوارزمية العمل مع برنامج Adversarial Reprogramming ، الذي يوصى به للتعرف بشكل أفضل في المقالة الأصلية.
في هذه المقالة ، أود أن أتحدث على وجه التحديد عن طرق توليد أمثلة معادية ، وفي المقالة الثانية سننتقل إلى طرق الحماية واختبار خوارزميات التعلم الآلي.
تصنيف الهجوم
يمكن تقسيم جميع الهجمات إلى فئتين: WhiteBox (WB) و BlackBox (BB) . في حالة WB ، نعرف كل المعلومات حول النموذج المدار للخوارزمية ، بينما في حالة BB ، لا يمكننا الوصول إلا إلى مدخلات ومخرجات النموذج. في الواقع ، لا يزال خيار GrayBox ممكنًا عندما لا نعرف المعلومات المتعلقة بالنموذج المدرب ، ولكن هناك معلومات حول نوع الخوارزمية ومعلماته الفوقية. لكن هذا النوع لا يبرز في فصل منفصل ، لأن المعلومات الإضافية ليست كافية للذهاب إلى WB ، مما يعني أن هذه ليست سوى مجموعة إضافية من المعلومات للقيام بهجوم BB.
بعد ذلك ، يجدر تصنيف الهجمات على المستهدفة وغير المستهدفة . الهجمات المستهدفة تعني أن الهجوم يتم في اتجاه معين. على سبيل المثال ، على مجموعة البيانات MNIST ، نقوم بتدريب الشبكة العصبية والتقاط الصورة 0 من مجموعة الاختبار. تنتج الشبكة العصبية المدربة احتمال وجود درجة 0 في 1.00 في هذا الكائن. إذا كنا نريد أن يتم التعرف على مثال الخصومة كفئة 1 بعد تطبيق هجوم الخصومة ، فسنستخدم الهجوم المستهدف. خلاف ذلك ، إذا لم يكن من المهم بشكل خاص بالنسبة لنا إلى أي فئة ستتلقى الشبكة العصبية الصورة (الشيء الرئيسي هو أنها لم تعد فئة 0) ، فسيكون هذا الهجوم غير مستهدف.
بالإضافة إلى ذلك ، يتم تقسيم الهجمات إلى مقياس يتم بموجبه اعتبار كائنين متشابهين - l0،l2،l infty القواعد. l0دولا القاعدة - عدد المعلمات المتغيرة. l2دولا المسافة الإقليدية بين متجهين. l infty الحد الأقصى للعنصر الفرق بين متجهين.
مكتبات بايثون
تتيح لك مكتبات بيانات Python العمل باستخدام أمثلة معادية. هذه هي FoolBox و CleverHans و ART-IBM.
| Foolbox | كليفرهان | ART-IBM |
|---|
| الأطر المدعومة | TensorFlow ، Keras ، Theano ، PyTorch ، لازانيا ، MXNet | TensorFlow ، كراس | TensorFlow ، Keras ، وعد MXNet ، PyTorch |
الآن ، دعونا ننظر إلى الهجمات بمزيد من التفصيل ، ونبدأ بهجمات WhiteBox.
هجوم L-BFGS
يمكن كتابة بيان طريقة L-BFGS على النحو التالي.
تصغير spacec|r|+lossf(x+r،l)
ويترتب على ذلك أننا نريد تقليل وظيفة الخسارة في اتجاه الفئة المستهدفة مع تقييد أن التغييرات المقدمة كانت ضئيلة. في الوقت نفسه ، تم اقتراح حل مثل هذه المشكلة في المقالة الأصلية باستخدام طريقة L-BFGS ، وبالتالي اسم هذا الهجوم.
المقال الأصلي - الخصائص المثيرة للشبكات العصبية
يتم تقديم هذا الهجوم في 2 من 3 مكتبات سبق التعبير عنها - FoolBox و CleverHans.
وتطبيق هذا الهجوم على FoolBox يأخذ 3 أسطر من التعليمات البرمجية في Python:
from foolbox.attacks import LBFGSAttack attack = LBFGSAttack(fmodel) adversarial = attack(image, label)
سيساعدك استخدام L-BFGS في العثور على أفضل الأمثلة للعداء استنادًا إلى القيود الخاصة بك ، ولكن أولاً ، قد يستغرق البحث عن هذا المثال وقتًا طويلًا ، وثانيًا ، من المحتمل تمامًا ألا تتقارب الطريقة ببساطة.
هجوم ختان الإناث
كانت المرحلة التالية من التطوير هي FGSM (طريقة التدرج السريع للإشارة) ، والتي يمكن إظهارها باستخدام الصيغة:
X′=X+ epsilon∗sign( nablaxJ(X،ytrue))
تعمل هذه الطريقة بشكل أسرع من L-BFGS. نحن هنا نأخذ ببساطة العلامات من دالة التدرج لوظيفة الخسارة الأصلية ، بضرب العلامة من قبل البعض epsilon ، أضف إلى الصورة الأصلية.

فيما يلي مثال على كيفية عمل هذه الطريقة. خريطة الضوضاء مع epsilon يساوي 0.007 ، واتضح أن صورة الباندا أصبحت معروفة الآن باسم Gibbon باحتمال قدره 99.3٪
هذه الطريقة سهلة التنفيذ ، ولكن في نفس الوقت ، تكون نتيجة هذه الطريقة صاخبة جدًا.
المقالة الأصلية - شرح وتسخير أمثلة الخصوم
يمكنك العثور على تنفيذ هذه الطريقة في المكتبات ، كما أن استخدام صندوق التوفير لن يستغرق الكثير من الوقت.
from foolbox.attacks import FGSM attack = FGSM(fmodel) adversarial = attack(image, label)
هجوم Deepfool
DeepFool هو أسلوب غير مستهدف. الفرق الرئيسي بينه وبين الأساليب السابقة هو أنه يحاول عمل خريطة ضوضاء بسيطة ، والتي ستخدع الخوارزمية. لا تسمح لك هذه الطريقة بإخراج فصل معين من فصل واحد ، لكن لا تسمح لك بفصل واحد أقرب إلى الصورة الأصلية.

مثال يوضح الصورة الأصلية ، في الخلاصة - طريقة FGSM ، وفي الوسط - مجرد هجوم DeepFool. يمكن ملاحظة أن بطاقة الضوضاء أصغر بكثير من تلك الموجودة في ختان الإناث.
المقال الأصلي - DeepFool: طريقة بسيطة ودقيقة لخداع الشبكات العصبية العميقة
يمكن تنفيذ هذا الهجوم باستخدام أي من المكتبات المدرجة ، والتطبيق على ART-IBM لا يستغرق سوى 3 أسطر من التعليمات البرمجية:
from art.attacks import DeepFool attack = DeepFool(model) img_adv = attack.generate(img)
يعقوب خريطة الهجوم saliency
في طريقة JSMA ، يتم اعتبار مشتق مباشر ، على أساسه يتم إنشاء خريطة متدرجة. على الخريطة ، كل معلمة للكائن في الواقع تتوافق مع مساهمة هذه المعلمة في تغيير النتيجة النهائية للخوارزمية. وبالتالي ، تسمح لك الطريقة بتغيير أقل عدد ممكن من المعلمات في الكائن الذي تمت مهاجمته. وبناء عليه ، فإنه يعمل على l0دولا عادي
المقال الأصلي - حدود التعلم العميق في إعدادات الخصومة
يمكن تنفيذ هذا الهجوم باستخدام CleverHans أو ART-IBM. وعلى CleverHans ، يبدو مثل هذا:
from cleverhans.attacks import SaliencyMapMethod jsma = SaliencyMapMethod(model, sees=sees) jsma_params = { 'theta' : 1., 'gamma' : 0.1, 'clip_min' : 0., 'clip_max' : 1., 'y_target' : None} adv_x = jsma.generate_np(img, **jsma_params)
هجوم بكسل واحد
والسؤال المنطقي هو: ما هو الحد الأدنى لعدد البكسلات التي يجب تغييرها من أجل شن هجوم على الخوارزمية ، وبما أن الكثيرين قد خمنوا بالفعل باسم الهجوم ، يكفي 1 بكسل.

على سبيل المثال ، تصبح صورة الحصان مع تغيير بكسل واحد فقط بمثابة ضفدع باحتمال قدره 99.9٪
المقال الأصلي - هجوم بكسل واحد لخداع الشبكات العصبية العميقة
يتم دعم هذا الهجوم فقط في FoolBox ، ويتم تنفيذه على النحو التالي:
from foolbox.attacks import SinglePixelAttack attack = SinglePixelAttack(fmodel) adversarial = attack(image,max_pixel=1)
تجدر الإشارة هنا ونقول إن تنفيذ الخوارزمية في Foolbox ، بالمقارنة مع المقال الأصلي ، على الرغم من أن له هدفًا مشتركًا (لتغيير عدد معين من وحدات البكسل في الصورة) ، ولكن يختلف في طريقة الحصول على الصورة.
الطرق المعتمدة على تعميم BlackBox Model
تتطلب معظم الطرق فهمًا لكيفية هيكلة بنية النموذج ، ومعرفة القيم الدقيقة لمعلماته ، ولكن هذا نادرًا ما يكون ذلك ممكنًا في الممارسة العملية. وهذا هو سبب ظهور اتجاه هجوم منفصل - هجمات BlacBox / GrayBox. لمثل هذه الهجمات ، يكفي الوصول إلى مدخلات ومخرجات النموذج.
إحدى طرق تنفيذ الهجوم على نموذج BlackBox هي تعميم هذا النموذج على نموذج الطالب (في صورة بديلة).
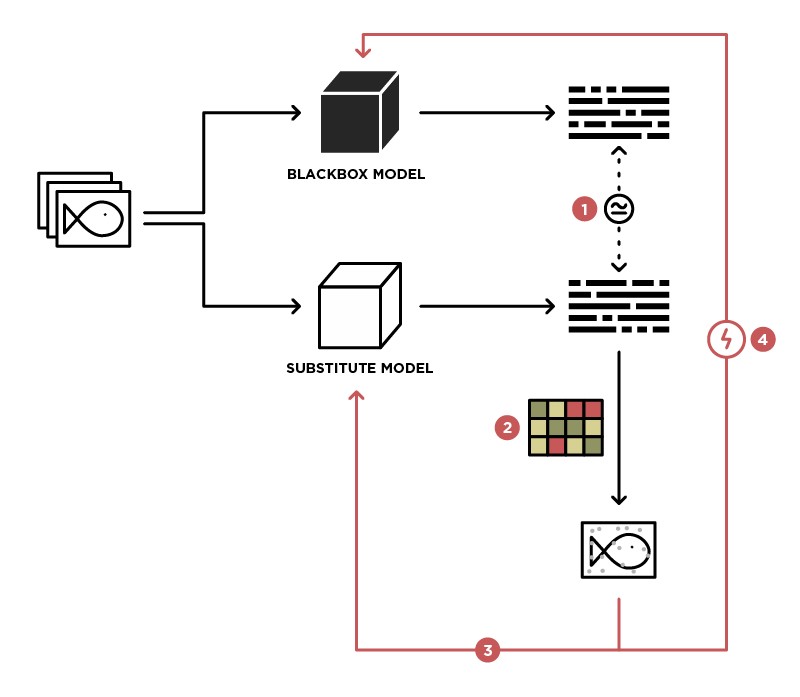
من خلال الوصول إلى إرسال البيانات إلى نموذج BlackBox (المعلم) والوصول إلى إخراج هذا النموذج ، يمكننا إنشاء مجموعة بيانات يمكن من خلالها تدريب نموذجنا الخاص (الطالب) ، وبالتالي تعميم نموذج المعلم. بعد ذلك ، يمكنك استخدام هجوم WhiteBox على نموذج الطالب ، ومع وجود درجة عالية من الاحتمال ، سيحدث هذا الهجوم أيضًا على نموذج المعلم. احتمال وقوع مثل هذا الهجوم هو الأعلى ، والمزيد من المعرفة حول نموذج المعلم لدينا. على سبيل المثال ، نعلم أن نموذج المعلم يعالج الصور ، وغالبًا ما يتم استخدام بنيات مدربة مسبقًا (ResNet ، Inception) مع أوزان ImageNet لمعالجة الصور. استنادًا إلى نموذج الطالب بنفس البنية ، سيتم زيادة احتمال حدوث هجوم ناجح.
المقال الأصلي - هجمات الصندوق الأسود العملية ضد التعلم الآلي
لا يتم تقديم هذه الطريقة في أي من المكتبات وتتطلب تنفيذ نموذج الطالب بشكل مستقل ، ويمكن تنفيذ الهجمات عليها باستخدام الطرق الموضحة أعلاه.
الأساليب المعتمدة على GAN
كانت المرحلة التالية في تطوير هجمات BlackBox هي الهجمات القائمة على تضمين نموذج BlackBox في بنية شبكة الخصوم التوليدية (GAN) ، وهي شبكة تسمح بتوليد كائنات جديدة ، والتي سيتم نقلها لاحقًا إلى طراز Black-Box.
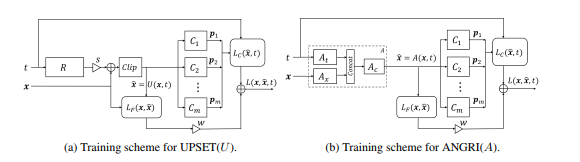
سمحت هذه الطريقة بتوليد أمثلة عدوانية لأي معمارية تقريبًا. كما يتطلب الوصول إلى مدخل وخروج النموذج المهاجم.
اقرأ المزيد حول هذه الطريقة في المقالة الأصلية - UPSET و ANGRI: كسر مصنفات الصور عالية الأداء
كما قد تكون خمنت ، لا يتم تمثيل هذه الطرق في أي من المكتبات.
الخاتمة
في الواقع ، هناك عدد كبير من الهجمات. هذا المقال لا يغطي سوى عدد قليل منهم. نأمل أن تكون هذه المادة قد ساعدت في فهم المفاهيم الأساسية لأمثلة الخصومة وخوارزميات جيلها. للحصول على مراجعة أكثر تفصيلاً ، نوصيك بقراءة المقالات والمواد الأصلية من قائمة المراجع.
نراكم في المقالة التالية ، والتي ستركز على طرق حماية واختبار خوارزميات التعلم الآلي.
المراجع
- تهديدات الهجمات العدوانية على التعلم العميق في رؤية الكمبيوتر: دراسة استقصائية - نظرة عامة رائعة على أساليب الهجوم على خوارزميات التعلم العميق في رؤية الكمبيوتر
- مهاجمة تعلم الآلة باستخدام أمثلة عدائية - مدونة OpenAI مخصصة لأمثلة الخصم
- Awesome Adversarial Machine Learning - github مع روابط لكثير من المواد المفيدة حول مواضيع العدو
- عرض تقديمي حول التعلم الآلي للعداء - عرض تقديمي من مؤتمر MoscowPythonConf2018 حول التعلم الآلي للعداء