مقدمة
في مقال سابق (
"الجزء 2: استخدام كتل Cypress PSoC UDB لتقليل عدد المقاطعات في طابعة ثلاثية الأبعاد" ) ، لاحظت إحدى الحقائق المهمة جدًا: إذا أزال جهاز في UDB البيانات من FIFO بسرعة كبيرة ، فقد تمكنت من ملاحظة الحالة التي تشير إلى وجود جديد لا توجد بيانات في FIFO ، وبعد ذلك يذهب إلى حالة
الخمول الخاطئ. بالطبع ، كنت مهتمًا بهذه الحقيقة. لقد أظهرت النتائج المفتوحة لمجموعة من معارفه. أجاب شخص واحد أن كل هذا كان واضحًا تمامًا ، بل وسمى الأسباب. لم يكن الباقي أقل دهشة مما كنت عليه في بداية البحث. لن يجد بعض الخبراء شيئًا جديدًا هنا ، لكن سيكون من الجيد تقديم هذه المعلومات لعامة الناس حتى يراعيها جميع المبرمجين في ميكروكنترولر.
ليس هذا كان انهيار نوع من التغطية. اتضح أن كل هذا تم توثيقه جيدًا ، ولكن المشكلة هي أنه ليس بشكل رئيسي ، ولكن في مستندات إضافية. وشخصي ، كنت في جهل سعيد ، معتقدًا أن DMA هو نظام فرعي ذكي للغاية يمكنه زيادة كفاءة البرامج بشكل كبير ، حيث يوجد نقل منهجي للبيانات دون تشتيت زيادة التسجيل وتنظيم الدورة إلى نفس الأوامر. بالنسبة لتحسين الكفاءة - كل شيء حقيقي ، ولكن بسبب أشياء مختلفة قليلاً.
لكن أول الأشياء أولا.
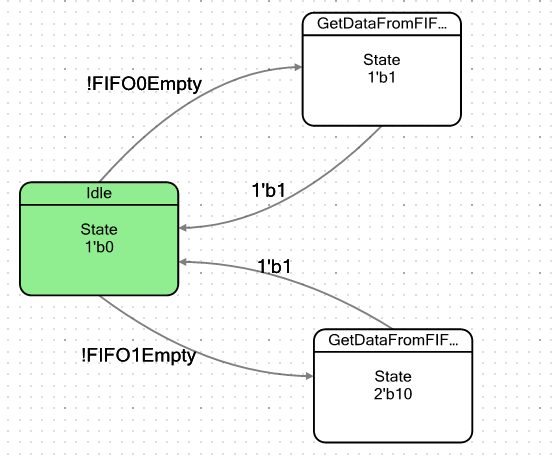
تجارب مع السرو PSoC
لنصنع آلة بسيطة. سيكون لها حالتان مشروطتان: حالة الخمول والحالة التي ستقع فيها عندما يكون هناك بايت واحد على الأقل من البيانات في FIFO. عند الدخول إلى هذه الحالة ، سيأخذ هذه البيانات ببساطة ، ثم يفشل مرة أخرى في حالة راحة. كلمة "مشروطة" لم أذكرها بطريق الخطأ. لدينا FIFOs ، لذلك سأقوم بإنشاء حالتين ، واحدة لكل FIFO ، للتأكد من أنها متطابقة تمامًا في السلوك. تحول رسم بياني الانتقال للجهاز مثل هذا:
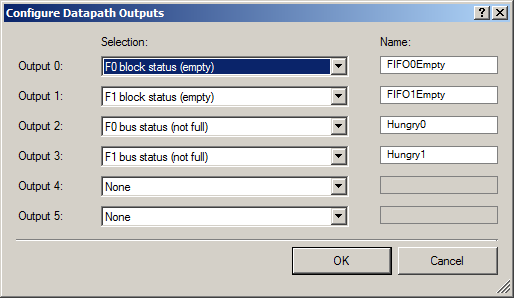
يتم تعريف إشارات الخروج من حالة الخمول كما يلي:
لا تنسَ إرسال بتات رقم الحالة إلى مدخلات Datapath:

إلى الخارج ، نقوم بإخراج مجموعتين من الإشارات: زوج من الإشارات التي تتمتع FIFO بمساحة حرة (حتى يتمكن DMA من بدء تحميل البيانات إليها) ، واثنين من الإشارات التي تكون FIFO فارغة (لعرض هذه الحقيقة على مرسمة الذبذبات).

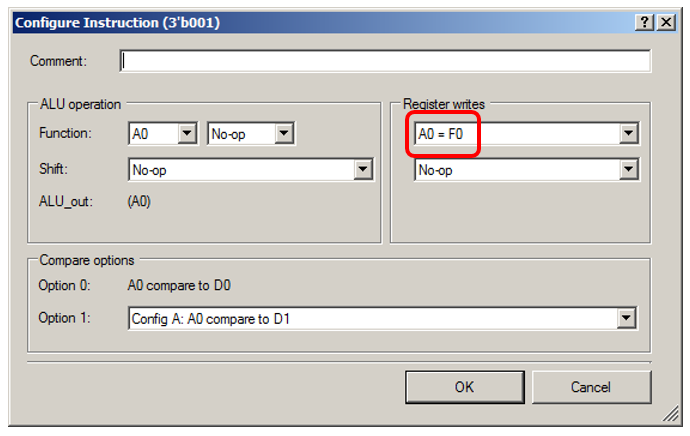
سوف ALU ببساطة تأخذ وهمية من البيانات FIFO:

اسمح لي بعرض تفاصيل الحالة "0001":
قمت أيضًا بتعيين عرض الناقل ، الذي كان في المشروع الذي لاحظت فيه هذا التأثير ، 16 بت:
ننتقل إلى مخطط المشروع نفسه. ظاهريًا ، لا أعطي إشارات تشير إلى أن FIFO فارغة فحسب ، ولكن أيضًا نبضات الساعة. هذا سيسمح لي أن أفعل دون قياسات المؤشر على الذبذبات. يمكنني فقط اتخاذ تدابير بإصبعي.
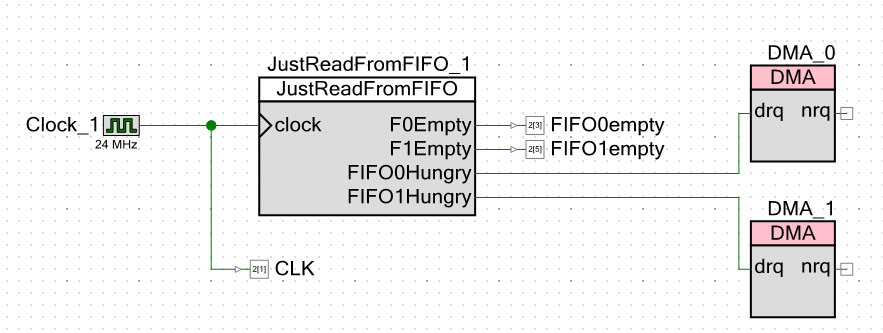
على ما يبدو ، لقد تقدمت سرعة 24 ميجا هرتز. تردد المعالج الأساسي هو نفسه تمامًا. كلما كان التردد أقل ، كان التداخل أقل في الذبذبات الصينية (رسميًا لديه نطاق 250 ميجاهرتز ، ولكن بعد ذلك ميغاهيرتز صيني) ، وسيتم إجراء جميع القياسات فيما يتعلق بنبضات الساعة. مهما كان التردد ، فإن النظام لا يزال يعمل فيما يتعلق بها. كنت سأحدد ميجاهرتز واحد ، لكن بيئة التطوير منعتني من إدخال قيمة تردد أساسية للمعالج أقل من 24 ميجاهرتز.
الآن اختبار الاشياء. للكتابة إلى FIFO0 ، قمت بهذه الوظيفة:
void WriteTo0FromROM() { static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // DMA , uint8 channel = DMA_0_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(JustReadFromFIFO_1_Datapath_1_F0_PTR)); CyDmaChRoundRobin (channel,1); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR / TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)JustReadFromFIFO_1_Datapath_1_F0_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
ترجع كلمة ROM في اسم الوظيفة إلى حقيقة أن الصفيف الذي سيتم إرساله يتم تخزينه في منطقة ROM ، وأن Cortex M3 بهندسة هارفارد. قد تختلف سرعة الوصول إلى ناقل RAM وحافلة ROM ، أردت التحقق من ذلك ، لذلك لدي وظيفة مماثلة لإرسال صفيف من ذاكرة الوصول العشوائي (لا تحتوي مصفوفة
الخطوات على معدل
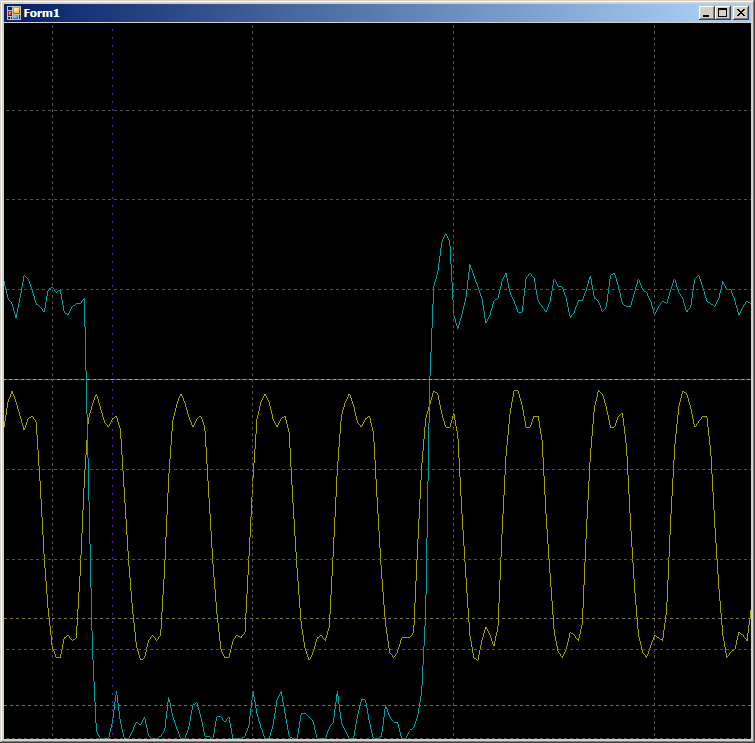
ثابت ثابت في نصها ). حسنًا ، هناك نفس وظائف الإرسال للإرسال إلى FIFO1 ، يختلف سجل المتلقي هناك: ليس F0 ، لكن F1. خلاف ذلك ، جميع وظائف متطابقة. بما أنني لم ألاحظ اختلافًا كبيرًا في النتائج ، فسأنظر في نتائج استدعاء الوظيفة المذكورة أعلاه تمامًا. شعاع أصفر ينبض بالساعة ، خرج أزرق
FIFO0empty .

أولاً ، تحقق من معقولية سبب تعبئة FIFO على مدار دورتين على مدار الساعة. دعونا نرى هذا الموقع بمزيد من التفاصيل:
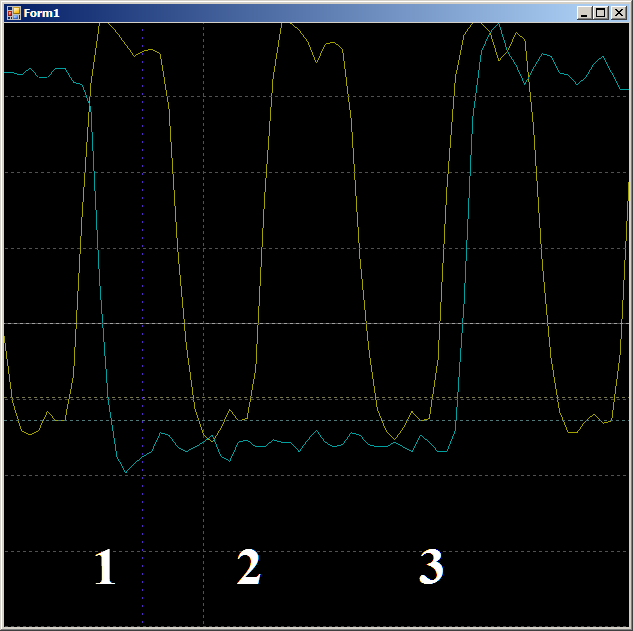
على الحافة 1 ، تقع البيانات في FIFO ، يسقط العلم
FIFO0enmpty . على الحافة 2 ، يدخل
الإكمال التلقائي في حالة
GetDataFromFifo1 . على الحافة 3 ، في هذه الحالة ، يتم نسخ بيانات FIFO إلى سجل ALU ، يتم إفراغ FIFO ، ويتم
رفع علامة
FIFO0 فارغة . بمعنى أن الشكل الموجي يتصرف بشكل معقول ، يمكنك الاعتماد عليه في دورة الساعة. نحصل على 9 قطع.
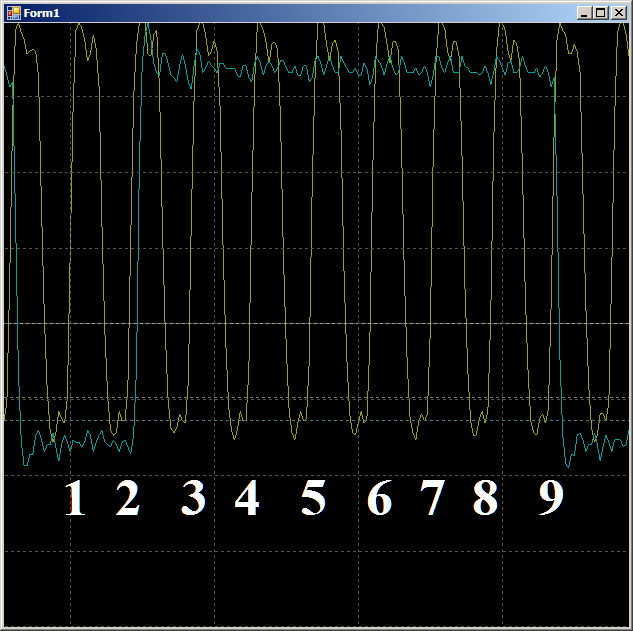 في المجموع ، في المنطقة التي تم فحصها ، يستغرق 9 دورات على مدار الساعة لنسخ كلمة واحدة من البيانات من ذاكرة الوصول العشوائي إلى UDB باستخدام DMA.
في المجموع ، في المنطقة التي تم فحصها ، يستغرق 9 دورات على مدار الساعة لنسخ كلمة واحدة من البيانات من ذاكرة الوصول العشوائي إلى UDB باستخدام DMA.والآن نفس الشيء ، ولكن بمساعدة جوهر المعالج. أولاً ، رمز مثالي يصعب تحقيقه في الحياة الواقعية:
volatile uint16_t* ptr = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; ptr[0] = 0; ptr[0] = 0;
ما سوف يتحول إلى رمز التجميع:
ldr r3, [pc, #8] ; (90 <main+0xc>) movs r2, #0 strh r2, [r3, #0] strh r2, [r3, #0] bn 8e <main+0xa> .word 0x40006898
لا فواصل ، لا دورات إضافية. اثنين من أزواج من التدابير في صف واحد ...
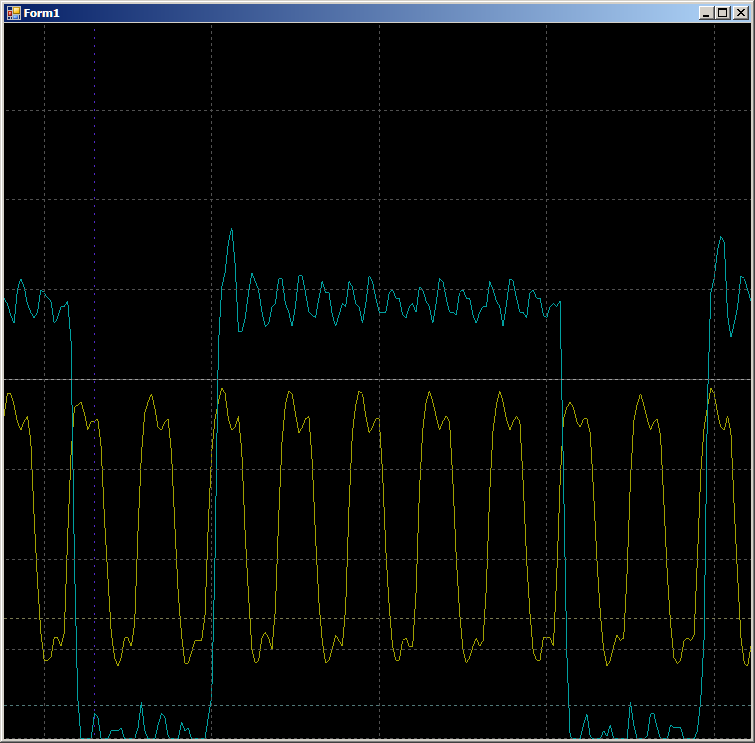
لنجعل الكود أكثر واقعية (مع الحمل العام لتنظيم الدورة وجلب البيانات وزيادة المؤشرات):
void SoftWriteTo0FromROM() { // . // static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; uint16_t* src = steps; volatile uint16_t* dest = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; for (int i=sizeof(steps)/sizeof(steps[0]);i>0;i--) { *dest = *src++; } }
رمز المجمّع المستلم:
ldr r3, [pc, #14] ; (9c <CYDEV_CACHE_SIZE>) ldr r0, [pc, #14] ; (a0 <CYDEV_CACHE_SIZE+0x4>) add.w r1, r3, #28 ; 0x28 ldrh.w r2, [r3], #2 cmp r3, r1 strh r2, [r0, #0] bne.n 8e <main+0xa>
على رسم الذبذبات نرى 7 دورات فقط لكل دورة مقابل تسع في حالة DMA:
قليلا عن الأسطورة
أن نكون صادقين ، بالنسبة لي كان في الأصل صدمة. اعتدت بطريقة ما على الاعتقاد بأن آلية DMA تسمح لك بنقل البيانات بسرعة وكفاءة. 1/9 من تردد الحافلة ليست بهذه السرعة. لكن اتضح أن لا أحد كان يخفيها. تحتوي وثيقة TRM الخاصة بـ PSoC 5LP على عدد من الاعتبارات النظرية ، وتصف الوثيقة "AN84810 - PSoC 3 و PSoC 5LP Advanced DMA Topics" بالتفصيل عملية الوصول إلى DMA. الكمون هو السبب. تأخذ دورة التبادل مع الناقل عددًا معينًا من علامات التجزئة. في الواقع ، هذه التدابير هي التي تلعب دورا حاسما في حدوث تأخير. بشكل عام ، لا أحد يخفي أي شيء ، ولكن عليك أن تعرف هذا.
إذا كان GPIF الشهير المستخدم في FX2LP (بنية أخرى تم تصنيعها بواسطة Cypress) لا يحد من أي شيء ، فإن الحد الأقصى للسرعة هنا يرجع إلى الكمون الذي يحدث عند الوصول إلى الحافلة.DMA تحقق على STM32
لقد تأثرت لدرجة أنني قررت إجراء تجربة على STM32. تم أخذ STM32F103 له نفس المعالج كورتيكس M3 كأرنب تجريبي. لا يحتوي على UDB التي يمكن اشتقاق إشارات الخدمة منها ، لكن من الممكن التحقق من DMA. ما هو GPIO؟ هذه مجموعة من السجلات في مساحة العنوان العامة. هذا جيد نقوم بتكوين DMA في وضع نسخ "الذاكرة - الذاكرة" ، مع تحديد الذاكرة الحقيقية (ROM أو RAM) كمصدر ، وتسجيل بيانات GPIO دون زيادة العنوان كمستقبل. سوف نرسل هناك بالتناوب إما 0 أو 1 ، ونصلح النتيجة مع الذبذبات. للبدء ، اخترت المنفذ B ، وكان من الأسهل الاتصال به على اللوح.

لقد استمتعت حقًا بإحصاء الإجراءات بإصبع وليس مؤشرات. هل من الممكن أن تفعل الشيء نفسه على وحدة التحكم هذه؟ تماما! خذ تردد الساعة المرجعي لذراع الذبذبة من الضلع MCO ، المتصل بمنفذ PA8 على STM32F10C8T6. اختيار مصادر هذه البلورة الرخيصة ليس رائعًا (نفس STM32F103 ، ولكنه أكثر إثارة للإعجاب ، فهو يوفر خيارات أكثر بكثير) ، سنرسل إشارة SYSCLK إلى هذا الإخراج. نظرًا لأنه لا يمكن أن يكون التردد على MCO أعلى من 50 MHz ، فسنخفض سرعة ساعة النظام الإجمالية إلى 48 MHz. سنقوم بضرب تردد كوارتز MHz 8 ليس ب 9 ، ولكن ب 6 (منذ 6 * 8 = 48):

نفس النص: void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct; RCC_ClkInitTypeDef RCC_ClkInitStruct; RCC_PeriphCLKInitTypeDef PeriphClkInit; /**Initializes the CPU, AHB and APB busses clocks */ RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.HSEPredivValue = RCC_HSE_PREDIV_DIV1; RCC_OscInitStruct.HSIState = RCC_HSI_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; // RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL9; RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL6; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { _Error_Handler(__FILE__, __LINE__); }
سنقوم
ببرمجة MCO باستخدام مكتبة
mcucpp في Konstantin
Chizhov (من الآن فصاعدًا
سأجري جميع المكالمات إلى المعدات من خلال هذه المكتبة الرائعة):
// MCO Mcucpp::Clock::McoBitField::Set (0x4); // MCO Mcucpp::IO::Pa8::SetConfiguration (Mcucpp::IO::Pa8::Port::AltFunc); // Mcucpp::IO::Pa8::SetSpeed (Mcucpp::IO::Pa8::Port::Fastest);
حسنًا ، لقد قمنا الآن بتعيين إخراج صفيف البيانات في GPIOB:
typedef Mcucpp::IO::Pb0 dmaTest0; typedef Mcucpp::IO::Pb1 dmaTest1; ... // GPIOB dmaTest0::ConfigPort::Enable(); dmaTest0::SetDirWrite(); dmaTest1::ConfigPort::Enable(); dmaTest1::SetDirWrite(); uint16_t dataForDma[]={0x0000,0x8001,0x0000,0x8001,0x0000, 0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001}; typedef Mcucpp::Dma1Channel1 channel; // dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); // , DMA channel::Init (channel::Mem2Mem|channel::MSize16Bits|channel::PSize16Bits|channel::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); while (1) { } }
إن الشكل الموجي الناتج مشابه جدًا لتلك الموجودة في PSoC.

في الوسط سنام أزرق كبير. هذه هي عملية تهيئة DMA. وردت النبضات الزرقاء على اليسار بحتة بواسطة البرنامج على PB1. تمددهم على نطاق أوسع:

2 تدابير لكل نبضة. تشغيل النظام كما هو متوقع. ولكن الآن دعونا نلقي نظرة على المساحة الأكبر المحددة في الشكل الموجي الرئيسي بخلفية زرقاء داكنة. في هذه المرحلة ، تعمل كتلة DMA بالفعل.
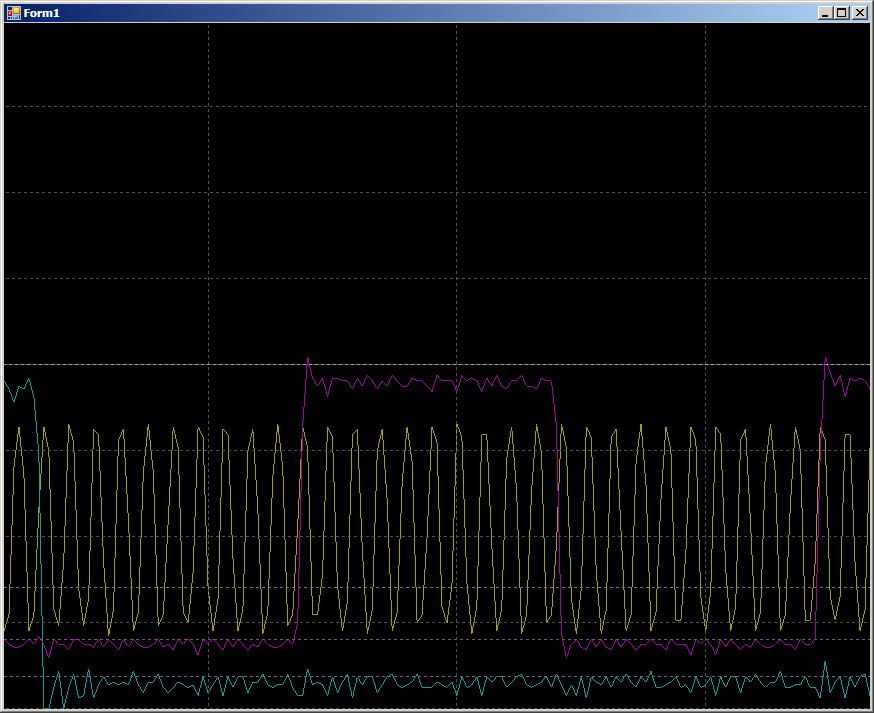
10 دورات لكل تغيير خط GPIO. في الواقع ، يذهب العمل مع ذاكرة الوصول العشوائي ، ويتم تنفيذ البرنامج في دورة ثابتة. لا توجد مكالمات إلى ذاكرة الوصول العشوائي من جوهر المعالج. الحافلة هي تماما تحت تصرف وحدة DMA ، ولكن 10 دورات. لكن في الواقع ، لا تختلف النتائج اختلافًا كبيرًا عن تلك التي تظهر على PSoC ، لذلك فقط ابدأ في البحث عن ملاحظات التطبيق المتعلقة بـ DMA على STM32. كان هناك العديد منهم. يوجد AN2548 على F0 / F1 ، وهناك AN3117 على L0 / L1 / L3 ، وهناك AN4031 على F2 / F4 / F77. ربما هناك بعض أكثر ...
ولكن ، مع ذلك ، نرى منهم هنا ، أيضًا ، الكمون هو السبب. علاوة على ذلك ، فإن وصول مجموعة F103 إلى الحافلة باستخدام DMA أمر مستحيل. إنها ممكنة لـ F4 ، لكن ليس أكثر من أربع كلمات. ثم مرة أخرى سوف تنشأ مشكلة الكمون.
دعونا نحاول تنفيذ نفس الإجراءات ، ولكن بمساعدة سجل البرنامج. أعلاه ، رأينا أن التسجيل المباشر إلى المنافذ يذهب على الفور. لكن كان هناك سجل مثالي. الصفوف:
// dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set();
مع مراعاة إعدادات التحسين هذه (يجب عليك تحديد التحسين للوقت):

تحولت إلى رمز المجمع التالي:
STR r6,[r2,#0x00] MOV r0,#0x20000 STR r0,[r2,#0x00] STR r6,[r2,#0x00]
في النسخ الحقيقية ، ستكون هناك دعوة للمصدر ، إلى المتلقي ، تغيير في متغير الحلقة ، المتفرعة ... بشكل عام ، الكثير من الحمل (الذي ، كما يعتقد ، يلغي DMA فقط). ماذا ستكون سرعة التغييرات في الميناء؟ لذلك ، نكتب:
uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
يتحول رمز C ++ إلى رمز التجميع هذا:
MOVS r1,#0x0E LDRH r3,[r0],#0x02 STRH r3,[r2,#0x00] LDRH r3,[r0],#0x02 SUBS r1,r1,#2 STRH r3,[r2,#0x00] CMP r1,#0x00 BGT 0x080032A8
ونحن نحصل على:
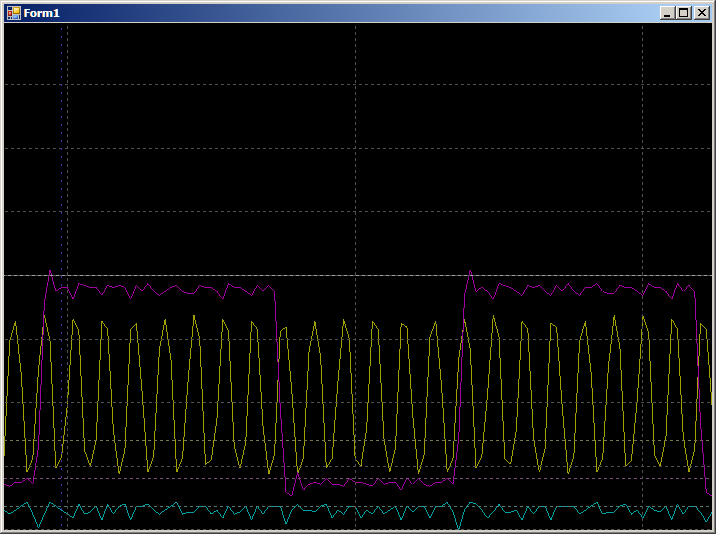
8 تدابير في النصف العلوي من الدورة و 6 في النصف السفلي (راجعت ، تتكرر النتيجة لجميع فترات النصف). نشأ الفرق لأن المحسن قام بعمل نسختين لكل تكرار. لذلك ، يتم إضافة تدبيرين في إحدى الفترات إلى العملية الفرعية.
بمعنى تقريبي ، مع نسخ البرامج ، يتم إنفاق 14 إجراء على نسخ كلمتين مقابل 20 تدبيرا على نفس الشيء ، ولكن بواسطة DMA. النتيجة موثقة تمامًا ، لكنها غير متوقعة للغاية بالنسبة لأولئك الذين لم يقرأوا بعد الأدبيات الممتدة.جيد ولكن ماذا يحدث إذا بدأت في كتابة البيانات في دفقين DMA في وقت واحد؟ كم سرعة ستسقط؟ قم بتوصيل الأشعة الزرقاء بـ PA0 وأعد كتابة البرنامج كما يلي:
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
أولاً ، لنفحص طبيعة النبضات:
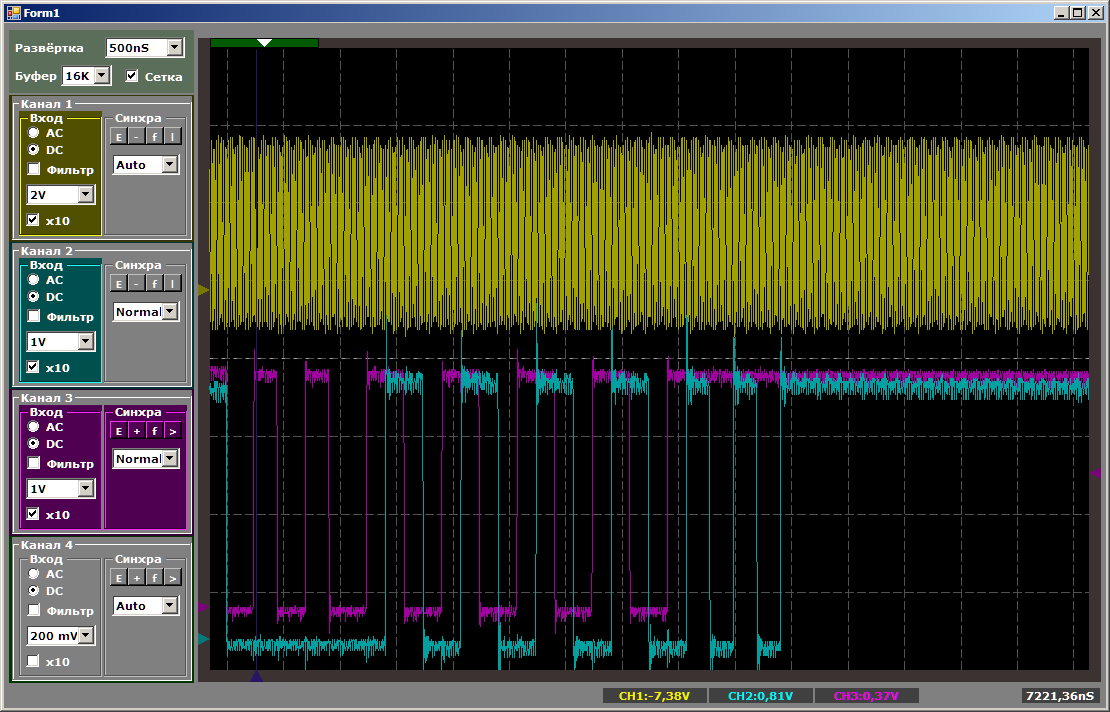
أثناء ضبط القناة الثانية ، تكون سرعة النسخ للأول أعلى. ثم ، عند النسخ في أزواج ، تنخفض السرعة. عند الانتهاء من القناة الأولى ، تبدأ الثانية في العمل بشكل أسرع. كل شيء منطقي ، يبقى فقط لمعرفة مقدار انخفاض السرعة بالضبط.
بينما لا يوجد سوى قناة واحدة ، يستغرق التسجيل من 10 إلى 12 قياسًا (الأرقام تطفو).

أثناء التعاون ، نحصل على 16 دورة لكل سجل في كل منفذ:
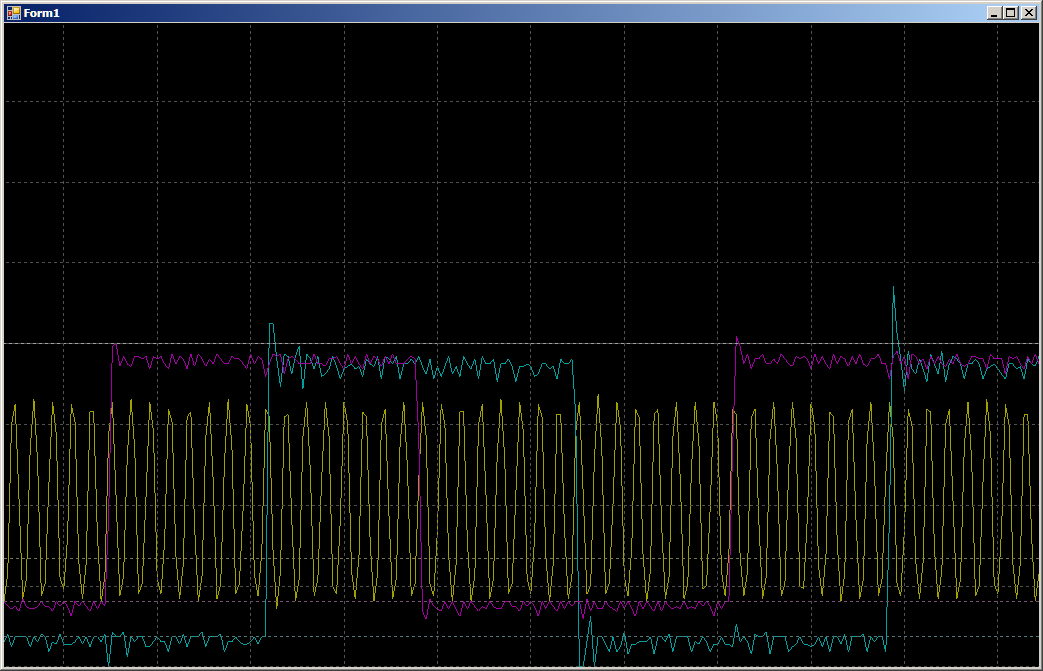
وهذا هو ، ليست سرعة النصف. ولكن ماذا لو بدأت الكتابة في ثلاثة خيوط في وقت واحد؟ نضيف العمل مع PC15 ، نظرًا لأن PC0 لا يتم إخراجه (وهذا هو السبب في عدم إصدار 0 ، 1 ، 0 ، 1 ... ، ولكن 0x0000،0x8001 ، 0x0000 ، 0x8001 ... في الصفيف).
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; typedef Mcucpp::Dma1Channel3 channel3; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2);
النتيجة هنا غير متوقعة لدرجة أنني أطفئ الحزمة التي تعرض تردد الساعة. ليس لدينا وقت للقياسات. نحن ننظر إلى منطق العمل.

حتى تنتهي القناة الأولى من العمل ، لم تبدأ القناة الثالثة في العمل. ثلاث قنوات في نفس الوقت لا تعمل! يمكن استنتاج شيء ما حول هذا الموضوع من AppNote إلى DMA ، حيث يشير إلى أن F103 لديه محركان فقط في كتلة واحدة (ونحن نقوم بنسخ باستخدام كتلة واحدة من DMA ، والثاني هو الخمول الآن ، وحجم المقالة بالفعل بحيث يمكنني استخدامها بالفعل أنا لست كذلك. نعيد كتابة نموذج البرنامج حتى تبدأ القناة الثالثة قبل أي شخص آخر:

نفس النص: // , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
سوف تتغير الصورة على النحو التالي:

تم إطلاق القناة الثالثة ، حتى أنها عملت مع القناة الأولى ، ولكن مع دخول القناة الثانية العمل ، تم استبدال القناة الثالثة حتى اكتمال القناة الأولى.
قليلا عن الأولويات
في الواقع ، ترتبط الصورة السابقة لأولويات DMA ، هناك بعض. إذا كانت جميع قنوات العمل لها نفس الأولوية ، فسيتم تشغيل أرقامها. ضمن أولوية واحدة معينة ، من لديه عدد أصغر هو الذي له الأولوية. دعنا نجرب القناة الثالثة للإشارة إلى أولوية عالمية مختلفة ، ورفعها فوق كل القنوات الأخرى (على طول الطريق ، سنزيد أولوية القناة الثانية أيضًا):

نفس النص: channel3::Init (channel3::PriorityVeryHigh|channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel1::PriorityVeryHigh|channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
الآن أول من اعتاد أن يكون أروع سيكون محروما.
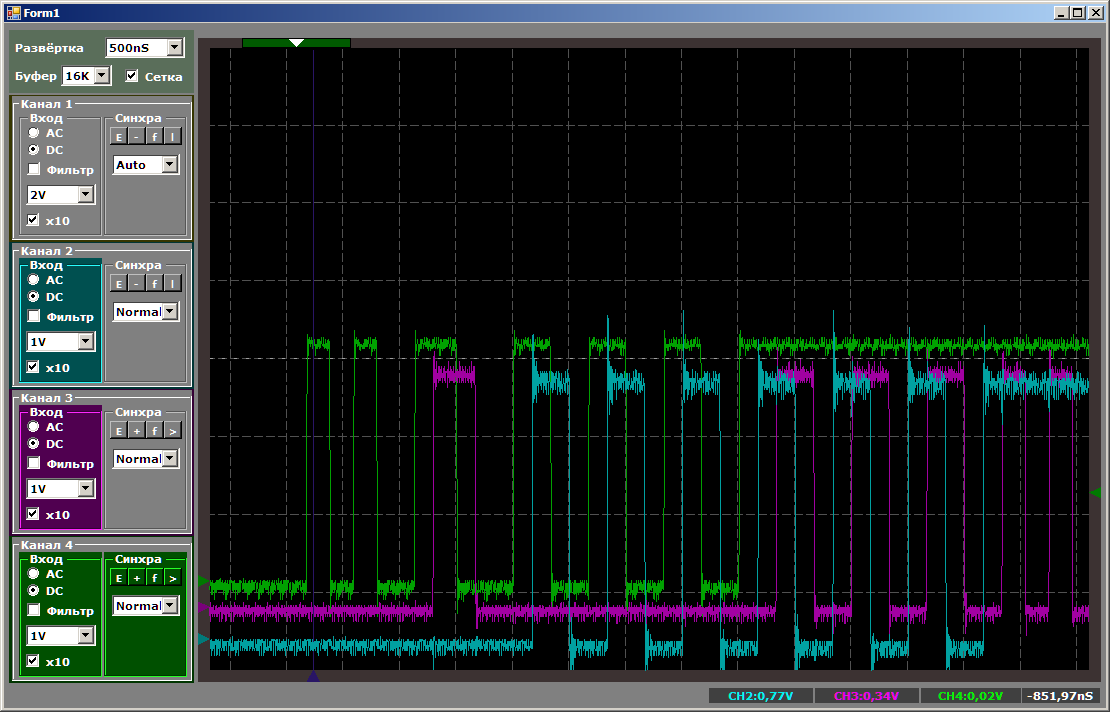
بشكل إجمالي ، نرى أنه حتى في اللعب في الأولويات ، لا يمكن لـ STM32F103 تشغيل أكثر من مؤشر ترابط على كتلة DMA واحدة. من حيث المبدأ ، يمكن تشغيل الخيط الثالث على جوهر المعالج. هذا سوف يسمح لنا بمقارنة الأداء.
// , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
أولاً ، الصورة العامة ، التي توضح أن كل شيء يعمل بشكل متواز وأن نواة المعالج تتمتع بأعلى سرعة نسخ:
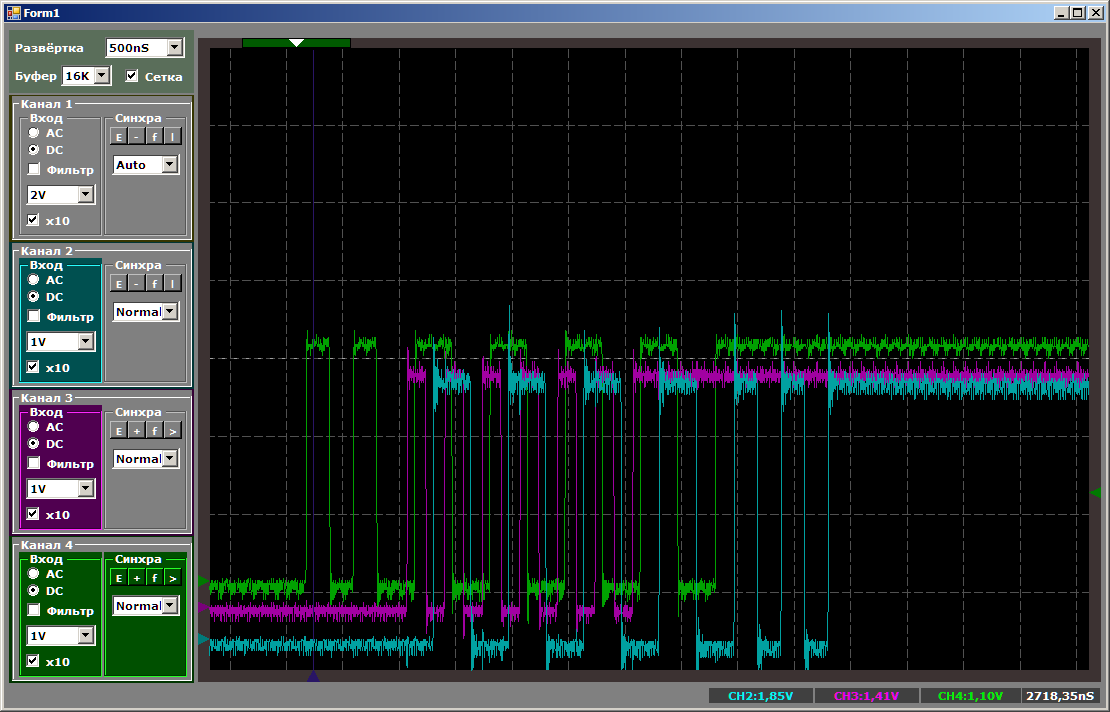
والآن ، سأمنح الجميع الفرصة لحساب الإجراءات في وقت تكون فيه جميع تدفقات النسخ نشطة:
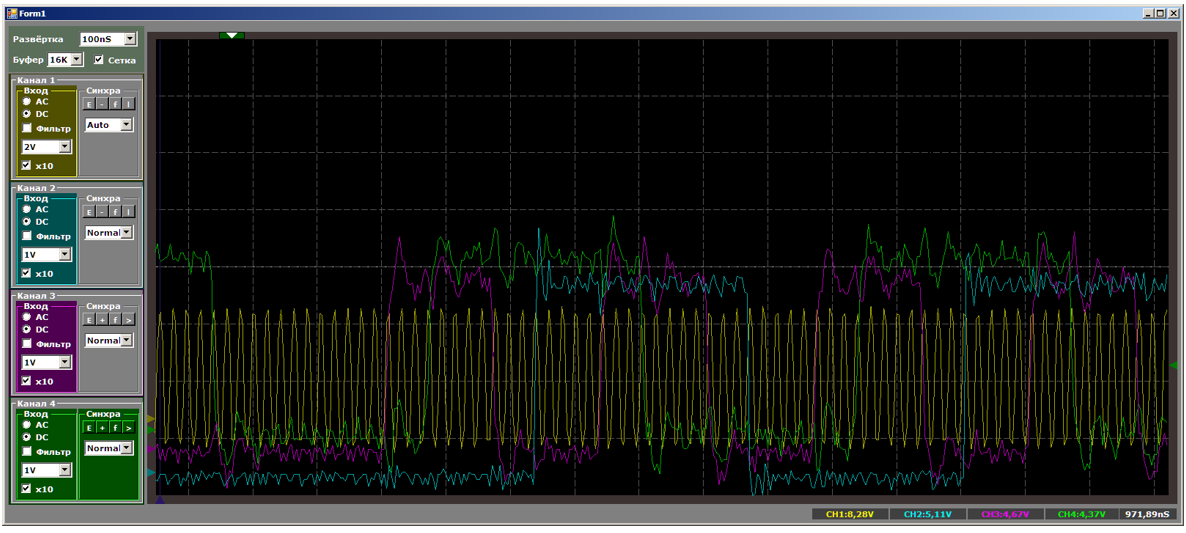
جوهر المعالج يعطي الأولوية لجميع
الآن دعنا نعود إلى حقيقة أنه خلال عملية ذات خيطين ، بينما تم ضبط القناة الثانية ، أعطت الأولى بيانات لعدد مختلف من دورات الساعة. تم توثيق هذه الحقيقة أيضًا بشكل جيد في AppNote على DMA. الحقيقة هي أنه أثناء إعداد القناة الثانية ، يتم إرسال طلبات الوصول إلى ذاكرة الوصول العشوائي (RAM) بشكل دوري ، ويكون لب المعالج أولوية أعلى عند الوصول إلى ذاكرة الوصول العشوائي (RAM) من مركز DMA. عندما طلب المعالج بعض البيانات ، استغرق DMA بعيدا دورات على مدار الساعة ، وتلقى البيانات مع تأخير ، وبالتالي ، يتم نسخها ببطء أكثر. دعونا نفعل التجربة الأخيرة لهذا اليوم. دعنا نجلب العمل إلى واقع أكثر واقعية. بعد بدء DMA ، لن ندخل في دورة فارغة (عندما لا يكون هناك حقًا الوصول إلى RAM) ، ولكننا سنجري عملية نسخ من RAM إلى RAM ، لكن هذه العملية لن تتعلق بتشغيل مراكز DMA:
channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint32_t src1[0x200]; uint32_t dest1 [0x200]; while (1) { uint32_t* src = src1; uint32_t* dest = dest1; for (int i=sizeof(src1)/sizeof(src1[0]);i>0;i--) { *dest++ = *src++; } }

في بعض الأماكن ، امتدت الدورة من 16 إلى 17 قياسًا. كنت خائفة أنه سيكون أسوأ.
البدء في استخلاص النتائج
في الواقع ، ننتقل إلى ما أردت أن أقوله.
سأبدأ من بعيد. قبل بضع سنوات ، بدأت دراسة STM32 ، درست إصدارات MiddleWare for USB التي كانت موجودة في ذلك الوقت وتساءلت عن سبب قيام المطورين بإزالة نقل البيانات من خلال DMA. كان من الواضح أن مثل هذا الخيار في البداية كان في الأفق ، ثم تم إزالته إلى الفناءات الخلفية ، وفي النهاية كانت هناك أساسيات منه. الآن بدأت أشك في أنني أفهم المطورين.
في
المقالة الأولى حول UDB ، قلت إنه على الرغم من أن UDB يمكنه العمل مع البيانات المتوازية ، فمن غير المحتمل أن يحل محل GPIF مع نفسه ، نظرًا لأن حافلة USB PSoC تعمل بسرعة كاملة مقابل السرعة العالية لـ FX2LP. اتضح أن هناك عامل أكثر خطورة الحد. DMA ببساطة ليس لديها الوقت لتسليم البيانات بنفس السرعة التي يوفرها GPIF ، حتى داخل وحدة التحكم ، دون مراعاة ناقل USB.
كما ترون ، لا يوجد كيان واحد DMA. أولاً ، كل مصنع يجعله بطريقته الخاصة. ليس ذلك فحسب ، بل إن منتجًا واحدًا للعائلات المختلفة يمكنه تغيير طريقة بناء DMA. إذا كنت تخطط لتحميل هذه الوحدة على محمل الجد ، فيجب أن تفكر بعناية فيما إذا كان سيتم تلبية الاحتياجات.
ربما ، من الضروري تخفيف التدفق المتشائم بملاحظة متفائلة واحدة. سوف تسليط الضوء عليها حتى.
تسمح لك DMA لوحدات تحكم Cortex M بزيادة أداء النظام وفقًا لمبدأ Javelins الشهير: "التشغيل والنسيان". نعم ، بيانات نسخ البرنامج أسرع قليلاً. ولكن إذا كنت بحاجة إلى نسخ مؤشرات ترابط متعددة ، فلن يتمكن أي مُحسِّن من تشغيل المعالج جميعها دون تحميل حلقات التسجيل وإعادة الدوران. بالإضافة إلى ذلك ، بالنسبة للمنافذ البطيئة ، لا يزال يتعين على المعالج انتظار التوافر ، ويقوم DMA بذلك على مستوى الجهاز.ولكن حتى هنا الفروق الدقيقة المختلفة ممكنة. إذا كان المنفذ بطيئًا نسبيًا ... حسنًا ، على سبيل المثال ، يعمل SPI بأعلى تردد ممكن ، فهناك حالات ممكنة من الناحية النظرية عندما لا يكون لدى DMA وقت لجمع البيانات من المخزن المؤقت ويحدث تجاوز السعة. أو العكس - ضع البيانات في سجل المخزن المؤقت. عندما يكون دفق البيانات واحدًا ، فمن غير المحتمل أن يحدث هذا ، ولكن عندما يكون هناك الكثير منهم ، فقد رأينا ما يمكن أن يحدث في التراكبات المدهشة. للتعامل مع هذا ، يجب عليك تطوير المهام ليس بشكل منفصل ، ولكن مجتمعة. ويحاول المختبرون إثارة مثل هذه المشكلات (مثل هذا العمل المدمر للمختبرين).
مرة أخرى ، لا أحد يخفي هذه البيانات. ولكن لسبب ما ، لا يتم تضمين كل هذا عادة في المستند الرئيسي ، ولكن في ملاحظات التطبيق. لذلك كانت مهمتي هي لفت انتباه المبرمجين إلى حقيقة أن DMA ليس حلا سحريا ، لكنه مجرد أداة مناسبة.
ولكن ، بالطبع ، ليس فقط المبرمجين ، ولكن أيضًا مطوري الأجهزة. لنفترض أنه في مؤسستنا ، يتم تطوير مجموعة كبيرة من البرامج والأجهزة من أجل تصحيح الأخطاء عن بُعد للأنظمة المدمجة. الفكرة هي أن شخصًا ما يقوم بتطوير جهاز ، لكنه يريد طلب "البرامج الثابتة" على الجانب. ولسبب ما ، لا يمكن توفير المعدات إلى الجانب. يمكن أن تكون ضخمة ، يمكن أن تكون باهظة الثمن ، يمكن أن تكون فريدة من نوعها و "تحتاج إليها بنفسك" ، يمكن أن تعمل مجموعات مختلفة معها في مناطق زمنية مختلفة ، مما يوفر نوعًا من العمل متعدد المناوبات ، ويمكن أن يخطر على بالك باستمرار ... بشكل عام ، يمكنك التوصل إلى أسباب الكثير ، مجموعتنا فقط ترك هذه المهمة لأسفل أمرا مفروغا منه.
وفقًا لذلك ، يجب أن يكون مجمع تصحيح الأخطاء قادرًا على محاكاة أكبر عدد ممكن من الأجهزة الخارجية ، بدءًا من المحاكاة التافهة لمطابع الأزرار إلى بروتوكولات SPI و I2C و CAN و 4-20 مللي أمبير وغيرها من الأشياء الأخرى ، حتى يتمكن المحاكيون من خلالهم من إعادة إنشاء سلوكيات خارجية مختلفة الكتل المتصلة بالمعدات التي يتم تطويرها (قمت شخصيا في وقت واحد بالكثير من أجهزة المحاكاة لتصحيح الأخطاء الأرضية لمرفقات طائرات الهليكوبتر ، على موقعنا
يتم البحث عن الحالات ذات الصلة من خلال كلمة Cassel Aero ).
وهكذا ، في المتطلبات الفنية لتطوير بعض المتطلبات. الكثير من SPI ، I2C ، الكثير من GPIO. يجب أن تعمل في مثل هذه الترددات القصوى ومثل هذه. يبدو أن كل شيء واضح. نضع STM32F4 و ULPI للعمل مع USB في وضع HS. ثبت التكنولوجيا. ولكن هنا يأتي عطلة نهاية أسبوع طويلة مع عطلات نوفمبر ، والتي اكتشفت مع UDB. رؤية شيء ما كان خطأ ، حصلت في الأمسيات على النتائج العملية التي قدمت في بداية هذا المقال. وأدركت أن كل شيء ، بالطبع ، شيء رائع ، لكن ليس لهذا المشروع. كما أشرت بالفعل ، عندما يقترب أقصى أداء ممكن للنظام من الحد الأعلى ، ينبغي تصميم كل شيء بشكل منفصل ، ولكن بشكل مجمع.
ولكن هنا لا يمكن أن يكون التصميم المتكامل للمهام من حيث المبدأ.
نحن نعمل اليوم مع جهاز واحد تابع لجهة خارجية ، غدًا - مختلف تمامًا. سيتم استخدام الحافلات من قبل المبرمجين لكل حالة مضاهاة حسب تقديرهم. لذلك ، تم رفض الخيار ، تم إضافة عدد من جسور FTDI المختلفة إلى الدائرة. داخل الجسر ، سيتم حل وظيفة أو وظيفتين أو أربع وفقًا لنظام صارم ، وبين الجسور سيحل مضيف USB كل شيء. للأسف DMA. , , , , – , .
. DMA (, 10: 1 , , 1 , 10 ) .