
"2048" في غضون بضعة أسابيع يصادف 5 سنوات ، مما يعني أن الوقت قد حان لكتابة شيء مخصص لهذه اللعبة الرائعة.
موضوع لعبة مستقلة عن الذكاء الاصطناعي في اللغز هو بالمعلومات بشكل خاص. هناك مجموعة متنوعة من الطرق لتنفيذه ، وسنقوم اليوم بتحليل طريقة سهلة نسبيًا. وهي سنعمل على تعليم عقل الكمبيوتر لجمع درجات علمية باستخدام طريقة مونت كارلو.

كُتب هذا المقال بدعم من EDISON Software ، وهي شركة تقوم بتطوير تطبيقات الهاتف المحمول وتوفر خدمات اختبار البرمجيات .
كان مصدر إلهام هذا العمل هو مناقشة حول stackoverflow ، حيث
اقترح الرجال الأذكياء طرقًا فعالة لعبة كمبيوتر . على ما يبدو ، فإن أفضل طريقة هي طريقة minimax مع لقطة ألفا بيتا وفي غضون يومين ، سيتم تخصيص المنشور التالي لها.
طريقة كازينو المقترحة من قبل المستخدم stackoverflow
 روننز
روننز كجزء من المناقشة أعلاه. القسم التالي بأكمله هو ترجمة من نشره.
طريقة مونت كارلو
لقد أصبحت مهتمًا بفكرة الذكاء الاصطناعى لهذه اللعبة ، حيث
لا يوجد ذكاء مشفر (أي أنه لا يوجد استدلال ، سجل ، إلخ). يجب أن "تعرف" فقط قواعد اللعبة و "تفهم" اللعبة. هذا يميزها عن معظم الذكاء الاصطناعى (كما هو الحال في هذا الموضوع) ، لأن اللعبة ، في الواقع ، هي القوة الغاشمة التي تسيطر عليها وظيفة التهديف ، مما يعكس الفهم الإنساني للعبة.
خوارزمية الذكاء الاصطناعى
لقد وجدت خوارزمية لعبة بسيطة ولكنها جيدة بشكل مدهش: لتحديد الخطوة التالية لحالة معينة من المجال ، تلعب لعبة الذكاء الاصطناعي اللعبة في ذاكرة الوصول العشوائي ،
وتقوم بحركات عشوائية حتى تنتهي اللعبة بالهزيمة. يتم ذلك عدة مرات ، مع تتبع النتيجة النهائية. ثم ، يتم حساب متوسط النتيجة النهائية مع الأخذ بعين الاعتبار الدورة الأولية. يتم تحديد الخطوة الأولية التي أظهرت أعلى متوسط نتيجة كحركة تم اختيارها بالفعل.
مع 100 تشغيل لكل منعطف أولي ، تحصل AI على التجانب 2048 في 80٪ من الحالات والبلاطة 4096 في 50٪ من الحالات. عند استخدام 10000 عملية ، يتم الحصول على 2048 في 100 ٪ من الحالات ، و 70 ٪ لمدة 4096 وحوالي 1 ٪ ل 8192.
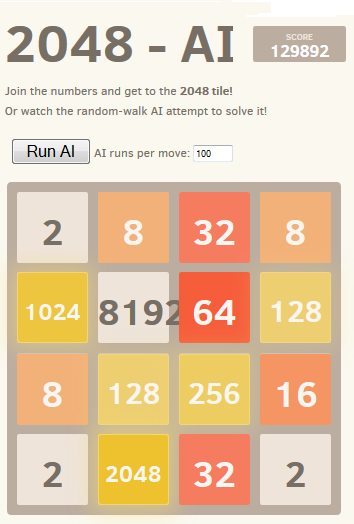 عرض في العمل
عرض في العملتظهر أفضل النتائج المحققة في لقطة الشاشة:
حقيقة مثيرة للاهتمام لهذه الخوارزمية هي أنه على الرغم من أنه من المتوقع أن تكون الألعاب ذات الحركات التي يتم تنفيذها بشكل عشوائي سيئة للغاية ، ومع ذلك ، فإن اختيار أفضل (أو الأقل سيئة ، إذا كنت تحب) يؤدي إلى لعب جيد للغاية: يمكن أن تحقق لعبة Monte Carlo AI النموذجية 70،000 لعبة نقاط لـ 3000 حركة ، لكن الألعاب التي توجد بها لعبة تعسفية في الذاكرة من أي موضع معين توفر في المتوسط 340 نقطة إضافية لنحو 40 حركة إضافية قبل الخسارة. (يمكنك التحقق من ذلك بنفسك عن طريق بدء تشغيل AI وفتح وحدة التحكم في التصحيح.)
يوضح هذا الرسم البياني هذا المفهوم: يوضح الخط الأزرق درجة اللعبة بعد كل خطوة. يُظهر الخط الأحمر
أفضل نتيجة للخوارزمية ، حيث يقوم بتحركات بشكل تعسفي من هذا الموضع إلى نهاية اللعبة. في الواقع ، فإن القيم الحمراء "تسحب" القيم الزرقاء للأعلى ، لأنها أفضل الجمل في الخوارزمية. ومن المثير للاهتمام ، أن الخط الأحمر أعلى قليلاً من الخط الأزرق في كل نقطة ، لكن الخط الأزرق يقلل الفجوة أكثر فأكثر.
أجد أنه من المستغرب أن الخوارزمية لا تتوقع بالضرورة طريقة لعب جيدة ، ومع ذلك تختار الحركات التي تنتجها (عملية جيدة).
اكتشفت لاحقًا أن هذه الطريقة يمكن تصنيفها
كخوارزمية بحث عن شجرة مونتي كارلو .
التنفيذ والروابط
أولاً ، قمت بإنشاء إصدار JavaScript يمكن
رؤيته أثناء العمل هنا . هذا الإصدار قادر على تشغيل 100 تشغيل في فترة زمنية معقولة. افتح وحدة التحكم لمزيد من المعلومات. (
المصدر )
في وقت لاحق ، للتجول ، استخدمت البنية التحتية المحسنة للغايةnneonneo ونفذت الإصدار الخاص بي في الإصدار C ++. يسمح هذا الإصدار بما يصل إلى 100،000 تشغيل في كل مرة وحتى 1،000،000 إذا كنت مستعدًا للانتظار. وشملت تعليمات التجميع. كل شيء يعمل في وحدة التحكم ، ولديه أيضًا جهاز تحكم عن بعد للتشغيل في إصدار الويب. (
المصدر )
النتائج
والمثير للدهشة أن الزيادة في عدد مرات التشغيل لا تؤدي إلى تحسين طريقة اللعب بشكل أساسي. يبدو أن هذه الإستراتيجية لها حدًا قدره 80،000 نقطة مع حد أقصى قدره 4096 نقطة ، وكل النتائج الأصغر قريبة جدًا من الوصول إلى الرقم 8192. تزيد الزيادة في عدد مرات التشغيل من 100 إلى 100000 فرصة للوصول إلى هذا الحد (من 5٪ إلى 40٪) ، لكن ليس يتغلب عليه.
إن أداء 10000 رهان مع زيادة مؤقتة تصل إلى 1،000،000 بالقرب من المواقع الحرجة قد مكّن من التغلب على هذا الحاجز في أقل من 1٪ من الحالات مع الحد الأقصى لعدد النقاط التي سجلت 129892 والبلاطات 8192.
التحسينات والتحسينات
بعد تنفيذ هذه الخوارزمية ، جربت العديد من التحسينات ، بما في ذلك استخدام الحد الأدنى أو الحد الأقصى من التصنيفات أو مجموعة من القيم الدنيا والحد الأقصى والمتوسط. حاولت أيضًا استخدام العمق: بدلاً من محاولة إكمال تشغيلات K في كل دور ، حاولت تجربة K في قائمة الحركات بطول معين (على سبيل المثال ، "أعلى ، أعلى ، يسار") واخترت الخطوة الأولى من قائمة التحركات مع أفضل فوز.
بعد ذلك ، قمت بتنفيذ شجرة نقاط تأخذ في الاعتبار الاحتمال الشرطي بأنه سيكون قادرًا على إكمال الحركة بعد قائمة معينة من التحركات.
ومع ذلك ، فإن أيا من هذه الأفكار أظهرت ميزة حقيقية على فكرة أولى بسيطة. تركت علق كود لهذه الأفكار في مصدر C ++.
لقد أضفت آلية Deep Search ، التي زادت مؤقتًا عدد مرات التشغيل إلى 1،000،000 عندما تمكنت أي من عمليات التشغيل عن طريق الخطأ من الوصول إلى أعلى مستوى تالي. هذا أدى إلى تحسن في أداء الوقت.
سأكون مهتمًا بمعرفة ما إذا كان لدى أي شخص أية أفكار تحسين أخرى تدعم استقلالية الذكاء الاصطناعى عن مجال الموضوع؟
خيارات واستنساخ 2048
من أجل المتعة ، قمت أيضًا بتطبيق AI كإشارة مرجعية ، وربطه بعناصر تحكم اللعبة. يتيح لك هذا العمل مع كل من اللعبة الأصلية والعديد من أشكالها.
هذا ممكن نظرًا لطبيعة AI المستقلة عن المجال. بعض الخيارات أصلية تمامًا ، مثل استنساخ سداسي.
2048.xlsm
يمكن تنزيل تطبيق Excel نفسه
من Google .
الصورة قابلة للنقر - سيتم فتح صورة بالحجم الكامل.
لفترة وجيزة على واجهة ووظائف التطبيق.
لبدء اللعب ، تحتاج إلى النقر على زر "
المستخدم: بدء اللعبة ". عندما تضغط على هذا الزر مرة أخرى ، يتغير النقش من "
المستخدم: ابدأ اللعبة " إلى "
المستخدم: إنهاء اللعبة " والعكس ، أي يمكنك في أي وقت إيقاف اللعبة ثم تشغيلها مرة أخرى. عندما تتوقف اللعبة ، يمكنك تغيير المحاذاة يدويًا في الميدان ، أو تحسين وضعك أو تفاقمه من أجل اختبار بعض الأفكار أو التحقق منها.
أثناء اللعبة نفسها ، يمكنك اتخاذ خطوات بطريقتين:
- لوحة المفاتيح: ببساطة عن طريق الضغط على مفاتيح "أعلى" ، "لأسفل" ، "يسار" ، "يمين".
- باستخدام الماوس: النقر فوق الخلايا ذات الأسهم الكبيرة التي تشير إلى الاتجاه المطلوب.
زر "
حقل جديد " يمسح الملعب ويضع عشوائيًا "اثنين" و "أربعة" عليه.
الشيء الأكثر إثارة للاهتمام هو أنه تم تنفيذ طريقة مونت كارلو ، بالضبط في الشكل الذي اقترحه المتأنق مع stackoverflow. في كل موقف ، يمر الكمبيوتر في الذاكرة بفروع عشوائية لكل حركة أولى ("أعلى" ، "أسفل" ، "يسار" ، "يمين") حتى يؤدي إلى الخسارة. إحصائيا ، يتم تمييز الاتجاه الأكثر ملاءمة باللون الأحمر في جدول خاص أدناه. يمكنك استخدامه بمثابة تلميح إذا رأيت أن لعبتك في مأزق وتحتاج إلى إنقاذ نفسك بطريقة أو بأخرى. ؛)
فوق الجدول توجد مربعات اختيار مع خيارات التحليل. في الوقت الحالي ، تم تحديد Monte Carlo فقط ، وستتم إضافة الباقي في الأيام القادمة (نتيجة لذلك سيكون هناك المزيد من harastas مع تحديث تطبيق excel وشروحات النظرية).
هناك أيضا
AI: زر
اللعبة . من خلال النقر فوقه ، سيقوم مساعد الكمبيوتر بإجراء خطوة واحدة وفقًا لطريقة مونت كارلو أو طريقة أخرى محددة في مجموعة المحولات (ستعمل الشبكة المصغرة والشبكة العصبية في هذه القائمة لاحقًا).
جميع المواد من سلسلة AI و 2048