لقد استخدمت الألعاب لعقود من الزمن كواحدة من الطرق الرئيسية لاختبار وتقييم نجاح أنظمة الذكاء الاصطناعي. مع نمو الفرص ، بحث الباحثون عن ألعاب تتسم بالتعقيد المتزايد باستمرار ، مما يعكس عناصر التفكير المختلفة اللازمة لحل المشكلات العلمية أو التطبيقية في العالم الواقعي. في السنوات الأخيرة ، تُعتبر StarCraft واحدة من أكثر استراتيجيات الوقت الفعلي تنوعًا وتعقيدًا وواحدة من أكثر الاستراتيجيات شعبية على الساحة الإلكترونية في التاريخ ، وأصبحت StarCraft الآن التحدي الرئيسي لبحوث الذكاء الاصطناعي.
AlphaStar هو أول نظام ذكاء اصطناعي قادر على هزيمة أفضل اللاعبين المحترفين. في سلسلة من المباريات التي جرت في 19 ديسمبر ، فاز AlphaStar بفوز ساحق على Grzegorz Komincz (مانا) من فريق
Liquid ، أحد
أقوى اللاعبين في العالم ، بنتيجة 5: 0. قبل ذلك ، لعبت مباراة مظاهرة ناجحة ضد زميله داريو ونش (
TLO ). نظمت المباريات وفقًا لجميع القواعد الاحترافية على
بطاقة البطولة الخاصة ودون أي قيود.
على الرغم من النجاحات الكبيرة التي تحققت في ألعاب مثل
Atari و
Mario و
Quake III Arena و
Dota 2 ، حارب فنيو الذكاء الاصطناعى دون جدوى تعقيد StarCraft.
تم تحقيق أفضل
النتائج من خلال إنشاء العناصر الأساسية للنظام يدويًا ، عن طريق فرض قيود متنوعة على قواعد اللعبة ، أو بتزويد النظام بقدرات خارقة ، أو باللعب على خرائط مبسطة. لكن حتى هذه الفروق الدقيقة جعلت من المستحيل الاقتراب من مستوى اللاعبين المحترفين. على عكس ذلك ، تلعب لعبة AlphaStar لعبة كاملة باستخدام شبكات عصبية عميقة ، يتم تدريبها على أساس بيانات اللعبة الأولية ، باستخدام طرق
التدريس مع المعلم والتعلم مع التعزيز .
التحدي الرئيسي
StarCraft II هو عالم خيالي خيالي مع لعبة غنية متعددة المستويات. جنبا إلى جنب مع الإصدار الأصلي ، هذه هي اللعبة الأكبر والأكثر نجاحًا في كل العصور ، والتي خاضتها في البطولات لأكثر من 20 عامًا.

هناك طرق عديدة للعب ، لكن الأكثر شيوعًا في الألعاب الإلكترونية هي البطولات الفردية التي تتكون من 5 مباريات. للبدء ، يجب على اللاعب اختيار واحد من ثلاثة سباقات - zergs أو protoss أو terrans ، لكل منها خصائصه وقدراته الخاصة. لذلك ، غالباً ما يتخصص اللاعبون المحترفون في سباق واحد. يبدأ كل لاعب بعدة وحدات عمل تستخرج موارد لبناء المباني أو الوحدات الأخرى أو تطوير التكنولوجيا. هذا يسمح للاعب بالاستيلاء على الموارد الأخرى ، وبناء قواعد أكثر تطوراً وتطوير قدرات جديدة للتغلب على الخصم. للفوز ، يجب على اللاعب موازنة صورة الاقتصاد الكلي بدقة ، والتي تسمى "الماكرو" ، والتحكم في المستوى المنخفض للوحدات الفردية ، والتي تسمى "الجزئي".
تشكل الحاجة إلى تحقيق التوازن بين الأهداف القصيرة الأجل والطويلة الأجل والتكيف مع المواقف غير المتوقعة تحديًا كبيرًا للأنظمة التي تتحول في الواقع إلى أنها غير مرنة تمامًا. يتطلب حل هذه المشكلة طفرة في العديد من مجالات الذكاء الاصطناعى:
The Game Theory : StarCraft هي لعبة حيث ، مثل "Stone، Scissors، Paper" ، ليست هناك استراتيجية فردية. لذلك ، في عملية التعلم ، يجب أن تستكشف منظمة العفو الدولية باستمرار وتوسع آفاق معرفتها الاستراتيجية.
معلومات غير كاملة : على عكس لعبة الشطرنج أو الذهاب ، حيث يرى اللاعبون كل ما يحدث ، في StarCraft غالباً ما تكون المعلومات المهمة مخفية ويجب استخلاصها بنشاط من خلال الذكاء.
التخطيط طويل الأجل : كما هو الحال في المهام الواقعية ، قد لا تكون علاقات السبب والنتيجة فورية. يمكن أن تدوم اللعبة أيضًا ساعة أو أكثر ، وبالتالي فإن الإجراءات التي يتم تنفيذها في بداية اللعبة قد لا يكون لها أي أهمية على المدى الطويل.
الوقت الحقيقي : على عكس ألعاب الطاولة التقليدية ، حيث يتناوب المشاركون بدورهم ، في StarCraft ، يقوم اللاعبون بأعمالهم بشكل مستمر ، إلى جانب مرور الوقت.
مساحة عمل ضخمة : يجب مراقبة المئات من الوحدات والمباني المختلفة في وقت واحد ، في الوقت الفعلي ، مما يوفر مساحة اندماجية هائلة حقًا من الفرص. بالإضافة إلى ذلك ، فإن العديد من الإجراءات هي هرمية ويمكن أن تتغير وتستكمل على طول الطريق. توفر المعلمة الخاصة بنا للعبة ما متوسطه حوالي 10 إلى 26 إجراء لكل وحدة زمنية.
في ضوء هذه التحديات ، أصبح StarCraft تحديا كبيرا للباحثين منظمة العفو الدولية. جذور
مسابقتي StarCraft و StarCraft II جذورهما في إطلاق
BroodWar API في عام 2009. من بينها
مسابقة AIIDE StarCraft AI و
CIG StarCraft Competition و
Student StarCraft AI Tournament و
Starcraft II AI Ladder .
ملاحظة : في عام 2017 ، نشرت PatientZero على Habré ترجمة ممتازة لـ " تاريخ مسابقات الذكاء الاصطناعى في Starcraft ".لمساعدة المجتمع في
استكشاف هذه المشكلات بشكل أكبر ، قمنا ،
بالتعاون مع Blizzard في عامي 2016 و 2017 ، بنشر
مجموعة أدوات PySC2 ، والتي تضم أكبر مجموعة من عمليات إعادة النشر المجهولة التي تم نشرها على الإطلاق. بناءً على هذا العمل ، قمنا بدمج إنجازاتنا الهندسية والخوارزمية لإنشاء AlphaStar.
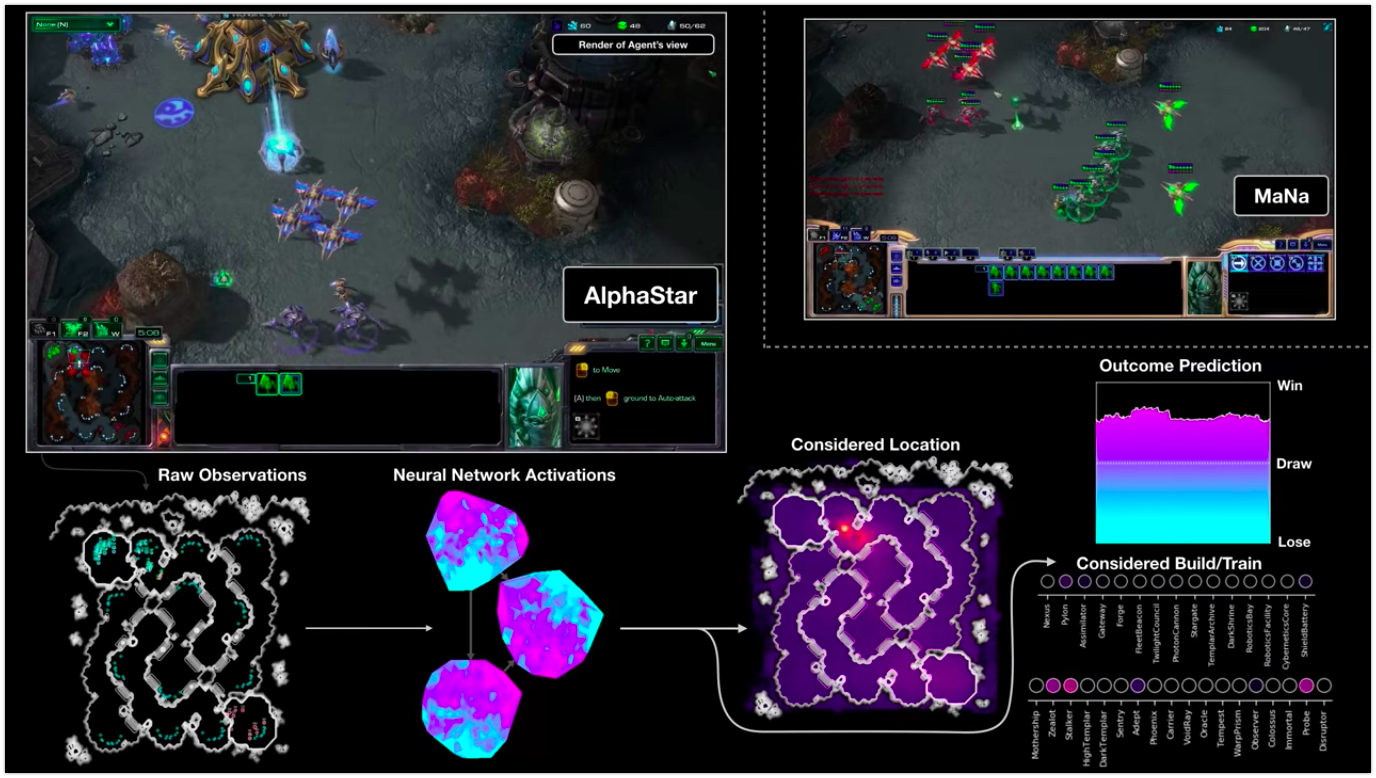
 تصور AlphaStar أثناء القتال ضد MNa ، يوضح اللعبة بالنيابة عن الوكيل - البيانات الأولية المرصودة ، نشاط الشبكة العصبية ، بعض الإجراءات المقترحة والإحداثيات المطلوبة ، وكذلك النتيجة التقديرية للمباراة. يتم عرض طريقة عرض اللاعب MaNa أيضًا ، لكن بالطبع ، لا يمكن الوصول إليه من قبل الوكيل.
تصور AlphaStar أثناء القتال ضد MNa ، يوضح اللعبة بالنيابة عن الوكيل - البيانات الأولية المرصودة ، نشاط الشبكة العصبية ، بعض الإجراءات المقترحة والإحداثيات المطلوبة ، وكذلك النتيجة التقديرية للمباراة. يتم عرض طريقة عرض اللاعب MaNa أيضًا ، لكن بالطبع ، لا يمكن الوصول إليه من قبل الوكيل.كيف يتم التدريب
يتم إنشاء سلوك AlphaStar
بواسطة شبكة عصبية تعليمية عميقة ، والتي تتلقى البيانات الأولية من خلال الواجهة (قائمة من الوحدات وخصائصها) وتعطي سلسلة من الإرشادات التي تعتبر إجراءات في اللعبة. وبشكل أكثر تحديدًا ، تستخدم بنية الشبكة العصبية مقاربة "
تحويل الجذع إلى الوحدات ، مع
نواة LSTM عميقة ،
ورئيس سياسة التراجع التلقائي مع
شبكة مؤشر ،
وخط أساس قيمة مركزي "
(لدقة المصطلحات المتبقية دون ترجمة) . نعتقد أن هذه النماذج ستساعد بشكل أكبر في التعامل مع المهام الهامة الأخرى للتعلم الآلي ، بما في ذلك نمذجة التسلسلات طويلة المدى ومساحات الإخراج الكبيرة مثل الترجمة ونمذجة اللغة والتمثيلات المرئية.
يستخدم AlphaStar أيضًا خوارزمية التعلم متعددة الوكلاء الجديدة. تم تدريب هذه الشبكة العصبية في الأصل باستخدام طريقة تعلم قائمة على المعلم تستند إلى عمليات إعادة تحديد الهوية المجهولة
المتاحة من خلال عاصفة ثلجية قوية. سمح هذا لـ AlphaStar بدراسة ومحاكاة الاستراتيجيات الأساسية والجزئية الأساسية التي يستخدمها اللاعبون في البطولات. هزم هذا الوكيل مستوى الذكاء المدمج "النخبة" ، وهو ما يعادل مستوى لاعب في الدوري الذهبي في 95 ٪ من ألعاب الاختبار.
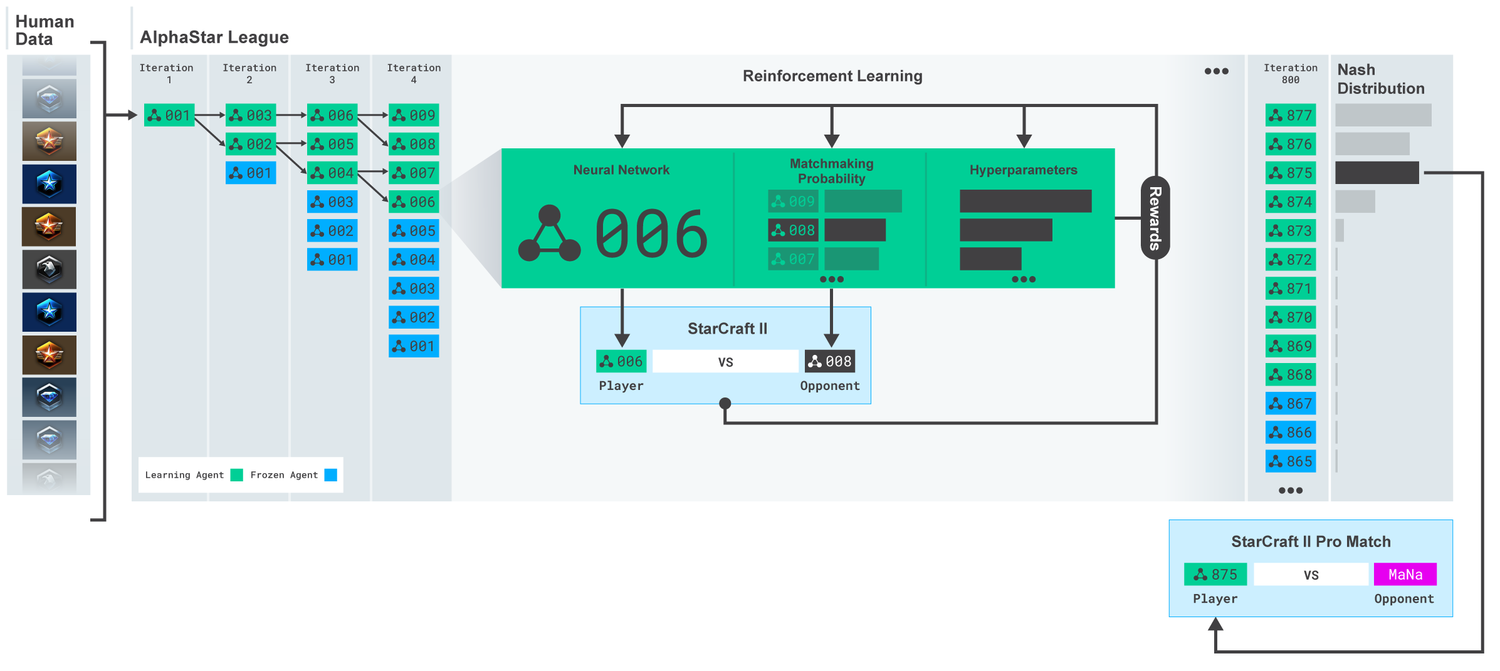 الدوري AlphaStar. تم تدريب الوكلاء في البداية على أساس عمليات إعادة المباريات البشرية ، ثم على أساس المباريات التنافسية فيما بينهم. في كل تكرار ، يتنافس المعارضون الجدد ويتجمد الخصوم الأصليون. تحدد احتمالية مقابلة خصوم ومعلمات تشعبية أخرى أهداف التعلم لكل وكيل ، مما يزيد من التعقيد ، الذي يحتفظ بالتنوع. يتم تحديث المعلمات وكيل مع التدريب التعزيز على أساس نتيجة اللعبة ضد المعارضين. يتم تحديد الوكيل النهائي (بدون بديل) استنادًا إلى توزيع Nash.
الدوري AlphaStar. تم تدريب الوكلاء في البداية على أساس عمليات إعادة المباريات البشرية ، ثم على أساس المباريات التنافسية فيما بينهم. في كل تكرار ، يتنافس المعارضون الجدد ويتجمد الخصوم الأصليون. تحدد احتمالية مقابلة خصوم ومعلمات تشعبية أخرى أهداف التعلم لكل وكيل ، مما يزيد من التعقيد ، الذي يحتفظ بالتنوع. يتم تحديث المعلمات وكيل مع التدريب التعزيز على أساس نتيجة اللعبة ضد المعارضين. يتم تحديد الوكيل النهائي (بدون بديل) استنادًا إلى توزيع Nash.ثم يتم استخدام هذه النتائج لبدء عملية تعلم التعزيز متعدد الوكلاء. لهذا ، تم إنشاء دوري حيث يلعب وكلاء الخصم ضد بعضهم البعض ، تمامًا كما يكتسب الأشخاص الخبرة من خلال لعب البطولات. تم إضافة منافسين جدد عن طريق الدوري ، عن طريق تكرار وكلاء الحالية. يتيح لك هذا الشكل الجديد من التعلم ، الذي يستعصي بعض الأفكار من طريقة التعلم المعزز بعناصر من خوارزميات
تستند إلى الجينات (
القائمة على السكان ) ، إنشاء عملية مستمرة لاستكشاف الفضاء الاستراتيجي الواسع لألعاب StarCraft ، والتأكد من قدرة الوكلاء على تحمل أقوى الاستراتيجيات ، وليس نسيان القديمة.
 النتيجة MMR (تقييم صنع مباراة) - مؤشر تقريبي لمهارة اللاعب. للمنافسة في دوري AlphaStar أثناء التدريب ، مقارنةً ببطولات Blizzard عبر الإنترنت.
النتيجة MMR (تقييم صنع مباراة) - مؤشر تقريبي لمهارة اللاعب. للمنافسة في دوري AlphaStar أثناء التدريب ، مقارنةً ببطولات Blizzard عبر الإنترنت.مع تطور الدوري وإنشاء وكلاء جدد ، ظهرت استراتيجيات مضادة تمكنت من هزيمة الشركات السابقة. على الرغم من أن بعض الوكلاء قاموا فقط بتحسين الاستراتيجيات التي واجهوها من قبل ، فإن الوكلاء الآخرين قاموا بإنشاء مستجدات جديدة تمامًا ، بما في ذلك أوامر بناء جديدة غير عادية وتكوين وحدة وإدارة الماكرو. على سبيل المثال ، في وقت مبكر ، ازدهرت "الجبن" - الاندفاع السريع بمساعدة
مدافع الفوتون المدفعية أو
Dark Templars . ولكن مع تقدم عملية التعلم ، تم تجاهل هذه الاستراتيجيات المحفوفة بالمخاطر ، وتمهيد الطريق أمام الآخرين. على سبيل المثال ، إنتاج عدد فائض من العمال للحصول على تدفق إضافي للموارد أو التبرع
بعرسيين لضرب عمال العدو وتقويض اقتصاده. تشبه هذه العملية كيف اكتشف اللاعبون العاديون استراتيجيات جديدة وهزموا المناهج الشعبية القديمة ، خلال السنوات العديدة منذ إطلاق StarCraft.
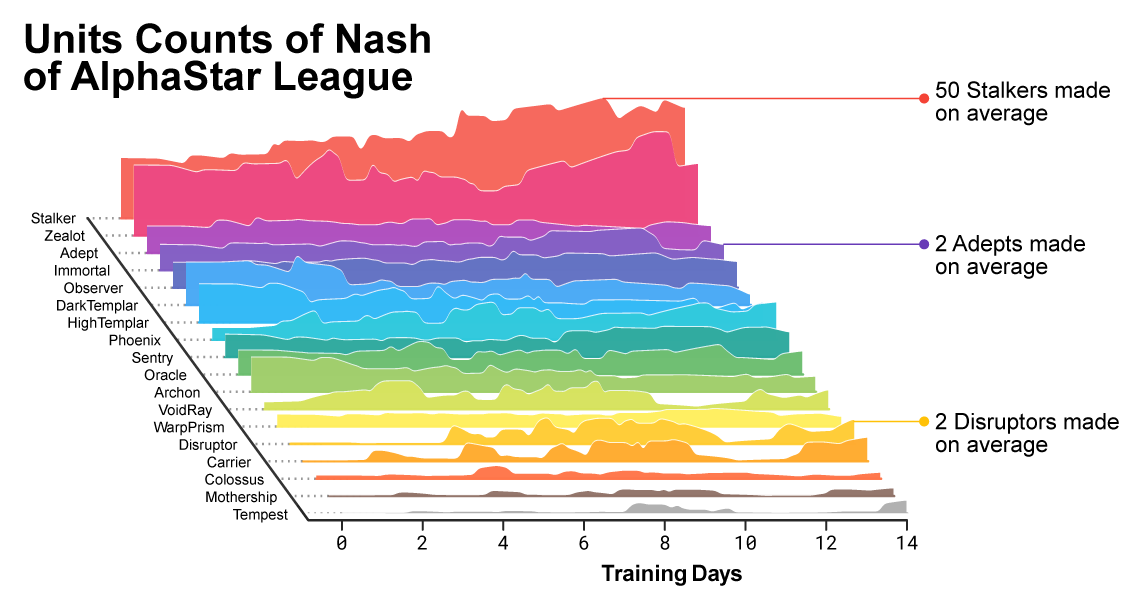 مع تقدم التدريب ، كان من الملحوظ كيف كان تكوين الوحدات المستخدمة من قبل العملاء يتغير.
مع تقدم التدريب ، كان من الملحوظ كيف كان تكوين الوحدات المستخدمة من قبل العملاء يتغير.لضمان التنوع ، تم منح كل عميل هدفه التعليمي الخاص. على سبيل المثال ، أي المعارضين يجب أن يهزم هذا العامل ، أو أي دافع جوهري آخر يحدد لعبة الوكيل. قد يكون هدف وكيل معين هو هزيمة خصم معين ، والآخر مجموعة كاملة من المعارضين ، ولكن فقط وحدات محددة. هذه الأهداف قد تغيرت طوال عملية التعلم.
 التصور التفاعلي (تتوفر الميزات التفاعلية في المقالة الأصلية ) ، والتي تُظهر منافسيها من خلال لعبة AlphaStar League. يتم وضع علامة بشكل منفصل على الوكيل الذي لعب ضد TLO و MaNa.
التصور التفاعلي (تتوفر الميزات التفاعلية في المقالة الأصلية ) ، والتي تُظهر منافسيها من خلال لعبة AlphaStar League. يتم وضع علامة بشكل منفصل على الوكيل الذي لعب ضد TLO و MaNa.تم تحديث معاملات (الأوزان) للشبكة العصبية لكل وكيل باستخدام تدريب التعزيز على أساس الألعاب مع المعارضين من أجل تحسين أهدافهم التعليمية المحددة. قاعدة تحديث الوزن هي خوارزمية تعلم فعالة جديدة "خوارزمية تعلم تعزيز فاعلية
خارج السياسة مع
إعادة التجربة ،
وتعلم التقليد الذاتي وتقطير السياسة "
(لدقة المصطلحات التي تُركت دون ترجمة) .
 تُظهر الصورة كيف قام أحد الوكلاء (النقطة السوداء) ، والذي تم اختياره كنتيجة للمباراة ضد مانا ، بتطوير استراتيجيته مقارنةً بالمعارضين (النقاط الملونة) في عملية التدريب. كل نقطة تمثل الخصم في الدوري. يوضح موضع النقطة الاستراتيجية والحجم - التكرار الذي يتم به اختياره كمعارض لخادم مان في عملية التعلم.
تُظهر الصورة كيف قام أحد الوكلاء (النقطة السوداء) ، والذي تم اختياره كنتيجة للمباراة ضد مانا ، بتطوير استراتيجيته مقارنةً بالمعارضين (النقاط الملونة) في عملية التدريب. كل نقطة تمثل الخصم في الدوري. يوضح موضع النقطة الاستراتيجية والحجم - التكرار الذي يتم به اختياره كمعارض لخادم مان في عملية التعلم.لتدريب AlphaStar ، أنشأنا نظامًا موزعًا قابلًا للتطوير استنادًا إلى
Google TPU 3 ، والذي يوفر عملية التدريب الموازي لمجموعة كاملة من الوكلاء مع الآلاف من نسخ تشغيل StarCraft II. استمرت لعبة AlphaStar League لمدة 14 يومًا باستخدام 16 وحدة تبويب لكل وكيل. خلال التدريب ، واجه كل وكيل ما يصل إلى 200 عام من الخبرة في لعب StarCraft في الوقت الفعلي. النسخة النهائية من وكيل AlphaStar تحتوي على مكونات
التوزيع ناش كل الدوري. بمعنى آخر ، المزيج الأكثر فاعلية من الاستراتيجيات التي تم اكتشافها أثناء الألعاب. ويمكن تشغيل هذا التكوين على واحد GPU سطح المكتب القياسي. يتم إعداد وصف تقني كامل للنشر في مجلة علمية تمت مراجعتها من قبل النظراء.
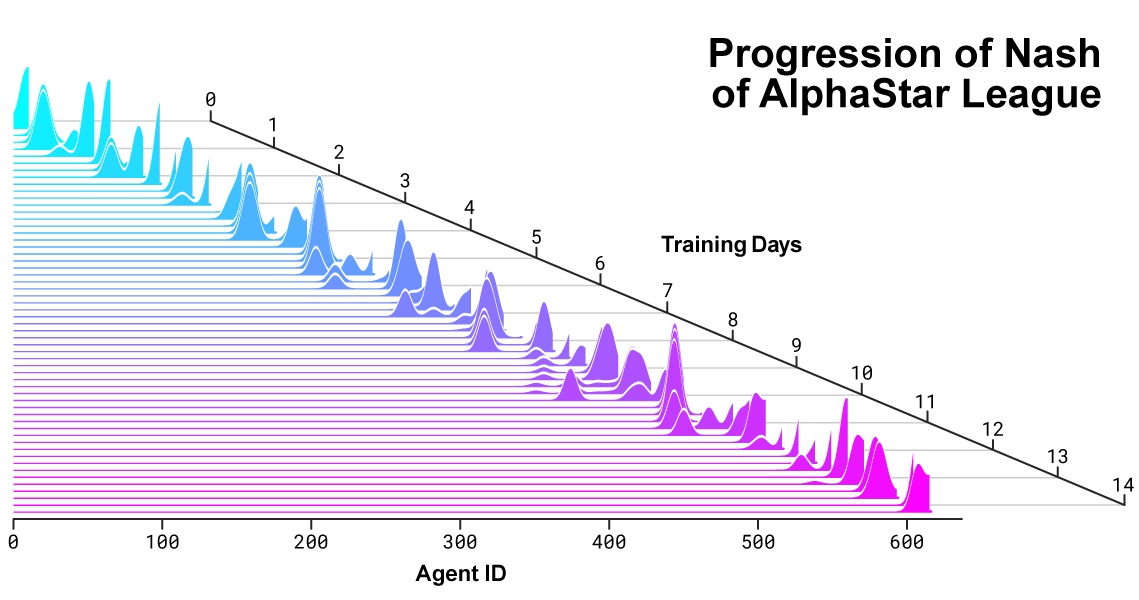 ناش التوزيع بين المنافسين خلال تطوير الدوري وخلق خصوم جدد. إن توزيع Nash ، وهو أقل مجموعة من المنافسين التكميليين قابلية للاستغلال ، يقدر اللاعبين الجدد ، مما يدل على التقدم المستمر على جميع المنافسين السابقين.
ناش التوزيع بين المنافسين خلال تطوير الدوري وخلق خصوم جدد. إن توزيع Nash ، وهو أقل مجموعة من المنافسين التكميليين قابلية للاستغلال ، يقدر اللاعبين الجدد ، مما يدل على التقدم المستمر على جميع المنافسين السابقين.كيف يعمل AlphaStar ويرى اللعبة
يمكن للاعبين المحترفين مثل TLO أو MaNa إجراء مئات الإجراءات في الدقيقة (
APM ). ولكن هذا أقل بكثير من معظم
برامج الروبوت الموجودة التي تتحكم بشكل مستقل في كل وحدة وتنتج الآلاف ، إن لم يكن عشرات الآلاف من الإجراءات.
في مبارياتنا ضد TLO و MaNa ، أبقى AlphaStar على APM بمعدل 280 ، وهو أقل بكثير من اللاعبين المحترفين ، على الرغم من أن أفعالها قد تكون أكثر دقة. هذا APM المنخفض يرجع بشكل خاص إلى حقيقة أن AlphaStar بدأت في الدراسة على أساس تعويضات اللاعبين العاديين وحاولت تقليد طريقة اللعب البشري. بالإضافة إلى ذلك ، يتفاعل AlphaStar مع تأخير بين المراقبة والعمل بمعدل 350 مللي ثانية تقريبًا.
 توزيع APM AlphaStar في المباريات ضد مانا و TLO ، والتأخير الكلي بين الملاحظة والعمل.
توزيع APM AlphaStar في المباريات ضد مانا و TLO ، والتأخير الكلي بين الملاحظة والعمل.خلال المباريات ضد TLO و MNA ، تفاعل AlphaStar مع محرك ألعاب StarCraft من خلال واجهة أولية ، أي أنه يمكن أن يرى سمات وحداته ووحدات العدو المرئية على الخريطة مباشرةً ، دون الحاجة إلى تحريك الكاميرا - اللعب بفعالية مع عرض مخفض للمنطقة بأكملها . على عكس ذلك ، يجب على الأشخاص الأحياء إدارة "اقتصاد الاهتمام" بوضوح من أجل تحديد مكان تركيز الكاميرا باستمرار. ومع ذلك ، يكشف تحليل لألعاب AlphaStar أنه يتحكم ضمنيًا في التركيز. في المتوسط ، يغير الوكيل سياق انتباهه حوالي 30 مرة في الدقيقة ، مثل مانا و TLO.
بالإضافة إلى ذلك ، قمنا بتطوير الإصدار الثاني من AlphaStar. بوصفهم لاعبين بشريين ، فإن هذا الإصدار من AlphaStar يختار بوضوح وقت ومكان نقل الكاميرا. في هذا النموذج ، يقتصر إدراكه على المعلومات التي تظهر على الشاشة ، كما لا يُسمح بالإجراءات إلا في المنطقة المرئية من الشاشة.
 أداء AlphaStar عند استخدام الواجهة الأساسية وواجهة الكاميرا. يوضح الرسم البياني أن العامل الجديد الذي يعمل مع الكاميرا يحقق أداءً قابلاً للمقارنة بسرعة للعامل باستخدام الواجهة الأساسية.
أداء AlphaStar عند استخدام الواجهة الأساسية وواجهة الكاميرا. يوضح الرسم البياني أن العامل الجديد الذي يعمل مع الكاميرا يحقق أداءً قابلاً للمقارنة بسرعة للعامل باستخدام الواجهة الأساسية.لقد دربنا وكيلين جديدين ، أحدهما يستخدم الواجهة الأساسية والآخر كان من المفترض أن يتعلم كيفية التحكم في الكاميرا ، ويلعب ضد فريق AlphaStar. تم تدريب كل عميل في البداية مع معلم بناءً على المباريات البشرية ، يليه تدريب مع التعزيز الموصوف أعلاه. حقق إصدار AlphaStar ، الذي يستخدم واجهة الكاميرا ، نفس النتائج تقريبًا مثل الإصدار مع الواجهة الأساسية ، وهو ما يتجاوز علامة 7000 MMR على لوحة المتصدرين الداخلية الخاصة بنا. في مباراة مظاهرة ، هزم مانا النموذج الأولي لـ AlphaStar باستخدام الكاميرا. قمنا بتدريب هذا الإصدار فقط 7 أيام. نأمل أن نتمكن من تقييم نسخة مدربة بالكامل باستخدام كاميرا في المستقبل القريب.
توضح هذه النتائج أن نجاح AlphaStar في المباريات ضد شركات MNa و TLO هو في المقام الأول نتيجة الإدارة الجيدة للماكرو والجزئي ، وليس فقط نسبة نقرات كبيرة أو رد فعل سريع أو الوصول إلى المعلومات على الواجهة الأساسية.
نتائج لعبة AlphaStar مقابل لاعبين محترفين
تسمح StarCraft للاعبين باختيار واحد من ثلاثة سباقات - terrans أو zerg أو protoss. قررنا أن AlphaStar سيتخصص حاليًا في سباق واحد معين ، وهو protoss ، من أجل تقليل وقت التدريب والاختلافات في تقييم نتائج دورينا المحلي. ولكن تجدر الإشارة إلى أنه يمكن تطبيق عملية تعلم مماثلة على أي سباق. تم تدريب وكيلاؤنا على لعب StarCraft II الإصدار 4.6.2 في وضع protoss مقابل protoss على خريطة CatalystLE. لتقييم أداء AlphaStar ، اختبرنا وكلاءنا في البداية في المباريات ضد TLO - لاعب محترف للصفر ولاعب لمستوى البروتوس "GrandMaster". فاز AlphaStar المباريات برصيد 5: 0 ، وذلك باستخدام مجموعة واسعة من الوحدات وبناء أوامر. قال: "لقد فوجئت بمدى قوة العميل". يأخذ AlphaStar استراتيجيات معروفة ويحولها رأسًا على عقب. أظهر الوكيل استراتيجيات لم أفكر فيها مطلقًا. وهذا يدل على أنه لا يزال هناك طرق للعب لا تزال غير مفهومة بالكامل. "
بعد أسبوع إضافي من التدريب ، لعبنا ضد MaNa ، أحد أقوى لاعبي StarCraft II في العالم ، وواحد من أفضل 10 لاعبين. فاز AlphaStar هذه المرة 5-0 ، مما يدل على مهارات الإدارة الجزئية والاستراتيجية الكلية قوية. وقال "لقد دهشت لرؤية AlphaStar باستخدام الأساليب الأكثر تقدما واستراتيجيات مختلفة في كل لعبة ، مما يدل على أسلوب إنساني للغاية من اللعب لم أتوقع رؤيته". "لقد أدركت مدى قوة أسلوبي في اللعب يعتمد على استخدام الأخطاء على أساس ردود الفعل البشرية. وهذا يضع اللعبة على مستوى جديد تمامًا. كلنا نتوقع بحماس أن نرى ما سيحدث بعد ذلك ".
AlphaStar وغيرها من المشاكل الصعبة
على الرغم من أن StarCraft هي مجرد لعبة ، حتى لو كانت صعبة للغاية ، فإننا نعتقد أن التقنيات الأساسية لـ AlphaStar قد تكون مفيدة في حل المشكلات الأخرى. على سبيل المثال ، هذا النوع من بنية الشبكة العصبية قادر على محاكاة تسلسلات طويلة جدًا من الإجراءات المحتملة ، في الألعاب التي تستمر غالبًا لمدة ساعة وتحتوي على عشرات الآلاف من الإجراءات استنادًا إلى معلومات غير كاملة. يتم استخدام كل إطار في StarCraft كخطوة إدخال واحدة. في هذه الحالة ، تتوقع الشبكة العصبية في كل خطوة من هذه الخطوات التسلسل المتوقع لإجراءات اللعبة المتبقية بأكملها. تم العثور على المهمة الأساسية المتمثلة في إعداد تنبؤات معقدة لتسلسل بيانات طويل جدًا في العديد من مشكلات العالم الحقيقي ، مثل التنبؤ بالطقس ، ونمذجة المناخ ، وفهم اللغة ، وما إلى ذلك. نحن سعداء جدًا بالتعرف على الإمكانات الهائلة التي يمكن تطبيقها في هذه المناطق ، باستخدام الخبرة التي اكتسبناها في مشروع AlphaStar.
نعتقد أيضًا أن بعض طرق التدريس لدينا قد تكون مفيدة في دراسة سلامة وموثوقية الذكاء الاصطناعي. واحدة من أصعب المشاكل في مجال الذكاء الاصطناعي هو عدد الخيارات التي قد يكون فيها النظام خاطئًا.
ووجد اللاعبون المحترفون في الماضي طرقًا للالتفاف على الذكاء الاصطناعي باستخدام أخطائهم بالطريقة الأصلية. نهج AlphaStar المبتكر ، القائم على التدريب في الدوري ، يجد مثل هذه الأساليب ويجعل العملية الشاملة أكثر موثوقية ومحمية من مثل هذه الأخطاء. يسعدنا أن إمكانات هذا النهج يمكن أن تساعد في تحسين أمن وموثوقية أنظمة الذكاء الاصطناعى بشكل عام. خاصة في المجالات الحرجة مثل الطاقة ، حيث من المهم للغاية أن تتفاعل بشكل صحيح في المواقف الصعبة.يمثل تحقيق مثل هذا المستوى العالي من اللعب في StarCraft طفرة كبيرة في واحدة من أكثر ألعاب الفيديو تحديًا على الإطلاق. نعتقد أن هذه الإنجازات ، إلى جانب النجاحات في مشاريع أخرى ، سواء كانت AlphaZero أو AlphaFold تمثل خطوة إلى الأمام في تنفيذ مهمتنا لإنشاء أنظمة ذكية من شأنها أن تساعدنا في يوم من الأيام على إيجاد حلول للقضايا العلمية الأكثر تعقيدًا وأساسية.
11 إصدارات من جميع المبارياتVideo of the مظاهرة مباراة ضد MaNaVideo مع تصور AlphaStar للمباراة الثانية الكاملة ضد مانا