
أعلنت شركة DeepMind ، وهي شركة تابعة لشركة Alphabet ، التي تعمل في مجال البحوث في مجال الذكاء الاصطناعي ، عن إنجاز جديد في هذا المسعى الكبير:
لأول مرة ، هزمت AI شخصًا في استراتيجية Starcraft II . في ديسمبر 2018 ، قامت شبكة عصبية
تلافوية تسمى
AlphaStar بنشر اللاعبين المحترفين
TLO (داريو ونش ، ألمانيا) ومانا (Grzegorz Kominz ، بولندا) ، حيث سجلوا عشرة انتصارات. أعلنت الشركة عن هذا الحدث أمس في
بث مباشر على YouTube و Twitch.
في كلتا الحالتين ، لعبت كل من الناس والبرنامج كما protoss. على الرغم من أن TLO لا يتخصص في هذا السباق ، إلا أن مانا طرح مقاومة جدية ، ثم فاز بلعبة واحدة.
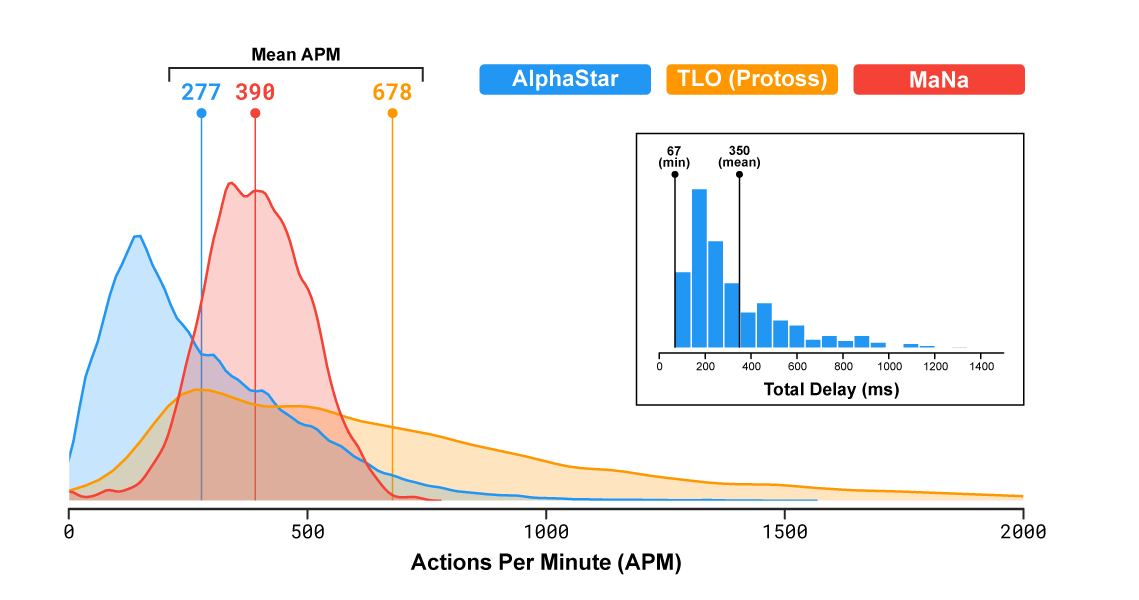
في إستراتيجية الوقت الفعلي الشائعة ، يمثل اللاعبون أحد السباقات الثلاثة التي تتنافس على الموارد ، وتبني الهياكل ، وتقاتل على الخريطة الكبيرة. من المهم أن نلاحظ أن سرعة البرنامج ورؤيته في ساحة المعركة كانت محدودة بحيث لم يكتسب AlphaStar ميزة غير عادلة على الأشخاص (التصحيح: على ما يبدو ، كانت الرؤية محدودة فقط في المباراة الأخيرة). في الواقع ، ووفقًا للإحصاءات ، قام البرنامج بعمل أقل في الدقيقة من الأشخاص: متوسط 277 لـ AlphaStar ، و 390 لـ MNA ، و 678 لـ TLO.
يُظهر
الفيديو وجهة نظر اللعبة من وجهة نظر وكيل الذكاء الاصطناعى في المباراة الثانية ضد مانا. يتم أيضًا عرض المنظر من الجانب الإنساني ، لكنه لم يكن متاحًا للبرنامج.
تم تدريب AlphaStar على اللعب من أجل protoss في بيئة تسمى AlphaStar League. أولاً ، أمضت الشبكة العصبية ثلاثة أيام في البحث عن تسجيلات للألعاب ، ثم اللعب مع نفسها ، باستخدام تقنية تعرف باسم التدريب التعزيز ، ومهارات الشحذ.
في ديسمبر ، قاموا أولاً بتنظيم جلسة لعبة ضد TLO ، حيث تم اختبار خمسة إصدارات مختلفة من AlphaStar. في هذه المناسبة ،
اشتكى TLO أنه لا يستطيع التكيف مع لعبة الخصم. فاز البرنامج برصيد 5-0.
بعد تحسين إعدادات الشبكة العصبية ، نظمت مباراة بعد ذلك بأسبوع ضد مانا. فاز البرنامج مرة أخرى بخمس مباريات ، لكن مانّا انتقم في المباراة الأخيرة ضد أحدث نسخة من الخوارزمية على الهواء ، لذلك لديه شيء ليفخر به.
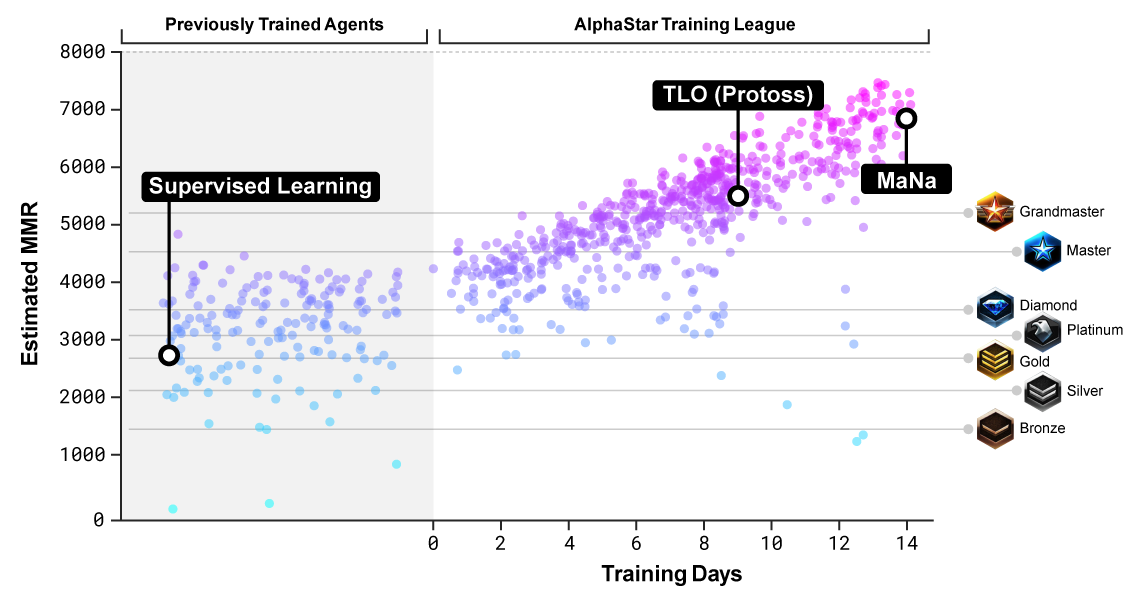 تقييم مستوى المعارضين الذين تم تدريب الشبكة العصبية عليهم
تقييم مستوى المعارضين الذين تم تدريب الشبكة العصبية عليهملفهم مبادئ التخطيط الاستراتيجي ، كان على AlphaStar إتقان التفكير الخاص. يمكن أن تكون الطرق المطورة لهذه اللعبة مفيدة في العديد من المواقف العملية عندما تكون هناك حاجة لاستراتيجية معقدة: على سبيل المثال ، التخطيط التجاري أو العسكري.
ستاركرافت الثاني ليست فقط لعبة صعبة للغاية. هذه أيضًا لعبة تحتوي على معلومات غير كاملة ، حيث لا يمكن للاعبين دائمًا رؤية تصرفات خصمهم. كما أنه يفتقر إلى الاستراتيجية المثلى. ويستغرق الأمر بعض الوقت حتى تصبح نتائج تصرفات اللاعب واضحة: وهذا يجعل التعلم أمرًا صعبًا أيضًا. استخدم فريق DeepMind بنية شبكة عصبية متخصصة للغاية لحل هذه المشكلات.
التعلم محدود في الألعاب
يُعرف DeepMind كمطور برامج يتفوق على أفضل محترفي الذهاب والشطرنج في العالم. قبل ذلك ، طورت الشركة العديد من الخوارزميات التي تعلمت لعب ألعاب أتاري البسيطة. تعد ألعاب الفيديو طريقة رائعة لقياس التقدم في الذكاء الاصطناعي ومقارنة أجهزة الكمبيوتر بالناس. ومع ذلك ، هذه منطقة اختبار ضيقة للغاية. مثل البرامج السابقة ، يقوم تطبيق AlphaStar بمهمة واحدة فقط ، وإن كان جيدًا بشكل لا يصدق.
يمكننا القول أن الذكاء الاصطناعي الضيق ضعيف الهدف يتقن مهارات التخطيط الاستراتيجي وتكتيكات العمليات القتالية. من الناحية النظرية ، يمكن أن تأتي هذه المهارات في متناول اليد في العالم الحقيقي. ولكن في الممارسة العملية هذا ليس هو الحال بالضرورة.
يعتقد بعض الخبراء أن مثل هذه التطبيقات عالية التخصص من الذكاء الاصطناعي لا علاقة لها بالذكاء الاصطناعى القوي: "البرامج التي تعلمت أن تلعب ببراعة لعبة فيديو معينة أو لعبة لوح على مستوى" فوق إنسان "
تضيع تمامًا عندما يكون هناك أدنى تغيير في الظروف (تغيير الخلفية على الشاشة أو تغيير الموضع افتراضية "منصة" لضرب "الكرة")، - يقول أستاذ علوم الكومبيوتر في جامعة بورتلاند الدولة، ميلاني ميتشل في المادة
"ركض الذكاء الاصطناعي في ponima حاجز ستعقد " . - هذه مجرد أمثلة قليلة تثبت عدم موثوقية أفضل برامج الذكاء الاصطناعي ، إذا كان الموقف مختلفًا قليلاً عن تلك التي تم تدريبهم عليها. تتراوح الأخطاء في هذه الأنظمة من السخيفة وغير المؤذية إلى الكارثية المحتملة. "
يعتقد الأستاذ أن سباق تسويق الذكاء الاصطناعي يفرض ضغطًا هائلاً على الباحثين لإنشاء أنظمة تعمل "بشكل جيد إلى حد معقول" في مهام ضيقة. ولكن في النهاية ، يتطلب تطوير الذكاء الاصطناعى الموثوق به دراسة أعمق لقدراتنا وفهم جديد للآليات المعرفية التي نستخدمها نحن:
يعتمد فهمنا للمواقف التي نواجهها على "مفاهيم الفطرة السليمة" الواسعة والبديهية حول كيفية عمل العالم والأهداف والدوافع والسلوك المحتمل للكائنات الحية الأخرى ، وخاصة الأشخاص الآخرين. بالإضافة إلى ذلك ، يعتمد فهمنا للعالم على قدراتنا الأساسية لتعميم ما نعرفه ، لتشكيل مفاهيم مجردة ورسم أوجه التشابه - باختصار ، تكييف مفاهيمنا بمرونة مع المواقف الجديدة. على مدار عقود من الزمن ، جرب الباحثون تدريس مفهوم الذكاء الاصطناعي البسيط والقدرات البشرية المستدامة للتعميم ، لكن لم يتحقق تقدم كبير في هذه المسألة الصعبة للغاية.
يمكن لشبكة AlphaStar العصبية أن تلعب فقط من أجل protoss حتى الآن. أعلن المطورون عن خطط لتدريبها في المستقبل على اللعب في السباقات الأخرى.