هذا مقال جديد من
Google Job Interview Parsing . عندما عملت هناك ، عرضت على المرشحين هذه المهام. ثم كان هناك تسرب ، وتم حظرهم. لكن للعملة جانب جانبي: الآن يمكنني شرح الحل بحرية.
نبأ عظيم للبدء: لقد تركت Google! يسعدني أن أبلغكم بأنني أعمل الآن كمدير فني لشركة رديت في نيويورك! ولكن هذه السلسلة من المقالات ستظل مستمرة.
إخلاء المسئولية: على الرغم من أن إجراء المقابلات مع المرشحين يعد أحد واجباتي المهنية ، إلا أنني أشارك في هذا المدونة ملاحظات شخصية وقصص وآراء شخصية. يرجى عدم اعتبار هذا بيانًا رسميًا من Google أو Alphabet أو Reddit أو أي شخص أو مؤسسة أخرى.سؤال
بعد
آخر مقالتين عن تقدم الحصان في طلب رقم هاتف ، تلقيت انتقادات بأن هذه ليست مشكلة واقعية. بغض النظر عن مدى فائدة دراسة مهارات التفكير للمرشح ، ولكن يجب أن أعترف: المهمة ليست واقعية إلى حد ما. على الرغم من أنني لدي بعض الأفكار حول العلاقة بين أسئلة المقابلة والواقع ، إلا أنني سأتركها لي الآن. تأكد من أنني قرأت التعليقات في كل مكان ولديّ شيء يجب الإجابة عليه ، لكن ليس الآن.
ولكن عندما تم حظر مهمة اجتياز الحصان قبل عدة سنوات ، أخذت انتقادات شديدة وحاولت استبداله بسؤال أكثر صلة بنطاق Google قليلاً. وما الذي يمكن أن يكون أكثر صلة بـ Google من آليات استعلامات البحث؟ لذلك وجدت هذا السؤال واستخدمته لفترة طويلة قبل أن يتم نشره أيضًا وتم حظره. كما كان من قبل ، سأقوم بصياغة السؤال ، والتعمق في شرحه ، ثم سأقول كيف استخدمته في المقابلات ولماذا أعجبتني.
لذا فإن السؤال هو.
تخيل أنك تدير محرك بحث شائعًا وترى طلبين في السجلات: مثل "تصنيفات موافقة أوباما" و "مستوى شعبية أوباما" (إذا كنت أتذكر بشكل صحيح ، فهذه أمثلة حقيقية من قاعدة الأسئلة ، على الرغم من أنها قديمة بعض الشيء الآن ...) . نرى استعلامات مختلفة ، لكن الجميع سيوافقون: يبحث المستخدمون عن نفس المعلومات بشكل أساسي ، لذا يجب اعتبار الاستعلامات متكافئة عند حساب عدد الاستعلامات وإظهار النتائج ، وما إلى ذلك.
كيف يمكنك تحديد ما إذا كان هناك استبيانان مترادفان؟دعونا إضفاء الطابع الرسمي على المهمة. افترض أن هناك مجموعتين من أزواج السلسلة: أزواج المترادفات وأزواج الاستعلام.
على وجه التحديد ، فيما يلي مثال للمدخلات لتوضيح:
SYNONYMS = [ ('rate', 'ratings'), ('approval', 'popularity'), ] QUERIES = [ ('obama approval rate', 'obama popularity ratings'), ('obama approval rates', 'obama popularity ratings'), ('obama approval rate', 'popularity ratings obama') ]
من الضروري إنتاج قائمة من القيم المنطقية: هي الاستعلامات في كل زوج مرادف.
كل الأسئلة الجديدة ...
للوهلة الأولى ، هذه مهمة بسيطة. ولكن كلما زاد طول فترة تفكيرك ، أصبح الأمر أكثر صعوبة. يمكن للكلمة أن يكون لها عدة مرادفات؟ هل ترتيب الكلمات مهم؟ هل العلاقات مرادفة متعدّدة ، أي إذا كان مرادفًا لـ B و B مرادفًا لـ C ، فهل هو مرادف لـ C؟ هل يمكن للمرادفات أن تغطي بضع كلمات ، كيف أن "الولايات المتحدة الأمريكية" مرادف لعبارات "الولايات المتحدة الأمريكية" أو "الولايات المتحدة"؟
هذا الغموض على الفور يجعل من الممكن إثبات نفسك لمرشح جيد. أول شيء يفعله هو البحث عن مثل هذه الغموض ومحاولة حلها. يقوم كل شخص بذلك بطرق مختلفة: البعض يقترب من اللوحة ويحاول حل حالات معينة يدويًا ، بينما ينظر آخرون إلى السؤال ويرون على الفور الثغرات. في أي حال ، تحديد هذه المشاكل في مرحلة مبكرة أمر بالغ الأهمية.
تعتبر مرحلة "فهم المشكلة" ذات أهمية كبيرة. أحب أن أسمي هندسة البرمجيات تخصصًا كسريًا. مثل الفركتلات ، يكشف التقريب عن تعقيد إضافي. تعتقد أنك تفهم المشكلة ، ثم ألق نظرة فاحصة - وترى أنك فاتتك بعض الدقة أو التفاصيل الخاصة بالتنفيذ التي يمكن تحسينها. أو نهج مختلف لهذه المشكلة.
 مجموعة ماندلبروتيتم تحديد عيار المهندس إلى حد كبير من خلال مدى عمق يمكن أن يفهم المشكلة.
مجموعة ماندلبروتيتم تحديد عيار المهندس إلى حد كبير من خلال مدى عمق يمكن أن يفهم المشكلة. الخطوة الأولى في هذه العملية هي تحويل بيان غامض للمشكلة إلى مجموعة مفصلة من المتطلبات ، والتخفيض المتعمد يجعل من الممكن تقييم مدى تقارب المرشح في المواقف الجديدة.
نترك جانباً أسئلة تافهة ، مثل "هل الأحرف الكبيرة مهمة؟" وهذا لا يؤثر على الخوارزمية الرئيسية. أنا دائمًا أقدم أبسط إجابة على هذه الأسئلة (في هذه الحالة ، "افترض أن جميع الأحرف قد تم تجهيزها مسبقًا وتحولت إلى أحرف صغيرة")الجزء 1. (ليس تماما) قضية بسيطة
إذا طرح المرشحون أسئلة ، فأنا أبدأ دائمًا بأبسط الحالات: يمكن أن تحتوي الكلمة على عدة مرادفات ، ومسائل ترتيب الكلمات ، والمرادفات ليست متعدية. هذا يعطي محرك البحث وظائف محدودة للغاية ، ولكن لديه ما يكفي من التفاصيل الدقيقة لإجراء مقابلة مثيرة للاهتمام.
نظرة عامة رفيعة المستوى هي كما يلي: قسّم الاستعلام إلى كلمات (على سبيل المثال ، حسب المسافات) وقارن الأزواج المقابلة للبحث عن كلمات ومرادفات متطابقة. بصريا ، يبدو مثل هذا:
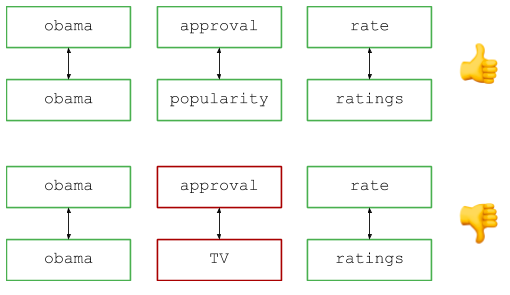
في الكود:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif words_are_synonyms(w1, w2): continue result = False break output.append(result) return output
سهل ، أليس كذلك؟ حسابيًا ، إنه بسيط جدًا. لا يوجد دينامية البرمجة ، العودية ، الهياكل المعقدة ، وما إلى ذلك. التلاعب البسيط بالمكتبة القياسية وخوارزمية تعمل في الوقت الخطي ، أليس كذلك؟
ولكن هناك فروق دقيقة أكثر مما يبدو للوهلة الأولى. بطبيعة الحال ، فإن المكون الأكثر صعوبة هو المقارنة بين المرادفات. على الرغم من أن المكون سهل الفهم والوصف ، إلا أن هناك العديد من الطرق لارتكاب خطأ. سوف أخبرك عن الأخطاء الأكثر شيوعًا.
من أجل الوضوح: لن تؤدي أي أخطاء إلى استبعاد أي مرشح ؛ إذا كان الأمر كذلك ، فأنا فقط أشير إلى وجود خطأ في التنفيذ ، فإنه يصلح ، ونحن نمضي قدمًا. ومع ذلك ، فإن المقابلة هي أولاً وقبل كل شيء كفاح ضد الزمن. سوف ترتكب الأخطاء وتلاحظها وتصحيحها ، لكن الأمر قد يستغرق وقتًا في وقت آخر ، على سبيل المثال ، لإنشاء حل أفضل. كل شخص تقريباً يرتكب أخطاء ، هذا أمر طبيعي ، لكن المرشحين الذين يصغرونهم يظهرون نتائج أفضل ببساطة لأنهم يقضون وقتًا أقل في تصحيحها.
هذا هو السبب في أنني أحب هذه المشكلة. إذا كانت خطوة فارس تتطلب نظرة ثاقبة لفهم الخوارزمية ، ثم (آمل) تنفيذ بسيط ، فإن الحل هنا هو الكثير من الخطوات في الاتجاه الصحيح. تمثل كل خطوة عقبة صغيرة يمكن للمرشح من خلالها القفز بلطف أو التعثر والارتفاع. بفضل الخبرة والحدس ، يتجنب المرشحون الجيدين هذه المزالق الصغيرة - ويحصلون على حل أكثر تفصيلاً وصحيحاً ، بينما يقضي أضعف منهم الوقت والجهد على الأخطاء ويبقون عادةً مع الكود الخطأ.
في كل مقابلة ، رأيت مزيجًا مختلفًا من النجاح والفشل ، فهذه هي الأخطاء الأكثر شيوعًا.
قتلة الأداء العشوائي
أولاً ، قام بعض المرشحين بتنفيذ الكشف عن مرادفات من خلال اجتياز قائمة المرادفات ببساطة:
... elif (w1, w2) in synonym_words: continue ...
للوهلة الأولى ، يبدو هذا معقولاً. لكن بعد الفحص الدقيق ، الفكرة سيئة للغاية. بالنسبة لأولئك منكم الذين لا يعرفون Python ، فإن الكلمة المفتاحية هي السكر النحوي للأسلوب الذي
يحتوي على ويعمل على جميع حاويات Python القياسية. هذه مشكلة لأن
synonym_words عبارة عن قائمة تنفذ الكلمة الأساسية باستخدام البحث الخطي. يكون مستخدمو Python حساسين بشكل خاص لهذا الخطأ لأن اللغة تخفي أنواعًا ، لكن مستخدمي C ++ و Java ارتكبوا أيضًا أخطاء مماثلة في بعض الأحيان.
خلال مسيرتي المهنية ، كتبت فقط عدة مرات باستخدام شفرة بحث خطية ، وكل منها في قائمة لا تزيد عن 24 عنصرًا. وحتى في هذه الحالة ، كتب تعليقًا طويلًا يشرح سبب اختياره لمثل هذا النهج على ما يبدو دون المستوى الأمثل. أظن أن بعض المرشحين استخدموه ببساطة لأنهم لم يعرفوا كيف تعمل الكلمة الرئيسية في قوائم في مكتبة Python القياسية. هذا خطأ بسيط ، وليس قاتلاً ، لكن التعارف الضعيف مع لغتك المفضلة ليس جيدًا.
في الممارسة العملية ، يتم تجنب هذا الخطأ بسهولة. أولاً ، لا تنس أبدًا أنواع الكائنات الخاصة بك ، حتى إذا كنت تستخدم لغة غير نمطية مثل Python! ثانياً ، تذكر أنه عند استخدام الكلمة الأساسية
في القائمة ، يبدأ البحث الخطي. إذا لم يكن هناك ضمان بأن تظل هذه القائمة صغيرة جدًا دائمًا ، فسوف تقتل الأداء.
لكي يأتي المرشح إلى رشده ، يكفي عادة تذكيره بأن بنية الإدخال هي قائمة. من المهم جدًا ملاحظة كيفية استجابة المرشح للموجه. يحاول أفضل المرشحين على الفور المعالجة المسبقة للمرادفات ، وهذا يعد بداية جيدة. ومع ذلك ، فإن هذا النهج لا يخلو من المآزق ...
استخدم بنية البيانات الصحيحة
من الكود أعلاه ، يتضح على الفور أنه من أجل تنفيذ هذه الخوارزمية في الوقت الخطي ، من الضروري العثور على المرادفات بسرعة. وعندما نتحدث عن عمليات البحث السريعة ، فهي دائمًا خريطة أو مجموعة من التجزئات.
لا يهمني ما إذا كان المرشح يختار خريطة أو مجموعة من التجزئات. الشيء المهم هو أنه سوف يضعها هناك (بالمناسبة ، لا تستخدم dict / hashmap مع الانتقال إلى
True أو
False ). معظم المرشحين اختيار نوع من dict / hashmap. الخطأ الأكثر شيوعًا هو الافتراض الباطن بأن كل كلمة ليس لها أكثر من مرادف واحد:
... synonyms = {} for w1, w2 in synonym_words: synonyms[w1] = w2 ... elif synonyms[w1] == w2: continue
أنا لا أعاقب المرشحين لهذا الخطأ. تمت صياغة المهمة خصيصًا حتى لا تركز على حقيقة أن الكلمات يمكن أن يكون لها عدة مرادفات ، وبعض المرشحين ببساطة لم يواجهوا مثل هذا الموقف. بسرعة أكبر إصلاح الخلل عندما أشر إلى ذلك. يلاحظ المرشحون الجيدون ذلك في مرحلة مبكرة وعادة ما لا يقضون الكثير من الوقت.
المشكلة الأكثر خطورة هي قلة الوعي بأن علاقة المرادفات تنتشر في كلا الاتجاهين. لاحظ أنه في الكود أعلاه ، يتم أخذ ذلك في الاعتبار. ولكن هناك تطبيقات مع وجود خطأ:
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) synonyms[w2].append(w1) ... elif w2 in synonyms.get(w1, tuple()): continue
لماذا إدراج اثنين واستخدام ضعف الذاكرة؟
... synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].append(w2) ... elif (w2 in synonyms.get(w1, tuple()) or w1 in synonyms.get(w2, tuple())): continue
الاستنتاج:
فكر دائمًا في كيفية تحسين الكود ! في الماضي ، يعد التقليب في وظائف البحث تحسينًا واضحًا ، وإلا يمكننا أن نستنتج أن المرشح لم يفكر في خيارات التحسين. مرة أخرى ، أنا سعيد بإعطاء تلميح ، لكن من الأفضل تخمين ذلك بنفسك.
فرز؟
يريد بعض المرشحين الأذكياء فرز قائمة المرادفات ثم استخدام البحث الثنائي. في الواقع ، تتمتع هذه الطريقة بميزة مهمة: فهي لا تتطلب مساحة إضافية ، باستثناء قائمة المرادفات (بشرط أن يتم تغيير القائمة).
لسوء الحظ ، يتداخل تعقيد الوقت: يتطلب فرز قائمة المرادفات
Nlog(N) ، ثم
log(N) آخر
log(N) للبحث عن كل زوج من المرادفات ، بينما يحدث حل المعالجة المسبقة الموصوفة في وقت خطي ثم ثابت. بالإضافة إلى ذلك ، أنا أعارض بشكل قاطع إجبار المرشح على تنفيذ عملية الفرز والبحث الثنائي على السبورة ، لأنه: 1) خوارزميات الفرز معروفة جيدًا ، لذلك ، بقدر ما أعرف ، يمكن للمرشح إصدارها دون تفكير ؛ 2) يصعب تنفيذ هذه الخوارزميات بشكل شيطاني ، وغالبًا ما يرتكب حتى أفضل المرشحين أخطاء لا تقل شيئًا عن مهاراتهم في البرمجة.
كلما اقترح أحد المرشحين مثل هذا الحل ، كنت مهتمًا بوقت تنفيذ البرنامج وسألني عما إذا كان هناك خيار أفضل. للحصول على معلومات: إذا سألك القائم بإجراء المقابلة إذا كان هناك خيار أفضل ، فالجواب دائمًا ما يكون نعم. إذا طرحت عليك هذا السؤال ، فإن الإجابة ستكون بالتأكيد.
وأخيرا الحل
في النهاية ، يقدم المرشح شيئًا صحيحًا ومثاليًا بشكل معقول. فيما يلي تطبيق في الوقت الخطي والمساحة الخطية لظروف معينة:
def synonym_queries(synonym_words, queries): ''' synonym_words: iterable of pairs of strings representing synonymous words queries: iterable of pairs of strings representing queries to be tested for synonymous-ness ''' synonyms = defaultdict(set) for w1, w2 in synonym_words: synonyms[w1].add(w2) output = [] for q1, q2 in queries: q1, q2 = q1.split(), q2.split() if len(q1) != len(q2): output.append(False) continue result = True for i in range(len(q1)): w1, w2 = q1[i], q2[i] if w1 == w2: continue elif ((w1 in synonyms and w2 in synonyms[w1]) or (w2 in synonyms and w1 in synonyms[w2])): continue result = False break output.append(result) return output
بعض الملاحظات السريعة:
- لاحظ استخدام
dict.get() . يمكنك تنفيذ فحص لمعرفة ما إذا كان المفتاح موجودًا في الأمر ، ثم الحصول عليه ، لكن هذا نهج معقد ، على الرغم من أنه بهذه الطريقة ستظهر معرفتك بالمكتبة القياسية. - أنا شخصياً لست من المعجبين بالكود مع المتابعة
continue ، وبعض أدلة الأنماط تمنعهم أو لا توصي بهم . أنا نفسي في الإصدار الأول من هذا الرمز نسيت بيان المتابعة بعد التحقق من طول الطلب. هذه ليست طريقة سيئة ، فقط اعلم أنها عرضة للخطأ.
الجزء 2: الحصول على أكثر صعوبة!
لا يزال أمام المرشحين الجيدين ، بعد حل المشكلة ، ما بين 10 إلى 15 دقيقة من الوقت المتبقي. لحسن الحظ ، هناك مجموعة من الأسئلة الإضافية ، على الرغم من أنه من غير المرجح أن نكتب الكثير من التعليمات البرمجية خلال هذا الوقت. ومع ذلك ، هذا ليس ضروريا. أريد أن أعرف شيئين عن المرشح: هل هو قادر على تطوير الخوارزميات وهل يمكنه الرمز؟ المشكلة في تحرك الفارس أولاً تجيب على سؤال حول تطوير الخوارزمية ، ثم تحقق من الترميز ، وهنا نحصل على الإجابات بالترتيب العكسي.
بحلول الوقت الذي أكمل فيه المرشح الجزء الأول من السؤال ، كان قد حل المشكلة بالفعل من خلال الترميز (غير المدهش). في هذه المرحلة ، يمكنني التحدث بثقة عن قدرته على تطوير خوارزميات بدائية وترجمة الأفكار إلى رمز ، وكذلك معرفته بلغته المفضلة ومكتبته القياسية. أصبحت المحادثة الآن أكثر إثارة للاهتمام ، لأنه يمكن الاسترخاء في متطلبات البرمجة ، وسنتعمق في الخوارزميات.
لهذا الغرض ، نعود إلى الافتراضات الرئيسية للجزء الأول: ترتيب الكلمات مهم ، المترادفات غير متعدية ، ولكل كلمة يمكن أن يكون هناك عدة مرادفات. مع تقدم المقابلة ، أقوم بتغيير كل من هذه القيود ، وفي هذه المرحلة الجديدة ، أقوم أنا والمرشح بإجراء مناقشة حسابية بحتة. سأقدم هنا أمثلة على الكود لتوضيح وجهة نظري ، لكن في مقابلة حقيقية نتحدث فقط عن الخوارزميات.
قبل البدء ، سأشرح موقفي: جميع الإجراءات اللاحقة في هذه المرحلة من المقابلة هي أساسًا "نقاط مكافأة". توجهي الشخصي هو تحديد المرشحين الذين يمرون بالمرحلة الأولى ويعدون مناسبين للعمل. هناك حاجة إلى المرحلة الثانية لتسليط الضوء على الأفضل. التصنيف الأول قوي بالفعل ويعني أن المرشح جيد بما فيه الكفاية للشركة ، والتصنيف الثاني يقول أن المرشح ممتاز وأن تعيينه سيكون نصرًا كبيرًا لنا.
الانتقالية: النهج الساذجة
أولاً ، أود إزالة قيد النقل ، لذا إذا كان الزوجان A - B و B - C هما مترادفتان ، فإن الكلمتين A و C هما مرادفتان. سوف يفهم المرشحون الأذكياء بسرعة كيفية تكييف حلهم السابق ، على الرغم من أنه مع إزالة القيود الأخرى ، فإن المنطق الأساسي للخوارزمية سوف يتوقف عن العمل.
ومع ذلك ، كيفية تكييفه؟ نهج واحد مشترك هو الحفاظ على مجموعة كاملة من المرادفات لكل كلمة على أساس العلاقات متعدية. في كل مرة نقوم فيها بإدراج كلمة في مجموعة من المرادفات ، نضيفها أيضًا إلى المجموعات المقابلة لكل الكلمات في هذه المجموعة:
synonyms = defaultdict(set) for w1, w2 in synonym_words: for w in synonyms[w1]: synonyms[w].add(w2) synonyms[w1].add(w2) for w in synonyms[w2]: synonyms[w].add(w1) synonyms[w2].add(w1)
يرجى ملاحظة أنه عند إنشاء الشفرة ، لقد بحثنا بالفعل في هذا الحل.هذا الحل يعمل ، ولكن أبعد ما يكون عن الأمثل. لفهم الأسباب ، نقدر التعقيد المكاني لهذا الحل. يجب إضافة كل مرادف ليس فقط لمجموعة الكلمة الأولى ، ولكن أيضًا إلى مجموعات جميع مرادفاتها. إذا كان هناك مرادف واحد ، فسيتم إضافة إدخال واحد. ولكن إذا كان لدينا 50 مرادفًا ، فيجب عليك إضافة 50 إدخالًا. في الشكل ، يبدو مثل هذا:
لاحظ أننا انتقلنا من ثلاثة مفاتيح وستة سجلات إلى أربعة مفاتيح واثني عشر سجلًا. ستتطلب الكلمة التي تحتوي على 50 مرادفًا 50 مفتاحًا وحوالي 2500 إدخال. المساحة اللازمة لتمثيل كلمة واحدة تنمو بشكل رباعي مع زيادة في مجموعة المرادفات ، والتي هي مضيعة إلى حد ما.
هناك حلول أخرى ، لكنني لن أبذل قصارى جهدي حتى لا أضخّم المقال. الأكثر إثارة للاهتمام منهم هو استخدام بنية بيانات مرادف لبناء رسم بياني موجه ، ومن ثم بحث أولي للعثور على المسار بين كلمتين. هذا حل رائع ، لكن البحث يصبح خطيًا في حجم مجموعة المرادفات للكلمة. نظرًا لأننا نجري هذا البحث لكل طلب عدة مرات ، فإن هذا الأسلوب ليس هو الأمثل.
Transitivity: استخدام مجموعات Disjoint
اتضح أن البحث عن المرادفات أمر ممكن لوقت ثابت (تقريبًا) بفضل بنية بيانات تسمى مجموعات منفصلة. يوفر هذا الهيكل إمكانيات مختلفة قليلاً عن مجموعة بيانات منتظمة.
بنية المجموعة المعتادة (hashset ، مجموعة الأشجار) عبارة عن حاوية تسمح لك بتحديد ما إذا كان الكائن داخلها أم خارجها بسرعة. تعمل مجموعات Disjoint على حل مشكلة مختلفة تمامًا: فبدلاً من تحديد عنصر معين ، تسمح لك بتحديد
ما إذا كان هناك عنصران ينتميان إلى نفس المجموعة . علاوة على ذلك ، فإن الهيكل يقوم بذلك لوقت سريع للغاية
O(a(n)) ، حيث
a(n) هي وظيفة أكرمان معكوسة. إذا لم تكن قد درست الخوارزميات المتقدمة ، فقد لا تعرف هذه الوظيفة ، والتي يتم تنفيذها فعليًا في جميع الأوقات بالنسبة لجميع المدخلات المعقولة.
على مستوى عالٍ ، تعمل الخوارزمية على النحو التالي. يتم تمثيل مجموعات من الأشجار مع الآباء لكل عنصر. نظرًا لأن كل شجرة لها جذر (عنصر يمثل أصلها الرئيسي) ، يمكننا تحديد ما إذا كان عنصران ينتميان إلى نفس المجموعة من خلال تتبع الوالدين على الجذر. إذا كان لدى عنصرين جذر واحد ، فهما ينتميان إلى مجموعة واحدة. من السهل أيضًا الجمع بين المجموعات: فما عليك سوى العثور على العناصر الجذرية وجعل أحدها جذر الآخر.
جيد حتى الآن ، ولكن حتى الآن لم تشهد أي سرعة مذهلة. عبقرية هذه البنية في إجراء يسمى
الضغط . افترض أن لديك الشجرة التالية:
تخيل أنك تريد معرفة ما إذا كانت
السرعة والمتسرعة مرادفات. اذهب من خلال كل والدين - والعثور على نفس الجذر
السريع . لنفترض الآن أننا نقوم بإجراء فحص مشابه للكلمات
السريعة والسريعة . مرة أخرى ، نذهب إلى الجذر ، ومن
السريع نسير في نفس الطريق. هل يمكن تجنب ازدواجية العمل؟
اتضح ما تستطيع. بمعنى ما ، كل عنصر في هذه الشجرة مقدر له أن
يصوم . بدلاً من المرور عبر الشجرة بأكملها في كل مرة ، لماذا لا تقوم بتغيير الوالد لجميع المتحدرين
بسرعة لتقصير الطريق إلى الجذر؟ هذه العملية تسمى الضغط ، وفي مجموعات منفصلة يتم تضمينها في عملية البحث عن الجذر. على سبيل المثال ، بعد أول عملية مقارنة
سريعة ومتسارعة ، ستفهم البنية أنها مترادفات وستضغط الشجرة على النحو التالي:
بالنسبة لجميع الكلمات بين السرعة والسرعة ، تم تحديث الأصل ، حدث الشيء نفسه مع متسرعالآن ستحدث جميع المكالمات اللاحقة في وقت ثابت ، لأن كل عقدة في هذه الشجرة تشير إلى
الصيام . ليس من السهل للغاية تقييم التعقيد الزمني للعمليات: في الواقع ، ليس ثابتًا ، لأنه يعتمد على عمق الأشجار ، ولكنه قريب من الثابت ، لأن الهيكل يتم تحسينه بسرعة. للبساطة ، نحن نفترض أن الوقت ثابت.
مع هذا المفهوم ، ننفذ مجموعات غير مرتبطة بمشكلتنا:
class DisjointSet(object): def __init__(self): self.parents = {} def get_root(self, w): words_traversed = [] while self.parents[w] != w: words_traversed.append(w) w = self.parents[w] for word in words_traversed: self.parents[word] = w return w def add_synonyms(self, w1, w2): if w1 not in self.parents: self.parents[w1] = w1 if w2 not in self.parents: self.parents[w2] = w2 w1_root = self.get_root(w1) w2_root = self.get_root(w2) if w1_root < w2_root: w1_root, w2_root = w2_root, w1_root self.parents[w2_root] = w1_root def are_synonymous(self, w1, w2): return self.get_root(w1) == self.get_root(w2)
باستخدام هذا الهيكل ، يمكنك معالجة المترادفات مسبقًا وحل المشكلة في الوقت الخطي.التقييم والملاحظات
بحلول هذا الوقت ، وصلنا إلى الحد الأقصى لما يمكن للمرشح إظهاره في 40-45 دقيقة من المقابلة. لجميع المرشحين الذين تعاملوا مع الجزء التمهيدي وأحرزوا تقدمًا كبيرًا في وصف (لا ينفذون) مجموعات غير مرتبطة ، حددت تصنيفًا "موصى به للغاية للتأجير" وسمحت لهم بطرح أي أسئلة. لم أر أي مرشح يذهب إلى هذا الحد ولم يتبق الكثير من الوقت.من حيث المبدأ ، لا تزال هناك متغيرات للمشكلة المتعلقة بالنقل: على سبيل المثال ، قم بإزالة القيود المفروضة على ترتيب الكلمات أو على عدة مرادفات لكلمة. سيكون كل قرار صعبًا وممتعًا ، لكنني سأتركه لاحقًا.ميزة هذه المهمة هي أنها تسمح للمرشحين بارتكاب أخطاء. يتكون تطوير البرامج اليومي من دورات لا تنتهي من التحليل والتنفيذ والصقل. تتيح هذه المشكلة للمرشحين إظهار قدراتهم في كل مرحلة. النظر في المهارات اللازمة للحصول على أقصى درجة في هذه المسألة:- النظر في بيان المشكلة و تحديد مكان ليس بما فيه الكفاية التعبير ، وضع صياغة واضحة. استمر في القيام بذلك أثناء حلك وتثور أسئلة جديدة. لتحقيق أقصى قدر من الكفاءة ، قم بتنفيذ هذه العمليات في أقرب وقت ممكن ، لأنه كلما استمر العمل ، زاد الوقت اللازم لإصلاح الخطأ.
- , . , .
- . , , .
- , . ,
continue , , .
- , : , , , . , , , .
- . — , . — .
لا يمكن تعلم أي من هذه المهارات من الكتب المدرسية (مع استثناء محتمل لهياكل البيانات والخوارزميات). الطريقة الوحيدة لاكتساب هذه الممارسات هي الممارسة المنتظمة والواسعة ، والتي تتوافق جيدًا مع ما يحتاج إليه صاحب العمل: المرشحون المتمرسون القادرون على تطبيق معارفهم بفعالية. كان الهدف من المقابلات هو العثور على هؤلاء الأشخاص ، وقد ساعدتني مهمة هذا المقال جيدًا لفترة طويلة.الخطط المستقبلية
كما يمكنك أن تفهم ، أصبحت المهمة في نهاية المطاف معروفة للجمهور . منذ ذلك الحين ، استخدمت العديد من الأسئلة الأخرى ، بناءً على ما طرحه المقابلات السابقون وعلى مزاجي (طرح سؤال واحد ممل طوال الوقت). ما زلت أستخدم بعض الأسئلة ، لذلك سأبقيها سراً ، لكن البعض الآخر ليس كذلك! يمكنك العثور عليها في المقالات التالية.في المستقبل القريب أخطط لمادتين. أولاً ، كما وعدنا أعلاه ، سأشرح الحل للمشكلتين المتبقيتين لهذه المهمة. لم أطلب منهم أبدًا في المقابلات ، لكنهم مثيرون للاهتمام في أنفسهم. بالإضافة إلى ذلك ، سوف أشارك أفكاري وآرائي الشخصية حول الإجراء الخاص بالعثور على موظفين في تكنولوجيا المعلومات ، وهو ما يهمني بشكل خاص الآن لأنني أبحث عن مهندسين لفريقي في Reddit.كما هو الحال دائمًا ، إذا كنت تريد معرفة إصدار مقالات جديدة ، فاتبعني على Twitter أو على " متوسط" . إذا أعجبك هذا المقال ، فلا تنس التصويت لصالحه أو اترك تعليقًا.شكرا للقراءة!PS: يمكنك فحص شفرة جميع المقالات في هذا جيثب مستودع أو اللعب معهم حية بفضل أصدقائي جيدة من repl.it .