
يكتسب موضوع تحسين أداء أنظمة التشغيل وإيجاد الاختناقات شعبية هائلة. في هذه المقالة ، سنتحدث عن أداة واحدة للعثور على هذه الأماكن بالذات باستخدام مثال مكدس الكتلة في Linux وحالة واحدة لاستكشاف أخطاء المضيف.
مثال 1. اختبار
لا شيء يعمل
الاختبار في قسمنا هو مواد تركيبية على أجهزة المنتج واختبارات برامج التطبيقات اللاحقة. تلقينا محرك Intel Optane للاختبار. لقد كتبنا بالفعل عن اختبار محركات Optane
في مدونتنا .
تم تثبيت القرص في خادم قياسي تم إنشاؤه لفترة طويلة نسبيًا ضمن أحد المشاريع السحابية.
أثناء الاختبار ، أظهر القرص نفسه ليس بأفضل طريقة: أثناء الاختبار بعمق قائمة انتظار طلب 1 لكل تيار ، في كتل من 4 كيلو بايت حوالي 70 كيلو بايت. وهذا يعني أن زمن الاستجابة ضخم: حوالي 13 ميكروثانية لكل طلب!
إنه أمر غريب ، لأن
المواصفات تعد بـ "زمن الاستجابة - قراءة 10 ”s" ، وحصلنا على 30٪ أكثر ، الفرق كبير جدًا. تمت إعادة ترتيب القرص إلى نظام أساسي آخر ، وهو مجموعة "جديدة" تستخدم في مشروع آخر.
لماذا تعمل؟
إنه أمر مضحك ، ولكن كان محرك الأقراص على المنصة الجديدة يعمل كما ينبغي. زيادة الأداء ، وانخفض الكمون ، وحدة المعالجة المركزية لكل رف ، تيار واحد لكل طلب ، كتل بايت 4K ، ~ 106 كيلو بايت في حوالي 9 ميكروثانية لكل طلب.
ثم حان الوقت
لمقارنة الإعدادات للحصول على أفضل
أداء من
الأرجل الواسعة. بعد كل شيء ، نتساءل لماذا؟ مع
perf ، يمكنك:
- خذ قراءات عدادات الأجهزة: عدد مكالمات التعليمات ، وملفات التخزين المؤقت المفقودة ، والفروع التي تم التنبؤ بها بشكل غير صحيح ، إلخ. (أحداث PMU)
- قم بإزالة المعلومات من نقاط التداول الثابتة ، وعدد الأحداث
- إجراء تتبع ديناميكي
للتحقق ، استخدمنا أخذ العينات وحدة المعالجة المركزية.
خلاصة القول هي أن
perf يمكن أن تقوم بتجميع تتبع المكدس بالكامل لبرنامج قيد التشغيل. وبطبيعة الحال ، سيؤدي تشغيل
perf إلى تأخير تشغيل النظام بأكمله. ولكن لدينا العلم
-F # ، حيث
# هو تردد أخذ العينات ، ويقاس بال هرتز.
من المهم أن نفهم أنه كلما زاد تردد أخذ العينات ، زاد احتمال اتصاله بوظيفة معينة ، ولكن كلما زاد عدد المكابح التي يقدمها المحول إلى النظام. كلما كان التردد أقل ، زادت فرصة عدم رؤية جزء من المكدس.
عند اختيار التردد ، تحتاج إلى الاسترشاد بالحس السليم وخدعة واحدة - حاول ألا تضبط ترددًا متساويًا ، حتى لا تدخل في موقف عندما تدخل بعض الأعمال التي تعمل على جهاز توقيت مع هذا التردد في العينات.
هناك نقطة أخرى مضللة في البداية - يجب أن يتم تجميع البرنامج باستخدام مؤشر flag
-fno-omit ، إذا كان ذلك ممكنًا بالطبع. خلاف ذلك ، في التتبع ، بدلاً من أسماء الوظائف ، سنرى قيمًا
غير معروفة صلبة. بالنسبة لبعض البرامج ، تأتي رموز تصحيح الأخطاء كحزمة منفصلة ، على سبيل المثال ،
someutil-dbg . يوصى بتثبيتها قبل تشغيل
perf .
قمنا بتنفيذ الإجراءات التالية:
- تم الحصول عليها من fio: //git.kernel.dk/fio.git ، tag fio-3.9
- تمت إضافة الخيار -fno-omit-frame- index إلى CPPFLAGS في Makefile
- أطلقت جعل -J8
perf record -g ~/fio/fio --name=test --rw=randread --bs=4k --ioengine=pvsync2 --filename=/dev/nvme0n1 --direct=1 --hipri --filesize=1G
هناك حاجة إلى الخيار -g لالتقاط مكدس التتبعات.
يمكنك عرض النتيجة بواسطة الأمر:
perf report -g fractal
هناك حاجة إلى الخيار
-g فركتل بحيث النسب المئوية التي تعكس عدد العينات مع هذه الوظيفة والتي تظهر من خلال
perf هي نسبة إلى وظيفة الاستدعاء ، التي يتم أخذ عدد المكالمات منها 100 ٪.
قرب نهاية مكدس fio call الطويل على النظام الأساسي "fresh build" ، سنرى:
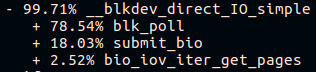
وعلى منصة "البناء القديم":

عظيم! لكنني أريد flamegrafs جميلة.
بناء flamegrams
لتكون جميلة ، هناك أداتان:
- نسبيا flamegraph ثابت
- Flamescope ، والذي يجعل من الممكن تحديد فترة زمنية محددة من العينات التي تم جمعها. هذا مفيد للغاية عندما يقوم رمز البحث بتحميل وحدة المعالجة المركزية مع رشقات قصيرة.
تقبل هذه الأدوات المساعدة
النص البرمجي perf> مدخلات.
تنزيل
النتيجة وإرسالها عبر الأنابيب إلى
svg :
FlameGraph/stackcollapse-perf.pl ./result | FlameGraph/flamegraph.pl > ./result.svg
افتح في متصفح واستمتع بصور قابلة للنقر.
يمكنك استخدام طريقة أخرى:
- إضافة نتيجة إلى flamescope / مثال /
- تشغيل بيثون
- نذهب من خلال المتصفح إلى 5000 منفذ للمضيف المحلي
ماذا نرى في النهاية؟
إن السيرة الذاتية الجيدة تقضي الكثير من الوقت في
الاقتراع :
قوة سحرية سيئة تقضي وقتًا في أي مكان ، ولكن ليس في الاقتراع:
للوهلة الأولى ، يبدو أن الاقتراع لا يعمل على المضيف القديم ، ولكن في كل مكان يكون 4.15 kernel من نفس التجميع ويتم تمكين الاستقصاء افتراضيًا على أقراص NVMe. تحقق مما إذا تم تمكين الاستقصاء في
sysfs :
أثناء الاختبارات ، يتم
استخدام مكالمات
preadv2 التي تحمل علامة
RWF_HIPRI - وهي شرط ضروري
لاستكمال عملية الاقتراع. وإذا كنت تدرس بعناية الرسم البياني للهب (أو لقطة الشاشة السابقة من إخراج
تقرير perf ) ، فيمكنك العثور عليها ، ولكنها تستغرق وقتًا صغيرًا للغاية.
الشيء الثاني المرئي هو مكدس الاستدعاءات المختلف للدالة submit_bio () وعدم وجود مكالمات io_schedule (). دعونا نلقي نظرة فاحصة على الفرق داخل submit_bio ().
منصة بطيئة "البناء القديم":
منصة سريعة "جديدة":
يبدو أنه على النظام الأساسي البطيء ، يقطع الطلب شوطًا طويلًا في الجهاز ، وفي الوقت نفسه الدخول في برنامج
جدولة kyber . يمكنك قراءة المزيد حول برامج الإدخال / الإخراج في
مقالتنا .
مرة واحدة تم إيقاف تشغيل kyber ، أظهر اختبار fio نفسه متوسط زمن الوصول حوالي 10 ميكروثانية ، كما هو مذكور في المواصفات. عظيم!
ولكن من أين يأتي الفرق في ميكروثانية أخرى؟
وإذا أعمق قليلا؟
كما سبق ذكره ، يسمح لك
perf بجمع إحصائيات من عدادات الأجهزة. دعنا نحاول أن نرى عدد أخطاء ذاكرة التخزين المؤقت وتعليمات كل دورة:
perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles /root/fio/fio --clocksource=cpu --name=test --bs=4k --filename=/dev/nvme0n1p4 --direct=1 --ioengine=pvsync2 --hipri --rw=randread --filesize=4G --loops=10


يمكن أن نرى من النتائج أن النظام الأساسي السريع ينفذ المزيد من الإرشادات لدورة وحدة المعالجة المركزية ويحتوي على نسبة أقل من ذاكرة التخزين المؤقت المفقودة أثناء التنفيذ. بالطبع ، لن ندخل في تفاصيل تشغيل الأنظمة الأساسية للأجهزة المختلفة في إطار هذه المقالة.
مثال 2. بقالة
هناك خطأ ما
في عمل نظام تخزين البيانات الموزع ، لوحظ زيادة في الحمل على وحدة المعالجة المركزية على أحد المضيفين مع زيادة حركة المرور الواردة. المضيفين هم أقرانهم وأقرانهم ولديهم أجهزة وبرامج مماثلة.
دعنا ننظر إلى تحميل وحدة المعالجة المركزية:
~
نشأت المشكلة في 09:23:46 ونرى أن العملية نجحت في مساحة kernel حصريًا للثانية بأكملها. دعونا ننظر إلى ما كان يحدث في الداخل.
لماذا بطيئة جدا؟
في هذه الحالة ، أخذنا عينات من النظام بأكمله:
perf record -a -g -- sleep 22 perf script > perf.results
الخيار
-a مطلوب هنا للحصول على
perf لإزالة الآثار من جميع وحدات المعالجة المركزية.
افتح
perf.results مع
flamescope لتتبع لحظة زيادة تحميل وحدة المعالجة المركزية.
أمامنا "خريطة حرارة" ، يمثل كلا المحورين (X و Y) الوقت.
على المحور X ، يتم تقسيم المساحة إلى ثوانٍ ، وعلى المحور Y ، إلى شرائح من 20 مللي ثانية في غضون X ثانية ، ويمتد الوقت من الأسفل إلى الأعلى ومن اليسار إلى اليمين. ألمع المربعات لديها أكبر عدد من العينات. وهذا هو ، وحدة المعالجة المركزية في هذا الوقت عملت بنشاط أكبر.
في الواقع ، نحن مهتمون بالبقعة الحمراء في الوسط. حدده بالماوس ، وانقر فوقه وشاهد ما يخفيه:
بشكل عام ، من الواضح بالفعل أن المشكلة
تكمن في العملية البطيئة
tcp_recvmsg و
skb_copy_datagram_iovec .
للوضوح ، قارن مع نماذج مضيف آخر لا تسبب فيه نفس مقدار الحركة الواردة مشاكل:
استنادًا إلى حقيقة أن لدينا نفس القدر من حركة المرور الواردة ، والمنصات المتطابقة التي كانت تعمل لفترة طويلة دون توقف ، يمكننا أن نفترض أن المشاكل قد نشأت على جانب الحديد. تقوم دالة
skb_copy_datagram_iovec بنسخ البيانات من بنية kernel إلى البنية في مساحة المستخدم لتمريرها إلى التطبيق. ربما هناك مشاكل مع ذاكرة المضيف. في الوقت نفسه ، لا توجد أخطاء في السجلات.
نعيد تشغيل النظام الأساسي. عند تحميل نظام الإدخال / الإخراج الأساسي (BIOS) ، نرى رسالة حول شريط ذاكرة مكسور. استبدال ، يبدأ المضيف ولم يعد يتم تكرار المشكلة مع وحدة المعالجة المركزية المحملة.
بوستسكريبت
أداء النظام مع perf
بشكل عام ، على نظام مزدحم ، قد يؤدي تشغيل
perf إلى تأخير في معالجة الطلبات. يعتمد حجم هذه التأخيرات أيضًا على الحمل على الخادم.
دعنا نحاول العثور على هذا التأخير:
~
الفرق ليس ملحوظًا للغاية ، فقط حوالي 8 نانو ثانية.
دعونا نرى ما يحدث إذا قمت بزيادة الحمل:
~
هنا الفرق أصبح بالفعل ملحوظا. يمكن القول أن النظام تباطأ بنسبة أقل من 1 ٪ ، ولكن فقدان حوالي 7Kiops على نظام محملة بشكل كبير يمكن أن يؤدي إلى مشاكل.
من الواضح أن هذا المثال اصطناعي ، ومع ذلك فهو يكشف كثيرًا.
دعونا نحاول إجراء اختبار اصطناعي آخر يحسب الأعداد الأولية -
sysbench :
~
هنا يمكنك أن ترى أنه حتى الحد الأدنى لوقت المعالجة زاد بمقدار 270 ميكروثانية.
بدلا من الاستنتاج
يعد
Perf أداة قوية للغاية لتحليل أداء النظام وتصحيح الأخطاء. ومع ذلك ، كما هو الحال مع أي أداة أخرى ، تحتاج إلى الحفاظ على نفسك في السيطرة وتذكر أن أي نظام تحميل تحت إشراف دقيق يعمل بشكل أسوأ.
روابط ذات صلة: